Acquisition, conversion, sorting and coincidence algorithm of animal PET
The project is mainly responsible for the type conversion of the read chnnel original data according to the location spectrum and energy spectrum to obtain the location information, time information and energy information, and sort them according to the time information. GPU merging sorting is mainly used for rapid sorting, so as to prepare for the later time compliance.
Input / output structure description
Input data description
1. typedef struct _DataFrameV2
2. {
3. uint8 nHeadAndDU;
4. uint8 nBDM;
5. uint8 nTime[8];
6. uint8 x;
7. uint8 y;
8. uint8 Energy[2];
9. int8 nTemperatureInt;
10. uint8 nTemperatureAndTail;
11. } DataFrameV2;
Output data description
1. typedef struct _SinglesStruct
2. {
3. uint32 globalCrystalIndex;
4. float energy;
5. double timevalue;
6. }SinglesStruct;
Conversion algorithm
Algorithm idea
It mainly realizes parallelization on the original CPU algorithm. By default, the energy is consistent. By default, one thread block starts 128 threads, and one thread processes 32 data for conversion (parameters can be adjusted).
1. If energy matching is performed, a variable will be used in each thread to record the number of energy matching data after type conversion of the elements processed by the current thread, which is shown as localTrue in the program; Then, using the characteristics of warp and calling the intraBlockScan function, you can get the number of data that can be matched by energy in all threads before each thread (including this thread) in this thread block, and then use the atomic operation atomicAdd to get the starting position of each thread block, which can be obtained through calculation, Each thread block needs to be placed at the starting position of the energy compliance element, which is shown as indexTrue in the program. Then the energy compliance data can be placed at its corresponding position in the dst, and the total data length * coinEnergyLength can be obtained.
2. If there is no energy matching, each data will not be filtered out, and the position in src will be taken out and placed in the corresponding position in dst.
Kernel function implementation
template <unsigned threadsConvert, unsigned elemsConvert>
__global__ void convertUdpToSinglesKernel(DataFrameV2* src, SinglesStruct* dst, SinglesStruct* dstBuffer, unsigned arrayLength, const CoinPetPara mCoinPetPara, uint8* d_m_pPositionTable, float* d_m_pEnergyCorrFactor, bool mIsCoinEnergy, unsigned* coinEnergyLength) {
unsigned offset, dataBlockLength;
calcDataBlockLength<threadsConvert, elemsConvert>(offset, dataBlockLength, arrayLength); // Find the offset and length of each thread block operation element
/* Position, Energy, Time corrections included */
unsigned m_nChannelNum = mCoinPetPara.m_nChannelNum;
// unsigned moduleNumX = mCoinPetPara.m_nModuleNumX;
unsigned moduleNumY = mCoinPetPara.m_nModuleNumY;
// unsigned moduleNumZ = mCoinPetPara.m_nModuleNumZ;
// unsigned blockNumX = mCoinPetPara.m_nBlockNumX;
unsigned blockNumY = mCoinPetPara.m_nBlockNumY;
unsigned blockNumZ = mCoinPetPara.m_nBlockNumZ;
// unsigned crystalNumX = mCoinPetPara.m_nCrystalNumX;
unsigned crystalNumY = mCoinPetPara.m_nCrystalNumY;
unsigned crystalNumZ = mCoinPetPara.m_nCrystalNumZ;
unsigned positionSize = mCoinPetPara.m_nPositionSize;
unsigned localTrue = 0;
unsigned scanTrue = 0;
for (unsigned tx = threadIdx.x; tx < dataBlockLength; tx += threadsConvert) {
/* Temporary structure to provide BDM and DU info */
// Temporary structure to provide BDM and DU information
TempSinglesStruct temp;
temp.globalBDMIndex = src[offset + tx].nBDM;
temp.localDUIndex = src[offset + tx].nHeadAndDU & (0x0F); // Why take and operation (truncate the first 8 bits and leave the last 8 bits)
/* Time convertion, from unsigned char[8] to double */
// Time conversion, from unsigned char[8] to double
uint64 nTimeTemp;
nTimeTemp = src[offset + tx].nTime[0];
for (unsigned i = 1; i <= 7; ++i) {
nTimeTemp <<= 8; // Convert eight 8-bit data into one 64 bit data
nTimeTemp |= src[offset + tx].nTime[i];
}
temp.timevalue = (double)nTimeTemp;
/* Position correction */
// Position correction (what is the structure here and what is being calculated)
uint32 originCrystalIndex = (d_m_pPositionTable + temp.globalBDMIndex * mCoinPetPara.m_nDUNum * mCoinPetPara.m_nPositionSize * mCoinPetPara.m_nPositionSize +
temp.localDUIndex * mCoinPetPara.m_nPositionSize * mCoinPetPara.m_nPositionSize)[src[offset + tx].X + src[offset + tx].Y * positionSize];
uint32 localX = originCrystalIndex % crystalNumZ;
uint32 localY = originCrystalIndex / crystalNumY;
temp.localCrystalIndex = localX + (crystalNumY - 1 - localY) * crystalNumZ;
/* Time correction */
/* Energy convertion, from unsigned char[2] to float */
uint32 nEnergyTemp;
nEnergyTemp = (src[offset + tx].Energy[0] << 8 | src[offset + tx].Energy[1]); // Combine the two energies
temp.energy = (float)nEnergyTemp;
/* Up to different system structure ||Changeable|| */
//uint32 nCrystalIdInRing = temp.globalBDMIndex % m_nChannelNum * m_nCrystalSize + (m_nCrystalSize - temp.localCrystalIndex / m_nCrystalSize -1);
//uint32 nRingId = temp.localDUIndex % m_nDUNum * m_nCrystalSize + temp.localCrystalIndex % m_nCrystalSize;
//uint32 nCrystalNumOneRing = m_nCrystalSize * m_nChannelNum;
uint32 nCrystalIdInRing = temp.globalBDMIndex % (m_nChannelNum * moduleNumY) * blockNumY * crystalNumY + temp.localDUIndex / blockNumZ * crystalNumY + temp.localCrystalIndex / crystalNumZ;
uint32 nRingId = temp.globalBDMIndex / (m_nChannelNum * moduleNumY) * blockNumZ * crystalNumZ + temp.localDUIndex % blockNumZ * crystalNumZ + temp.localCrystalIndex % crystalNumZ;
uint32 nCrystalNumOneRing = crystalNumY * blockNumY * m_nChannelNum;
dstBuffer[offset + tx].globalCrystalIndex = nCrystalIdInRing + nRingId * nCrystalNumOneRing;
/* Energy correction */
// Energy correction
dstBuffer[offset + tx].energy = temp.energy * (d_m_pEnergyCorrFactor + temp.globalBDMIndex * mCoinPetPara.m_nDUNum * mCoinPetPara.m_nCrystalSize * mCoinPetPara.m_nCrystalSize * 1000 +
temp.localDUIndex * mCoinPetPara.m_nCrystalSize * mCoinPetPara.m_nCrystalSize * 1000 +
temp.localCrystalIndex * 1000)[int(floor(temp.energy / 10))];
dstBuffer[offset + tx].timevalue = temp.timevalue;
// Here we need to filter and merge energy
// TODO: THE RIGHT PLACE FOR COIN ENERGY!
// Calculate the number of elements whose energy meets the requirements in the elements operated by each thread
localTrue += coinEnergyKernel(dstBuffer[offset + tx].energy, mCoinPetPara);
}
// The operation is different for each thread block
// Get the number of TRUE elements in all threads before each thread (including this thread) in this thread block
scanTrue = intraBlockScan<threadsConvert>(localTrue);
__syncthreads();
__shared__ unsigned globalTrue;
if (threadIdx.x == (threadsConvert - 1)) // The last thread in each thread block. In this thread, scanLower stores the total number of elements less than pivots in this thread block
{
globalTrue = atomicAdd(coinEnergyLength, scanTrue); // Atomic operations must be carried out one by one
}
__syncthreads();
unsigned indexTrue = globalTrue + scanTrue - localTrue; // Each thread is smaller than the starting position of the pivots to be stored
for (unsigned tx = threadIdx.x; tx < dataBlockLength; tx += threadsConvert) // The merge operation is completed here
{
SinglesStruct temp = dstBuffer[offset + tx]; // Take out each element to be processed
if (coinEnergyKernel(temp.energy, mCoinPetPara))
{
dst[indexTrue++] = temp;
}
}
}
sort
GPU merging and sorting is mainly adopted, which is mainly divided into three steps:
1. Fill data (become an integer power of 2)
2. Local order
3. Global order
Algorithm flow
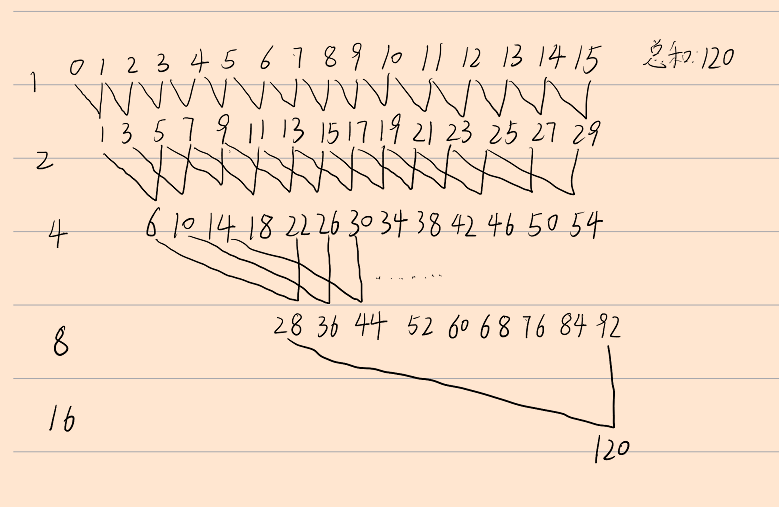
1. If the data length is not the whole power of 2, it is necessary to expand the data length to the whole power of the next 2 and fill the maximum value, which is more convenient for subsequent operations and fill the data in parallel.
2. Then make the data locally ordered, call the runMergeSortKernel function to make the data locally ordered, calculate the position of the current element in another piece of data respectively, and add the current position to get the position where it should be placed. In order to prevent position duplication, the data in one piece looks for the position smaller than the current element in the other piece, If the data in another block is not less than the position of the current element in this block, we can finally get locally ordered data. In the code, the default is every 1024 data in order.
3. Finally, let the locally ordered parts merge gradually, mainly to generate multiple blocks. Each block takes an endpoint value, and the default interval between blocks is 256. The endpoint value of each block is responsible for finding the position in another data to be merged, and then merge the elements in the block according to the same idea as above, and finally get completely ordered data.
code implementation
External frame:
void parallelMergeSort(SinglesStruct* dst, SinglesStruct* dstBuffer, unsigned arrayLength) {
unsigned* d_ranksEven = NULL;
unsigned* d_ranksOdd = NULL;
unsigned elemsPerThreadBlock = THREADS_MERGESORT * ELEMS_MERGESORT;
unsigned arrayLenRoundedUp = max(nextPowerOf2(arrayLength), elemsPerThreadBlock);
unsigned ranksLength = (arrayLenRoundedUp - 1) / SUB_BLOCK_SIZE + 1; // Find the number of sub blocks
cudaError_t error;
error = cudaMalloc((void**)&d_ranksEven, 2 * ranksLength * sizeof(*d_ranksEven));
checkCudaError(error);
error = cudaMalloc((void**)&d_ranksOdd, 2 * ranksLength * sizeof(*d_ranksOdd));
checkCudaError(error);
unsigned sortedBlockSize = THREADS_MERGESORT * ELEMS_MERGESORT;
unsigned lastPaddingMergePhase = log2((double)(sortedBlockSize)); // Calculation consolidation phase
unsigned arrayLenPrevPower2 = previousPowerOf2(arrayLength);
addPadding(dst, dstBuffer, arrayLength); // Both arrays are filled to the power of 2 (which may lead to out of bounds)
runMergeSortKernel(dst, arrayLength); // The data is locally ordered and the databuffer is out of order. The second step is to order every 1024 elements
//Step 3
while (sortedBlockSize < arrayLength)
{
SinglesStruct* temp = dst;
dst = dstBuffer;
dstBuffer = temp;
lastPaddingMergePhase = copyPaddedElements( // Judge whether the remaining parts need to be sorted, if so, whether data transfer should be carried out, and record the last stage in which the remaining parts participated in sorting
dst + arrayLenPrevPower2, dstBuffer + arrayLenPrevPower2,
arrayLength, sortedBlockSize, lastPaddingMergePhase
);
runGenerateRanksKernel(dstBuffer, d_ranksEven, d_ranksOdd, arrayLength, sortedBlockSize); //Generate blocks with records
runMergeKernel(dstBuffer, dst, d_ranksEven, d_ranksOdd, arrayLength, sortedBlockSize); //Merge in order
sortedBlockSize *= 2;
}
error = cudaFree(d_ranksEven);
checkCudaError(error);
error = cudaFree(d_ranksOdd);
checkCudaError(error);
}
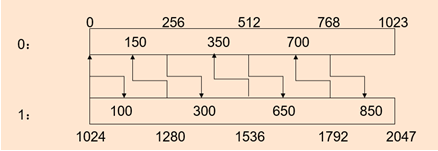
Generate the position kernel function of each block with records:
template <unsigned subBlockSize>
__global__ void generateRanksKernel(SinglesStruct* data, unsigned* ranksEven, unsigned* ranksOdd, unsigned sortedBlockSize)
{
unsigned subBlocksPerSortedBlock = sortedBlockSize / subBlockSize; // How many sub blocks is each ordered array divided into
unsigned subBlocksPerMergedBlock = 2 * subBlocksPerSortedBlock; // The total number of sub blocks of two merged sorted arrays
// Find the endpoint value to process
SinglesStruct sampleValue = data[blockIdx.x * (blockDim.x * subBlockSize) + threadIdx.x * subBlockSize]; // Note that a thread looks for an endpoint
unsigned rankSampleCurrent = blockIdx.x * blockDim.x + threadIdx.x; // Endpoint number
unsigned rankSampleOpposite;
// Find the sequence of the endpoint number (sub block) and its corresponding sequence
unsigned indexBlockCurrent = rankSampleCurrent / subBlocksPerSortedBlock; // Sequence corresponding to endpoint number
unsigned indexBlockOpposite = indexBlockCurrent ^ 1; // Corresponding sequence to be processed
// Find which sub block of the corresponding sequence this endpoint value is in
if (indexBlockCurrent % 2 == 0)
{
rankSampleOpposite = binarySearchInclusive<subBlockSize>( // Binary search with stride
data, sampleValue, indexBlockOpposite * sortedBlockSize, // Find the location of the endpoint in another sequence
indexBlockOpposite * sortedBlockSize + sortedBlockSize - subBlockSize
);
rankSampleOpposite = (rankSampleOpposite - sortedBlockSize) / subBlockSize; // relative position
}
else
{
rankSampleOpposite = binarySearchExclusive<subBlockSize>(
data, sampleValue, indexBlockOpposite * sortedBlockSize,
indexBlockOpposite * sortedBlockSize + sortedBlockSize - subBlockSize
);
rankSampleOpposite /= subBlockSize;
}
// Calculate the sample index within the merged block
unsigned sortedIndex = rankSampleCurrent % subBlocksPerSortedBlock + rankSampleOpposite; // Block number
// Calculates the position of the sample in the current and relative sorting blocks
unsigned rankDataCurrent = (rankSampleCurrent * subBlockSize % sortedBlockSize) + 1; // Relative position in current sequence + 1
unsigned rankDataOpposite;
// Calculate the sub block index within the relatively sorted block (the search scope is reduced here)
unsigned indexSubBlockOpposite = sortedIndex % subBlocksPerMergedBlock - rankSampleCurrent % subBlocksPerSortedBlock - 1;
unsigned indexStart = indexBlockOpposite * sortedBlockSize + indexSubBlockOpposite * subBlockSize + 1; // Do not take endpoint value
unsigned indexEnd = indexStart + subBlockSize - 2;
if ((int)(indexStart - indexBlockOpposite * sortedBlockSize) >= 0)
{
if (indexBlockOpposite % 2 == 0) // Itself is an odd sequence
{
rankDataOpposite = binarySearchExclusive( // Binary search location
data, sampleValue, indexStart, indexEnd // The last position after the condition is satisfied (this ensures that it can also be satisfied when there are two identical numbers in the two sequences)
);
}
else // Itself is an even sequence
{
rankDataOpposite = binarySearchInclusive(
data, sampleValue, indexStart, indexEnd // Locations that meet conditions
);
}
rankDataOpposite -= indexBlockOpposite * sortedBlockSize;
}
else
{
rankDataOpposite = 0;
}
// Corresponding end position of each sub block
if ((rankSampleCurrent / subBlocksPerSortedBlock) % 2 == 0) // Itself is an even sequence
{
ranksEven[sortedIndex] = rankDataCurrent; // An extra 1 is added here to ensure that at least one element participates in the merge
ranksOdd[sortedIndex] = rankDataOpposite;
}
else
{
ranksEven[sortedIndex] = rankDataOpposite;
ranksOdd[sortedIndex] = rankDataCurrent; // One more is added here
}
}
Merge kernel functions:
//Merges consecutive even and odd subblocks determined by the rank array.
template <unsigned subBlockSize>
__global__ void mergeKernel(
SinglesStruct* data, SinglesStruct* dataBuffer, unsigned* ranksEven, unsigned* ranksOdd, unsigned sortedBlockSize
)
{
__shared__ SinglesStruct tileEven[subBlockSize]; // The number of elements in each sub block shall not exceed 512
__shared__ SinglesStruct tileOdd[subBlockSize]; // The number of elements of odd and even sub blocks in the sub block shall not exceed 256
unsigned indexRank = blockIdx.y * (sortedBlockSize / subBlockSize * 2) + blockIdx.x; // Find the sub block corresponding to the current thread block
unsigned indexSortedBlock = blockIdx.y * 2 * sortedBlockSize; // The starting position of the operation of the sequence in which the sub block of the thread block operation is located
// Index adjacent even and odd blocks, which will be merged
unsigned indexStartEven, indexStartOdd, indexEndEven, indexEndOdd;
unsigned offsetEven, offsetOdd;
unsigned numElementsEven, numElementsOdd;
// Reads the START index of even and odd subblocks
// Each thread block operates at the same start and end positions
if (blockIdx.x > 0)
{
indexStartEven = ranksEven[indexRank - 1];
indexStartOdd = ranksOdd[indexRank - 1];
}
else
{
indexStartEven = 0;
indexStartOdd = 0;
}
// Reads the END index of even and odd subblocks
if (blockIdx.x < gridDim.x - 1)
{
indexEndEven = ranksEven[indexRank];
indexEndOdd = ranksOdd[indexRank];
}
else // The last thread block corresponding to the sequence
{
indexEndEven = sortedBlockSize; // Last sequence
indexEndOdd = sortedBlockSize;
}
numElementsEven = indexEndEven - indexStartEven; // Find the number of elements of the thread block operation
numElementsOdd = indexEndOdd - indexStartOdd;
// Read data from even ordered sub blocks
if (threadIdx.x < numElementsEven)
{
offsetEven = indexSortedBlock + indexStartEven + threadIdx.x;
tileEven[threadIdx.x] = data[offsetEven];
}
// Read data from odd ordered sub blocks
if (threadIdx.x < numElementsOdd)
{
offsetOdd = indexSortedBlock + indexStartOdd + threadIdx.x;
tileOdd[threadIdx.x] = data[offsetOdd + sortedBlockSize];
}
__syncthreads();
if (threadIdx.x < numElementsEven)
{
unsigned rankOdd = binarySearchInclusive(tileOdd, tileEven[threadIdx.x], 0, numElementsOdd - 1);
rankOdd += indexStartOdd;
// Find the position in the global array
dataBuffer[offsetEven + rankOdd] = tileEven[threadIdx.x];
}
if (threadIdx.x < numElementsOdd)
{
unsigned rankEven = binarySearchExclusive(tileEven, tileOdd[threadIdx.x], 0, numElementsEven - 1);
rankEven += indexStartEven;
dataBuffer[offsetOdd + rankEven] = tileOdd[threadIdx.x];
}
}
accord with
Coincidence mainly introduces the concept of time window. When there are only two events in a time window and the global crystal numbers of the two events are inconsistent, a coincidence pair can be generated, otherwise it will be eliminated!
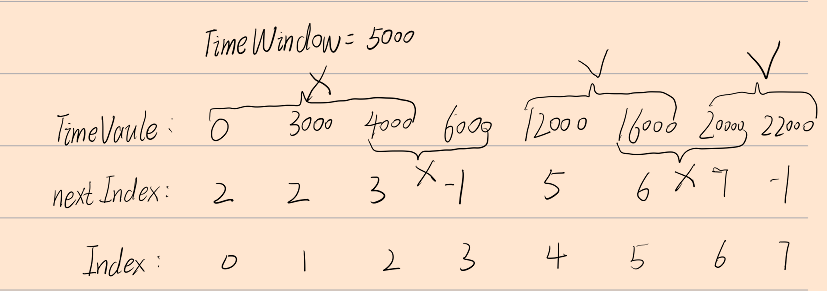
Algorithm idea
Here, I use four kernel functions to solve,
Step 1: find the location of the next event that can match the event and store it in nextIdex;
Step 2: filter to find the position where the time difference between the last two adjacent events is greater than the time window and record it as left. If it can be found, pos=left. If it cannot be found, pos=offset+tx is the starting point. This position is the starting point of the judgment. If nextIndex [pos] - pos > = 2, it indicates that there are multiple (> 2) events in the event window, which needs to be eliminated, Wipe all nextIndex within this range to - 1, indicating that pairing cannot be performed. If nextIndex[pos]-pos==1, it means that the event at pos position can be paired with pos+1, then wipe nextIndex[pos+1] to - 1; Finally, only the element nextIndex that can be paired has meaningful values, and all that cannot be paired are - 1;
The third step is pairing, and the intraBlockScan function is also used to calculate the location;
Step 4, each thread obtains its storage location, places data, and completes the compliance operation!
Step 1 code implementation:
inline __device__ int searchIndex(SinglesStruct* data, unsigned curIndex, unsigned arrayLength)
{
unsigned next = curIndex + 1;
while (next < arrayLength && data[next].timevalue - data[curIndex].timevalue <= TIMEWINDOW) { ++next; }
return next == curIndex + 1 ? -1 : next - 1;
}
inline __global__ void CoinTimeKernel(SinglesStruct* data, int* nextIndex, unsigned arrayLength) {
unsigned offset, dataBlockLength;
calcDataBlockLength<THREAD_NUM, THREAD_ELEM>(offset, dataBlockLength, arrayLength);
//Each thread finds the rightmost index that meets the time window and puts it in the nextIndex array
//Each thread finds the furthest satisfaction from it. The time window of each two elements is less than the time window
for (unsigned tx = threadIdx.x; tx < dataBlockLength; tx += THREAD_NUM) {
nextIndex[tx + offset] = searchIndex(data, offset + tx, arrayLength);
}
}
Step 2:
inline __device__ int leftIndex(SinglesStruct* data, unsigned curIndex)
{
int left = curIndex - 1;
unsigned pos = curIndex;
while (left >= 0 && data[curIndex].timevalue - data[left].timevalue <= TIMEWINDOW) { --curIndex; --left;}
return curIndex == pos ? -1 : curIndex;
}
inline __global__ void SelectKernel( SinglesStruct* data,int* nextIndex, unsigned* scanId, unsigned* globalLen, unsigned arrayLength) {
unsigned offset, dataBlockLength;
calcDataBlockLength<THREAD_NUM, THREAD_ELEM>(offset, dataBlockLength, arrayLength);
Find the leftmost starting point
for (unsigned tx = threadIdx.x; tx < dataBlockLength; tx += THREAD_NUM) {
int pos;
int left = leftIndex(data, tx + offset);
if (left != -1) {
pos = left; //Left starting point
}
else {
pos = tx + offset; //The starting point is itself
}
if (nextIndex[tx + offset] == -1 && pos != tx + offset) {
while (pos <= offset + tx) {
if ((nextIndex[pos] - pos) >= 2) {
int begin = pos;
int end = nextIndex[pos];
for (; begin <= end; ++begin) {
nextIndex[begin] = -1;
}
pos = begin;
}
else if ((nextIndex[pos] - pos) == 1) {
if (data[pos].globalCrystalIndex == data[nextIndex[pos]].globalCrystalIndex) {
nextIndex[pos] = -1;
}
nextIndex[++pos] = -1; //++The pos position is the second in the event pair
++pos;
}
else if (nextIndex[pos] == -1) {
++pos;
}
}
}
}
}
Step 3:
inline __global__ void FillDataKernel(SinglesStruct* d_SingleData, CoinStruct* d_CoinData, int* nextIndex, unsigned arrayLength, unsigned* newLength, unsigned* scanId, unsigned* globalLen) {
unsigned offset1, dataBlockLength1;
unsigned local1 = 0, scan1 = 0;
unsigned id = threadIdx.x + blockDim.x * blockIdx.x;
__shared__ unsigned global1;
unsigned index = threadIdx.x + blockDim.x * blockIdx.x;
if (index * THREAD_ELEM < arrayLength) {
offset1 = index * THREAD_ELEM;
dataBlockLength1 = offset1 + THREAD_ELEM <= arrayLength ? THREAD_ELEM : arrayLength - offset1; //Special treatment last piece
}
else {
return;
}
for (unsigned tx = 0; tx < dataBlockLength1; ++tx) {
if (nextIndex[tx + offset1] != -1) {
local1++;
}
}
__syncthreads();
scan1 = intraBlockScan<THREAD_NUM>(local1);
__syncthreads();
if (threadIdx.x == THREAD_NUM - 1 || offset1 + dataBlockLength1 == arrayLength) {
atomicAdd(newLength, scan1);
//globalPos[blockIdx.x] = atomicAdd(newLength, scan1);
globalLen[blockIdx.x] = scan1;
}
__syncthreads();
scanId[id] = scan1 - local1;
}
Step 4:
inline __global__ void CorrectPosKernel(SinglesStruct* d_SingleData, CoinStruct* d_data, unsigned* newLength, unsigned* scanId, unsigned* globalLen, unsigned arrayLength, int* nextIndex) {
unsigned offset1, dataBlockLength1;
unsigned global = 0;
unsigned index = threadIdx.x + blockDim.x * blockIdx.x;
if (index * THREAD_ELEM < arrayLength) {
offset1 = index * THREAD_ELEM;
dataBlockLength1 = offset1 + THREAD_ELEM <= arrayLength ? THREAD_ELEM : arrayLength - offset1; //Special treatment last piece
}
else {
return;
}
for (int i = 0; i < blockIdx.x; ++i) {
global += globalLen[i];
}
unsigned localBegin = global + scanId[index];
for (unsigned tx = 0; tx < dataBlockLength1; ++tx) {
if (nextIndex[tx + offset1] != -1) {
d_data[localBegin].nCoinStruct[0] = d_SingleData[tx + offset1];
d_data[localBegin++].nCoinStruct[1] = d_SingleData[tx + offset1 + 1];
}
}
}
Important kernel function
calcDataBlockLength
Fuc: calculate the position offset of each thread and the number of elements processed. Special processing is required for the last block
template <unsigned numThreads, unsigned elemsThread>
inline __device__ void calcDataBlockLength(unsigned& offset, unsigned& dataBlockLength, unsigned arrayLength)
{
unsigned elemsPerThreadBlock = numThreads * elemsThread; // Calculate the amount of data to be processed by each thread block
offset = blockIdx.x * elemsPerThreadBlock;
dataBlockLength = offset + elemsPerThreadBlock <= arrayLength ? elemsPerThreadBlock : arrayLength - offset; // Special handling of the last thread block
}
intraBlockScan
Func: calculate the total number of qualified elements in this thread block, which needs to be used with intraWarpScan.
General flow of the algorithm: val is the number of elements that meet the requirements of each thread. Using the nature of forming a warp every 32 threads, find the position of the thread in the warp, and then use intraWarpScan to get the sum of the number of all elements before this position in each warp, That is, the last thread in each warp records the number of all data that meet the requirements in this warp, and then the first few locations can be used to store the total number of elements that meet the requirements in each warp. For example, scanTile[0] stores the total number of elements that meet the requirements in the first warp, scanTile[1] stores the total number of elements that meet the requirements in the second warp, etc, Then perform similar operations on the previously stored data. Then, scanTile[0]=0, scanTile[1] = the number of total elements that meet the requirements in the first warp, scanTile[2] = the number of total elements that meet the requirements in the first warp + the number of total elements that meet the requirements in the second warp, and so on. The final return value is before the thread (including the current thread) The number of elements that meet the requirements. If this thread is the last thread in the block, its return value is the number of elements that meet the requirements in the whole block!
template <unsigned blockSize>
inline __device__ unsigned intraBlockScan(unsigned val) {
__shared__ unsigned scanTile[blockSize * 2];
unsigned warpIdx = threadIdx.x / WARP_SIZE;
unsigned laneIdx = threadIdx.x & (WARP_SIZE - 1); // Thread index inside warp
unsigned warpResult = intraWarpScan<blockSize>(scanTile, val);
__syncthreads();
if (laneIdx == WARP_SIZE - 1) // Get the sum of 32 values and put them in the corresponding warpIdx
{
scanTile[warpIdx] = warpResult + val;
}
__syncthreads();
if (threadIdx.x < WARP_SIZE) // Operate with only one of the warp s
{
scanTile[threadIdx.x] = intraWarpScan<blockSize / WARP_SIZE>(scanTile, scanTile[threadIdx.x]);
}
__syncthreads();
return warpResult + scanTile[warpIdx] + val;
}
intraWarpScan
Func: calculate the number of elements that meet the requirements before (excluding) the thread in this Warp
template <unsigned blockSize>
inline __device__ unsigned intraWarpScan(volatile unsigned* scanTile, unsigned val) {
unsigned index = 2 * threadIdx.x - (threadIdx.x & (min(blockSize, WARP_SIZE) - 1));
scanTile[index] = 0; // Set the previous column to zero
index += min(blockSize, WARP_SIZE);
scanTile[index] = val;
if (blockSize >= 2)
{
scanTile[index] += scanTile[index - 1];
}
if (blockSize >= 4)
{
scanTile[index] += scanTile[index - 2];
}
if (blockSize >= 8)
{
scanTile[index] += scanTile[index - 4];
}
if (blockSize >= 16)
{
scanTile[index] += scanTile[index - 8];
}
if (blockSize >= 32)
{
scanTile[index] += scanTile[index - 16];
}
// Combine the values of multiple elements
return scanTile[index] - val;
}
Similar to Reduce solution: