In the first two articles Binary Tree and Binary Search Tree Three traversals of binary trees have been involved. Recursive writing, as long as you understand the idea, a few lines of code. But non-recursive writing is not easy. Here, we summarize and thoroughly analyze their non-recursive writing. Among them, the non-recursive method of mid-order traversal is the simplest and the post-order traversal is the most difficult. Our discussion is based on the following:
-
-
typedef struct node
-
{
-
int data;
-
struct node* lchild;
-
struct node* rchild;
-
}BTNode;
First of all, one thing is clear: non-recursive writing is bound to use stacks, which should not be explained too much. Let's first look at the middle order traversal:
Intermediate traversal
Analysis
Recursive definition of intermediate traversal: first left subtree, then root node, then right subtree. How to write non-recursive code? Bottom line: Let the code follow your thinking. What is our thinking? Thinking is the path of intermediate traversal. Suppose you have a binary tree in front of you. Now you are asked to write out its intermediate traversal sequence. If you have a thorough understanding of ordered traversal, you must first find the bottom node of the left subtree. So the following code is taken for granted:
Intermediate sequence code segment (i)
-
BTNode* p = root;
-
stack<BTNode*> s;
-
-
while (p)
-
{
-
s.push(p);
-
p = p->lchild;
-
}
The reason for preserving the root nodes along the way is: the need for intermediate traversal, after traversing the left subtree, need to use the root node to enter the right subtree. When the code comes here and the pointer p is empty, there are two situations:
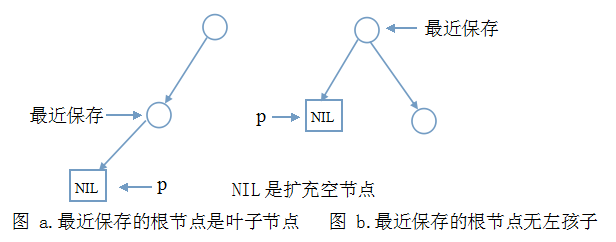
Explain:
- In the figure above, only the necessary nodes and edges are given. The other edges and nodes are independent of discussion and need not be drawn.
- You may think that the most recent saved node in Figure a is not the root node. If you've seen it Tree and Binary Tree Foundation It can be explained by using the concept of extended binary tree. In short, there is no need to tangle with this meaningless issue.
- The whole binary tree with only one root node can be drawn into graph a.
Think carefully, the left subtree of the binary tree, the bottom is not the above two cases? Anyway, you have to go out of the stack and access the node. This node is the first node in the ordered sequence. According to our thinking, the code should be like this:____________
-
p = s.top();
-
s.pop();
-
cout << p->data;
Our thinking goes on and the two pictures are treated differently:
1. In Figure a, a left child is visited, traversing in middle order, and then the root node should be visited. That's another node in Figure a. Happily, it's saved on the stack. We just need the same code as the previous one:
-
p = s.top();
-
s.pop();
-
cout << p->data;
The left child and the root are all visited, and then the right child, right? Next, just one line of code: p = p - > rchild; in the right subtree, there will be a new round of code segments (i), code segments (ii)... Until the stack is empty and p is empty.
2. Look at Figure b again, because there is no left child, the root node is the first in the middle sequence, and then directly enters the right subtree: p = p - > rchild; in the right subtree, there will be a new round of code segments (i), code segments (ii)... Until the stack is empty and p is empty.
Think here, it seems very unclear, really want to distinguish? According to the following code segment (ii) of Figure a:
-
p = s.top();
-
s.pop();
-
cout << p->data;
-
p = s.top();
-
s.pop();
-
cout << p->data;
-
p = p->rchild;
According to Figure b, the code snippet (ii) is like this again:
-
p = s.top();
-
s.pop();
-
cout << p->data;
-
p = p->rchild;
We can conclude that the traversal process is a loop, and a loop is made up of code segments (i), code segments (ii), until the stack is empty and p is empty.
Different ways of dealing with it are maddening. Can they be dealt with in a unified way? It's really possible! Looking back on the extended binary tree, can each node be regarded as the root node? Then, the code only needs to be written in the same form as figure b. That is to say, the code snippet (ii) unification is as follows:
Intermediate sequence code segment (ii)
-
p = s.top();
-
s.pop();
-
cout << p->data;
-
p = p->rchild;
Speech has no basis, it has to go through the theoretical test.
The reason why the code segment (ii) of Figure a can also be written as Figure b is that because it is a leaf node, p=-= p-> rchild; then p must be empty. Is there a new round of code (i) to go through? Obviously not. (because loop conditions are not met) go straight to the code snippet (ii). Look! Finally, it's the same. Or two consecutive trips out of the stack. When you see this, think about it carefully. I'm sure you'll understand.
It's not difficult to write traversal loops.
-
BTNode* p = root;
-
stack<BTNode*> s;
-
while (!s.empty() || p)
-
{
-
-
while (p)
-
{
-
s.push(p);
-
p = p->lchild;
-
}
-
-
if (!s.empty())
-
{
-
p = s.top();
-
s.pop();
-
cout << setw(4) << p->data;
-
-
p = p->rchild;
-
}
-
}
Think carefully, is the code written according to the direction of our thinking? With the detection of boundary conditions, the complete code of intermediate traversal in non-recursive form is as follows:
Intermediate traversal code 1
-
-
void InOrderWithoutRecursion1(BTNode* root)
-
{
-
-
if (root == NULL)
-
return;
-
-
BTNode* p = root;
-
stack<BTNode*> s;
-
while (!s.empty() || p)
-
{
-
-
while (p)
-
{
-
s.push(p);
-
p = p->lchild;
-
}
-
-
if (!s.empty())
-
{
-
p = s.top();
-
s.pop();
-
cout << setw(4) << p->data;
-
-
p = p->rchild;
-
}
-
}
-
}
Congratulations, you've finished traversing non-recursive code in intermediate order. Is it difficult to review?
The next code is essentially the same. I believe you can understand it without my explanation.
Intermediate traversal code 2
-
-
void InOrderWithoutRecursion2(BTNode* root)
-
{
-
-
if (root == NULL)
-
return;
-
-
BTNode* p = root;
-
stack<BTNode*> s;
-
while (!s.empty() || p)
-
{
-
if (p)
-
{
-
s.push(p);
-
p = p->lchild;
-
}
-
else
-
{
-
p = s.top();
-
s.pop();
-
cout << setw(4) << p->data;
-
p = p->rchild;
-
}
-
}
-
}
Preorder traversal
Analysis
The recursive definition of preamble traversal: first root node, then left subtree, then right subtree. With the basis of intermediate traversal, I don't need to guide it like intermediate traversal.
First, we traverse the left subtree, print while traversing, and store the root node in the stack. Then we need to use these nodes to enter the right subtree to start a new cycle. It has to be repeated that all nodes can be regarded as root nodes. Write code snippets (i) according to the direction of thinking:
Preorder code segment (i)
-
-
while (p)
-
{
-
cout << setw(4) << p->data;
-
s.push(p);
-
p = p->lchild;
-
}
Next is to go out of the stack and enter the right subtree according to the top node of the stack.
Preorder code segment (ii)
-
-
if (!s.empty())
-
{
-
p = s.top();
-
s.pop();
-
p = p->rchild;
-
}
Similarly, code snippets (i)(ii) constitute a complete loop. So far, it is not difficult to write a complete pre-order traversal of non-recursive writing.
Preorder traversal code 1
-
void PreOrderWithoutRecursion1(BTNode* root)
-
{
-
if (root == NULL)
-
return;
-
BTNode* p = root;
-
stack<BTNode*> s;
-
while (!s.empty() || p)
-
{
-
-
while (p)
-
{
-
cout << setw(4) << p->data;
-
s.push(p);
-
p = p->lchild;
-
}
-
-
if (!s.empty())
-
{
-
p = s.top();
-
s.pop();
-
p = p->rchild;
-
}
-
}
-
cout << endl;
-
}
Here is another piece of code that is essentially the same:
Preorder traversal code 2
-
-
void PreOrderWithoutRecursion2(BTNode* root)
-
{
-
if (root == NULL)
-
return;
-
BTNode* p = root;
-
stack<BTNode*> s;
-
while (!s.empty() || p)
-
{
-
if (p)
-
{
-
cout << setw(4) << p->data;
-
s.push(p);
-
p = p->lchild;
-
}
-
else
-
{
-
p = s.top();
-
s.pop();
-
p = p->rchild;
-
}
-
}
-
cout << endl;
-
}
stay
Binary Tree This is a slightly different way of writing and essentially the same:
Preorder traversal code 3
-
void PreOrderWithoutRecursion3(BTNode* root)
-
{
-
if (root == NULL)
-
return;
-
stack<BTNode*> s;
-
BTNode* p = root;
-
s.push(root);
-
while (!s.empty())
-
{
-
-
cout << setw(4) << p->data;
-
-
-
-
-
if (p->rchild)
-
s.push(p->rchild);
-
if (p->lchild)
-
p = p->lchild;
-
else
-
{
-
p = s.top();
-
s.pop();
-
}
-
}
-
cout << endl;
-
}
Finally, enter the most difficult post-order traversal:
Postorder traversal
Analysis
Later order traversal recursive definition: first left subtree, then right subtree, then root node. The difficulty of post-order traversal is to determine whether the last visited node is located in the left subtree or the right subtree. If it is located in the left subtree, it needs to skip the root node, enter the right subtree first, and then return to the root node; if it is located in the right subtree, it directly accesses the root node. Look directly at the code, there are detailed comments in the code.
Post-order traversal code 1
-
-
void PostOrderWithoutRecursion(BTNode* root)
-
{
-
if (root == NULL)
-
return;
-
stack<BTNode*> s;
-
-
BTNode* pCur, *pLastVisit;
-
-
pCur = root;
-
pLastVisit = NULL;
-
-
while (pCur)
-
{
-
s.push(pCur);
-
pCur = pCur->lchild;
-
}
-
while (!s.empty())
-
{
-
-
pCur = s.top();
-
s.pop();
-
-
if (pCur->rchild == NULL || pCur->rchild == pLastVisit)
-
{
-
cout << setw(4) << pCur->data;
-
-
pLastVisit = pCur;
-
}
-
-
-
-
-
else
-
{
-
-
s.push(pCur);
-
-
pCur = pCur->rchild;
-
while (pCur)
-
{
-
s.push(pCur);
-
pCur = pCur->lchild;
-
}
-
}
-
}
-
cout << endl;
-
}
Here's another way of thinking about the code. The idea is to attach a left (right) tag to each node. If the left subtree of the node has been accessed, mark it as left; if the right subtree has been accessed, mark it as right. Obviously, a node can only be accessed if its tag bit is right; otherwise, it must first enter its right subtree. See the comments in the code for more details.
Post-order traversal code 2
-
-
enum Tag{left,right};
-
-
typedef struct
-
{
-
BTNode* node;
-
Tag tag;
-
}TagNode;
-
-
void PostOrderWithoutRecursion2(BTNode* root)
-
{
-
if (root == NULL)
-
return;
-
stack<TagNode> s;
-
TagNode tagnode;
-
BTNode* p = root;
-
while (!s.empty() || p)
-
{
-
while (p)
-
{
-
tagnode.node = p;
-
-
tagnode.tag = Tag::left;
-
s.push(tagnode);
-
p = p->lchild;
-
}
-
tagnode = s.top();
-
s.pop();
-
-
if (tagnode.tag == Tag::left)
-
{
-
-
tagnode.tag = Tag::right;
-
-
s.push(tagnode);
-
p = tagnode.node;
-
-
p = p->rchild;
-
}
-
else
-
{
-
cout << setw(4) << (tagnode.node)->data;
-
-
p = NULL;
-
}
-
}
-
cout << endl;
-
}<span style="font-family: 'Courier New'; "> </span>
summary
There is always a huge gap between thinking and code. Usually the thinking is correct and clear, but it is not easy to write the correct code. If we want to cross this gap, there is no other way but to try and draw lessons from it.
The following are the keys to understanding the above code:
- All nodes can be regarded as parent nodes (leaf nodes can be regarded as empty parent nodes for two children).
- Compare the code of the same algorithm. The essence of the algorithm can often be seen in the differences.
- According to your understanding, try to modify the code. Write the code you understand. Written, that's really mastered.
Original address:
http://blog.csdn.net/zhangxiangdavaid/article/details/37115355