Why use concurrenthashmap (the disadvantage of HashMap)
-
HashMap is the most commonly used Map class in Java. It has good performance and fast speed, but it can not guarantee thread safety. It can use null value as Key/value
The thread insecurity of HashMap is mainly reflected in the dead loop when resizing and fast fail when using iterator
In a multithreaded environment, put ting with HashMap will cause an endless loop, so HashMap cannot be used in concurrency
For example, when executing the following code:
final HashMap<String, String> map = new HashMap<>(2);
Thread t = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
new Thread(() -> map.put(UUID.randomUUID().toString(), ""), "ftf" + i).start();
}
}, "ftf");
t.start();
t.join();
//https://cloud.tencent.com/developer/article/1124663
When HashMap executes put concurrently, it will cause an endless loop because multithreading will cause the Entry linked list of HashMap to form a ring. Once the ring is formed, the next node of the Entry will never be empty, resulting in an endless loop
About concurrenthashmap1 seven
ConcurrentHashMap discards a single map range lock and replaces it with a set of 32 locks, each of which is responsible for protecting a subset of hash bucket s. Locks are mainly used by variable operations (put() and remove()). Having 32 independent locks means that up to 32 threads can modify the map at the same time. This does not necessarily mean that when the number of threads concurrently writing to the map is less than 32, other write operations will not be blocked - 32 is the theoretical concurrency limit for write threads, but it may not reach this value in practice. However, 32 is still much better than 1, and is sufficient for most applications running on the current generation of computer systems
- First, the data is stored in sections
- Then assign a lock to each piece of data
- When a thread accesses the data of one segment by using the lock, the data of other segments can also be accessed by other threads
Storage structure:
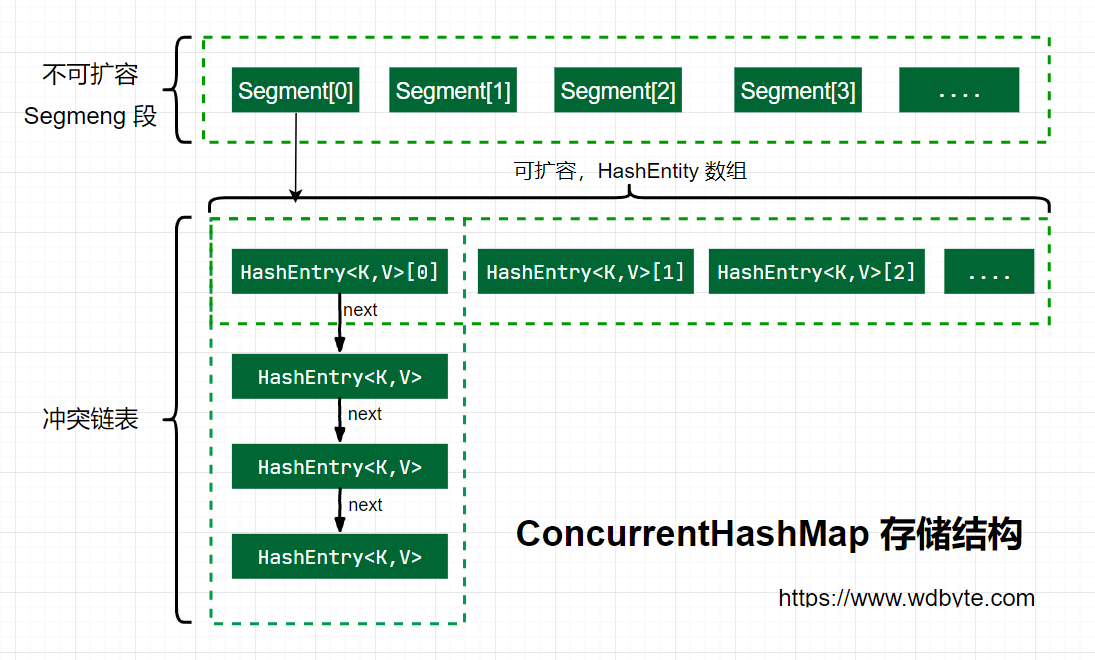
The storage structure of ConcurrentHashMap in jdk7 is shown in the figure above. Segment is a reentrant lock, and HashEntry is used to store key value pair data. A ConcurrentHashMap contains an array of segments. The structure of segment is similar to HashMap, which is an array and linked list structure A segment contains a HashEntry array. Each HashEntry is an element of a linked list structure. Each segment guards the elements in a HashEntry array. When modifying the data of the HashEntry array, you must first obtain the corresponding segment lock, and the internal capacity of each segment can be expanded. However, the number of segments cannot be changed once initialized. The default number of segments is 16, that is, concurrent HashMap supports up to 16 threads by default.
Initialization 1.7
Calling the default parameterless construction of ConcurrentHashMap will create a new empty map with the default initial array size of 16
/**
* Creates a new, empty map with a default initial capacity (16),
* load factor (0.75) and concurrencyLevel (16).
*/
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
The default value 9 of three parameters is passed in the parameterless construction
/**
* Default initialization capacity
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* Default load factor
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* Default concurrency level
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
On the internal implementation logic of parametric constructor
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
// Parameter verification
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// Verify the size of concurrency level. If it is greater than 1 < < 16, reset it to 65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
// To the power of 2
int sshift = 0;
int ssize = 1;
// This loop can find the nearest power value of 2 above the concurrencyLevel
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// Record segment offset
this.segmentShift = 32 - sshift;
// Record segment mask
this.segmentMask = ssize - 1;
// Set capacity
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// c = capacity / ssize, default 16 / 16 = 1. Here is the capacity similar to HashMap in each Segment
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//The HashMap like capacity in Segment is at least 2 or a multiple of 2
while (cap < c)
cap <<= 1;
// create segments and segments[0]
// Create Segment array and set segments[0]
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
Initialization logic of CocurrentHashMap in java7
The default value of parameterless construction is 16. If the size of concurrencyLevel is greater than the maximum value, it will be reset to the maximum value.
Where segments is the native array of segments. The length of this array can be specified by using the concurrency parameter in the constructor of ConcurrentHashMap, and its default value is DEFAULT_CONCURRENCY_LEVEL=16
- segmentShift is used to calculate the displacement of the segments array index. This value is n in [capacity = n power of 2]. put will be used to calculate the position. The default is 32 - sshift = 28 instead
- segmentMask is used to calculate the mask value of the index. The default value is ssize - 1 = 16 -1 = 15
For example, when the concurrency is 16 (that is, the length of the segments array is 16), the segmentShift is 32-4 = 28 (because the fourth power of 2 is 16), while the segmentMask is 1111 (binary). The calculation formula of the index is as follows:
int j = (hash >>> segmentShift) & segmentMask;
Take the power value of the nearest 2 of concurrency level as the initialization capacity, and the default value is 16
- Initialize segments[0], the default size is 2, the load factor is 0.75, and the capacity expansion threshold is 2 * 0.75 = 1.5. The capacity expansion will be carried out only when the second value is inserted
put method (1.7):
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// The hash value is unsigned and shifted to the right by 28 bits (obtained during initialization), and then performs an and operation with segmentMask=15
// In fact, it is to do and operation between the upper 4 bits and segmentMask (1111)
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// If the found Segment is empty, initialize
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// Judge whether the Segment of u position is null
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
// Get the initialization length of hashentry < K, V > in segment 0
int cap = proto.table.length;
// Obtain the capacity expansion load factor in the hash table in segment 0. The loadfactors of all segments are the same
float lf = proto.loadFactor;
// Calculate the expansion threshold
int threshold = (int)(cap * lf);
// Create a HashEntry array with cap capacity
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
// Check whether the Segment at the u position is null again, because there may be other threads operating at this time
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// Check whether the Segment of u position is null
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// Using CAS assignment will only succeed once
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
The specific process is
-
Calculate the position of the key to put and obtain the segment of the specified position.
-
If the segment at the specified location is empty, initialize the segment
Initial session process:
- Check whether the segment of the calculated position is null
- Continue initialization with null and create a HashEntry array using the capacity and load factor of segment [0]
- Check again whether the calculated Segment at the specified location is null
- Initialize this Segment by creating a HashEntry array
- Spin judge (i.e. keep cycling until the judgment is reached) whether the calculated Segment at the specified position is null, and use optimistic lock (CAS) to assign Segment at this position.
CAS operation: complete an operation without locking each time but assuming no conflict. If it fails due to conflict, retry until it succeeds.
Segment.put insert key and value
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// Obtain ReentrantLock exclusive lock, cannot obtain, scanAndLockForPut obtain.
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// Calculate the data location to put
int index = (tab.length - 1) & hash;
// CAS gets the value of the index coordinate
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// Check whether the key already exists. If so, traverse the linked list to find the location, and replace value after finding it
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// There is a conflict between the first value in the header and the first value in the header.
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// If the capacity is greater than the expansion threshold and less than the maximum capacity, expand the capacity
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// The index position is assigned node, which may be an element or the header of a linked list
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
Since Segment inherits ReentrantLock, it is convenient to obtain locks inside Segment, which is used in put process
-
tryLock() obtains the lock, but cannot obtain it. Continue to obtain it by using the scanAndLockForPut method.
-
Calculate the index location where the put data should be put, and then obtain the HashEntry at this location.
-
Traverse the new put element. The HashEntry obtained here may be an empty element or the linked list already exists, so it needs to be treated differently.
If the HashEntry in this location does not exist:
- If the current capacity is greater than the expansion threshold and less than the maximum capacity, expand the capacity
- Direct head insertion
If the HashEntry in this location exists:
- Judge whether the key and hash values of the current element of the linked list are consistent with the key and hash values to be put. Replace value if consistent
- If it is inconsistent, obtain the next node in the linked list until it is found that the same value is replaced, or there is no same value after traversing the linked list, then:
- If the current capacity is greater than the expansion threshold and less than the maximum capacity, expand the capacity
- Direct head insertion
- If the position to be inserted exists before, the old value is returned after replacement; otherwise, null is returned
scanAndLockForPut operation:
Keep spinning tryLock() to get the lock. When the number of spins is greater than the specified number, lock() is used to block the acquisition of the lock. Obtain the HashEntry of the lower hash position in the spin order table
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// Spin acquisition lock
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
// After the spin reaches the specified number of times, the block waits until only the lock is obtained
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
Capacity expansion rehash (delete this method in 1.7-1.8)
The capacity of ConcurrentHashMap is doubled. When the data in the old array is moved to the new array, the position is either unchanged or changed to index+oldsize. The node in the parameter will be inserted into the specified position by header interpolation after capacity expansion
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
// Old capacity
int oldCapacity = oldTable.length;
// New capacity, double expansion
int newCapacity = oldCapacity << 1;
// New expansion threshold
threshold = (int)(newCapacity * loadFactor);
// Create a new array
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// For the new mask, the default 2 is 4 after capacity expansion, - 1 is 3, and binary is 11.
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
// Traverse the old array
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// Calculate the new location. The new location can only be inconvenient or the old location + old capacity.
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
// If the current position is not a linked list, but just an element, assign a value directly
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// If it's a linked list
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// The new location can only be inconvenient or the old location + old capacity.
// After traversal, the element positions after lastRun are the same
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// , the element positions after lastRun are the same, and they are directly assigned to the new position as a linked list.
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
// Traverse the remaining elements and insert the header to the specified k position.
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// Insert a new node by head interpolation
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
get method (1.7)
Calculate the storage location of the key.
Traverse the specified position of key to find the same value.
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// Calculate the storage location of the key
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
// If it is a linked list, traverse to find the value of the same key.
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
ConcurrenrtHashMap 1.8
Compared with java7, java8 is no longer a segment array + hash array + linked list. Instead, it is a node array + linked list / red black tree. When the conflict chain is expressed to a certain length, the linked list will be converted into a red black tree.
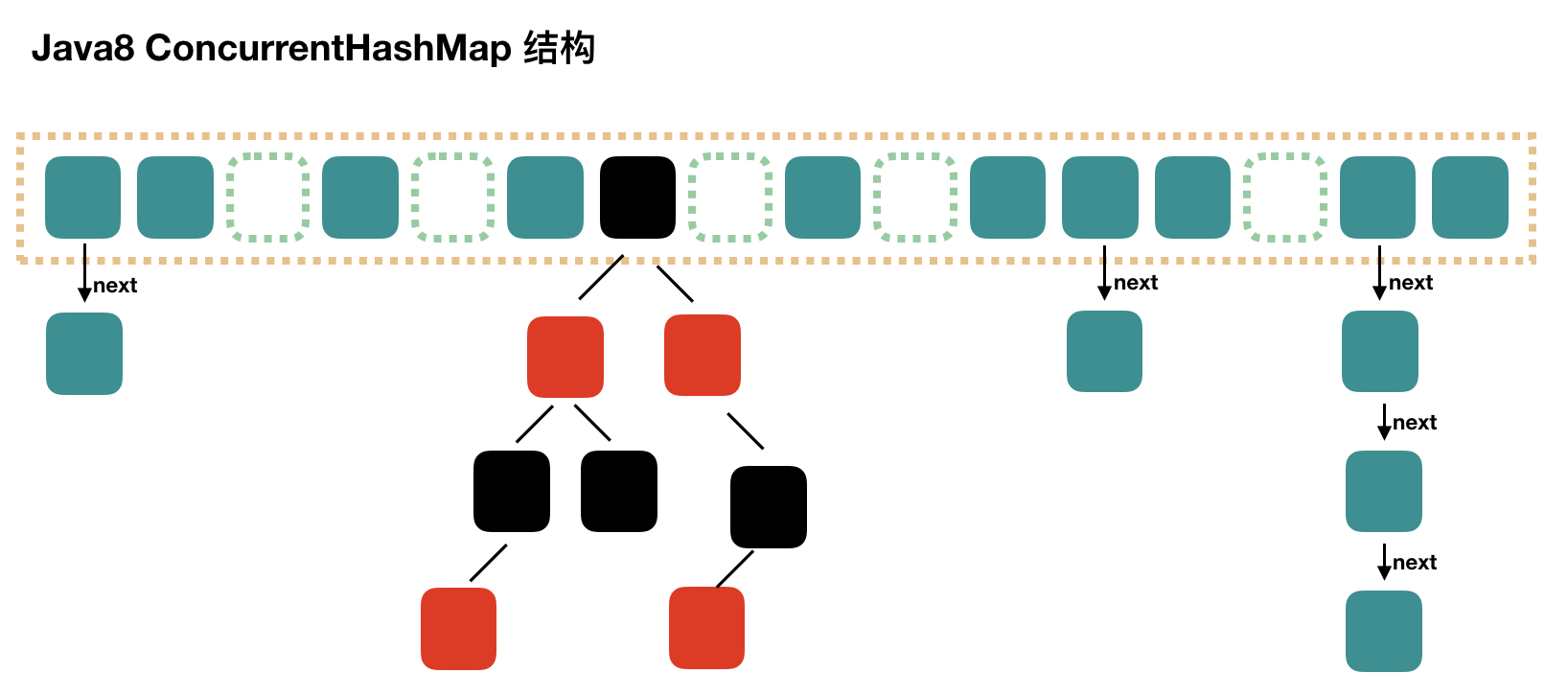
Initialize InitTable
table: the array of containers is initialized at the first insertion, and the size is always an exponential power of 2
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// If sizeCtl < 0 ,Describes the execution of another thread CAS Successful, initializing.
if ((sc = sizeCtl) < 0)
// Cede CPU usage rights
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
The initialization of ConcurrentHashMap is completed through spin and optimistic lock operations.
Note that the value of the variable sizeCtl determines the current initialization state
- -1 description initializing
- -N indicates that N-1 threads are expanding
- Indicates the initialization size of the table. If the table is not initialized
- Indicates the capacity of the table. If the table has been initialized
put(1.8)
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key and value cannot be empty
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = target location element
Node<K,V> f; int n, i, fh;// The element hash value of the target location is stored after fh
if (tab == null || (n = tab.length) == 0)
// Array bucket is empty, initialize array bucket (spin + CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// If the bucket is empty, CAS is put into it without locking. If it succeeds, it will directly break out
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// Join a node using synchronized locking
synchronized (f) {
if (tabAt(tab, i) == f) {
// The description is a linked list
if (fh >= 0) {
binCount = 1;
// Loop to add new or overlay nodes
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// Red black tree
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
- Calculate the hashcode according to the key
- Determine whether initialization is required
- That is, the node located by the current key. If it is empty, it means that the current position can write data. Use the optimistic lock to try to write. If it fails, the spin guarantees success
- If hashcode == MOVED == -1 in the current location, capacity expansion is required
- If they are not satisfied, the synchronized lock is used to write data
- If the quantity is greater than tree_ Threshold is converted to red black tree
get(1.8)
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// hash position of key
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// If the specified node location is the same as the hash element
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
// If the key hash values are equal and the key values are the same, the element value is returned directly
return e.val;
}
else if (eh < 0)
// If the hash value of the header node is less than 0, it indicates that the capacity is being expanded or it is a red black tree. find it
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
// Is a linked list, traversal search
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
- Calculate the position according to the hash value.
- Find the specified location. If the header node is the one to be found, directly return its value
- If the hash value of the head node is less than 0, it indicates that the capacity is being expanded or it is a red black tree. Find it
- If it is a linked list, traverse and find it
Conclusion
The piecewise lock used by ConcurrentHashMap in java7 means that only one thread can operate on each Segment and only one thread can operate on each Segment. Each Segment is a structure similar to HashMap array, which can be expanded, and its conflict will be transformed into a linked list. However, the number of segments cannot be changed once initialized
The concurrent HashMap in java8 uses the Synchronized lock plus optimistic lock mechanism. The structure is transformed into node array + linked list / red black tree. Node is similar to a HashEntry structure. When the conflict reaches a certain size, it will be transformed into a red black tree. When the conflict is less than a certain number, it will be returned to the linked list.
Collated from: https://snailclimb.gitee.io/javaguide
https://cloud.tencent.com/developer/article/1124663