1. What is flick
flink is a flow processing framework. Usually, the usage scenario is to consume kafka data and send it to other systems after grouping and aggregation. Grouping and aggregation are the core of flink. This paper only describes a single usage scenario. Stream data is equivalent to continuous data. The log data in kafka in production can be understood as stream data. Stream data can also be divided into bounded stream and unbounded stream. Bounded means text data. As data stream with fixed size, unbounded means continuous data.
2. flink interface
The following figure shows the interface of flink. In the interface, you can submit the code jar package and run the processing in real time
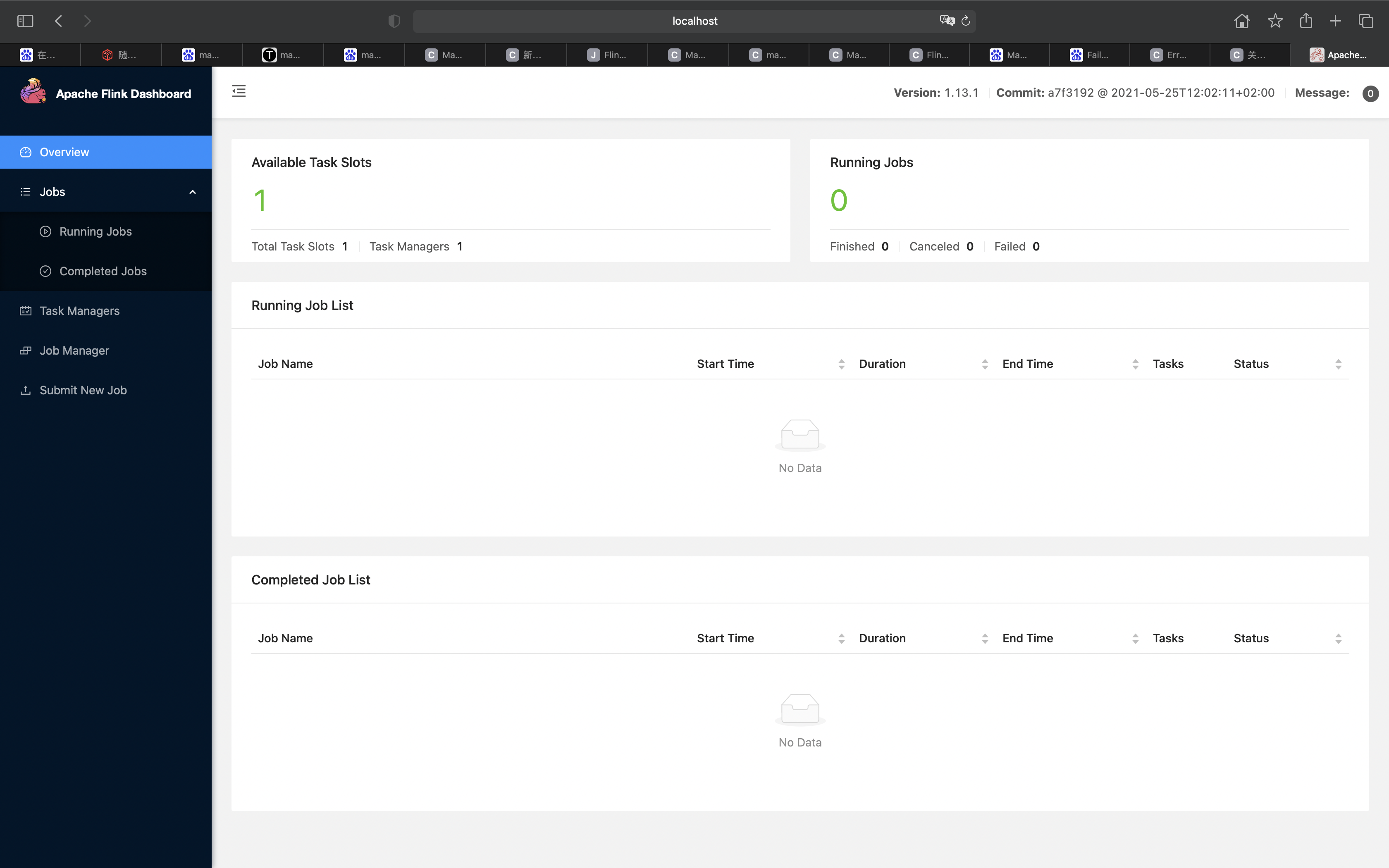
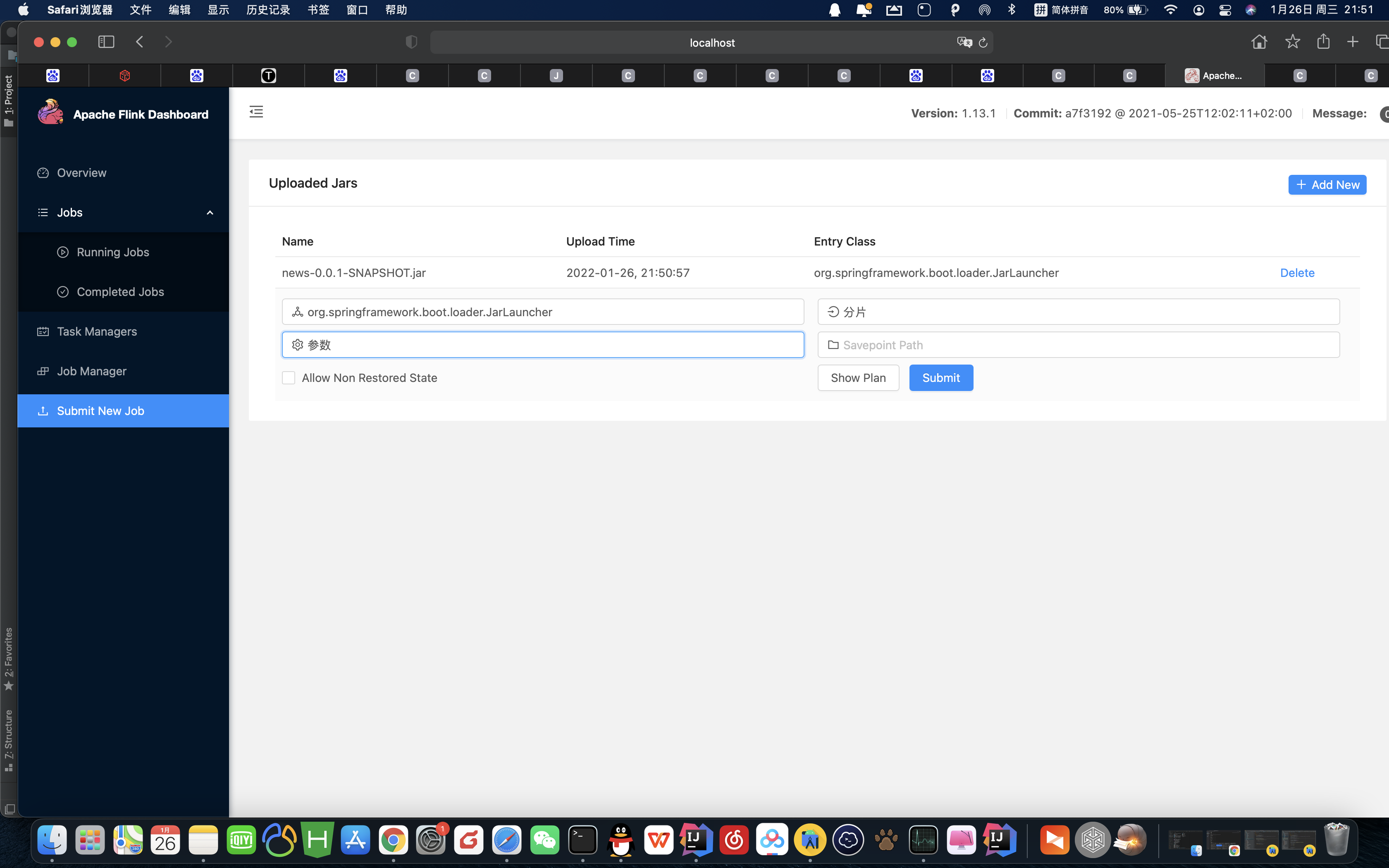
3. flink explains the usage scenarios in combination with code cases
Define the following methods in the main entry function
//Get streaming environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Get data stream
DataStream<String> stringDataStreamSource = env.socketTextStream("127.0.0.1", 6666);
//Transfer to pojo
SingleOutputStreamOperator<KafkaEntity> map = stringDataStreamSource.map(new MapFunction<String, KafkaEntity>() {
@Override
public KafkaEntity map(String value) throws Exception {
KafkaEntity kafkaEntity = new KafkaEntity();
if (!"".equals(value)){
String[] splitResult = value.split("1");
kafkaEntity.setCityId(splitResult[0]);
kafkaEntity.setAppId(splitResult[1]);
kafkaEntity.setProcessCode(splitResult[2]);
kafkaEntity.setStartTime(splitResult[3].substring(0,12));
kafkaEntity.setErrCode(splitResult[4]);
}
return kafkaEntity;
}
});
//Grouping, aggregation
SingleOutputStreamOperator<Object> applyResult = map.keyBy("processCode", "appId", "cityId", "startTime")
.timeWindow(Time.seconds(15))//Aggregate every 15 seconds
.apply(new WindowFunction<KafkaEntity, Object, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<KafkaEntity> input, Collector<Object> out) throws Exception {
//Total number of calls
KafkaEntity aggregateResult = input.iterator().next();
int reqAmount = IteratorUtils.toList(input.iterator()).size();
//Success times
int successAmount = 0;
//Total time
long timeAll = 0;
//Current limiting times
int failAmount = 0;
List<KafkaEntity> list = IteratorUtils.toList(input.iterator());
for (int i = 0; i < list.size(); i++) {
KafkaEntity kafkaEntity = list.get(i);
timeAll += Long.parseLong(kafkaEntity.getDuration());
if ("0".equals(kafkaEntity.getErrCode())) {
successAmount += 1;
} else {
failAmount += 1;
}
}
//Average call duration
long averageDuration = (timeAll / reqAmount);
//Aggregation results
aggregateResult.setReqAmount(String.valueOf(reqAmount));
aggregateResult.setSuccessAmount(String.valueOf(successAmount));
aggregateResult.setAverageDuration(String.valueOf(averageDuration));
aggregateResult.setFailAmount(String.valueOf(failAmount));
aggregateResult.setInsertTime(new Date());
out.collect(aggregateResult);
}
});
applyResult.addSink(new RichSinkOperation());
env.execute();
4. Code interpretation
4.1
First, you need to get the flow environment
4.2
Replace kafka consumers with socket text stream, start it with nc-lk 6666 in linux, and then write and send text to simulate kafka consumers to read data. Here, the data stream is also obtained through the first step of stream environment
4.3
After obtaining the data stream, turn the datastream into a pojo class through the map method (which can also be regarded as an operator). At this point, the data preparation is completed
4.4
SingleOutputStreamOperator is also a subclass of datastream. The obtained pojo streams are grouped by keyby. The grouping dimensions are four, namely "processCode", "appId", "cityId", "startTime". As long as one element in the received data is different from the previous one, it is a new group
4.5
After grouping, set the window size to 15 seconds through timewindow, that is, aggregate once every 15 seconds. The aggregation method is apply below
4.6
The apply method is to process the data received within 15 seconds according to the user's definition
KafkaEntity aggregateResult = input.iterator().next(); Represents pojo objects grouped according to the four dimensions. The four attributes in the same group are the same. In this example, the total number of times of the same group is calculated, that is, after grouping according to the current dimension, the number of data in each group, that is, the size of the list, is recalculated and put into an attribute of pojo, and finally through out The collect method summarizes the calculated results in several attributes of an object and outputs them
4.7
applyResult is the result after aggregation. The last step is to output the aggregation result to the external system. Here, for example, enter the database (redis or hbase are the same)
4.8
public class RichSinkOperation extends RichSinkFunction {
@Override
public void invoke(Object value) throws Exception {
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
//Get factory
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = factory.openSession();
FlinkDao flinkDao = sqlSession.getMapper(FlinkDao .class);
KafkaEntity kafkaEntity = (KafkaEntity) value;
flinkDao.insertRecord(kafkaEntity);
sqlSession.commit();
}
@Override
public void open(Configuration parameters) throws Exception {
}
}
mybatis is integrated here. This user-defined class inherits RichSinkFunction and mainly implements the invoke method to store each aggregation result
The code of this example is only used in very limited scenarios. It is only used to get through the overall process. Different application processing methods need to be defined according to different businesses. The sink operation here is also unreasonable. In production, the database connection should be placed in open and the data pool should be used. In addition, it also needs to consider that there are hundreds of millions of data every minute of production. If you open a one minute window, The aggregation results are all in memory. Whether the memory will explode and whether the one-time sink database operation will be blocked after aggregation need pressure measurement to get the actual effect verification.