Linux(vi/vim)
Pattern
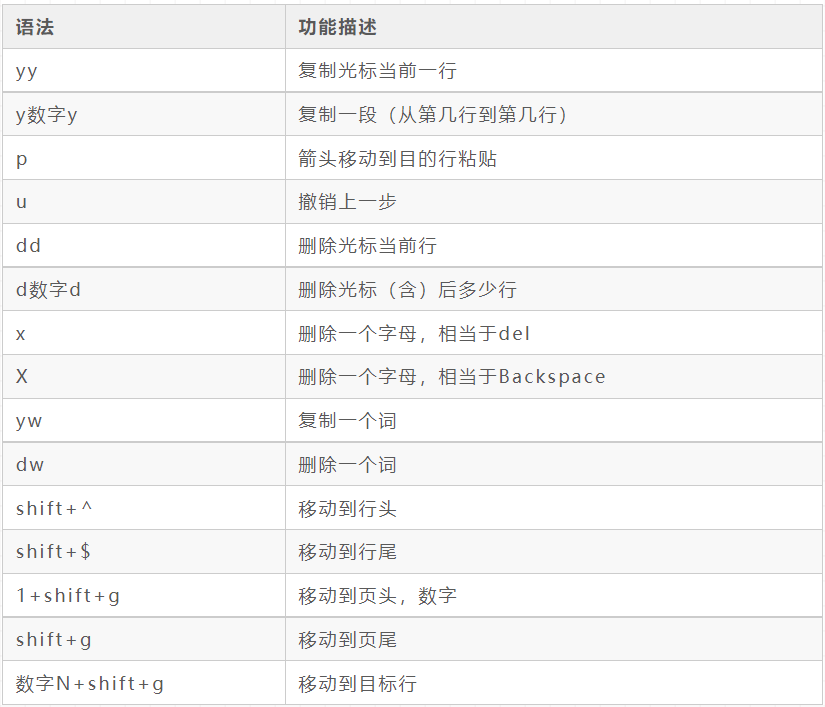
Edit mode
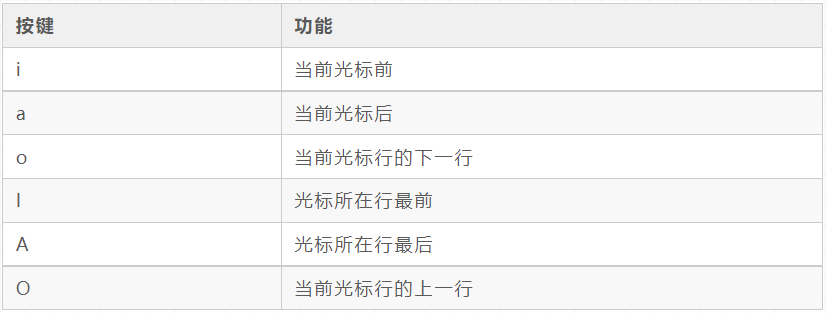
Instruction mode
Compression and decompression
gzip/gunzip compression
(1) Only files can be compressed, not directories
(2) Do not keep the original file
gzip compression: gzip hello txt
Gunzip extract file: gunzip hello txt. gz
zip/unzip compression
You can compress directories and keep source files
Zip compression (compress 1.txt and 2.txt, and the compressed name is mypackage.zip): zip hello.zip hello.txt world.txt
Unzip unzip: unzip hello zip
Unzip to the specified directory: unzip hello zip -d /opt
tar packaging
Tar compresses multiple files: tar - zcvf hello txt world. txt
Tar compressed Directory: tar -zcvf hello tar. gz opt/
Extract tar to the current directory: tar -zxvf hello tar. gz
Extract tar to the specified directory: tar -zxvf hello tar. gz -C /opt
RPM
RPM query command: rpm -qa |grep firefox
RPM unload command:
rpm -e xxxxxx
rpm -e --nodeps xxxxxx (do not check dependencies)
RPM installation command:
rpm -ivh xxxxxx.rpm
rpm -ivh --nodeps fxxxxxx.rpm (- - nodeps, do not detect dependent progress)

Shell
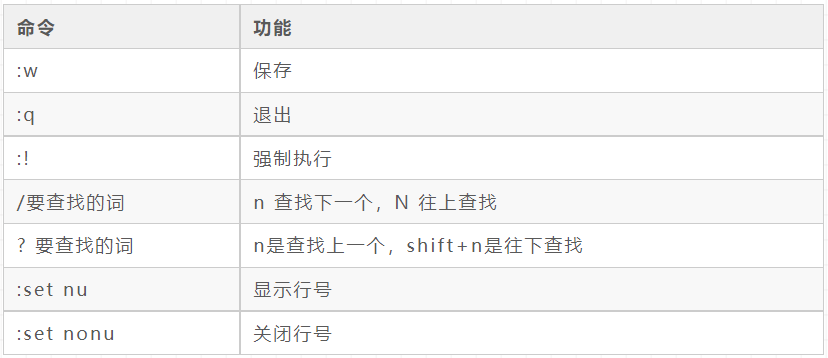
Input / output redirection
Script editing
Hadoop
Start class Command

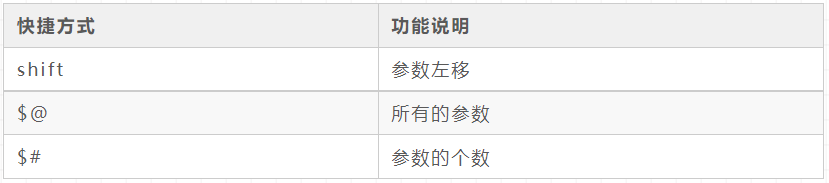
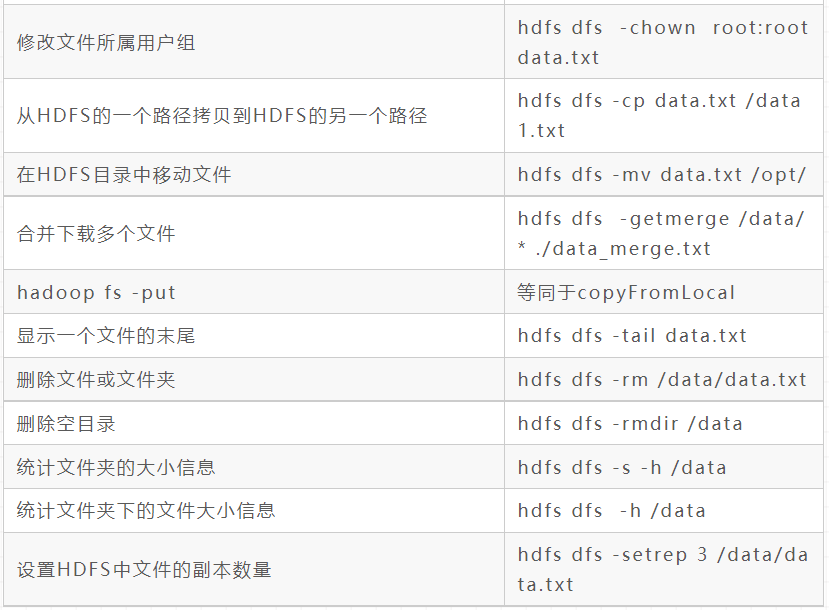
hadoop fs/hdfs dfs command

yarn command

Zookeeper
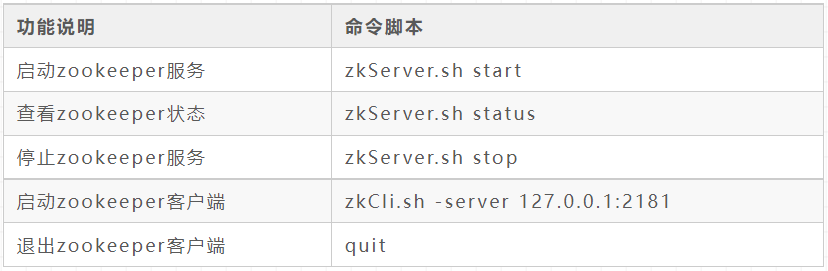
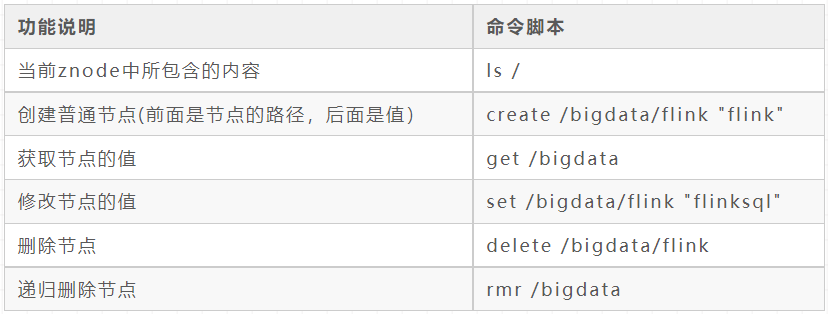
Start command
basic operation
Four letter command
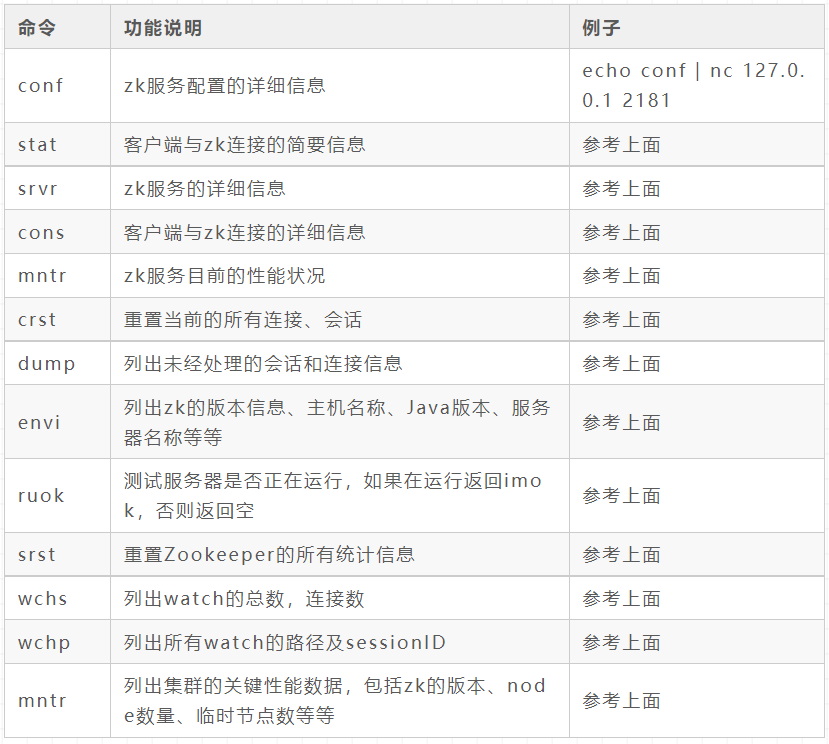
Kafka
Note: I only write one machine here. You can also use the command/ bin/xx.sh (e.g. / bin / Kafka topics. SH)
View all topic s in the current server
kafka-topics --zookeeper xxxxxx:2181 --list --exclude-internal explain: exclude-internal: exclude kafka inside topic For example: --exclude-internal --topic "test_.*"
Create topic
kafka-topics --zookeeper xxxxxx:2181 --create --replication-factor --partitions 1 --topic topic_name explain: --topic definition topic name --replication-factor Define the number of copies --partitions Define number of partitions
Delete topic
Note: server is required Set delete in properties topic. Enable = true, otherwise it is only marked for deletion
kafka-topics --zookeeper xxxxxx:2181 --delete --topic topic_name
producer
kafka-console-producer --broker-list xxxxxx:9092 --topic topic_name Can add:--property parse.key=true(have key Message)
consumer
kafka-console-consumer --bootstrap-server xxxxxx:9092 --topic topic_name Note: optional --from-beginning: All previous data in the topic will be read out --whitelist '.*' : Consume all topic --property print.key=true: display key Consumption --partition 0: Specify partition consumption --offset: Specify start offset consumption
View the details of a Topic
kafka-topics --zookeeper xxxxxx:2181 --describe --topic topic_name
Modify the number of partitions
kafka-topics --zookeeper xxxxxx:2181 --alter --topic topic_name --partitions 6
View a consumer group information
kafka-consumer-groups --bootstrap-server xxxxxx:9092 --describe --group group_name
Delete consumer group
kafka-consumer-groups --bootstrap-server xxxxxx:9092 ---delete --group group_name
Reset offset
kafka-consumer-groups --bootstrap-server xxxxxx:9092 --group group_name --reset-offsets --all-topics --to-latest --execute
leader re-election
Specify the Topic to specify the partition and use the preempted: priority replica policy to re elect the Leader
kafka-leader-election --bootstrap-server xxxxxx:9092 --topic topic_name --election-type PREFERRED --partition 0
All topics and all partitions re elect leaders with the re PREFERRED: priority replica policy
kafka-leader-election --bootstrap-server xxxxxx:9092 --election-type preferred --all-topic-partitions
Query kafka version information
kafka-configs --bootstrap-server xxxxxx:9092 --describe --version
Add, delete and change configuration
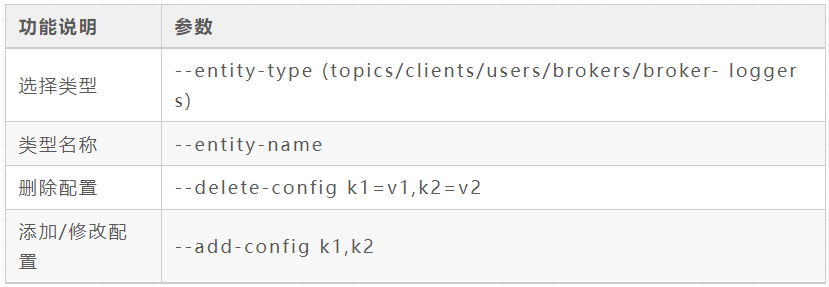
topic add / modify dynamic configuration
kafka-configs --bootstrap-server xxxxxx:9092 --alter --entity-type topics --entity-name topic_name --add-config file.delete.delay.ms=222222,retention.ms=999999
topic delete dynamic configuration
kafka-configs --bootstrap-server xxxxxx:9092 --alter --entity-type topics --entity-name topic_name --delete-config file.delete.delay.ms,retention.ms
Continuous batch pull messages
Maximum consumption of 10 messages per time (without parameters, it means continuous consumption)
kafka-verifiable-consumer --bootstrap-server xxxxxx:9092 --group group_name --topic topic_name --max-messages 10
Delete message for specified partition
Delete the message of a partition of the specified topic to an offset of 1024
JSON file offset JSON file json
{
"partitions": [
{
"topic": "topic_name",
"partition": 0,
"offset": 1024
}
],
"version": 1
}
kafka-delete-records --bootstrap-server xxxxxx:9092 --offset-json-file offset-json-file.json
View Broker disk information
Query the disk information of the specified topic
kafka-log-dirs --bootstrap-server xxxxxx:9090 --describe --topic-list topic1,topic2
Query specified Broker disk information
kafka-log-dirs --bootstrap-server xxxxxx:9090 --describe --topic-list topic1 --broker-list 0
Hive
Startup class
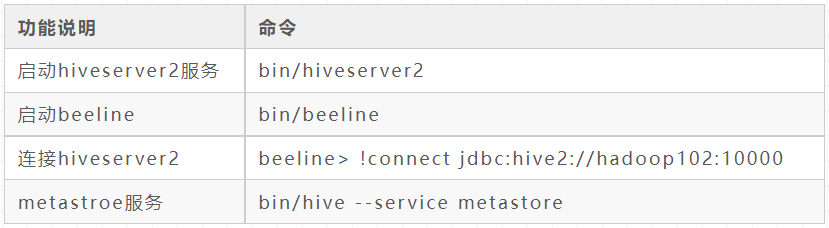
hive starts the metadata service (metastore and hiveserver2) and closes the script gracefully
Start: hive.sh start close: hive.sh stop Restart: hive.sh restart Status: hive.sh status
The script is as follows
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
mkdir -p $HIVE_LOG_DIR
#Check whether the process is running normally. Parameter 1 is the process name and parameter 2 is the process port
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe Service started"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2 Service started"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore Service not started"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2 Service not started"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore The service is running normally" || echo "Metastore Service running abnormally"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2 The service is running normally" || echo "HiveServer2 Service running abnormally"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
Common interactive commands
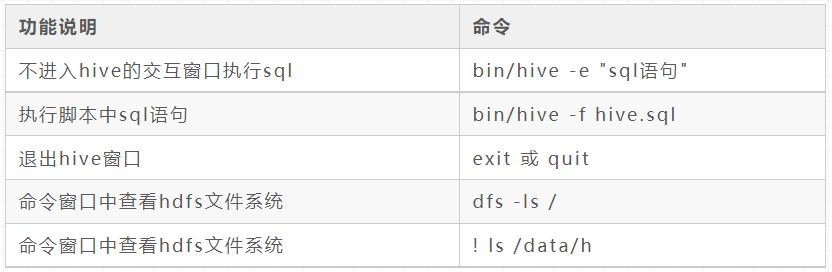
SQL class (special)
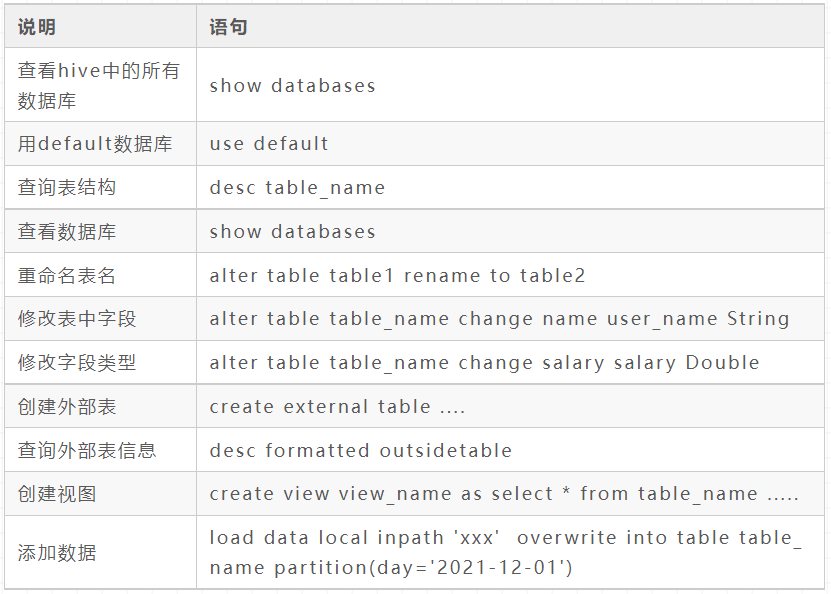
Built in function
(1) NVL
Assign a value to the data whose value is NULL, and its format is NVL (value, default_value). Its work Big data training Yes, if value is NULL, the NVL function returns default_value, otherwise return the value of value. If both parameters are NULL, return NULL
select nvl(column, 0) from xxx;
(2) Row to column

(3) Column to row (one column to multiple rows)
Split(str, separator): cut the string according to the following separator and convert it into character array.
"Expand (Col):" split the complex array or map structure in the hive column into multiple rows.
「LATERAL VIEW」
Usage: LATERAL VIEW udtf(expression) tableAlias AS columnAlias
Explanation: lateral view is used with split, expand and other udtfs. It can split a row of data into multiple rows of data. On this basis, it can aggregate the split data.
The lateral view first calls UDTF for each row of the original table. UDTF will split a row into one or more rows, and then the lateral view combines the results to generate a virtual table that supports alias tables.
"Prepare data source test"

「SQL」
SELECT movie,category_name FROM movie_info lateral VIEW explode(split(category,",")) movie_info_tmp AS category_name ;
"Test results"
<Meritorious service record <Meritorious service plot <War wolf 2 Warfare <War wolf 2 action <War wolf 2 disaster
Window function
(1)OVER()
Determine the data window size of the analysis function. The data window size may change with the change of rows.
(2) CURRENT ROW
n PRECEDING: Go ahead n Row data n FOLLOWING: Back n Row data
(3) UNBOUNDED
UNBOUNDED PRECEDING The front has no boundary, indicating the starting point from the front UNBOUNDED FOLLOWING There is no boundary at the back, indicating the end point at the back
SQL case: aggregation from starting point to current row
select
sum(money) over(partition by user_id order by pay_time rows between UNBOUNDED PRECEDING and current row)
from or_order;
"SQL case: aggregate the current row and the previous row"
select
sum(money) over(partition by user_id order by pay_time rows between 1 PRECEDING and current row)
from or_order;
"SQL case: aggregate the current row with the previous row and the next row"
select
sum(money) over(partition by user_id order by pay_time rows between 1 PRECEDING AND 1 FOLLOWING )
from or_order;
"SQL case: current line and all subsequent lines"
select
sum(money) over(partition by user_id order by pay_time rows between current row and UNBOUNDED FOLLOWING )
from or_order;
(4)LAG(col,n,default_val)
If there is no data in the nth row, default_val
(5)LEAD(col,n, default_val)
If there is no data in the next n line, default_val
"SQL case: query user purchase details, last purchase time and next purchase time"
select user_id,,pay_time,money, lag(pay_time,1,'1970-01-01') over(PARTITION by name order by pay_time) prev_time, lead(pay_time,1,'1970-01-01') over(PARTITION by name order by pay_time) next_time from or_order;
(6)FIRST_VALUE(col,true/false)
The first value in the current window and the second parameter are true. Skip null values.
(7)LAST_VALUE (col,true/false)
The last value under the current window. The second parameter is true. Skip null values.
"SQL case: query the first purchase time and the last purchase time of each month"
select
FIRST_VALUE(pay_time)
over(
partition by user_id,month(pay_time) order by pay_time
rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING
) first_time,
LAST_VALUE(pay_time)
over(partition by user_id,month(pay_time) order by pay_time rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING
) last_time
from or_order;
(8)NTILE(n)
Distribute the rows of the ordered window to the groups of the specified data. Each group has a number. The number starts from 1. For each row, NTILE returns the number of the group to which the row belongs. (used to divide the grouped data into n slices in order and return the current slice value)
"SQL case: query the order information in the first 25% of the time"
select * from (
select User_id,pay_time,money,
ntile(4) over(order by pay_time) sorted
from or_order
) t
where sorted = 1;
4 By
(1)Order By
For global sorting, there is only one Reducer.
(2)Sort By
The partition is orderly.
(3)Distrbute By
Similar to Partition in MR, Partition is used in combination with sort by.
(4) Cluster By
When the distribution by and Sorts by fields are the same, the Cluster by method can be used. In addition to the function of Distribute by, Cluster by also has the function of Sort by. However, sorting can only be in ascending order, and the sorting rule cannot be ASC or DESC.
In the production environment, Order By is rarely used, which easily leads to OOM.
In the production environment, sort by + distribute by is used more frequently.
Sorting function
(1)RANK()
If the sorting is the same, it will repeat, and the total number will not change
1 1 3 3 5
(2)DENSE_RANK()
If the sorting is the same, it will be repeated and the total number will be reduced
1 1 2 2 3
(3)ROW_NUMBER()
Will be calculated in order
1 2 3 4 5
Date function
datediff: returns the number of days from the end date minus the start date
datediff(string enddate, string startdate)
select datediff('2021-11-20','2021-11-22')
date_add: returns the start date. startdate is the date after days is added
date_add(string startdate, int days)
select date_add('2021-11-20',3)
date_sub: returns the date after the start date is reduced by days
date_sub (string startdate, int days)
select date_sub('2021-11-22',3)
Redis
Startup class
key
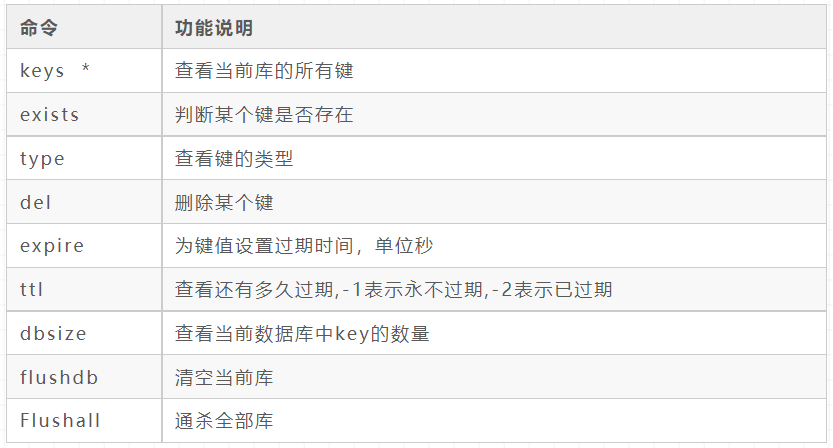
String
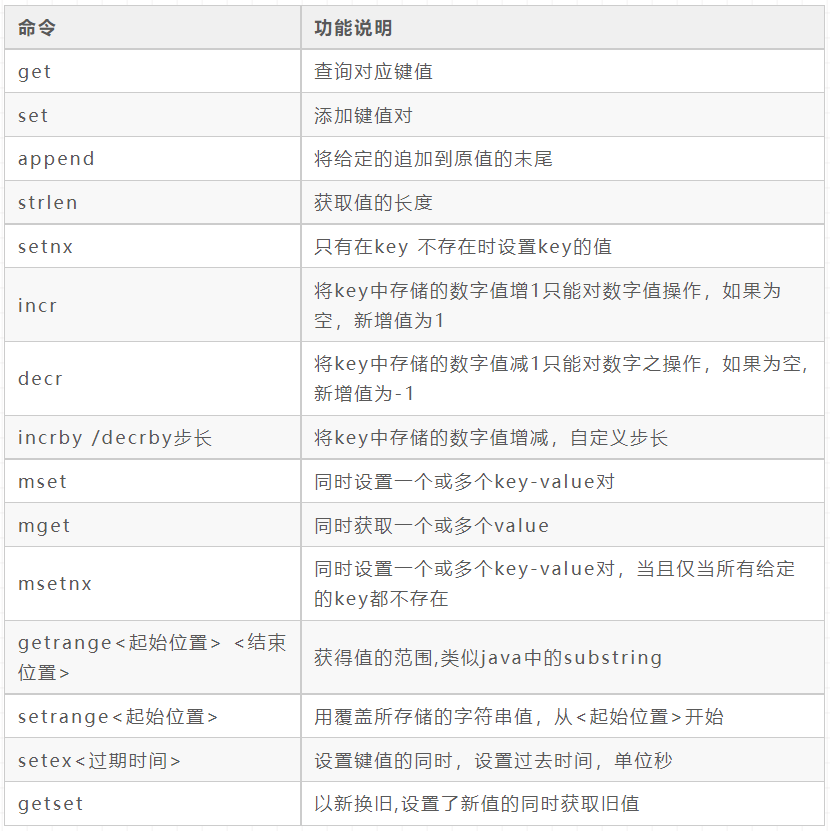
List
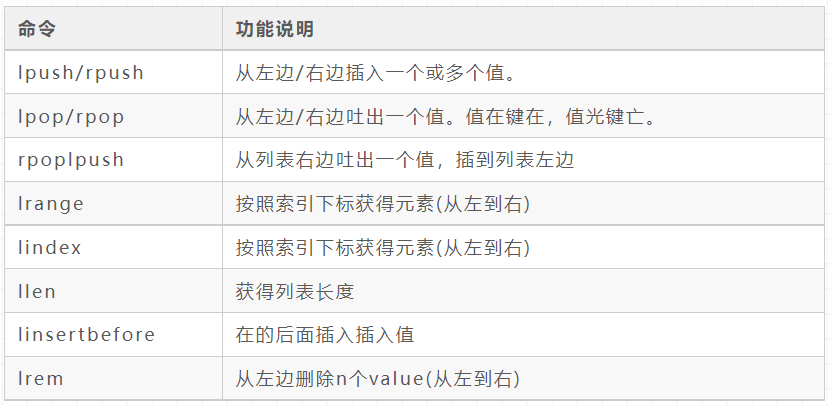
Set

Hash
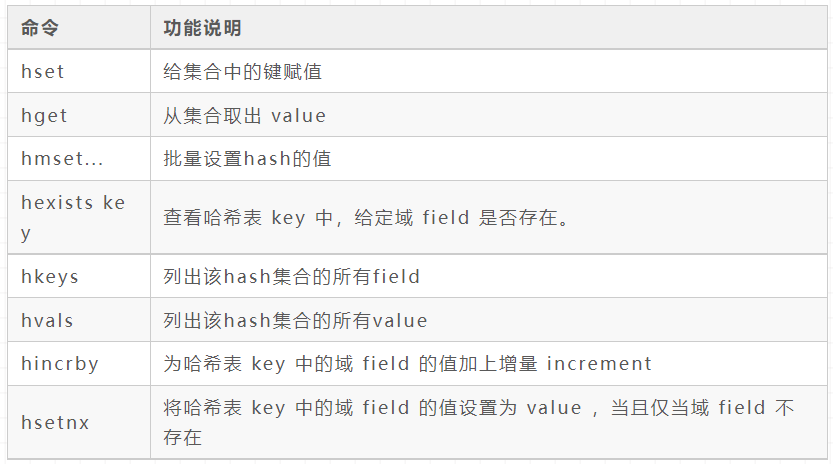
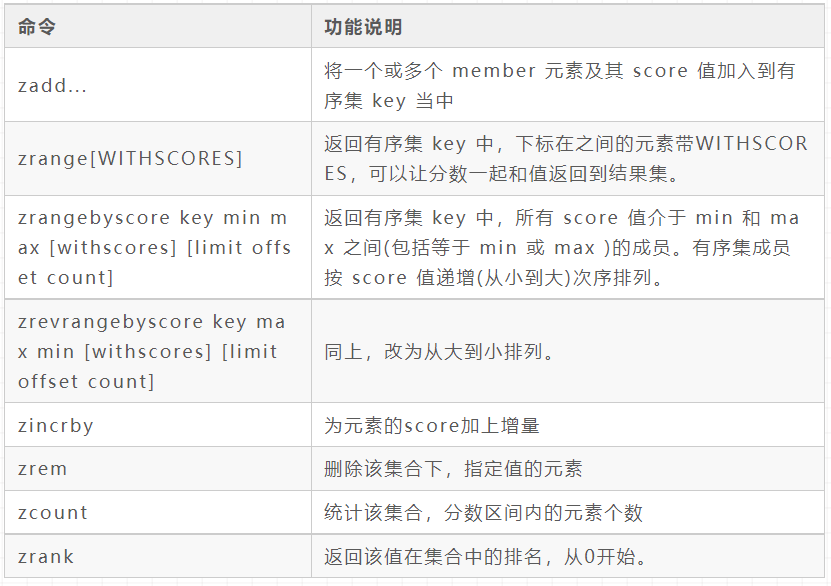
zset(Sorted set)
Flink
start-up
./start-cluster.sh
run
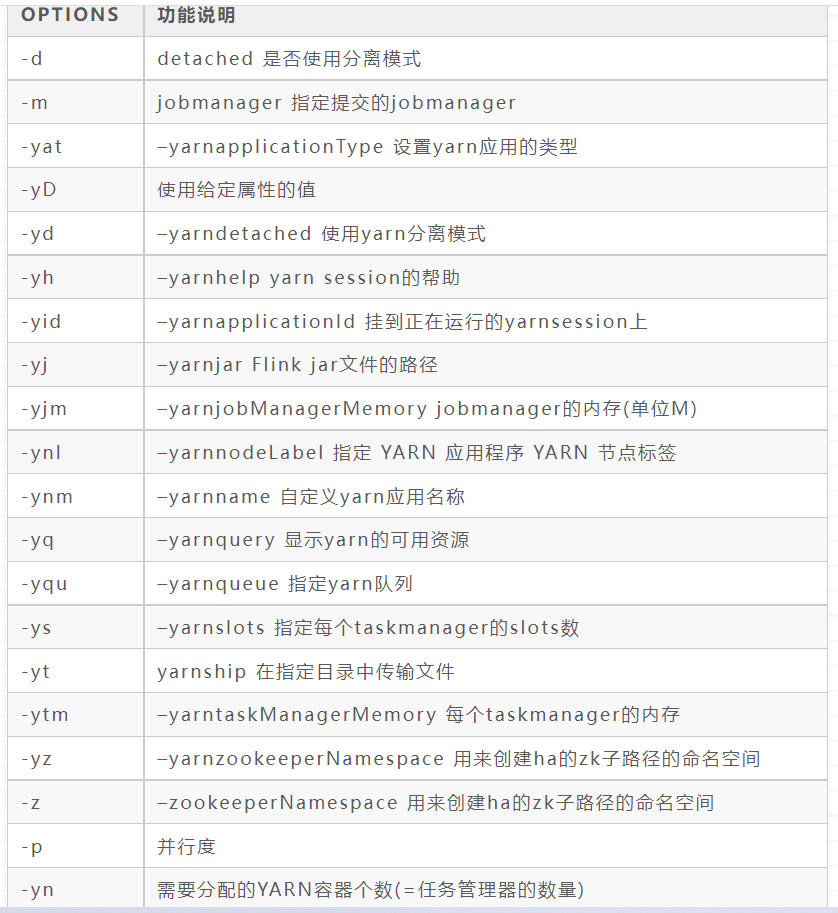
./bin/flink run [OPTIONS] ./bin/flink run -m yarn-cluster -c com.wang.flink.WordCount /opt/app/WordCount.jar
info
./bin/flink info [OPTIONS]

list
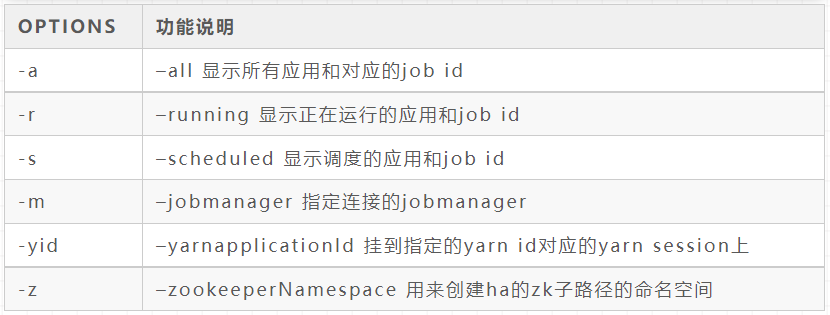
./bin/flink list [OPTIONS]
stop
./bin/flink stop [OPTIONS] <Job ID>

Cancel (weakening)
./bin/flink cancel [OPTIONS] <Job ID>

savepoint
./bin/flink savepoint [OPTIONS] <Job ID>
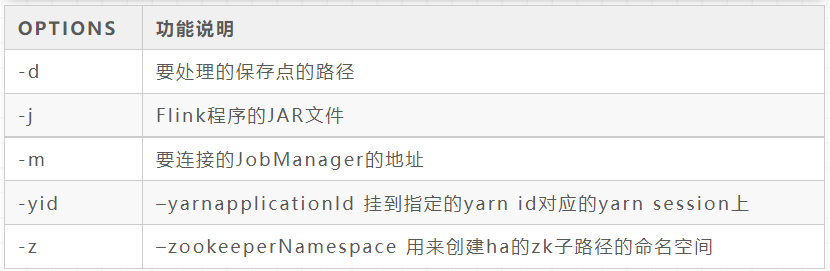
Original author: Wang Gebo