1. Introduction to Ajax:
In short, it is a technology that keeps the URL unchanged when crawling data and requests resources from the server through Ajax requests to enrich the interface [for example, in https://m.weibo.cn Slide down to get more microblogs, and the home page of station B also adopts this technology]. Its process is also very simple: 1 Send ajax request 2 Parse the content returned by the server 3 Render web pages in the browser.
2.Ajax analysis:
With https://m.weibo.cn/u/6481722754 (carrying smuggled goods, hehe) as an example.
1. View request. In sequence: ① right click and select "check" to enter the developer option → ② select Network → ③ select Fetch/XHR and refresh the browser page [as shown in Figure 1, the Ajax request sent if the Type is XHR].
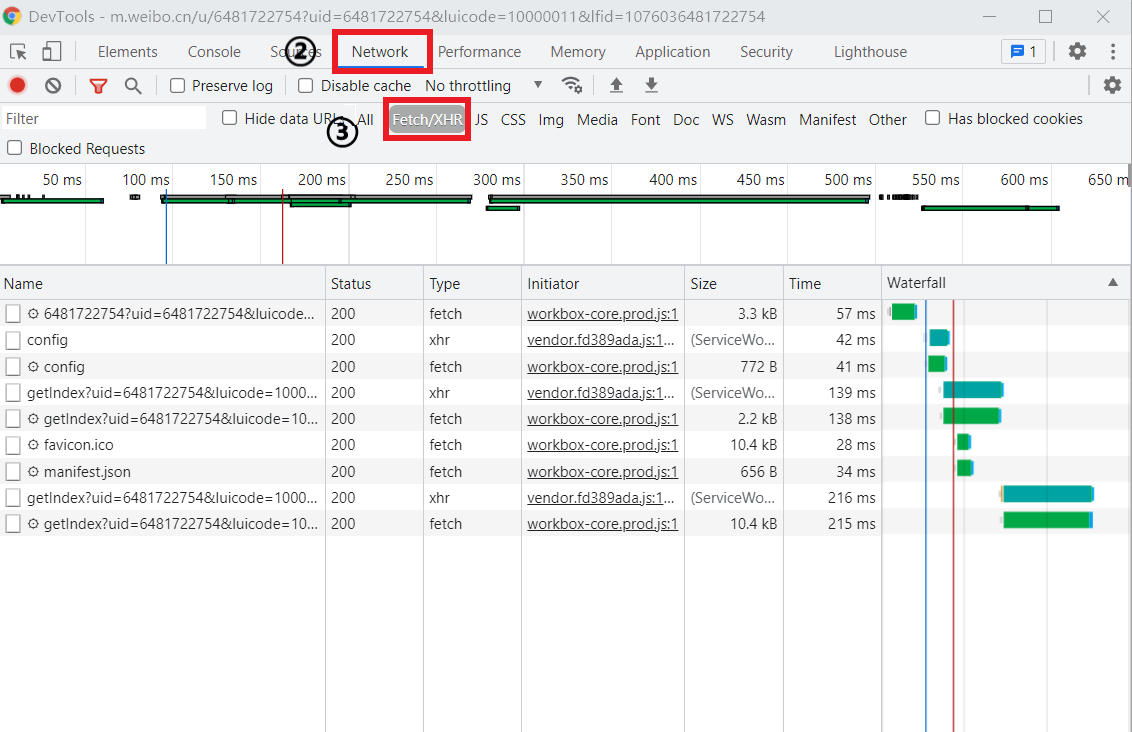
Figure I
2. View the Response. The Response returned by itself is in JSON format, which has been parsed by the browser, so what you see is in the form of a dictionary. In sequence: ① click an Ajax request you want to view → ② Query String Parameters are the sent request parameters [very important and can be used to construct Ajax requests] → ③ Response and Preview are the returned responses [as shown in Figure 2, it is recommended to view in Preview for image comparison].
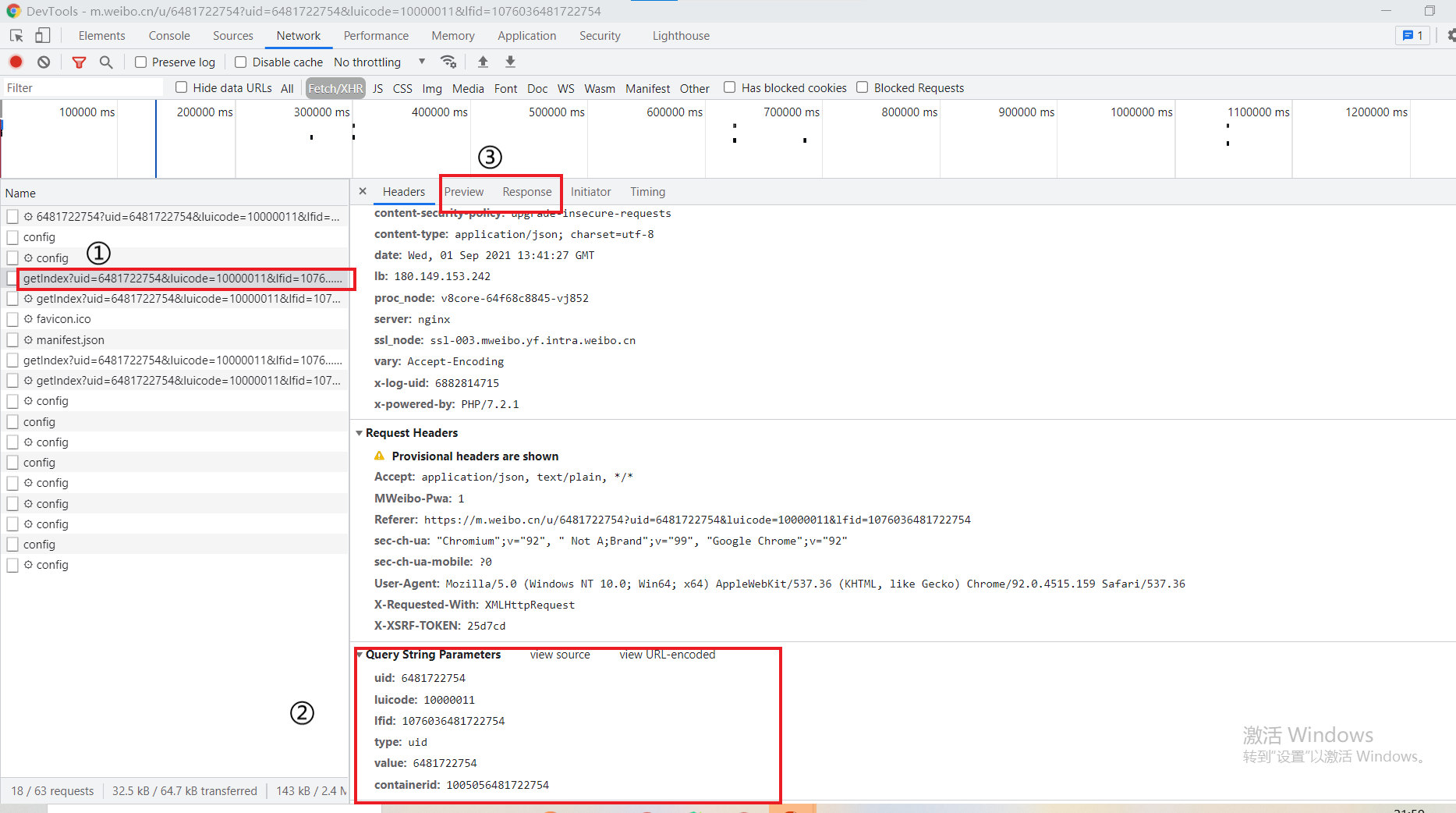
Figure II
3. Project practice [crawl the microblog of this address]:
After analyzing the response of each Ajax request, it is not difficult to find the second getIndex? The response returned by the Ajax request at the beginning contains some microblogs [the first contains some information about the layout of the home page, but there is no microblog], specifically in data → cards → number → mblog [as shown in Figure 3]:
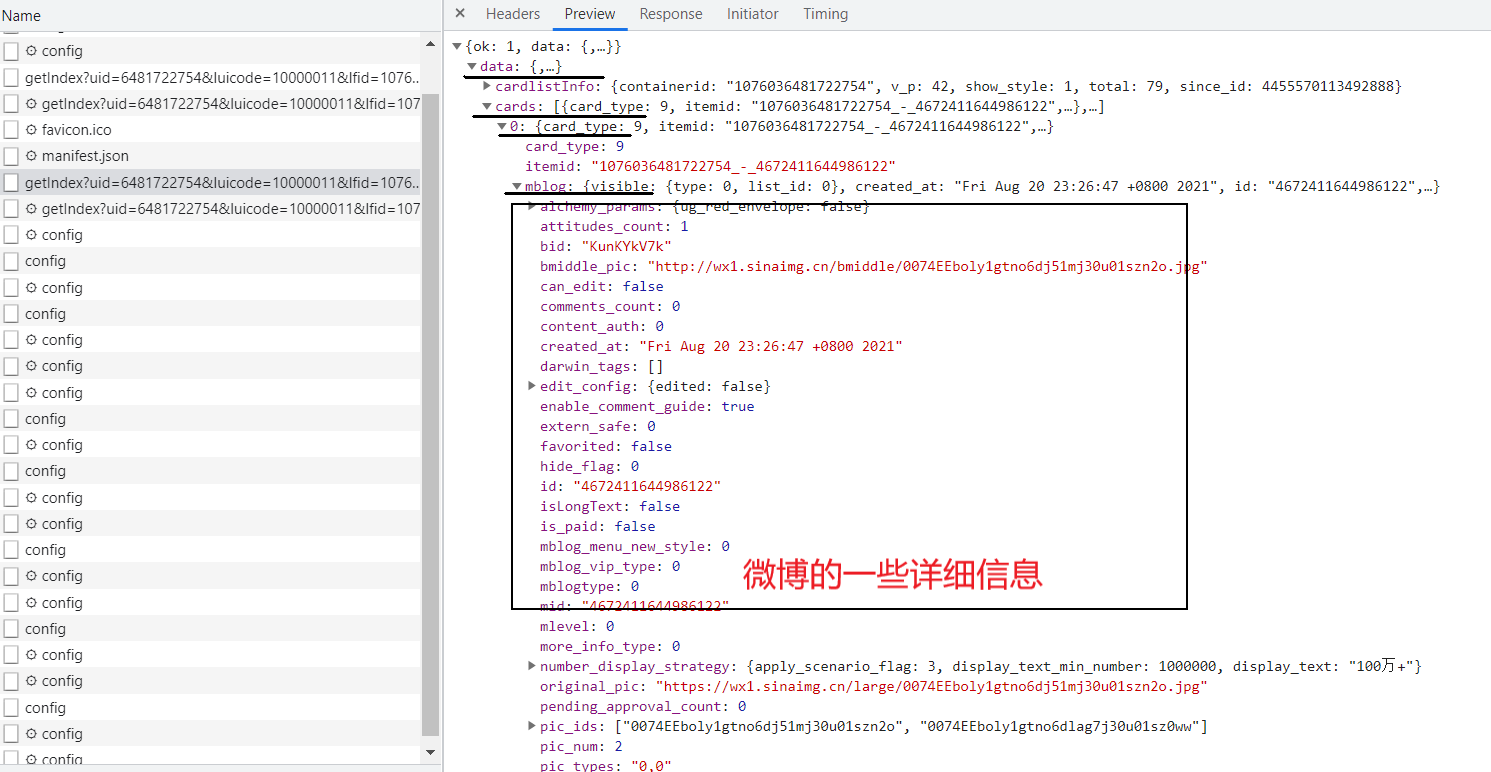
Figure III
However, there are only the first few microblogs of the blogger in this response. This is because the initial response returned by the server contains so much information. At this time, AJAX technology needs to be used to obtain more microblogs. You can try to slide down the browser interface. When more microblogs are displayed, switch to the developer option, and you can see that more Ajax requests are sent. Next, we analyze these Ajax requests so that we can construct the request to send to the server.
In Figure 2, you can see that the request parameters include uid, luicode, lfid, type, value, contained, [subsequent requests also include since_id, which page to locate]. Because since_ The corresponding value of ID is complex. You can refer to https://blog.csdn.net/weixin_44489501/article/details/104119556 Here, we select page parameters to locate according to < Python 3 web crawler development practice > (pro test is available). Of course, these parameters are not all necessary. Only type, value [uid], containerid and page are required to construct the request.
With these foundations, you can write crawlers as follows:
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
# The first half of an Ajax request
base_url = 'https://m.weibo.cn/api/container/getIndex?'
# It is used to construct request, which can be viewed in the Request Headers of config (part)
headers = {
'Referer': 'https://m.weibo.cn/u/6481722754',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# Get the response of microblog with specific pages
def get_weibo(page):
# Construct the parameters of the Ajax request
params = {
'type': 'uid',
'value': 6481722754,
'containerid': 1076036481722754,
'page': page
}
# Construction request
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
# Analysis of response
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
# Parse the response and extract the desired information
def get_parse(json):
items = json.get('data').get('cards')
for item in items:
mblog = item.get('mblog')
weibo = {}
weibo['Praise quantity'] = mblog.get('attitudes_count')
weibo['Comment volume'] = mblog.get('comments_count')
# Extract the text and remove the HTML tag
weibo['text'] = pq(mblog.get('text')).text()
yield weibo
if __name__ == '__main__':
for i in range(1,3):
json = get_weibo(i)
results = get_parse(json)
for result in results:
print(result)