After Python batch processes excel data, import it into sqlserver
- 1. Foreword
- 2. Start thinking
- 2.1 disassembly + clear requirements
- 2.2 installation of third-party package
- 2.3 reading excel data
- 2.4 special data processing
- 2.5 other requirements
- 2.6 complete calling code
1. Foreword
Following yesterday's article Windows download, install and configure SQL Server and SSMS, and use Python connection to read and write data , we have installed and configured SQL server, and successfully tested how to use Python to connect, read and write data to the database.
Today, we officially begin to meet the demand: there are many Excel, which need to be processed in batch and then stored in different data tables.
2. Start thinking
2.1 disassembly + clear requirements
1) What excel data needs to be modified?
- There is a column of data, DocketDate, which is a short-time value in excel and needs to be transformed into the normal format of year, month and day; eg. 44567 --> 2022/1/6
- Some data needs to be processed repeatedly according to SOID, and the latest data is retained according to DocketDate;
- A column of data needs date format conversion. eg. 06/Jan/2022 12:27 --> 2022-1-6
It mainly involves date format processing and data De duplication processing
2) Does each excel correspond to a different data sheet? Is the table name consistent with the name of Excel attachment?
- Some Excel tables correspond to the same table
- The table name is inconsistent with the Excel attachment name, but there is a corresponding relationship eg. attachment test1 and test2 correspond to table testa, and attachment test3 corresponds to testb
It mainly involves data consolidation and processing
2.2 installation of third-party package
pip3 install sqlalchemy pymssql pandas xlrd xlwt
- sqlalchemy: you can map the table structure of the relational database to the object, and then process the database content by processing the object;
- pymssql: python is the driver for connecting to the SQL Server database. You can also directly use it to connect to the database for reading and writing operations;
- pandas: it can process all kinds of data and has many built-in data processing methods, which is very convenient;
- xlrd xlwt: read and write Excel files, and pandas will call them when reading and writing excel.
Import package:
import pandas as pd from datetime import date, timedelta, datetime import time import os from sqlalchemy import create_engine import pymssql
2.3 reading excel data
Reading data is relatively simple. You can directly call pandas read_excel function is enough. If the file has any special format, such as coding, you can also customize the setting.
# Reading excel data
def get_excel_data(filepath):
data = pd.read_excel(filepath)
return data
2.4 special data processing
"1) date days are shortened "
This is difficult. It is very simple to directly transfer in excel. Directly select the data to be transferred, and then select the short date in the start data format column.
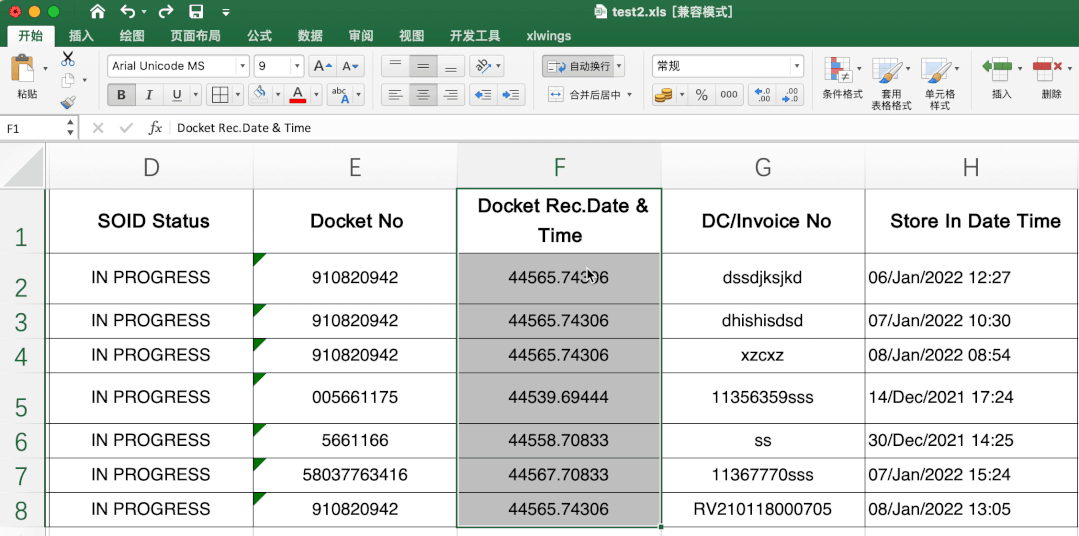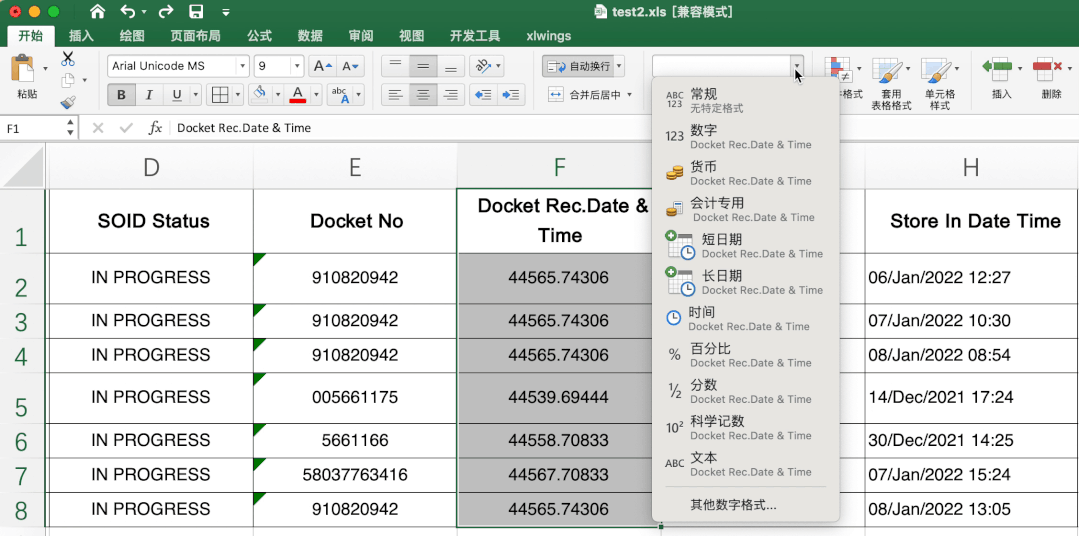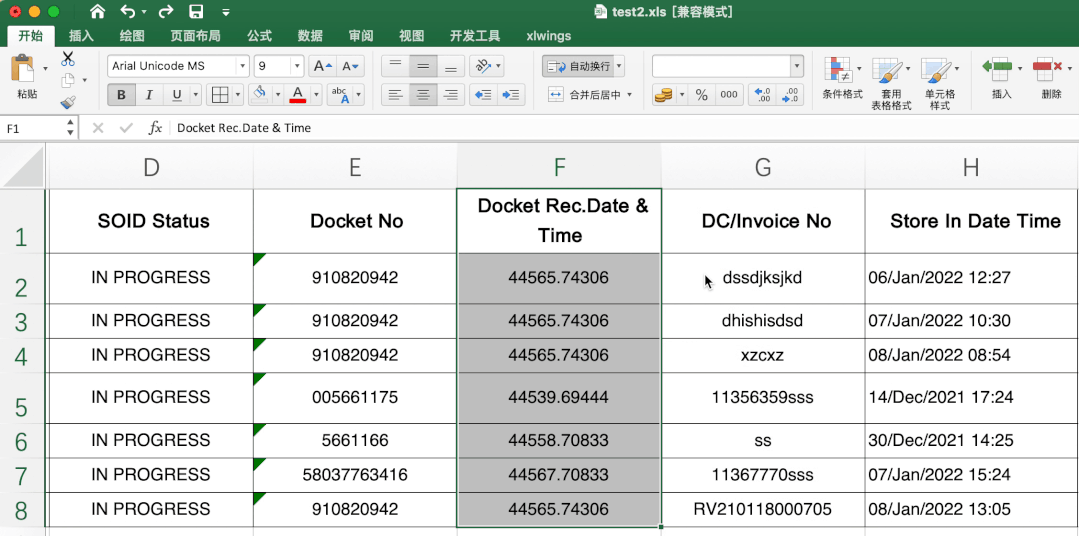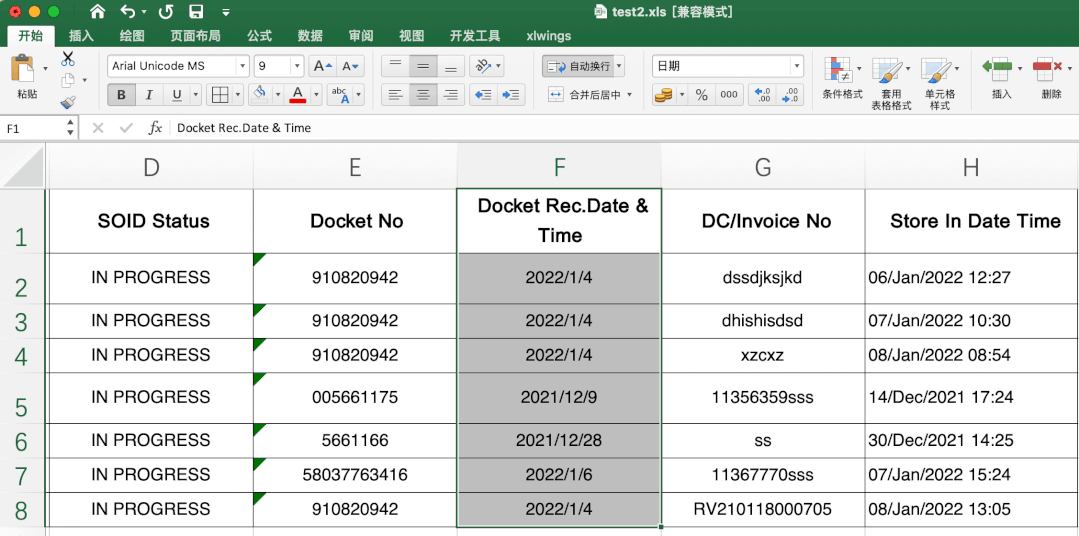
First of all, I don't know the starting date of the search. In the end, I don't know whether there is a change in the number of days. I don't think there is a change in the starting date of the search. In the end, I don't know whether there is a change in the number of days. In the end, I don't know whether there is a change in the number of days. I think there is a change in the starting date of the search.
First, we need to judge the null value, then set the date and days to calculate the start time, use the timedelta function of datetime module to convert the time and days into time difference, and then directly calculate with the start date to obtain the date it represents.
# Date days to shorten date
def days_to_date(days):
# Processing nan values
if pd.isna(days):
return
# 44567 2022/1/6
# It is calculated that the excel days shortening date is calculated from December 30, 1899
start = date(1899,12,30)
# Convert days to timedelta type, which can be calculated directly with the date
delta = timedelta(days)
# Start date + time difference to get the corresponding short date
offset = start + delta
return offset
It's hard to think about the start date of calculating the number of days here, but it's also easy to calculate after you think about it. From excel, we can directly convert the number of days of the date into a short date. The equation already exists. There is only one unknown number x. we just need to list a unary equation to solve the unknown number x.
from datetime import date, timedelta date_days = 44567 # Convert days to date type interval delta = timedelta(date_days) # Result date result = date(2022,1,6) # Calculate unknown start date x = result - delta print(x) ''' Output: 1899-12-30 '''
"2) convert the English language of the date into numbers "
At first, I wanted to use regular matching to take out the year, month and day, and then convert the English month into a number. Later, I found that the English month can be directly recognized in the date.
The code is as follows. First, convert the string into date type data according to the format. The original data is 06/Jan/2022 12:27 (digital day / English month / digital year, digital hour: Digital minute). Replace it according to the corresponding relationship in the date format symbol interpretation table.
# Convert official date format to common format
def date_to_common(time):
# Processing nan values
if pd.isna(time):
return
# 06/Jan/2022 12:27 2022-1-6
# Test print(time,':', type(time))
# Convert string to date
time_format = datetime.strptime(time,'%d/%b/%Y %H:%M')
# Convert to specified date format
common_date = datetime.strftime(time_format, '%Y-%m-%d')
return common_date
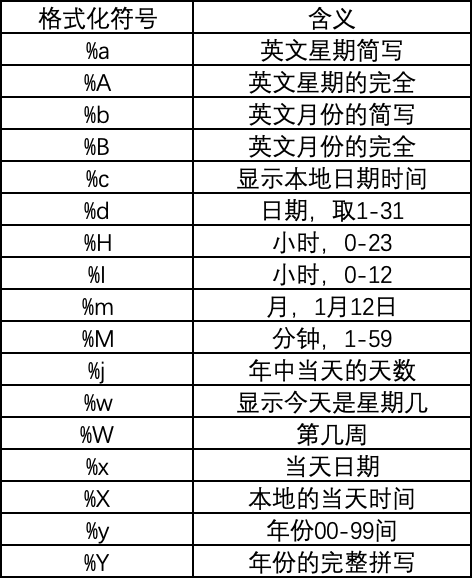
Date formatting symbol interpretation table @CSDN - boating messenger
"3) de duplication by order number SOID "
To repeat here, in addition to removing duplicates according to the specified column, the latest data needs to be retained by date.
My idea is to call pandas's sort first_ The values function sorts all the data in ascending order according to the date column, and then calls drop_. The duplicates function specifies that the duplicate is removed according to the SOID column, and the keep value is last, indicating that the last row of data is retained in the duplicate data.
The code is as follows:
# Remove duplicates SOID removes the oldest data by date
def delete_repeat(data):
# Sort by the date column docket rec.date & time first. The default descending order ensures that the date left is the latest
data.sort_values(by=['Docket Rec.Date & Time'], inplace=True)
# Delete duplicate lines by SOID
data.drop_duplicates(subset=['SOID #'], keep='last', inplace=True)
return data
2.5 other requirements
"Multiple Excel data correspond to the table of one database "
You can write a dictionary to store the database table and the corresponding Excel data name, and then store them in the corresponding database table one by one (or process the data in advance and then merge).
- Merge Excel tables of the same type
# The merged data of the same table is transferred into the merged excel list
def merge_excel(elist, files_path):
data_list = [get_excel_data(files_path+i) for i in elist]
data = pd.concat(data_list)
return data
Here, you can pass in the same type of Excel file name list (elist) and the absolute / relative path of the data storage folder (files_path). You can get the absolute / relative path of the Excel data table file through the file absolute / relative path + excel file name, and then call get_ excel_ The data function can read the data.
The list derivation is used to traverse and read the Excel table data. Finally, the corresponding data can be merged by using the concat function of pandas.
- Data storage to SQL Server
# Initialize database connection engine
# create_engine("database type + database driver: / / database user name: database password @ IP address: port / database", other parameters)
engine = create_engine("mssql+pymssql://sa:123456@localhost/study?charset=GBK")
# Store data
def data_to_sql(data, table_naem, columns):
# Then process the data a little, select the specified column and store it in the database
data1 = data[columns]
# First parameter: table name
# Second parameter: database connection engine
# Third parameter: store index
# The fourth parameter: append data if the table exists
t1 = time.time() # Timestamp in seconds
print('Data insertion start time:{0}'.format(t1))
data1.to_sql(table_naem, engine, index=False, if_exists='append')
t2 = time.time() # Timestamp in seconds
print('Data insertion end time:{0}'.format(t2))
print('Successfully inserted data%d Article,'%len(data1), 'Time consuming:%.5f Seconds.'%(t2-t1))
Pay attention to the following when connecting sqlserver with sqlalchemy+pymssql: specify the database code. The database created by slqserver is GBK code by default. You can check the article on the installation and use of sqlserver Windows download, install and configure SQL Server and SSMS, and use Python connection to read and write data.
2.6 complete calling code
'''
Batch process all excel data
'''
# Data files are stored in a specified directory, such as:
files_path = './data/'
bf_path = './process/'
# Get the names of all files in the current directory
# files = os.listdir(files_path)
# files
# Table name: attachment excel name
data_dict = {
'testa': ['test1.xls', 'test2.xls'],
'testb': ['test3.xls'],
'testc': ['test4.xls']
}
# Select the specified column in the attachment and save only the data in the specified column
columns_a = ['S/No', 'SOID #', 'Current MileStone', 'Store In Date Time']
columns_b = ['Received Part Serial No', 'Received Product Category', 'Received Part Desc']
columns_c = ['From Loc', 'Orig Dispoition Code']
columns = [columns_a, columns_b, columns_c]
flag = 0 # Column selection tag
# Traverse the dictionary, merge relevant excel, then process the data and store it in sql
for k,v in data_dict.items():
table_name = k
data = merge_excel(v, files_path)
# 1. Processing data
if 'SOID #' not in data.columns:
# If it does not contain the columns to be processed, it will be directly and simply de duplicated and stored in the database
data.drop_duplicates(inplace=True)
else:
# Special processing data
data = process_data(data)
# 2. Store data
# To be on the safe side, save one locally
data.to_excel(bf_path+table_name+'.xls')
# Store to database
data_to_sql(data, table_name, columns[flag])
flag+=1