2.8.1 introduction
set/multiset container concept
-
Set and multiset are a collection container, in which the elements contained in set are unique, and the elements in the collection are automatically arranged in a certain order. Set is implemented using the data structure of red black tree variant, which belongs to balanced binary tree. It is faster than vector in insert and delete operations. The efficiency of finding the target number in N numbers is log 2 n.
-
Duplicate elements are not allowed in the set container, and duplicate elements are allowed in multiset.
-
Only Insert method initialization is provided, as shown in the following figure.
set common API s see set common APIs_ qq_ 41050821 blog - CSDN blog
2.8.2 code example
#include<iostream>
#include<set>
using namespace std;
//functor
class mycompare
{
public:
bool operator()(int v1,int v2)const
{
return v1 > v2;
}
//const should be added here. The original video vs2019 will report an error. See for details https://www.cnblogs.com/qrlozte/p/4437418.html
};
//initialization
void text01()
{
set<int> s1;//Sort automatically, from small to large by default.
s1.insert(7);
s1.insert(2);
s1.insert(4);
s1.insert(5);
s1.insert(1);
s1.insert(9);
for (set<int>::iterator it = s1.begin(); it != s1.end(); it++)
{
cout << *it << " ";
}
cout << endl;
//Assignment operation
set<int> s2;
s2 = s1;
//Delete operation
s1.erase(s1.begin());
s1.erase(7);
for (set<int>::iterator it = s1.begin(); it != s1.end(); it++)
{
cout << *it << " ";
}
cout << endl;
//How to change the default sort from large to small// First order traversal, middle order traversal, and second order traversal.
//With the help of imitation function
mycompare com;
com(20, 30);
set<int, mycompare> s3;//Sort automatically, from small to large by default.
s3.insert(7);
s3.insert(2);
s3.insert(4);
s3.insert(5);
s3.insert(1);
s3.insert(9);
for (set<int/*,mycompare*/>::iterator it2 = s3.begin(); it2 != s3.end(); it2++)
{
cout << *it2 << " ";
}
cout << endl;
}
//lookup
void text02()
{
//Real value
set<int> s1;
s1.insert(7);
s1.insert(2);
s1.insert(4);
s1.insert(5);
s1.insert(1);
s1.insert(9);
set<int>::iterator ret = s1.find(4);//There is no value to return end()
if (ret == s1.end())
{
cout << "Can't find" << endl;
}
else
{
cout << "ret:" << *ret << endl;
}
//lower_bound(2) find the first (element) iterator value greater than or equal to k
ret = s1.lower_bound(2);
if (ret == s1.end())
{
cout << "Can't find" << endl;
}
else
{
cout << "ret:" << *ret << endl;
}
//Find the first value greater than K
ret = s1.upper_bound(2);
if (ret == s1.end())
{
cout << "Can't find" << endl;
}
else
{
cout << "ret:" << *ret << endl;
}
//equal_range returns Lower_bound and upper_bound value
pair<set<int>::iterator, set<int>::iterator> myret = s1.equal_range(2);
//pair is used here. Let's add the relevant contents of the group below.
/*myret.first;
myret.second;*/
if (myret.first == s1.end())
{
cout << "can't find" << endl;
}
else
{
cout << "myret:" << *myret.first << endl;//Return to Lower_bound
}
if (myret.second == s1.end())
{
cout << "can't find" << endl;
}
else
{
cout << "myret:" << *myret.second << endl; //Return to upper_bound
}
}
class Person
{
public:
Person(int age, int id):id(id),age(age){}
public:
int id;
int age;
};
class mycompare2
{
public:
bool operator()(Person p1, Person p2)const
{
return p1.age > p2.age;
}
};
void text03()
{
set<Person,mycompare2> sp;
Person p1(10, 20), p2(30, 40), p3(50, 60);
sp.insert(p1);
sp.insert(p2);
sp.insert(p3);
Person p4(10, 20);
for (set<Person, mycompare2>::iterator it = sp.begin(); it != sp.end(); it++)
{
cout << (*it).age << " " << (*it).id << endl;
}
//lookup
sp.find(p1);
sp.find(p4);
auto ret = sp.find(p4);//set<Person,mycompare2>::iterator
if (ret == sp.end())
{
cout << "can't find" << endl;
}
else
{
cout << "find:" << (*ret).id << " " << (*ret).age << endl;
}
}
int main()
{
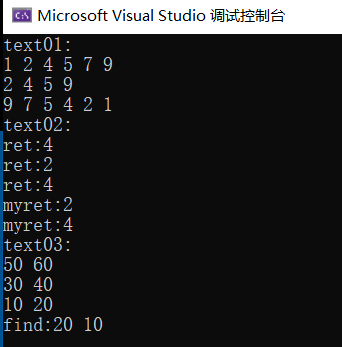
cout <<"text01:"<< endl;
text01();
cout << "text02:" << endl;
text02();
cout << "text03:" << endl;
text03();
return 0;
}
2.8.3 code running results
2.8.4 supplement to pair group
Code example
//Supplement relevant contents of the group
#include<iostream>
#include<string>
using namespace std;
void text01()
{
//Create pair group
//FA Yi
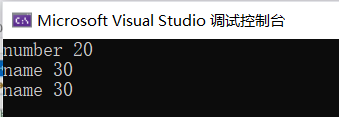
pair<string, int> pair1(string("number"), 20);
cout << pair1.first << " " << pair1.second << endl;
//Or pair < string, int > pair2 = make_ pair("name",30)
pair<string, int> pair2 = make_pair("name", 30);
cout << pair2.first << " " << pair2.second << endl;
//pair assignment
pair<string, int> pair3 = pair2;
cout << pair2.first << " " << pair2.second << endl;
}
int main()
{
text01();
return 0;
}
Operation results
summary
When brushing the buckle, we found that unordered in c++11_ Set is also very commonly used. We can find the following conclusions by comparing it.
- set and unordered in c++ std_ set is different from map and unordered_ The differences between maps are similar. The underlying data structure is described as follows:
1. set is implemented based on the red black tree. The red black tree has the function of automatic sorting, so all the data in the map is orderly at any time.
2,unordered_set is based on hash table. The time complexity of data insertion and lookup is very low, almost constant time, at the cost of consuming more memory and no automatic sorting function. In the bottom implementation, an array with a large subscript range is used to store elements to form many buckets, and the hash function is used to map the key to different areas for storage.
For details, see [difference between c++ set and unordered set - armanididi blog Park (cnblogs. Com)]( https://www.cnblogs.com/codingmengmeng/p/13992692.html#: ~: text = set compared with unordered: 1. Set uses less memory to store the same number of elements than unordered_set. 2. For a small number of elements, searching in set may be faster than searching in unordered_set.)
Thank you for reading (″ '' ▽ ''). If there are any mistakes, you are welcome to point them out. If you think they are good, you can praise them.