(1) case of ashes -- UDTF seeking wordcount
Data format:
Each line is a string and separated by spaces.
Code implementation:
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//Block redundant logs
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//Building programming portals
val conf: SparkConf = new SparkConf()
conf.setAppName("SparkSqlTest")
.setMaster("local[2]")
val spark: SparkSession = SparkSession.builder().config(conf)
.enableHiveSupport()
.getOrCreate()
//Create sqlcontext object
val sqlContext: SQLContext = spark.sqlContext
val wordDF: DataFrame = sqlContext.read.text("C:\\z_data\\test_data\\ip.txt").toDF("line")
wordDF.createTempView("lines")
val sql=
"""
|select t1.word,count(1) counts
|from (
|select explode(split(line,'\\s+')) word
|from lines) t1
|group by t1.word
|order by counts
""".stripMargin
spark.sql(sql).show()
}
}Result: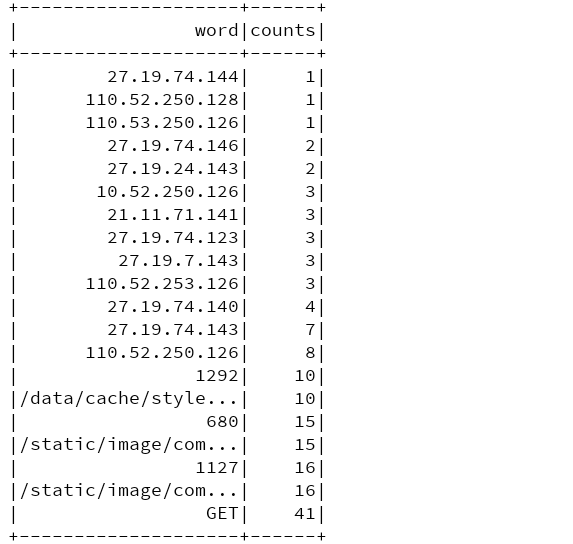
(2) window function for topN
Data format:
Top three in each course
Code implementation:
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//Block redundant logs
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//Building programming portals
val conf: SparkConf = new SparkConf()
conf.setAppName("SparkSqlTest")
.setMaster("local[2]")
val spark: SparkSession = SparkSession.builder().config(conf)
.enableHiveSupport()
.getOrCreate()
//Create sqlcontext object
val sqlContext: SQLContext = spark.sqlContext
val topnDF: DataFrame = sqlContext.read.json("C:\\z_data\\test_data\\score.json")
topnDF.createTempView("student")
val sql=
"""select
|t1.course course,
|t1.name name,
|t1.score score
|from (
|select
|course,
|name,
|score,
|row_number() over(partition by course order by score desc ) top
|from student) t1 where t1.top<=3
""".stripMargin
spark.sql(sql).show()
}
}Result: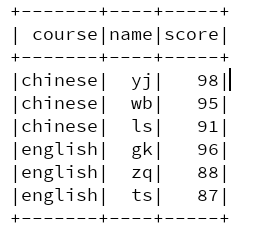
(3) spark SQL to deal with data skew
Idea: (use two-stage aggregation)
- find the key with data skew
- split the key of data with skew
- local polymerization
- remove suffix
- Global aggregation
Take the above wordcount as an example to find out the corresponding words with large amount of data
Code implementation:
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//Block redundant logs
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//Building programming portals
val conf: SparkConf = new SparkConf()
conf.setAppName("SparkSqlTest")
.setMaster("local[2]")
val spark: SparkSession = SparkSession.builder().config(conf)
.enableHiveSupport()
.getOrCreate()
//Create sqlcontext object
val sqlContext: SQLContext = spark.sqlContext
//Registered UDF
sqlContext.udf.register[String,String,Integer]("add_prefix",add_prefix)
sqlContext.udf.register[String,String]("remove_prefix",remove_prefix)
//Create a sparkContext object
val sc: SparkContext = spark.sparkContext
val lineRDD: RDD[String] = sc.textFile("C:\\z_data\\test_data\\ip.txt")
//Find words with data skew
val wordsRDD: RDD[String] = lineRDD.flatMap(line => {
line.split("\\s+")
})
val sampleRDD: RDD[String] = wordsRDD.sample(false,0.2)
val sortRDD: RDD[(String, Int)] = sampleRDD.map(word=>(word,1)).reduceByKey(_+_).sortBy(kv=>kv._2,false)
val hot_word = sortRDD.take(1)(0)._1
val bs: Broadcast[String] = sc.broadcast(hot_word)
import spark.implicits._
//Label the key with data skew
val lineDF: DataFrame = sqlContext.read.text("C:\\z_data\\test_data\\ip.txt")
val wordDF: Dataset[String] = lineDF.flatMap(row => {
row.getAs[String](0).split("\\s+")
})
//word with data skew
val hotDS: Dataset[String] = wordDF.filter(row => {
val hot_word = bs.value
row.equals(hot_word)
})
val hotDF: DataFrame = hotDS.toDF("word")
hotDF.createTempView("hot_table")
//word without data skew
val norDS: Dataset[String] = wordDF.filter(row => {
val hot_word = bs.value
!row.equals(hot_word)
})
val norDF: DataFrame = norDS.toDF("word")
norDF.createTempView("nor_table")
var sql=
"""
|(select
|t3.word,
|sum(t3.counts) counts
|from (select
|remove_prefix(t2.newword) word,
|t2.counts
|from (select
|t1.newword newword,
|count(1) counts
|from
|(select
|add_prefix(word,3) newword
|from hot_table) t1
|group by t1.newword) t2) t3
|group by t3.word)
|union
|(select
| word,
| count(1) counts
|from nor_table
|group by word)
""".stripMargin
spark.sql(sql).show()
}
//Custom UDF prefixes
def add_prefix(word:String,range:Integer): String ={
val random=new Random()
random.nextInt(range)+"_"+word
}
//Custom UDF remove suffix
def remove_prefix(word:String): String ={
word.substring(word.indexOf("_")+1)
}
}Result: