1. Title of competition
Script role emotion recognition Competition link: https://www.datafountain.cn/competitions/518
2. Competition background
The importance of scripts to the film and television industry is self-evident. A good script is not only the basis of good reputation and large traffic, but also can bring higher business returns. Script analysis is the first link in the film and television content production chain, in which the emotion recognition of script characters is a very important task, which mainly analyzes and identifies the emotion from multiple dimensions for each character involved in each dialogue and action description in the script. Compared with the usual emotional analysis of news and critical texts, it has its unique business characteristics and challenges.
3. Competition task
Part of the movie script is provided as the training set in this competition. The data of the training set has been manually marked. The participating teams need to analyze and identify the emotion of each character involved in each dialogue and action description in the script scene from multiple dimensions. The main difficulties and challenges of this task include: 1) the writing style of the script is quite different from the usual news corpus and is more colloquial; 2) The role emotion in the script does not only depend on the current text, but may be deeply dependent on the previous semantics.
4 data introduction
The data sources of the competition are mainly some movie scripts and the emotional annotation results of iqiyi annotation team, which are mainly used to provide model training and result verification to all participating teams.
Data description
Training data: the training data is in txt format, separated by English tabs. The first line is the header, and the field description is as follows:
Field name | type | describe | explain |
|---|---|---|---|
id | String | Data ID | - |
content | String | Text content | Script dialogue or action description |
character | String | Role name | Roles mentioned in the text |
emotion | String | Emotion recognition results (in order) | Love feeling value, music feeling value, fear feeling value, anger feeling value, fear feeling value, sadness feeling value |
remarks: 1) the definition of emotion in this competition consists of 6 categories (in order): love, music, fear, anger, fear and sadness; 2) emotion recognition results: the emotion values corresponding to the above six types of emotions are in a fixed order. The range of emotion values is [0, 1, 2, 3], 0-none, 1-weak, 2-medium, 3-strong, separated by English half angle commas; 3) the title does not need to identify the role name in the script; file code: UTF-8 no BOM code
5 evaluation criteria
The algorithm score of this competition adopts the commonly used root mean square error (RMSE) to calculate the score, which is counted according to the emotion value corresponding to the six types of emotion identified by "text content + role name".
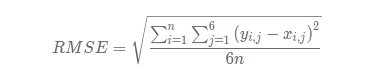
score = 1/(1 + RMSE)
Where is the emotional value predicted by Yi and j, Xi and j are the labeled emotional value, and n is the total number of test samples. The final ranking is based on score.
6 target learning based on pre training model
There are many operational aspects of this topic. When I first saw this competition, I thought of the model construction of multi outputs. Here I share this baseline. I hope some leaders can optimize this idea~
6.1 loading data
Read the data first
with open('data/train_dataset_v2.tsv', 'r', encoding='utf-8') as handler:
lines = handler.read().split('\n')[1:-1]
data = list()
for line in tqdm(lines):
sp = line.split('\t')
if len(sp) != 4:
print("ERROR:", sp)
continue
data.append(sp)
train = pd.DataFrame(data)
train.columns = ['id', 'content', 'character', 'emotions']
test = pd.read_csv('data/test_dataset.tsv', sep='\t')
submit = pd.read_csv('data/submit_example.tsv', sep='\t')
train = train[train['emotions'] != '']Extract emotional goals
train['emotions'] = train['emotions'].apply(lambda x: [int(_i) for _i in x.split(',')])
train[['love', 'joy', 'fright', 'anger', 'fear', 'sorrow']] = train['emotions'].values.tolist()6.2 building data sets
There are six labels for the dataset:
class RoleDataset(Dataset):
def __init__(self,texts,labels,tokenizer,max_len):
self.texts=texts
self.labels=labels
self.tokenizer=tokenizer
self.max_len=max_len
def __len__(self):
return len(self.texts)
def __getitem__(self,item):
"""
item For the data index, the iteration takes the second item Data bar
"""
text=str(self.texts[item])
label=self.labels[item]
encoding=self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=True,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
# print(encoding['input_ids'])
sample = {
'texts': text,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten()
}
for label_col in target_cols:
sample[label_col] = torch.tensor(label[label_col], dtype=torch.float)
return sample6.3 model construction
class EmotionClassifier(nn.Module):
def __init__(self, n_classes):
super(EmotionClassifier, self).__init__()
self.bert = BertModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
self.out_love = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_joy = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_fright = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_anger = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_fear = nn.Linear(self.bert.config.hidden_size, n_classes)
self.out_sorrow = nn.Linear(self.bert.config.hidden_size, n_classes)
def forward(self, input_ids, attention_mask):
_, pooled_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict = False
)
love = self.out_love(pooled_output)
joy = self.out_joy(pooled_output)
fright = self.out_fright(pooled_output)
anger = self.out_anger(pooled_output)
fear = self.out_fear(pooled_output)
sorrow = self.out_sorrow(pooled_output)
return {
'love': love, 'joy': joy, 'fright': fright,
'anger': anger, 'fear': fear, 'sorrow': sorrow,
}6.4 model training
The regression loss function directly selects NN. Mselos ()
EPOCHS = 1 # Number of training rounds optimizer = AdamW(model.parameters(), lr=3e-5, correct_bias=False) total_steps = len(train_data_loader) * EPOCHS scheduler = get_linear_schedule_with_warmup( optimizer, num_warmup_steps=0, num_training_steps=total_steps ) loss_fn = nn.MSELoss().to(device)
The total loss of the model is the sum of the six target values
def train_epoch(
model,
data_loader,
criterion,
optimizer,
device,
scheduler,
n_examples
):
model = model.train()
losses = []
correct_predictions = 0
for sample in tqdm(data_loader):
input_ids = sample["input_ids"].to(device)
attention_mask = sample["attention_mask"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
loss_love = criterion(outputs['love'], sample['love'].to(device))
loss_joy = criterion(outputs['joy'], sample['joy'].to(device))
loss_fright = criterion(outputs['fright'], sample['fright'].to(device))
loss_anger = criterion(outputs['anger'], sample['anger'].to(device))
loss_fear = criterion(outputs['fear'], sample['fear'].to(device))
loss_sorrow = criterion(outputs['sorrow'], sample['sorrow'].to(device))
loss = loss_love + loss_joy + loss_fright + loss_anger + loss_fear + loss_sorrow
losses.append(loss.item())
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# return correct_predictions.double() / (n_examples*6), np.mean(losses)
return np.mean(losses)Online submission 0.67+