origin #
One day, a colleague on the product side contacted him and reported an error in the bill transmission program. The phenomenon is as follows: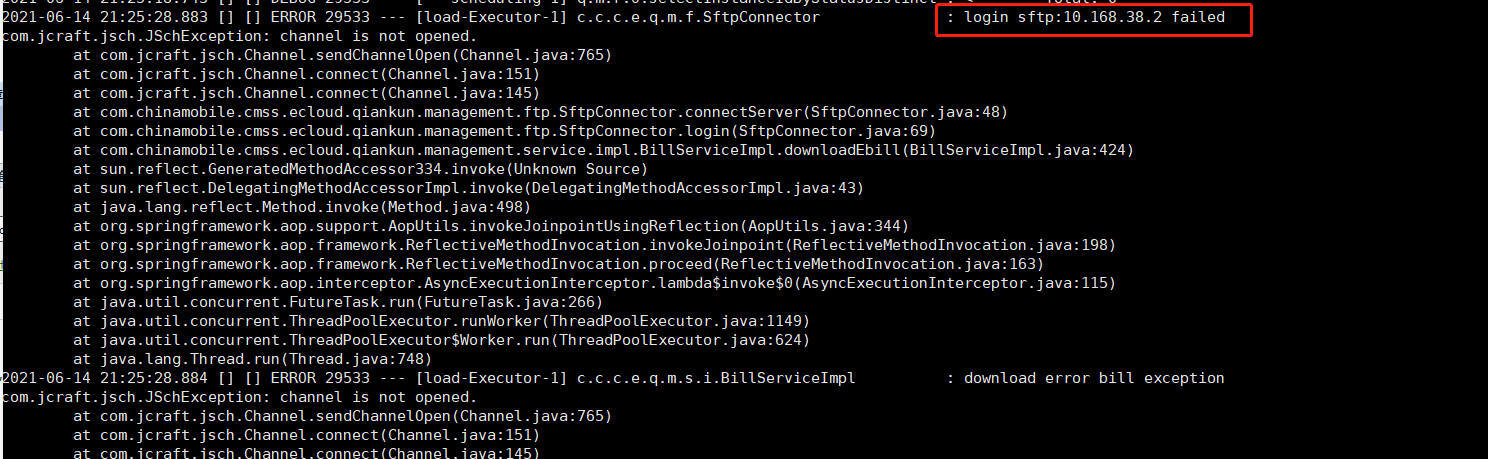
In fact, the node only provides an sftp service for the product side to transmit bills for temporary storage, which is taken away by the billing department.
analysis #
So I asked my o & M colleague to go to the server and found the following problems:
-
The ssh process is too high (because the sftp accounts assigned to each department in the early stage are different, the source can be identified by the account name)

-
According to the above information, the TCP link status is checked and it is found that most of them are ESTABLISHED connections:
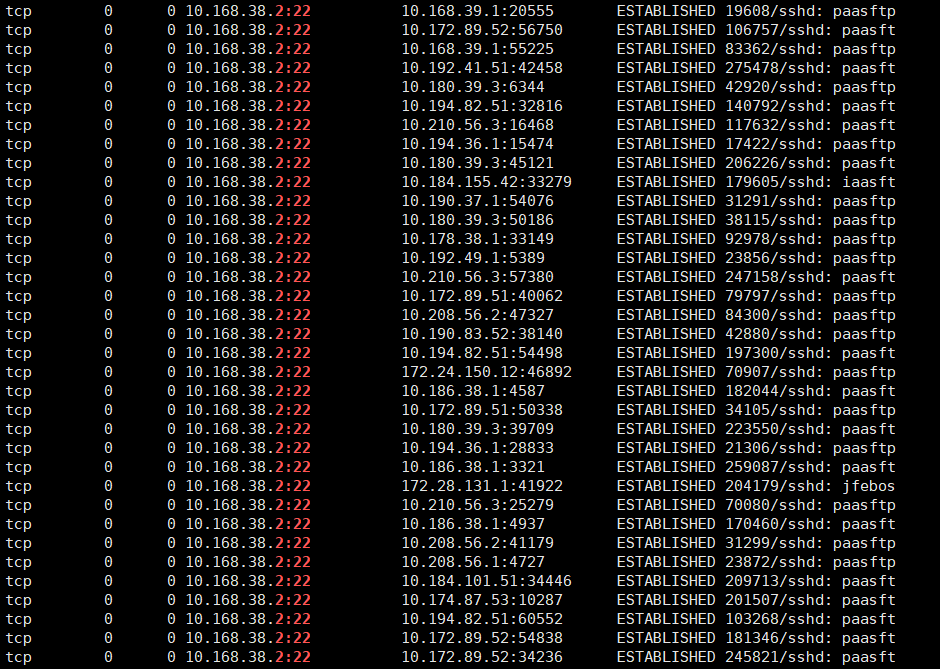
-
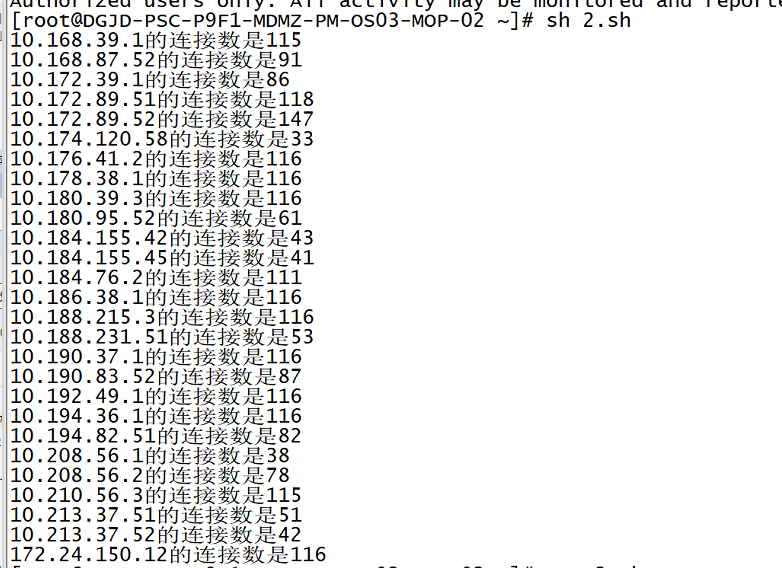
So I counted the sources of TCP links

#/bin/bash
for i in `netstat -ant | grep ESTABLISHED | awk '{print $5}' | awk -F: '{print $1}' | sort |uniq`
do
count=`netstat -ant | grep ESTABLISHED | grep $i|wc -l`
if [[ ${count} -ge 30 ]] ;then
echo "$i The number of connections is $count"
#else
# continue
fi
done
-
Discovery links mainly focus on some IP addresses:
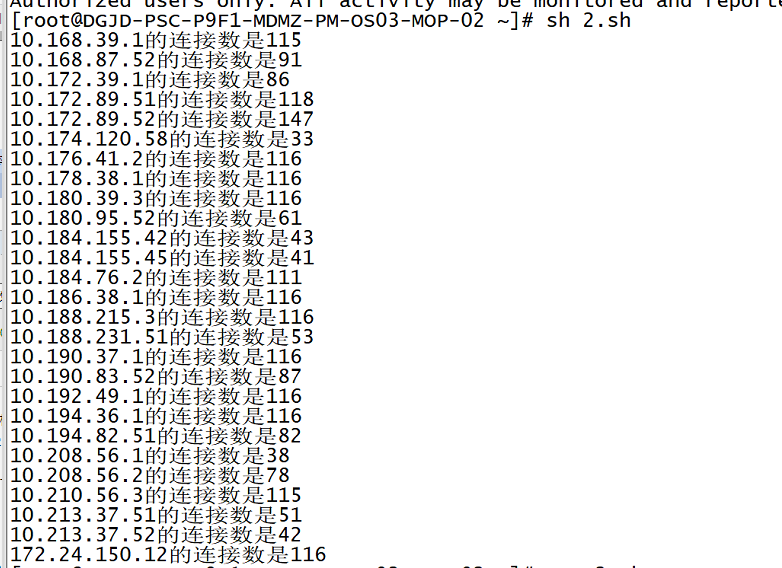
-
Due to the continuous rise of links, it is speculated that the ssh connection is not released normally in combination with the business scenario.
expand #
First of all, the link has accumulated tens of thousands in several days and is not automatically released. It can almost be concluded that the client is not released for the following reasons: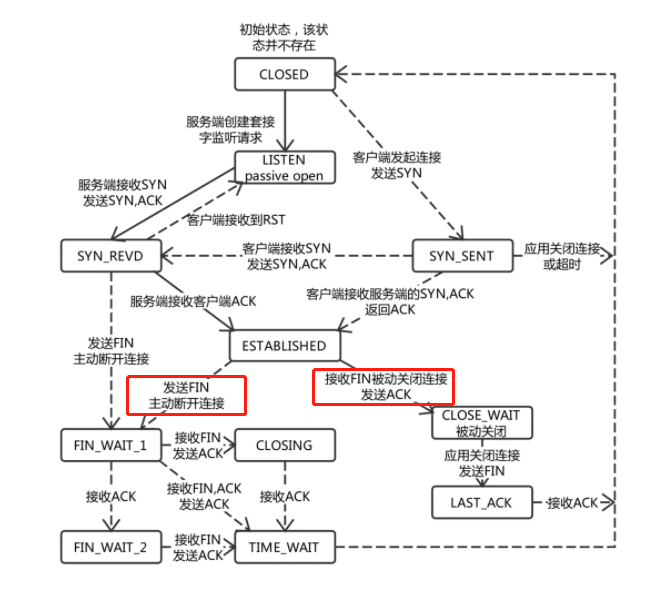
According to the state machine requested by TCP, the link in the ESTABLISHED state will actively disconnect the TCP link only when sending FIN or receiving FIN (that is, no one sends FIN);
Suppose a scenario in which the client sends a FIN but the server does not receive it because of the network or for some reason, the TCP keepalive mechanism will detect it many times and disconnect it (that means that the keepalive mechanism always responds).
Keep alive will be the next introduction to TCP request alive.
Root cause #
Therefore, the product side was organized to conduct troubleshooting and finally find the reason:
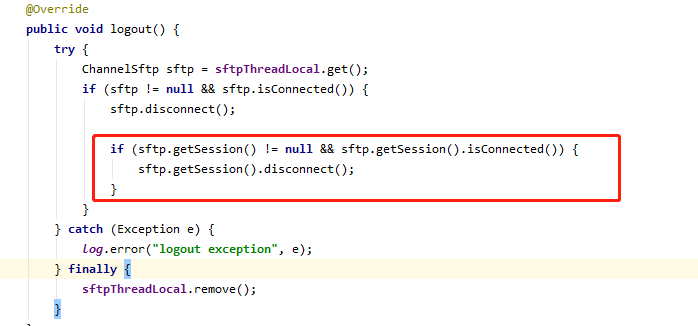
In the original code, after exiting the sftp task, only the channel is closed without closing the corresponding session (the red box content is missing)
According to the official example: http://www.jcraft.com/jsch/examples/Sftp.java.html Finally, the session should be closed so that there will be no residue.

What is channel and session? #
- Channel Mechanism --------- from:rfc4254
All terminal sessions, forwarded connections, etc., are channels.
Either side may open a channel. Multiple channels are multiplexed
into a single connection.
Channels are identified by numbers at each end. The number referring
to a channel may be different on each side. Requests to open a
channel contain the sender's channel number. Any other channel-
related messages contain the recipient's channel number for the
channel.
Channels are flow-controlled. No data may be sent to a channel until
a message is received to indicate that window space is available.
-----------------------------------------------------from:rfc4254
3.1. What are Channels? ----------------- from:Net::SSH Manual
The SSH protocol requires that requests for services on a remote machine be made over channels. A single SSH connection may contain multiple channels, all run simultaneously over that connection.
Each channel, in turn, represents the processing of a single service. When you invoke a process on the remote host with Net::SSH, a channel is opened for that invocation, and all input and output relevant to that process is sent through that channel. The connection itself simply manages the packets of all of the channels that it has open.
This means that, for instance, over a single SSH connection you could execute a process, download a file via SFTP, and forward any number of ports, all (seemingly) at the same time!
Naturally, they do not occur simultaneously, but rather work in a "time-share" fashion by sharing the bandwidth of the connection. Nevertheless, the fact that these channels exist make working with the SSH protocol a bit more challenging than simpler protocols (like FTP, HTTP, or Telnet).
According to the above information, we can see that:
- Log in to ssh once to generate an ssh session, that is, corresponding to a TCP link;
- One session / TCP link can carry multiple channel s;
- scp/ssh/port forwarding can be independent channel s;
- Flow control exists between different channel s to ensure independent safety;
The shape is as follows: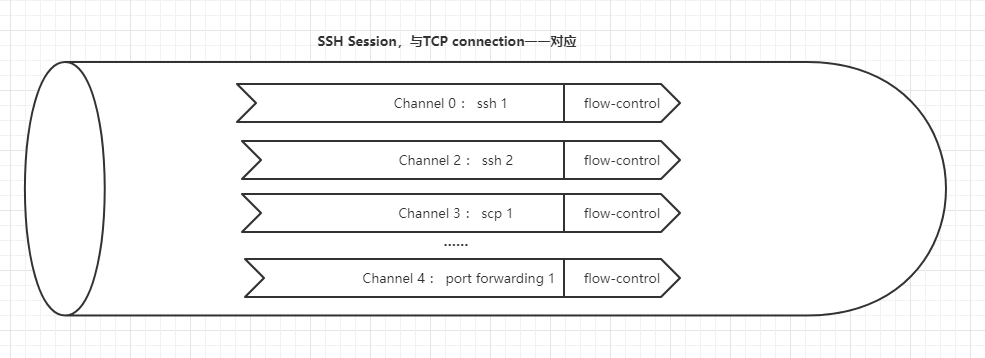
replay #
So far, the problem has been solved, so it needs to be analyzed again:
Have you configured the performance limit of sshd service in the early stage? #
It is understood that in order to limit the number of links on the product side in the early stage, there have been corresponding restricted configurations:
The two configurations are explained here:
MaxSessions 1000 limits the maximum number of sessions;
MaxStartups 1000:30:1200 links after the number of sessions reaches 1000 have a 30% chance of failure; All sessions fail when the number of sessions reaches 1200;
But why is it that hundreds of thousands of connections have not been released in actual production?
After some investigation, the reason is finally found: each login will create a new connection in the ssh service, and each sftp operation at the code level will generate a new session / session.
Therefore, the maxsession actually limits the number of new sessions that can be created for each connection.
Therefore, the configuration exists, but it does not play the expected effect.
Corresponding to various ssh tools, there is a copy session and a copy channel, corresponding to these two concepts.
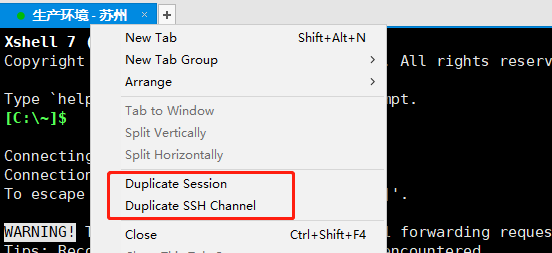
So how to configure it correctly? #
In fact, the limit on the number of login connections at the user level can be configured in ulimit:
/etc/security/limits. The conf file is actually the PAM in the Linux PAM (Pluggable Authentication Modules)_ limits. So, and only for a single session.
# /etc/security/limits.conf # #This file sets the resource limits for the users logged in via PAM. The document is approved PAM Set resource limits for logged in users. #It does not affect resource limits of the system services. #It does not affect the resource constraints of system services. #Also note that configuration files in /etc/security/limits.d directory, #which are read in alphabetical order, override the settings in this #file in case the domain is the same or more specific. Please note that/etc/security/limits.d The next alphabetical profile will be overwritten /etc/security/limits.conf Medium domain Same configuration #That means for example that setting a limit for wildcard domain here #can be overriden with a wildcard setting in a config file in the #subdirectory, but a user specific setting here can be overriden only #with a user specific setting in the subdirectory. This means, for example, using wildcards domain It will be overwritten by the same wildcard configuration in the subdirectory, but the specific configuration of a user It can only be overwritten by the user's configuration in the letter path. In fact, it is a user A If in/etc/security/limits.conf With configuration, when /etc/security/limits.d The configuration file under the subdirectory also has users A When configuring, then A Some configurations in will be overwritten. The final value is /etc/security/limits.d The configuration of the configuration file under. # #Each line describes a limit for a user in the form: #Each line describes a user configuration in the following format: #<domain> <type> <item> <value> #Where: #<domain> can be: # -A user name is a user name # -a group name, with @group syntax user group format is @ GROUP_NAME # -The wildcard *, configured as * by default for default entry, represents all users # - the wildcard %, can be also used with %group syntax, # for maxlogin limit # #<type> can have the two values: # - "soft" for enforcing the soft limits # - "hard" for enforcing hard limits have soft,hard and-,soft It refers to the effective setting value of the current system, and the soft limit can also be understood as a warning value. hard Table name is the maximum value that can be set in the system. soft The limits of cannot be compared hard Limit high, use-The table name is also set soft and hard Value of. #< item > can be one of the following: # -core - limits the core file size (KB) limits the size of the kernel file. # -data - max data size (KB) maximum data size # -Fsize - maximum file size (KB) maximum file size # -Memlock - Max locked in memory address space (KB) maximum locked memory address space # -nofile - max number of open file descriptors maximum number of open files (counted by file descriptor) # -rss - max resident set size (KB) maximum persistent set size # -stack - max stack size (KB) maximum stack size # -cpu - max CPU time (MIN) the maximum CPU time, in MIN # -nproc - max number of processes # -as - address space limit (KB) # -maxlogins - max number of logins for this user the maximum number of logins allowed for this user # -maxsyslogins - max number of logins on the system # -priority - the priority to run user process with # -locks - max number of file locks the user can hold # - sigpending - max number of pending signals # - msgqueue - max memory used by POSIX message queues (bytes) # -nice - max nice priority allowed to raise to values: [-20, 19] max nice priority allowed to raise to values # - rtprio - max realtime pr iority
Therefore, the solution is obvious, as long as it is configured in limit
testssh - maxlogins 1
It takes effect immediately.
etc: you can combine the above maxsession to control the number of connections / sessions of a user more accurately.
How to test the launch in the early stage? #
It is not carried out here, and the importance of the test work cannot be questioned; However, you can't test for testing. The last small function needs to run all the tests again;
I'm afraid the article is too small to discuss.
Why didn't you find out in advance? #
In the early stage, the monitoring alarm was accessed, but the access content was only limited to the scene where the openssh process disappeared and port 22 was lost;
Obviously, there is a lack of monitoring on the number of processes, TCP links and port consumption;
In a word, there is only 1 / 0 monitoring and no health/err monitoring;
The same is true for the above reasons. We can neither passively wait for a single supplement after fault discovery, nor bring the complexity of overall operation and maintenance due to too many detailed monitoring items;
Therefore, my personal understanding is to add the monitoring items of general indicators, that is, the monitoring indicators need to reflect the common problems at the system level or the health degree at the service level, and implement them into ssh services. The suggestions are as follows:
Process quantity monitoring (no), TCP link quantity monitoring (yes, percentage monitoring), port consumption quantity monitoring (yes, percentage monitoring), ssh service response time dial test (yes, simulate ssh login and scp operation monitoring)