Demo prototype project that follows the compilation principle and main process to print 1 + 1 Results
Project introduction
Printing 1 + 1 results is so complicated that it is not a dazzling skill, but only for simple display: 1. Lexical analyzer; 2. Parser; 3. Script compiler; 4. There are four processes for compiling executors, because they are the basis for implementing a custom script engine. Based on this method, subsequent extension conditions (if/else), loops (for/while), other types (map, object, list,set...), and other syntax features (import, anonymous functions) are more convenient and controllable. After a set of scripts supports common data types and syntax, it is worthy of the name to call it a custom script engine. It should also be noted that the project also embodies a part of the idea of all in one low code platform (for other ideas about all in one low code platform, please refer to my previous articles).
Code git: https://github.com/bossfriday/expression-engine-protype
Process introduction
1. Lexical analyzer (developed)
1. Scan the source code text, scan the text from left to right, and break the text into some words.
2. Analyze what the disassembled words are: keywords, identifiers, symbols, notes... And the result product is Token.
The above words are not easy to understand. Take chestnuts for example:
var a = 1 + 1; // Comment var : keyword a : identifier = : Symbol 1 : number // Comment: comment
Test code:
public static void main(String[] args) throws Exception {
String strScript = "var a = 1 + 1; // Comment";
ScriptTokenRegister tokenRegister = new ScriptTokenRegister();
List<Token> tokens = tokenRegister.getTokens(strScript);
tokens.forEach(token->{
System.out.println(token.toString());
});
}
The word segmentation results are as follows (Note: because it is meaningless for script execution, it is directly discarded):
Token{value='var', lineNo=0, offset=0, type='Keyword'}
Token{value='a', lineNo=0, offset=4, type='Identifier'}
Token{value='=', lineNo=0, offset=6, type='SingleSymbol'}
Token{value='1', lineNo=0, offset=8, type='Integer'}
Token{value='+', lineNo=0, offset=10, type='SingleSymbol'}
Token{value='1', lineNo=0, offset=12, type='Integer'}
Token{value=';', lineNo=0, offset=13, type='SingleSymbol'}
2. Parser (development completed)
1. The token sequence will recognize various phrases in the text through the syntax parser.
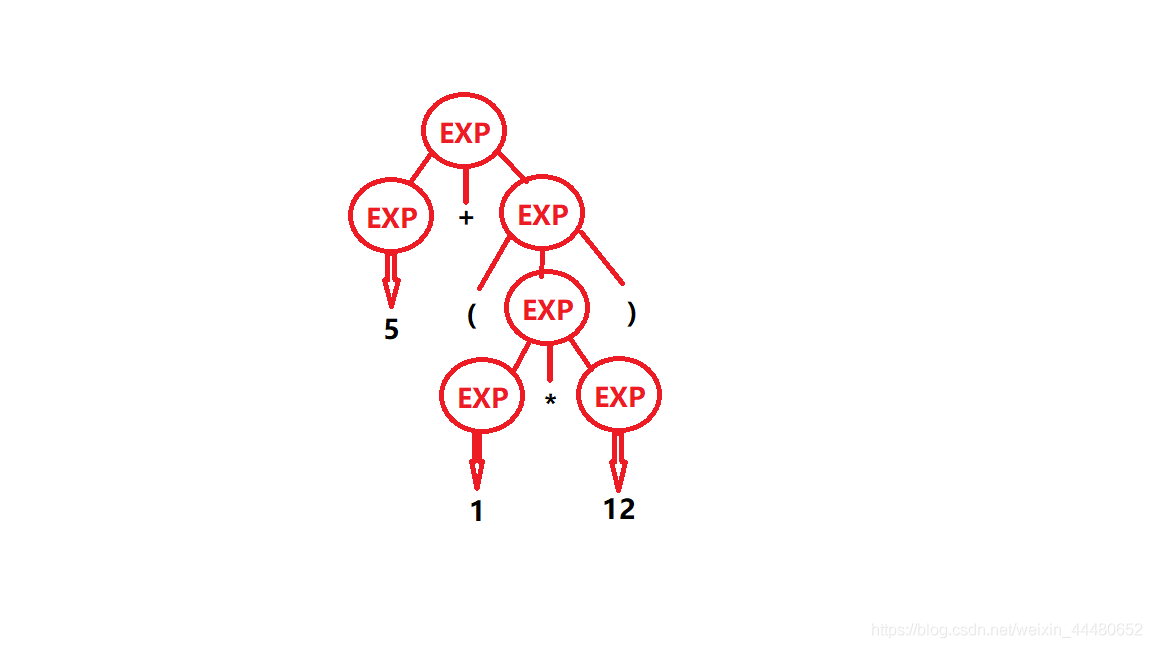
2. The parsing tree is output according to the rules of grammar of the language. This tree (AST: abstract syntax tree) is a tree description of the code. Grammar is to solve the problem of finite expression of infinite language with simple symbols. Take chestnuts for example: 5 + (12 * 1) the parsing tree generated according to the corresponding grammar is:
- Syntax rules are expressed by configuration files. The advantage of this is that when implementing script multilingualism, you only need to define a new grammar configuration file and write the corresponding statementHandler. At present, our script syntax is highly suitable for JavaScript. If we want to implement the syntax of other languages in the future, it will be relatively convenient (for example,. Net supports C#, VB.Net and JS. Net, but the intermediate language generated after compilation is the same).
- The grammar rule configuration file (the above grammar rule: rules of grammar) itself is parsed by the parser itself. The grammar rule configuration file is as follows. The format is one data per line, and the format of each line is: [rule name]: rule expression. In regular expressions*+ The meaning of equal sign is the same as that of regular expression (? Zero or once; * zero or more; + one or more)
root : statementList? ;
statementList : statement+ ;
statement : variableStatement
| expressionStatement
;
variableStatement : variableDeclarationList ';' ;
variableDeclarationList : 'var' variableDeclaration (',' variableDeclaration)*;
variableDeclaration : Identifier ('=' singleExpression)? ;
expressionStatement : expressionSequence ';' ;
expressionSequence : singleExpression (',' singleExpression)* ;
arguments : '('(argument (',' argument)* ','?)?')' ;
argument : singleExpression | Identifier ;
singleExpression
: singleExpression arguments # ArgumentsExpression
| singleExpression ('+' | '-') singleExpression # AdditiveExpression
| singleExpression '=' singleExpression # AssignmentExpression
| singleExpression assignmentOperator singleExpression # AssignmentOperatorExpression
| Identifier # IdentifierExpression
| literal # LiteralExpression
;
assignmentOperator : '*=' | '/=' | '%=' | '+=' | '-=' | '&=' | '^=' | '|=';
literal : Null | Boolean | String | MultiLineString | numericLiteral ;
numericLiteral : Float | Integer;
3. Compiler
1. Generate quaternion according to AST.
2. Serialization quaternion (with certain compression optimization, it is obviously easy to optimize if there are long identifiers all over the street). Since the encoding and decoding of tuples is not the core content of the description, it is not fully implemented in the demo at present (it is not easy to share something by using business time).
About quaternion, take chestnuts for example (of course, now we basically do it with return and ternary):
5 + 6 -> Quaternion: 5 : p1 6 : p2 + : operator 11 : result
4. Actuator
1. Simply put, it is to execute quaternion arrays in order, and of course jump. There are basically two situations at the execution level: sequential execution and jumping to another position after execution to a certain position. We can think about the conversion of a for loop to do while and the execution of if/else. Basically, many grammars are "grammar sugar" wrapped on the basis of basic grammar.
2. Since the script engine is implemented based on JAVA, the execution efficiency of the runtime can only be close to that of the JVM. In principle, the difference of about one order of magnitude can be achieved. Try to avoid string Equal and other things, as well as its own logic, try to avoid unnecessary performance loss. Here is just a prototype Demo, which is originally used in the actuator: operator Equals ("xxx") is obviously inappropriate.
Test code and results
Test code:
public class ExpressionEngine {
private ASTPattern astPattern;
private ScriptTokenRegister tokenRegister;
public ExpressionEngine() throws Exception {
tokenRegister = new ScriptTokenRegister();
astPattern = ASTPattern.compileWithFile("AstParser.conf");
}
/**
* apply
*/
public void apply(String script) throws Exception {
List<Token> tokens = tokenRegister.getTokens(script); // 1. Lexical analysis
System.out.println("---------Tokens-----------");
tokens.forEach(token -> {
System.out.println(token.toFullString());
});
System.out.println("---------AST Result-----------"); // 2. Syntax analysis
ASTMatcher astResult = astPattern.match(tokens);
System.out.println(astResult.toString());
System.out.println("---------Tuples-----------");
MethodStack methodStack = AbstractStatementHandle.parseMethodStack(astResult); // 3. Generate quaternion according to AST
Arrays.asList(methodStack.getTuples()).forEach(tuple -> {
System.out.println(tuple.toString());
});
System.out.println("---------apply-----------");
TupleExecutor executor = new TupleExecutor(methodStack);
executor.apply(null); // 4. Quaternion actuator
}
public static void main(String[] args) throws Exception {
String script = "var a = 1 + 1; printl(a);";
ExpressionEngine expEngine = new ExpressionEngine();
expEngine.apply(script);
}
}
Execution result:
---------Tokens-----------
Token{value='var', lineNo=0, offset=0, type='Keyword'}
Token{value='a', lineNo=0, offset=4, type='Identifier'}
Token{value='=', lineNo=0, offset=6, type='SingleSymbol'}
Token{value='1', lineNo=0, offset=8, type='Integer'}
Token{value='+', lineNo=0, offset=10, type='SingleSymbol'}
Token{value='1', lineNo=0, offset=12, type='Integer'}
Token{value=';', lineNo=0, offset=13, type='SingleSymbol'}
Token{value='printl', lineNo=0, offset=15, type='Identifier'}
Token{value='(', lineNo=0, offset=21, type='SingleSymbol'}
Token{value='a', lineNo=0, offset=22, type='Identifier'}
Token{value=')', lineNo=0, offset=23, type='SingleSymbol'}
Token{value=';', lineNo=0, offset=24, type='SingleSymbol'}
---------AST Result-----------
'root':['statementList':['statement':['variableStatement':['variableDeclarationList':[var, 'variableDeclaration':[a, =, 'singleExpression#AdditiveExpression':
['singleExpression#LiteralExpression':['literal':['numericLiteral':[1]]], +, 'singleExpression#LiteralExpression':['literal':['numericLiteral':[1]]]]]], ;]], 'statement':
['expressionStatement':['expressionSequence':['singleExpression#ArgumentsExpression':['singleExpression#IdentifierExpression':[printl], 'arguments':[(, 'argument':
['singleExpression#IdentifierExpression':[a]], )]]], ;]]]]
---------Tuples-----------
QuaternionTuple{p1=1, p2=1, op=+, result=#0, end=false, lineNo=0}
QuaternionTuple{p1=a, p2=#0, op=:=, result=a, end=true, lineNo=0}
FunctionTuple{name='printl', arguments=[a], result=#1}
---------apply-----------
2