Why do I need to reduce the load
In micro service clusters, the call link is perplexing. As a service provider, there is a mechanism to protect itself, which prevents the caller from calling himself down without any brain calls and ensuring the high availability of his services.
The most common protection mechanism is the current limiting mechanism. The premise of using the current limiter is to know the maximum number of concurrency it can handle. Generally, the maximum number of concurrency is obtained through pressure measurement before going online. Moreover, the current limiting parameters of each interface are different in the daily request process. At the same time, the system is constantly iterative, and its processing capacity often changes accordingly, It is very tedious to carry out pressure measurement before each line and adjust the current limiting parameters.
So is there a more concise current limiting mechanism that can achieve maximum self-protection?
What is adaptive load shedding
Adaptive load shedding can intelligently protect the service itself, and dynamically judge whether load shedding is required according to the system load of the service itself.
Design objectives:
- Ensure that the system does not collapse.
- Maintain the system throughput on the premise of system stability.
So the key is how to measure the load of the service itself?
Judging high load mainly depends on two indicators:
- Whether the cpu is overloaded.
- Whether the maximum concurrent number is overloaded.
When the above two points are met at the same time, it indicates that the service is in a high load state, and adaptive load shedding is carried out.
At the same time, it should also be noted that in high concurrency scenarios, the cpu load and concurrency number often fluctuate greatly. From the data, we call this phenomenon burr. Burr may cause the system to perform automatic load shedding frequently, so we generally obtain the average value of the index for a period of time to make the index smoother. In the implementation, it can accurately record the indicators in a period of time, and then directly calculate the average value, but it needs to occupy some system resources.
There is an algorithm in Statistics: exponential moving average, which can be used to estimate the local mean of variables, so that the update of variables is related to the historical value of a period of history. The average estimation can be realized without recording all historical local variables, which saves valuable server resources.
Principle of moving average algorithm It is very clear to refer to this article.
The variable V is recorded as Vt at time t, θ T is the value of variable V at time t, that is, Vt when the moving average model is not used= θ t. After using the moving average model, the update formula of Vt is as follows:
Vt=β⋅Vt−1+(1−β)⋅θt
- β = Vt at 0= θ t
- β = At 0.9, it is roughly equivalent to the past 10 months θ Average of t values
- β = At 0.99, it is roughly equivalent to the past 100 months θ Average of t values
code implementation
Next, let's look at the code implementation of go zero adaptive load shedding.
core/load/adaptiveshedder.go
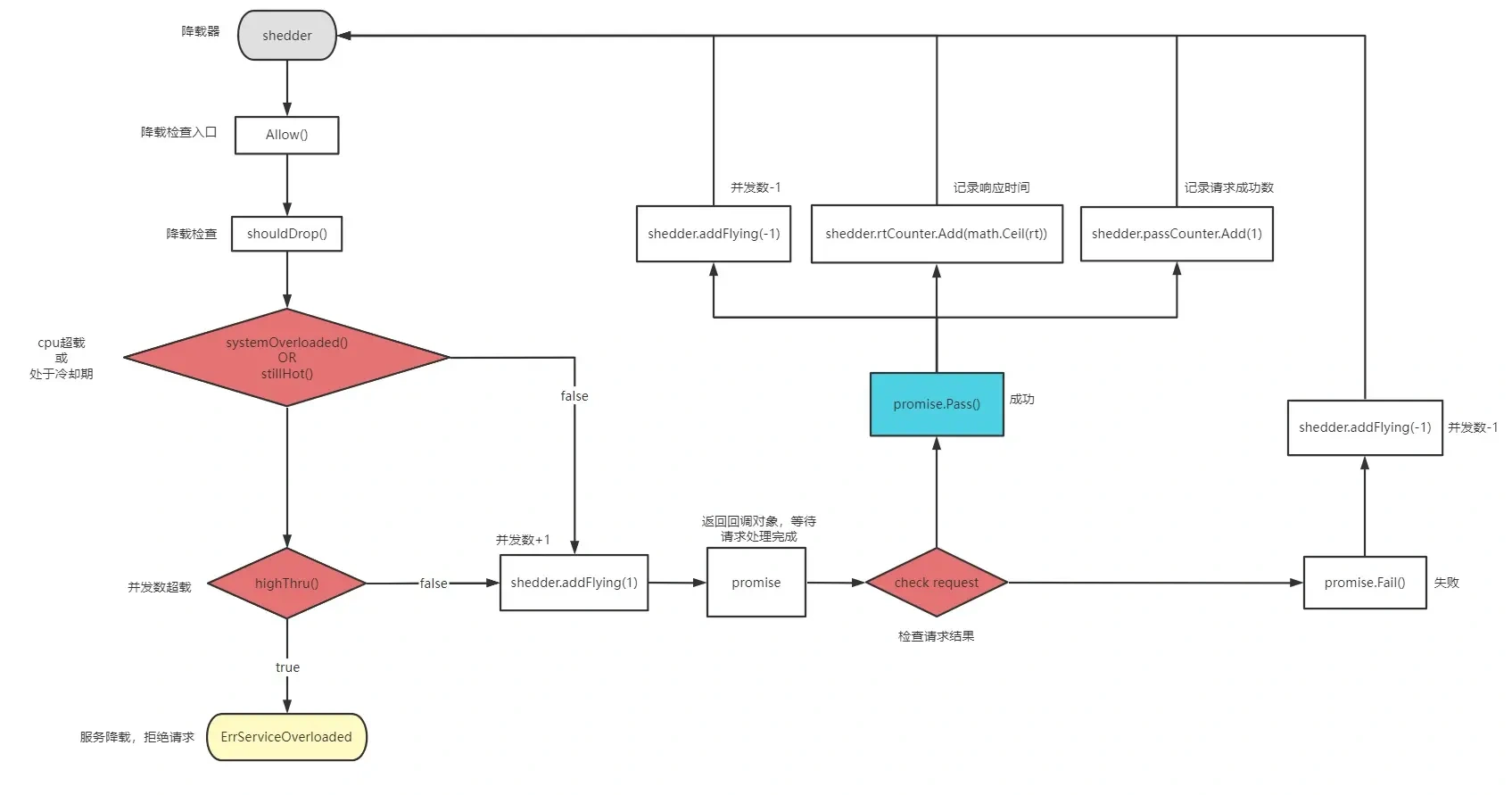
Definition of adaptive load shedding interface:
// Callback function
Promise interface {
// This function is called back when the request is successful
Pass()
// This function is called back when the request fails
Fail()
}
// Load shedding interface definition
Shedder interface {
// Load reduction inspection
// 1. If calling is allowed, you need to manually execute Promise.accept()/reject() to report the actual task structure
// 2. If the call is rejected, it will directly return err: Service overload error ErrServiceOverloaded
Allow() (Promise, error)
}The interface definition is very concise, which means that it is actually very simple to use. It exposes an 'Allow()(Promise,error).
Go zero usage example:
In the business, you only need to call this method to judge whether the load is reduced. If it is reduced, the process will be ended directly. Otherwise, the return value Promise can be used to callback the result according to the execution result.
func UnarySheddingInterceptor(shedder load.Shedder, metrics *stat.Metrics) grpc.UnaryServerInterceptor {
ensureSheddingStat()
return func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler) (val interface{}, err error) {
sheddingStat.IncrementTotal()
var promise load.Promise
// Check whether the load is reduced
promise, err = shedder.Allow()
// Reduce the load and record relevant logs and indicators
if err != nil {
metrics.AddDrop()
sheddingStat.IncrementDrop()
return
}
// Last callback execution result
defer func() {
// Execution failed
if err == context.DeadlineExceeded {
promise.Fail()
// Successful execution
} else {
sheddingStat.IncrementPass()
promise.Pass()
}
}()
// Execute business methods
return handler(ctx, req)
}
}Interface implementation class definition:
It mainly contains three types of attributes
- cpu load threshold: exceeding this value means that the cpu is in a high load state.
- Cooling period: if the load has been reduced before the service, it will enter the cooling period to prevent back and forth shaking caused by pressurization immediately before the load is reduced. Because it takes time to reduce the load, you should continue to check whether the number of concurrent requests exceeds the limit during the cooling period. If the limit is exceeded, you should continue to discard requests.
- Concurrency: the number of concurrency currently being processed, the average number of concurrency currently being processed, and the number of requests and response time in the latest period. The purpose is to calculate whether the number of concurrency currently being processed is greater than the maximum number of concurrency that the system can carry.
// option parameter mode
ShedderOption func(opts *shedderOptions)
// Optional configuration parameters
shedderOptions struct {
// Sliding time window size
window time.Duration
// Number of sliding time windows
buckets int
// cpu load threshold
cpuThreshold int64
}
// For adaptive load shedding structure, Shedder interface shall be realized
adaptiveShedder struct {
// cpu load threshold
// Higher than the critical value means that high load requires load shedding to ensure service
cpuThreshold int64
// How many barrels are there in 1s
windows int64
// Concurrent number
flying int64
// Sliding smoothing concurrency
avgFlying float64
// Spin lock, one load shedding shared by one service
// It must be locked when counting the number of requests currently being processed
// Lossless concurrency for improved performance
avgFlyingLock syncx.SpinLock
// Last rejection time
dropTime *syncx.AtomicDuration
// Have you been rejected recently
droppedRecently *syncx.AtomicBool
// Count the number of requests, and record the indicators in the latest period of time through the sliding time window
passCounter *collection.RollingWindow
// Response time statistics, record the indicators in the latest period of time through the sliding time window
rtCounter *collection.RollingWindow
}Adaptive load shedding constructor:
func NewAdaptiveShedder(opts ...ShedderOption) Shedder {
// To ensure code uniformity
// When the developer closes, it returns the default empty implementation to realize code unification
// Go zero adopts this design in many places, such as Breaker and log component
if !enabled.True() {
return newNopShedder()
}
// options mode sets optional configuration parameters
options := shedderOptions{
// Default statistics data in the last 5s
window: defaultWindow,
// The default number of barrels is 50
buckets: defaultBuckets,
// cpu load
cpuThreshold: defaultCpuThreshold,
}
for _, opt := range opts {
opt(&options)
}
// Calculate the interval time of each window. The default is 100ms
bucketDuration := options.window / time.Duration(options.buckets)
return &adaptiveShedder{
// cpu load
cpuThreshold: options.cpuThreshold,
// How many sliding window units are included in 1s
windows: int64(time.Second / bucketDuration),
// Last rejection time
dropTime: syncx.NewAtomicDuration(),
// Have you been rejected recently
droppedRecently: syncx.NewAtomicBool(),
// qps statistics, sliding time window
// Ignoring the currently writing window (bucket), incomplete time period may cause data exception
passCounter: collection.NewRollingWindow(options.buckets, bucketDuration,
collection.IgnoreCurrentBucket()),
// Response time statistics, sliding time window
// Ignoring the currently writing window (bucket), incomplete time period may cause data exception
rtCounter: collection.NewRollingWindow(options.buckets, bucketDuration,
collection.IgnoreCurrentBucket()),
}
}Load drop check (allow):
Check whether the current request should be discarded. The discarded service side needs to directly interrupt the request protection service, which also means that the load shedding takes effect and enters the cooling period. If it is released, return promise and wait for the business side to execute the callback function to perform indicator statistics.
// Load reduction inspection
func (as *adaptiveShedder) Allow() (Promise, error) {
// Check whether the request is discarded
if as.shouldDrop() {
// Set drop time
as.dropTime.Set(timex.Now())
// Recently drop ped
as.droppedRecently.Set(true)
// Return overload
return nil, ErrServiceOverloaded
}
// Number of requests being processed plus 1
as.addFlying(1)
// Here, a new promise object is returned for each allowed request
// promise holds the unload pointer object internally
return &promise{
start: timex.Now(),
shedder: as,
}, nil
}Check if shouldDrop() should be discarded:
// Should the request be discarded
func (as *adaptiveShedder) shouldDrop() bool {
// The current cpu load exceeds the threshold
// The service is in a cooling down period and should continue to check the load and try to discard the request
if as.systemOverloaded() || as.stillHot() {
// Check whether the concurrency being processed exceeds the maximum number of concurrencies that can currently be hosted
// If exceeded, the request is discarded
if as.highThru() {
flying := atomic.LoadInt64(&as.flying)
as.avgFlyingLock.Lock()
avgFlying := as.avgFlying
as.avgFlyingLock.Unlock()
msg := fmt.Sprintf(
"dropreq, cpu: %d, maxPass: %d, minRt: %.2f, hot: %t, flying: %d, avgFlying: %.2f",
stat.CpuUsage(), as.maxPass(), as.minRt(), as.stillHot(), flying, avgFlying)
logx.Error(msg)
stat.Report(msg)
return true
}
}
return false
}cpu threshold check systemOverloaded():
The cpu load calculation algorithm adopts the moving average algorithm to prevent burr. Sample every 250ms β It is 0.95, which is roughly equivalent to the average value of 20 cpu loads in history, and the time period is about 5s.
// Is the cpu overloaded
func (as *adaptiveShedder) systemOverloaded() bool {
return systemOverloadChecker(as.cpuThreshold)
}
// cpu check function
systemOverloadChecker = func(cpuThreshold int64) bool {
return stat.CpuUsage() >= cpuThreshold
}
// cpu sliding average
curUsage := internal.RefreshCpu()
prevUsage := atomic.LoadInt64(&cpuUsage)
// cpu = cpuᵗ⁻¹ * beta + cpuᵗ * (1 - beta)
// Moving average algorithm
usage := int64(float64(prevUsage)*beta + float64(curUsage)*(1-beta))
atomic.StoreInt64(&cpuUsage, usage)Check whether it is in cooling period stillHot:
Judge whether the current system is in the cooling period. If it is in the cooling period, continue to try to check whether to discard the request. The main purpose is to prevent the system from shaking back and forth due to increasing pressure immediately before the load is reduced during overload recovery. At this time, you should try to continue to discard the request.
func (as *adaptiveShedder) stillHot() bool {
// No requests have been dropped recently
// The service is normal
if !as.droppedRecently.True() {
return false
}
// Not in cooling period
dropTime := as.dropTime.Load()
if dropTime == 0 {
return false
}
// The cooling time is 1s by default
hot := timex.Since(dropTime) < coolOffDuration
// Not in cooling down period, normal processing request
if !hot {
// Reset drop record
as.droppedRecently.Set(false)
}
return hot
}Check the number of concurrencies currently being processed highThru():
Once the number of concurrent transactions currently processed > the upper limit of concurrent load, it will enter the load reduction state.
Why lock here? Because adaptive load shedding is used globally, in order to ensure the correctness of the average value of concurrency.
Why add a spin lock here? Because during concurrent processing, other goroutine execution tasks can not be blocked, and lock free concurrency is adopted to improve performance.
func (as *adaptiveShedder) highThru() bool {
// Lock
as.avgFlyingLock.Lock()
// Get moving average
// Update after each request
avgFlying := as.avgFlying
// Unlock
as.avgFlyingLock.Unlock()
// Maximum concurrent number of the system at this time
maxFlight := as.maxFlight()
// Is the number of concurrencies being processed and the average number of concurrencies greater than the maximum number of concurrencies in the system
return int64(avgFlying) > maxFlight && atomic.LoadInt64(&as.flying) > maxFlight
}How to get the number of concurrency being processed and the average number of concurrency?
The statistics of the number of concurrent transactions currently being processed are actually very simple. The number of concurrent transactions allowed each time is + 1. After the request is completed, you can call back - 1 through the promise object, and use the sliding average algorithm to solve the average number of concurrent transactions.
type promise struct {
// Request start time
// Statistics of request processing time
start time.Duration
shedder *adaptiveShedder
}
func (p *promise) Fail() {
// Request ended, number of requests currently being processed - 1
p.shedder.addFlying(-1)
}
func (p *promise) Pass() {
// Response time in milliseconds
rt := float64(timex.Since(p.start)) / float64(time.Millisecond)
// Request ended, number of requests currently being processed - 1
p.shedder.addFlying(-1)
p.shedder.rtCounter.Add(math.Ceil(rt))
p.shedder.passCounter.Add(1)
}
func (as *adaptiveShedder) addFlying(delta int64) {
flying := atomic.AddInt64(&as.flying, delta)
// After the request ends, count the concurrent requests currently being processed
if delta < 0 {
as.avgFlyingLock.Lock()
// Estimate the average number of requests for the current service in the recent period
as.avgFlying = as.avgFlying*flyingBeta + float64(flying)*(1-flyingBeta)
as.avgFlyingLock.Unlock()
}
}The current number of systems is not enough. We also need to know the upper limit of the number of concurrency that the current system can handle, that is, the maximum number of concurrency.
The number of requests and response time are realized by sliding window. For the implementation of sliding window, please refer to the article of adaptive fuse.
The maximum concurrent number of the current system = the maximum number of passes in the window unit time * the minimum response time in the window unit time.
// Calculate the maximum number of system concurrencies per second
// Maximum concurrent number = maximum requests (qps) * minimum response time (rt)
func (as *adaptiveShedder) maxFlight() int64 {
// windows = buckets per second
// maxQPS = maxPASS * windows
// minRT = min average response time in milliseconds
// maxQPS * minRT / milliseconds_per_second
// as.maxPass()*as.windows - Maximum QPS per bucket * number of buckets in 1s
// as.minRt()/1e3 - minimum average response time in all buckets of the window / 1000ms, here is to convert to seconds
return int64(math.Max(1, float64(as.maxPass()*as.windows)*(as.minRt()/1e3)))
}
// There are multiple buckets in the sliding time window
// Find the one with the most requests
// The time occupied by each bucket is internal ms
// qps refers to the number of requests within 1s. qps: maxPass * time.Second/internal
func (as *adaptiveShedder) maxPass() int64 {
var result float64 = 1
// Bucket with the most requests in the current time window
as.passCounter.Reduce(func(b *collection.Bucket) {
if b.Sum > result {
result = b.Sum
}
})
return int64(result)
}
// There are multiple buckets in the sliding time window
// Calculate the minimum average response time
// Because it is necessary to calculate the maximum concurrent number that the system can handle in a recent period of time
func (as *adaptiveShedder) minRt() float64 {
// The default is 1000ms
result := defaultMinRt
as.rtCounter.Reduce(func(b *collection.Bucket) {
if b.Count <= 0 {
return
}
// Average request response time
avg := math.Round(b.Sum / float64(b.Count))
if avg < result {
result = avg
}
})
return result
}reference material
Google BBR congestion control algorithm
Principle of moving average algorithm
Go zero adaptive load shedding
Project address
Welcome to go zero and star support us!
Wechat communication group
Focus on the "micro service practice" official account and click on the exchange group to get the community community's two-dimensional code.