Team Introduction
The name of our team is Baseline. Because we share Baseline, we call our team Baseline.
Captain: Fang Xi is from Shanghai Jiaotong University, the third graduate student.
Team member: LV Xiaoxin from Netease, AI Engineer
Team member: Wang Hao is from Beijing Xinghe bright spot, software R & D
Team member: Yang Xinda is an AI engineer from an enterprise in Guangzhou
programme
abstract
For the current communication system, the physical layer is the basis for the guarantee of communication services; For the physical layer, MIMO is the basic supporting technology; For MIMO, it is essential to accurately determine the channel quality and make effective feedback and utilization.
In the discussion of 3GPP of international organization for standardization, this part of work is completed through CSI reference signal design and CSI feedback mechanism. In the current CSI feedback design, it mainly relies on vector quantization and codebook design to realize channel feature extraction and feedback, such as CSI feedback design based on TYPE1 and TYPE2. In current practice, this kind of feedback method is effective, but because its core idea is based on information extraction and codebook feedback, the target information fed back is actually lossy channel information.
In this competition, we modeled from the perspective of computer vision and designed a self encoder structure based on CNN. We use BCSP module with SE structure as the basic component of the network, which has a good effect in computing efficiency and network accuracy; The quantization module with error recovery ability can not only reduce the quantization error, but also improve the training effect of the encoder; By analyzing the competition data, we found four data enhancement methods by using the idea of fast autoaugment, which perfectly solved the problem of network over fitting of bit number near 384; We greatly accelerated our training process by pruning and reducing the quantization accuracy. Finally, we got the good result of No. 7.
key word
Wireless communication, channel feedback, convolutional neural network, attention mechanism, data enhancement
1. Use of attention mechanism
The attention mechanism we adopted is se net: sequence and exception networks, abbreviated as Se net [1], which won the champion of the classification task of the last Imagenet 2017 competition. Its basic principle is to predict a constant weight for each output channel and add weight to each channel. The structure is shown in the figure below:
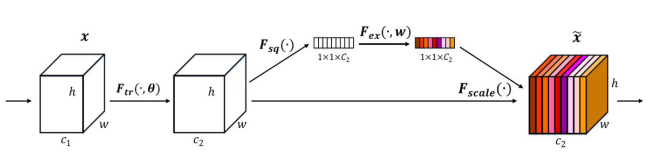
Figure 1: SE attention mechanism
In the first step, the global average number of H*W of each channel is pooled to obtain a scalar, called Squeeze, and then the two FC get a weight value between 01. Multiply each element of each original HxW by the weight of the corresponding channel to obtain a new feature map, called exception. Any original network structure can be feature recalibrated through this Squeeze exception, as shown in the following figure.
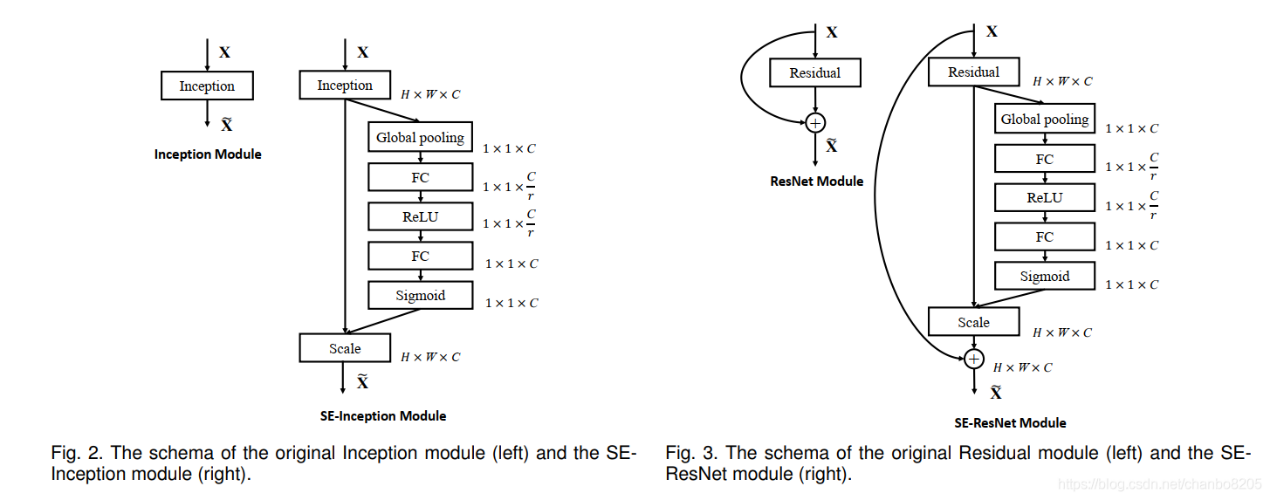
Figure 2: SENet infrastructure
The specific implementation is a global average pooling FC relu FC sigmoid. The FC of the first layer will lower the channel, and then the FC of the second layer will raise the channel to obtain C weights with the same number of channels. Each weight is used to weight the corresponding channel. r in the figure above is the reduction coefficient. It is determined by experiment that selecting 16 can obtain better performance and relatively small amount of calculation. The core of the training method of the feature of the feature of the feature of the feature of the net is that the weight of the feature of the feature of the net is small, and the effective result of the training is better according to the weight of the feature of the net.
We embed a substructure of SENet into the last layer of C3 and BottleneckCSP modules. As shown in Figure 3.
In this competition, SE structure or attention mechanism can greatly improve the fitting ability of the model, so that our model can successfully complete the 432bit standard, but the subsequent model over fitting phenomenon has plagued us for a long time.
2 quantization error recovery module
In the process of quantization coding, after quantization inverse quantization operation, some information of the original coding will be lost, that is, quantization error. The existence of quantization error will not only make the final NMSE of the model higher than that without quantization operation, but also slow down the training speed and effect of coder. Therefore, we propose a quantization error recovery module, that is, refine the inverse quantized coding to make it closer to no quantization loss.
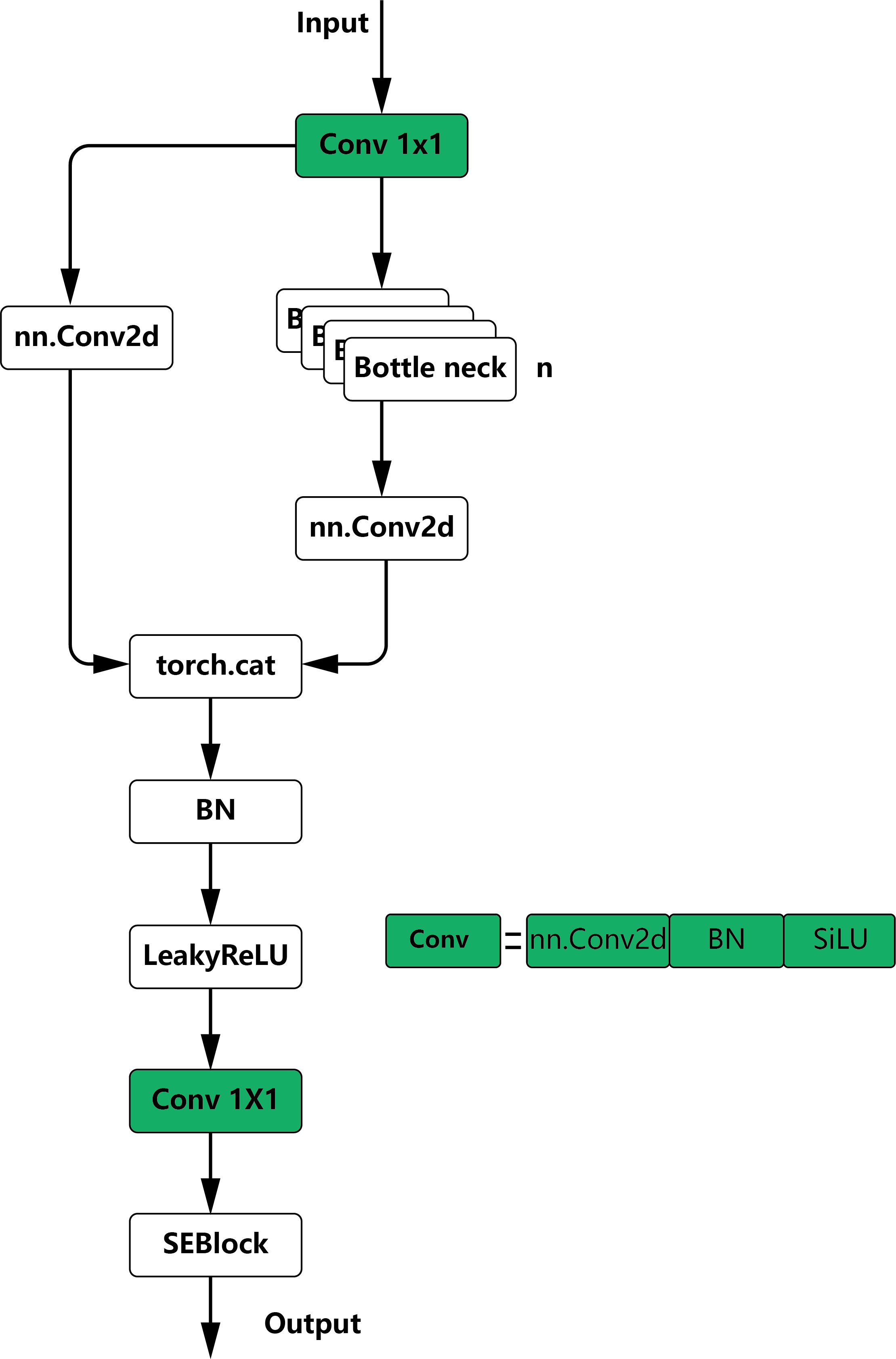
Figure 3: basic module diagram
The specific operation is that for the coding after quantization and inverse quantization, through two-layer full connection (with bn and nonlinear layer) and standardization processing, we get the output with the same value domain as the quantization error value domain (adjust the value domain to [- 12B+1,12B+1] through sigmoid and scale operations)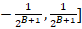 )The residual is added to the original inverse quantization coding to recover the quantization error. At the same time, in order to make this module work better, we add a loss function to the output of this module, so that the recovered coding is closer to the coding before quantization.
)The residual is added to the original inverse quantization coding to recover the quantization error. At the same time, in order to make this module work better, we add a loss function to the output of this module, so that the recovered coding is closer to the coding before quantization.
Assuming that the pre quantization code is X 'and the post quantization code is X', our error recovery module is r, the additional supervision is expressed as follows: L(X+R(X'), X)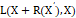 .
.
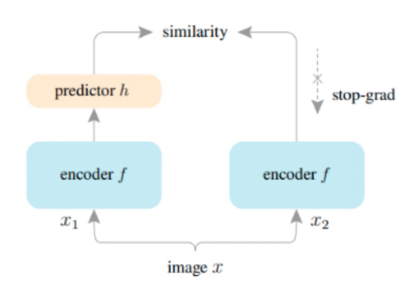
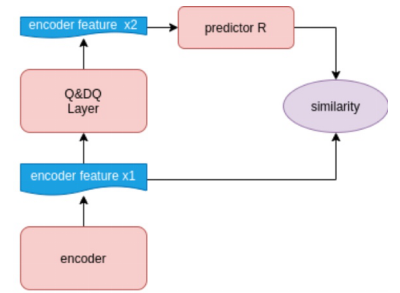
Figure 4: structure comparison between error recovery module and Simsiam
The figure above compares the structure of error recovery module and SimSiam[2] in self-monitoring algorithm. If we regard the quantization error as a kind of data enhancement, the quantization error repair can just be regarded as a self supervised learning network. At the same time, there is a branch that can calculate the accurate gradient in the back-propagation process, so that we can obtain a better encoder layer.
3 data enhancement
The data 200 * 3000 provided by the competitor is placed in order. Through analysis, we find that there seems to be some similar relationships among the data in the dimension of 3000, and we will not destroy this model in all the data enhancement process. Although data enhancement can alleviate the over fitting of the model to a certain extent, if the design is not appropriate, the network will learn a lot of useless information and can not train a very low nmse. Therefore, we learn from the idea of fast autoaugment. For each data enhancement, we use the model trained by the original data to enhance the statistical nmse in the validation set data + this data, If the nmse is too high, then this data enhancement probability changes the original data distribution and should not be adopted. In this way, we selected four data enhancement methods:
- 1-X
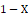
- Real part imaginary part shuffle
- MixUp
- CutMix
The traditional MixUp and CutMix will destroy the original mode of data, so we make some modifications to it. In the process of sample sampling, we will only select two samples belonging to the same Patten for fusion; We will not destroy the numerical relationship of dimension 16, so we randomly select a part of 24 rows to replace in the CutMix process. This is because although dimension 24 has patten, it seems that there is no particularly obvious numerical relationship. In this way, we can successfully train a 384bit model.
Figure 5: effect diagram of data enhancement
5 pruning and quantification
In the quantization layer, we choose a simple uniform quantization operation. In the selection of quantization bit number, considering that the task focuses more on smaller transmission bits rather than the ultimate accuracy (low NMSE), we can choose to use a smaller number of quantization bits, and too small number of quantization bits will lead to too large quantization error, making decoder training more difficult and easier to fit. Weighing the above, we chose the quantization operation with Bit=3.
When training the initial model, we first choose to use the bitstream with 432 bits to build the model for training. After the training, we cut the full connection of the last layer of encoder and the full connection of the first layer of decoder to obtain the 384bit autoencoder model, and then further finetune to obtain the 384bit model (3bit*128). In the final stage of the competition, we choose to compress 6 of 128 codes from 3bit to 2bit, and further finetune to obtain the 378bit model finally submitted. That is, among the 378bit models finally submitted, 122 codes adopt 3bit quantization coding and 6 codes adopt 2bit quantization coding.
thank
Thank the organizers for providing data, and the DataFountain platform for providing support and timely problem feedback!
Code
modelDesign.py
# =======================================================================================================================
# =======================================================================================================================
import numpy as np
import torch.nn as nn
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
from collections import OrderedDict
NUM_FEEDBACK_BITS_STARTS = 768
NUM_FEEDBACK_BITS = 384 # The pytorch version must have this parameter
channel_last = 1
CR_dim = 128
REFINEMENT = 1
class Mish(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * (torch.tanh(torch.nn.functional.softplus(x)))
return x
ACT = nn.SiLU()
# =======================================================================================================================
# =======================================================================================================================
# Number to Bit Defining Function Defining
def Num2Bit(Num, B):
Num_ = Num.type(torch.uint8)
def integer2bit(integer, num_bits=B * 2):
dtype = integer.type()
exponent_bits = -torch.arange(-(num_bits - 1), 1).type(dtype)
exponent_bits = exponent_bits.repeat(integer.shape + (1,))
out = integer.unsqueeze(-1) // 2 ** exponent_bits
return (out - (out % 1)) % 2
bit = integer2bit(Num_)
bit = (bit[:, :, B:]).reshape(-1, Num_.shape[1] * B)
return bit.type(torch.float32)
def Bit2Num(Bit, B):
Bit_ = Bit.type(torch.float32)
Bit_ = torch.reshape(Bit_, [-1, int(Bit_.shape[1] / B), B])
num = torch.zeros(Bit_[:, :, 1].shape).cuda()
for i in range(B):
num = num + Bit_[:, :, i] * 2 ** (B - 1 - i)
return num
# =======================================================================================================================
# =======================================================================================================================
# Quantization and Dequantization Layers Defining
class Quantization(torch.autograd.Function):
@staticmethod
def forward(ctx, x, B):
ctx.constant = B
step = 2 ** B
out = torch.round(x * step - 0.5)
out = Num2Bit(out, B)
return out
@staticmethod
def backward(ctx, grad_output):
# return as many input gradients as there were arguments.
# Gradients of constant arguments to forward must be None.
# Gradient of a number is the sum of its B bits.
b, _ = grad_output.shape
grad_num = torch.sum(grad_output.reshape(b, -1, ctx.constant), dim=2) / ctx.constant
return grad_num, None
class Dequantization(torch.autograd.Function):
@staticmethod
def forward(ctx, x, B):
ctx.constant = B
step = 2 ** B
out = Bit2Num(x, B)
out = (out + 0.5) / step
return out
@staticmethod
def backward(ctx, grad_output):
# return as many input gradients as there were arguments.
# Gradients of non-Tensor arguments to forward must be None.
# repeat the gradient of a Num for B time.
b, c = grad_output.shape
grad_output = grad_output.unsqueeze(2) / ctx.constant
grad_bit = grad_output.expand(b, c, ctx.constant)
return torch.reshape(grad_bit, (-1, c * ctx.constant)), None
class QuantizationLayer(nn.Module):
def __init__(self, B):
super(QuantizationLayer, self).__init__()
self.B = B
def forward(self, x):
out = Quantization.apply(x, self.B)
return out
class DequantizationLayer(nn.Module):
def __init__(self, B):
super(DequantizationLayer, self).__init__()
self.B = B
def forward(self, x):
out = Dequantization.apply(x, self.B)
return out
# =======================================================================================================================
# =======================================================================================================================
# Encoder and Decoder Class Defining
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class SEBlock(nn.Module):
def __init__(self, input_channels, internal_neurons):
super(SEBlock, self).__init__()
self.down = nn.Conv2d(in_channels=input_channels, out_channels=internal_neurons, kernel_size=1, stride=1,
bias=True, padding_mode='circular')
self.up = nn.Conv2d(in_channels=internal_neurons, out_channels=input_channels, kernel_size=1, stride=1,
bias=True, padding_mode='circular')
def forward(self, inputs):
x = F.avg_pool2d(inputs, kernel_size=inputs.size(3))
x = self.down(x)
x = F.leaky_relu(x)
x = self.up(x)
x = torch.sigmoid(x)
x = x.repeat(1, 1, inputs.size(2), inputs.size(3))
return inputs * x
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = ACT
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.att = SEBlock(c2, c2 // 2)
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.att(self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1)))))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
self.att = SEBlock(c2, c2 // 2)
def forward(self, x):
return self.att(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)))
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
class Contract(nn.Module):
# Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
N, C, H, W = x.size() # assert (H / s == 0) and (W / s == 0), 'Indivisible gain'
s = self.gain
x = x.view(N, C, H // s, s, W // s, s) # x(1,64,40,2,40,2)
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
return x.view(N, C * s * s, H // s, W // s) # x(1,256,40,40)
class Expand(nn.Module):
# Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
def __init__(self, c1, c2, gain=2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.gain = gain
self.conv = Conv(c1 // 4, c2, k, s, p, g, act)
def forward(self, x):
N, C, H, W = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
s = self.gain
x = x.view(N, s, s, C // s ** 2, H, W) # x(1,2,2,16,80,80)
x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
return self.conv(x.view(N, C // s ** 2, H * s, W * s)) # x(1,16,160,160)
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=True)
class WLBlock(nn.Module):
def __init__(self, paths, in_c, k=16, n=[1, 1], e=[1.0, 1.0], quantization=True):
super(WLBlock, self).__init__()
self.paths = paths
self.n = n
self.e = e
self.k = k
self.in_c = in_c
for i in range(self.paths):
self.__setattr__(str(i), nn.Sequential(OrderedDict([
("Conv0", Conv(self.in_c, self.k, 3)),
("BCSP_1", BottleneckCSP(self.k, self.k, n=self.n[i], e=self.e[i])),
("C3_1", C3(self.k, self.k, n=self.n[i], e=self.n[i])),
("Conv1", Conv(self.k, self.k, 3)),
])))
self.conv1 = conv3x3(self.k * self.paths, self.k)
def forward(self, x):
outs = []
for i in range(self.paths):
_ = self.__getattr__(str(i))(x)
outs.append(_)
out = torch.cat(tuple(outs), dim=1)
out = self.conv1(out)
out = out + x if self.in_c == self.k else out
return out
class Encoder(nn.Module):
B = 3
def __init__(self, feedback_bits, quantization=True):
super(Encoder, self).__init__()
self.feedback_bits = feedback_bits
self.k = 256
self.encoder1 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 16, 5)),
("BCSP_1", BottleneckCSP(16, 16, n=2, e=0.5)),
("C3_1", C3(16, 16, n=1, e=2.0)),
("Conv1", Conv(16, self.k, 3))
]))
self.encoder2 = nn.Sequential(OrderedDict([
("Focus0", Focus(2, 16)),
("BCSP_1", BottleneckCSP(16, 16, n=1, e=1.0)),
("C3_1", C3(16, 16, n=2, e=2.0)),
("Expand0", Expand(16, 16)),
("Conv1", Conv(16, self.k, 3))
]))
self.encoder3 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 32, 3)),
("WLBlock1", WLBlock(3, 32, 32, [1, 2, 3], [0.5, 1, 1.5])),
("WLBlock2", WLBlock(2, 32, 32, [2, 4], [1, 2])),
("Conv1", Conv(32, self.k, 3)),
]))
self.encoder_conv = nn.Sequential(OrderedDict([
("conv1x1", Conv(self.k * 3, 2, 1)),
]))
self.fc = nn.Linear(768, int(NUM_FEEDBACK_BITS_STARTS / self.B))
self.dim_verify = nn.Linear(int(NUM_FEEDBACK_BITS_STARTS / self.B), int(self.feedback_bits / self.B))
self.sig = nn.Sigmoid()
self.quantize = QuantizationLayer(self.B)
self.quantization = quantization
def forward(self, x):
if channel_last:
x = x.permute(0, 3, 1, 2).contiguous()
x0 = x.view(-1, 768)
encoder1 = self.encoder1(x)
encoder2 = self.encoder2(x)
encoder3 = self.encoder3(x)
out = torch.cat((encoder1, encoder2, encoder3), dim=1)
out = self.encoder_conv(out)
out = out.view(-1, 768) + x0
out = self.fc(out)
out = self.dim_verify(out)
out = self.sig(out)
enq_data = out
if self.quantization:
out = self.quantize(out)
elif self.quantization == 'check':
out = out
else:
out = self.fake_quantize(out)
return out, enq_data
class Decoder(nn.Module):
B = 3
def __init__(self, feedback_bits, quantization=True):
super(Decoder, self).__init__()
self.k = 64
self.feedback_bits = feedback_bits
self.dequantize = DequantizationLayer(self.B)
self.dim_verify = nn.Linear(int(self.feedback_bits / self.B), int(NUM_FEEDBACK_BITS_STARTS / self.B))
self.fc = nn.Linear(int(NUM_FEEDBACK_BITS_STARTS / self.B), 768)
self.ende_refinement = nn.Sequential(
nn.Linear(int(self.feedback_bits / self.B), int(self.feedback_bits / self.B)),
nn.BatchNorm1d(int(self.feedback_bits / self.B)),
nn.ReLU(True),
nn.Linear(int(self.feedback_bits / self.B), int(self.feedback_bits / self.B), bias=False),
nn.Sigmoid(),
)
self.decoder1 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 16, 3)),
("BCSP_1", BottleneckCSP(16, 16, n=1, e=1.0)),
("Conv1", Conv(16, self.k, 1)),
]))
self.decoder2 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 32, 5)),
("BCSP_1", BottleneckCSP(32, 32, n=4, e=2.0)),
("Conv1", Conv(32, self.k, 1)),
]))
self.decoder3 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 32, (1, 3))),
("BCSP_1", BottleneckCSP(32, 32, n=4, e=2.0)),
("Conv1", Conv(32, self.k, 1)),
]))
self.decoder4 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 32, (3, 1))),
("BCSP_1", BottleneckCSP(32, 32, n=4, e=2.0)),
("Conv1", Conv(32, self.k, 1)),
]))
self.decoder5 = nn.Sequential(OrderedDict([
("Focus0", Focus(2, self.k)),
("WLBlock1", WLBlock(3, self.k, self.k, [1, 2, 3], [0.5, 1, 1.5])),
("WLBlock2", WLBlock(2, self.k, self.k, [2, 4], [1, 2])),
("Expand0", Expand(self.k, self.k)),
("Conv1", Conv(self.k, self.k, 1)),
]))
self.decoder6 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 32, (3, 5))),
("BCSP_1", BottleneckCSP(32, 32, n=4, e=2.0)),
("Conv1", Conv(32, self.k, 5)),
]))
self.decoder7 = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 32, (5, 3))),
("BCSP_1", BottleneckCSP(32, 32, n=4, e=2.0)),
("Conv1", Conv(32, self.k, 3)),
]))
self.decoder8 = nn.Sequential(OrderedDict([
("Focus0", Focus(2, self.k, 5)),
("WLBlock1", WLBlock(2, self.k, self.k, [1, 2], [0.5, 1])),
("WLBlock2", WLBlock(2, self.k, self.k, [1, 2], [1, 0.5])),
("Expand0", Expand(self.k, self.k)),
("Conv1", Conv(self.k, self.k, 5)),
]))
if REFINEMENT:
self.refinemodel = nn.Sequential(OrderedDict([
("Conv0", Conv(2, 64, 3)),
("WLBlock1", WLBlock(3, 64, 64, [1, 2, 3], [0.5, 1, 1.5])),
("WLBlock2", WLBlock(2, 64, 64, [2, 4], [1, 2])),
("WLBlock3", WLBlock(2, 64, 64, [2, 4], [1, 2])),
("WLBlock4", WLBlock(2, 64, 64, [1, 3], [1, 2])),
("Conv1", Conv(64, 2, 3)),
]))
self.decoder_conv = conv3x3(self.k * 8, 2)
self.sig = nn.Sigmoid()
self.quantization = quantization
def forward(self, x):
if self.quantization:
out = self.dequantize(x)
else:
out = x
out = out.view(-1, int(self.feedback_bits / self.B))
out_error = self.ende_refinement(out)
out = out + out_error - 0.5
deq_data = out
out = self.dim_verify(out)
out = self.sig(self.fc(out))
out = out.view(-1, 2, 24, 16)
out0 = out
out1 = self.decoder1(out)
out2 = self.decoder2(out)
out3 = self.decoder3(out)
out4 = self.decoder4(out)
out5 = self.decoder5(out)
out6 = self.decoder6(out)
out7 = self.decoder7(out)
out8 = self.decoder8(out)
out = torch.cat((out1, out2, out3, out4, out5, out6, out7, out8), dim=1)
out = self.decoder_conv(out) + out0
out = self.sig(out)
if REFINEMENT:
out = self.sig(self.refinemodel(out)) - 0.5 + out
if channel_last:
out = out.permute(0, 2, 3, 1)
return out, deq_data
class AutoEncoder(nn.Module):
def __init__(self, feedback_bits):
super(AutoEncoder, self).__init__()
self.encoder = Encoder(feedback_bits)
self.decoder = Decoder(feedback_bits)
def forward(self, x):
feature, enq_data = self.encoder(x)
out, deq_data = self.decoder(feature)
return out, feature, enq_data, deq_data
# =======================================================================================================================
# =======================================================================================================================
# NMSE Function Defining
def NMSE(x, x_hat):
x_real = np.reshape(x[:, :, :, 0], (len(x), -1))
x_imag = np.reshape(x[:, :, :, 1], (len(x), -1))
x_hat_real = np.reshape(x_hat[:, :, :, 0], (len(x_hat), -1))
x_hat_imag = np.reshape(x_hat[:, :, :, 1], (len(x_hat), -1))
x_C = x_real - 0.5 + 1j * (x_imag - 0.5)
x_hat_C = x_hat_real - 0.5 + 1j * (x_hat_imag - 0.5)
power = np.sum(abs(x_C) ** 2, axis=1)
mse = np.sum(abs(x_C - x_hat_C) ** 2, axis=1)
nmse = np.mean(mse / power)
return nmse
def Score(NMSE):
score = 1 - NMSE
return score
def NMSE_cuda(x, x_hat):
x_real = x[:, 0, :, :].view(len(x), -1) - 0.5
x_imag = x[:, 1, :, :].view(len(x), -1) - 0.5
x_hat_real = x_hat[:, 0, :, :].view(len(x_hat), -1) - 0.5
x_hat_imag = x_hat[:, 1, :, :].view(len(x_hat), -1) - 0.5
power = torch.sum(x_real ** 2 + x_imag ** 2, axis=1)
mse = torch.sum((x_real - x_hat_real) ** 2 + (x_imag - x_hat_imag) ** 2, axis=1)
nmse = mse / power
return nmse
class NMSELoss(nn.Module):
def __init__(self, reduction='sum'):
super(NMSELoss, self).__init__()
self.reduction = reduction
def forward(self, x_hat, x):
nmse = NMSE_cuda(x, x_hat)
if self.reduction == 'mean':
nmse = torch.mean(nmse)
else:
nmse = torch.sum(nmse)
return nmse
# =======================================================================================================================
# =======================================================================================================================
import random
# Data Loader Class Defining
class DatasetFolder(Dataset):
def __init__(self, matData, phase='val'):
self.matdata = matData
self.phase = phase
def __getitem__(self, index):
y = self.matdata[index]
if self.phase == 'train' and random.random() < -0.5:
y = y[::-1, :, :].copy()
if self.phase == 'train' and random.random() < 0.5:
y = y[:, ::-1, :].copy()
if self.phase == 'train' and random.random() < 0.5:
y = 1 - self.matdata[index] # There is a similar orthogonal relationship in the data
if self.phase == 'train' and random.random() < 0.5:
_ = y
_[:, :, 0] = y[:, :, 1]
_[:, :, 1] = y[:, :, 0]
y = _ # The real and imaginary parts of data at different times are equal
if self.phase == 'train' and random.random() < 0.5:
index_ = random.randint(0, self.matdata.shape[0] // 3000 - 1) * 3000 + index % 3000
p = random.random()
rows = max(int(24 * p), 1)
_rows = [i for i in range(24)]
random.shuffle(_rows)
_rows = _rows[:rows]
if random.random() < 0.7:
y[_rows] = self.matdata[index_][_rows] # Different sampling points are merged by row to maintain the unique characteristics of sampling points and reduce the dependence of the model on 24 dimensions
else:
y = (1 - p * 0.2) * y + (p * 0.2) * self.matdata[index_] # Increase numerical disturbance and maintain the unique characteristics of sampling points
return y
def __len__(self):
return self.matdata.shape[0]
modelTrain.py
#=======================================================================================================================
#=======================================================================================================================
import numpy as np
import torch
from modelDesign import AutoEncoder,DatasetFolder,NUM_FEEDBACK_BITS,NUM_FEEDBACK_BITS_STARTS,NMSELoss,channel_last #*
import os
import torch.nn as nn
import scipy.io as sio
import random
from torch.cuda.amp import autocast, GradScaler
def NMSE_cuda1(x, x_hat):
x_real = x[:, :, :, 0].view(len(x),-1) - 0.5
x_imag = x[:, :, :, 1].view(len(x),-1) - 0.5
x_hat_real = x_hat[:, :, :, 0].view(len(x_hat), -1) - 0.5
x_hat_imag = x_hat[:, :, :, 1].view(len(x_hat), -1) - 0.5
power = torch.sum(x_real**2 + x_imag**2, axis=1)
mse = torch.sum((x_real-x_hat_real)**2 + (x_imag-x_hat_imag)**2, axis=1)
nmse = mse/power
return nmse
class NMSELoss1(nn.Module):
def __init__(self, reduction='sum'):
super(NMSELoss1, self).__init__()
self.reduction = reduction
def forward(self, x_hat, x):
nmse = NMSE_cuda1(x, x_hat)
if self.reduction == 'mean':
nmse = torch.mean(nmse)
else:
nmse = torch.sum(nmse)
return nmse
#=======================================================================================================================
#=======================================================================================================================
# Parameters Setting for Data
CHANNEL_SHAPE_DIM1 = 24
CHANNEL_SHAPE_DIM2 = 16
CHANNEL_SHAPE_DIM3 = 2
# Parameters Setting for Training
BATCH_SIZE = 64
EPOCHS = 1000
LEARNING_RATE = 1e-5
PRINT_RREQ = 100
#NUM_FEEDBACK_BITS =NUM_FEEDBACK_BITS_3
torch.manual_seed(42)
random.seed(42)
#=======================================================================================================================
#=======================================================================================================================
def load_pretrained_weights(model,model_path):
encoder_pretrained = torch.load(model_path)['state_dict']
model_dict = model.state_dict()
#pretrained_weights ={k:v for k,v in encoder_pretrained.items() if (k in model_dict and 'dim_verify' not in k and 'ende_refinement' not in k and 'fc' not in k)}
pretrained_weights ={k:v for k,v in encoder_pretrained.items() if (k in model_dict )}
# prune dim_verify layer
if 0 and NUM_FEEDBACK_BITS != NUM_FEEDBACK_BITS_STARTS:
w = encoder_pretrained['dim_verify.weight']
b = encoder_pretrained['dim_verify.bias']
if model_dict['dim_verify.weight'].shape[0] != encoder_pretrained['dim_verify.weight'].shape[0]:
dim = -1
bits_num =model_dict['dim_verify.weight'].shape[0]
long = encoder_pretrained['dim_verify.weight'].shape[0]
else:
dim = 0
bits_num =model_dict['dim_verify.weight'].shape[1]
long = encoder_pretrained['dim_verify.weight'].shape[1]
#importance = abs(w).sum(dim)
#sorted_index = torch.argsort(-1*importance) # descend
start = (long -bits_num)//2
end = bits_num + (long - bits_num)//2
if dim == -1:
pretrained_weights['dim_verify.weight'] = w[start:end,:]
else:
pretrained_weights['dim_verify.weight'] = w[:,start:end]
model_dict.update(pretrained_weights)
model.load_state_dict(model_dict)
return model
# Model Constructing
autoencoderModel = AutoEncoder(NUM_FEEDBACK_BITS)
# model_path = './modelSubmit/encoder.pth.tar'
# autoencoderModel.encoder =load_pretrained_weights(autoencoderModel.encoder,model_path)
# model_path = './modelSubmitTeacher/decoder.pth.tar'
# autoencoderModel.decoder =load_pretrained_weights(autoencoderModel.decoder,model_path)
model_path = './modelSubmit/encoder.pth.tar'
autoencoderModel.encoder.load_state_dict(torch.load(model_path)['state_dict'])
model_path = './modelSubmit/decoder.pth.tar'
autoencoderModel.decoder.load_state_dict(torch.load(model_path)['state_dict'])
#=======================================================================================================================
#=======================================================================================================================
# Data Loading
mat = sio.loadmat('channelData/H_4T4R.mat')
data = mat['H_4T4R']
data = data.astype('float32')
data = np.reshape(data, (-1, CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
if not channel_last:
data = np.transpose(data, (0, 3, 1, 2))
#random.shuffle(data)
split = int(data.shape[0] * 0.95)
data_train0, data_test = data[:split], data[split:]
random.shuffle(data_train0)
split = int(data_train0.shape[0]*0.95)
data_train, data_val = data_train0[:split],data_train0[split:]
train_dataset = DatasetFolder(data_train0,'train')
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True)
val_dataset = DatasetFolder(data_val,'val')
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
test_dataset = DatasetFolder(data_test,'val')
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
#=======================================================================================================================
#=======================================================================================================================
#autoencoderModel = autoencoderModel.cuda()
autoencoderModel = torch.nn.DataParallel(autoencoderModel.cuda())
ctl = NMSELoss1(reduction='mean') if channel_last else NMSELoss(reduction='mean')
criterion = ctl #nn.MSELoss()
criterion_test = ctl
feature_criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(autoencoderModel.parameters(), lr=LEARNING_RATE)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, T_mult=1, eta_min=1e-9, last_epoch=-1)
#=======================================================================================================================
#=======================================================================================================================
# Model Training and Saving
bestLoss = 0.105
valLoss = 1e-5
for epoch in range(EPOCHS):
scaler = GradScaler()
print('lr:',optimizer.param_groups[0]['lr'])
autoencoderModel.train()
for i, autoencoderInput in enumerate(train_loader):
autoencoderInput = autoencoderInput.cuda()
with autocast():
autoencoderOutput,_, enq, deq = autoencoderModel(autoencoderInput)
loss1 = criterion(autoencoderOutput, autoencoderInput)
loss2 = feature_criterion(enq, deq)
loss = loss1+0*loss2
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
if i % PRINT_RREQ == 0:
print('Epoch: [{0}][{1}/{2}]\t' 'Loss {loss:.4f}\t,Loss_nmse {loss_nmse:.4f}\t,Loss ende {loss_q:.4f}\t'.format(epoch,
i, len(train_loader), loss=loss.item(),loss_nmse=loss1.item(),loss_q=loss2.item()))
# if (i+1) % (4*PRINT_RREQ) == 0:
# break
# Model Evaluating
autoencoderModel.eval()
totalLoss = 0
hist =0
with torch.no_grad():
for i, autoencoderInput in enumerate(val_loader):
autoencoderInput = autoencoderInput.cuda()
autoencoderOutput, feature, enq, deq = autoencoderModel(autoencoderInput)
hist = hist+feature.sum(0)/autoencoderInput.shape[0]
totalLoss += criterion_test(autoencoderOutput, autoencoderInput).item()*autoencoderInput.shape[0]
averageLoss = totalLoss / len(test_dataset)
loss2 = feature_criterion(enq, deq)
print('==random split test step==')
print(np.std(hist.cpu().numpy()))
print(averageLoss,loss2.item())
valavgloss = averageLoss
totalLoss = 0
hist =0
with torch.no_grad():
for i, autoencoderInput in enumerate(test_loader):
autoencoderInput = autoencoderInput.cuda()
autoencoderOutput, feature, enq, deq = autoencoderModel(autoencoderInput)
hist = hist+feature.sum(0)/autoencoderInput.shape[0]
totalLoss += criterion_test(autoencoderOutput, autoencoderInput).item()*autoencoderInput.shape[0]
averageLoss = totalLoss / len(test_dataset)
loss2 = feature_criterion(enq, deq)
print('==last split test step==')
print(np.std(hist.cpu().numpy()))
print(averageLoss,loss2.item())
if averageLoss < bestLoss:
# Model saving
# Encoder Saving
torch.save({'state_dict': autoencoderModel.module.encoder.state_dict(), }, './modelSubmit/encoder.pth.tar')
# Decoder Saving
torch.save({'state_dict': autoencoderModel.module.decoder.state_dict(), }, './modelSubmit/decoder.pth.tar')
print("Model saved,avgloss:",averageLoss)
bestLoss = averageLoss
valLoss = valavgloss
print('==show best==')
print('valloss:', valLoss, 'testloss:',bestLoss)
if epoch>0*50:
scheduler.step()
#break
#=======================================================================================================================
#=======================================================================================================================