The first tone is to write so much. The second tone is to sort out some contents of global optimization, but it is estimated that it will take some time. This record is purely personal understanding. If there is any difference, welcome to discuss ~ as for the part of using optical flow for dynamic object tracking in the paper, I am not sure whether the understanding is correct. If you know, please give me some advice~
I Main function vdo_slam.cc
You can see some traces of ORBSLAM from the source code. The most critical place in the main function is slam TrackRGBD(imRGB,imD_f,imFlow,imSem,mTcw_gt,vObjPose_gt,tframe,imTraj,nImages);, From here, you can enter the whole system. Here are two things to understand:
1. How to get the pose truth matrix here and what is its function?
The files of pose truth values are found on the official website of the dataset. Some may need to be converted because of different coordinate systems. In the source code, this truth value is only used to calculate the error result, which will not affect the Tracking process. For details, please refer to issue#21
2. What is the optical flow information like and how will it be used later?
The optical flow information is obtained through the pytorch version of PWC-NET flo file. In the source code, the optical flow information corresponding to the current frame is the matching relationship between the current frame and the next frame.
II Tracking::GrabImageRGBD()
Overall process
From System::TrackRGBD(), you can see Tracking::GrabImageRGBD(). Here, list all the tasks in it, and don't write the same as ORBSLAM. Tracking::DynObjTracking() is the key function, and the details in it will be recorded in the next big point:
-
Preprocessing depth map: note that for binocular mode, each pixel of the depth map stores the parallax value.
-
Updating semantic mask information Tracking::UpdateMask(): according to the results of the semantic segmentation graph and optical flow of the previous frame, you can restore some semantic label information to the semantic segmentation graph of the current frame.
-
Construct the current frame: it is also similar to ORBSLAM. The difference is mainly reflected in the extraction of feature points. The feature points and related information of background and object will be stored in different variables.
Step 1: here, the feature points belonging to the background are processed. The author sets two options: 1)use ORB Feature extraction feature points, 2)Or take random sampling points as feature points, Then, the corresponding depth (Parallax) value is stored according to the feature point position. Step 2: sample the gray image and take points every three rows and three columns. If it belongs to objrct The points on the are stored, and the matching points, depth, semantic labels and other information are saved -
Update information: take the background & object matching points obtained from the optical flow in the previous frame as the coordinates of the background & object feature points of the current frame, and store the corresponding depth information, etc. Associated pose truth value, here is to output an RPE in each frame.
-
Entering the Tracking status Tracking:: Track(), the ultimate purpose is to get the information of camera pose and object
Step 1: initialize if necessary. Note the background and background points here object 3 of feature point construction D Points are stored in different containers. Step 2: first process the camera pose, using the matching information of the front and back frames 1) use P3P+RANSAC Method and uniform motion model are used to solve the initial pose of the camera respectively. The result of which method has more interior points is taken 2) Based on the initial estimation, the pose is optimized. Here is a similar example ORBSLAM There are two options: the optimization of position and pose combined with optical flow 3) Update the speed information according to the uniform motion model ( 4)According to the incoming camera pose gt Value to calculate the relative translation error and relative rotation error ) Step 3: Processing object 1) Sparse scene flow is calculated for feature points Tracking::GetSceneFlowObj(). Scene flow can be used as a dynamic judgment object Basis for. Scene flow of the current frame=World coordinates of feature points in the current frame-World coordinates of feature points corresponding to the previous frame 2) Track the object, that is, find the corresponding relationship between the two objects in the front and back frames Tracking::DynObjTracking() 3) Motion estimation of objects. In fact, from here on, it is based on the 3 of the front and back frames of the object D-2D Match to find one T,Then use the camera pose obtained before, Finally, the transformation of the object before and after the frame in the world coordinate system is obtained T. Step 4: update variables Tracking::RenewFrameInfo(),Similar operations are performed on static points and dynamic object points respectively 1) Save the interior points of the keys of the previous frame, and calculate the position in the next frame with optical flow, 2) For each Obj,If the tracked feature points cannot reach a fixed value, they are extracted from the current frame orb In feature points/It is not extracted from the sampling points until a sufficient number 3) This step is only for dynamic objects: update the new object and find the new object label,And add the key points on the new object to the variable 4) The corresponding depth value is stored for each key point, and the pixel coordinates, depth and camera of the known key point pose The world coordinates corresponding to the key points of the current frame are obtained Step 5: local optimization Step 6: Global Optimization -
Visualization implementation, such as visualization of feature point position, object bounding box and speed, etc
-
Returns the final pose of the current frame
Variable description
Frame class
Tmp after the name is the extension variable of the key points detected or sampled from the ORB feature of the current frame. The key with the same name but without Tmp suffix is the extension variable of the key tracked by the key of the previous frame + the optical flow information of the previous frame
| Variable name | type | meaning |
|---|---|---|
| mvStatKeysTmp | Keys detected / sampled by ORB feature in current frame | |
| mvStatKeys | The key points in the current frame, but these points are the matching points tracked by the key points of the previous frame through the optical flow information of the previous frame | |
| mvCorres | std::vector<cv::KeyPoint> | Given the key points and optical flow information in the current frame, the coordinates of matching points in the next frame can be calculated |
| mvFlowNext | std::vector<cv::Point2f> | Save the corresponding of the current frame Optical flow information of flo file |
| mvObjKeys | When constructing the frame, the key points sampled from the obj are stored. In the GrabImageRGBD function, this variable is assigned to the variable of Tracking class. Later, the key points of the current frame obtained from the previous frame + optical flow Tracking are stored | |
| nModLabel | tracking id for storing obj | |
| vObjMod | vector<cv::Mat> | Save obj's motion?? Is it a storage speed?? |
| vSpeed | vector<cv::Point_<float>> | The speed of obj is stored. An estimated value and a calculated true value of speed are stored |
| vnObjID | vector<vector<int>> | obj id of the current frame?? What is the difference between this and the semantic tag, track id? |
III Object related parts in Tracking::Track()
A. Scene flow calculation Tracking::GetSceneFlowObj();
The calculation of scene flow itself is not difficult, that is, the difference between the 3D world coordinates of the feature point in the current frame and the 3D world coordinates of the feature point in the previous frame.
The stored contents of member variables with and without tmp are changed from one to another, so the most important thing is to pay attention to whether the two coordinates taken here and now are the points taken during sampling or optical flow tracking?
//The UnprojectStereoObject function directly processes the mvObjKeys[i] of the object frame cv::Mat x3D_p = mLastFrame.UnprojectStereoObject(i,0); cv::Mat x3D_c = mCurrentFrame.UnprojectStereoObject(i,0);
Here is the conclusion:
-
x3D_p: The most important point here is to complete the final update of mvObjKeys in the RenewFrameInfo() function.
-
x3D_c: In the current frame image, the feature point coordinates tracked by the optical flow from the previous frame Obj and one-to-one corresponding to the sampling points of the previous frame. The most important line of code here is in cv::Mat Tracking::GrabImageRGBD() before Track()
mCurrentFrame.mvObjKeys = mLastFrame.mvObjCorres;
B. Object Tracking::DynObjTracking()
Here is to track the prior dynamic objects in the previous semantic mask. The process is as follows:
-
Classify and store the key point indexes according to the tag values: traverse the semantic tags of all object key points, record the indexes of all key points corresponding to the k-th semantic tag (for example, there are N objects, 1~n represents the object number, 0 represents the background, and - 1 represents the outer point), and store them in the variable Posi.
For example, Posi[2] stores the IDs of all key points of all semantic tags 2 (the tag value is ranked third from small to large). -
Filter the key points of Obj according to the boundary range: if more than half of the key points of the object with semantic label i fall at the boundary of the image (the range is set by itself), all the key points of the object will be eliminated. Important variables are as follows: finally, use variables to store the semantic tags of the corresponding qualified types.
Variable name type meaning ObjId vector<vector<int>> Store all key points of each qualified obj sem_posi vector<int> Specific semantic tag value corresponding to each qualified category Obj vObjLabel vector<int> Keys that are screened out are treated as outer points and marked as - 1 For example: after filtering, the qualified tags are 1,3,5, so all key point indexes corresponding to tag value 1 are stored in ObjId[0], and sem_posi[0] has a value of 1.
-
The key points of dynamic Obj are selected according to the calculated scene flow screening: dynamic object screening is carried out by using the scene flow information calculated by Tracking::GetSceneFlowObj(). Calculate the scene flow intensity of sampling points on each object (the threshold in the configuration file is set to 0.12). Points greater than the threshold are considered as dynamic points. If the static points on an object exceed 30% of the total, the object is considered as a static background, and vObjLabel is set to 0.
In a small place, only the values of x and z are used to calculate the scene flow. According to the data set run by the author, it feels that the y-axis is vertical. For moving on the flat ground, the influence of the y-axis direction is relatively small and can be ignored.float sf_norm = std::sqrt( mCurrentFrame.vFlow_3d[ObjId[i][j]].x*mCurrentFrame.vFlow_3d[ObjId[i][j]].x + mCurrentFrame.vFlow_3d[ObjId[i][j]].z*mCurrentFrame.vFlow_3d[ObjId[i][j]].z); -
Filter according to the average depth and number of keys on obj: if the average depth of all keys on an obj is greater than the threshold, that is, it is too far from the camera, it will be regarded as an unreliable outer point; Or if the number of key points on the object is too small (< 150), it is also regarded as an outer point.
Finally, the filtered key point information will be stored in ObjIdNew and SemPosNew, which only retains the dynamic objects to be tracked later. These two variables can correspond to the previous ObjId and sem_posi understand. -
Update the tracking ID of dynamic Obj: my personal understanding here is to directly use optical flow to associate the two tag values on the semantic mask of the front and back frames. It is said in the paper that there may be noise and other situations. A sorting operation is also carried out in the code, but when the output of the data set is passed, the variable lb_ There is only one value in last. There are still some doubts here. I hope you can leave a message in the comment area~
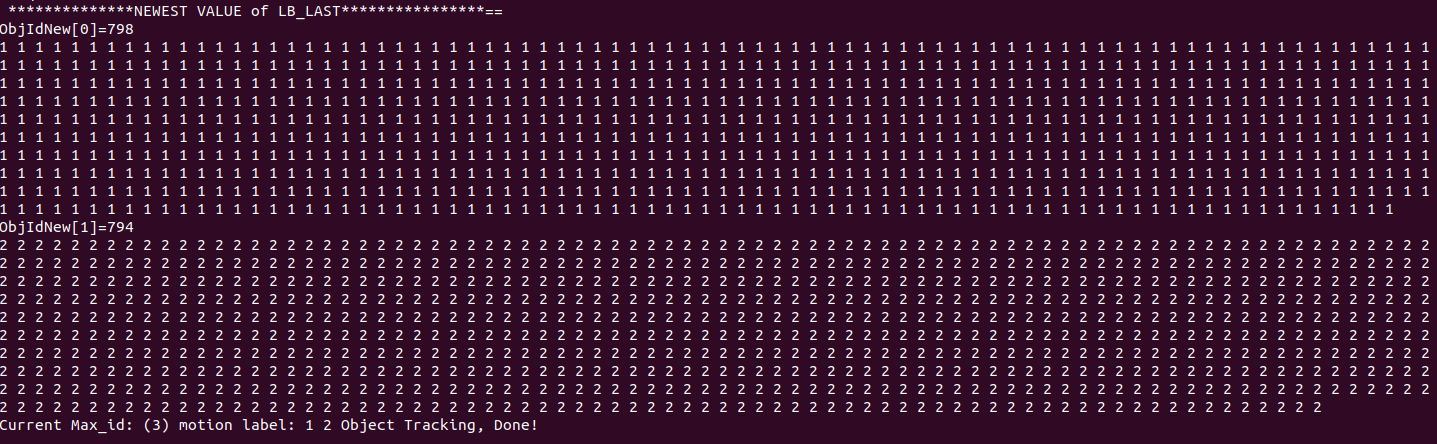 According to my current understanding, if a new object appears in frame n, it will not appear in the picture until frame n+1.
According to my current understanding, if a new object appears in frame n, it will not appear in the picture until frame n+1.
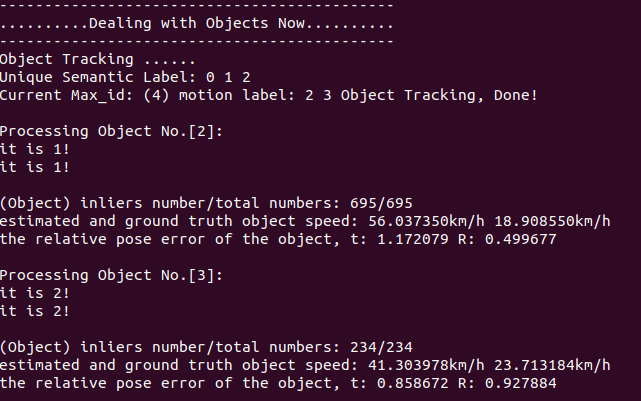 | 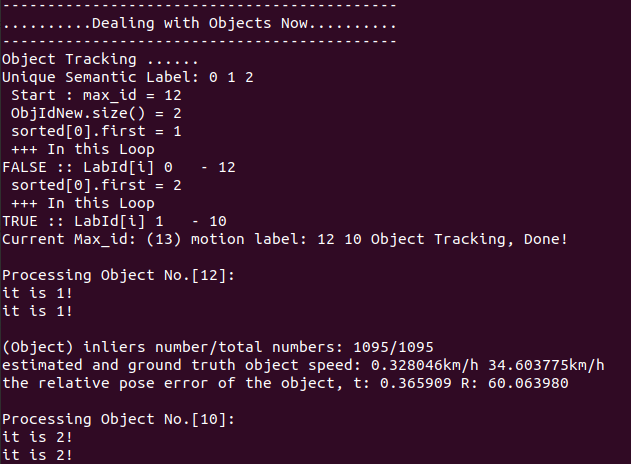 |
|---|
C. Object motion estimation
This section of code is easy to understand. The purpose is to find the transformation of Obj in the front and back frames and the speed of Obj in world coordinates.
Note: if the camera pose true value given to the system is the wrong number, the speed true value of Obj in the output window will also be wrong. The reason is clearly stated in the description of github. There is an object in the folder_ pose. Txt file, in which the object information t1-t3 and r1 are the reference camera coordinate system. When running the program, this value will be transferred to the world coordinate system by using the camera pose true value to calculate the real motion of Obj in the world coordinate system.
Here are the two most important excerpts:
// Corresponding paper formula 24 sp_est_v = mCurrentFrame.vObjMod[i].rowRange(0,3).col(3) - (cv::Mat::eye(3,3,CV_32F)-mCurrentFrame.vObjMod[i].rowRange(0,3).colRange(0,3))*ObjCentre3D_pre; // The normal m/s of TODO is converted into km/h, which should be multiplied by 3.6. Here, it is assumed that the time interval is 0.1s?? float sp_est_norm = std::sqrt( sp_est_v.at<float>(0)*sp_est_v.at<float>(0) + sp_est_v.at<float>(1)*sp_est_v.at<float>(1) + sp_est_v.at<float>(2)*sp_est_v.at<float>(2) )*36; cout << "estimated and ground truth object speed: " << sp_est_norm << "km/h " << sp_gt_norm << "km/h " << endl; // Corresponding formula 23 cv::Mat H_p_c_body_est = L_w_p_inv*mCurrentFrame.vObjMod[i]*L_w_p; cv::Mat RePoEr = Converter::toInvMatrix(H_p_c_body_est)*H_p_c_body;
※ supplementary description
In the source code of VDO-SLAM, there are some codes that do not affect the main line. There are some questions when looking at them, and the author also answered them on github, so it is also recorded here.
1. Calculate camera RPE
In the function Tracking::Track(), there is a section of the author's own code for debug ging to calculate the relative pose error of the camera.
// ----------- compute camera pose error ----------
cv::Mat T_lc_inv = mCurrentFrame.mTcw*Converter::toInvMatrix(mLastFrame.mTcw);
cv::Mat T_lc_gt = mLastFrame.mTcw_gt*Converter::toInvMatrix(mCurrentFrame.mTcw_gt);
cv::Mat RePoEr_cam = T_lc_inv*T_lc_gt;
//rmse of relative translation error
float t_rpe_cam = std::sqrt( RePoEr_cam.at<float>(0,3)*RePoEr_cam.at<float>(0,3) + RePoEr_cam.at<float>(1,3)*RePoEr_cam.at<float>(1,3) + RePoEr_cam.at<float>(2,3)*RePoEr_cam.at<float>(2,3) );
float trace_rpe_cam = 0;
for (int i = 0; i < 3; ++i)
{
// The calculation here is used by the author for debug ging. You can see the details https://github.com/halajun/VDO_SLAM/issues/17
if (RePoEr_cam.at<float>(i,i)>1.0)
//
trace_rpe_cam = trace_rpe_cam + 1.0-(RePoEr_cam.at<float>(i,i)-1.0);
else
trace_rpe_cam = trace_rpe_cam + RePoEr_cam.at<float>(i,i);
}
cout << std::fixed << std::setprecision(6);
// rmse for calculating relative rotation error
float r_rpe_cam = acos( (trace_rpe_cam -1.0)/2.0 )*180.0/3.1415926;
cout << "the relative pose error of estimated camera pose, " << "t: " << t_rpe_cam << " R: " << r_rpe_cam << endl;
This one's right for trace_ rpe_ The calculation of cam seems confusing. The main idea of the answer given by the author in github is as follows: in very few cases, RePoEr_cam may not be a positive definite matrix (but it will be very close to positive definite). At this time, the diagonal element will be slightly larger than 1, but the result of ACOS ((trace_rpe_cam - 1.0) / 2.0) is a non real number. In order to avoid this axis angle becoming an imaginary number, write it like this. But the standard method is to find a line closest to RePoEr_cam orthogonal matrix, and then carry out the following operations. The author's suggestion is that if you want to evaluate the results of VDO-SLAM, it is best to use other evaluation tools.
Extension: how to calculate the approximate orthogonal matrix of a matrix?
http://people.csail.mit.edu/bkph/articles/Nearest_Orthonormal_Matrix.pdf
2. Results of semantic segmentation of Oxford Multimotion dataset
The questioner wondered that there were no semantic tags such as "cubes" or "boxes" in the COCO dataset, and wondered how the author got the mask.
A: for this less complex data set, the author uses the traditional visual method, combined with box color information + Otsu algorithm + multi label processing