Algorithms Series 15 Days Quick - Seven Classic Sorting on the Third Day
Today I'm going to talk about the last three sorts of sorting: direct insertion sort, Hill sort and merge sort.
Direct insertion sort:
This sort is quite understandable. A real example is that we fight against landlords. When we catch a hand of random cards, we have to sort out the cards according to their size. After 30 seconds,
After carding poker, 4 3, 5 s, wow... recall how we did it.
The leftmost card is 3, the second card is 5, and the third card is 3. Put it behind the first card and the fourth card is 3.
The fifth card is 3, ecstasy, haha, a gun came into being.
Well, there are algorithms everywhere in our life, which have already been integrated into our life and blood.
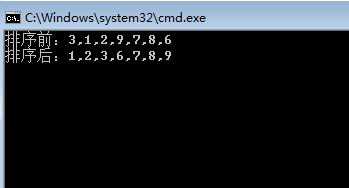
Following is the illustration of the above picture:

Look at this picture, I don't know if you can understand that in insertion sort, arrays are divided into two kinds: ordered array blocks and disordered array blocks.
Yes, on the first pass, a number 20 is extracted from the Unordered Array Block as an ordered array block.
On the second pass, an orderly number of 60 is extracted from the "disordered array block" and placed in the "ordered array block", that is, 20,60.
The third time, the same thing happens, except that 10 is found to be smaller than the value of an ordered array, so 20, 60 positions are moved backwards and a position is set aside for 10 to insert.
Then you can insert all of them according to this rule.

Hill Sort:
Watch Insert Sort: It's not hard to see that she has a weakness:
If the data is "5, 4, 3, 2, 1", then we insert the records in the "disordered block" into the "ordered block", we estimate that we are going to crash.
Move the position every time you insert, and the efficiency of insertion sort can be imagined.
Based on this weakness, shell has improved its algorithm and incorporated an idea called "Reduced Incremental Sorting", which is actually quite simple, but a little noteworthy is that:
Increments are not arbitrary, but regular.
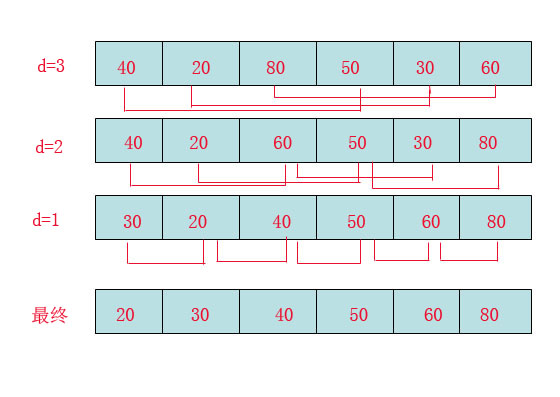
First of all, we need to clarify the method of increment.
The first increment is d=count/2;
The second increment is d=(count/2)/2;
Last until: d=1;
The phenomena observed in the picture above are as follows:
d=3:40 to 50, because 50 is big, no exchange.
Compare 20 to 30, because 30 is big, no exchange.
Compare 80 to 60, because 60 is small, exchange.
d=2:40 to 60, no exchange, 60 to 30, then 30 is smaller than 40, and 40 and 30 are exchanged, as shown above.
Make 20 to 50, no exchange, continue to make 50 to 80, no exchange.
d=1: This is the insertion sort mentioned earlier, but the sequence is almost ordered at this time, which brings a great performance improvement to the insertion sort.
Since Hill Sorting is an improved version of Insert Sorting, how much faster can we get in a wh number than that?
Here's a test:

 View Code
View CodeThe screenshots are as follows:
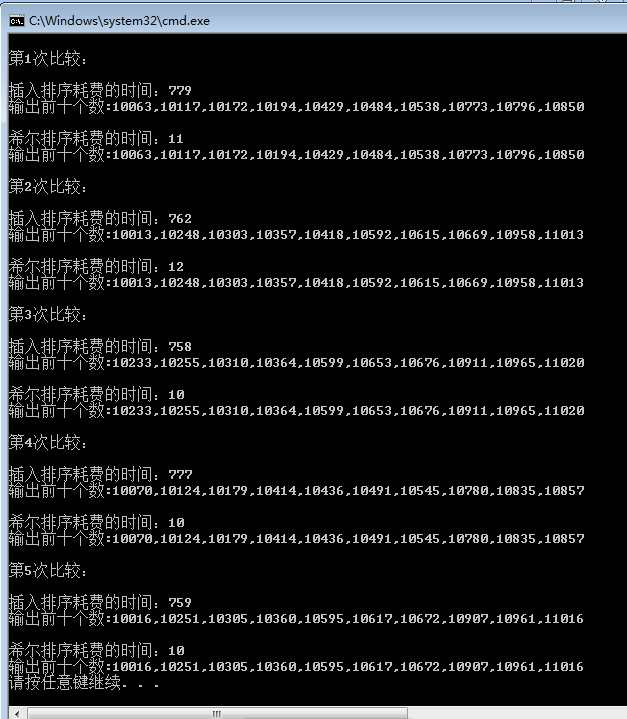
As you can see, Hill ranking has been optimized a lot. In w ranking, the difference is more than 70 times wow.
Merge Sort:
Personally, the sorting that we can easily understand is basically O (n^2), and the sorting that is more difficult to understand is basically N(LogN), so merge sorting is also more difficult to understand, especially in code.
Writing, I just did it all afternoon, giggling.
First look at the picture:

There are two things to do in merging and sorting:
The first is "score", which is to divide arrays as much as possible up to the atomic level.
The second is "union", which combines two or two atomic levels and produces results.
Code:
Results:
ps: The time complexity of insertion sort is: O(N^2)
The time complexity of Hill sort is: O(N^3/2)
Worst: O(N^2)
The time complexity of merge sort is O(NlogN)
Spatial complexity: O(N)