Task2 Alibaba Tianchi Python syntax record
Python basic exercise data structure summary
Delete list contents:
Both remove and pop can delete elements. The former specifies the specific element to be deleted, and the latter specifies an index.
del var1[, var2...] Deletes one or more objects.
Get elements in the list:
Get a single element from the list through the index value of the element. Note that the list index value starts from 0.
By specifying an index of - 1, Python returns the last list element, an index of - 2 returns the penultimate list element, and so on.
section:
x = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] print(x[3:]) # ['Thursday', 'Friday'] print(x[-3:]) # ['Wednesday', 'Thursday', 'Friday'] week = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] print(week[:3]) # ['Monday', 'Tuesday', 'Wednesday'] print(week[:-3]) # ['Monday', 'Tuesday'] week = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] print(week[1:3]) # ['Tuesday', 'Wednesday'] print(week[-3:-1]) # ['Wednesday', 'Thursday'] week = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] print(week[1:4:2]) # ['Tuesday', 'Thursday'] print(week[:4:2]) # ['Monday', 'Wednesday'] print(week[1::2]) # ['Tuesday', 'Thursday'] print(week[::-1]) #Setting step to - 1 is equivalent to reversing the list # ['Friday', 'Thursday', 'Wednesday', 'Tuesday', 'Monday']
Light copy and deep copy:
list1 = [123, 456, 789, 213] list2 = list1 list3 = list1[:] print(list2) # [123, 456, 789, 213] print(list3) # [123, 456, 789, 213] list1.sort() print(list2) # [123, 213, 456, 789] print(list3) # [123, 456, 789, 213] list1 = [[123, 456], [789, 213]] list2 = list1 list3 = list1[:] print(list2) # [[123, 456], [789, 213]] print(list3) # [[123, 456], [789, 213]] list1[0][0] = 111 print(list2) # [[111, 456], [789, 213]] print(list3) # [[111, 456], [789, 213]]
Index lookup for list:
list.index(x[, start[, end]]) finds the index position of the first match of a value from the list
list1 = [123, 456] * 5 print(list1.index(123)) # 0 print(list1.index(123, 1)) # 2 print(list1.index(123, 3, 7)) # 4
list.reverse() reverses the elements in the list
x = [123, 456, 789] x.reverse() print(x) # [789, 456, 123]
list.sort(key=None, reverse=False) sorts the original list.
key – it is mainly used to compare elements. There is only one parameter. The parameters of the specific function are taken from the iteratable object. Specify an element in the iteratable object to sort.
Reverse – collation, reverse = True descending, reverse = False ascending (default).
This method does not return a value, but sorts the objects in the list.
x = [123, 456, 789, 213]
x.sort()
print(x)
# [123, 213, 456, 789]
x.sort(reverse=True)
print(x)
# [789, 456, 213, 123]
# Gets the second element of the list
def takeSecond(elem):
return elem[1]
x = [(2, 2), (3, 4), (4, 1), (1, 3)]
x.sort(key=takeSecond)
print(x)
# [(4, 1), (2, 2), (1, 3), (3, 4)]
x.sort(key=lambda a: a[0])
print(x)
# [(1, 3), (2, 2), (3, 4), (4, 1)]
Tuple:
Python tuples are similar to lists, except that tuples cannot be modified after they are created, which is similar to strings.
Tuples use parentheses and lists use square brackets.
Tuples, like lists, are indexed and sliced with integers.
t1 = (1, 10.31, 'python') t2 = 1, 10.31, 'python' print(t1, type(t1)) # (1, 10.31, 'python') <class 'tuple'> print(t2, type(t2)) # (1, 10.31, 'python') <class 'tuple'> tuple1 = (1, 2, 3, 4, 5, 6, 7, 8) print(tuple1[1]) # 2 print(tuple1[5:]) # (6, 7, 8) print(tuple1[:5]) # (1, 2, 3, 4, 5) tuple2 = tuple1[:] print(tuple2) # (1, 2, 3, 4, 5, 6, 7, 8)
You can create tuples with parentheses (), or without anything. For readability, it is recommended to use ().
When a tuple contains only one element, you need to add a comma after the element, otherwise the parentheses will be used as operators.
x = (1) print(type(x)) # <class 'int'> x = 2, 3, 4, 5 print(type(x)) # <class 'tuple'> x = [] print(type(x)) # <class 'list'> x = () print(type(x)) # <class 'tuple'> x = (1,) print(type(x)) # <class 'tuple'>
Tuples have immutable properties, so we cannot directly assign values to the elements of tuples. However, as long as the elements in tuples are mutable, we can directly change their elements. Note that this is different from assigning their elements.
t1 = (1, 2, 3, [4, 5, 6]) print(t1) # (1, 2, 3, [4, 5, 6]) t1[3][0] = 9 print(t1) # (1, 2, 3, [9, 5, 6])
The tuple size and content cannot be changed, so there are only count and index methods.
Decompress tuples:
unpack a one-dimensional tuple (there are several elements, and the left parenthesis defines several variables)
Decompress two-dimensional tuples (define variables according to the tuple structure in tuples)
If you only want a few elements of a tuple, use the wildcard, "", which is called wildcard in English, and represents one or more elements in computer language.
If you don't care about rest variables at all, underline "" with wildcard "".
character string:
In Python, a string is defined as a collection of characters between quotation marks.
Python supports the use of paired single or double quotation marks.
If you need single or double quotation marks in the string, you can use the escape symbol \ to escape the symbols in the string.
The original string only needs to be preceded by an English letter r.
Three quotation marks allow a string to span multiple lines. The string can contain line breaks, tabs and other special characters.
Slicing and splicing of strings:
Similar to tuples, it is immutable
Start with 0 (like Java)
Slices are usually written in the form of start:end, including the elements corresponding to the "start index" and excluding the elements corresponding to the "end index".
The index value can be positive or negative, and the positive index starts from 0, from left to right; The negative index starts from - 1, right to left. When a negative index is used, the count starts from the last element. The position number of the last element is - 1.
Common built-in methods for Strings:
capitalize() converts the first character of a string to uppercase.
lower() converts all uppercase characters in the string to lowercase.
upper() converts lowercase letters in a string to uppercase.
swapcase() converts uppercase to lowercase and lowercase to uppercase in the string.
count(str, beg= 0,end=len(string)) returns the number of occurrences of str in the string. If beg or end is specified, it returns the number of occurrences of str in the specified range.
Endswitch (suffix, beg = 0, end = len (string)) checks whether the string ends with the specified substring suffix. If yes, it returns True; otherwise, it returns False. If beg and end specify values, check within the specified range.
Startswitch (substr, beg = 0, end = len (string)) checks whether the string starts with the specified substr. If yes, it returns True; otherwise, it returns False. If beg and end specify values, check within the specified range.
find(str, beg=0, end=len(string)) checks whether str is included in the string. If the specified range is beg and end, check whether it is included in the specified range. If it is included, return the starting index value, otherwise return - 1.
rfind(str, beg=0,end=len(string)) is similar to the find() function, but it starts from the right.
isnumeric() returns True if the string contains only numeric characters, otherwise False.
ljust(width[, fillchar]) returns a left aligned original string and fills the new string with fillchar (default space) to the length width.
rjust(width[, fillchar]) returns a right aligned original string and fills the new string with fillchar (default space) to the length width.
lstrip([chars]) truncates the space or specified character to the left of the string.
rstrip([chars]) deletes spaces or specified characters at the end of a string.
strip([chars]) executes lstrip() and rstrip() on a string.
partition(sub) finds the substring sub and divides the string into a triple (pre_sub,sub,fol_sub). If the string does not contain sub, it returns ('original string ',', ').
rpartition(sub) is similar to the partition() method, but it starts from the right.
replace(old, new [, max]) replaces old in the string with new. If max is specified, the replacement shall not exceed max times.
split(str="", num) has no parameters. The default is to slice strings with spaces as separators. If the num parameter is set, only num substrings will be separated and a list of spliced substrings will be returned.
str5 = ' I Love LsgoGroup '
print(str5.strip().split()) # ['I', 'Love', 'LsgoGroup']
print(str5.strip().split('o')) # ['I L', 've Lsg', 'Gr', 'up']
u = "www.baidu.com.cn"
# Use default separator
print(u.split()) # ['www.baidu.com.cn']
# With "." Is a separator
print((u.split('.'))) # ['www', 'baidu', 'com', 'cn']
# Split 0 times
print((u.split(".", 0))) # ['www.baidu.com.cn']
# Split once
print((u.split(".", 1))) # ['www', 'baidu.com.cn']
# Split twice
print(u.split(".", 2)) # ['www', 'baidu', 'com.cn']
# Split twice and take the item with sequence 1
print((u.split(".", 2)[1])) # baidu
# Split twice, and save the divided three parts to three variables
u1, u2, u3 = u.split(".", 2)
print(u1) # www
print(u2) # baidu
print(u3) # com.cn
Splitlines ([keepers]) are separated by lines ('\ r', '\ r\n', \ n ') and return a list containing lines as elements. If the parameter keepers is False, it does not contain line breaks. If it is True, it retains line breaks.
Maketrans (inb, outtab) creates a character mapping conversion table. The first parameter is a string, which represents the characters to be converted, and the second parameter is also a string, which represents the target of conversion.
translate(table, deletechars = "") convert the characters of the string according to the table given by the parameter table, and put the characters to be filtered into the deletechars parameter.
str7 = 'this is string example....wow!!!'
intab = 'aeiou'
outtab = '12345'
trantab = str7.maketrans(intab, outtab)
print(trantab) # {97: 49, 111: 52, 117: 53, 101: 50, 105: 51}
print(str7.translate(trantab)) # th3s 3s str3ng 2x1mpl2....w4w!!!
# Press the ALT key, then press the number on the keypad, and release the ALT key to get the character corresponding conversion table, that is, 97 corresponds to a, 49 corresponds to 1...
format formatting function
str8 = "{0} Love {1}".format('I', 'Lsgogroup') # Position parameters
print(str8) # I Love Lsgogroup
str8 = "{a} Love {b}".format(a='I', b='Lsgogroup') # Keyword parameters
print(str8) # I Love Lsgogroup
str8 = "{0} Love {b}".format('I', b='Lsgogroup') # The location parameter should precede the keyword parameter
print(str8) # I Love Lsgogroup
str8 = '{0:.2f}{1}'.format(27.658, 'GB') # Keep two decimal places
print(str8) # 27.66GB
Python string formatting symbol
%c format characters and their ASCII codes
%s format the string, and use the str() method to process the object
%r format the string and process the object with the rper() method
%d format integer
%o format unsigned octal numbers
%x format unsigned hexadecimal number
%X format unsigned hexadecimal number (upper case)
%f format floating-point numbers to specify the precision after the decimal point
%e format floating point numbers with scientific counting method
%E works the same as% e, formatting floating-point numbers with scientific counting method
%g use% f or% e depending on the size of the value
%g is the same as% g, and% f or% E are used according to the size of the value
Formatting operator helper
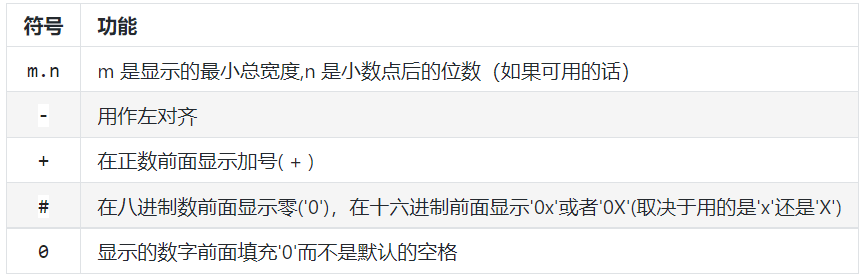
print('%c' % 97) # a
print('%c %c %c' % (97, 98, 99)) # a b c
print('%d + %d = %d' % (4, 5, 9)) # 4 + 5 = 9
print("My name is %s this year %d year!" % ('Xiao Ming', 10)) # My name is Xiao Ming. I'm 10 years old!
print('%o' % 10) # 12
print('%x' % 10) # a
print('%X' % 10) # A
print('%f' % 27.658) # 27.658000
print('%e' % 27.658) # 2.765800e+01
print('%E' % 27.658) # 2.765800E+01
print('%g' % 27.658) # 27.658
text = "I am %d years old." % 22
print("I said: %s." % text) # I said: I am 22 years old..
print("I said: %r." % text) # I said: 'I am 22 years old.'
print('%5.1f' % 27.658) # ' 27.7'
print('%.2e' % 27.658) # 2.77e+01
print('%10d' % 10) # ' 10'
print('%-10d' % 10) # '10 '
print('%+d' % 10) # +10
print('%#o' % 10) # 0o12
print('%#x' % 108) # 0x6c
print('%010d' % 5) # 0000000005
Dictionaries
Definition of Dictionary:
The dictionary is an unordered set of key:value pairs. The keys must be different from each other (within the same dictionary).
The internal storage order of dict has nothing to do with the order in which key s are placed.
dict search and insert speed is very fast and will not increase with the increase of key s, but it needs to occupy a lot of memory.
The dictionary definition syntax is {element 1, element 2,..., element n}
Each element is a "key value pair" -- key: value
The key points are braces {}, commas, and colons
Braces – tie all elements together
Comma – separate each key value pair
Colon – separates the key from the value
brand = ['Li Ning', 'Nike', 'Adidas']
slogan = ['Anything is possible', 'Just do it', 'Impossible is nothing']
print('Nike's slogan is:', slogan[brand.index('Nike')])
# Nike's slogan is: Just do it
dic = {'Li Ning': 'Anything is possible', 'Nike': 'Just do it', 'Adidas': 'Impossible is nothing'}
print('Nike's slogan is:', dic['Nike'])
# Nike's slogan is: Just do it
Note: if the key we selected does not exist in the dictionary, an error KeyError will be reported directly
Create a dictionary through the constructor dict.
dict() creates an empty dictionary.
[example] directly put the data into the dictionary through the key, but a key can only correspond to one value. If you put value into a key multiple times, the subsequent value will flush out the previous value.
dic = dict()
dic['a'] = 1
dic['b'] = 2
dic['c'] = 3
print(dic)
# {'a': 1, 'b': 2, 'c': 3}
dic['a'] = 11
print(dic)
# {'a': 11, 'b': 2, 'c': 3}
dic['d'] = 4
print(dic)
# {'a': 11, 'b': 2, 'c': 3, 'd': 4}
dic1 = dict([('apple', 4139), ('peach', 4127), ('cherry', 4098)])
print(dic1) # {'apple': 4139, 'peach': 4127, 'cherry': 4098}
Built in method of Dictionary:
dict.fromkeys(seq[, value]) is used to create a new dictionary. The elements in seq sequence are used as dictionary keys. Value is the initial value corresponding to all keys in the dictionary.
seq = ('name', 'age', 'sex')
dic1 = dict.fromkeys(seq)
print(dic1)
# {'name': None, 'age': None, 'sex': None}
dic2 = dict.fromkeys(seq, 10)
print(dic2)
# {'name': 10, 'age': 10, 'sex': 10}
dic3 = dict.fromkeys(seq, ('pony', '8', 'male'))
print(dic3)
# {'name': ('pony ',' 8 ',' male '),'age': ('pony ',' 8 ',' male '),'sex': ('pony ',' 8 ',' male ')}
dict.keys() returns an iteratable object. You can use list() to convert it into a list. The list is all the keys in the dictionary.
dic = {'Name': 'lsgogroup', 'Age': 7}
print(dic.keys()) # dict_keys(['Name', 'Age'])
lst = list(dic.keys()) # Convert to list
print(lst) # ['Name', 'Age']
dict.values() returns an iterator that can be converted into a list using list(), which is all the values in the dictionary.
dic = {'Sex': 'female', 'Age': 7, 'Name': 'Zara'}
print(dic.values())
# dict_values(['female', 7, 'Zara'])
print(list(dic.values()))
# ['female', 7, 'Zara']
dict.items() returns an array of traversable (key, value) tuples in a list.
dic = {'Name': 'Lsgogroup', 'Age': 7}
print(dic.items())
# dict_items([('Name', 'Lsgogroup'), ('Age', 7)])
print(tuple(dic.items()))
# (('Name', 'Lsgogroup'), ('Age', 7))
print(list(dic.items()))
# [('Name', 'Lsgogroup'), ('Age', 7)]
dict.get(key, default=None) returns the value of the specified key. If the value is not in the dictionary, it returns the default value.
dic = {'Name': 'Lsgogroup', 'Age': 27}
print("Age Value is : %s" % dic.get('Age')) # Age value: 27
print("Sex Value is : %s" % dic.get('Sex', "NA")) # Sex value: NA
print(dic) # {'Name': 'Lsgogroup', 'Age': 27}
dict.setdefault(key, default=None) is similar to the get() method. If the key does not exist in the dictionary, the key will be added and the value will be set as the default value.
dic = {'Name': 'Lsgogroup', 'Age': 7}
print("Age The value of the key is : %s" % dic.setdefault('Age', None)) # The value of the Age key is: 7
print("Sex The value of the key is : %s" % dic.setdefault('Sex', None)) # The value of the Sex key is: None
print(dic)
# {'Name': 'Lsgogroup', 'Age': 7, 'Sex': None}
The key in dict in operator is used to determine whether the key exists in the dictionary. If the key is in the dictionary dict, it returns true; otherwise, it returns false. On the contrary, the not in operator returns false if the key is in the dictionary dict, otherwise it returns true.
dic = {'Name': 'Lsgogroup', 'Age': 7}
# in detects whether the key Age exists
if 'Age' in dic:
print("key Age existence")
else:
print("key Age non-existent")
# Check whether the key Sex exists
if 'Sex' in dic:
print("key Sex existence")
else:
print("key Sex non-existent")
# not in check whether the key Age exists
if 'Age' not in dic:
print("key Age non-existent")
else:
print("key Age existence")
# Key Age exists
# Key Sex does not exist
# Key Age exists
dict.pop(key[,default]) deletes the value corresponding to the key given in the dictionary, and the return value is the deleted value. The key value must be given. If the key does not exist, the default value is returned.
del dict[key] deletes the value corresponding to the key given in the dictionary.
dic1 = {1: "a", 2: [1, 2]}
print(dic1.pop(1), dic1) # a {2: [1, 2]}
# The default value must be added, otherwise an error will be reported
print(dic1.pop(3, "nokey"), dic1) # nokey {2: [1, 2]}
del dic1[2]
print(dic1) # {}
dict.popitem() randomly returns and deletes a pair of keys and values in the dictionary. If this method is called when the dictionary is empty, a KeyError exception is reported.
dic1 = {1: "a", 2: [1, 2]}
print(dic1.popitem()) # {2: [1, 2]}
print(dic1) # (1, 'a')
dict.clear() is used to delete all elements in the dictionary.
dic = {'Name': 'Zara', 'Age': 7}
print("Dictionary length : %d" % len(dic)) # Dictionary length: 2
dic.clear()
print("Length after dictionary deletion : %d" % len(dic))
# Length after dictionary deletion: 0
dict.copy() returns a shallow copy of a dictionary.
dic1 = {'Name': 'Lsgogroup', 'Age': 7, 'Class': 'First'}
dic2 = dic1.copy()
print(dic2)
# {'Name': 'Lsgogroup', 'Age': 7, 'Class': 'First'}
The difference between direct assignment and copy
dic1 = {'user': 'lsgogroup', 'num': [1, 2, 3]}
# Reference object
dic2 = dic1
# Shallow copy parent object (level-1 directory), child object (level-2 directory) is not copied, or is it referenced
dic3 = dic1.copy()
print(id(dic1)) # 148635574728
print(id(dic2)) # 148635574728
print(id(dic3)) # 148635574344
# Modify data
dic1['user'] = 'root'
dic1['num'].remove(1)
# Output results
print(dic1) # {'user': 'root', 'num': [2, 3]}
print(dic2) # {'user': 'root', 'num': [2, 3]}
print(dic3) # {'user': 'lsgogroup', 'num': [2, 3]}
dict.update(dict2) updates the key:value pair of the dictionary parameter dict2 to the dictionary dict.
dic = {'Name': 'Lsgogroup', 'Age': 7}
dic2 = {'Sex': 'female', 'Age': 8}
dic.update(dic2)
print(dic)
# {'Name': 'Lsgogroup', 'Age': 8, 'Sex': 'female'}
aggregate
Similar to dict, set in Python is also a set of keys, but does not store value. Since keys cannot be repeated, there are no duplicate keys in set.
Note that the key is an immutable type, that is, the hash value.
num = {}
print(type(num)) # <class 'dict'>
num = {1, 2, 3, 4}
print(type(num)) # <class 'set'>
- Creation of collections
Create objects before adding elements.
When creating an empty collection, only s = set() can be used because s = {} creates an empty dictionary.
basket = set()
basket.add('apple')
basket.add('banana')
print(basket) # {'banana', 'apple'}
Directly enclose a pile of elements in curly braces {element 1, element 2,..., element n}.
Duplicate elements are automatically filtered in the set.
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # {'banana', 'apple', 'pear', 'orange'}
Use the set(value) factory function to convert a list or tuple into a set.
a = set('abracadabra')
print(a)
# {'r', 'b', 'd', 'c', 'a'}
b = set(("Google", "Lsgogroup", "Taobao", "Taobao"))
print(b)
# {'Taobao', 'Lsgogroup', 'Google'}
c = set(["Google", "Lsgogroup", "Taobao", "Google"])
print(c)
# {'Taobao', 'Lsgogroup', 'Google'}
Remove duplicate elements from the list
lst = [0, 1, 2, 3, 4, 5, 5, 3, 1]
temp = []
for item in lst:
if item not in temp:
temp.append(item)
print(temp) # [0, 1, 2, 3, 4, 5]
a = set(lst)
print(list(a)) # [0, 1, 2, 3, 4, 5]
From the results, we find two characteristics of sets: unordered and unique.
Because set stores unordered sets, we cannot create indexes or perform slice operations for the set, and there are no keys to obtain the values of elements in the set, but we can judge whether an element is in the set.
Accessing values in a collection
You can use the len() built-in function to get the size of the collection
s = set(['Google', 'Baidu', 'Taobao']) print(len(s)) # 3
You can use for to read the data in the set one by one.
s = set(['Google', 'Baidu', 'Taobao'])
for item in s:
print(item)
# Baidu
# Google
# Taobao
You can judge whether an element already exists in the collection by in or not in
s = set(['Google', 'Baidu', 'Taobao'])
print('Taobao' in s) # True
print('Facebook' not in s) # True
Built in methods for Collections:
set.add(elmnt) is used to add elements to the collection. If the added elements already exist in the collection, no operation will be performed.
fruits = {"apple", "banana", "cherry"}
fruits.add("orange")
print(fruits)
# {'orange', 'cherry', 'banana', 'apple'}
fruits.add("apple")
print(fruits)
# {'orange', 'cherry', 'banana', 'apple'}
set.update(set) is used to modify the current set. You can add a new element or set to the current set. If the added element already exists in the set, the element will only appear once, and the repeated elements will be ignored.
x = {"apple", "banana", "cherry"}
y = {"google", "baidu", "apple"}
x.update(y)
print(x)
# {'cherry', 'banana', 'apple', 'google', 'baidu'}
y.update(["lsgo", "dreamtech"])
print(y)
# {'lsgo', 'baidu', 'dreamtech', 'apple', 'google'}
set.remove(item) is used to remove the specified element from the collection. If the element does not exist, an error occurs.
fruits = {"apple", "banana", "cherry"}
fruits.remove("banana")
print(fruits) # {'apple', 'cherry'}
set.discard(value) is used to remove the specified collection element. The remove() method will cause an error when removing a non-existent element, while the discard() method will not.
fruits = {"apple", "banana", "cherry"}
fruits.discard("banana")
print(fruits) # {'apple', 'cherry'}
set.pop() is used to randomly remove an element.
fruits = {"apple", "banana", "cherry"}
x = fruits.pop()
print(fruits) # {'cherry', 'apple'}
print(x) # banana
Because set is a set of unordered and non repeating elements, two or more sets can do set operations in the mathematical sense.
set.intersection(set1, set2) returns the intersection of two sets.
Set1 & set2 returns the intersection of two sets.
set.intersection_update(set1, set2) intersection to remove non overlapping elements from the original set.
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
c = a.intersection(b)
print(c) # {'a', 'c'}
print(a & b) # {'c', 'a'}
print(a) # {'a', 'r', 'c', 'b', 'd'}
a.intersection_update(b)
print(a) # {'a', 'c'}
set.union(set1, set2) returns the union of two sets.
set1 | set2 returns the union of two sets.
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
print(a | b)
# {'l', 'd', 'm', 'b', 'a', 'r', 'z', 'c'}
c = a.union(b)
print(c)
# {'c', 'a', 'd', 'm', 'r', 'b', 'z', 'l'}
set.difference(set) returns the difference set of the set.
set1 - set2 returns the difference set of the set.
set.difference_update(set) is the difference set of the set. The element is directly removed from the original set without return value.
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
c = a.difference(b)
print(c) # {'b', 'd', 'r'}
print(a - b) # {'d', 'b', 'r'}
print(a) # {'r', 'd', 'c', 'a', 'b'}
a.difference_update(b)
print(a) # {'d', 'r', 'b'}
set.symmetric_difference(set) returns the XOR of the set.
set1 ^ set2 returns the XOR of the set.
set.symmetric_difference_update(set) removes the same elements in another specified set in the current set, and inserts different elements in another specified set into the current set.
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
c = a.symmetric_difference(b)
print(c) # {'m', 'r', 'l', 'b', 'z', 'd'}
print(a ^ b) # {'m', 'r', 'l', 'b', 'z', 'd'}
print(a) # {'r', 'd', 'c', 'a', 'b'}
a.symmetric_difference_update(b)
print(a) # {'r', 'b', 'm', 'l', 'z', 'd'}
set.issubset(set) determines whether the set is contained by other sets. If yes, it returns True; otherwise, it returns False.
Set1 < = set2 determines whether the set is included by other sets. If so, it returns True; otherwise, it returns False.
x = {"a", "b", "c"}
y = {"f", "e", "d", "c", "b", "a"}
z = x.issubset(y)
print(z) # True
print(x <= y) # True
x = {"a", "b", "c"}
y = {"f", "e", "d", "c", "b"}
z = x.issubset(y)
print(z) # False
print(x <= y) # False
set.issuperset(set) is used to judge whether the set contains other sets. If yes, it returns True; otherwise, it returns False.
Set1 > = set2 determines whether the set contains other sets. If so, it returns True; otherwise, it returns False.
x = {"f", "e", "d", "c", "b", "a"}
y = {"a", "b", "c"}
z = x.issuperset(y)
print(z) # True
print(x >= y) # True
x = {"f", "e", "d", "c", "b"}
y = {"a", "b", "c"}
z = x.issuperset(y)
print(z) # False
print(x >= y) # False
set.isdisjoint(set) is used to judge whether two sets do not intersect. If yes, it returns True; otherwise, it returns False.
x = {"f", "e", "d", "c", "b"}
y = {"a", "b", "c"}
z = x.isdisjoint(y)
print(z) # False
x = {"f", "e", "d", "m", "g"}
y = {"a", "b", "c"}
z = x.isdisjoint(y)
print(z) # True
Conversion of sets:
se = set(range(4))
li = list(se)
tu = tuple(se)
print(se, type(se)) # {0, 1, 2, 3} <class 'set'>
print(li, type(li)) # [0, 1, 2, 3] <class 'list'>
print(tu, type(tu)) # (0, 1, 2, 3) <class 'tuple'>
Immutable set:
Python provides an implementation version that cannot change the collection of elements, that is, elements cannot be added or deleted. The type is called frozenset. It should be noted that frozenset can still perform collection operations, but the method with update cannot be used.
frozenset([iterable]) returns a frozen collection. After freezing, no elements can be added or deleted from the collection.
a = frozenset(range(10)) # Generate a new immutable set
print(a)
# frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
b = frozenset('lsgogroup')
print(b)
# frozenset({'g', 's', 'p', 'r', 'u', 'o', 'l'})
sequence
In Python, sequence types include string, list, tuple, set and dictionary. These sequences support some general operations, but in particular, set and dictionary do not support index, slice, addition and multiplication operations.
- Built in functions for sequences
list(sub) converts an iteratable object into a list.
a = list() print(a) # [] b = 'I Love LsgoGroup' b = list(b) print(b) # ['I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p'] c = (1, 1, 2, 3, 5, 8) c = list(c) print(c) # [1, 1, 2, 3, 5, 8]
tuple(sub) converts an iteratable object into a tuple.
a = tuple()
print(a) # ()
b = 'I Love LsgoGroup'
b = tuple(b)
print(b)
# ('I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p')
c = [1, 1, 2, 3, 5, 8]
c = tuple(c)
print(c) # (1, 1, 2, 3, 5, 8)
str(obj) converts obj objects to strings
a = 123 a = str(a) print(a) # 123
len(s) returns the length of an object (character, list, tuple, etc.) or the number of elements. S – object.
a = list()
print(len(a)) # 0
b = ('I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p')
print(len(b)) # 16
c = 'I Love LsgoGroup'
print(len(c)) # 16
max(sub) returns the maximum value in the sequence or parameter set
print(max(1, 2, 3, 4, 5)) # 5
print(max([-8, 99, 3, 7, 83])) # 99
print(max('IloveLsgoGroup')) # v
min(sub) returns the minimum value in the sequence or parameter set
print(min(1, 2, 3, 4, 5)) # 1
print(min([-8, 99, 3, 7, 83])) # -8
print(min('IloveLsgoGroup')) # G
sum(iterable[, start=0]) returns the sum of the sequence iterable and the optional parameter start.
print(sum([1, 3, 5, 7, 9])) # 25 print(sum([1, 3, 5, 7, 9], 10)) # 35 print(sum((1, 3, 5, 7, 9))) # 25 print(sum((1, 3, 5, 7, 9), 20)) # 45
sorted(iterable, key=None, reverse=False) sorts all iteratable objects.
Iteratable – iteratable object.
key – it is mainly used to compare elements. There is only one parameter. The parameters of the specific function are taken from the iteratable object. Specify an element in the iteratable object to sort.
Reverse – collation, reverse = True descending, reverse = False ascending (default).
Returns a reordered list.
x = [-8, 99, 3, 7, 83]
print(sorted(x)) # [-8, 3, 7, 83, 99]
print(sorted(x, reverse=True)) # [99, 83, 7, 3, -8]
t = ({"age": 20, "name": "a"}, {"age": 25, "name": "b"}, {"age": 10, "name": "c"})
x = sorted(t, key=lambda a: a["age"])
print(x)
# [{'age': 10, 'name': 'c'}, {'age': 20, 'name': 'a'}, {'age': 25, 'name': 'b'}]
The reversed(seq) function returns an inverted iterator.
seq – the sequence to be converted, which can be tuple, string, list or range.
s = 'lsgogroup'
x = reversed(s)
print(type(x)) # <class 'reversed'>
print(x) # <reversed object at 0x000002507E8EC2C8>
print(list(x))
# ['p', 'u', 'o', 'r', 'g', 'o', 'g', 's', 'l']
t = ('l', 's', 'g', 'o', 'g', 'r', 'o', 'u', 'p')
print(list(reversed(t)))
# ['p', 'u', 'o', 'r', 'g', 'o', 'g', 's', 'l']
r = range(5, 9)
print(list(reversed(r)))
# [8, 7, 6, 5]
x = [-8, 99, 3, 7, 83]
print(list(reversed(x)))
# [83, 7, 3, 99, -8]
enumerate(sequence, [start=0])
[example] it is used to combine a traversable data object (such as list, tuple or string) into an index sequence, and list data and data subscripts at the same time. It is generally used in the for loop.
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
a = list(enumerate(seasons))
print(a)
# [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
b = list(enumerate(seasons, 1))
print(b)
# [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
for i, element in a:
print('{0},{1}'.format(i, element))
# 0,Spring
# 1,Summer
# 2,Fall
# 3,Winter
zip(iter1 [,iter2 [...]])
It is used to take the iteratable object as a parameter, package the corresponding elements in the object into tuples, and then return the object composed of these tuples. The advantage of this is to save a lot of memory.
We can use the list() transformation to output the list.
If the number of elements of each iterator is inconsistent, the length of the returned list is the same as that of the shortest object. The tuple can be decompressed into a list by using the * operator.
a = [1, 2, 3] b = [4, 5, 6] c = [4, 5, 6, 7, 8] zipped = zip(a, b) print(zipped) # <zip object at 0x000000C5D89EDD88> print(list(zipped)) # [(1, 4), (2, 5), (3, 6)] zipped = zip(a, c) print(list(zipped)) # [(1, 4), (2, 5), (3, 6)] a1, a2 = zip(*zip(a, b)) print(list(a1)) # [1, 2, 3] print(list(a2)) # [4, 5, 6]
It is only used as a learning record and is deleted in case of infringement