catalogue
Experimental environment
Experimental environment: 1,win10,vmwrokstation Virtual machine; 2,k8s Cluster: 3 sets centos7.6 1810 Virtual machine, 1 master node,2 individual node node k8s version: v1.22.2 containerd://1.5.5
Experimental software
Link: https://pan.baidu.com/s/1CAC9j5yU-sg-aDfLPYVflg?pwd=b3jp
Extraction code: b3jp
2022.2.19-40. Topological distribution constraints - experimental code

1. Pod Topology Distribution constraints
⚠️
This is a little complicated to understand;
This may not be used much, but if you want to carry out some fine-grained control, it is still very good to use this;
In k8s cluster scheduling, affinity related concepts essentially control how pods are scheduled – stacked or fragmented.
podAffinity and podAntiAffinity control the distribution of Pod in different topological domains.
Pod affinity can schedule countless pods to a specific topology domain, which is the embodiment of stacking;
podAntiAffinity can control that there is only one Pod in a topology domain, which is the embodiment of fragmentation;
However, these two situations are extreme and can not achieve the ideal effect in many scenarios. For example, in order to achieve disaster recovery and high availability, it is difficult to distribute the business Pod evenly in different availability areas as much as possible.
The PodTopologySpread (Pod Topology Distribution constraint) feature is proposed to provide finer control over the scheduling distribution of Pod, so as to improve service availability and resource utilization. PodTopologySpread is controlled by the EvenPodsSpread feature gate in V1 Version 16 was released for the first time and was released in V1 Version 18 enters the beta phase and is enabled by default.
2. Usage specification
Add a topologySpreadConstraints field in the Spec specification of Pod to configure Topology Distribution constraints, as shown below:
spec:
topologySpreadConstraints:
- maxSkew: <integer> #This attribute is not so direct to understand...; Inclination;
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
Since this new field is added at the Pod spec level, the PodTopologySpread function can also be used for higher-level controls (Deployment, daemon set, stateful set).
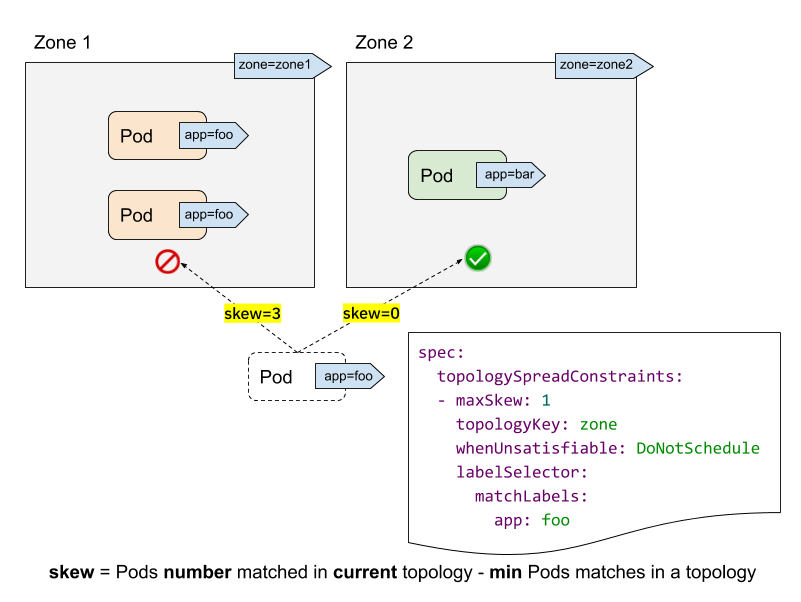
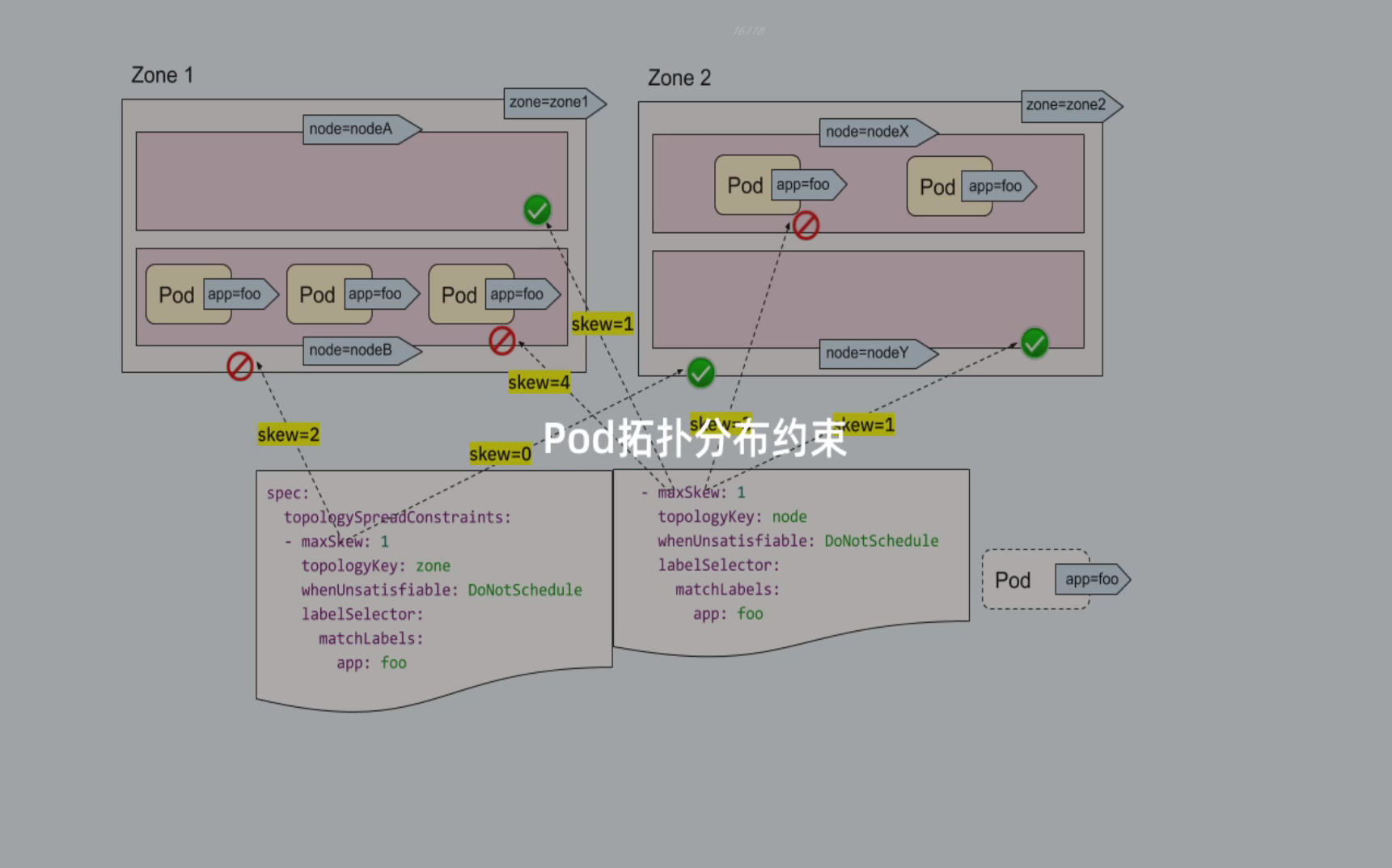
Let's understand the meaning and function of each field in topologySpreadConstraints in combination with the above figure:
- labelSelector: used to find matching pods. We can calculate the number of pods matching the label selector in each topology field. In the above figure, if the label selector is app:foo, then the number of matches in zone1 is 2 and the number of matches in zone2 is 0.
- topologyKey: is the key of the Node label. If two Node labels have the same key and have the same value, they are in the same topology domain. In the above figure, if the topologyKey is specified as zone, the nodes with the label of zone=zone1 are divided into one topology domain, and the nodes with the label of zone=zone2 are divided into another topology domain.
- ⚠️ maxSkew: this attribute is not directly understood. It describes the maximum degree of uneven distribution of pods in different topology domains (specify the maximum allowable difference between matched pods in any two topology domains in the topology type). It must be greater than zero. Each topological domain has a skew value. The calculation formula is: skew[i] = number of matched pods in topological domain [i] - min {number of matched pods in other topological domains}. In the figure above, we create a new Pod with app=foo tag:
- If the Pod is scheduled to zone1, the skew value of the Node in zone1 becomes 3 and the skew value of the Node in zone2 becomes 0 (zone1 has 3 matching pods and zone2 has 0 matching pods)
- If the Pod is scheduled to zone2, the skew value of the Node in zone1 becomes 2, and the skew value of the Node in zone2 becomes 1(zone2 has a matching Pod, and the topology domain with the global minimum number of matching pods is zone2 itself), then it meets the constraint of maxSkew: 1 (the difference is 1)
- When unsatisfiable: describes what strategy to take if Pod does not meet the distribution constraints:
- DoNotSchedule (default) tells the scheduler not to schedule the Pod, so it can also be called hard policy;
- ScheduleAnyway tells the scheduler to score and sort according to the skew value of each Node and still schedule. Therefore, it can also be called soft strategy.
3. Single topology constraint
Suppose you have a 4-node cluster, in which three pods marked foo:bar are located in node1, node2 and node3 respectively:
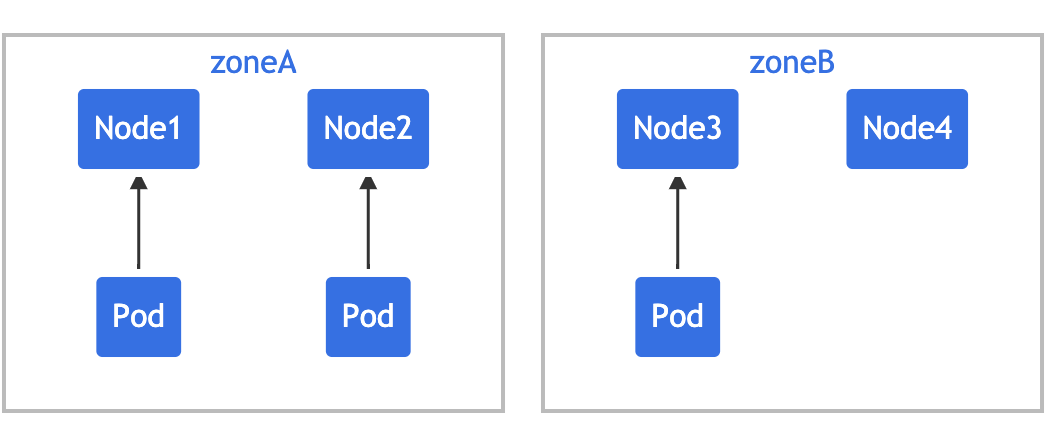
If you want the new Pod to be evenly distributed in the existing available area, you can set its constraints as follows:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1
topologyKey: zone means that uniform distribution will only be applied to nodes with a tag key value pair of zone: < any value >. When unsatisfiable: donotschedule tells the scheduler that if the new Pod does not meet the constraints, it is not schedulable. If the scheduler puts the new Pod into "zoneA", the Pods distribution will become [3,1], so the actual deviation is 2 (3 - 1), which violates the Convention of maxSkew: 1. In this example, the new Pod can only be placed on "zoneB":
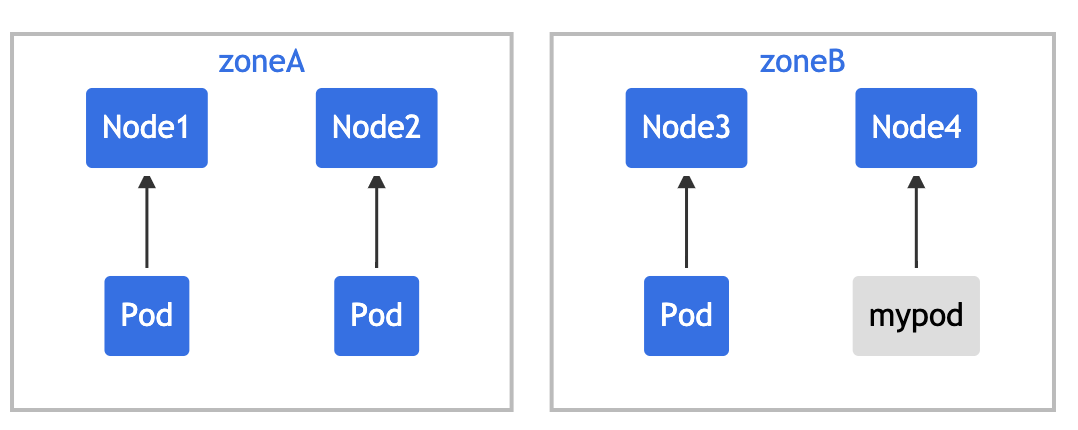
perhaps
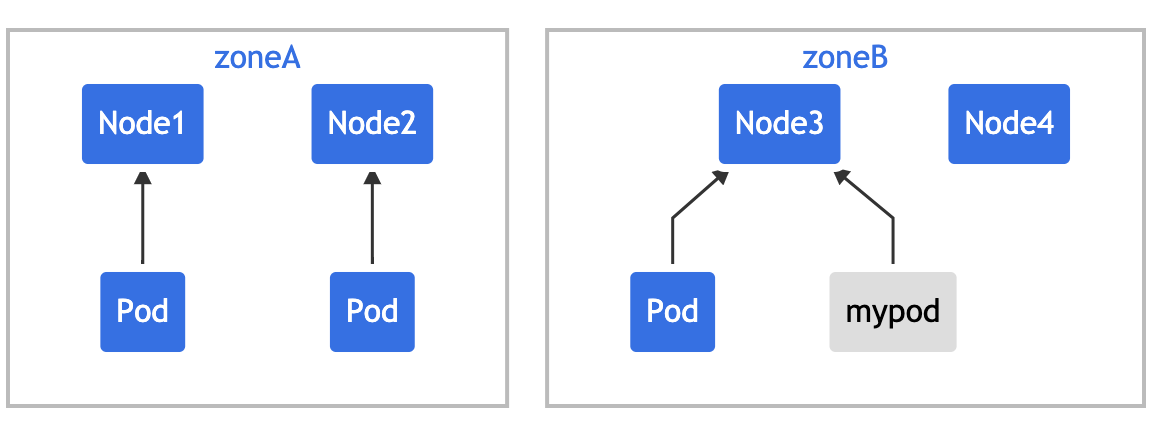
You can adjust Pod constraints to meet various requirements:
- Change maxSkew to a larger value, such as "2", so that the new Pod can also be placed on "zoneA".
- Change the topologyKey to "node" so that the Pod is evenly distributed over the nodes rather than areas. In the above example, if maxSkew remains "1", the incoming Pod can only be placed on "node4".
- Change whenUnsatisfiable: DoNotSchedule to whenUnsatisfiable: ScheduleAnyway to ensure that the new Pod can be scheduled.
4. Multiple topology constraints
The above is the case of a single Pod topological distribution constraint. The following example is based on the previous example to illustrate multiple Pod topological distribution constraints. Suppose you have a 4-node cluster, in which three pods marked foo:bar are located on node1, node2 and node3 respectively:
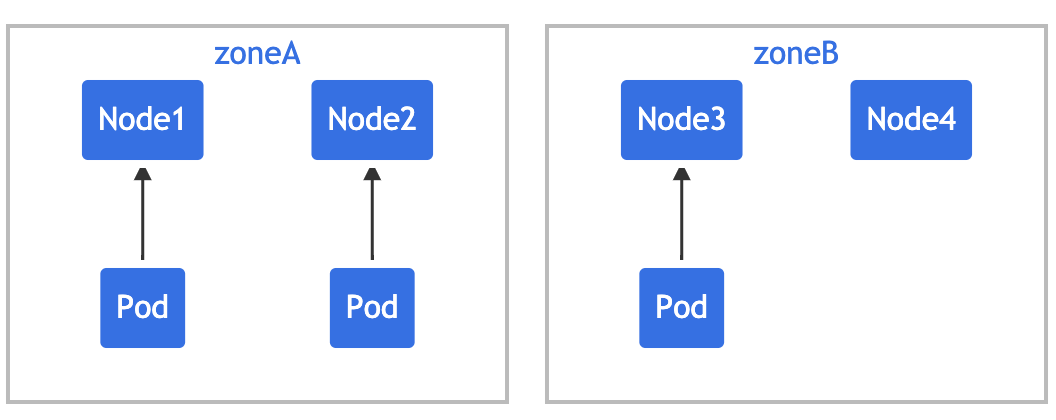
We can use two topologyspreadconstraints to control the distribution of Pod in the two dimensions of region and node:
# two-constraints.yaml
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1
In this case, in order to match the first constraint, the new Pod can only be placed in "zoneB"; In the second constraint, the new Pod can only be placed on "node4". When the results of the last two constraints are added together, the only feasible option is to place it on "node4".
🍀 There may be conflicts between multiple constraints. Suppose there is a 3-node cluster spanning two regions:
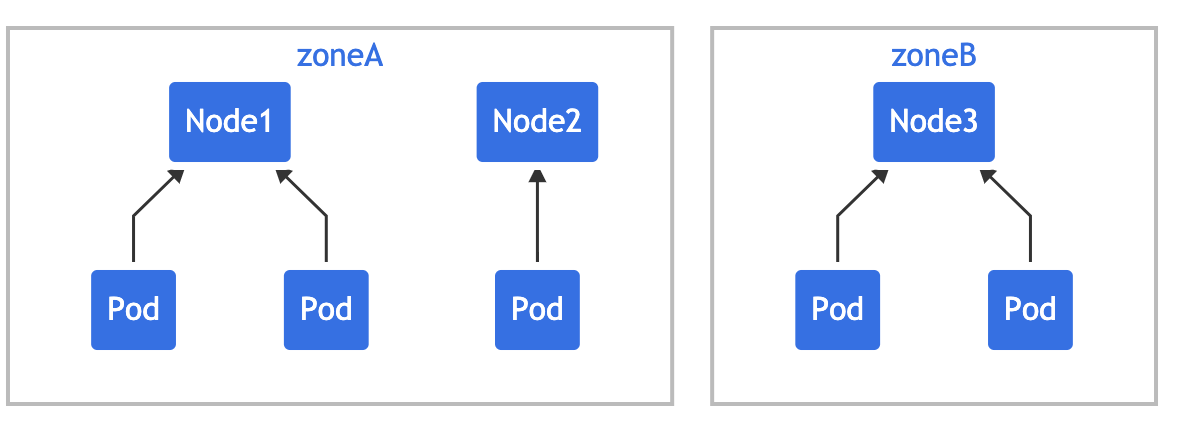
If you apply two constraints to a cluster Yaml, you will find that "mypod" is in Pending state. This is because in order to meet the first constraint, "mypod" can only be placed in "zoneB", while the second constraint requires that "mypod" can only be placed on "node2". Pod scheduling cannot meet these two constraints, so it conflicts.
To overcome this situation, you can add maxSkew or modify one of the constraints to use when unsatisfiable: schedule anyway.
5. Use with NodeSelector /NodeAffinity
After careful observation, you may find that we do not have a field similar to topologyValues to limit which topologies Pod will be scheduled to. By default, all nodes will be searched and grouped by topologyKey. Sometimes this may not be an ideal situation. For example, suppose there is a cluster with nodes marked env=prod, env=staging and env=qa. Now you want to place the Pod evenly into the qa environment across regions. Is it feasible?
The answer is yes. We can use it together with NodeSelector or NodeAffinity. PodTopologySpread can satisfy the propagation constraints between the nodes of the selector.
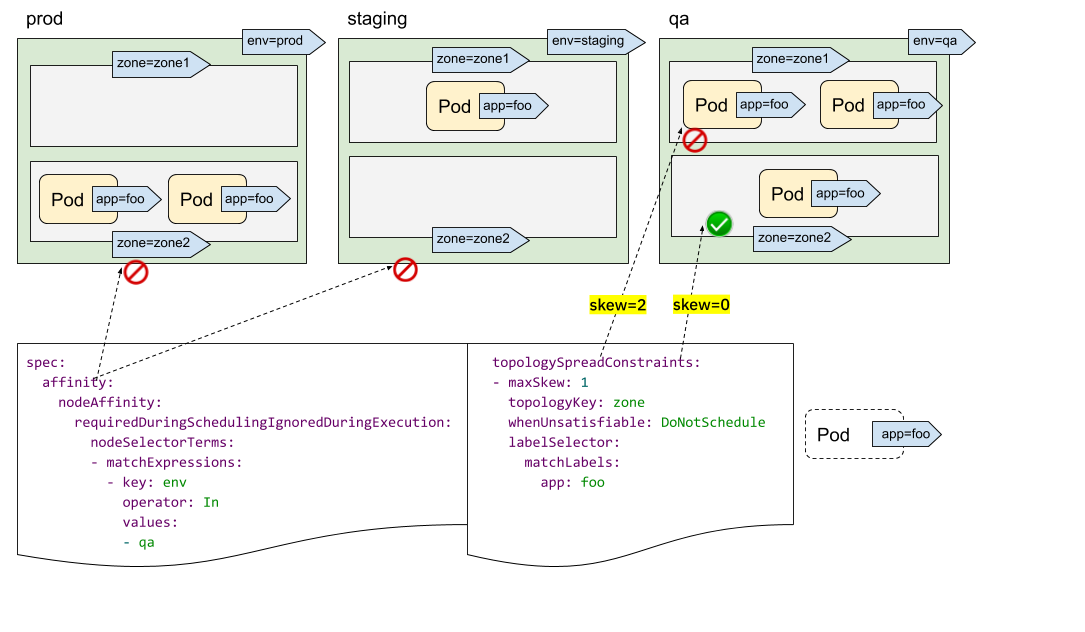
As shown in the figure above, we can specify spec.affinity Nodeaffinity limits the search scope to qa environment. Within this scope, Pod will be scheduled to an area that meets topologySpreadConstraints. Here, it can only be scheduled to the node with zone=zone2.
6. Cluster default constraints
In addition to setting the topology distribution constraint for a single Pod, you can also set the default Topology Distribution constraint for the cluster. The default Topology Distribution constraint is applied to the Pod only when the following conditions are met:
- Pod is not in its spec.topologySpreadConstraints set any constraints;
- Pod belongs to a service, replica controller, ReplicaSet or StatefulSet.
You can Scheduling profile Set the default constraint as part of the PodTopologySpread plug-in parameters. The constraint settings are consistent with the specifications in the previous Pod, except that the labelSelector must be empty. An example of configuration might look like this:
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
7. After class exercises
📍 Demonstrate the success of distributed function test with topology constraint
Now let's solve a problem left by the last lesson - if you want to run two (or more) Pod copies on each node (or some specified nodes), how to implement it?
🍀 Take our cluster as an example. In addition, the master node has a total of 3 nodes, and each node runs 2 replicas, which requires a total of 6 Pod replicas. To run on the master node, tolerance also needs to be added. If you only want to run 2 replicas on one node, you can use our Topology Distribution constraint for fine-grained control, The corresponding resource list is as follows:
#01-daemonset2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: topo-demo
spec:
replicas: 6
selector:
matchLabels:
app: topo
template:
metadata:
labels:
app: topo
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
name: ngpt
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: topo
Here, we need to focus on the configuration of topologySpreadConstraints. We choose to use kubernetes IO / hostname is a topological domain, which means that the three nodes are independent. maxSkew: 1 means that the maximum distribution unevenness is 1, so the only scheduling result is that each node runs two pods.
maxSkew=2 is equivalent to a soft strategy and is not desirable.
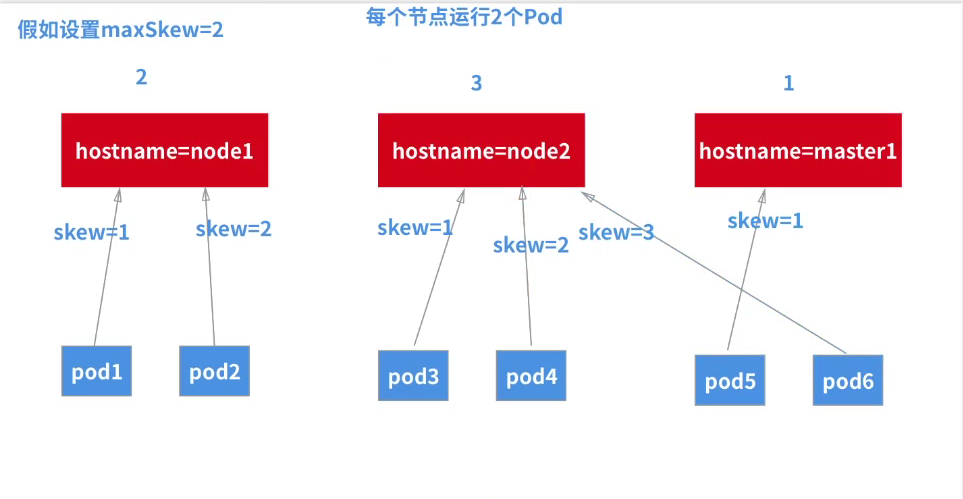
maxSkew=1 this satisfies the requirement.
maxSkew=1, which is scheduled down one round; (in general, maxSkew=1 should be commonly used)
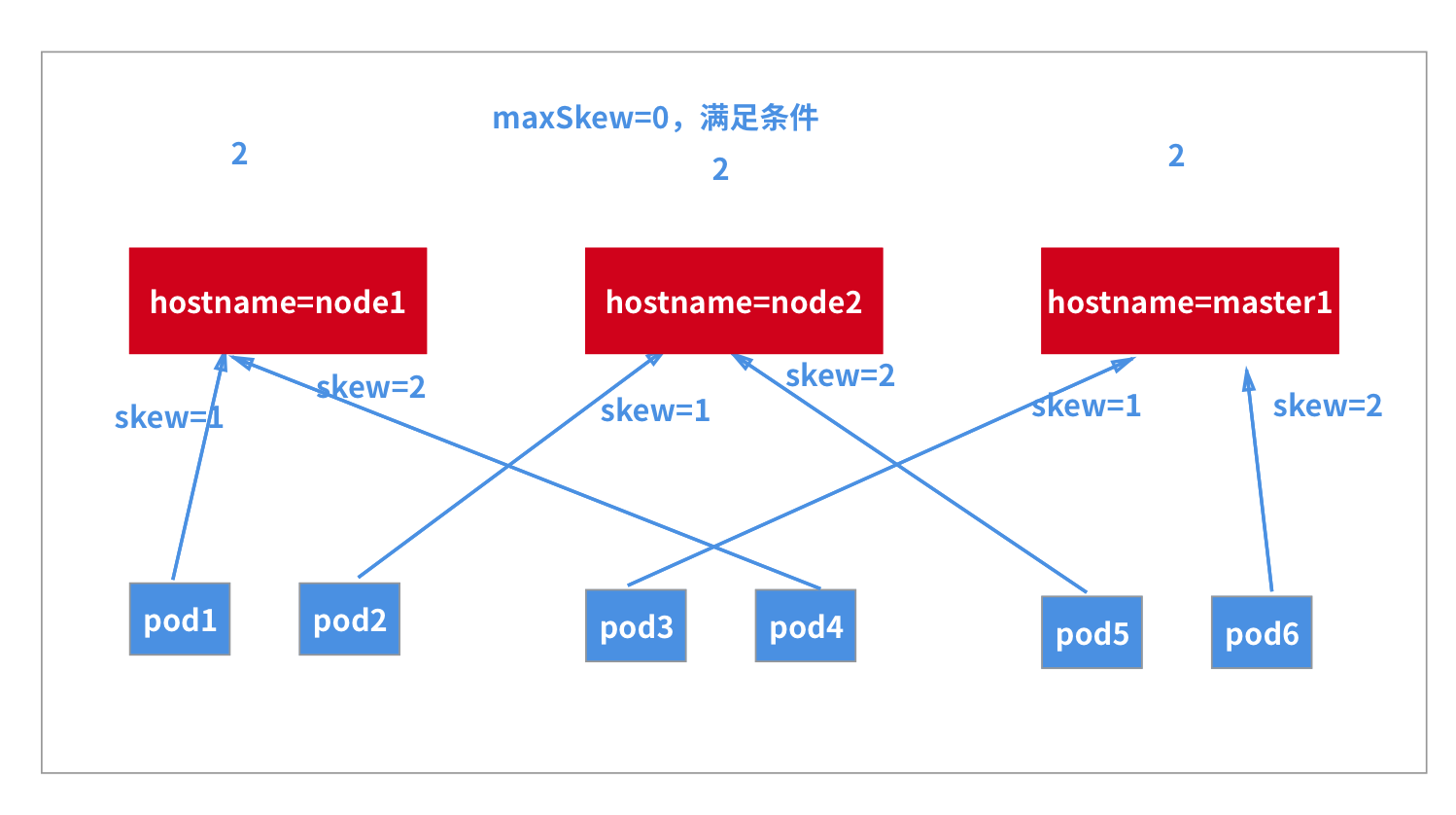
🍀 Directly create the above resources to verify:
$ kubectl apply -f 01-daemonset2.yaml deployment.apps/topo-demo created $ kubectl get po -l app=topo -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES topo-demo-6bbf65d967-ctf66 1/1 Running 0 43s 10.244.1.110 node1 <none> <none> topo-demo-6bbf65d967-gkqpx 1/1 Running 0 43s 10.244.0.16 master1 <none> <none> topo-demo-6bbf65d967-jsj4h 1/1 Running 0 43s 10.244.2.236 node2 <none> <none> topo-demo-6bbf65d967-kc9x8 1/1 Running 0 43s 10.244.2.237 node2 <none> <none> topo-demo-6bbf65d967-nr9b9 1/1 Running 0 43s 10.244.1.109 node1 <none> <none> topo-demo-6bbf65d967-wfzmf 1/1 Running 0 43s 10.244.0.17 master1 <none> <none>
We can see that it is in line with our expectations. There are 2 copies of Pod running on each node.
🍀 What if you need to run three copies of Pod on each node? You can also try to practice.
#02-daemonset.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: topo-demo2
spec:
replicas: 9
selector:
matchLabels:
app: topo2
template:
metadata:
labels:
app: topo2
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
name: ngpt1
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: topo2
Viewing phenomena:
hg@LAPTOP-G8TUFE0T:/mnt/c/Users/hg/Desktop/yaml/2022.2.19-40.Topological distribution constraints-Experimental code $ kubectl apply -f 02-daemonset.yaml deployment.apps/topo-demo2 created hg@LAPTOP-G8TUFE0T:/mnt/c/Users/hg/Desktop/yaml/2022.2.19-40.Topological distribution constraints-Experimental code $ kubectl get po -l app=topo2 -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES topo-demo2-87d77dbbd-25wbw 1/1 Running 0 53s 10.244.2.240 node2 <none> <none> topo-demo2-87d77dbbd-77gm8 1/1 Running 0 53s 10.244.1.113 node1 <none> <none> topo-demo2-87d77dbbd-97npc 1/1 Running 0 53s 10.244.0.20 master1 <none> <none> topo-demo2-87d77dbbd-fspcq 1/1 Running 0 53s 10.244.1.111 node1 <none> <none> topo-demo2-87d77dbbd-k5llk 1/1 Running 0 53s 10.244.1.112 node1 <none> <none> topo-demo2-87d77dbbd-pc24x 1/1 Running 0 53s 10.244.2.238 node2 <none> <none> topo-demo2-87d77dbbd-rdmwn 1/1 Running 0 53s 10.244.2.239 node2 <none> <none> topo-demo2-87d77dbbd-s4rjp 1/1 Running 0 53s 10.244.0.18 master1 <none> <none> topo-demo2-87d77dbbd-xrwmk 1/1 Running 0 53s 10.244.0.19 master1 <none> <none>
The experiment is over. 😘
About me
Theme of my blog: I hope everyone can make experiments with my blog, first do the experiments, and then understand the technical points in a deeper level in combination with theoretical knowledge, so as to have fun and motivation in learning. Moreover, the content steps of my blog are very complete. I also share the source code and the software used in the experiment. I hope I can make progress with you!
If you have any questions during the actual operation, you can contact me at any time to help you solve the problem for free:
-
Personal wechat QR Code: x2675263825 (shede), qq: 2675263825.

-
Personal blog address: www.onlyonexl.com cn
-
Personal WeChat official account: cloud native architect real battle

-
Personal csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
-
Personal dry goods 😘
name link 01 actual combat: create a king cloud note: typera + nut cloud + Alibaba cloud oss https://www.jianguoyun.com/p/DXS6qiIQvPWVCRiS0qoE 02 actual combat: customize the most beautiful typora theme skin in the universe https://www.jianguoyun.com/p/DeUK9u0QvPWVCRib0qoE vscode 03 https://www.jianguoyun.com/p/DZe8gmsQvPWVCRid0qoE 04 Chen Guo's happiness philosophy course https://www.jianguoyun.com/p/Db0kM7gQvPWVCRj2q6YE
last
Well, that's all for the topological distribution constraint experiment. Thank you for reading. Finally, paste the photo of my goddess. I wish you a happy life and a meaningful life every day. See you next time!
