1. Background
At present, AI algorithm development, especially training, is basically based on python. Mainstream AI computing frameworks such as TensorFlow and PyTorch provide rich Python interfaces. As a saying goes, life is short. I use python. However, because Python is a dynamic language, it is difficult to directly meet the real-time Serving requirements with high performance requirements due to the lack of mature JIT scheme for interpretation and execution, and the limited multi-core concurrency in computing intensive scenarios. In some scenarios with high performance requirements, it is still necessary to use C/C + + to solve them. However, if the algorithm students are required to use C + + to develop online reasoning services, the cost is very high, resulting in development efficiency and waste of resources. Therefore, if there is a portable method to combine python with some core code written in C + +, it can achieve the effect of ensuring both development efficiency and service performance. This paper mainly introduces the accelerated practice of pybind11 in Tencent advertising multimedia AI Python algorithm, as well as some experience summary in the process.
2. Industry programmes
2.1 original scheme
Python officially provides Python/C API, which can realize "writing Python Library in C language". First, experience the previous code:
static PyObject *
spam_system(PyObject *self, PyObject *args)
{
const char *command;
int sts;
if (!PyArg_ParseTuple(args, "s", &command))
return NULL;
sts = system(command);
return PyLong_FromLong(sts);
}It can be seen that the transformation cost is very high. All basic types must be manually changed to the binding type encapsulated by CPython interpreter. Therefore, it is not difficult to understand why the Python official website also recommends that you use third-party solution 1.
2.2 Cython
Python mainly connects Python and C to facilitate the writing of C extensions for Python. Python's compiler supports the conversion of Python code into C code, which can call Python/C API s. In essence, Python is python that contains C data types. At present, numpy of Python and TRPC Python framework of our factory are applied.
Disadvantages:
- It is necessary to manually implant Python's own syntax (cdef, etc.), and the cost of transplantation and reuse is high
- Other files need to be added, such as setup py,*. pyx to turn your Python code into high-performance C code
- There is doubt about the degree of support for C + +
2.3 SIWG
SIWG mainly solves the problem of interaction between other high-level languages and C and C + + languages, and supports more than a dozen programming languages, including common java, c#, javascript, Python, etc. Use * i file defines the interface, and then uses tools to generate cross language interaction code. However, due to the large number of supported languages, the performance on the Python side is not very good.
It is worth mentioning that TensorFlow also used SWIG to encapsulate Python interface in the early stage. Officially, TensorFlow has switched SIWG to pybind112 in 2019 due to problems such as poor performance, complex construction and obscure binding code.
2.4 Boost.Python
The Boost open source library widely used in C + + also provides Python binding function. In use, python API calls are simplified through macro definition and meta programming. However, the biggest disadvantage is that it needs to rely on a huge Boost library, and the burden of compilation and dependency is heavy. If it is only used to solve Python binding, it has a visual sense of anti-aircraft shelling mosquitoes.
2.5 pybind11
It can be understood as boost Python is the blueprint, which only provides a simplified version of Python & C + + binding function, compared with boost Python has many advantages in binary size and compilation speed. It supports C + + very well. Various new features are applied based on C++11. Maybe the suffix 11 of pybind11 is for this reason.
Pybind11 infers type information through introspection during C + + compilation, so as to minimize the complex template code when expanding Python modules, and realize the automatic conversion of common data types, such as STL data structure, smart pointer, class, function overload, instance method and so on. Among them, the function can receive and return the value of user-defined data type Pointer or reference.
characteristic:
- Lightweight and single function, focusing on providing C + + & Python binding, and concise interactive code
- It is well compatible with common C + + data types such as STL and Python libraries such as numpy, without manual conversion cost
- In the only header mode, no additional code generation is required. The binding relationship can be established at the compilation time to reduce the size of the binary
- Support the new features of C + +, overload and inherit C + +, and the debug method is convenient and easy to use
- Perfect official document support, applied to many well-known open source projects
“Talk is cheap, show me your code.” Three lines of code can quickly implement binding, and you deserve it:
PYBIND11_MODULE (libcppex, m) {
m.def("add", [](int a, int b) -> int { return a + b; });
}3. Adjust C++
3.1 start with GIL lock
GIL (Global Interpreter Lock) Global Interpreter Lock: only one thread is allowed to use the interpreter in a process at the same time, so that multi threads cannot really use multi-core. Because the thread holding the lock will automatically release the Gil lock when performing some waiting operations such as I/O-Intensive functions, multithreading is effective for I/O-Intensive services. However, for CPU intensive operations Because only one thread can actually perform calculation at a time, the impact on performance can be imagined.
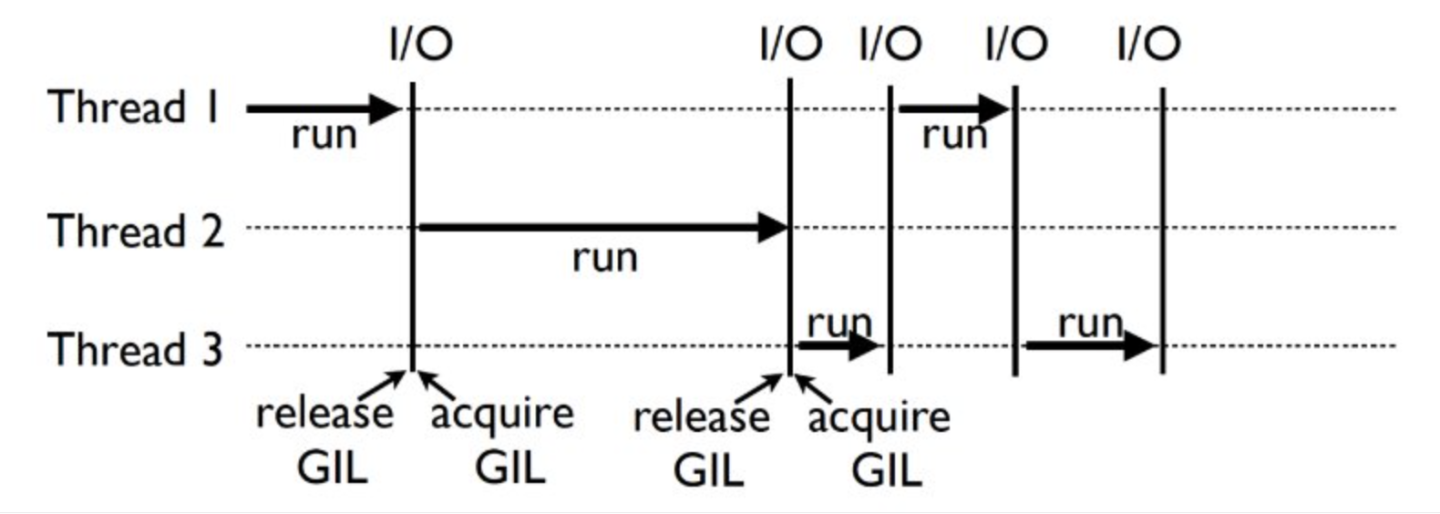
It must be noted here that GIL is not a defect of Python itself, but a thread safety lock introduced by CPython parser, which is currently used by Python by default. We generally say that there is a GIL lock in Python. In fact, it is only for the CPython interpreter. So if we can find a way to avoid GIL lock, can we have a good acceleration effect? The answer is yes. One solution is to use other interpreters, such as pypy, but the compatibility with mature C extension libraries is not good enough and the maintenance cost is high. Another solution is to encapsulate the computationally intensive code through C/C + + extensions and remove the GIL lock during execution.
3.2 Python algorithm performance optimization
pybind11 provides an interface to manually release the GIL lock on the C + + side. Therefore, we only need to transform part of the intensive computing code into C + + code, release / obtain the GIL lock before and after execution, and the multi-core computing power of Python algorithm will be unlocked. Of course, in addition to displaying the method of calling the interface to release the GIL lock, you can also switch the computing intensive code to other C + + threads for asynchronous execution in C + +, or avoid the GIL lock and use multi-core.
Taking 1 million calculations of spherical distance between cities as an example, the performance differences before and after C + + expansion are compared:
C + + end:
#include <math.h>
#include <stdio.h>
#include <time.h>
#include <pybind11/embed.h>
namespace py = pybind11;
const double pi = 3.1415926535897932384626433832795;
double rad(double d) {
return d * pi / 180.0;
}
double geo_distance(double lon1, double lat1, double lon2, double lat2, int test_cnt) {
py::gil_scoped_release release; // Release GIL lock
double a, b, s;
double distance = 0;
for (int i = 0; i < test_cnt; i++) {
double radLat1 = rad(lat1);
double radLat2 = rad(lat2);
a = radLat1 - radLat2;
b = rad(lon1) - rad(lon2);
s = pow(sin(a/2),2) + cos(radLat1) * cos(radLat2) * pow(sin(b/2),2);
distance = 2 * asin(sqrt(s)) * 6378 * 1000;
}
py::gil_scoped_acquire acquire; // Restore GIL lock before the end of C + + execution
return distance;
}
PYBIND11_MODULE (libcppex, m) {
m.def("geo_distance", &geo_distance, R"pbdoc(
Compute geography distance between two places.
)pbdoc");
}Python Caller:
import sys
import time
import math
import threading
from libcppex import *
def rad(d):
return d * 3.1415926535897932384626433832795 / 180.0
def geo_distance_py(lon1, lat1, lon2, lat2, test_cnt):
distance = 0
for i in range(test_cnt):
radLat1 = rad(lat1)
radLat2 = rad(lat2)
a = radLat1 - radLat2
b = rad(lon1) - rad(lon2)
s = math.sin(a/2)**2 + math.cos(radLat1) * math.cos(radLat2) * math.sin(b/2)**2
distance = 2 * math.asin(math.sqrt(s)) * 6378 * 1000
print(distance)
return distance
def call_cpp_extension(lon1, lat1, lon2, lat2, test_cnt):
res = geo_distance(lon1, lat1, lon2, lat2, test_cnt)
print(res)
return res
if __name__ == "__main__":
threads = []
test_cnt = 1000000
test_type = sys.argv[1]
thread_cnt = int(sys.argv[2])
start_time = time.time()
for i in range(thread_cnt):
if test_type == 'p':
t = threading.Thread(target=geo_distance_py,
args=(113.973129, 22.599578, 114.3311032, 22.6986848, test_cnt,))
elif test_type == 'c':
t = threading.Thread(target=call_cpp_extension,
args=(113.973129, 22.599578, 114.3311032, 22.6986848, test_cnt,))
threads.append(t)
t.start()
for thread in threads:
thread.join()
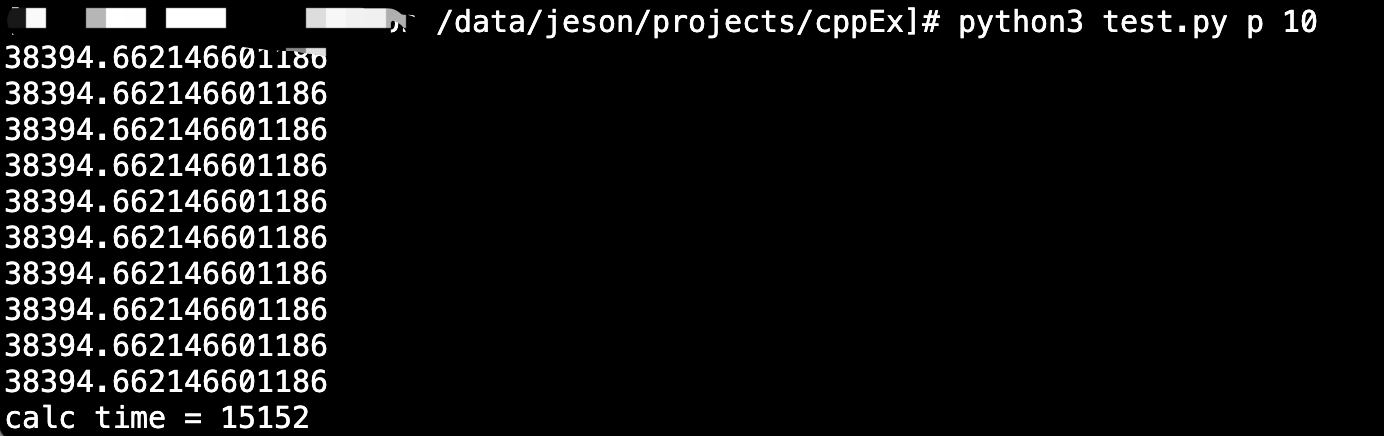
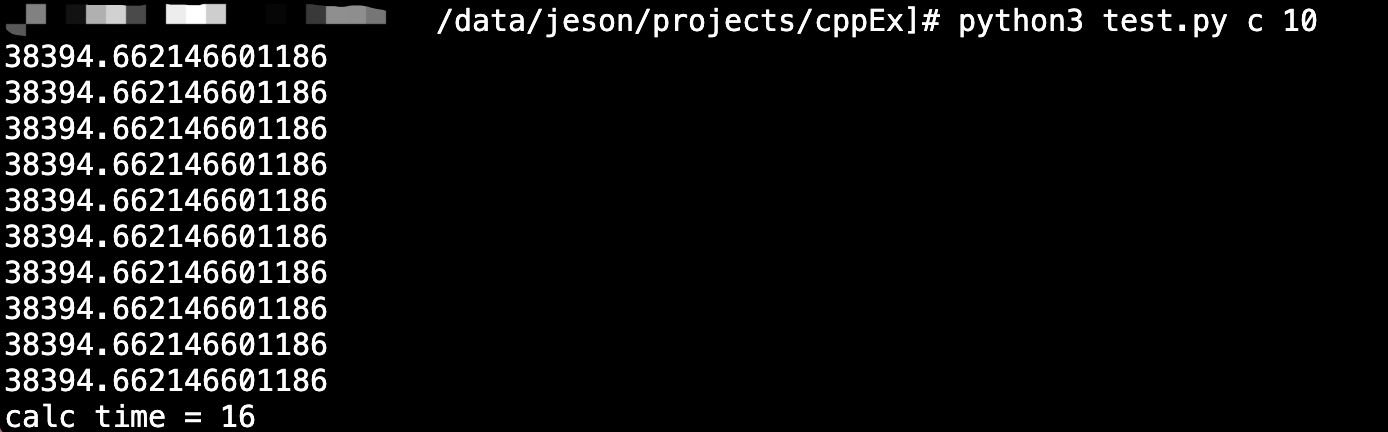
print('calc time = %d' % int((time.time() - start_time) * 1000))Performance comparison:
- Single thread time consumption: Python 1500ms, C++ 8ms

- 10 thread time consumption: Python 15152ms, C++ 16ms
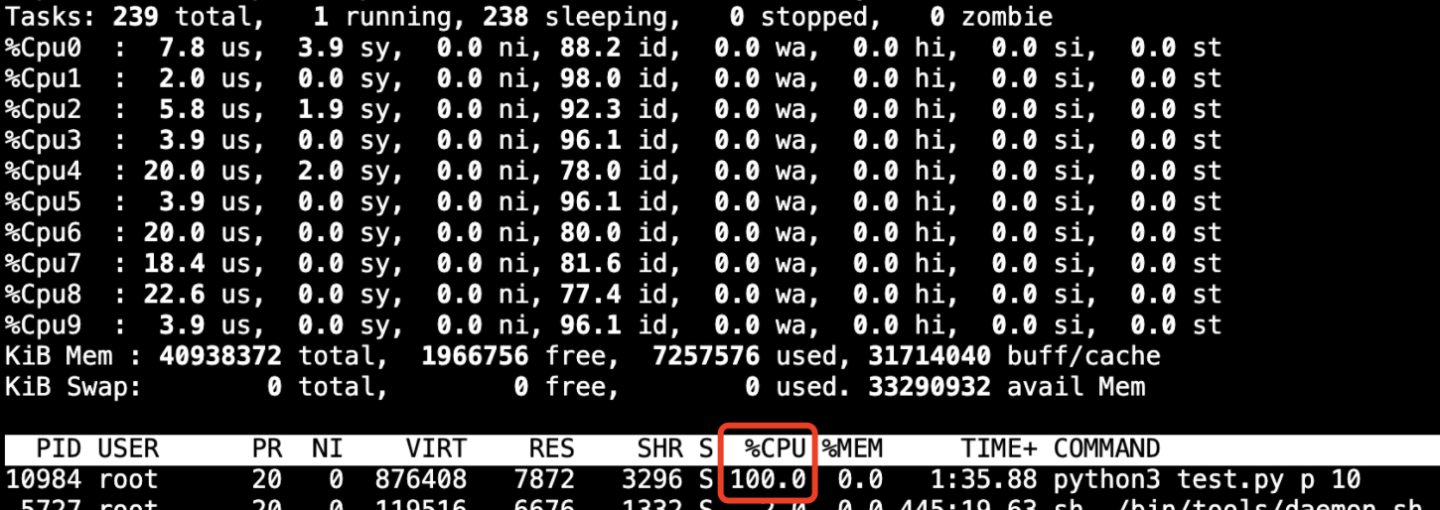
- CPU utilization:
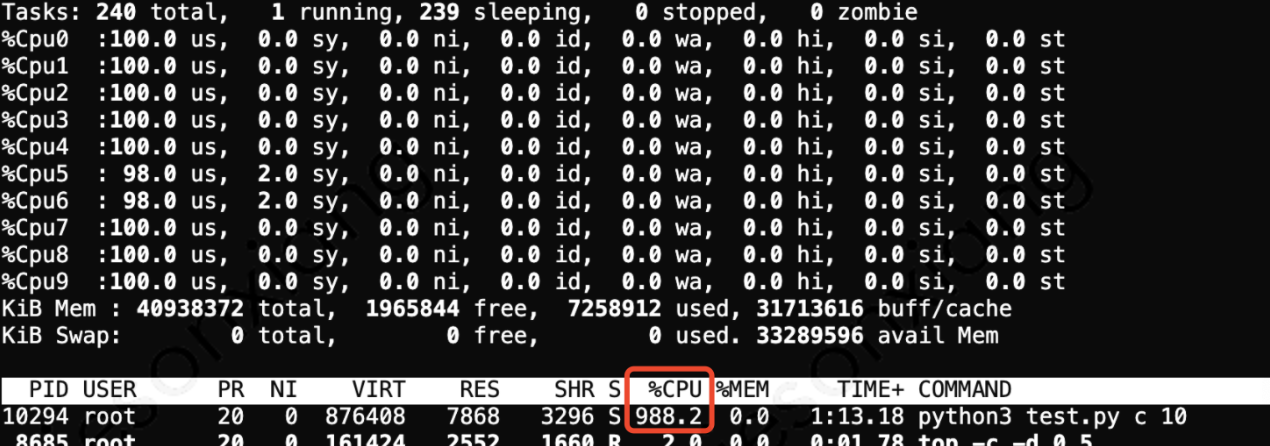
Conclusion:
Computing intensive code can achieve good performance improvement simply by changing to C + +. With the blessing of multi-threaded release of G il lock, it can make full use of multi-core performance, easily obtain linear speedup ratio and greatly improve resource utilization. Although Python multi-process can also be used to use multi-core in the actual scene, under the trend of the model becoming larger and larger, which is prone to tens of gigabytes, the memory occupation is too large, the context switching overhead of frequent switching between processes, and the performance difference of the language itself, resulting in many gaps with the C + + expansion method.
(Note: the above test demo github address: https://github.com/jesonxiang/cpp_extension_pybind11 , the test environment is CPU 10 core container. You can also do performance verification if you are interested.)
3.3 compilation environment
Compile instructions:
g++ -Wall -shared -std=gnu++11 -O2 -fvisibility=hidden -fPIC -I./ perfermance.cc -o libcppex.so `Python3-config --cflags --ldflags --libs`
If the Python environment is not configured correctly, an error may be reported:
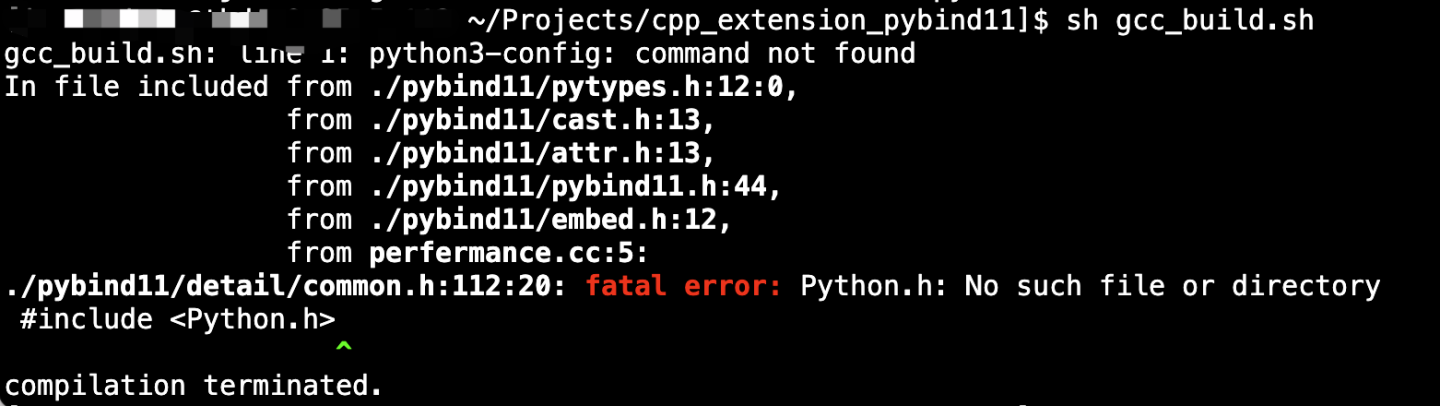
The dependency on Python here is automatically specified through Python 3-config -- cflags -- ldflags -- LIBS. You can run this command separately to verify whether the python dependency is configured correctly. The normal execution of Python 3-config depends on Python 3-dev, which can be installed through the following command:
yum install Python3-devel
4. C + + debugging Python
Generally, pybind11 is used to encapsulate the python side interface for C + + code, but conversely, C + + calling Python is also supported. Just #include < pybind11 / embedded h> The header file can be used, which is implemented internally by embedding the CPython interpreter. It is also very simple and easy to use, and has good readability. It is very similar to calling Python interface directly. For example, call some methods on a numpy array. The reference examples are as follows:
// C++
pyVec = pyVec.attr("transpose")().attr("reshape")(pyVec.size());# Python pyVec = pyVec.transpose().reshape(pyVec.size)
The following takes the frame extraction so of C++ GPU high-performance version developed by us as an example. In addition to providing the frame extraction interface for calling to python, it also needs to call back to Python to notify the frame extraction progress and frame data.
Python callback interface:
def on_decoding_callback(task_id:str, progress:int):
print("decoding callback, task id: %s, progress: %d" % (task_id, progress))
if __name__ == "__main__":
decoder = DecoderWrapper()
decoder.register_py_callback(os.getcwd() + "/decode_test.py",
"on_decoding_callback")C + + side interface Registration & callback Python:
#include <pybind11/embed.h>
int DecoderWrapper::register_py_callback(const std::string &py_path,
const std::string &func_name) {
int ret = 0;
const std::string &pyPath = py_get_module_path(py_path);
const std::string &pyName = py_get_module_name(py_path);
SoInfo("get py module name: %s, path: %s", pyName.c_str(), pyPath.c_str());
py::gil_scoped_acquire acquire;
py::object sys = py::module::import("sys");
sys.attr("path").attr("append")(py::str(pyPath.c_str())); //The path to the Python script
py::module pyModule = py::module::import(pyName.c_str());
if (pyModule == NULL) {
LogError("Failed to load pyModule ..");
py::gil_scoped_release release;
return PYTHON_FILE_NOT_FOUND_ERROR;
}
if (py::hasattr(pyModule, func_name.c_str())) {
py_callback = pyModule.attr(func_name.c_str());
} else {
ret = PYTHON_FUNC_NOT_FOUND_ERROR;
}
py::gil_scoped_release release;
return ret;
}
int DecoderListener::on_decoding_progress(std::string &task_id, int progress) {
if (py_callback != NULL) {
try {
py::gil_scoped_acquire acquire;
py_callback(task_id, progress);
py::gil_scoped_release release;
} catch (py::error_already_set const &PythonErr) {
LogError("catched Python exception: %s", PythonErr.what());
} catch (const std::exception &e) {
LogError("catched exception: %s", e.what());
} catch (...) {
LogError("catched unknown exception");
}
}
}5. Data type conversion
5.1 class member function
For the binding of classes and member functions, objects need to be constructed first, so it is divided into two steps: the first step is to wrap the instance construction method, and the other step is to register the access method of member functions. At the same time, DEF is also supported_ static,def_readwrite to bind static methods or member variables. For details, refer to official document 3.
#include <pybind11/pybind11.h>
class Hello
{
public:
Hello(){}
void say( const std::string s ){
std::cout << s << std::endl;
}
};
PYBIND11_MODULE(py2cpp, m) {
m.doc() = "pybind11 example";
pybind11::class_<Hello>(m, "Hello")
.def(pybind11::init()) //Constructor, corresponding to the constructor of c + + class. If there is no declaration or the parameters are wrong, the call will fail
.def( "say", &Hello::say );
}
/*
Python Call method:
c = py2cpp.Hello()
c.say()
*/5.2 STL container
Pybind11 supports automatic conversion of stl containers. When stl containers need to be processed, just include the header file < pybind11 / STL h> Just. The automatic conversion provided by pybind11 includes: STD:: vector < > / STD:: List < > / STD:: array < > conversion to Python list; std::set<>/std::unordered_ Set < > Convert to Python set; std::map<>/std::unordered_ Map < > Convert to dict, etc. In addition, the conversion of STD:: pair < > and STD:: tuple < > is also in < pybind11 / pybind11 h> Provided in the header file.
#include <iostream>
#include <pybind11/pybind11.h>
#include <pybind11/stl.h>
class ContainerTest {
public:
ContainerTest() {}
void Set(std::vector<int> v) {
mv = v;
}
private:
std::vector<int> mv;
};
PYBIND11_MODULE( py2cpp, m ) {
m.doc() = "pybind11 example";
pybind11::class_<ContainerTest>(m, "CTest")
.def( pybind11::init() )
.def( "set", &ContainerTest::Set );
}
/*
Python Call method:
c = py2cpp.CTest()
c.set([1,2,3])
*/5.3 passing of bytes and string types
In Python 3, the string type is UTF-8 encoding by default. If the protobuf data of string type is transmitted from the C + + side to python, an error message of "Unicode decodeerror: 'UTF-8' codec can't decode byte 0xba in position 0: invalid start byte" will appear.
Solution: pybind11 provides the binding type of non text data py::bytes:
m.def("return_bytes",
[]() {
std::string s("\xba\xd0\xba\xd0"); // Not valid UTF-8
return py::bytes(s); // Return the data without transcoding
}
);5.4 smart pointer
- std::unique_ptr pybind11 supports direct conversion:
std::unique_ptr<Example> create_example() { return std::unique_ptr<Example>(new Example()); }
m.def("create_example", &create_example);- std::shared_ptr It should be noted that bare pointers cannot be used directly. Get as follows_ Calling the child function on the Python side will report a memory access exception (such as segmentation fault).
class Child { };
class Parent {
public:
Parent() : child(std::make_shared<Child>()) { }
Child *get_child() { return child.get(); } /* Hint: ** DON'T DO THIS ** */
private:
std::shared_ptr<Child> child;
};
PYBIND11_MODULE(example, m) {
py::class_<Child, std::shared_ptr<Child>>(m, "Child");
py::class_<Parent, std::shared_ptr<Parent>>(m, "Parent")
.def(py::init<>())
.def("get_child", &Parent::get_child);
}5.5 cv::Mat to numpy conversion
When the frame extraction result is returned to the Python side, since pybind11 does not support automatic conversion of cv::Mat data structure at present, it is necessary to manually handle the binding between C++ cv::Mat and numpy on the Python side. The conversion code is as follows:
/*
Python->C++ Mat
*/
cv::Mat numpy_uint8_3c_to_cv_mat(py::array_t<uint8_t>& input) {
if (input.ndim() != 3)
throw std::runtime_error("3-channel image must be 3 dims ");
py::buffer_info buf = input.request();
cv::Mat mat(buf.shape[0], buf.shape[1], CV_8UC3, (uint8_t*)buf.ptr);
return mat;
}
/*
C++ Mat ->numpy
*/
py::array_t<uint8_t> cv_mat_uint8_3c_to_numpy(cv::Mat& input) {
py::array_t<uint8_t> dst = py::array_t<uint8_t>({ input.rows,input.cols,3}, input.data);
return dst;
}5.6 zero copy
Generally speaking, cross language calls produce performance overhead, especially for the transmission of large data blocks. Therefore, pybind11 also supports the way of data address transmission, avoids the copy operation of large data blocks in memory, and greatly improves the performance.
class Matrix {
public:
Matrix(size_t rows, size_t cols) : m_rows(rows), m_cols(cols) {
m_data = new float[rows*cols];
}
float *data() { return m_data; }
size_t rows() const { return m_rows; }
size_t cols() const { return m_cols; }
private:
size_t m_rows, m_cols;
float *m_data;
};
py::class_<Matrix>(m, "Matrix", py::buffer_protocol())
.def_buffer([](Matrix &m) -> py::buffer_info {
return py::buffer_info(
m.data(), /* Pointer to buffer */
sizeof(float), /* Size of one scalar */
py::format_descriptor<float>::format(), /* Python struct-style format descriptor */
2, /* Number of dimensions */
{ m.rows(), m.cols() }, /* Buffer dimensions */
{ sizeof(float) * m.cols(), /* Strides (in bytes) for each index */
sizeof(float) }
);
});6. Landing & Industry Application
The above scheme has been implemented in algorithms such as color extraction related services of advertising multimedia AI and GPU high-performance frame extraction, and has achieved very good speed-up effect. In the industry, most of the AI computing frameworks on the market today, such as TensorFlow, Pytorch, Ali X-Deep Learning, Baidu PaddlePaddle, all use pybind11 to provide C++ to Python end interface encapsulation, and their stability and performance have been widely verified.
7. Conclusion
Under the background of increasing revenue and reducing expenditure, reducing cost and improving efficiency in the AI field, how to make full use of existing resources and improve resource utilization is the key. This paper provides a very convenient solution to improve Python algorithm service performance and CPU utilization, and has achieved good results online. In addition, Tencent also has some other Python acceleration schemes. For example, the compilation optimization team of TEG is currently optimizing the Python interpreter. You can look forward to it in the future.
8. Appendix
1(https://docs.Python.org/3/extending/index.html#extending-index)
3(https://pybind11.readthedocs.io/en/stable/advanced/cast/index.html)