RFM user value model
1 demand
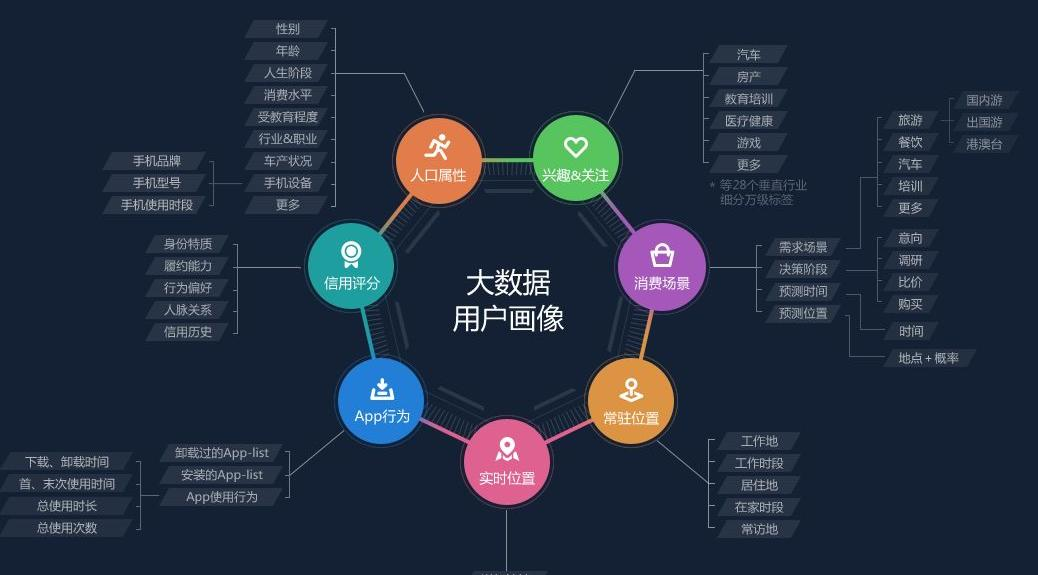
- Assuming I am a marketer, I might think about the following questions before doing an activity
- Who are my more valuable customers?
- Who has the potential to become a valuable customer?
- Who's losing?
- Who can stay?
- Who cares about this event?
- In fact, all the above thoughts focus on one theme value
- RFM is one of the most common tools used to evaluate value and potential value
2 what is RFM
- Evaluate a person's value to the company through the time since the last consumption, the consumption frequency per unit time and the average consumption amount. It can be understood that RFM is an integrated value, as follows: RFM = rencency, frequency and monetary
- The RFM model can illustrate the following facts:
- The closer the last purchase, the more interested the user is in the promotion
- The higher the purchase frequency, the higher the satisfaction with us
- The larger the amount of consumption, the richer, and the higher the consumption
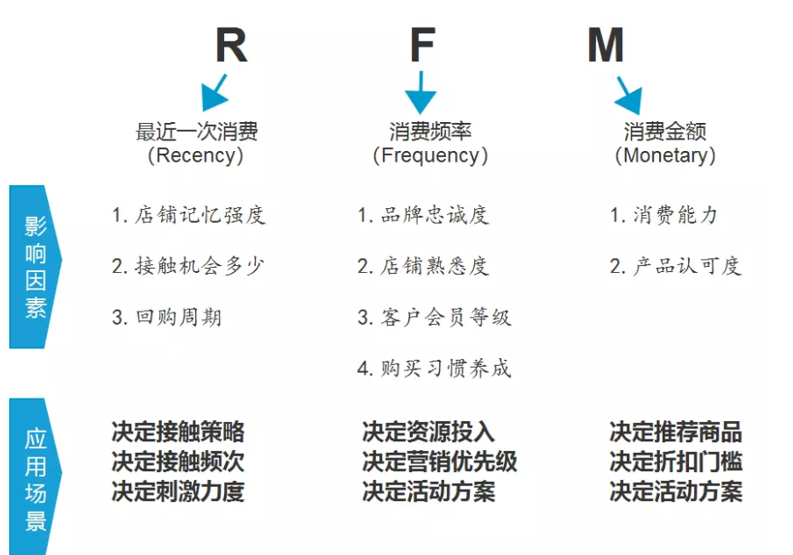
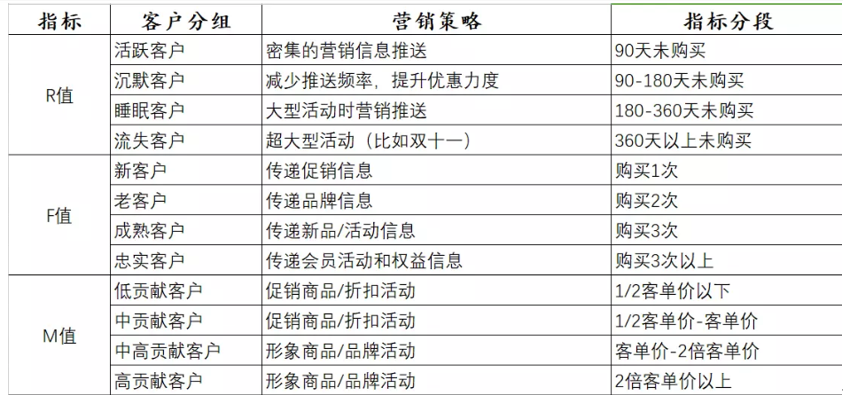
3 practical application of RFM
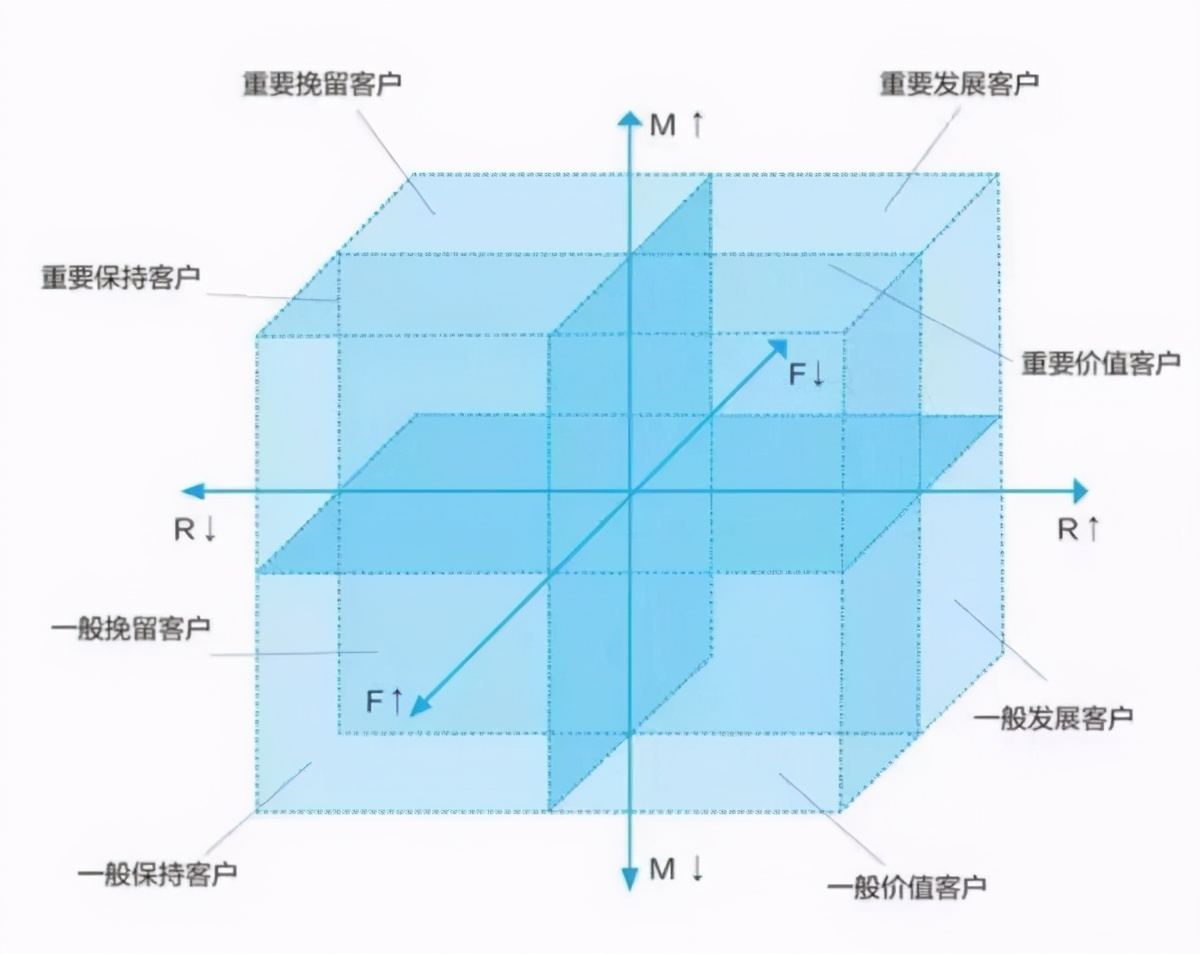
4 high dimensional spatial model
5 unify dimensions through scoring - R: 1-3 days = 5 points, 4-6 days = 4 points, 7-9 days = 3 points, 10-15 days = 2 points, more than 16 days = 1 point
- F: ≥ 200 = 5 points, 150-199 = 4 points, 100-149 = 3 points, 50-99 = 2 points, 1-49 = 1 point
- M: ≥ 20w=5 points, 10-19w=4 points, 5-9w=3 points, 1-4w=2 points, < 1W = 1 point
val rScore: Column = when('r.>=(1).and('r.<=(3)), 5)
.when('r >= 4 and 'r <= 6, 4)
.when('r >= 7 and 'r <= 9, 3)
.when('r >= 10 and 'r <= 15, 2)
.when('r >= 16, 1)
.as("r_score")
val fScore: Column = when('f >= 200, 5)
.when(('f >= 150) && ('f <= 199), 4)
.when((col("f") >= 100) && (col("f") <= 149), 3)
.when((col("f") >= 50) && (col("f") <= 99), 2)
.when((col("f") >= 1) && (col("f") <= 49), 1)
.as("f_score")
val mScore: Column = when(col("m") >= 200000, 5)
.when(col("m").between(100000, 199999), 4)
.when(col("m").between(50000, 99999), 3)
.when(col("m").between(10000, 49999), 2)
.when(col("m") <= 9999, 1)
.as("m_score")
6 model training and prediction
- RFMTrainModel training model, saving model to HDFS, scheduling cycle, once a month.
- RFMPredictModel prediction model reads the clustering model from HDFS and predicts the whole data set once a day
def process(source: DataFrame): DataFrame = {
val assembled = assembleDataFrame(source)
val regressor = new KMeans()
.setK(7)
.setSeed(10)
.setMaxIter(10)
.setFeaturesCol("features")
.setPredictionCol("predict")
regressor.fit(assembled).save(MODEL_PATH)
null
}
val assembled = RFMModel.assembleDataFrame(source)
val kmeans = KMeansModel.load(RFMModel.MODEL_PATH)
val predicted = kmeans.transform(assembled)
// Find the relationship between the group number generated by kmeans and the rule
val sortedCenters: IndexedSeq[(Int, Double)] = kmeans.clusterCenters.indices // IndexedSeq
.map(i => (i, kmeans.clusterCenters(i).toArray.sum))
.sortBy(c => c._2).reverse
val sortedDF = sortedCenters.toDF("index", "totalScore")
RFE activity
- Similar to RFM, we use RFE to calculate user activity
- RFE = R (last access time) + F (access frequency in a specific time) + E (number of activities)
- R = datediff(date_sub(current_timestamp(),60), max('log_time))
- F = count('loc_url)
- E = countDistinct('loc_url)
- R:0-15 days = 5 points, 16-30 days = 4 points, 31-45 days = 3 points, 46-60 days = 2 points, more than 61 days = 1 point
- F: ≥ 400 = 5 points, 300-399 = 4 points, 200-299 = 3 points, 100-199 = 2 points, ≤ 99 = 1 point
- E: ≥ 250 = 5 points, 230-249 = 4 points, 210-229 = 3 points, 200-209 = 2 points, 1 = 1 point
PSM price sensitivity model
- PSM is used to calculate the price sensitivity of users
- For different levels of price sensitive users, different degrees of marketing can be implemented
1 PSM calculation formula
- PSM Score = proportion of preferential orders + (average preferential amount / average receivable per order) + proportion of preferential amount
- Proportion of preferential orders
- Preferential orders / total orders
- Preferential orders = quantity of preferential orders / total orders
- Unprivileged orders = unprivileged order quantity / total orders
- Average preferential amount
- Total preferential amount / number of preferential orders
- Average receivable per order
- Total receivable / total orders
- Proportion of preferential amount
- Total preferential amount / total receivable amount
// Amount receivable
val receivableAmount = ('couponCodeValue + 'orderAmount).cast(DoubleType) as "receivableAmount"
// Preferential amount
val discountAmount = 'couponCodeValue.cast(DoubleType) as "discountAmount"
// Paid in amount
val practicalAmount = 'orderAmount.cast(DoubleType) as "practicalAmount"
// Is it preferential
val state = when(discountAmount =!= 0.0d, 1) // =!= Is the method of column
.when(discountAmount === 0.0d, 0)
.as("state")
// Number of preferential orders
val discountCount = sum('state) as "discountCount"
// Total orders
val totalCount = count('state) as "totalCount"
// Total preference
val totalDiscountAmount = sum('discountAmount) as "totalDiscountAmount"
// Total receivable
val totalReceivableAmount = sum('receivableAmount) as "totalReceivableAmount"
// Average preferential amount
val avgDiscountAmount = ('totalDiscountAmount / 'discountCount) as "avgDiscountAmount"
// Average receivable per order
val avgReceivableAmount = ('totalReceivableAmount / 'totalCount) as "avgReceivableAmount"
// Proportion of preferential orders
val discountPercent = ('discountCount / 'totalCount) as "discountPercent"
// Proportion of average preferential amount
val avgDiscountPercent = (avgDiscountAmount / avgReceivableAmount) as "avgDiscountPercent"
// Proportion of preferential amount
val discountAmountPercent = ('totalDiscountAmount / 'totalReceivableAmount) as "discountAmountPercent"
// Proportion of preferential orders + (average preferential amount / average receivable per order) + proportion of preferential amount
val psmScore = (discountPercent + (avgDiscountPercent / avgReceivableAmount) + discountAmountPercent) as "psm"
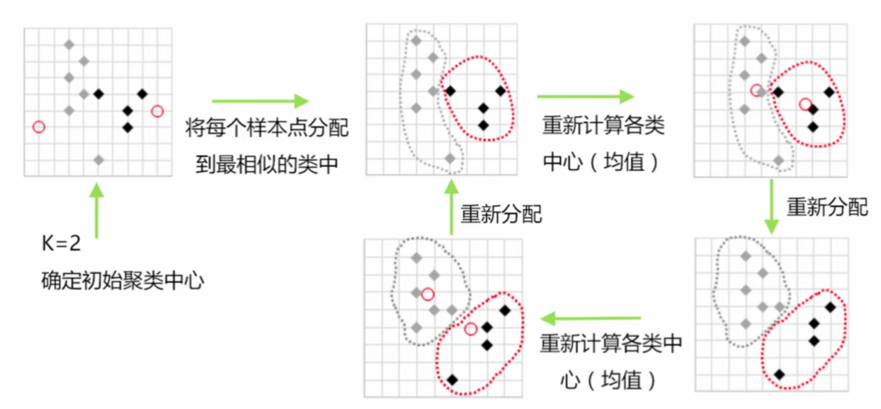
2 principle of clustering algorithm
- Select K points as the initial midpoint
- Calculate the distance from each midpoint to similar points, and gather the similar points into a class (cluster)
- Euclidean distance
- Recalculate the midpoint of each cluster
- Repeat the above steps until no changes occur
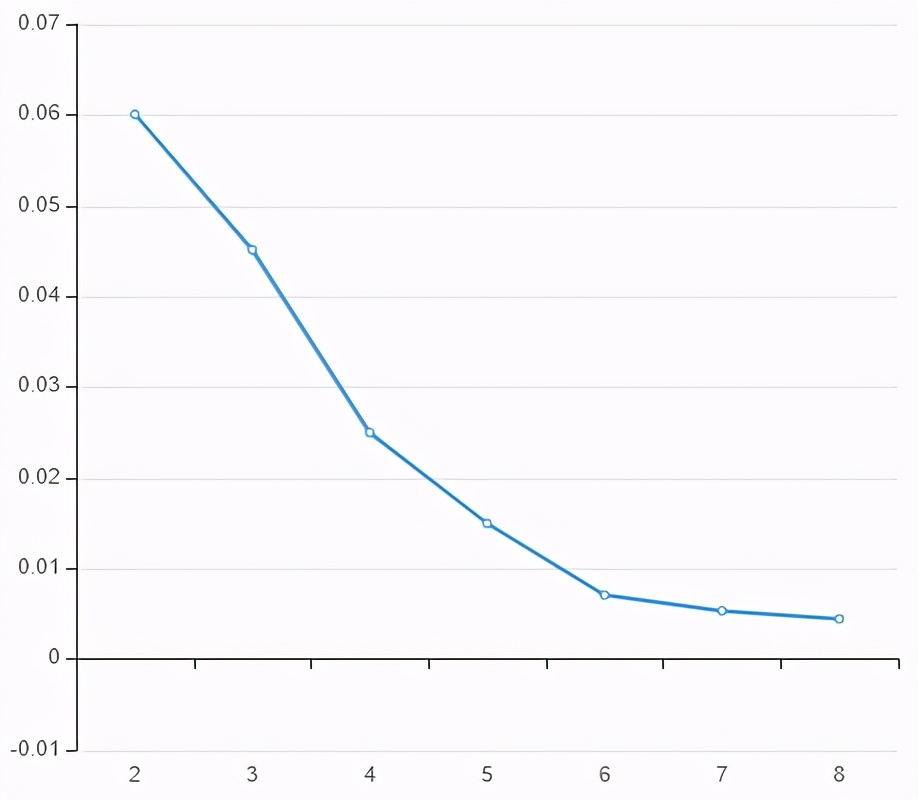
3 determine the K-elbow rule
- According to the loss function, calculate the overall loss in the case of each K
- Draw a graph and find the inflection point, which is the appropriate K
4 model training and iterative calculation
val kArray = Array(2, 3, 4, 5, 6, 7, 8)
val wssseMap = kArray.map(f = k => {
val kmeans = new KMeans()
.setK(k)
.setMaxIter(10)
.setPredictionCol("prediction")
.setFeaturesCol("features")
val model: KMeansModel = kmeans.fit(vectored)
import spark.implicits._
// mlLib calculation loss function
val vestors: Array[OldVector] = model.clusterCenters.map(v => OldVectors.fromML(v))
val libModel: LibKMeansModel = new LibKMeansModel(vestors)
val features = vectored.rdd.map(row => {
val ve = row.getAs[Vector]("features")
val oldVe: OldVector = OldVectors.fromML(ve)
oldVe
})
val wssse: Double = libModel.computeCost(features)
(k, wssse)
}).toMap
Classification model - predicting gender
- There are two meanings of shopping gender model:
- Predict the gender of users through their shopping behavior
- Through the user's shopping behavior, determine the user's shopping gender preference
1 preset label, quantization attribute
|memberId| color|productType|gender|colorIndex| color| productType|gender|productTypeIndex| features|featuresIndex|
+--------+------+-----------+------+----------+------------------+---------------+------+----------------+-----------+-------------+
| 4|Cherry Blossom powder| Smart TV| 1| 14.0|Cherry Blossom powder| Smart TV| 1| 13.0|[14.0,13.0]| [14.0,13.0]|
| 4|Cherry Blossom powder| Smart TV| 1| 14.0| blue| Haier/Haier refrigerator| 0| 1.0| [14.0,1.0]| [14.0,1.0]|
val label = when('ogColor.equalTo("Cherry Blossom powder")
.or('ogColor.equalTo("white"))
.or('ogColor.equalTo("Champagne"))
.or('ogColor.equalTo("Champagne gold"))
.or('productType.equalTo("food processor"))
.or('productType.equalTo("Hanging ironing machine"))
.or('productType.equalTo("Vacuum cleaner/Mite remover")), 1)
.otherwise(0)
.alias("gender")
2 decision tree algorithm
- Decision tree is a supervised learning algorithm, which needs to manually label the data set first. Here, the overall process is simplified, and the required labels are preset through simple matching
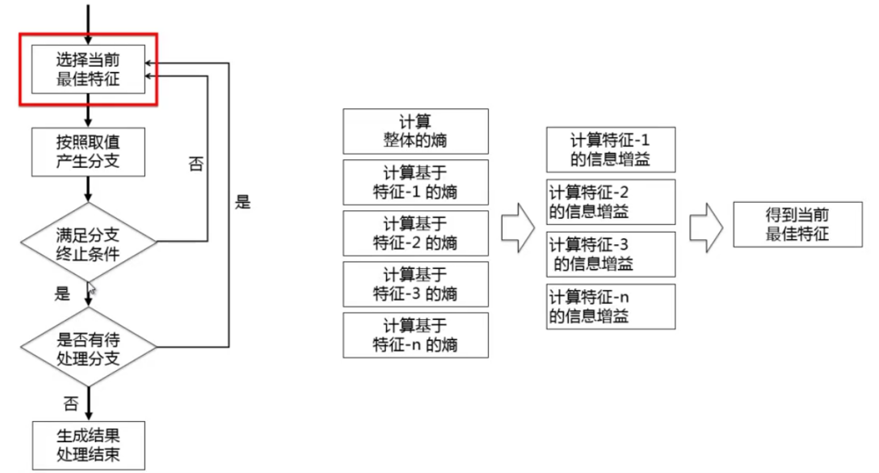
3 algorithm engineering and model evaluation
val featureVectorIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("featuresIndex")
.setMaxCategories(3)
val decisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("featuresIndex")
.setLabelCol("gender")
.setPredictionCol("predict")
.setMaxDepth(5)
.setImpurity("gini")
val pipeline = new Pipeline()
.setStages(Array(colorIndexer, productTypeIndexer, featureAssembler, featureVectorIndexer, decisionTreeClassifier))
val Array(trainData, testData) = source.randomSplit(Array(0.8, 0.2))
val model: PipelineModel = pipeline.fit(trainData)
val pTrain = model.transform(trainData)
val tTrain = model.transform(testData)
val accEvaluator = new MulticlassClassificationEvaluator()
.setPredictionCol("predict")
.setLabelCol("gender")
.setMetricName("accuracy")//accuracy