Task 3: thesis code statistics
3.1 task description
- Task topic: thesis code statistics, statistics related to the codes in all papers;
- Task content: use regular expressions to count code connections, pages and chart data;
- Task achievement: learn regular expression statistics;
3.2 data processing steps
In the original arxiv data set, the author often gives specific code links in the comments or abstract fields of the paper, so we need to find the code links from these fields.
- Determine where the data appears;
- Use regular expressions to complete matching;
- Complete relevant statistics;
3.3 regular expressions
Regular expression describes a pattern of string matching, which can be used to check whether a string contains a seed string, replace the matched substring, or take the substring that meets a certain condition from a string.
3.3.1 ordinary characters: upper and lower case letters, all numbers, all punctuation marks and some other symbols
| character | describe |
|---|---|
| [ABC] | Match all characters in [...], for example, [aeiou] matches all e o u a letters in the string "google runoob taobao". |
| [^ABC] | Match all characters except the characters in [...]. For example, [^ aeiou] matches all letters except e o u a in the string "google runoob taobao". |
| [A-Z] | [A-Z] represents an interval that matches all uppercase letters, [A-Z] represents all lowercase letters. |
| . | Matches any single character except the newline character (\ n, \ r), which is equal to [^ \ n\r]. |
| [\s\S] | Match all. \S matches all whitespace characters, including line breaks, and s non whitespace characters, including line breaks. |
| \w | Match letters, numbers, underscores. Equivalent to [A-Za-z0-9_] |
3.3.2 special characters: characters with special meanings
| Special character | describe |
|---|---|
| ( ) | Marks the beginning and end of a subexpression. Subexpressions can be obtained for later use. To match these characters, use (and). |
| * | Matches the previous subexpression zero or more times. To match the * character, use *. |
| + | Matches the previous subexpression one or more times. To match the + character, use +. |
| . | Matches any single character except the newline character. To match, Please use. |
| [ | Marks the beginning of a bracket expression. To match [, use [. |
| ? | Matches the previous subexpression zero or once, or indicates a non greedy qualifier. To match? Characters, please use?. |
| \ | Marks the next character as a or special character, or literal character, or backward reference, or octal escape character. For example, 'n' matches the character 'n' \N 'matches the newline character. Sequence '\' matches' ', while' ('matches'' ('. |
| ^ | Matches the starting position of the input string, unless used in a square bracket expression. When the symbol is used in a square bracket expression, it means that the character set in the square bracket expression is not accepted. To match the ^ character itself, use ^. |
| { | Mark the beginning of the qualifier expression. To match {, use {. |
| | | Indicates a choice between two items. To match |, use |. |
3.3.3 qualifier
| character | describe |
|---|---|
| * | Matches the previous subexpression zero or more times. For example, zo * can match "z" and "zoo"* Equivalent to {0,}. |
| + | Matches the previous subexpression one or more times. For example, 'zo +' can match "zo" and "zoo", but not "z"+ Equivalent to {1,}. |
| ? | Matches the previous subexpression zero or once. For example, "do(es)" You can match "does" in "do", "does" and "do" in "doxy".? Equivalent to {0,1}. |
| {n} | N is a nonnegative integer. Match the determined n times. For example, 'o{2}' cannot match 'o' in "Bob", but it can match two o's in "food". |
| {n,} | n is a nonnegative integer. Match at least n times. For example, 'o{2,}' cannot match 'o' in "Bob", but it can match all o's in "foood"‘ o{1,} 'is equivalent to' O + '‘ o{0,} 'is equivalent to' o * '. |
| {n,m} | Both M and N are nonnegative integers, where n < = M. Match at least N times and at most m times. For example, "o{1,3}" will match the first three o's in "food"‘ o{0,1} 'is equivalent to' o? '. Please note that there can be no space between comma and two numbers. |
3.4 specific code implementation and explanation
First, let's count the number of paper pages, that is, extract the pages and figures in the comments field, and read the fields first.
data = [] #initialization
#Advantages of using with statement: 1 Automatically close the file handle; 2. Automatic display (processing) file reading data exception
with open("arxiv-metadata-oai-snapshot.json", 'r') as f:
for idx, line in enumerate(f):
d = json.loads(line)
d = {'abstract': d['abstract'], 'categories': d['categories'], 'comments': d['comments']}
data.append(d)
data = pd.DataFrame(data) #Change the list into dataframe format to facilitate analysis with pandas
Extract pages:
# Use regular expression matching, XX pages
data['pages'] = data['comments'].apply(lambda x: re.findall('[1-9][0-9]* pages', str(x)))
# Select the papers with pages
data = data[data['pages'].apply(len) > 0]
# Since the matching result is a list, such as ['19 pages'], it needs to be converted
data['pages'] = data['pages'].apply(lambda x: float(x[0].replace(' pages', '')))
Statistics of pages:
data['pages'].describe().astype(int)
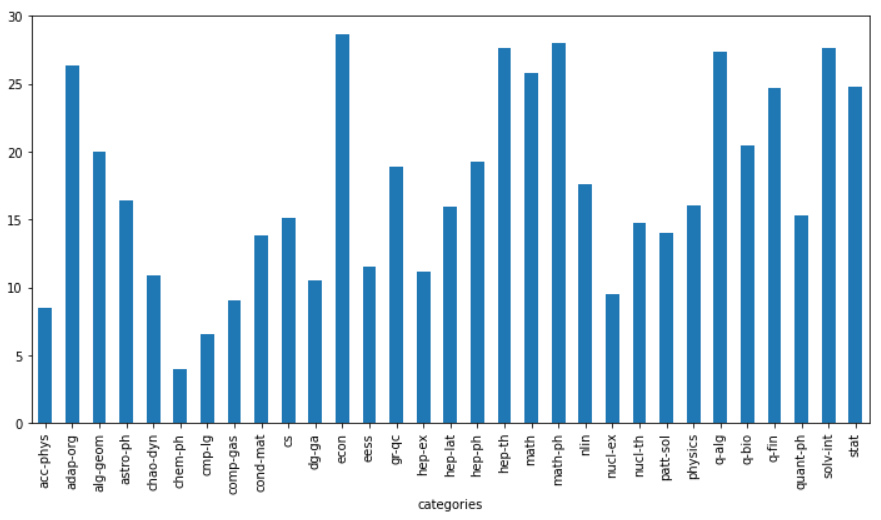
The statistical results are as follows: the average number of pages of papers is 17, 75% of papers are within 22 pages, and the longest paper is 11232 pages.
count 1089180 mean 17 std 22 min 1 25% 8 50% 13 75% 22 max 11232 Name: pages, dtype: int64
Next, according to the classified statistics of the number of pages of papers, the main categories of the first category of papers are selected:
# Select main category
data['categories'] = data['categories'].apply(lambda x: x.split(' ')[0])
data['categories'] = data['categories'].apply(lambda x: x.split('.')[0])
# Average number of pages per type of paper
plt.figure(figsize=(12, 6))
data.groupby(['categories'])['pages'].mean().plot(kind='bar')
Next, extract the number of charts in the paper:
data['figures'] = data['comments'].apply(lambda x: re.findall('[1-9][0-9]* figures', str(x)))
data = data[data['figures'].apply(len) > 0]
data['figures'] = data['figures'].apply(lambda x: float(x[0].replace(' figures', '')))
Finally, we extract the code links of the paper. In order to simplify the task, we only extract github links:
# Screening papers containing github
data_with_code = data[
(data.comments.str.contains('github')==True)|
(data.abstract.str.contains('github')==True)
]
data_with_code['text'] = data_with_code['abstract'].fillna('') + data_with_code['comments'].fillna('')
# Matching papers using regular expressions
pattern = '[a-zA-z]+://github[^\s]*'
data_with_code['code_flag'] = data_with_code['text'].str.findall(pattern).apply(len)
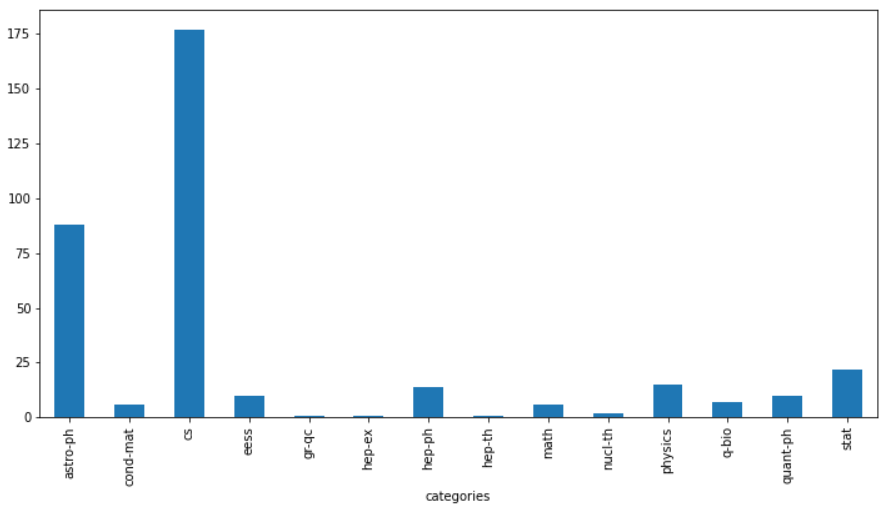
And draw the paper according to the category:
data_with_code = data_with_code[data_with_code['code_flag'] == 1] plt.figure(figsize=(12, 6)) data_with_code.groupby(['categories'])['code_flag'].count().plot(kind='bar')