1. What is cache avalanche? How?
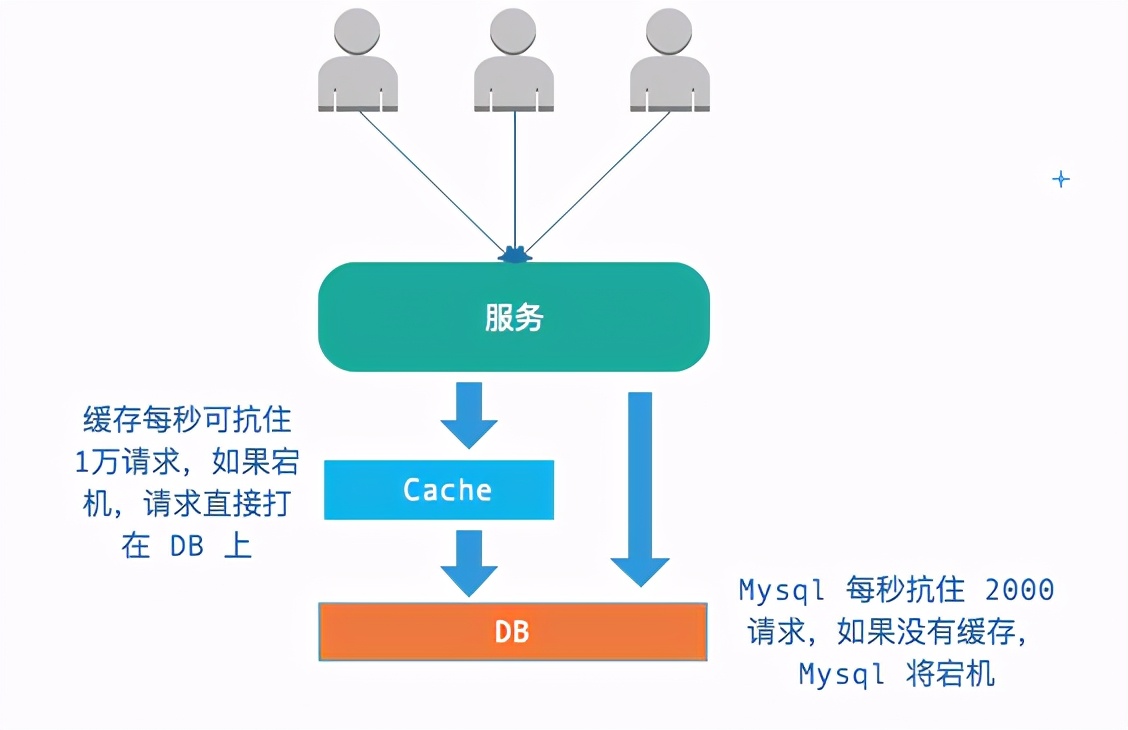
Usually, we use cache to buffer the impact on DB. If the cache goes down, all requests will be directly sent to DB, resulting in DB downtime - leading to the downtime of the whole system.
How to solve it?
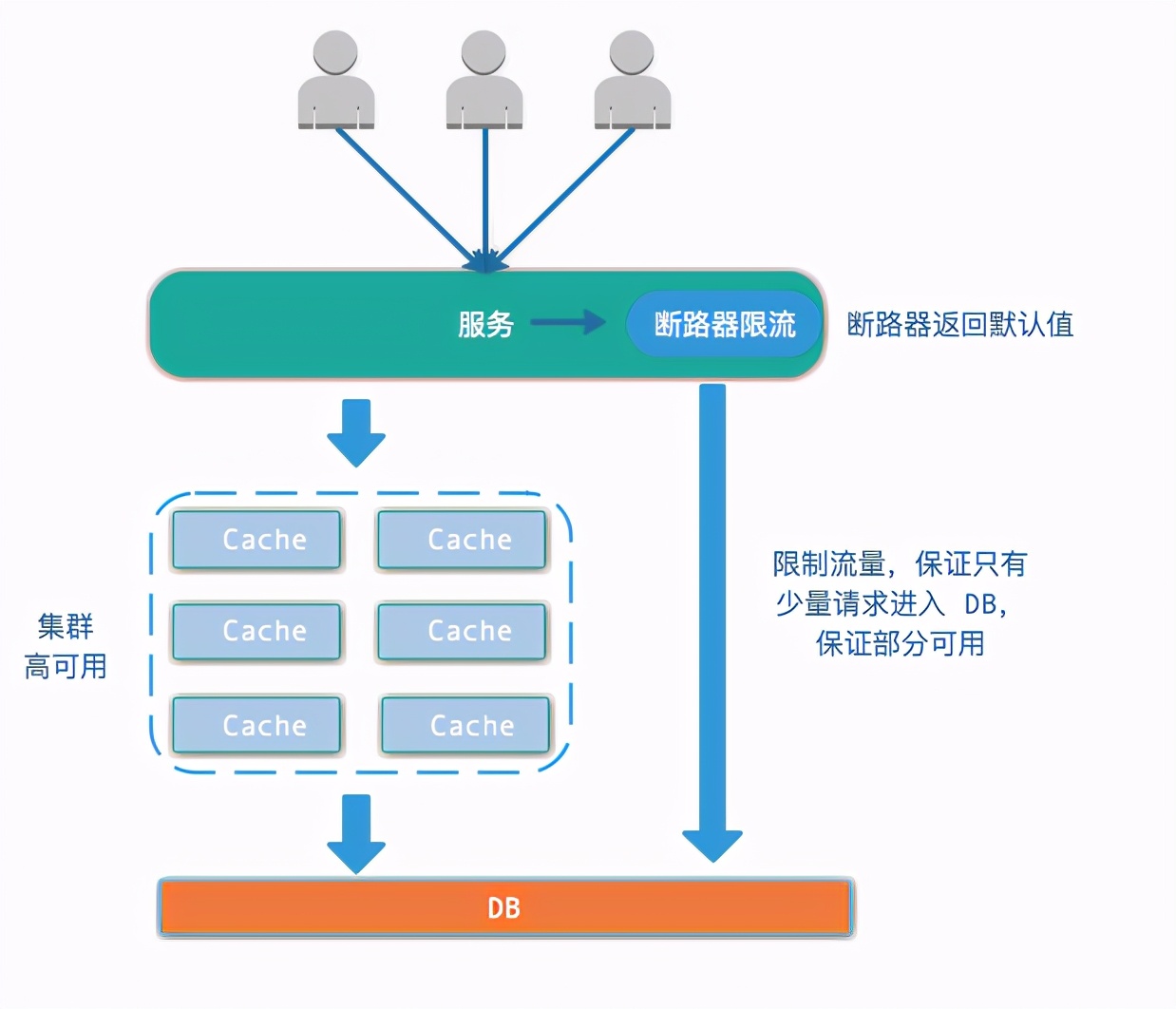
Two strategies (used simultaneously):
- Make cache highly available to prevent cache downtime
- Using the circuit breaker, if the cache goes down, in order to prevent all system downtime, limit part of the flow into the DB and ensure that some are available, and the remaining requests return to the default value of the circuit breaker.
2. What is the inconsistency between cache and database double write? How?
Explanation: the database and cache are written continuously, but during the operation, concurrency occurs and the data is inconsistent.
Generally, there are several orders for updating the cache and database:
- Update the database first and then the cache.
- Delete the cache first, and then update the database.
- Update the database before deleting the cache.
Look at the advantages and disadvantages of the three methods:
Update the database first and then the cache.
The problem with this is: when two requests update data at the same time, if you do not use distributed locks, you will not be able to control the last cached value. That is, there is a problem when writing concurrently.
Delete the cache first, and then update the database.
The problem of doing so: if a client reads data after deleting the cache, it may read the old data and set it into the cache, resulting in the data in the cache always being old data.
There are 2 solutions:
- Use "double deletion", that is, delete and change deletion. The last step of deletion is asynchronous operation, which is to prevent the old value from being set when a client reads it.
- Use the queue. When the key does not exist, put it into the queue for serial execution. You can't read the data until the database is updated.
Generally speaking, it's troublesome.
Update the database before deleting the cache
This is actually a commonly used scheme, but many people don't know it. Here's an introduction. It's called Cache Aside Pattern, which was invented by foreigners. If you update the database first and then delete the cache, there will be instant data before updating the database, which is not very timely.
At the same time, if the cache just fails before the update, the reading client may read the old value, and then set the old value again after the deletion of the writing client. It is a very coincidence.
There are two preconditions: the cache fails before writing, and the old data is placed after the write client deletion operation is completed - that is, the read is slower than the write** Set that some write operations will also lock the table**
So, this is hard to appear, but what if it does? Use double delete!!! Whether the client reads the database during the update of the record. If so, perform the delayed deletion after the database is updated.
There is another possibility. What if the service hangs when updating the database and preparing to delete the cache, and the deletion fails???
This is the pit!!! However, it can be deleted by subscribing to the binlog of the database.
3. Talk about the relationship between hashCode() and equals()?
introduce
equals() is used to determine whether two objects are equal.
hashCode() is used to obtain hash code, also known as hash code; It actually returns an int integer. The function of this hash code is to determine the index position of the object in the hash table.
relationship
We use "class purpose" to explain the "relationship between hashCode() and equals()" in two cases.
1. Hash table corresponding to class will not be created
By "not creating hash table corresponding to class", we mean that we will not use this class in HashSet, Hashtable, HashMap and other data structures that are essentially hash tables. For example, the HashSet collection for this class will not be created.
In this case, "hashCode() and equals()" of this class have no relationship of half a dime! Equals () is used to compare whether two objects of this class are equal. Hashcode () has no effect at all.
Next, let's check the value of hashCode() when two objects of a class are equal or unequal through an example.
import java.util.*;
import java.lang.Comparable;
/**
* @desc Compare the value of hashCode() when equals() returns true and false.
*
*/
public class NormalHashCodeTest{
public static void main(String[] args) {
// Create two Person objects with the same content,
// Then use equals to compare whether they are equal
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
System.out.printf("p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
System.out.printf("p1.equals(p3) : %s; p1(%d) p3(%d)\n", p1.equals(p3), p1.hashCode(), p3.hashCode());
}
/**
* @desc Person Class.
*/
private static class Person {
int age;
String name;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + " - " +age;
}
/**
* @desc Override equals method
*/
public boolean equals(Object obj){
if(obj == null){
return false;
}
//If it is the same object, return true; otherwise, return false
if(this == obj){
return true;
}
//Determine whether the types are the same
if(this.getClass() != obj.getClass()){
return false;
}
Person person = (Person)obj;
return name.equals(person.name) && age==person.age;
}
}
}Operation results:
p1.equals(p2) : true; p1(1169863946) p2(1901116749) p1.equals(p3) : false; p1(1169863946) p3(2131949076)
It can also be seen from the results that when p1 and p2 are equal, hashCode() is not necessarily equal.
2. A hash table corresponding to the class is created
The "hash table corresponding to the class" mentioned here means that we will use this class in HashSet, Hashtable, HashMap and other data structures that are essentially hash tables. For example, a HashSet collection of this class is created.
In this case, "hashCode() and equals()" of this class are related:
- If two objects are equal, they must have the same hashCode() value. Equality here means that it returns true when comparing two objects through equals().
- If two objects hashCode() are equal, they are not necessarily equal. Because in the hash table, hashCode() is equal, that is, the hash values of two key value pairs are equal. However, equal hash values do not necessarily lead to equal key value pairs. Add: "two different key value pairs have equal hash values", which is hash conflict.
In addition, in this case. To determine whether two objects are equal, override the hashCode() function in addition to equals (). Otherwise, equals() is invalid.
For example, to create a HashSet collection of a Person class, you must override both the equals() and hashCode() methods of the Person class.
If you just override the equals() method. We will find that the equals() method does not achieve the desired effect.
import java.util.*;
import java.lang.Comparable;
/**
* @desc Compare the value of hashCode() when equals() returns true and false.
*
*/
public class ConflictHashCodeTest1{
public static void main(String[] args) {
// Create a new Person object,
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
// New HashSet object
HashSet set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
// Compare p1 and p2 and print their hashCode()
System.out.printf("p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
// Print set
System.out.printf("set:%s\n", set);
}
/**
* @desc Person Class.
*/
private static class Person {
int age;
String name;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return "("+name + ", " +age+")";
}
/**
* @desc Override equals method
*/
@Override
public boolean equals(Object obj){
if(obj == null){
return false;
}
//If it is the same object, return true; otherwise, return false
if(this == obj){
return true;
}
//Determine whether the types are the same
if(this.getClass() != obj.getClass()){
return false;
}
Person person = (Person)obj;
return name.equals(person.name) && age==person.age;
}
}
}Operation results:
p1.equals(p2) : true; p1(1169863946) p2(1690552137) set:[(eee, 100), (eee, 100), (aaa, 200)]
Result analysis:
We have rewritten the equals() of Person. However, it is strange to find that there are still duplicate elements in HashSet: p1 and p2. Why does this happen?
This is because although the contents of p1 and p2 are equal, their hashcodes () are different; Therefore, when adding p1 and p2, HashSet thinks they are not equal.
What about overriding the equals() and hashCode() methods at the same time?
import java.util.*;
import java.lang.Comparable;
/**
* @desc Compare the value of hashCode() when equals() returns true and false.
*
*/
public class ConflictHashCodeTest2{
public static void main(String[] args) {
// Create a new Person object,
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
Person p4 = new Person("EEE", 100);
// New HashSet object
HashSet set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
// Compare p1 and p2 and print their hashCode()
System.out.printf("p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
// Compare p1 and p4 and print their hashCode()
System.out.printf("p1.equals(p4) : %s; p1(%d) p4(%d)\n", p1.equals(p4), p1.hashCode(), p4.hashCode());
// Print set
System.out.printf("set:%s\n", set);
}
/**
* @desc Person Class.
*/
private static class Person {
int age;
String name;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + " - " +age;
}
/**
* @desc Rewrite hashCode
*/
@Override
public int hashCode(){
int nameHash = name.toUpperCase().hashCode();
return nameHash ^ age;
}
/**
* @desc Override equals method
*/
@Override
public boolean equals(Object obj){
if(obj == null){
return false;
}
//If it is the same object, return true; otherwise, return false
if(this == obj){
return true;
}
//Determine whether the types are the same
if(this.getClass() != obj.getClass()){
return false;
}
Person person = (Person)obj;
return name.equals(person.name) && age==person.age;
}
}
}Operation results:
p1.equals(p2) : true; p1(68545) p2(68545) p1.equals(p4) : false; p1(68545) p4(68545) set:[aaa - 200, eee - 100]
Result analysis:
Now, equals() takes effect, and there are no duplicate elements in the HashSet.
Comparing p1 and p2, we find that their hashcodes () are equal, and they also return true by comparing with equals(). p1 is considered equal to p2.
Comparing p1 and p4, we find that although their hashCode() is equal; However, by comparing them with equals(), they return false. Therefore, p1 and p4 are considered to be unequal.
principle
1. Whenever the same object (not modified) calls hashCode(), the return value must be the same. If a key object calls hashCode() during put to determine the storage location, and calls hashCode() during get to get a different return value. This value is mapped to a different place from the original, then the original key value pair must not be found.
2. Objects with equal return values of hashCode() are not necessarily equal. An object must be uniquely identified through hashCode() and equals(). The results of hashCode() of unequal objects can be equal. hashCode() should also pay attention to the generation speed when paying attention to the collision problem. Perfect hash is unrealistic.
3. Once the equals() function is rewritten (pay attention to reflexivity, symmetry, transitivity and consistency when rewriting equals), the hashCode() function must be rewritten. Moreover, the hash value generated by hashCode() should be based on the field used to compare whether it is equal in equals().
If the hashcodes generated by two equal objects specified by equals() are different, they are likely to be mapped to different locations for hashMap. There is no chance to call equals() to compare whether they are equal. Two actually equal objects may be inserted into different locations and errors occur. Other methods based on this hash class may also have problems
4. Talk about the following methods of Object class?
How many methods are there for Object?
Java language is a single inheritance structure language. All classes in java have a common ancestor. This ancestor is the Object class.
If a class does not explicitly indicate that it inherits from a class with extensions, it inherits the Object class by default.
We usually use the method of Object, but if we are not prepared to be asked suddenly, we are still a little confused.
analysis
The Object class is the base class of all classes in Java. Located in Java Lang package, a total of 13 methods. As shown below:
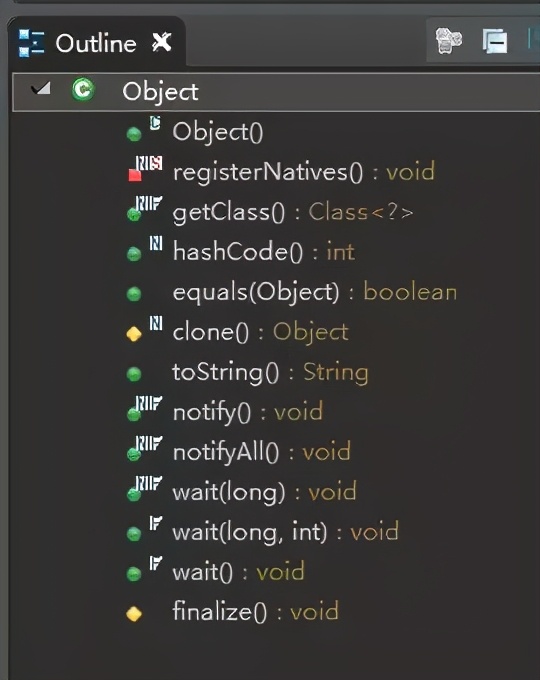
Specific answers
1.Object()
There's nothing to say about this. The constructor of the Object class. (non key)
2.registerNatives()
In order for the JVM to discover native functions, they are named in a certain way. For example, for
java.lang.Object.registerNatives. The corresponding C function is named Java_java_lang_Object_registerNatives.
By using registernatives (or more precisely, JNI function registernatives), you can name any C function you want. (non key)
3.clone()
The purpose of the clone() function is to save another existing object. This method can be called only when the clonable interface is implemented, otherwise it will be thrown
CloneNotSupportedException exception. (Note: answering here may lead to questions about design patterns)
4.getClass()
final method to get the type of the runtime. This method returns the class Object / runtime class Object of this Object object. Effect and Object Class is the same. (Note: answering here may lead to questions about class loading, reflection and other knowledge points)
5.equals()
Equals is used to compare whether the contents of two objects are equal. By default (inherited from the Object class), equals and = = are the same unless overridden. (Note: this may lead to more frequently asked questions about "the difference between equals and = =" and the implementation principle of hashmap)
6.hashCode()
This method is used to return the physical address (hash code value) of the object where it is located. It is often rewritten at the same time as the equals method to ensure that two equal objects have equal hashcodes. (again, it may lead to questions about the implementation principle of hashmap)
7.toString()
The toString() method returns the string representation of the object. This method has nothing to say.
8.wait()
Causes the current thread to wait until another thread calls the notify() method or notifyAll() method of this object. (lead to thread communication and the question of "the difference between wait and sleep")
9.wait(long timeout)
Causes the current thread to wait until another thread calls the notify() method or notifyAll() method of this object, or exceeds the specified amount of time. (lead to thread communication and the question of "the difference between wait and sleep")
10.wait(long timeout, int nanos)
Causes the current thread to wait until another thread calls the notify() method or notifyAll() method of this object, or another thread interrupts the current thread, or it has exceeded a certain actual amount of time. (lead to thread communication and the question of "the difference between wait and sleep")
11.notify()
Wake up a single thread waiting on this object monitor. (ask questions about thread communication)
12. notifyAll()
Wake up all threads waiting on this object monitor. (ask questions about thread communication)
13.finalize()
This method is called by the object's garbage collector when the garbage collector determines that there are no more references to the object. (it's not important, but be careful to ask questions about garbage collection)
5. How does redis implement distributed locks?
There are three common implementations of distributed locks:
- Database lock;
- Redis based distributed lock;
- Distributed lock based on ZooKeeper.
The local interview site is. Are you familiar with Redis? How to implement distributed locks in Redis.
main points
To realize distributed locking, Redis should meet the following conditions
Mutex
- At any time, only one client can hold the lock.
No deadlock
- The client crashes while holding the lock without actively unlocking, which can also ensure that other subsequent clients can lock.
Fault tolerance
- As long as most Redis nodes operate normally, the client can lock and unlock.
realization
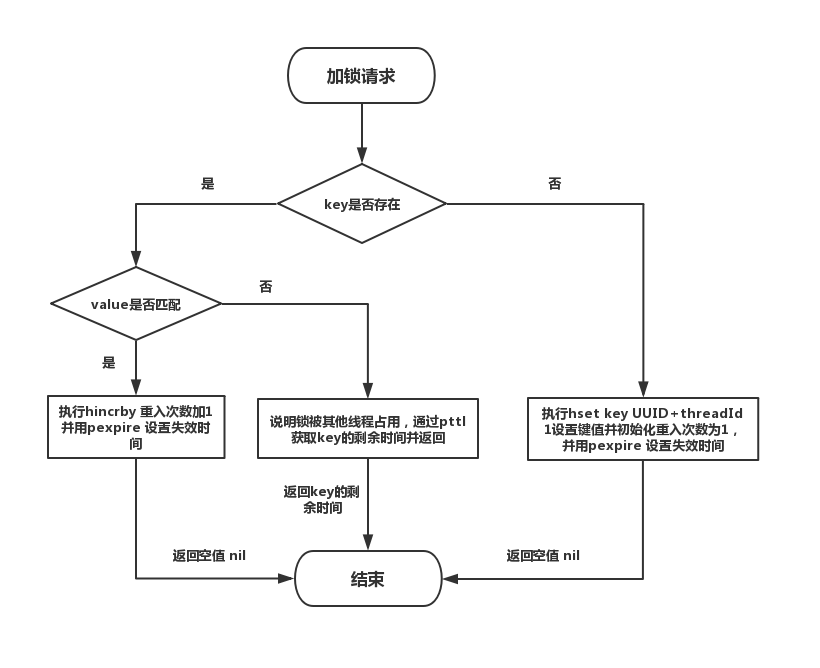
Locking can be realized directly through the set key value px milliseconds nx command, and unlocking can be realized through Lua script.
//Obtain lock (unique_value can be UUID, etc.)
SET resource_name unique_value NX PX 30000
//Release the lock (in lua script, be sure to compare value to prevent accidental unlocking)
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endCode interpretation
- The set command uses , set key value px milliseconds nx instead of , setnx + expire , which needs to execute the command twice to ensure atomicity,
- To make value unique, you can use UUID randomUUID(). The toString () method is used to identify which request the lock belongs to, and there can be a basis when unlocking;
- When releasing the lock, verify the value value to prevent false unlocking;
- Use Lua script to avoid the concurrency problem of Check And Set model, because multiple Redis operations are involved when releasing the lock (using the atomicity of eval command to execute Lua script);
Lock code analysis
First, the NX parameter is added to set() to ensure that if the existing key exists, the function will not be called successfully, that is, only one client can hold the lock and meet the mutual exclusion. Secondly, because we have set the expiration time for the lock, even if the lock holder crashes and does not unlock later, the lock will be unlocked automatically (i.e. the key will be deleted) because of the expiration time, and there will be no deadlock. Finally, because we assign value to requestId to identify which request the lock belongs to, we can verify whether it is the same client when the client is unlocked.
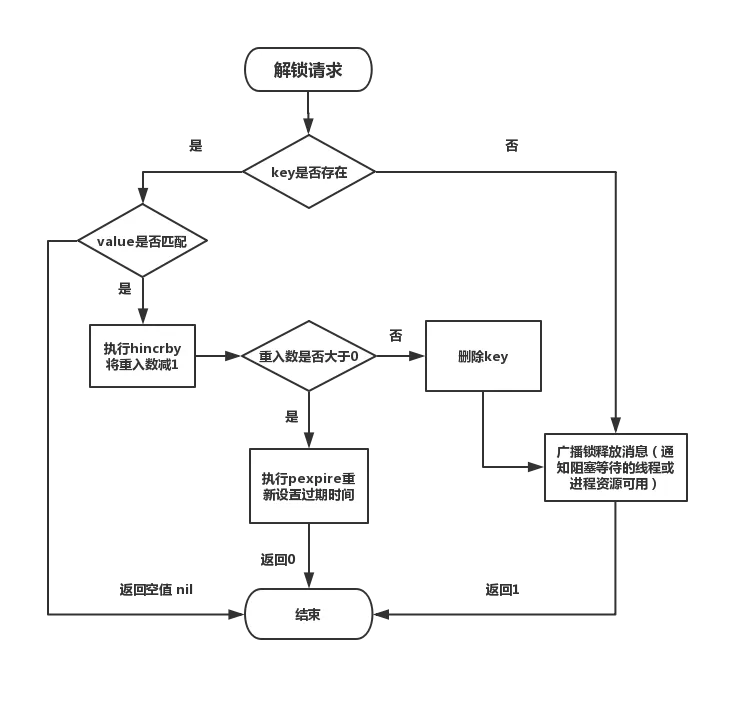
Unlock code analysis
Pass Lua code to jedis Eval() method, and assign the parameter KEYS[1] to lockKey and ARGV[1] to requestId. When executing, first obtain the value value corresponding to the lock, check whether it is equal to requestId, and if it is equal, unlock (delete the key).
Existing risks
If the node of the key corresponding to the storage lock hangs, there may be a risk of losing the lock, resulting in multiple clients holding the lock, so the exclusive sharing of resources cannot be realized.
- Client A obtains the lock from the master
- Before the master synchronizes the lock to the slave, the Master goes down (the master-slave synchronization of Redis is usually asynchronous). During master-slave switching, the slave node is promoted to the master node
- Client B obtains another lock of the same resource that client A has obtained. This causes more than one thread to acquire locks at the same time.
redlock algorithm appears
This scenario assumes that there is a redis cluster and five redis master instances. Then perform the following steps to obtain a lock:
- Get the current timestamp, in milliseconds;
- Similar to the above, try to create locks on each master node in turn. The expiration time is short, usually tens of milliseconds;
- Try to establish a lock on most nodes. For example, five nodes require three nodes n / 2 + 1;
- The client calculates the time to establish the lock. If the time to establish the lock is less than the timeout, the establishment is successful;
- If the lock creation fails, delete the previously created locks in turn;
- As long as someone else establishes a distributed lock, you have to constantly poll to try to obtain the lock.
Redisson implementation
Redisson is a Java in memory data grid implemented on the basis of Redis. It not only provides a series of Distributed Common Java objects, but also implements Reentrant Lock, Fair Lock, MultiLock, RedLock, ReadWriteLock, etc. it also provides many distributed services.
Redisson provides the simplest and most convenient way to use Redis. Redisson aims to promote users' Separation of Concern on Redis, so that users can focus more on processing business logic.
Redisson distributed reentry lock usage
Redisson supports single point mode, master-slave mode, sentinel mode and cluster mode. Here, take single point mode as an example:
// 1. Construct redisson to realize the necessary Config of distributed lock
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:5379").setPassword("123456").setDatabase(0);
// 2. Construct RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 3. Obtain the lock object instance (it cannot be guaranteed to be obtained in the order of threads)
RLock rLock = redissonClient.getLock(lockKey);
try {
/**
* 4.Attempt to acquire lock
* waitTimeout The maximum waiting time for trying to acquire a lock. If it exceeds this value, it is considered that acquiring a lock has failed
* leaseTime The holding time of the lock. After this time, the lock will automatically expire (the value should be set to be greater than the business processing time to ensure that the business can be processed within the lock validity period)
*/
boolean res = rLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);
if (res) {
//Successfully obtain the lock and process the business here
}
} catch (Exception e) {
throw new RuntimeException("aquire lock fail");
}finally{
//In any case, unlock it in the end
rLock.unlock();
}Locking flow chart
Unlocking flow chart
We can see that RedissonLock is reentrant, and the failure retry is considered. The maximum waiting time of the lock can be set. Some optimizations have been made in the implementation to reduce invalid lock applications and improve the utilization of resources.
It should be noted that RedissonLock also does not solve the problem of the risk of losing locks when a node hangs up. The reality is that some scenarios cannot be tolerated, so Redisson provides redisonredlock that implements the redislock algorithm. Redisonredlock really solves the problem of single point failure at the cost of building an additional Redis environment for redisonredlock.
Therefore, if the business scenario can tolerate such small probability errors, RedissonLock is recommended. If it cannot be tolerated, RedissonRedLock is recommended.
6. How many ways to write single case mode?
"Do you know how to write the word 'fennel' in fennel beans?"
Are there several ways to write tangled singleton mode useful? It's a little useful. One or several writing methods are often selected as the beginning of the interview. While examining the design pattern and coding style, it's easy to expand to other questions.
Here I will explain several common ways of writing, but do not copy mechanically and remember "the way of writing fennel beans". The greatest fun of programming is "know everything, control everything".
JDK version: Oracle Java 1.8.0_ one hundred and two
It can be divided into four categories. Their basic forms, varieties and characteristics are introduced below.
Full Han model
Full Han is the single case mode with the most varieties. Starting from the full Han Dynasty, we gradually understand the problems we need to pay attention to when implementing the singleton mode through its variants.
Basic satiated man
A full man is one who is already full. He can eat when he is not in a hurry and when he is hungry. Therefore, it does not initialize the singleton first, and then initialize it when it is used for the first time, that is, "lazy loading".
// Full Han
// UnThreadSafe
public class Singleton1 {
private static Singleton1 singleton = null;
private Singleton1() {
}
public static Singleton1 getInstance() {
if (singleton == null) {
singleton = new Singleton1();
}
return singleton;
}
}The core of the full man mode is lazy loading. The benefits of single instance initialization are faster and faster until the first instance is accessed; The minor disadvantage is that it is troublesome to write, the major disadvantage is that the thread is unsafe, and there are race conditions in the if statement.
It's not a big problem to write. It's readable. Therefore, in the single thread environment, basic Chinese is the author's favorite writing method. But in a multithreaded environment, the foundation is completely unavailable. The following variants are trying to solve the problem of unsafe basic threads.
Full Han - variant 1
The crudest offense is to use the synchronized keyword to modify the getInstance() method, which can achieve absolute thread safety.
// Full Han
// ThreadSafe
public class Singleton1_1 {
private static Singleton1_1 singleton = null;
private Singleton1_1() {
}
public synchronized static Singleton1_1 getInstance() {
if (singleton == null) {
singleton = new Singleton1_1();
}
return singleton;
}
}The advantage of variant 1 is that it is simple to write and absolutely thread safe; The disadvantage is that the concurrency performance is extremely poor. In fact, it completely degenerates to serial. Even if a single instance of getsynchronize () is initialized, it will only need to be initialized once, so that it will not be able to be initialized completely. Performance insensitive scenarios are recommended.
Full Han - variant 2
Variant 2 is the "notorious" DCL 1.0.
In view of the problem that the lock cannot be avoided after single instance initialization in variant 1, variant 2 sets another layer of check on the outer layer of variant 1, plus the check on the synchronized inner layer, that is, the so-called "Double Check Lock" (DCL for short).
// Full Han
// UnThreadSafe
public class Singleton1_2 {
private static Singleton1_2 singleton = null;
public int f1 = 1; // Trigger partial initialization problem
public int f2 = 2;
private Singleton1_2() {
}
public static Singleton1_2 getInstance() {
// may get half object
if (singleton == null) {
synchronized (Singleton1_2.class) {
if (singleton == null) {
singleton = new Singleton1_2();
}
}
}
return singleton;
}
}The core of variant 2 is DCL. It seems that variant 2 has achieved the ideal effect: lazy loading + thread safety. Unfortunately, as stated in the comment, DCL is still thread unsafe. Due to instruction reordering, you may get "half an object", that is, the problem of "partial initialization".
Full Han - Variant 3
Variant 3 is specific to variant 2, which can be described as DCL 2.0.
Three variants of "volatile" are added to the reference of "volatile" principle.
// Full Han
// ThreadSafe
public class Singleton1_3 {
private static volatile Singleton1_3 singleton = null;
public int f1 = 1; // Trigger partial initialization problem
public int f2 = 2;
private Singleton1_3() {
}
public static Singleton1_3 getInstance() {
if (singleton == null) {
synchronized (Singleton1_3.class) {
// must be a complete instance
if (singleton == null) {
singleton = new Singleton1_3();
}
}
}
return singleton;
}
}In multi-threaded environment, Variant 3 is more suitable for performance sensitive scenarios. But we will learn later that even if it is thread safe, there are still some ways to destroy single cases.
Of course, there are many ways to prevent partial initialization in a way similar to volatile. Readers can read the relevant contents of the memory barrier by themselves, but it is not recommended to actively install B during the interview.
Hungry man model
Compared with the full man, the hungry man is very hungry and only wants to eat as soon as possible. So he initializes the singleton at the earliest opportunity, that is, when the class is loaded, and then returns directly when accessing later.
// hungry man
// ThreadSafe
public class Singleton2 {
private static final Singleton2 singleton = new Singleton2();
private Singleton2() {
}
public static Singleton2 getInstance() {
return singleton;
}
}The advantage of hungry man is inherent thread safety (thanks to the class loading mechanism), which is super simple to write and has no delay in use; The disadvantage is that it may cause a waste of resources (if the singleton is not used after the class is loaded).
It is worth noting that in a single threaded environment, there is no difference in performance between a hungry man and a full man; However, in the multithreaded environment, because the full man needs to lock, the hungry man's performance is better.
Holder mode
We hope to make use of the convenience of static variables and thread safety in hungry man mode; And hope to avoid resource waste through lazy loading. Holder mode meets these two requirements: the core is still static variables, which is convenient and thread safe enough; Lazy loading is indirectly realized by holding the real instance through the static holder class.
// Holder mode
// ThreadSafe
public class Singleton3 {
private static class SingletonHolder {
private static final Singleton3 singleton = new Singleton3();
private SingletonHolder() {
}
}
private Singleton3() {
}
/**
* Corrigendum: more synchronized..
public synchronized static Singleton3 getInstance() {
return SingletonHolder.singleton;
}
*/
public static Singleton3 getInstance() {
return SingletonHolder.singleton;
}
}Compared with the hungry man mode, the Holder mode only increases the cost of a static internal class, which is equivalent to the effect of the full man Variant 3 (slightly better), and is a more popular implementation method. It is also recommended to consider.
Enumeration mode
Using enumeration to implement singleton mode is quite easy to use, but readability does not exist.
Basic enumeration
Take enumerated static member variables as instances of singletons:
// enumeration
// ThreadSafe
public enum Singleton4 {
SINGLETON;
}Less code than hungry man mode. However, users can only directly access the instance singleton4 Singleton -- in fact, this access method is also appropriate as a singleton, but at the expense of the advantages of the static factory method, such as lazy loading.
Ugly but useful grammar candy
Java enumeration is an "ugly but easy-to-use syntax sugar".
The essence of enumerated singleton pattern
By decompiling and opening the syntax sugar, you can see the essence of enumeration types, which is simplified as follows:
// enumeration
// ThreadSafe
public class Singleton4 extends Enum<Singleton4> {
...
public static final Singleton4 SINGLETON = new Singleton4();
...
}It is essentially the same as the hungry man mode, except that the public static member variables.
Implement some trick s with enumeration
This part has nothing to do with single cases and can be skipped. If you choose to read, please recognize the fact that although enumeration is quite flexible, it is difficult to use enumeration properly. A typical example that is simple enough is the TimeUnit class. It is recommended to have time to read patiently.
As we have seen above, the essence of enumeration singleton is still an ordinary class. In fact, we can add the functions that any ordinary class can accomplish to the enumerated singleton. The key point is the initialization of enumeration instances, which can be understood as instantiating an anonymous inner class. To be more obvious, we're in singleton 4_ 1 defines an ordinary private member variable, an ordinary public member method, and a public abstract member method, as follows:
// enumeration
// ThreadSafe
public enum Singleton4_1 {
SINGLETON("enum is the easiest singleton pattern, but not the most readable") {
public void testAbsMethod() {
print();
System.out.println("enum is ugly, but so flexible to make lots of trick");
}
};
private String comment = null;
Singleton4_1(String comment) {
this.comment = comment;
}
public void print() {
System.out.println("comment=" + comment);
}
abstract public void testAbsMethod();
public static Singleton4_1 getInstance() {
return SINGLETON;
}
}In this way, the enumeration class singleton4_ Each enumeration instance in 1 not only inherits the parent class singleton4_ The member method print() of 1 must also implement the parent class Singleton4_1's abstract member method testAbsMethod().
summary
The above analysis ignores the problems of reflection and serialization. Through reflection or serialization, we can still access the private constructor, create new instances and break the singleton pattern. At this time, only enumeration mode can naturally prevent this problem. Reflection and serialization are not well understood by the author, but the basic principle is not difficult and can be implemented manually in other modes.
Let's continue to ignore the problems of reflection and serialization and make a summary and aftertaste:
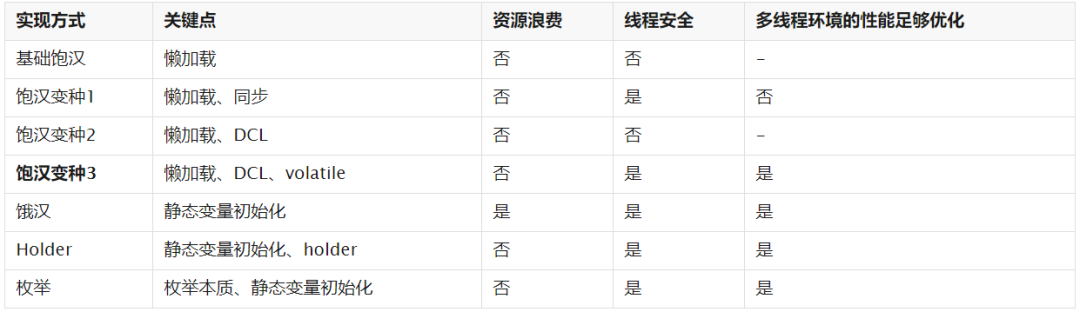
Single case mode is a common test point in the interview, which is very simple to write.
7. How to ensure the order of messages in message queue?
Q: how to ensure the order of messages?
Interviewer psychological analysis
In fact, this is also a topic that must be asked when using MQ. First, do you know the order? Second, see if you can ensure that the messages are in order? This is a common problem in the production system.
Analysis of interview questions
Let me give you an example. We used to build a mysql binlog synchronization system, which is still under great pressure. The daily synchronization data should reach hundreds of millions, that is, the data should be synchronized from one mysql database to another (mysql - > mysql). A common point is that, for example, a big data team needs to synchronize a mysql database to do various complex operations on the data of the company's business system.
If you add, delete and modify a piece of data in mysql, you will add, delete and modify three "binlog" logs. Then these three "binlog" logs will be sent to MQ, and then consumed and executed in turn. At least make sure that people come in order, right? Otherwise, it was: add, modify, delete; You have changed the order to delete, modify and add. Aren't they all wrong.
Originally, this data was synchronized, but it should be deleted at last; As a result, you make a mistake in this order. Finally, the data is retained, and the data synchronization is wrong.
Let's take a look at two scenes that are out of order:
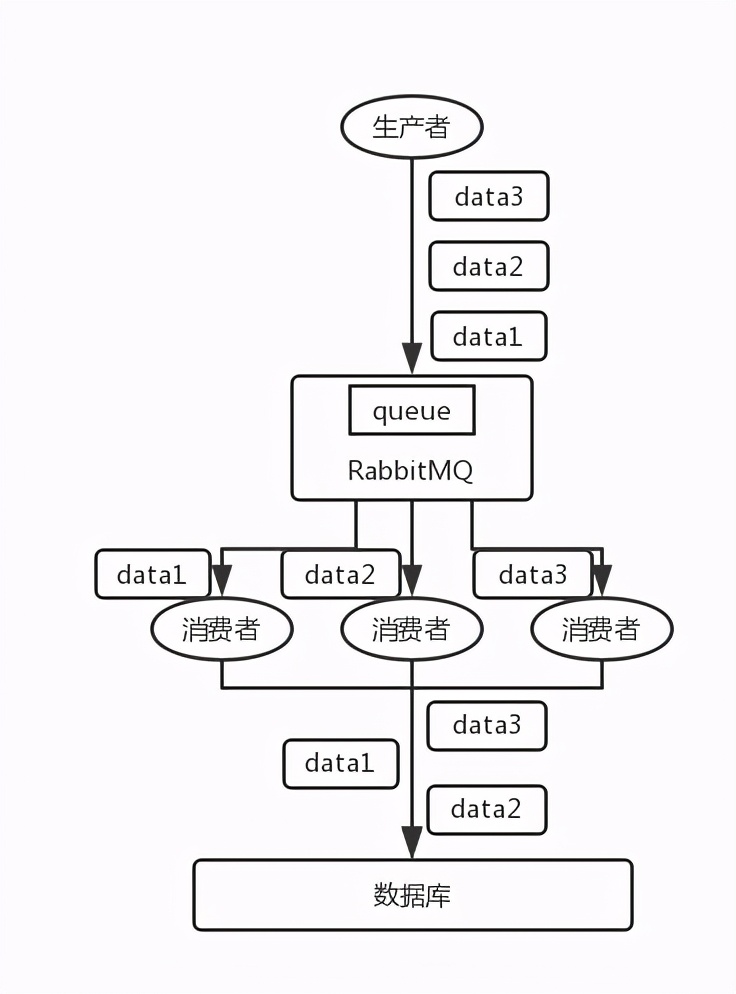
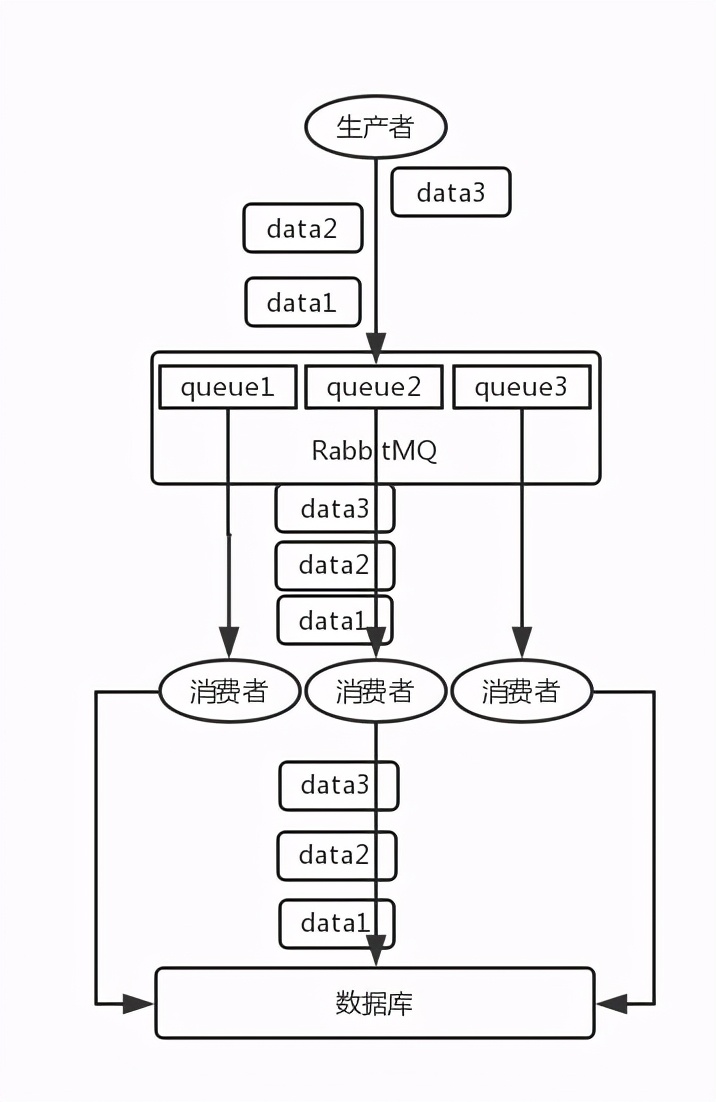
- RabbitMQ: one queue, multiple consumers. For example, the producer sent three pieces of data to RabbitMQ, in the order of data1/data2/data3, and pushed into a memory queue of RabbitMQ. Three consumers consume one of the three pieces of data from MQ. As a result, consumer 2 completes the operation first, stores data2 into the database, and then data1/data3. It's not obviously messy.
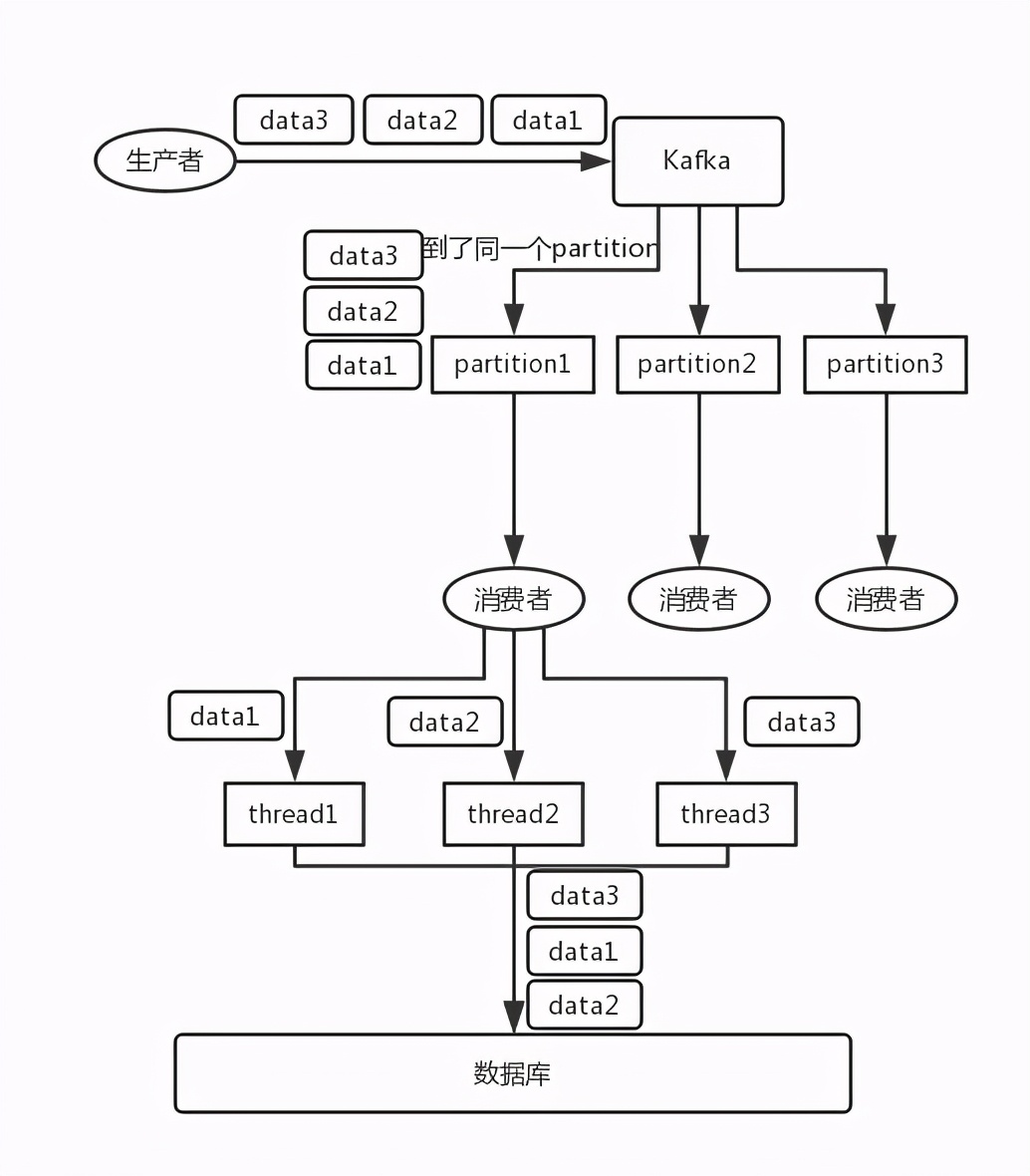
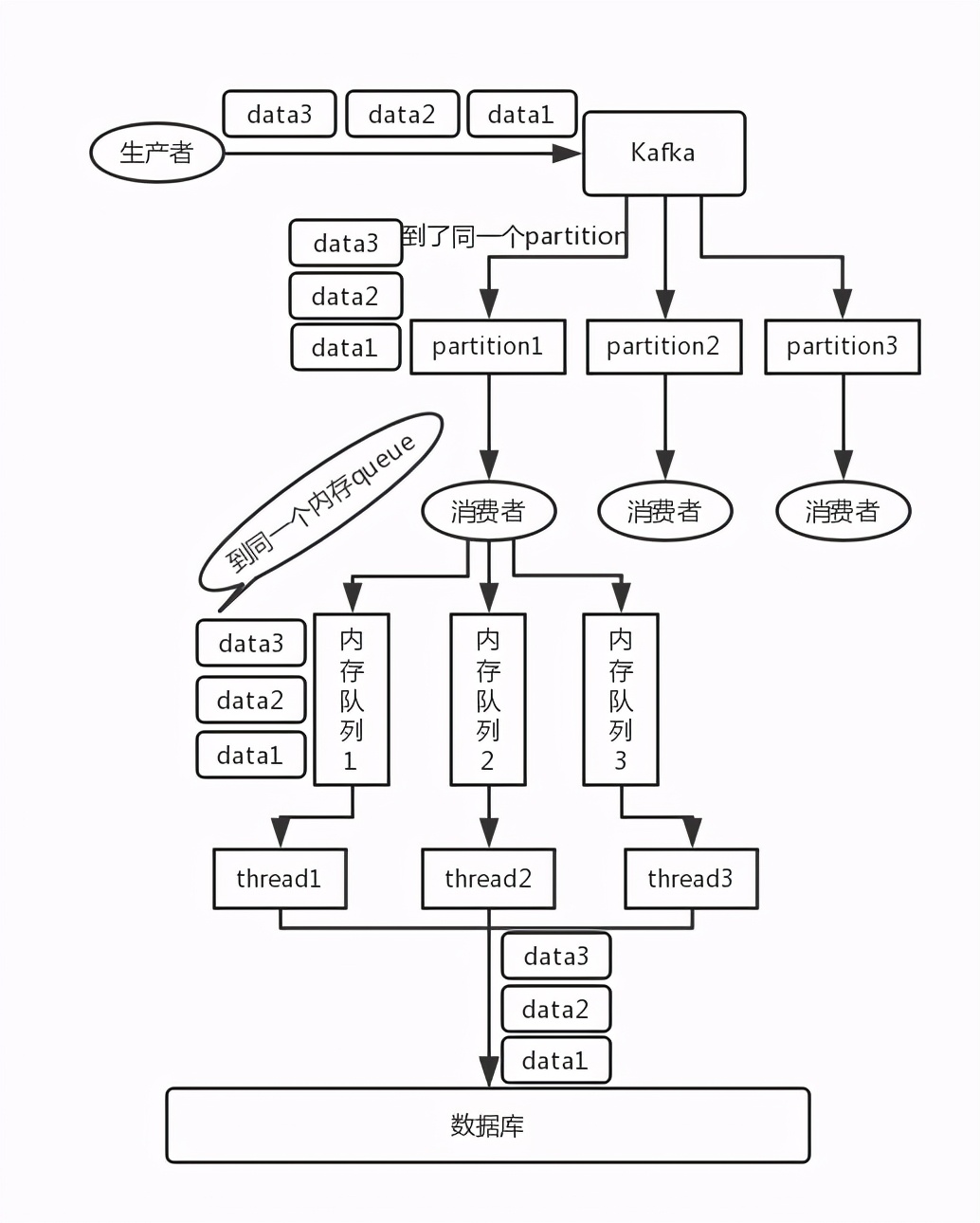
- Kafka: for example, we built a topic with three partitions. When writing, the producer can actually specify a key. For example, if we specify an order id as the key, the data related to the order will be distributed to the same partition, and the data in the partition must be in order. When consumers take out data from the partition, they must also be in order. Here, the order is ok and there is no confusion. Then, we may engage in multiple threads in the consumer to process messages concurrently. Because if the consumer is single threaded and the processing is time-consuming, for example, it takes tens of ms to process a message, then it can only process dozens of messages per second, which is too low throughput. If multiple threads run concurrently, the order may be out of order.
Solution
RabbitMQ
Splitting multiple queues, one consumer for each queue, is just more queues, which is really troublesome; Or a queue corresponds to a consumer, and then the consumer is queued internally with a memory queue, and then distributed to different worker s at the bottom for processing.
Kafka
- A topic, a partition, and a consumer are consumed by a single thread internally. The throughput of a single thread is too low. Generally, this is not used.
- Write N memory queues, and all data with the same key will be sent to the same memory queue; Then, for N threads, each thread can consume a memory queue respectively, so as to ensure sequencing.
8. Can you talk about the life cycle of Bean in Spring framework?
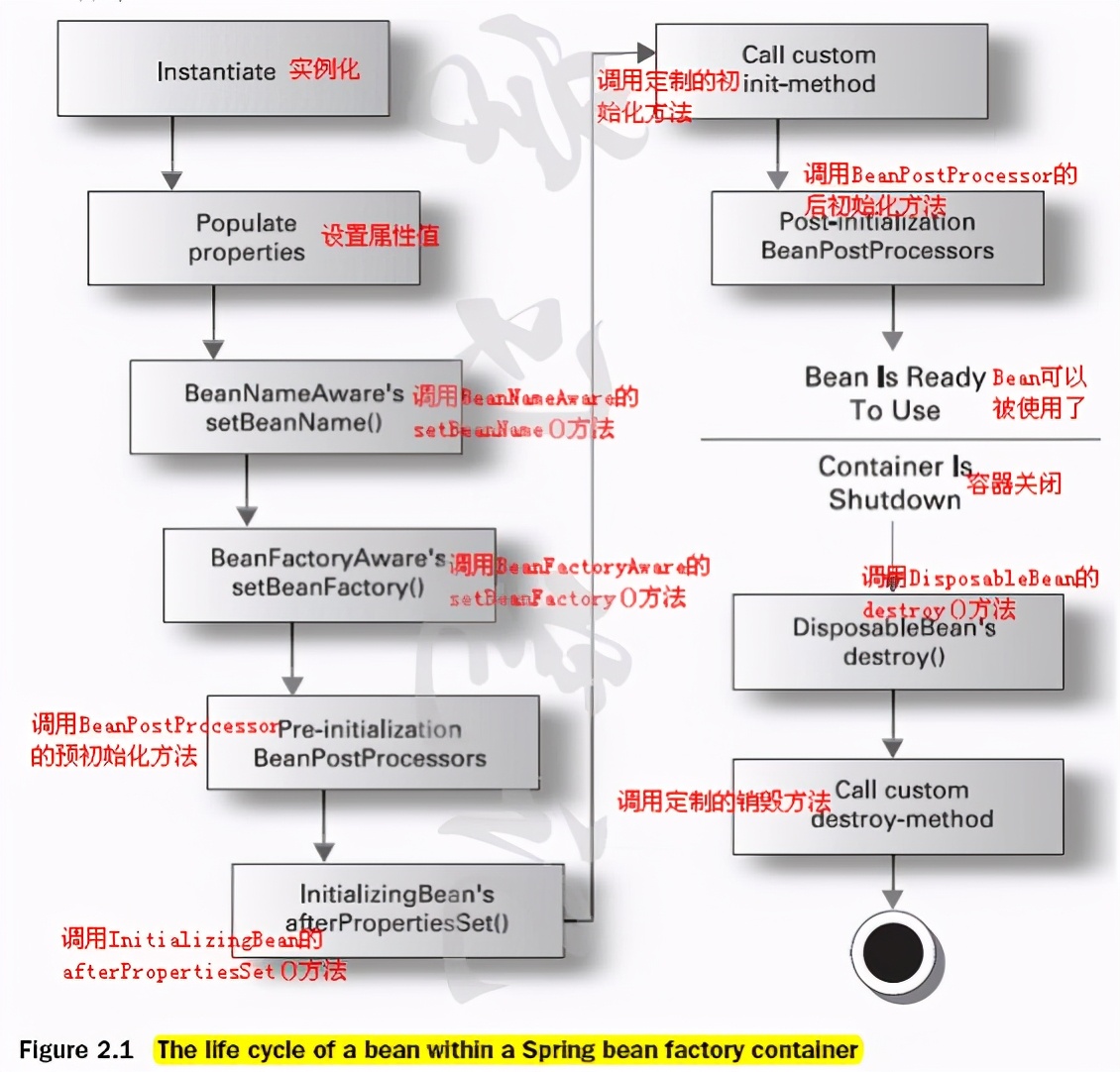
1. Instantiate a Bean -- that is, what we often call new;
2. Configure the instantiated Bean according to the Spring context - that is, IOC injection;
3. If the Bean has implemented the BeanNameAware interface, it will call the setBeanName(String) method it implements. What is passed here is the id value of the Bean in the Spring configuration file
4. If the Bean has implemented the BeanFactoryAware interface, it will call its implemented setBeanFactory(setBeanFactory(BeanFactory) to pass the Spring factory itself (you can use this method to obtain other beans, just configure an ordinary Bean in the Spring configuration file);
5. If the Bean has implemented the ApplicationContextAware interface, it will call the setApplicationContext(ApplicationContext) method to pass in the Spring context (this method can also implement the content of step 4, but it is better than 4, because ApplicationContext is a sub interface of BeanFactory and has more implementation methods);
6. If this Bean is associated with the BeanPostProcessor interface, it will call
postProcessBeforeInitialization(Object obj, String s) method. BeanPostProcessor is often used to change the Bean content. Because this method is called at the end of Bean initialization, it can also be applied to memory or cache technology;
7. If the Bean configures the init method attribute in the Spring configuration file, it will automatically call its configured initialization method.
8. If this Bean is associated with the BeanPostProcessor interface, it will call
postProcessAfterInitialization(Object obj, String s) method;
Note: after the above work is completed, this Bean can be applied. The Bean is a Singleton, so generally, we call a Bean with the same id in an instance with the same content address. Of course, non Singleton can also be configured in the Spring configuration file, which we will not repeat here.
9. When the Bean is no longer needed, it will go through the cleaning phase. If the Bean implements the DisposableBean interface, it will call the destroy() method of its implementation;
10. Finally, if the destroy method attribute is configured in the Spring configuration of this Bean, the configured destroy method will be called automatically.
Combined with the code to understand
1. Definition of Bean
Spring usually defines beans through configuration files. For example:
<?xml version="1.0″ encoding="UTF-8″?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd"> <bean id="HelloWorld" class="com.pqf.beans.HelloWorld"> <property name="msg"> <value>HelloWorld</value> </property> </bean> </beans>
This configuration file defines a Bean identified as HelloWorld. Multiple beans can be defined in one configuration document.
2. Initialization of Bean
There are two ways to initialize beans.
1. This is done in the configuration document by specifying the init method attribute
Implement a method to initialize the Bean attribute in the Bean class, such as init(), such as:
public class HelloWorld{
public String msg=null;
public Date date=null;
public void init() {
msg="HelloWorld";
date=new Date();
}
......
}Then, set the init mothod attribute in the configuration file:
2. Realize
org.springframwork.beans.factory.InitializingBean interface
Bean implements InitializingBean interface and adds afterpropertieset() method:
public class HelloWorld implement InitializingBean {
public String msg=null;
public Date date=null;
public void afterPropertiesSet() {
msg="Say hello to the world!";
date=new Date();
}
......
}Then, after all the properties of the Bean are set by Spring's BeanFactory, the afterpropertieset () method will be automatically called to initialize the Bean. Therefore, the configuration file does not need to specify the init method property.
3. Call of Bean
There are three ways to get a Bean and call it:
1. Using BeanWrapper
HelloWorld hw=new HelloWorld();
BeanWrapper bw=new BeanWrapperImpl(hw);
bw.setPropertyvalue("msg","HelloWorld");
system.out.println(bw.getPropertyCalue("msg"));2. Using BeanFactory
InputStream is=new FileInputStream("config.xml");
XmlBeanFactory factory=new XmlBeanFactory(is);
HelloWorld hw=(HelloWorld) factory.getBean("HelloWorld");
system.out.println(hw.getMsg());3. Using ApplicationContext
ApplicationContext actx=new FleSystemXmlApplicationContext("config.xml");
HelloWorld hw=(HelloWorld) actx.getBean("HelloWorld");
System.out.println(hw.getMsg());4. Destruction of Bean
1. Use the destroy method attribute in the configuration file
Similar to the initialization attribute init methods, implement a method to revoke the bean in the bean class, and then specify it in the configuration file through the destruction method. When the bean is destroyed, Spring will automatically call the specified destruction method.
2. Realize
org.springframwork.bean.factory.DisposebleBean interface
If the DisposebleBean interface is implemented, Spring will automatically call the destroy method in the bean to destroy it. Therefore, the destroy method must be provided in the bean.
graphic
9. What are the differences and connections between spring, spring MVC, spring boot and spring cloud?
Spring is a lightweight inversion of control (IoC) and aspect oriented (AOP) container framework. Spring enables you to write cleaner, more manageable, and easier to test code.
Spring MVC is a module of spring and a web framework. It is easy to develop web applications through Dispatcher Servlet, ModelAndView and View Resolver. It is mainly aimed at website application or service development - URL routing, Session, template engine, static web resources, etc.
Spring configuration is complex and cumbersome, so Spring boot is launched. The Convention is better than the configuration, which simplifies the spring configuration process.
Spring Cloud, built on Spring Boot, is a global service governance framework.
Spring VS SpringMVC:
Spring is a one-stop lightweight java development framework. Its core is control inversion (Ioc) and aspect oriented (AOP). It provides a variety of configuration solutions for the WEB layer (springMvc), business layer (Ioc), persistence layer (JDBC template) and so on;
Spring MVC is an MVC framework based on spring, which mainly deals with path mapping and view rendering of web development. It is a part of web layer development in spring framework;
SpringMVC VS SpringBoot:
Spring MVC belongs to an MVC framework for enterprise WEB development, covering front-end view development, file configuration, background interface logic development, etc. XML, config and other configurations are relatively cumbersome and complex;
Compared with spring MVC framework, SpringBoot framework focuses more on Developing Micro service background interface rather than front-end view;
SpringBoot and SpringCloud:
SpringBoot uses the concept that default is greater than configuration, integrates multiple Spring plug-ins developed rapidly, automatically filters redundant plug-ins that do not need to be configured, simplifies the development and configuration process of the project, cancels xml configuration to a certain extent, and is a set of scaffold for rapid configuration and development, which can quickly develop a single micro service;
Most of the functional plug-ins of SpringCloud are implemented based on SpringBoot. SpringCloud focuses on the integration and management of global microservices, integrating and managing multiple single microservices of SpringBoot; SpringCloud relies on SpringBoot development, which can be developed independently;
To sum up:
- Spring is the core and provides basic functions;
- Spring MVC is an MVC framework based on spring;
- Spring Boot is a rapid development integration package to simplify spring configuration;
- Spring Cloud is a service governance framework built on Spring Boot.
10. Distributed system interface, how to avoid repeated submission of forms?
How to realize the system carrying more users has always been a technical direction I focus on. Generally speaking, the transformation of the structure to improve the bearing capacity is divided into two general directions, which can be realized in cooperation with each other.
The hardware architecture improvement is mainly realized by using Alibaba cloud's multi-component cloud environment: through a combination of cloud products with different responsibilities, such as load balancing SLB, template cloned ECS, RDS, shared object storage OSS and so on.
Software architecture optimization mainly refers to the specification of software code development: business decoupling, architecture micro service, single machine statelessness, file storage and sharing, etc
On the way of learning distributed systems, we also continue to see new knowledge points. Today we want to talk about the implementation of "idempotency" of interface services in software development!
Idempotency
Effect: the system should return the same result for multiple requests for an interface! (except for the scenario of network access failure)
Purpose: to avoid repeated business processing caused by repeated requests for various reasons
Repeat request scenario:
1. After the first request from the client, the network exception causes the request execution logic to be received but not returned to the client. The client re initiates the request
2. The client quickly clicks the button to submit, resulting in the same logic being sent to the server many times
Simply divided, business logic can be summarized as addition, deletion, modification and query!
For the query, there are no other operations inside. The business that is read-only must meet the idempotency requirements.
For deletion, duplicate deletion requests will at least not cause data clutter. However, in some scenarios, the prompt of repeated clicks is that the deletion is successful, not that the target does not exist.
For addition and modification, here are the key parts to focus on today: for addition, it is necessary to avoid repeated insertion; Modify to avoid invalid repeated modification;
Implementation of idempotency
Implementation method: when the client makes a request, it carries the identification parameter identification, and the server identifies this identification. If the request is repeated, it can return the first result repeatedly.
For example, in the form of adding request, when the page of adding form is opened, an AddId ID is generated, which is submitted to the background interface together with the form.
According to this AddId, the server can mark and filter the cache. The cache Value can be AddId as the cache key and the returned content as the cache Value, so that it can be recognized even if the Add button is clicked many times.
When will this AddId be updated? Only after saving successfully and clearing the form can the AddId ID Id be changed to realize the form submission of new data