In practice, whether it is a search problem or a text problem, how to find similar text is a common scene, but TFIDF text similarity calculation is used too much, and young people often don't remember the classics.
It's almost four years since graduation. I recently prepared to sort out the four years since I graduated. When sorting out the documents, I saw a competition a long time ago and remembered that TFIDF and BERT's schemes had not won BM25 in terms of indicators. As the seventh issue of the "alchemy" series, let's talk about the relevant knowledge of similar text search.
What is BM25
BM25 is a classical algorithm used to calculate the similarity score between Query and document in the field of information indexing. Unlike TFIDF, the formula of BM25 mainly consists of three parts:
- Analyze the morpheme of Query to generate morpheme qi;
- For each search result D, calculate the correlation score between each morpheme qi and D;
- The correlation score of qi relative to D is weighted and summed to obtain the correlation score of Query and D.
The formula is as follows:
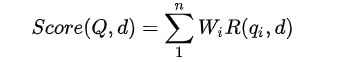
Where Q represents Query, qi represents a morpheme after Q parsing, D represents a search result document, Wi represents the weight of speech speed qi, and R(qi,d) represents the correlation score between morpheme qi and document D.
Implementation of BM25
class BM25:
def __init__(self, corpus, tokenizer=None):
self.corpus_size = len(corpus)
self.avgdl = 0
self.doc_freqs = []
self.idf = {}
self.doc_len = []
self.tokenizer = tokenizer
if tokenizer:
corpus = self._tokenize_corpus(corpus)
nd = self._initialize(corpus)
self._calc_idf(nd)
def _initialize(self, corpus):
nd = {} # word -> number of documents with word
num_doc = 0
for document in corpus:
self.doc_len.append(len(document))
num_doc += len(document)
frequencies = {}
for word in document:
if word not in frequencies:
frequencies[word] = 0
frequencies[word] += 1
self.doc_freqs.append(frequencies)
for word, freq in frequencies.items():
try:
nd[word]+=1
except KeyError:
nd[word] = 1
self.avgdl = num_doc / self.corpus_size
return nd
def _tokenize_corpus(self, corpus):
pool = Pool(cpu_count())
tokenized_corpus = pool.map(self.tokenizer, corpus)
return tokenized_corpus
def _calc_idf(self, nd):
raise NotImplementedError()
def get_scores(self, query):
raise NotImplementedError()
def get_batch_scores(self, query, doc_ids):
raise NotImplementedError()
def get_top_n(self, query, documents, n=5):
assert self.corpus_size == len(documents), "The documents given don't match the index corpus!"
scores = self.get_scores(query)
top_n = np.argsort(scores)[::-1][:n]
return [documents[i] for i in top_n]Actual case of data competition
Here, I will introduce a real case I wrote before. The task provides a paper library (containing about 200000 papers) and provides the description paragraphs of the papers, which come from the introduction of similar research in the papers. The task needs to match the description paragraphs with three most relevant papers.
example: Description paragraph: An efficient implementation based on BERT [1] and graph neural network (GNN) [2] is introduced. Related papers: [1] BERT: Pre-training of deep bidirectional transformers for language understanding. [2] Relational inductive biases, deep learning, and graph networks.
From the task description, we can see that the task needs to match the description paragraphs with the three most relevant papers. In form alone, it can be understood that this is a "cloze" task. However, compared with filling in the corresponding words in the corresponding position of this paper, what needs to be filled here is a Sentence, that is, the title of the paper. However, if you follow this idea to find a solution, you will find that the general computational power can not be satisfied with this level of text data.
In that case, we might as well think about this problem in another way. "Match the description paragraphs with the three most relevant papers". In fact, the simplest implementation method is to calculate the similarity between the description paragraphs and all the papers in the paper library and find out the most similar ones. But there will also be a problem. By exploring the data, you will find that "an effective implementation based on Bert [1] and graph neural network (GNN) [2] is introduced." This description paragraph refers to two articles at the same time. When calculating the similarity, which position should be which article?
01 core idea of modeling
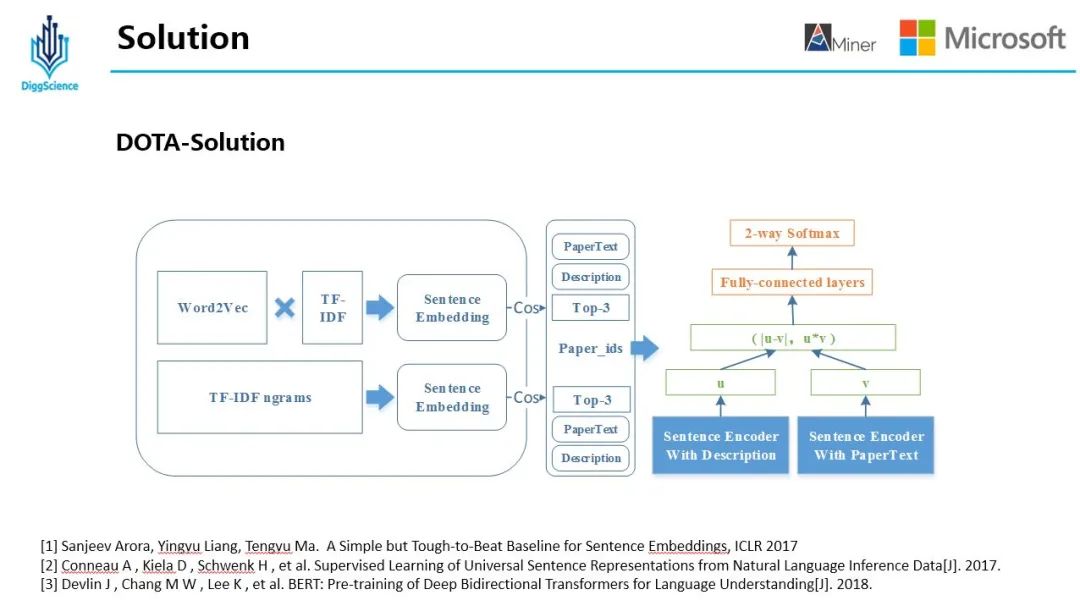
Two methods are used to solve this problem. One is to use the Wrod2Vec method to get the word vector of each word in the description paragraph, and use Word2Vec to weight the words in the sentence with IDF to get sense embedding. At the same time, in order to get better results, an improvement is made here, That is, use Smooth Inverse Frequency instead of IDF as the weight of each word; The second is to use BM25 to get sentince embedding. The two methods calculate the cosine similarity respectively to obtain 3 papers. After de duplication, there are 3-6 Recall Papers in each paragraph of the recall set.
02SIF Sentence Embedding

The calculation of SIF is divided into two steps:
1) For each word vector in the sentence, multiply by a unique weight b, which is a constant a divided by the sum of a and the frequency of the word. This method will reduce the weight of words with high frequency, that is, the higher the frequency, the smaller the weight;
2) Calculate the first principal component U of the sentence vector matrix and let each Sentence Embedding subtract its projection on u;
03InferSent
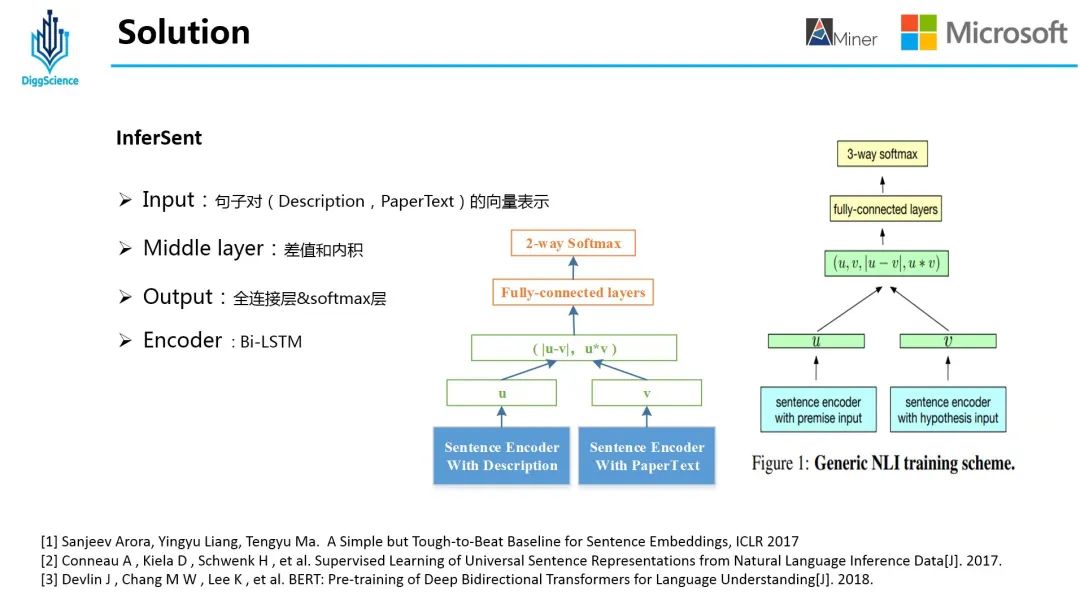
InferSent similarity model is a method proposed by Facebook to obtain sense embedding through different encoder s, and then calculate the difference and point multiplication of two sense embedding to obtain the interaction vector, and calculate the similarity between the two.
Here, two modifications have been made to the original paper method:
(1) To solve this problem, the 3-way softmax layer (entry, contrast, neutral) is modified to 2-way softmax;
(2) u and v are removed from the middle layer, and only two feature representation methods of difference and inner product are used;
04BERT
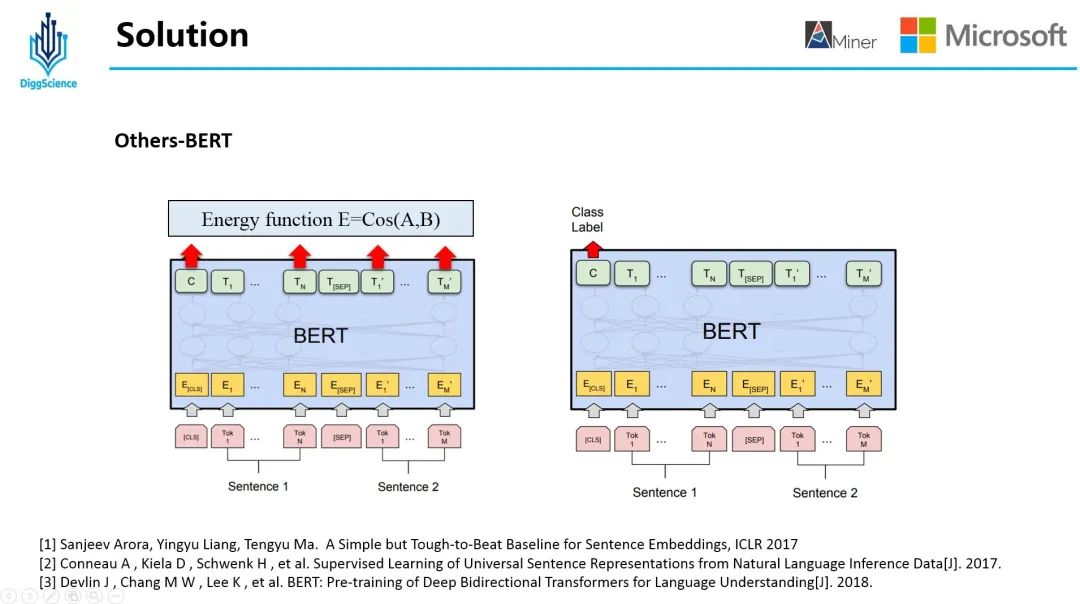
In the BERT era, it is indispensable in the attempt of solutions. Here we try two solutions with BERT. One is to use BERT to encode Description and PaperText and calculate the cosine similarity of the text; The second is to replace the InferSent part with BERT in the above overall model.
reference material
[1] Sanjeev Arora, Yingyu Liang, Tengyu Ma. A Simple but Tough-to-Beat Baseline for Sentence Embeddings, ICLR 2017
[2] Conneau A , Kiela D , Schwenk H , et al. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data[J]. 2017.
[3] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.