@[toc]
Air flow FAQ
Installation problem
1. ERROR "Python setup. Py XXX" appears during installation.
Question:
First, you need to update pip Version required'pip install --upgrade pip' command.
Second is setuptools The version is too old, so there are the following problems Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-G9yO9Z/tldr/,You need to update
File "/tmp/pip-build-G9yO9Z/tldr/setuptools_scm-3.3.3-py2.7.egg/setuptools_scm/integration.py", line 9, in version_keyword File "/tmp/pip-build-G9yO9Z/tldr/setuptools_scm-3.3.3-py2.7.egg/setuptools_scm/version.py", line 66, in _warn_if_setuptools_outdated setuptools_scm.version.SetuptoolsOutdatedWarning: your setuptools is too old (<12)
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-G9yO9Z/tldr/
You are using pip version 8.1.2, however version 19.2.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
#####Solution:
>(1) Use the "pip install - upgrade pip" command to upgrade the pip version.
>   [xiaokang@localhost ~]$ sudo pip install --upgrade pip
>(2) Use the "pip install --upgrade setuptools" command to upgrade the setuptools version.
>   [xiaokang@localhost ~]$ sudo pip install --upgrade setuptools
>After solving the above problems, you can successfully install the previous software
#### 2,ERROR: Cannot uninstall 'enum34' .
#####Question:
```python
During the installation of Airflow, the following error occurred:
ERROR: Cannot uninstall 'enum34'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.resolvent:
sudo pip install --ignore-installed enum34
When there are other errors that cannot be upgraded, you can use the following command format to force the upgrade:
sudo PIP install -- ignore installed + module name
3. Installation software reports an error, indicating that the package cannot be found
Problem: error: Command erred out with exit status 1:

ERROR: Command errored out with exit status 1:
command: /usr/bin/python -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-oZ2zgF/flask-appbuilder/setup.py'"'"'; __file__='"'"'/tmp/pip-install-oZ2zgF/flask-appbuilder/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-install-oZ2zgF/flask-appbuilder/pip-egg-info
cwd: /tmp/pip-install-oZ2zgF/flask-appbuilder/
Complete output (3 lines):
/usr/lib64/python2.7/distutils/dist.py:267: UserWarning: Unknown distribution option: 'long_description_content_type'
warnings.warn(msg)
error in Flask-AppBuilder setup command: 'install_requires' must be a string or list of strings containing valid project/version requirement specifiers
----------------------------------------
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
resolvent:
Check the installation command. Generally, this kind of problem occurs because the installation package cannot be found.
4. Prompt: Python.h cannot be found
Question: src/spt_python.h:14:20: fatal error: Python.h: No such file or directory
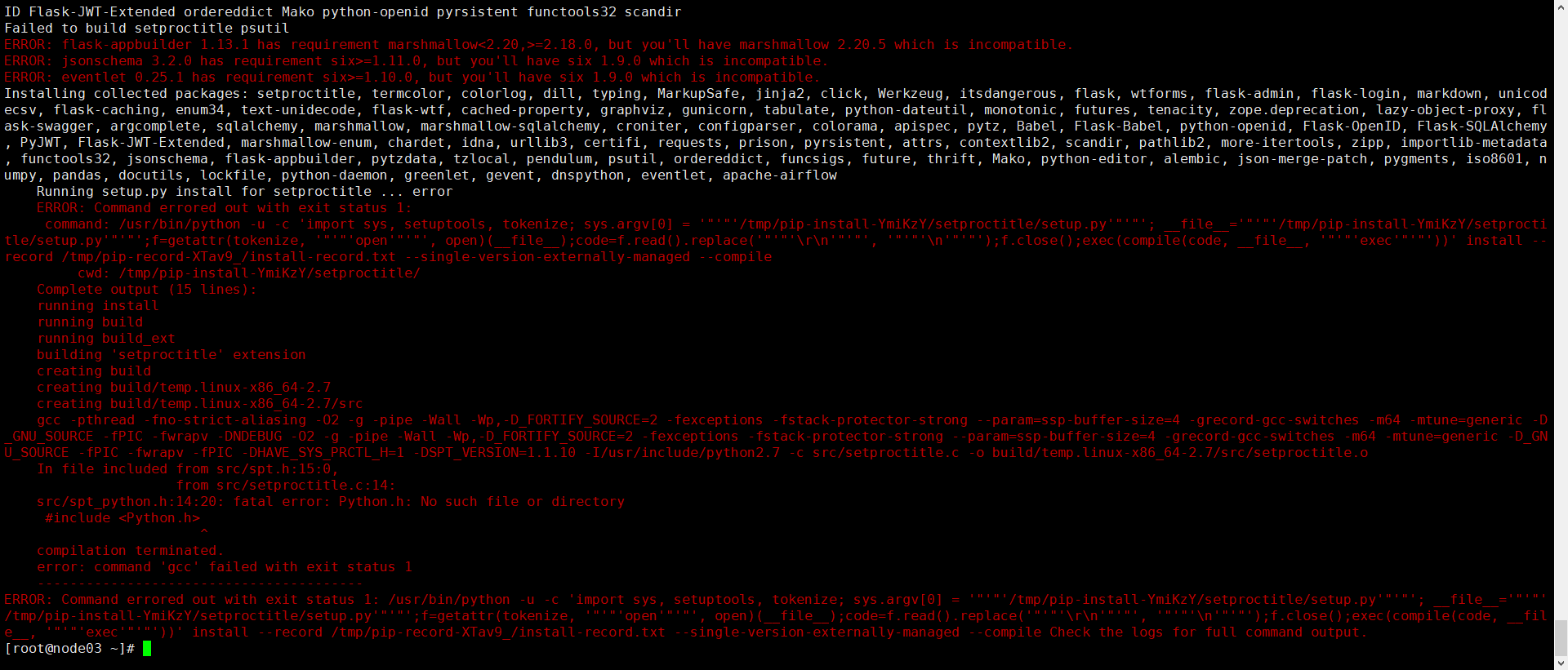
ERROR: Command errored out with exit status 1:
command: /usr/bin/python -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-YmiKzY/setproctitle/setup.py'"'"'; __file__='"'"'/tmp/pip-install-YmiKzY/setproctitle/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-XTav9_/install-record.txt --single-version-externally-managed --compile
cwd: /tmp/pip-install-YmiKzY/setproctitle/
Complete output (15 lines):
running install
running build
running build_ext
building 'setproctitle' extension
creating build
creating build/temp.linux-x86_64-2.7
creating build/temp.linux-x86_64-2.7/src
gcc -pthread -fno-strict-aliasing -O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -D_GNU_SOURCE -fPIC -fwrapv -DNDEBUG -O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -D_GNU_SOURCE -fPIC -fwrapv -fPIC -DHAVE_SYS_PRCTL_H=1 -DSPT_VERSION=1.1.10 -I/usr/include/python2.7 -c src/setproctitle.c -o build/temp.linux-x86_64-2.7/src/setproctitle.o
In file included from src/spt.h:15:0,
from src/setproctitle.c:14:
src/spt_python.h:14:20: fatal error: Python.h: No such file or directory
#include <Python.h>
^
compilation terminated.
error: command 'gcc' failed with exit status 1
----------------------------------------
ERROR: Command errored out with exit status 1: /usr/bin/python -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-YmiKzY/setproctitle/setup.py'"'"'; __file__='"'"'/tmp/pip-install-YmiKzY/setproctitle/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-XTav9_/install-record.txt --single-version-externally-managed --compile Check the logs for full command output.resolvent:
Because of the lack of python development package, yum install python devel installation can solve this problem
dag problem
1. bash_command='/root/touch.sh' execute command error.
Question:
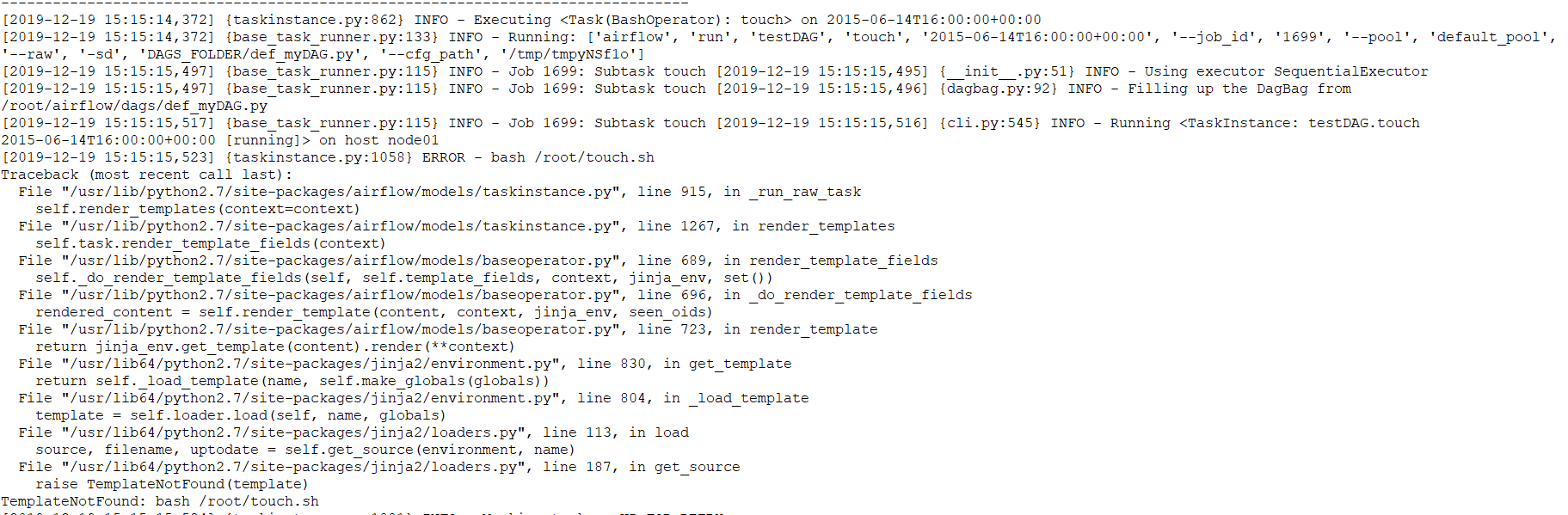
[2019-12-19 15:15:15,523] {taskinstance.py:1058} ERROR - bash /root/touch.sh
Traceback (most recent call last):
File "/usr/lib/python2.7/site-packages/airflow/models/taskinstance.py", line 915, in _run_raw_task
self.render_templates(context=context)
File "/usr/lib/python2.7/site-packages/airflow/models/taskinstance.py", line 1267, in render_templates
self.task.render_template_fields(context)
File "/usr/lib/python2.7/site-packages/airflow/models/baseoperator.py", line 689, in render_template_fields
self._do_render_template_fields(self, self.template_fields, context, jinja_env, set())
File "/usr/lib/python2.7/site-packages/airflow/models/baseoperator.py", line 696, in _do_render_template_fields
rendered_content = self.render_template(content, context, jinja_env, seen_oids)
File "/usr/lib/python2.7/site-packages/airflow/models/baseoperator.py", line 723, in render_template
return jinja_env.get_template(content).render(**context)
File "/usr/lib64/python2.7/site-packages/jinja2/environment.py", line 830, in get_template
return self._load_template(name, self.make_globals(globals))
File "/usr/lib64/python2.7/site-packages/jinja2/environment.py", line 804, in _load_template
template = self.loader.load(self, name, globals)
File "/usr/lib64/python2.7/site-packages/jinja2/loaders.py", line 113, in load
source, filename, uptodate = self.get_source(environment, name)
File "/usr/lib64/python2.7/site-packages/jinja2/loaders.py", line 187, in get_source
raise TemplateNotFound(template)
TemplateNotFound: bash /root/touch.shSolution: add an extra space after the executed command
a trap caused by airflow using jinja2 as the template engine, when using bash command, a space must be added at the end
airflow
1. Error in starting worker
Question:
Running a worker with superuser privileges when the worker accepts messages serialized with pickle is a very bad idea! If you really want to continue then you have to set the C_FORCE_ROOT environment variable (but please think about this before you do).
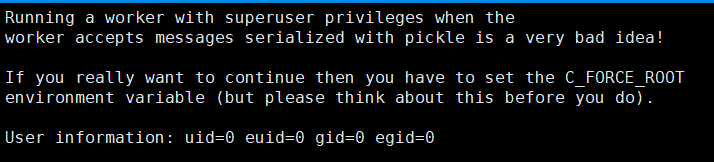
resolvent:
Add export C "force" root = "true" in / etc/profile
2. How to batch unpause a large number of dag tasks in airflow
A small number of common tasks can be started by the command "airflow unpause dag" ID, or by clicking the start button in the web interface, but when there are too many tasks, it is more difficult to start one by one. In fact, dag information is stored in the database. You can modify the database information in batch to achieve the effect of starting dag task in batch. If mysql is used as SQL ABCD alchemy ABCD Conn, you only need to log in to the airflow database, and then update the is ABCD used field of the dag table to 0 to start the dag task.
Example: update DAG set is "used = 0 where DAG" Id like "benchmark%";
3. The scheduler process of airflow suspends to enter the pseudo dead state after executing a task
The general reason for this is that the scheduler generated the task but could not publish it. There is no error message in the log.
The possible cause is that the Borker connection dependency library is not installed:
If redis is the broker, pip install apache ‐ airflow[redis]
If rabbitmq is the broker, PIP install Apache airflow [rabbitmq]
Also check whether the scheduler node can access rabbitmq normally.
4. When there are too many dag files defined, the scheduler node of airflow is slow to run
airflow Of scheduler By default, there are two threads. You can modify the configuration file airflow.cfg Improvement:
[scheduler] # The scheduler can run multiple threads in parallel to schedule dags. # This defines how many threads will run. #The default is 2. Here it's 100 max_threads = 100
5. airflow log level change
vi airflow.cfg [core] #logging_level = INFO logging_level = WARNING
NOTSET < DEBUG < INFO < WARNING < ERROR < CRITICAL
If the level of log is set to INFO, no log less than INFO level will be output, and no log greater than or equal to INFO level will be output. In other words, the higher the log level, the less detailed the printed log. The default log level is WARNING.
Note: if you change logging [level] to WARNING or above, not only the log, but also the command-line output details will be affected, and only the information greater than or equal to the specified level will be output. Therefore, if the command-line output information is incomplete and the system has no error log output, it means that the log level is too high.
6,AirFlow: jinja2.exceptions.TemplateNotFound
This is a trap caused by airflow using jinja2 as the template engine. When using bash command, a space must be added at the end:
- Described here : see below. You need to add a space after the script name in cases where you are directly calling a bash scripts in the bash_command attribute of BashOperator - this is because the Airflow tries to apply a Jinja template to it, which will fail.
t2 = BashOperator( task_id='sleep', bash_command="/home/batcher/test.sh", // This fails with `Jinja template not found` error #bash_command="/home/batcher/test.sh ", // This works (has a space after) dag=dag)
7,AirFlow: Task is not able to be run
The task cannot be executed after a period of time. The background worker log displays the following prompt:
[2018-05-25 17:22:05,068] {jobs.py:2508} INFO - Task is not able to be runTo view the execution log corresponding to a task:
cat /home/py/airflow-home/logs/testBashOperator/print_date/2018-05-25T00:00:00/6.log
...
[2018-05-25 17:22:05,067] {models.py:1190} INFO - Dependencies not met for <TaskInstance: testBashOperator.print_date 2018-05-25 00:00:00 [success]>,
dependency 'Task Instance State' FAILED: Task is in the 'success' state which is not a valid state for execution. The task must be cleared in order to be run.According to the error prompt, it indicates that the dependent task status fails. There are two solutions to this situation:
Specify to ignore dependent tasks when running tasks with airflow run:
$ airflow run -A dag_id task_id execution_date
Use the command "airflow clear DAG" ID to clean up the task:
$ airflow clear -u testBashOperator
8. After upgrading cell 4. X, use rabbitmq to throw the following exception for the broker running task:
[2018-06-29 09:32:14,622: CRITICAL/MainProcess] Unrecoverable error: PreconditionFailed(406, "PRECONDITION_FAILED - inequivalent arg 'x-expires' for queue 'celery@PQ
SZ-L01395.celery.pidbox' in vhost '/': received the value '10000' of type 'signedint' but current is none", (50, 10), 'Queue.declare')
Traceback (most recent call last):
File "c:\programdata\anaconda3\lib\site-packages\celery\worker\worker.py", line 205, in start
self.blueprint.start(self)
.......
File "c:\programdata\anaconda3\lib\site-packages\amqp\channel.py", line 277, in _on_close
reply_code, reply_text, (class_id, method_id), ChannelError,
amqp.exceptions.PreconditionFailed: Queue.declare: (406) PRECONDITION_FAILED - inequivalent arg 'x-expires' for queue 'celery@PQSZ-L01395.celery.pidbox' in vhost '/'
: received the value '10000' of type 'signedint' but current is noneThe reason for this error is generally because the parameters of rabbitmq's client and server are inconsistent. Just keep the parameters consistent.
For example, the prompt here is that the configuration in the cell ry corresponding to x-expires is control queue expires. So just add control queue expires = none to the configuration file.
There are no such two configurations in cellery 3. X. the consistency of these two configurations must be guaranteed in 4.x, or the above exception will be thrown.
The mapping relationship between the configuration of rabbitmq and the configuration of cellery is as follows:
| rabbitmq | celery4.x |
|---|---|
| x-expires | control_queue_expires |
| x-message-ttl | control_queue_ttl |
9,CELERY: The AMQP result backend is scheduled for deprecation in version 4.0 and removal in version v5.0.Please use RPC backend or a persistent backend
After upgrading cellery to 4.x, run and throw the following exception:
/anaconda/anaconda3/lib/python3.6/site-packages/celery/backends/amqp.py:67: CPendingDeprecationWarning:
The AMQP result backend is scheduled for deprecation in version 4.0 and removal in version v5.0. Please use RPC backend or a persistent backend.
alternative='Please use RPC backend or a persistent backend.')Reason analysis:
In cellery 4.0, rabbitmq configures the result ﹣ backend mode to change:
It used to be the same as broker: result_backend ='amqp: / / guest: guest @ localhost: 5672 / / '
Now it corresponds to RPC configuration: result_backend ='rpc: / / '
Reference link: http://docs.celeryproject.org/en/latest/userguide/configuration.html#std:setting-event_queue_prefix
10,CELERY: ValueError('not enough values to unpack (expected 3, got 0)',)
Running cellery 4. X on windows throws the following error:
[2018-07-02 10:54:17,516: ERROR/MainProcess] Task handler raised error: ValueError('not enough values to unpack (expected 3, got 0)',)
Traceback (most recent call last):
......
tasks, accept, hostname = _loc
ValueError: not enough values to unpack (expected 3, got 0)celery 4.x Temporarily not supported windows Platform, if for debugging purposes, can be replaced by celery The implementation of thread pool in windows Purpose of operation on the platform:
pip install eventlet celery -A <module> worker -l info -P eventlet
Reference link:
https://stackoverflow.com/questions/45744992/celery-raises-valueerror-not-enough-values-to-unpack
https://blog.csdn.net/qq_30242609/article/details/79047660
11,Airflow: ERROR - 'DisabledBackend' object has no attribute '_get_task_meta_for'
airflow The following exception is thrown during operation:
Traceback (most recent call last): File "/anaconda/anaconda3/lib/python3.6/site-packages/airflow/executors/celery_executor.py", line 83, in sync ...... return self._maybe_set_cache(self.backend.get_task_meta(self.id)) File "/anaconda/anaconda3/lib/python3.6/site-packages/celery/backends/base.py", line 307, in get_task_meta meta = self._get_task_meta_for(task_id) AttributeError: 'DisabledBackend' object has no attribute '_get_task_meta_for' [2018-07-04 10:52:14,746] {celery_executor.py:101} ERROR - Error syncing the celery executor, ignoring it: [2018-07-04 10:52:14,746] {celery_executor.py:102} ERROR - 'DisabledBackend' object has no attribute '_get_task_meta_for'
There are two possible reasons for this error:
- There is no configuration or configuration error for the cell? Result? Backend attribute;
- The version of celery is too low. For example, celery4.x should be used in airflow 1.9.0. Therefore, check the version of celery to keep the version compatible;
12,airflow.exceptions.AirflowException dag_id could not be found xxxx. Either the dag did not exist or it failed to parse
See worker Journal airflow-worker.err
airflow.exceptions.AirflowException: dag_id could not be found: bmhttp. Either the dag did not exist or it failed to parse. [2018-07-31 17:37:34,191: ERROR/ForkPoolWorker-6] Task airflow.executors.celery_executor.execute_command[181c78d0-242c-4265-aabe-11d04887f44a] raised unexpected: AirflowException('Celery command failed',) Traceback (most recent call last): File "/anaconda/anaconda3/lib/python3.6/site-packages/airflow/executors/celery_executor.py", line 52, in execute_command subprocess.check_call(command, shell=True) File "/anaconda/anaconda3/lib/python3.6/subprocess.py", line 291, in check_call raise CalledProcessError(retcode, cmd) subprocess.CalledProcessError: Command 'airflow run bmhttp get_op1 2018-07-26T06:28:00 --local -sd /home/ignite/airflow/dags/BenchMark01.py' returned non-zero exit status 1.
According to the Command information in the exception log, when the scheduling node generates the task message, it also specifies the path of the script to be executed (specified by the ds parameter), that is to say, the corresponding dag script files of the scheduling node (scheduler) and the work node (worker) must be placed under the same path, otherwise the above errors will occur.
Reference link: https://stackoverflow.com/questions/43235130/airflow-dag-id-could-not-be-found
13. airlfow's REST API call returns Airflow 404 = lots of circles
The reason for this error is that the URL does not provide the origin parameter, which is used for redirection, such as calling the / run interface of airflow. The available examples are as follows:
14. Broker and Executor selection
Please make sure to use rabbitmq + celeryexecution, after all, this is also the official Recommended Practice of Celery, so you can use some great functions, such as clicking the wrong Task on webui and ReRun
15,pkg_resources.DistributionNotFound: The 'setuptools==0.9.8' distribution was not found and is required by the application
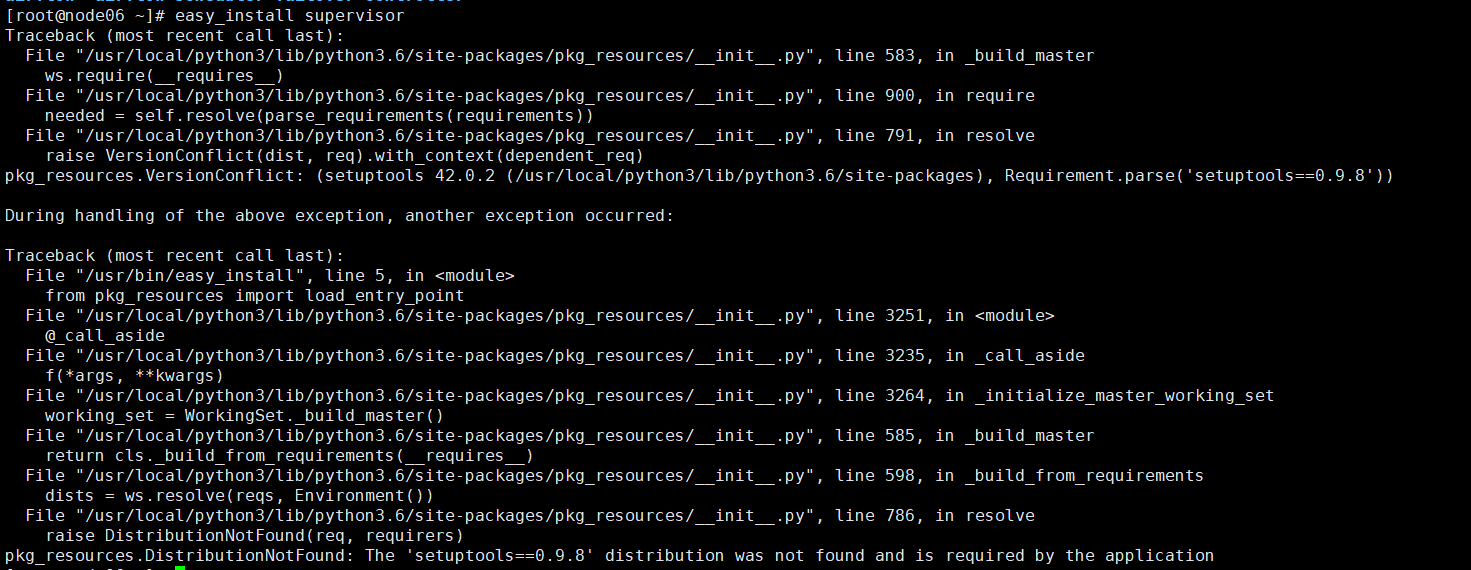
pip install distribution
16,Supervisor
When using the supervisor's startup worker, server, and scheduler, be sure to add
environment=AIRFLOW_HOME=xxxxxxxxxx
The main reason is that if your supervisor runs by calling a custom script, a service log service will be started when you start the worker. If you do not set the correct environment variable, the service log will find the log in the default airflow home, so you cannot view the log in webui
17,Serve_log
If you have deployed workers on multiple machines, you need iptables to open port 8793 of those machines so that webui can view the task logs of cross machine workers
18, AMPQ Library
celery Two kinds of libraries are provided to realize amqp, One is the default kombu, The other is librabbitmq, The latter is right c Binding of modules, At 1.8.1 Version, Used kombu It will appear scheduler Automatic disconnection, This should be its corresponding version 4.0.2 Problem, When cut into librabbitmq When, server And scheduler Run normally, however worker Never consume task, Finally find out the reason: Celery4.0.2 But librabbitmq No corresponding modification, The solution is, Modify the source code executors/celery_executor.py File and add parameters
CELERY_TASK_PROTOCOL = 1
19. RabbitMQ connection stuck
After running for a period of time, all tasks are in the queued state due to network problems. Only when the worker is restarted can it take effect. Someone said that there is a problem with the broker pool of cleary. Continue to add parameters to cellery_executor.py
Broker? Pool? Limit = 0 / / do not use connection pool
In addition, this will only reduce the probability of jamming. It is better to restart the worker regularly with crontab
20. Specific tasks run only on special machines
You can specify a queue for the task in the DAG, and then run the airflow worker - Q = queue? Name on a specific machine
21. Too many queue s in RabbitMQ
celery For the sake of scheduler Know each task And the time to know the result is O(1) , So the only solution is to create one for each task UUID Of queue, Defaults to this. queue The expiration time of is 1 day, Can be changed by celery_executor.py To adjust the expiration time
CELERY_TASK_RESULT_EXPIRES = time in seconds
22. The air flow worker role cannot be started using the root user
Reason: the ROOT reason why the ROOT user can't be used to start is that the airflow worker directly uses the cellery, and there are parameters in the cellery source code that can't be started by ROOT by default, otherwise an error will be reported
C_FORCE_ROOT = os.environ.get('C_FORCE_ROOT', False)
ROOT_DISALLOWED = """\
Running a worker with superuser privileges when the
worker accepts messages serialized with pickle is a very bad idea!
If you really want to continue then you have to set the C_FORCE_ROOT
environment variable (but please think about this before you do).
User information: uid={uid} euid={euid} gid={gid} egid={egid}
"""
ROOT_DISCOURAGED = """\
You're running the worker with superuser privileges: this is
absolutely not recommended!
Please specify a different user using the --uid option.
User information: uid={uid} euid={euid} gid={gid} egid={egid}
"""Solution 1: modify the source code of airlfow, and force C ﹣ force ﹣ root to be set in cellery ﹣ executor.py
from celery import Celery, platforms In app = Gallery ( Post added platforms.C_FORCE_ROOT = True Restart it
Solution 2: when the container initializes the environment variables, set the C ﹣ force ﹣ root parameter to solve the problem in a zero intrusion way
Force cell worker to run in root mode export C_FORCE_ROOT=True
23,docker in docker
When scheduling tasks in the way of docker in dags, we use the design concept of docker cs architecture to avoid heavy docker pull and other operations for container's lightweight. We only need to mount the host's / var/run/docker.sock file to the container directory to get docker in docker data: https://link.zhihu.com/?target=http://wangbaiyuan.cn/docker-in-docker.html#prettyPhoto
24. When scheduling and deserializing dag execution by multiple worker nodes, the module cannot be found
At that time, considering the consistency of file updates, the scheme of serializing dag issued by the master is adopted by all workers, instead of relying on the actual dag file on the worker node. The operations to enable this feature are as follows
On the worker node: airflow worker -cn=ip@ip -p //-p is the switch parameter, which means that the master serialized dag is used as the execution file, not the file in the local dag directory On the master node: airflow scheduler -p
Error reason: the actual dag file does not exist on the remote worker node. The module name cannot be found for the function or object defined in the dag during deserialization
Solution 1: publish dags directory on all worker nodes at the same time. The disadvantage is that dags consistency becomes a problem
Solution 2: modify the logic of serialization and deserialization in the source code. The main idea is to replace the nonexistent module with main. Amend to read:
//Model.py file, modify the class DagPickle(Base) definition import dill class DagPickle(Base): id = Column(Integer, primary_key=True) # Before modification: pickle = Column(PickleType(pickler=dill)) pickle = Column(LargeBinary) created_dttm = Column(UtcDateTime, default=timezone.utcnow) pickle_hash = Column(Text)
tablename = "dag_pickle"
def init(self, dag):
self.dag_id = dag.dag_id
if hasattr(dag, 'template_env'):
dag.template_env = None
self.pickle_hash = hash(dag)
raw = dill.dumps(dag)
Before modification: self.pickle = dag
reg_str = 'unusualprefix\w*{0}'.format(dag.dag_id)
result = re.sub(str.encode(reg_str), b'main', raw)
self.pickle =result
//cli.py file deserialization logic run(args, dag=None) function
//Deserialize binaries directly through dill, rather than through PickleType's result ﹣ processor
Before modification: dag = dag_pickle.pickle
After modification: dag = dill.loads(dag_pickle.pickle)
>Solution 3: zero source code intrusion, use python's types.FunctionType to re create a function without module, so there will be no problem in serialization and deserialization
new_func = types.FunctionType((lambda df: df.iloc[:, 0].size == xx).code, {})
#### 25. On the master node, the remote task log cannot be viewed through webserver
> Cause: due to airflow stay master See task The execution log is passed through each node http Service acquired, but deposited task_instance In table host_name No ip,Visible acquisition hostname There's a problem with the way.
> Solution: modify airflow/utils/net.py in get_hostname Function, adding the hostname Logic
```python
//models.py TaskInstance
self.hostname = get_hostname()
//net.py add a logic to get ﹣ hostname to get environment variables
import os
def get_hostname():
"""
Fetch the hostname using the callable from the config or using
`socket.getfqdn` as a fallback.
"""
# Try to get environment variables
if 'AIRFLOW_HOST_NAME' in os.environ:
return os.environ['AIRFLOW_HOST_NAME']
# First we attempt to fetch the callable path from the config.
try:
callable_path = conf.get('core', 'hostname_callable')
except AirflowConfigException:
callable_path = None
# Then we handle the case when the config is missing or empty. This is the
# default behavior.
if not callable_path:
return socket.getfqdn()
# Since we have a callable path, we try to import and run it next.
module_path, attr_name = callable_path.split(':')
module = importlib.import_module(module_path)
callable = getattr(module, attr_name)
return callable()