pack_padded_sequence and pad_packed_sequence
When using RNN to train sequence sample data, we will face the situation of different length of sequence sample data. For example, when doing NLP tasks and speech processing tasks, the length of each sentence or speech sequence is often different. Do you want to feed the network one by one for training? This obviously won't work.
For more efficient batch processing, it is necessary to fill the sample sequence to ensure that the length of each sample is the same, and use the function pad in PyTorch_ Sequence populates the sequence. Although the length of the filled sample sequence is the same, many invalid values 0 may be filled in the sequence. Feeding the filled value 0 to RNN for forward calculation will not only waste computing resources, but also cause errors in the final value. Therefore, before sending the sequence to RNN for processing, it is necessary to use pack_padded_sequence is compressed to compress invalid fill values. The output of the sequence after RNN processing is still a compressed sequence, and pad needs to be used_ packed_ Sequence refills the compressed sequence for subsequent processing.
The function of each function and the relationship between each function are described in detail below.
1, pad_sequence
parameter
sequences: indicates the input sample sequence, which is of type list, and the elements in the list are of type tensor. The size of tensor is L * F. Where l is the length of a single sequence and F is the number of features of each time step in the sequence. The dimension of F will vary according to different tasks.
batch_first: True corresponds to [batch_size, seq_len, feature]; False corresponds to [seq_len, batch_size, feature]. Conventionally, it is generally set to True, which is more in line with our cognition.
padding_value: fill in the value. The default value is 0.
explain
It is mainly used to fill in samples, and the filling value is generally 0. When we train the network, we usually feed the training sample data to the network in a mini batch manner. In PyTorch, data exists in the form of tensors. A mini batch is actually a high-dimensional tensor. The length of each sequence data must be the same to form a tensor. In order for the network to process the data in the form of mini batch, the sequence samples must be filled to ensure that the data length in a mini batch is the same.
In PyTorch, the data loader is generally used to load data, return data in the form of mini batch, and then feed this data to the network for training. We usually customize a collate_fn function to complete the filling of data.
Examples
import torch
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence,pack_padded_sequence,pack_sequence,pad_packed_sequence
class MyData(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
data = pad_sequence(data, batch_first=True, padding_value=0)
return data
a = torch.tensor([1,2,3,4])
b = torch.tensor([5,6,7])
c = torch.tensor([7,8])
d = torch.tensor([9])
train_x = [a, b, c, d]
data = MyData(train_x)
data_loader = DataLoader(data, batch_size=2, shuffle=True, collate_fn=collate_fn)
# Use the default collate_fn will report an error
#data_loader = DataLoader(data, batch_size=2, shuffle=True)
batch_x = iter(data_loader).next()Run the program to get batch_ Value of X:
# batch_x
tensor([[1, 2, 3, 4],
[9, 0, 0, 0]])From batch_ As can be seen from the value of X, the second line is filled with three zeros to keep its length consistent with the first line.
It should be noted that for sequences with different lengths, the default collate is used_ FN function, do not customize collate_fn function completes the filling of the sequence, and the above program will report an error.
2, pack_padded_sequence
parameter
input: via pad_ Data after sequence processing.
lengths: the actual length of each sequence in mini batch.
batch_first: True corresponds to [batch_size, seq_len, feature];
False corresponds to [seq_len, batch_size, feature].
enforce_sorted: if True, the input should be a sequence sorted by length in descending order. If it is False, it will be sorted inside the function. The default value is True.
explain
The meaning of this pack can be understood as compression or compression, because there will be a lot of redundant padding after the data is filled_ Value, so it needs to be compressed.
Why use this function?
How RNN reads data: the network eats a set of data with the same time step each time, that is, the data with the same subscript in all samples of mini batch, and then obtains the output of a mini batch; Then move to the next time step, read in all the data of the time step in the mini batch, and then output; Until all time step data is processed.
First time step:

Second time step:

0 in mini batch is just padding for data alignment_ Value, if the forward calculation is performed, the padding_value is also taken into account, which may cause RNN to pass a lot of useless padding_value, which not only wastes computing resources, but also may have errors in the final value. For the data of sequence 2 above, through the RNN network:
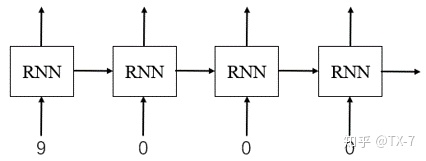
In fact, the calculation from the second time step to the last time step is redundant, and the input is invalid padding_ It's just value.
It can be seen from the above analysis that in order for RNN to efficiently read data for training, it is necessary to use pack after pad_ padded_ Sequence processes the data.
It should be noted that by default, we must arrange the input data according to the sequence length from large to small before sending it to the pack_padded_sequence, otherwise an error will be reported.
Examples
Just add the collate in the above example_ FN function can be modified slightly, and the rest remains unchanged.
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
seq_len = [s.size(0) for s in data] # Get the true length of the data
data = pad_sequence(data, batch_first=True)
data = pack_padded_sequence(data, seq_len, batch_first=True)
return dataOutput:
# batch_x
PackedSequence(data=tensor([1, 9, 2, 3, 4]),
batch_sizes=tensor([2, 1, 1, 1]),
sorted_indices=None, unsorted_indices=None)It can be seen that the output returns a PackedSequence object, which mainly includes two parts: data and batch_sizes .
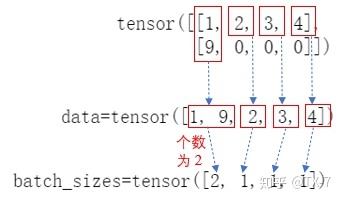
The fill value 0 is skipped. batch_ The value in size actually tells the network how much data to eat in each time step.
If you look closely, the output PackedSequence object also contains two parts sorted_indices and unsorted_indices . We talked about pack earlier_ padded_ Sequence also has one parameter, enforce_sorted, if True, the input should be a sequence sorted by length in descending order. If it is False, it will be sorted inside the function. The default value is True. That is, enter pack_ padded_ We can also not sort the data before sequence.
Now we will enforce_sorted is set to False, and the input data is not sorted in advance.
data = [torch.tensor([9]),
torch.tensor([1,2,3,4]),
torch.tensor([5,6])]
seq_len = [s.size(0) for s in data]
data = pad_sequence(data, batch_first=True)
data = pack_padded_sequence(data, seq_len, batch_first=True, enforce_sorted=False)Output:
PackedSequence(data=tensor([1, 5, 9, 2, 6, 3, 4]),
batch_sizes=tensor([3, 2, 1, 1]),
sorted_indices=tensor([1, 2, 0]),
unsorted_indices=tensor([2, 0, 1]))sorted_indices = tensor([1, 2, 0], indicating the corresponding relationship between the sorted result and the subscript of the tensor in the original data. 1 indicates that the first row in the original data is the longest, followed by the second row and the 0 row.
Suppose the result after sorting is:
sort_data = [torch.tensor([1,2,3,4]),
torch.tensor([5,6])
torch.tensor([9]),
]unsorted_indices = tensor([2, 0, 1], which indicates the result before sorting. 2 indicates that the second row of sort_data corresponds to row 0 of data; 0 indicates that row 0 of sort_data corresponds to row 1 of data; 1 indicates that row 1 of sort_data corresponds to row 2 of data.
3, pack_sequence
I checked PyTorch's official document, pack_ The sequence function is not available in versions below 0.4.0.
parameter
sequences: enter the sample sequence, which is of type list, and the elements in the list are tensor; The size of tensor is L * F, where l is the length of a single sequence and F is the number of features of each time step in the sequence. The dimension of F will vary according to different tasks.
enforce_sorted: if True, the input should be a sequence sorted by length in descending order. If it is False, it will be sorted inside the function. The default value is True.
explain
Let's look at the source code in PyTorch:
def pack_sequence(sequences, enforce_sorted=True): lengths = torch.as_tensor([v.size(0) for v in sequences]) return pack_padded_sequence(pad_sequence(sequences),lengths,enforce_sorted=enforce_sorted)
As you can see, pack_sequence is actually for pad_sequence and pack_ padded_ An encapsulation of the sequence operation. Work that can only be completed in two steps through a function.
Examples
Collate in front_ FN function can be further modified to:
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
data = pack_sequence(data)
#seq_len = [s.size(0) for s in data]
#data = pad_sequence(data, batch_first=True)
#data = pack_padded_sequence(data, seq_len, batch_first=True)
return dataThe output result is the same as before:
# batch_x
PackedSequence(data=tensor([1, 9, 2, 3, 4]),
batch_sizes=tensor([2, 1, 1, 1]),
sorted_indices=None, unsorted_indices=None)4, pad_packed_sequence
parameter
sequences: PackedSequence object, batch to be filled;
batch_first: generally set to True, and the returned data format is [batch_size, seq_len, feature];
padding_value: fill in value;
total_length: if it is not None, the output will be filled to length: total_length.
explain
If you use pack when feeding network data_ Sequence, and the RNN of pytorch will also package the output out into a PackedSequence object.
This function is actually pack_ padded_ Reverse operation of sequence function. Is to refill the compressed sequence.
Why fill it back? My understanding is that in collate_ Pad is usually called in FN function_ Sequence fills the label. In order to align the output result of RNN with the label, the compressed sequence needs to be filled back to facilitate subsequent calculation.
Examples
It should be noted that in the following program, in order to generate data conforming to the LSTM input format [batch_size, seq_len, feature], the function unsqueeze is used for dimension upgrading. Among them, batch_ Size is the number of samples, seq_ Len is the length of the sequence and feature is the number of features.
class MyData(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
seq_len = [s.size(0) for s in data]
data = pad_sequence(data, batch_first=True).float()
data = data.unsqueeze(-1)
data = pack_padded_sequence(data, seq_len, batch_first=True)
return data
a = torch.tensor([1,2,3,4])
b = torch.tensor([5,6,7])
c = torch.tensor([7,8])
d = torch.tensor([9])
train_x = [a, b, c, d]
data = MyData(train_x)
data_loader = DataLoader(data, batch_size=2, shuffle=True, collate_fn=collate_fn)
batch_x = iter(data_loader).next()
rnn = nn.LSTM(1, 4, 1, batch_first=True)
h0 = torch.rand(1, 2, 4).float()
c0 = torch.rand(1, 2, 4).float()
out, (h1, c1) = rnn(batch_x, (h0, c0))The result of out is as follows. It is an object of PackedSequence type, which is the same as the previous call to pack_padded_sequence gets the same result type.
# out
PackedSequence(data=tensor([[-1.3302e-04, 5.7754e-02, 4.3181e-02, 6.4226e-02],
[-2.8673e-02, 3.9089e-02, -2.6875e-03, 4.2686e-03],
[-1.0216e-01, 2.5236e-02, -1.2230e-01, 5.1524e-02],
[-1.6211e-01, 2.1079e-02, -1.5849e-01, 5.2800e-02],
[-1.5774e-01, 2.6749e-02, -1.3333e-01, 4.7894e-02]],
grad_fn=<CatBackward>),
batch_sizes=tensor([2, 1, 1, 1]),
sorted_indices=None, unsorted_indices=None)Call pad on out_ packed_ Fill in sequence:
out_pad, out_len = pad_packed_sequence(out, batch_first=True)
out_pad and out_ The results of len are as follows:
# out_pad
tensor([[[-1.3302e-04, 5.7754e-02, 4.3181e-02, 6.4226e-02],
[-1.0216e-01, 2.5236e-02, -1.2230e-01, 5.1524e-02],
[-1.6211e-01, 2.1079e-02, -1.5849e-01, 5.2800e-02],
[-1.5774e-01, 2.6749e-02, -1.3333e-01, 4.7894e-02]],
[[-2.8673e-02, 3.9089e-02, -2.6875e-03, 4.2686e-03],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]]],
grad_fn=<TransposeBackward0>)
# out_len
tensor([4, 1])Recall that we call pad_ Input after sequence filling:
# batch_x
tensor([[1, 2, 3, 4],
[9, 0, 0, 0]])This out_ The pad result actually corresponds to the input after filling.