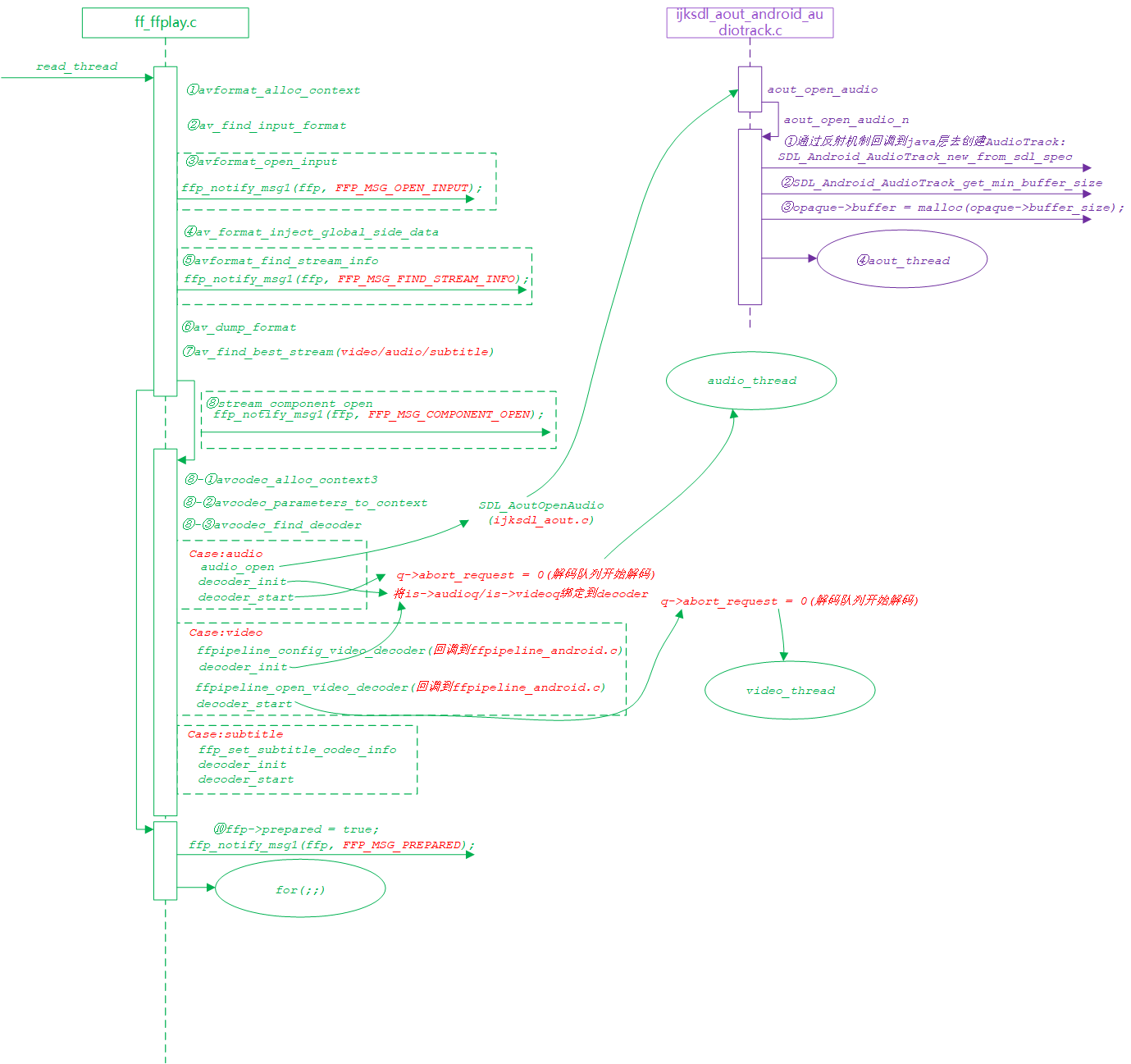
1, Introduction:
In the previous blog, we analyzed the whole jni process and message mechanism of ijkplayer in detail. The analysis of process mechanism helps us to have a general understanding of the whole architecture, which is convenient for the subsequent analysis of audio and video decoding and output rendering. The analysis of message mechanism helps us to understand how FFmpeg handles input and output buffer. Next, let's sort out read_thread this thread, and then analyze how the audio is decoded and output.
2, read_thread analysis:
read_ The thread function is very long. We only list the key codes:
static int read_thread(void *arg)
{
...
/* 1.Request formate context */
ic = avformat_alloc_context();
...
/* 2.Input stream type found */
if (ffp->iformat_name)
is->iformat = av_find_input_format(ffp->iformat_name);
...
/* 3.Open the input stream file and send a message */
err = avformat_open_input(&ic, is->filename, is->iformat, &ffp->format_opts);
if (err < 0) {
print_error(is->filename, err);
ret = -1;
goto fail;
}
ffp_notify_msg1(ffp, FFP_MSG_OPEN_INPUT);
...
/* 4.FFmpeg Native interface, I haven't used it much */
av_format_inject_global_side_data(ic);
...
/* 5.Find the bitstream information and send the message */
if (ffp->find_stream_info) {
AVDictionary **opts = setup_find_stream_info_opts(ic, ffp->codec_opts);
int orig_nb_streams = ic->nb_streams;
do {
...
err = avformat_find_stream_info(ic, opts);
} while(0);
ffp_notify_msg1(ffp, FFP_MSG_FIND_STREAM_INFO);
...
/* 6.FFmpeg Native interface */
av_dump_format(ic, 0, is->filename, 0);
...
/* 7.Confirm whether the original data of a/v/s stream is found */
if (!ffp->video_disable)
st_index[AVMEDIA_TYPE_VIDEO] =
av_find_best_stream(ic, AVMEDIA_TYPE_VIDEO,
st_index[AVMEDIA_TYPE_VIDEO], -1, NULL, 0);
if (!ffp->audio_disable)
st_index[AVMEDIA_TYPE_AUDIO] =
av_find_best_stream(ic, AVMEDIA_TYPE_AUDIO,
st_index[AVMEDIA_TYPE_AUDIO],
st_index[AVMEDIA_TYPE_VIDEO],
NULL, 0);
if (!ffp->video_disable && !ffp->subtitle_disable)
st_index[AVMEDIA_TYPE_SUBTITLE] =
av_find_best_stream(ic, AVMEDIA_TYPE_SUBTITLE,
st_index[AVMEDIA_TYPE_SUBTITLE],
(st_index[AVMEDIA_TYPE_AUDIO] >= 0 ?
st_index[AVMEDIA_TYPE_AUDIO] :
st_index[AVMEDIA_TYPE_VIDEO]),
NULL, 0);
...
/* 8.Open the a/v/d stream and configure the corresponding decoder (important) */
/* open the streams */
if (st_index[AVMEDIA_TYPE_AUDIO] >= 0) {
stream_component_open(ffp, st_index[AVMEDIA_TYPE_AUDIO]);
} else {
ffp->av_sync_type = AV_SYNC_VIDEO_MASTER;
is->av_sync_type = ffp->av_sync_type;
}
ret = -1;
if (st_index[AVMEDIA_TYPE_VIDEO] >= 0) {
ret = stream_component_open(ffp, st_index[AVMEDIA_TYPE_VIDEO]);
}
if (is->show_mode == SHOW_MODE_NONE)
is->show_mode = ret >= 0 ? SHOW_MODE_VIDEO : SHOW_MODE_RDFT;
if (st_index[AVMEDIA_TYPE_SUBTITLE] >= 0) {
stream_component_open(ffp, st_index[AVMEDIA_TYPE_SUBTITLE]);
}
ffp_notify_msg1(ffp, FFP_MSG_COMPONENT_OPEN);
...
/* 9.FFmpeg Inform the upper management after the preparation is completed */
ffp->prepared = true;
ffp_notify_msg1(ffp, FFP_MSG_PREPARED);
...
/* 10.for Loop and start reading the data to be decoded */
for (;;) {
/* Read a/v/s data */
...
}
...
}
In fact, the whole read_thread is basically copied from FFmpeg, but some auxiliary code is added, such as the message mechanism maintained by ijkplayer. Next, analyze the creation of audio decoding and output.
3, Audio decoding thread analysis:
FFmpeg combines the codes of decoding and output modules and interleaves them. We enter the stream_ component_ The open function is very long. Try to compress it as follows:
/* open a given stream. Return 0 if OK */
static int stream_component_open(FFPlayer *ffp, int stream_index)
{
VideoState *is = ffp->is;
AVFormatContext *ic = is->ic;
AVCodecContext *avctx;
AVCodec *codec = NULL;
const char *forced_codec_name = NULL;
AVDictionary *opts = NULL;
AVDictionaryEntry *t = NULL;
int sample_rate, nb_channels;
int64_t channel_layout;
int ret = 0;
int stream_lowres = ffp->lowres;
if (stream_index < 0 || stream_index >= ic->nb_streams)
return -1;
avctx = avcodec_alloc_context3(NULL);
if (!avctx)
return AVERROR(ENOMEM);
ret = avcodec_parameters_to_context(avctx, ic->streams[stream_index]->codecpar);
if (ret < 0)
goto fail;
av_codec_set_pkt_timebase(avctx, ic->streams[stream_index]->time_base);
/* Through codec_id find the corresponding decoder */
codec = avcodec_find_decoder(avctx->codec_id);
switch (avctx->codec_type) {
case AVMEDIA_TYPE_AUDIO : is->last_audio_stream = stream_index; forced_codec_name = ffp->audio_codec_name; break;
case AVMEDIA_TYPE_SUBTITLE: is->last_subtitle_stream = stream_index; forced_codec_name = ffp->subtitle_codec_name; break;
case AVMEDIA_TYPE_VIDEO : is->last_video_stream = stream_index; forced_codec_name = ffp->video_codec_name; break;
default: break;
}
/* Through codec_name found decoder */
if (forced_codec_name)
codec = avcodec_find_decoder_by_name(forced_codec_name);
if (!codec) {
if (forced_codec_name) av_log(NULL, AV_LOG_WARNING,
"No codec could be found with name '%s'\n", forced_codec_name);
else av_log(NULL, AV_LOG_WARNING,
"No codec could be found with id %d\n", avctx->codec_id);
ret = AVERROR(EINVAL);
goto fail;
}
avctx->codec_id = codec->id;
...
is->eof = 0;
ic->streams[stream_index]->discard = AVDISCARD_DEFAULT;
switch (avctx->codec_type) {
case AVMEDIA_TYPE_AUDIO:
...
sample_rate = avctx->sample_rate;
nb_channels = avctx->channels;
channel_layout = avctx->channel_layout;
...
/* prepare audio output */
/* 1.Prepare audio output */
if ((ret = audio_open(ffp, channel_layout, nb_channels, sample_rate, &is->audio_tgt)) < 0)
goto fail;
ffp_set_audio_codec_info(ffp, AVCODEC_MODULE_NAME, avcodec_get_name(avctx->codec_id));
is->audio_hw_buf_size = ret;
is->audio_src = is->audio_tgt;
is->audio_buf_size = 0;
is->audio_buf_index = 0;
/* init averaging filter */
is->audio_diff_avg_coef = exp(log(0.01) / AUDIO_DIFF_AVG_NB);
is->audio_diff_avg_count = 0;
/* since we do not have a precise anough audio FIFO fullness,
we correct audio sync only if larger than this threshold */
is->audio_diff_threshold = 2.0 * is->audio_hw_buf_size / is->audio_tgt.bytes_per_sec;
is->audio_stream = stream_index;
is->audio_st = ic->streams[stream_index];
/* 2.Initialize decoder */
decoder_init(&is->auddec, avctx, &is->audioq, is->continue_read_thread);
if ((is->ic->iformat->flags & (AVFMT_NOBINSEARCH | AVFMT_NOGENSEARCH | AVFMT_NO_BYTE_SEEK)) && !is->ic->iformat->read_seek) {
is->auddec.start_pts = is->audio_st->start_time;
is->auddec.start_pts_tb = is->audio_st->time_base;
}
/* 3.Turn on the decoder */
if ((ret = decoder_start(&is->auddec, audio_thread, ffp, "ff_audio_dec")) < 0)
goto out;
SDL_AoutPauseAudio(ffp->aout, 0);
break;
case AVMEDIA_TYPE_VIDEO:
...
case AVMEDIA_TYPE_SUBTITLE:
...
}
...
}
audio/video/subtitle share and call stream_component_open this function to determine the decoding and output related content.
Let's first look at note 2:
decoder_init(&is->auddec, avctx, &is->audioq, is->continue_read_thread);
static void decoder_init(Decoder *d, AVCodecContext *avctx, PacketQueue *queue, SDL_cond *empty_queue_cond) {
memset(d, 0, sizeof(Decoder));
d->avctx = avctx;
d->queue = queue;
d->empty_queue_cond = empty_queue_cond;
d->start_pts = AV_NOPTS_VALUE;
d->first_frame_decoded_time = SDL_GetTickHR();
d->first_frame_decoded = 0;
SDL_ProfilerReset(&d->decode_profiler, -1);
}
In read_ In the thread, we have determined what the decoder is, so here is to bind is - > audioq to the decoder.
Note 3:
if ((ret = decoder_start(&is->auddec, audio_thread, ffp, "ff_audio_dec")) < 0)
goto out;
Enter decoder_start:
static int decoder_start(Decoder *d, int (*fn)(void *), void *arg, const char *name)
{
/* packet packet queue start processing */
packet_queue_start(d->queue);
d->decoder_tid = SDL_CreateThreadEx(&d->_decoder_tid, fn, arg, name);
if (!d->decoder_tid) {
av_log(NULL, AV_LOG_ERROR, "SDL_CreateThread(): %s\n", SDL_GetError());
return AVERROR(ENOMEM);
}
return 0;
}
The most important function in this function is packet_queue_start:
static void packet_queue_start(PacketQueue *q)
{
SDL_LockMutex(q->mutex);
/* Start receiving data */
q->abort_request = 0;
packet_queue_put_private(q, &flush_pkt);
SDL_UnlockMutex(q->mutex);
}
abort_ We have seen the variable request many times in the introduction of message mechanism. Its value of 0 indicates that the queue starts to rotate and decoding is started.
Now that the queue starts decoding, we will immediately think of a problem. Where is the data to be decoded written to the queue? Remember read_ The last for loop in the thread? The answer is there. Let's analyze the for loop to see how to fill the input buffer:
for (;;) {
...
/* The previous is about seek. We don't focus on it */
/* if the queue are full, no need to read more */
/* If the decoding is too slow and the packet is full, sleep for 10ms */
if (ffp->infinite_buffer<1 && !is->seek_req &&
#ifdef FFP_MERGE
(is->audioq.size + is->videoq.size + is->subtitleq.size > MAX_QUEUE_SIZE
#else
(is->audioq.size + is->videoq.size + is->subtitleq.size > ffp->dcc.max_buffer_size
#endif
|| ( stream_has_enough_packets(is->audio_st, is->audio_stream, &is->audioq, MIN_FRAMES)
&& stream_has_enough_packets(is->video_st, is->video_stream, &is->videoq, MIN_FRAMES)
&& stream_has_enough_packets(is->subtitle_st, is->subtitle_stream, &is->subtitleq, MIN_FRAMES)))) {
if (!is->eof) {
ffp_toggle_buffering(ffp, 0);
}
/* wait 10 ms */
SDL_LockMutex(wait_mutex);
SDL_CondWaitTimeout(is->continue_read_thread, wait_mutex, 10);
SDL_UnlockMutex(wait_mutex);
continue;
}
...
pkt->flags = 0;
/* 1.Read packet data */
ret = av_read_frame(ic, pkt);
/* The following are some eof or error handling, which are not focused on */
...
/* Push the original data into the packet queue according to the id obtained in pkt */
/* check if packet is in play range specified by user, then queue, otherwise discard */
stream_start_time = ic->streams[pkt->stream_index]->start_time;
pkt_ts = pkt->pts == AV_NOPTS_VALUE ? pkt->dts : pkt->pts;
pkt_in_play_range = ffp->duration == AV_NOPTS_VALUE ||
(pkt_ts - (stream_start_time != AV_NOPTS_VALUE ? stream_start_time : 0)) *
av_q2d(ic->streams[pkt->stream_index]->time_base) -
(double)(ffp->start_time != AV_NOPTS_VALUE ? ffp->start_time : 0) / 1000000
<= ((double)ffp->duration / 1000000);
if (pkt->stream_index == is->audio_stream && pkt_in_play_range) {
packet_queue_put(&is->audioq, pkt);
} else if (pkt->stream_index == is->video_stream && pkt_in_play_range
&& !(is->video_st && (is->video_st->disposition & AV_DISPOSITION_ATTACHED_PIC))) {
packet_queue_put(&is->videoq, pkt);
} else if (pkt->stream_index == is->subtitle_stream && pkt_in_play_range) {
packet_queue_put(&is->subtitleq, pkt);
} else {
av_packet_unref(pkt);
}
}
We can see the filling of the original data, and the opening of the packet team can also be seen in the decoder_ In start, the following is to see if the decoder takes data from the packet and returns to the decoder_ The thread audio created by start_ thread:
static int audio_thread(void *arg)
{
do {
ffp_audio_statistic_l(ffp);
/* 1.Send the data in the packet to decode */
if ((got_frame = decoder_decode_frame(ffp, &is->auddec, frame, NULL)) < 0)
goto the_end;
if (got_frame) {
...
/* Processing after getting the data */
if (!(af = frame_queue_peek_writable(&is->sampq)))
goto the_end;
af->pts = (frame->pts == AV_NOPTS_VALUE) ? NAN : frame->pts * av_q2d(tb);
af->pos = frame->pkt_pos;
af->serial = is->auddec.pkt_serial;
af->duration = av_q2d((AVRational){frame->nb_samples, frame->sample_rate});
av_frame_move_ref(af->frame, frame);
frame_queue_push(&is->sampq)
}
} while (ret >= 0 || ret == AVERROR(EAGAIN) || ret == AVERROR_EOF);
}
The whole audio decoding thread is composed of a do... while. Its operation principle is to constantly call the decoding interface of FFmpeg and send the input buffer to FFmpeg. If a frame is obtained, push the pcm data after decoding into the frame queue.
First look at note 1:
static int decoder_decode_frame(FFPlayer *ffp, Decoder *d, AVFrame *frame, AVSubtitle *sub) {
int ret = AVERROR(EAGAIN);
for (;;) {
AVPacket pkt;
if (d->queue->serial == d->pkt_serial) {
do {
/* If the queue has not started decoding, an error is returned */
if (d->queue->abort_request)
return -1;
switch (d->avctx->codec_type) {
/* video processing */
case AVMEDIA_TYPE_VIDEO:
....
break;
/* Audio processing */
case AVMEDIA_TYPE_AUDIO:
/* Get decoded data */
ret = avcodec_receive_frame(d->avctx, frame);
if (ret >= 0) {
AVRational tb = (AVRational){1, frame->sample_rate};
if (frame->pts != AV_NOPTS_VALUE)
frame->pts = av_rescale_q(frame->pts, av_codec_get_pkt_timebase(d->avctx), tb);
else if (d->next_pts != AV_NOPTS_VALUE)
frame->pts = av_rescale_q(d->next_pts, d->next_pts_tb, tb);
if (frame->pts != AV_NOPTS_VALUE) {
d->next_pts = frame->pts + frame->nb_samples;
d->next_pts_tb = tb;
}
}
break;
default:
break;
}
if (ret == AVERROR_EOF) {
d->finished = d->pkt_serial;
avcodec_flush_buffers(d->avctx);
return 0;
}
if (ret >= 0)
return 1;
} while (ret != AVERROR(EAGAIN));
/* By do While to read data */
do {
/* If the data is insufficient, wait */
if (d->queue->nb_packets == 0)
SDL_CondSignal(d->empty_queue_cond);
if (d->packet_pending) {
av_packet_move_ref(&pkt, &d->pkt);
d->packet_pending = 0;
} else {
/* Otherwise, a packet of data is read from the packet sequence */
if (packet_queue_get_or_buffering(ffp, d->queue, &pkt, &d->pkt_serial, &d->finished) < 0)
return -1;
}
} while (d->queue->serial != d->pkt_serial);
}
if (pkt.data == flush_pkt.data) {
...
} else {
/* If the read data is subtitle processing */
if (d->avctx->codec_type == AVMEDIA_TYPE_SUBTITLE) {
...
} else {
/* Send the read data to the decoder */
if (avcodec_send_packet(d->avctx, &pkt) == AVERROR(EAGAIN)) {
av_log(d->avctx, AV_LOG_ERROR, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");
d->packet_pending = 1;
av_packet_move_ref(&d->pkt, &pkt);
}
}
/* Release packet */
av_packet_unref(&pkt);
}
}
}
In fact, the logic of the function is also well understood. Before entering this function, the decoder has been called respectively_ Init and decoder_start binds the queue where the packet is located to the decoder and starts the operation of the queue (Q - > abort_request = 0). The key point has been noted in the code. The audio processing of the function is to take a packet of data from the queue and send it to the external decoder for decoding.
Next, let's see how the data receives frames, which is in the avcodec of the function_ receive_ frame:
int attribute_align_arg avcodec_receive_frame(AVCodecContext *avctx, AVFrame *frame)
{
int ret;
av_frame_unref(frame);
if (!avcodec_is_open(avctx) || !av_codec_is_decoder(avctx->codec))
return AVERROR(EINVAL);
if (avctx->codec->receive_frame) {
if (avctx->internal->draining && !(avctx->codec->capabilities & AV_CODEC_CAP_DELAY))
return AVERROR_EOF;
/* Call the receive of the decoder_ The frame function gets the frame */
ret = avctx->codec->receive_frame(avctx, frame);
if (ret >= 0) {
if (av_frame_get_best_effort_timestamp(frame) == AV_NOPTS_VALUE) {
av_frame_set_best_effort_timestamp(frame,
guess_correct_pts(avctx, frame->pts, frame->pkt_dts));
}
}
return ret;
}
...
if (!avctx->internal->buffer_frame->buf[0])
return avctx->internal->draining ? AVERROR_EOF : AVERROR(EAGAIN);
av_frame_move_ref(frame, avctx->internal->buffer_frame);
return 0;
}
Summarize the coder_ decode_ Frame performs two operations: one is to take the source data from the packet sequence and send it to the decoder; the other is to get the decoded pcm data from the decoder. Now that you have obtained the pcm data, you need to see how the code sends the pcm data to aout for output.
4, aout output analysis:
Let's go back to stream_ component_ Note 1:
if ((ret = audio_open(ffp, channel_layout, nb_channels, sample_rate, &is->audio_tgt)) < 0)
goto fail;
Enter audio_open:
static int audio_open(FFPlayer *opaque, int64_t wanted_channel_layout, int wanted_nb_channels, int wanted_sample_rate, struct AudioParams *audio_hw_params)
{
FFPlayer *ffp = opaque;
VideoState *is = ffp->is;
/* Notice this structure */
SDL_AudioSpec wanted_spec, spec;
const char *env;
static const int next_nb_channels[] = {0, 0, 1, 6, 2, 6, 4, 6};
#ifdef FFP_MERGE
static const int next_sample_rates[] = {0, 44100, 48000, 96000, 192000};
#endif
static const int next_sample_rates[] = {0, 44100, 48000};
int next_sample_rate_idx = FF_ARRAY_ELEMS(next_sample_rates) - 1;
env = SDL_getenv("SDL_AUDIO_CHANNELS");
if (env) {
wanted_nb_channels = atoi(env);
wanted_channel_layout = av_get_default_channel_layout(wanted_nb_channels);
}
if (!wanted_channel_layout || wanted_nb_channels != av_get_channel_layout_nb_channels(wanted_channel_layout)) {
wanted_channel_layout = av_get_default_channel_layout(wanted_nb_channels);
wanted_channel_layout &= ~AV_CH_LAYOUT_STEREO_DOWNMIX;
}
wanted_nb_channels = av_get_channel_layout_nb_channels(wanted_channel_layout);
wanted_spec.channels = wanted_nb_channels;
wanted_spec.freq = wanted_sample_rate;
if (wanted_spec.freq <= 0 || wanted_spec.channels <= 0) {
av_log(NULL, AV_LOG_ERROR, "Invalid sample rate or channel count!\n");
return -1;
}
while (next_sample_rate_idx && next_sample_rates[next_sample_rate_idx] >= wanted_spec.freq)
next_sample_rate_idx--;
wanted_spec.format = AUDIO_S16SYS;
wanted_spec.silence = 0;
wanted_spec.samples = FFMAX(SDL_AUDIO_MIN_BUFFER_SIZE, 2 << av_log2(wanted_spec.freq / SDL_AoutGetAudioPerSecondCallBacks(ffp->aout)));
/* 1.Determine aout callback function */
wanted_spec.callback = sdl_audio_callback;
/* 2.Determine the source of pcm data */
wanted_spec.userdata = opaque;
/* 3.Keep writing data from FFmpeg to aout through the while loop */
while (SDL_AoutOpenAudio(ffp->aout, &wanted_spec, &spec) < 0) {
/* avoid infinity loop on exit. --by bbcallen */
if (is->abort_request)
return -1;
av_log(NULL, AV_LOG_WARNING, "SDL_OpenAudio (%d channels, %d Hz): %s\n",
wanted_spec.channels, wanted_spec.freq, SDL_GetError());
wanted_spec.channels = next_nb_channels[FFMIN(7, wanted_spec.channels)];
if (!wanted_spec.channels) {
wanted_spec.freq = next_sample_rates[next_sample_rate_idx--];
wanted_spec.channels = wanted_nb_channels;
if (!wanted_spec.freq) {
av_log(NULL, AV_LOG_ERROR,
"No more combinations to try, audio open failed\n");
return -1;
}
}
wanted_channel_layout = av_get_default_channel_layout(wanted_spec.channels);
}
if (spec.format != AUDIO_S16SYS) {
av_log(NULL, AV_LOG_ERROR,
"SDL advised audio format %d is not supported!\n", spec.format);
return -1;
}
if (spec.channels != wanted_spec.channels) {
wanted_channel_layout = av_get_default_channel_layout(spec.channels);
if (!wanted_channel_layout) {
av_log(NULL, AV_LOG_ERROR,
"SDL advised channel count %d is not supported!\n", spec.channels);
return -1;
}
}
audio_hw_params->fmt = AV_SAMPLE_FMT_S16;
audio_hw_params->freq = spec.freq;
audio_hw_params->channel_layout = wanted_channel_layout;
audio_hw_params->channels = spec.channels;
audio_hw_params->frame_size = av_samples_get_buffer_size(NULL, audio_hw_params->channels, 1, audio_hw_params->fmt, 1);
audio_hw_params->bytes_per_sec = av_samples_get_buffer_size(NULL, audio_hw_params->channels, audio_hw_params->freq, audio_hw_params->fmt, 1);
if (audio_hw_params->bytes_per_sec <= 0 || audio_hw_params->frame_size <= 0) {
av_log(NULL, AV_LOG_ERROR, "av_samples_get_buffer_size failed\n");
return -1;
}
/* When latency is set, the usage rate of Bluetooth scene is high */
SDL_AoutSetDefaultLatencySeconds(ffp->aout, ((double)(2 * spec.size)) / audio_hw_params->bytes_per_sec);
return spec.size;
}
The function looks a little complicated, but it's easy to understand. First, we need to pay attention to the local variable SDL when the function comes in_ Audiospec, take a look at the definition of this structure:
typedef struct SDL_AudioSpec
{
int freq; /**< DSP frequency -- samples per second */
SDL_AudioFormat format; /**< Audio data format */
Uint8 channels; /**< Number of channels: 1 mono, 2 stereo */
Uint8 silence; /**< Audio buffer silence value (calculated) */
Uint16 samples; /**< Audio buffer size in samples (power of 2) */
Uint16 padding; /**< NOT USED. Necessary for some compile environments */
Uint32 size; /**< Audio buffer size in bytes (calculated) */
SDL_AudioCallback callback;
void *userdata;
} SDL_AudioSpec;
The two most important variables are not annotated. Callback is a callback function called by aout. Its function is to copy the data decoded by FFmpeg to aout. As we analyzed in the previous blog, ijkplayer will use Android native AudioTrack or openSLES for output. userdata is pcm data decoded by FFmpeg. Generally speaking, its mechanism is to write the data in userdata into the output buffer of aout in callback. You can see that the sdl_audio_callback is assigned to wanted_spec.callback, which is located at ff_ffplay.c. Opaque is assigned to userdata because the structure type of opaque is FFPlayer, which contains input and output buffers.
Let's take a look at the SDL of the while loop_ What does aoutopenaudio do:
int SDL_AoutOpenAudio(SDL_Aout *aout, const SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
if (aout && desired && aout->open_audio)
return aout->open_audio(aout, desired, obtained);
return -1;
}
As you can see, this is to call aout's open_audio function pointer. We need to know what the pointer points to? How to confirm? Let's first clarify where aout is created. Look at the previous ijkplayer creation process, and we can find_ prepareAsync phase, ijkplayer C will be transferred to FF_ ffplay. FFP in C_ prepare_ async_ l. Go back here to create aout:
if (!ffp->aout) {
ffp->aout = ffpipeline_open_audio_output(ffp->pipeline, ffp);
if (!ffp->aout)
return -1;
}
Track ffpipeline_open_audio_output:
SDL_Aout *ffpipeline_open_audio_output(IJKFF_Pipeline *pipeline, FFPlayer *ffp)
{
return pipeline->func_open_audio_output(pipeline, ffp);
}
Here is another function pointer. You also need to confirm when the pipeline was created:
IJKFF_Pipeline *ffpipeline_create_from_android(FFPlayer *ffp)
{
...
pipeline->func_open_audio_output = func_open_audio_output;
...
}
Finally found the source:
static SDL_Aout *func_open_audio_output(IJKFF_Pipeline *pipeline, FFPlayer *ffp)
{
SDL_Aout *aout = NULL;
if (ffp->opensles) {
aout = SDL_AoutAndroid_CreateForOpenSLES();
} else {
aout = SDL_AoutAndroid_CreateForAudioTrack();
}
if (aout)
SDL_AoutSetStereoVolume(aout, pipeline->opaque->left_volume, pipeline->opaque->right_volume);
return aout;
}
In other words, AudioTrack or OpenSLES is actually set by the upper apk through opt. In the code, I use AudioTrack, naturally aout - > open_ Audio should also go through the corresponding function aout_open_audio:
static int aout_open_audio(SDL_Aout *aout, const SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
// SDL_Aout_Opaque *opaque = aout->opaque;
JNIEnv *env = NULL;
if (JNI_OK != SDL_JNI_SetupThreadEnv(&env)) {
ALOGE("aout_open_audio: AttachCurrentThread: failed");
return -1;
}
return aout_open_audio_n(env, aout, desired, obtained);
}
Continue tracking aout_open_audio_n:
static int aout_open_audio_n(JNIEnv *env, SDL_Aout *aout, const SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
assert(desired);
SDL_Aout_Opaque *opaque = aout->opaque;
opaque->spec = *desired;
/* 1.Create audiotrack by reflecting jni layer to java layer */
opaque->atrack = SDL_Android_AudioTrack_new_from_sdl_spec(env, desired);
if (!opaque->atrack) {
ALOGE("aout_open_audio_n: failed to new AudioTrcak()");
return -1;
}
/* 2.Get minimum buffersize */
opaque->buffer_size = SDL_Android_AudioTrack_get_min_buffer_size(opaque->atrack);
if (opaque->buffer_size <= 0) {
ALOGE("aout_open_audio_n: failed to getMinBufferSize()");
SDL_Android_AudioTrack_free(env, opaque->atrack);
opaque->atrack = NULL;
return -1;
}
/* 3.Apply for native layer buffer */
opaque->buffer = malloc(opaque->buffer_size);
if (!opaque->buffer) {
ALOGE("aout_open_audio_n: failed to allocate buffer");
SDL_Android_AudioTrack_free(env, opaque->atrack);
opaque->atrack = NULL;
return -1;
}
if (obtained) {
SDL_Android_AudioTrack_get_target_spec(opaque->atrack, obtained);
SDLTRACE("audio target format fmt:0x%x, channel:0x%x", (int)obtained->format, (int)obtained->channels);
}
opaque->audio_session_id = SDL_Android_AudioTrack_getAudioSessionId(env, opaque->atrack);
ALOGI("audio_session_id = %d\n", opaque->audio_session_id);
opaque->pause_on = 1;
opaque->abort_request = 0;
/* 4.Create aout thread */
opaque->audio_tid = SDL_CreateThreadEx(&opaque->_audio_tid, aout_thread, aout, "ff_aout_android");
if (!opaque->audio_tid) {
ALOGE("aout_open_audio_n: failed to create audio thread");
SDL_Android_AudioTrack_free(env, opaque->atrack);
opaque->atrack = NULL;
return -1;
}
return 0;
}
Note 1: the jni layer mainly calls back the java method to create audiotrack. After obtaining the minimum buffer size of audiotrack, it will also apply for a buffer of the same size in the jni layer to copy the pcm data decoded from FFmpeg to the buffer of the native layer, and then write the data in the buffer to audiotrack. How to write it specifically depends on aout_thread, follow up:
static int aout_thread(void *arg)
{
SDL_Aout *aout = arg;
// SDL_Aout_Opaque *opaque = aout->opaque;
JNIEnv *env = NULL;
if (JNI_OK != SDL_JNI_SetupThreadEnv(&env)) {
ALOGE("aout_thread: SDL_AndroidJni_SetupEnv: failed");
return -1;
}
return aout_thread_n(env, aout);
}
static int aout_thread_n(JNIEnv *env, SDL_Aout *aout)
{
SDL_Aout_Opaque *opaque = aout->opaque;
SDL_Android_AudioTrack *atrack = opaque->atrack;
SDL_AudioCallback audio_cblk = opaque->spec.callback;
void *userdata = opaque->spec.userdata;
uint8_t *buffer = opaque->buffer;
/* Note that the amount of data per copy is 256 */
int copy_size = 256;
assert(atrack);
assert(buffer);
SDL_SetThreadPriority(SDL_THREAD_PRIORITY_HIGH);
if (!opaque->abort_request && !opaque->pause_on)
SDL_Android_AudioTrack_play(env, atrack);
while (!opaque->abort_request) {
SDL_LockMutex(opaque->wakeup_mutex);
if (!opaque->abort_request && opaque->pause_on) {
SDL_Android_AudioTrack_pause(env, atrack);
while (!opaque->abort_request && opaque->pause_on) {
SDL_CondWaitTimeout(opaque->wakeup_cond, opaque->wakeup_mutex, 1000);
}
if (!opaque->abort_request && !opaque->pause_on) {
if (opaque->need_flush) {
opaque->need_flush = 0;
SDL_Android_AudioTrack_flush(env, atrack);
}
SDL_Android_AudioTrack_play(env, atrack);
}
}
if (opaque->need_flush) {
opaque->need_flush = 0;
SDL_Android_AudioTrack_flush(env, atrack);
}
if (opaque->need_set_volume) {
opaque->need_set_volume = 0;
SDL_Android_AudioTrack_set_volume(env, atrack, opaque->left_volume, opaque->right_volume);
}
if (opaque->speed_changed) {
opaque->speed_changed = 0;
SDL_Android_AudioTrack_setSpeed(env, atrack, opaque->speed);
}
SDL_UnlockMutex(opaque->wakeup_mutex);
/* 1.Call the callback function to write data to the buffer of the native layer first */
audio_cblk(userdata, buffer, copy_size);
if (opaque->need_flush) {
SDL_Android_AudioTrack_flush(env, atrack);
opaque->need_flush = false;
}
if (opaque->need_flush) {
opaque->need_flush = 0;
SDL_Android_AudioTrack_flush(env, atrack);
} else {
/* 2.Write the buffer data of the native layer into audiotrack */
int written = SDL_Android_AudioTrack_write(env, atrack, buffer, copy_size);
if (written != copy_size) {
ALOGW("AudioTrack: not all data copied %d/%d", (int)written, (int)copy_size);
}
}
// TODO: 1 if callback return -1 or 0
}
SDL_Android_AudioTrack_free(env, atrack);
return 0;
}
You can see that each time you write data, the amount of copy each time is 256 bytes. First look at audio_cblk, which we have analyzed before, is FF_ play. SDL in C_ audio_ callback:
/* prepare a new audio buffer */
static void sdl_audio_callback(void *opaque, Uint8 *stream, int len)
{
FFPlayer *ffp = opaque;
VideoState *is = ffp->is;
int audio_size, len1;
if (!ffp || !is) {
memset(stream, 0, len);
return;
}
ffp->audio_callback_time = av_gettime_relative();
...
while (len > 0) {
/* audio_buf_index Equivalent to write pointer position */
if (is->audio_buf_index >= is->audio_buf_size) {
/* Get the frame to be played from the FrameQueue and return the value audio_size is the size of the current frame */
audio_size = audio_decode_frame(ffp);
if (audio_size < 0) {
/* if error, just output silence */
is->audio_buf = NULL;
is->audio_buf_size = SDL_AUDIO_MIN_BUFFER_SIZE / is->audio_tgt.frame_size * is->audio_tgt.frame_size;
} else {
if (is->show_mode != SHOW_MODE_VIDEO)
update_sample_display(is, (int16_t *)is->audio_buf, audio_size);
is->audio_buf_size = audio_size;
}
is->audio_buf_index = 0;
}
if (is->auddec.pkt_serial != is->audioq.serial) {
is->audio_buf_index = is->audio_buf_size;
memset(stream, 0, len);
// stream += len;
// len = 0;
SDL_AoutFlushAudio(ffp->aout);
break;
}
/* Calculate and update the data that can be written in this frame */
len1 = is->audio_buf_size - is->audio_buf_index;
if (len1 > len)
len1 = len;
if (!is->muted && is->audio_buf && is->audio_volume == SDL_MIX_MAXVOLUME)
/* copy data */
memcpy(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1);
else {
memset(stream, 0, len1);
if (!is->muted && is->audio_buf)
SDL_MixAudio(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1, is->audio_volume);
}
/* Update related values */
len -= len1;
stream += len1;
is->audio_buf_index += len1;
}
is->audio_write_buf_size = is->audio_buf_size - is->audio_buf_index;
/* Let's assume the audio driver that is used by SDL has two periods. */
if (!isnan(is->audio_clock)) {
set_clock_at(&is->audclk, is->audio_clock - (double)(is->audio_write_buf_size) / is->audio_tgt.bytes_per_sec - SDL_AoutGetLatencySeconds(ffp->aout), is->audio_clock_serial, ffp->audio_callback_time / 1000000.0);
sync_clock_to_slave(&is->extclk, &is->audclk);
}
if (!ffp->first_audio_frame_rendered) {
ffp->first_audio_frame_rendered = 1;
ffp_notify_msg1(ffp, FFP_MSG_AUDIO_RENDERING_START);
}
if (is->latest_audio_seek_load_serial == is->audio_clock_serial) {
int latest_audio_seek_load_serial = __atomic_exchange_n(&(is->latest_audio_seek_load_serial), -1, memory_order_seq_cst);
if (latest_audio_seek_load_serial == is->audio_clock_serial) {
if (ffp->av_sync_type == AV_SYNC_AUDIO_MASTER) {
ffp_notify_msg2(ffp, FFP_MSG_AUDIO_SEEK_RENDERING_START, 1);
} else {
ffp_notify_msg2(ffp, FFP_MSG_AUDIO_SEEK_RENDERING_START, 0);
}
}
}
if (ffp->render_wait_start && !ffp->start_on_prepared && is->pause_req) {
while (is->pause_req && !is->abort_request) {
SDL_Delay(20);
}
}
}
The whole function is easy to understand. It is to pick up the data from FFmpeg and write it into the buffer opened by the native layer. Simply analyze the audio_ decode_ How does frame collect data:
static int audio_decode_frame(FFPlayer *ffp)
...
/* 1.dequeue one frame of data from FrameQueue */
if (!(af = frame_queue_peek_readable(&is->sampq)))
return -1;
frame_queue_next(&is->sampq);
} while (af->serial != is->audioq.serial);
/* Calculate the size of this frame of data */
data_size = av_samples_get_buffer_size(NULL, af->frame->channels,
af->frame->nb_samples,
af->frame->format, 1);
...
/* Need resampling */
/* Need resampling */
if (is->swr_ctx) {
...
}else {
/* Assign variables without resampling */
is->audio_buf = af->frame->data[0];
resampled_data_size = data_size;
}
...
/* The return value is the data size of the current frame */
return resampled_data_size;
}
The whole aout process is analyzed.
5, Summary:
There are a lot of contents to be analyzed. It is suggested to deepen the understanding by combining the logic diagram: