catalog:
Question answering system
Question answering system (QA) is an advanced form of information retrieval system. It can answer the questions raised by users in natural language with accurate and concise natural language. The main reason for the rise of its research is people's demand for fast and accurate access to information. Question answering system is a research direction in the field of artificial intelligence and natural language processing.
Text search engine
Based on the text search engine, this example supports uploading csv files, extracting features using sentence vector model, and subsequent retrieval based on milvus vector engine.
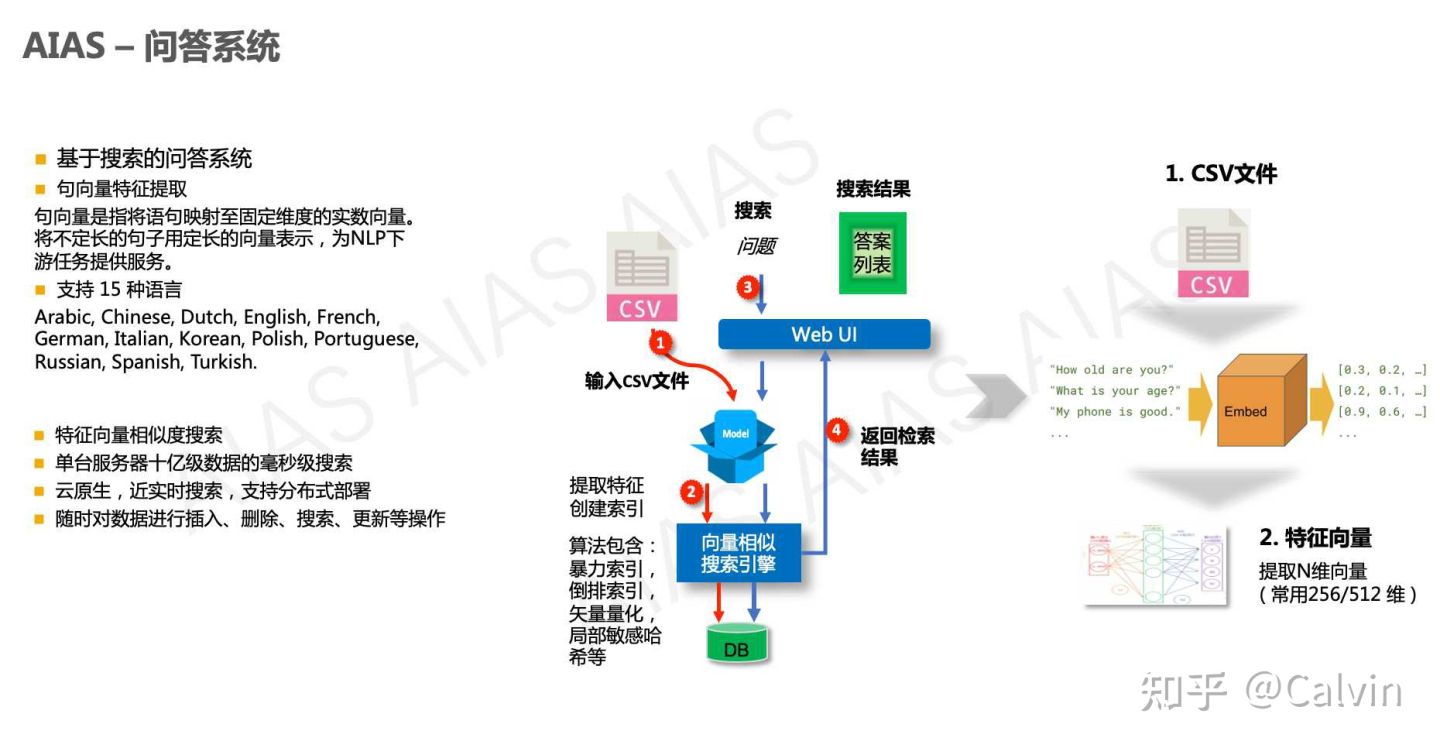
Main characteristics
- The bottom layer uses feature vector similarity search
- Millisecond search of billions of data on a single server
- Near real-time search, supporting distributed deployment
- Insert, delete, search and update data at any time
Sentence vector model [supports 15 languages]
A sentence vector is a real number vector that maps a statement to a fixed dimension. Variable length sentences are represented by fixed length vectors to provide services for NLP downstream tasks. It supports 15 languages: Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish
- Sentence vector
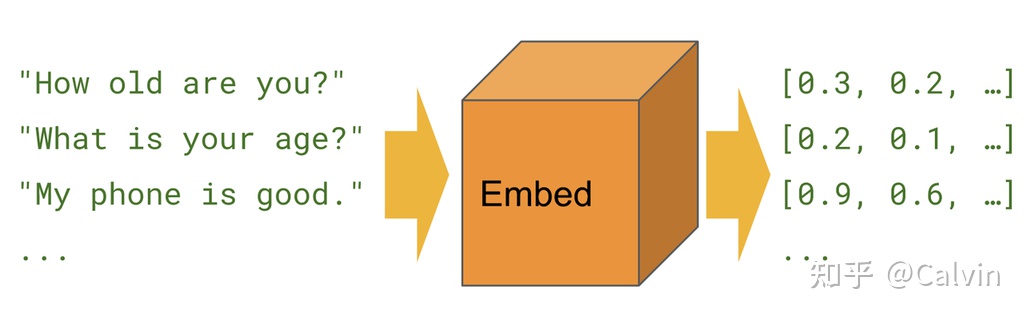
Sentence vector application:
- The semantic search / question answering system retrieves the text that best matches query in the corpus through sentence vector similarity
- Text clustering, the text is transformed into a fixed length vector, and similar texts can be unsupervised clustered through the clustering model
- Text classification, expressed as sentence vectors, directly uses a simple classifier, that is, training text classifier
1. Front end deployment
1.1 installation and operation:
# Install dependent packages npm install # function npm run dev
1.2 build dist installation package:
npm run build:prod
1.3 nginx deployment and operation (mac environment as an example):
cd /usr/local/etc/nginx/
vi /usr/local/etc/nginx/nginx.conf
# Edit nginx conf
server {
listen 8080;
server_name localhost;
location / {
root /Users/calvin/Documents/qa_system/dist/;
index index.html index.htm;
}
......
# Reload configuration:
sudo nginx -s reload
# After deploying the application, restart:
cd /usr/local/Cellar/nginx/1.19.6/bin
# Quick stop
sudo nginx -s stop
# start-up
sudo nginx
2. Backend jar deployment
2.1 environmental requirements:
- System JDK 1.8+
- application.yml
# File storage path
file:
mac:
path: ~/file/
linux:
path: /home/aias/file/
windows:
path: D:/aias/file/
# File size / M
maxSize: 3000
...
2.2 operation procedure:
# Run program java -jar qa-system-0.1.0.jar
3. Backend vector engine deployment (docker)
3.1 environmental requirements:
- docker running environment needs to be installed. Docker Desktop can be used in Mac environment
3.2 pull Milvus vector engine image (used to calculate eigenvalue vector similarity)
Please refer to the official website for the latest version
- Milvus vector engine reference link
Milvus vector engine official website
Milvus vector engine Github
sudo docker pull milvusdb/milvus:0.10.0-cpu-d061620-5f3c00
3.3 downloading configuration files
3.4 start Docker container
/Users/calvin/vector_engine is the host path, which can be modified as needed. conf is the configuration file required by the engine.
docker run -d --name milvus_cpu_0.10.0 \ -p 19530:19530 \ -p 19121:19121 \ -p 9091:9091 \ -v /Users/calvin/vector_engine/db:/var/lib/milvus/db \ -v /Users/calvin/vector_engine/conf:/var/lib/milvus/conf \ -v /Users/calvin/vector_engine/logs:/var/lib/milvus/logs \ -v /Users/calvin/vector_engine/wal:/var/lib/milvus/wal \ milvusdb/milvus:0.10.0-cpu-d061620-5f3c00
3.5 edit vector engine connection configuration information
- application.yml
- Edit the vector engine connection ip address 127.0 as needed 0.1 is the host ip of the container
##################### Vector engine ############################### search: host: 127.0.0.1 port: 19530 indexFileSize: 1024 # maximum size (in MB) of each index file nprobe: 256 nlist: 16384 faceDimension: 512 #dimension of each vector faceCollectionName: questions #collection name commDimension: 512 #dimension of each vector commCollectionName: comm #collection name
4. Open the browser
- Enter address: http://localhost:8090
- Upload CSV data file
1). Click the upload button to upload the CSV file
test data
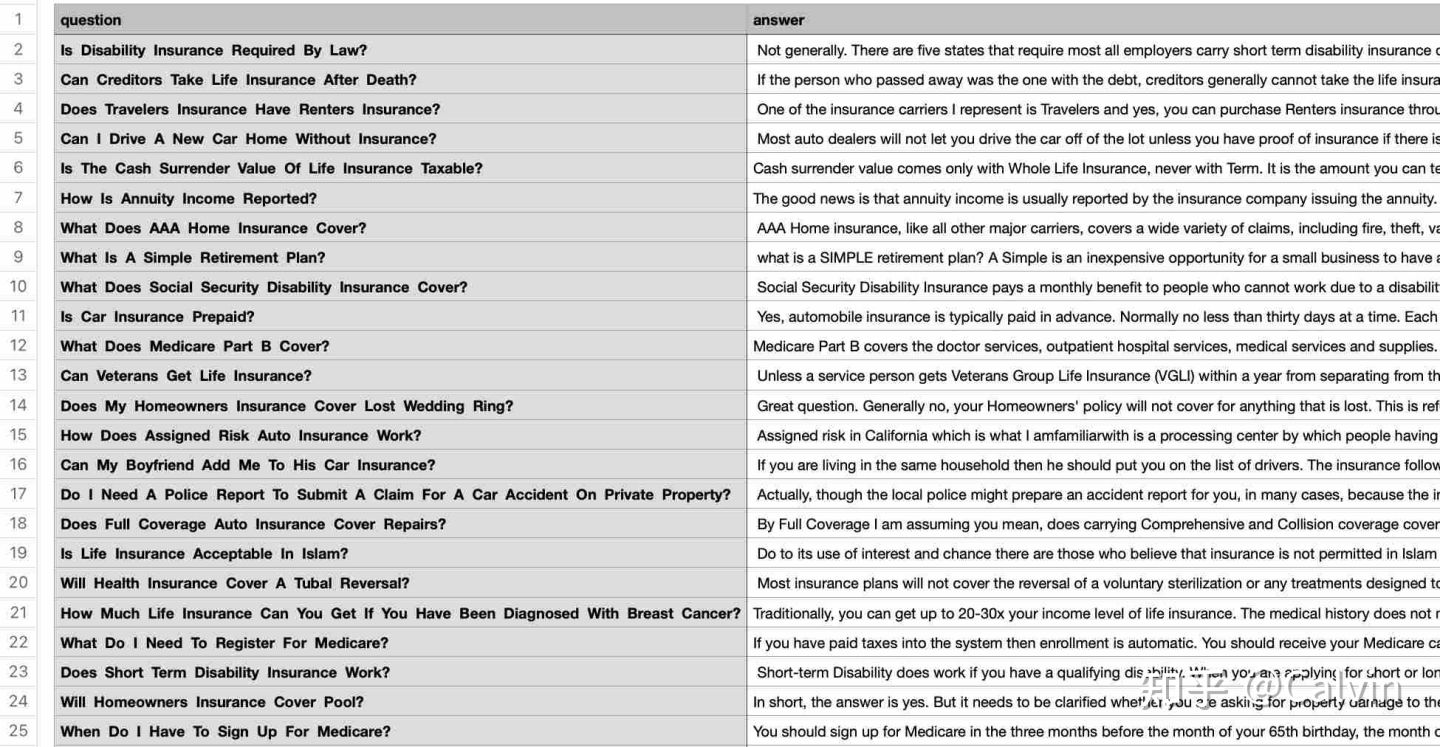
2). Click the feature extraction button Wait for CSV file parsing, feature extraction and feature storage in vector engine. You can see the progress information through the console.

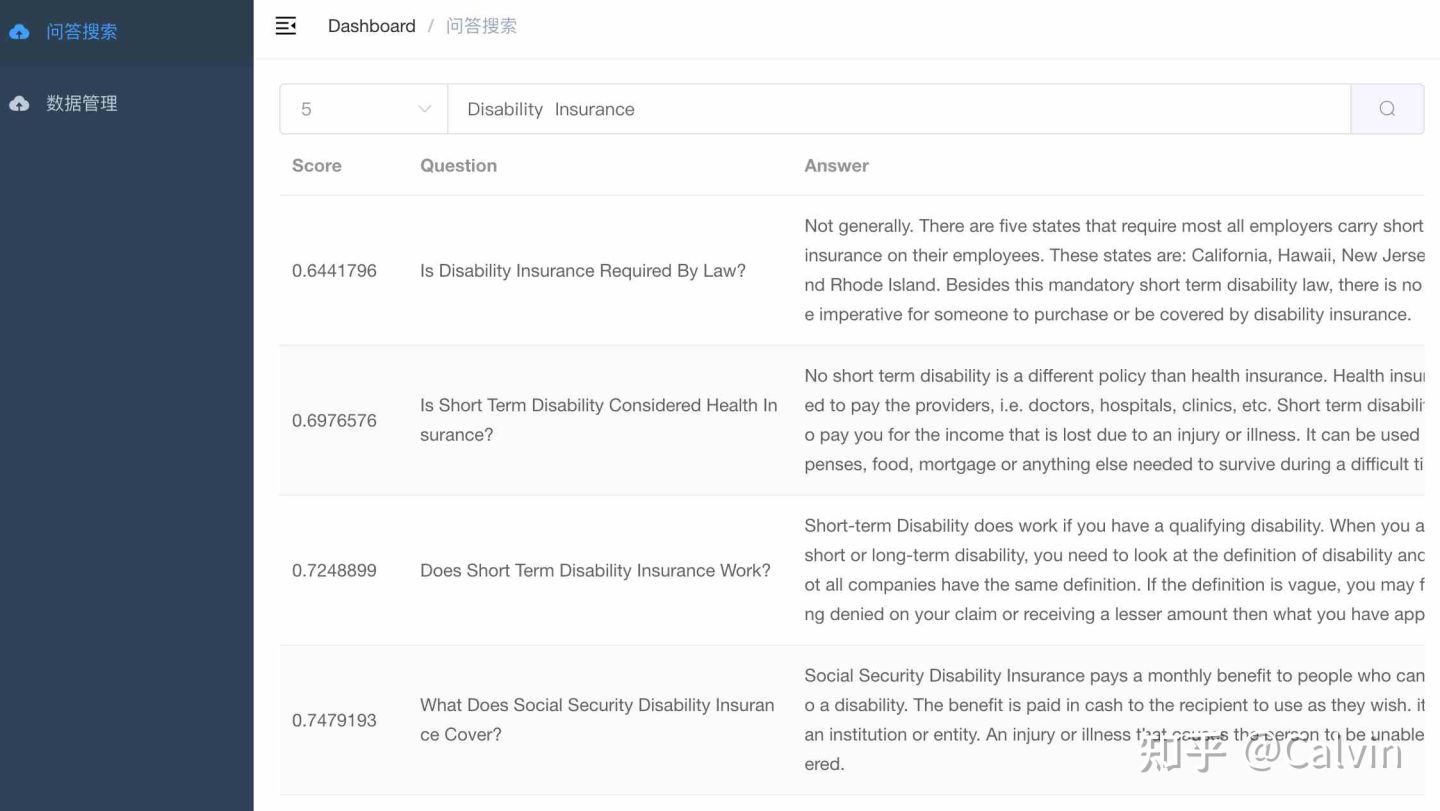
- Text search, input text and click query to see the returned list, which is sorted according to the similarity.
5. Help information
- swagger interface documentation:
http://localhost:8089/swagger-ui.html

- Initialize vector engine (empty data): me aias. tools. MilvusInit. java
String host = "127.0.0.1";
int port = 19530;
final String collectionName = "questions"; // collection name
MilvusClient client = new MilvusGrpcClient();
// Connect to Milvus server
ConnectParam connectParam = new ConnectParam.Builder().withHost(host).withPort(port).build();
try {
Response connectResponse = client.connect(connectParam);
} catch (ConnectFailedException e) {
e.printStackTrace();
}
// Check whether the collection exists
HasCollectionResponse hasCollection = hasCollection(client, collectionName);
if (hasCollection.hasCollection()) {
dropIndex(client, collectionName);
dropCollection(client, collectionName);
}
...