Hello, I'm Chen Cheng~
Today, I'd like to share the index settings of 8 common pandas
1. Convert index from group by operation to column
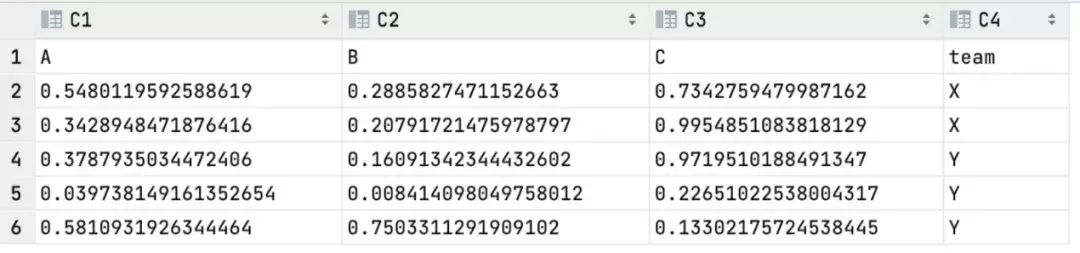
The group by grouping method is often used. For example, add a grouping column team to group.
>>> df0["team"] = ["X", "X", "Y", "Y", "Y"]
>>> df0
A B C team
0 0.548012 0.288583 0.734276 X
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
3 0.039738 0.008414 0.226510 Y
4 0.581093 0.750331 0.133022 Y
>>> df0.groupby("team").mean()
A B C
team
X 0.445453 0.248250 0.864881
Y 0.333208 0.306553 0.443828By default, grouping programmatically indexes grouped columns. However, in many cases, we do not want the grouped column to become an index, because some calculation or judgment logic may still need to use this column. Therefore, we need to set the grouping column not to become an index, but also to complete the grouping function.
There are two ways to complete the required operations. The first is to use reset_index. The second is to set as in the group by method_ index=False. I prefer the second method, which involves only two steps and is more concise.
>>> df0.groupby("team").mean().reset_index()
team A B C
0 X 0.445453 0.248250 0.864881
1 Y 0.333208 0.306553 0.443828
>>> df0.groupby("team", as_index=False).mean()
team A B C
0 X 0.445453 0.248250 0.864881
1 Y 0.333208 0.306553 0.4438282. Use the existing DataFrame to set the index
Of course, if we have read data or finished some data processing steps, we can use set_index set the index manually.
>>> df = pd.read_csv("data.csv", parse_dates=["date"])
>>> df.set_index("date")
temperature humidity
date
2021-07-01 95 50
2021-07-02 94 55
2021-07-03 94 56Here are two points to note.
- set_ The index method will create a new DataFrame by default. If you want to change the index of df in place, you need to set inplace=True.
df.set_index("date", inplace=True)- If you want to keep the columns that will be set as indexes, you can set drop=False.
df.set_index("date", drop=False)3. Reset the index after some operations
When processing DataFrame, some operations (such as deleting rows, index selection, etc.) will generate a subset of the original index, so the default sorting of digital indexes will be disordered. To regenerate continuous indexes, you can use the reset_index method.
>>> df0 = pd.DataFrame(np.random.rand(5, 3), columns=list("ABC"))
>>> df0
A B C
0 0.548012 0.288583 0.734276
1 0.342895 0.207917 0.995485
2 0.378794 0.160913 0.971951
3 0.039738 0.008414 0.226510
4 0.581093 0.750331 0.133022
>>> df1 = df0[df0.index % 2 == 0]
>>> df1
A B C
0 0.548012 0.288583 0.734276
2 0.378794 0.160913 0.971951
4 0.581093 0.750331 0.133022
>>> df1.reset_index(drop=True)
A B C
0 0.548012 0.288583 0.734276
1 0.378794 0.160913 0.971951
2 0.581093 0.750331 0.133022Generally, we do not need to keep the old index, so we can set the drop parameter to True. Similarly, if you want to reset the index in place, you can set the inplace parameter to True, otherwise a new DataFrame will be created.
4. Reset index after sorting
When using sort_value sorting method will also encounter this problem, because by default, the index changes with the sorting order, so it is messy. If we want the index not to change with the sort, we also need to use sort_ Set the parameter ignore in the values method_ Index.
>>> df0.sort_values("A")
A B C team
3 0.039738 0.008414 0.226510 Y
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
0 0.548012 0.288583 0.734276 X
4 0.581093 0.750331 0.133022 Y
>>> df0.sort_values("A", ignore_index=True)
A B C team
0 0.039738 0.008414 0.226510 Y
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
3 0.548012 0.288583 0.734276 X
4 0.581093 0.750331 0.133022 Y5. Reset the index after deleting duplicates
Deleting duplicate items is the same as sorting. By default, the sorting order will be disrupted after execution. Similarly, you can use drop_ Ignore is set in the duplicates method_ The index parameter is True.
>>> df0
A B C team
0 0.548012 0.288583 0.734276 X
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
3 0.039738 0.008414 0.226510 Y
4 0.581093 0.750331 0.133022 Y
>>> df0.drop_duplicates("team", ignore_index=True)
A B C team
0 0.548012 0.288583 0.734276 X
1 0.378794 0.160913 0.971951 Y6. Direct assignment of index
When we have a DataFrame, we want to use different data sources or separate operations to allocate indexes. In this case, you can assign the index directly to the existing DF index.
>>> better_index = ["X1", "X2", "Y1", "Y2", "Y3"] >>> df0.index = better_index >>> df0 A B C team X1 0.548012 0.288583 0.734276 X X2 0.342895 0.207917 0.995485 X Y1 0.378794 0.160913 0.971951 Y Y2 0.039738 0.008414 0.226510 Y Y3 0.581093 0.750331 0.133022 Y
7. Ignore index when writing CSV file
When exporting data to a CSV file, the default DataFrame has an index starting from 0. If we don't want to include it in the exported CSV file, we can use to_ Set the index parameter in the CSV method.
>>> df0.to_csv("exported_file.csv", index=False)As shown below, in the exported CSV file, the index column is not included in the file.
In fact, many methods have index settings, but we are generally concerned about the data and often ignore the index, which may lead to errors when continuing to run. The above high-frequency operations have index settings. It is recommended that you form the habit of setting indexes when you use them at ordinary times, which will save a lot of time.
8. Specify index column when reading
In many cases, our data source is a CSV file. Suppose you have a file named data CSV, which contains the following data.
date,temperature,humidity 07/01/21,95,50 07/02/21,94,55 07/03/21,94,56
By default, pandas will create an index row starting from 0, as follows:
>>> pd.read_csv("data.csv", parse_dates=["date"])
date temperature humidity
0 2021-07-01 95 50
1 2021-07-02 94 55
2 2021-07-03 94 56However, we can use index during the import process_ When the col parameter is set to a column, you can directly specify the index column.
>>> pd.read_csv("data.csv", parse_dates=["date"], index_col="date")
temperature humidity
date
2021-07-01 95 50
2021-07-02 94 55
2021-07-03 94 56last
Like the little partner can point a praise and attention Oh ~ thank you for your support!