RLP coding
Basic principles
The sole purpose of RLP (Recursive Length Prefix) coding is to solve the problem of structure coding. The two structures of RLP coding design are: String and List. They are defined as follows:
String Refers to a string of bytes, corresponding to Go In language string/[]byte/uint/[]uint/[N]uint etc.
List Specified by many String and List Make up a list, such as struct/[]interface{} etc.
For example, "\ x11 \x22 \x33" and "abc" are String types, while ["ab", ["abc", "a"], "\ x11"] are List types.
For String type, the RLP encoding rules are as follows:
- If the length of String is 1 1 1, and its value is [ 0 x 00 , 0 x 7 f ] [0x00,0x7f] Between [0x00,0x7f], the RLP code is the character itself, that is, the prefix is empty. The value of the prefix is [ 0 x 00 , 0 x 7 f ] [0x00,0x7f] Between [0x00,0x7f].
- Otherwise, if the length of String is less than 56 56 56, then its RLP code is the character itself on the prefix splicing, and its prefix is 0 x 80 0x80 0x80 plus String length. The value of the prefix is [ 0 x 80 , 0 x b 7 ] [0x80,0xb7] Between [0x80,0xb7].
- Otherwise, if the length of String is less than 2 64 2^{64} 264, the RLP code is the character length spliced with the prefix, and then the character itself spliced with the prefix 0 x b 7 0xb7 0xb7 plus the byte length of binary representation of String length. For example, the length of a String is 1024 1024 1024, the binary representation of its length is b 00000100 00000000 b00000100\quad00000000 b0000010000000000, the corresponding hexadecimal representation is 0 x 0400 0x0400 0x0400, byte length 2 2 2. The value of the prefix is [ 0 x b 8 , 0 x b f ] [0xb8,0xbf] Between [0xb8,0xbf].
- Otherwise, the length of the String is greater than or equal to 2 64 2^{64} 264, the RLP code is ∅ \varnothing ∅.
As you can see from the coding rules, the value of the prefix is related to the length of the String. In addition, it should be noted that when the String length is 0 and the String length is 1, but its value is not [ 0 x 00 , 0 x 7 f ] [0x00,0x7f] The situation in [0x00,0x7f] is included in rule 2.
For List type, RLP coding rules are as follows:
- If the RLP codes of items in the List are spliced together, the length is less than 56 56 56, then its RLP code is the RLP code of each item on the prefix splicing, and its prefix is 0 x c 0 0xc0 0xc0 plus the total length of RLP code splicing of each item. The value of the prefix is [ 0 x c 0 , 0 x f 7 ] [0xc0,0xf7] Between [0xc0,0xf7].
- Otherwise, if the splicing length of RLP codes of items in the List is less than 2 64 2^{64} 264, then its RLP code is the total length of each code spliced on the prefix splicing, and then the RLP code spliced on each item, and its prefix is 0 x f 7 0xf7 0xf7 plus the byte length of the binary representation of the total length. The value of the prefix is [ 0 x f 8 , 0 x f f ] [0xf8,0xff] Between [0xf8,0xff].
Because the list is arbitrarily nested, the encoding of the list is recursive.
The following figure shows the process of RLP coding. The black field represents the data to be encoded, and the red field represents the encoding result. The leaf node represents a String, while the non leaf node represents a List, and the items in the List represented by the non leaf node are composed of their children. Because the encoded prefix field reflects the data type and length information, we can decode the encoded data through the prefix field.
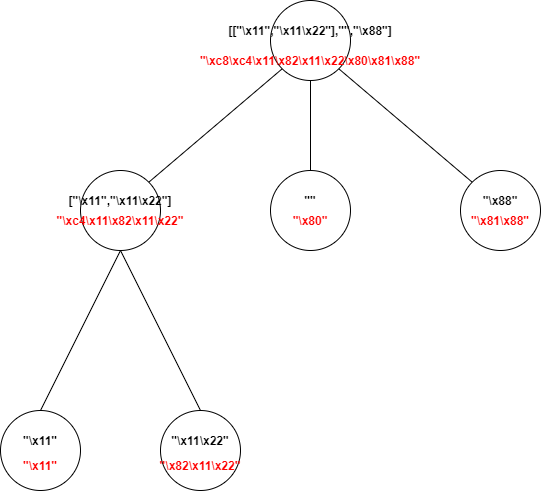
In addition, for empty strings and empty lists, their encodings are "\ x80" and "\ xc0" respectively.
Concrete implementation
The implementation of RLP coding by geth is located in the go Ethereum / RLP folder, and the main code files include typecache go, encode. go, decode. go. Because there are various built-in data types and user-defined types in go language, the specific implementation of encoder and decoder is different for different data types.
The overall framework of RLP coding module is as follows:
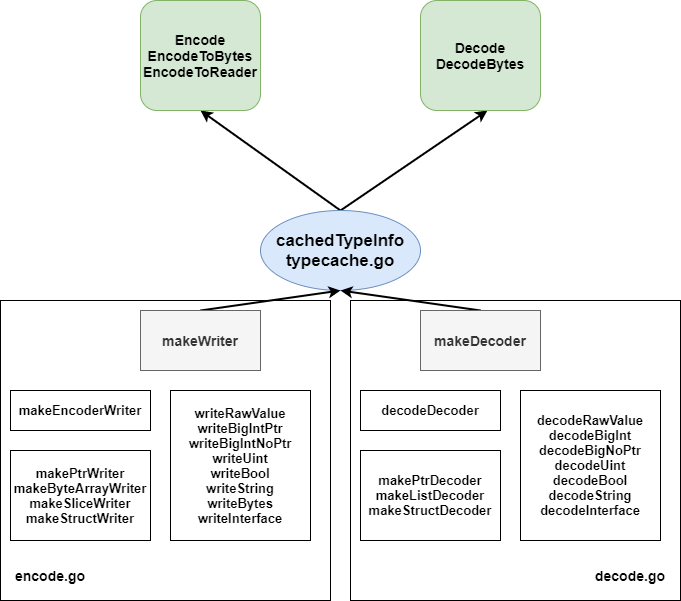
The export functions of this module are EncodeToBytes/Encode/EncodeToReader and Decode/DecodeBytes respectively. According to different requirements, the outside world can call different functions in this package. According to the encoded or decoded data type, the export function uses typeCache The cachedTypeInfo function in go obtains the corresponding encoder or decoder. typeCache. The type of coder or codec will be temporarily stored in the corresponding type of coder. When using cachedTypeInfo to obtain an encoder or decoder, if the encoder or decoder of the corresponding type has not been temporarily stored, encode. Will be called makeWriter and decode in go The makeDecoder in go generates the corresponding encoder and decoder and temporarily stores them. The next time you need this encoder or decoder, you can get it directly from typeCache.
typecache.go
typeCache. In go, the generated encoders and decoders are saved through typeCache variables (different encoders and decoders are required for different go language data types), and typeCacheMutex is used to realize mutually exclusive access to typeCache. They are defined as follows:
var (
typeCacheMutex sync.RWMutex
typeCache = make(map[typekey]*typeinfo)
)
type typekey struct {
reflect.Type
tags
}
type typeinfo struct {
decoder decoder
decoderErr error // error from makeDecoder
writer writer
writerErr error // error from makeWriter
}
// tags represents struct tags.
type tags struct {
// rlp:"nil" controls whether empty input results in a nil pointer.
nilOK bool
// This controls whether nil pointers are encoded/decoded as empty strings
// or empty lists.
nilKind Kind
// rlp:"tail" controls whether this field swallows additional list
// elements. It can only be set for the last field, which must be
// of slice type.
tail bool
// rlp:"-" ignores fields.
ignored bool
}
type decoder func(*Stream, reflect.Value) error
type writer func(reflect.Value, *encbuf) error
The corresponding type information is saved in typekey, and the corresponding encoder and decoder (function) are saved in typeinfo. If an error occurs when creating the encoder and decoder, it will record the corresponding error information. In addition, for the fields in the structure, their type information also includes the corresponding tags.
For example, for the following structures:
type S struct{
X uint
Y uint `rlp:"nil"`
}
The field Y is ignored when encoding structure S.
typecache. The cachedTypeInfo function is provided in go to obtain the encoder and decoder of the corresponding type. If it does not exist, it is generated through the generate function.
func cachedTypeInfo(typ reflect.Type, tags tags) *typeinfo {
typeCacheMutex.Lock()
defer typeCacheMutex.Unlock()
key := typekey{typ, tags}
info := typeCache[key]
if info != nil {
return info
}
info = new(typeinfo)
typeCache[key] = info
info.generate(typ, tags)
return info
}
In addition, typeCache Go also provides the structFields function to parse each field in the structure (export field, initial capital), create the corresponding encoder and decoder according to the type of the corresponding field and the tags information, and store them in typeCache.
encode.go
encode.go provides three export functions: Encode/EncodeToBytes/EncodeToReader to realize different output forms of RLP coding. These functions will call the encode function for encoding, and the encode function will obtain the corresponding encoder from the typeCache for encoding operation.
func (w *encbuf) encode(val interface{}) error {
rval := reflect.ValueOf(val)
writer, err := cachedWriter(rval.Type())
if err != nil {
return err
}
return writer(rval, w)
}
With the help of encbuf structure, its main function is to temporarily store the intermediate results of coding, and through it, the final coding results can be obtained. It is defined as follows:
type encbuf struct {
str []byte // string data, contains everything except list headers
lheads []listhead // all list headers
lhsize int // sum of sizes of all encoded list headers
sizebuf [9]byte // auxiliary buffer for uint encoding
bufvalue reflect.Value // used in writeByteArrayCopy
}
type listhead struct {
offset int // index of this header in string data
size int // total size of encoded data (including list headers)
}
Note that the result of the final RLP encoding is not stored in str, because it does not contain the header of List type, while the header of List type is stored in lheads. The final encoding result can be exported by these two items (implemented by toBytes and toWriter functions). Listead stores the offset of the corresponding List type header in the code and the size of the entire List type (the meaning of including the header in the comment is that if it is a nested List, the size of the size includes its sub List plus the size of its header, but does not include the size of its own header).
encode.go implements the implementation of various types of encoders in go language. The generate function in the cachedTypeInfo function will call the makeWriter to generate the corresponding encoder.
// makeWriter creates a writer function for the given type.
func makeWriter(typ reflect.Type, ts tags) (writer, error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return writeRawValue, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return writeBigIntPtr, nil
case typ.AssignableTo(bigInt):
return writeBigIntNoPtr, nil
case kind == reflect.Ptr:
return makePtrWriter(typ, ts)
case reflect.PtrTo(typ).Implements(encoderInterface):
return makeEncoderWriter(typ), nil
case isUint(kind):
return writeUint, nil
case kind == reflect.Bool:
return writeBool, nil
case kind == reflect.String:
return writeString, nil
case kind == reflect.Slice && isByte(typ.Elem()):
return writeBytes, nil
case kind == reflect.Array && isByte(typ.Elem()):
return makeByteArrayWriter(typ), nil
case kind == reflect.Slice || kind == reflect.Array:
return makeSliceWriter(typ, ts)
case kind == reflect.Struct:
return makeStructWriter(typ)
case kind == reflect.Interface:
return writeInterface, nil
default:
return nil, fmt.Errorf("rlp: type %v is not RLP-serializable", typ)
}
}
By passing in the corresponding type and flag, the makeWriter function will return the corresponding encoder.
String type
Here, take Uint as an example. Note that specific types (including user-defined types) in all go languages can be abstracted into String types and List types, and Uint can be abstracted into String types.
case isUint(kind):
return writeUint, nil
func isUint(k reflect.Kind) bool {
return k >= reflect.Uint && k <= reflect.Uintptr
}
If the type is Uint, the corresponding encoder is writeUint function, which is defined as follows:
func writeUint(val reflect.Value, w *encbuf) error {
w.encodeUint(val.Uint())
return nil
}
func (w *encbuf) encodeUint(i uint64) {
if i == 0 {
w.str = append(w.str, 0x80)
} else if i < 128 {
// fits single byte
w.str = append(w.str, byte(i))
} else {
s := putint(w.sizebuf[1:], i)
w.sizebuf[0] = 0x80 + byte(s)
w.str = append(w.str, w.sizebuf[:s+1]...)
}
}
Its encoding form is actually abstracting it into String type and encoding it according to the rules described above.
List type
Here, take Struct as an example, which can be abstracted as List type:
case kind == reflect.Struct: return makeStructWriter(typ)
The makeStructWriter function is defined as follows:
func makeStructWriter(typ reflect.Type) (writer, error) {
fields, err := structFields(typ)
if err != nil {
return nil, err
}
for _, f := range fields {
if f.info.writerErr != nil {
return nil, structFieldError{typ, f.index, f.info.writerErr}
}
}
writer := func(val reflect.Value, w *encbuf) error {
lh := w.list()
for _, f := range fields {
if err := f.info.writer(val.Field(f.index), w); err != nil {
return err
}
}
w.listEnd(lh)
return nil
}
return writer, nil
}
This function returns an encoder corresponding to the Struct. The encoder will parse each field in the Struct and encode each field in the corresponding encoding method. At the same time, note that since Struct can be abstracted as a list type, the list and listEnd functions will be called respectively to set the offset and size items of lhead s in encbuf when encoding starts and ends. Here are the definitions of list function and listEnd function:
// list adds a new list header to the header stack. It returns the index
// of the header. The caller must call listEnd with this index after encoding
// the content of the list.
func (w *encbuf) list() int {
w.lheads = append(w.lheads, listhead{offset: len(w.str), size: w.lhsize})
return len(w.lheads) - 1
}
func (w *encbuf) listEnd(index int) {
lh := &w.lheads[index]
lh.size = w.size() - lh.offset - lh.size
if lh.size < 56 {
w.lhsize++ // length encoded into kind tag
} else {
w.lhsize += 1 + intsize(uint64(lh.size))
}
}
The List function creates a listhead structure and adds it to the lheads of encbuf. The listEnd function will set the size field of the corresponding List type after the List type encoding is completed.
Other go language type variables can be abstracted as String type or List type. The specific coding methods are different in detail, but they are generally coded according to the basic principles
Other details
The encoded information is stored in the encbuf structure, but the final RLP code is not stored in it, but an intermediate result. We can convert it into a byte string by calling the toBytes function. As for why not directly store the final RLP encoding results, I think it is because it allows users to choose different output forms, such as toBytes or toWriter. The toBytes function is as follows:
func (w *encbuf) toBytes() []byte {
out := make([]byte, w.size())
strpos := 0
pos := 0
for _, head := range w.lheads {
// write string data before header
n := copy(out[pos:], w.str[strpos:head.offset])
pos += n
strpos += n
// write the header
enc := head.encode(out[pos:])
pos += len(enc)
}
// copy string data after the last list header
copy(out[pos:], w.str[strpos:])
return out
}
This function writes the final RLP encoding result to out and outputs it. Therefore, it is necessary to constantly copy data from w *encbuf to out, where pos represents the location of the current copy to out and strpos represents the location of the current copy in w.str. the final result of this code will add the content of w.str to the List type header in the appropriate location, write it into out and return it.
decode.go
decode.go provides two export functions of Decode/DecodeBytes to obtain RLP codes from different input sources and Decode them. These functions will call the Decode function to Decode, and the encode function will obtain the corresponding decoder from the typeCache for encoding operation.
// Decode decodes a value and stores the result in the value pointed
// to by val. Please see the documentation for the Decode function
// to learn about the decoding rules.
func (s *Stream) Decode(val interface{}) error {
if val == nil {
return errDecodeIntoNil
}
rval := reflect.ValueOf(val)
rtyp := rval.Type()
if rtyp.Kind() != reflect.Ptr {
return errNoPointer
}
if rval.IsNil() {
return errDecodeIntoNil
}
decoder, err := cachedDecoder(rtyp.Elem())
if err != nil {
return err
}
err = decoder(s, rval.Elem())
if decErr, ok := err.(*decodeError); ok && len(decErr.ctx) > 0 {
// add decode target type to error so context has more meaning
decErr.ctx = append(decErr.ctx, fmt.Sprint("(", rtyp.Elem(), ")"))
}
return err
}
val is required to be a pointer to go language type. If it is not a pointer or the pointer is empty, the corresponding error will be returned. Otherwise, query the corresponding decoder in typeCache for decoding.
In the decoding process, the Stream structure is needed to store the data to be decoded and some intermediate information in the decoding process. Its definition is as follows:
type Stream struct {
r ByteReader
// number of bytes remaining to be read from r.
remaining uint64
limited bool
// auxiliary buffer for integer decoding
uintbuf []byte
kind Kind // kind of value ahead
size uint64 // size of value ahead
byteval byte // value of single byte in type tag
kinderr error // error from last readKind
stack []listpos
}
// Kind is one of - 1, byte, string and list
type listpos struct{ pos, size uint64 }
//pos is the position of the read data in the whole List type, and size is the size of the original data of the List type
Among them, the data to be decoded is stored in r, which needs to be read and decoded continuously. Each time decoding is performed, the Reset function needs to be called to initialize the data to be decoded. When the Reset function Reset is called, the remaining, limited, uintbuf, kind, size, byteval, kinderr, stack fields will also be Reset. If the data to be decoded is a Byte string, set limited to true and remaining to its length. Uintbuf is used to temporarily store information such as Byte string length. Kind indicates the data type to be decoded (initialized to - 1), size indicates the native data length, if kind type is Byte, byteval is the value of single Byte data, and kinderr is the error encountered when reading type. Stack is mainly used to process nested lists.
String type
Here, take Uint as an example to observe how its specific decoder is implemented
case isUint(kind):
return decodeUint, nil
func decodeUint(s *Stream, val reflect.Value) error {
typ := val.Type()
num, err := s.uint(typ.Bits())
if err != nil {
return wrapStreamError(err, val.Type())
}
val.SetUint(num)
return nil
}
func (s *Stream) uint(maxbits int) (uint64, error) {
kind, size, err := s.Kind()
if err != nil {
return 0, err
}
switch kind {
case Byte:
if s.byteval == 0 {
return 0, ErrCanonInt
}
s.kind = -1 // rearm Kind reset type
return uint64(s.byteval), nil
case String:
if size > uint64(maxbits/8) {
return 0, errUintOverflow
}
v, err := s.readUint(byte(size))
switch {
case err == ErrCanonSize:
// Adjust error because we're not reading a size right now.
return 0, ErrCanonInt
case err != nil:
return 0, err
case size > 0 && v < 128:
return 0, ErrCanonSize
default:
return v, nil
}
default:
return 0, ErrExpectedString
}
}
The decodeUint function obtains the number of bits of the data type to be decoded and passes it into the member function uint of the Stream structure. The uint function first calls the kind function to obtain the type kind (Byte/String/List) of the data to be decoded and the size (number of bytes) of the original data. If there is an error in calling the kind function, the corresponding error message will be returned to err. If there is no error, according to the data type to be decoded obtained by the kind function, if the data to be decoded is a single Byte, its native data and encoded data are the same, and the data value of Byte type will be stored in the Byte of Stream when calling the kind function, and its value can be returned directly; If the data to be decoded is String, you can read the next data through the obtained original data size. At the same time, there will be a corresponding error detection process. If there is no error, the result will be returned.
List type
Here, take Struct as an example to observe how its specific decoder is implemented
case kind == reflect.Struct:
return makeStructDecoder(typ)
func makeStructDecoder(typ reflect.Type) (decoder, error) {
fields, err := structFields(typ)
if err != nil {
return nil, err
}
for _, f := range fields {
if f.info.decoderErr != nil {
return nil, structFieldError{typ, f.index, f.info.decoderErr}
}
}
dec := func(s *Stream, val reflect.Value) (err error) {
if _, err := s.List(); err != nil {
return wrapStreamError(err, typ)
}
for _, f := range fields {
err := f.info.decoder(s, val.Field(f.index))
if err == EOL {
return &decodeError{msg: "too few elements", typ: typ}
} else if err != nil {
return addErrorContext(err, "."+typ.Field(f.index).Name)
}
}
return wrapStreamError(s.ListEnd(), typ)
}
return dec, nil
}
The implementation form here is actually the same as encode Go is similar, except that the encoder is changed to a decoder. We mainly need to observe how the s.List and s.ListEnd functions modify s.stack to create List type information. Their implementation codes are as follows:
// List starts decoding an RLP list. If the input does not contain a
// list, the returned error will be ErrExpectedList. When the list's
// end has been reached, any Stream operation will return EOL.
func (s *Stream) List() (size uint64, err error) {
kind, size, err := s.Kind()
if err != nil {
return 0, err
}
if kind != List {
return 0, ErrExpectedList
}
s.stack = append(s.stack, listpos{0, size})
s.kind = -1
s.size = 0
return size, nil
}
// ListEnd returns to the enclosing list.
// The input reader must be positioned at the end of a list.
func (s *Stream) ListEnd() error {
if len(s.stack) == 0 {
return errNotInList
}
tos := s.stack[len(s.stack)-1]
if tos.pos != tos.size {
return errNotAtEOL
}
s.stack = s.stack[:len(s.stack)-1] // pop
if len(s.stack) > 0 {
s.stack[len(s.stack)-1].pos += tos.size
}
s.kind = -1
s.size = 0
return nil
}
The List function obtains the type and size of the data to be decoded by calling s.kind. If the data type to be decoded is List type, set s.stack, and then reset s.kind and s.size. The ListEnd function indicates that the resolution of a List type has been completed, so it needs to be taken out of the s.stack. Before taking it out, you need to compare its pos field and size field to ensure that the complete List has been read. Finally, if there is a nested List, you need to add the corresponding length to the pos of its parent List to indicate that this segment has been resolved.
Other details
Since all types of encoders are implemented with the help of member functions in the Stream structure, you need to see how some important member functions are implemented.
For the Kind function:
// Kind returns the kind and size of the next value in the
// input stream.
//
// The returned size is the number of bytes that make up the value.
// For kind == Byte, the size is zero because the value is
// contained in the type tag.
//
// The first call to Kind will read size information from the input
// reader and leave it positioned at the start of the actual bytes of
// the value. Subsequent calls to Kind (until the value is decoded)
// will not advance the input reader and return cached information.
func (s *Stream) Kind() (kind Kind, size uint64, err error) {
var tos *listpos
if len(s.stack) > 0 {
tos = &s.stack[len(s.stack)-1]
}
if s.kind < 0 {
s.kinderr = nil
// Don't read further if we're at the end of the
// innermost list.
if tos != nil && tos.pos == tos.size {
return 0, 0, EOL
}
s.kind, s.size, s.kinderr = s.readKind()
if s.kinderr == nil {
if tos == nil {
// At toplevel, check that the value is smaller
// than the remaining input length.
if s.limited && s.size > s.remaining {
s.kinderr = ErrValueTooLarge
}
} else {
// Inside a list, check that the value doesn't overflow the list.
if s.size > tos.size-tos.pos {
s.kinderr = ErrElemTooLarge
}
}
}
}
// Note: this might return a sticky error generated
// by an earlier call to readKind.
return s.kind, s.size, s.kinderr
}
The Kind function returns the type and size of the next data to be decoded in the input stream. At the same time, when obtaining the data size, the position of the read pointer in the input stream will be updated because the data needs to be read from the input stream. First, get the last element in s.stack. If the current decoding type is a list, the obtained content must not be empty (this can be used to detect whether the data to be decoded has exceeded the length of the whole list).
When a data to be decoded has been successfully processed (s.kind==-1 at this time), the next data type, size and other information to be processed will be obtained by calling s.readKind function. In addition, it is also necessary to check whether the size information has exceeded the length limit; Otherwise, directly return the data type, size and other information to be processed. s. The readkind function is defined as follows:
func (s *Stream) readKind() (kind Kind, size uint64, err error) {
b, err := s.readByte()
if err != nil {
if len(s.stack) == 0 {
// At toplevel, Adjust the error to actual EOF. io.EOF is
// used by callers to determine when to stop decoding.
switch err {
case io.ErrUnexpectedEOF:
err = io.EOF
case ErrValueTooLarge:
err = io.EOF
}
}
return 0, 0, err
}
s.byteval = 0
switch {
case b < 0x80:
// For a single byte whose value is in the [0x00, 0x7F] range, that byte
// is its own RLP encoding.
s.byteval = b
return Byte, 0, nil
case b < 0xB8:
// Otherwise, if a string is 0-55 bytes long,
// the RLP encoding consists of a single byte with value 0x80 plus the
// length of the string followed by the string. The range of the first
// byte is thus [0x80, 0xB7].
return String, uint64(b - 0x80), nil
case b < 0xC0:
// If a string is more than 55 bytes long, the
// RLP encoding consists of a single byte with value 0xB7 plus the length
// of the length of the string in binary form, followed by the length of
// the string, followed by the string. For example, a length-1024 string
// would be encoded as 0xB90400 followed by the string. The range of
// the first byte is thus [0xB8, 0xBF].
size, err = s.readUint(b - 0xB7)
if err == nil && size < 56 {
err = ErrCanonSize
}
return String, size, err
case b < 0xF8:
// If the total payload of a list
// (i.e. the combined length of all its items) is 0-55 bytes long, the
// RLP encoding consists of a single byte with value 0xC0 plus the length
// of the list followed by the concatenation of the RLP encodings of the
// items. The range of the first byte is thus [0xC0, 0xF7].
return List, uint64(b - 0xC0), nil
default:
// If the total payload of a list is more than 55 bytes long,
// the RLP encoding consists of a single byte with value 0xF7
// plus the length of the length of the payload in binary
// form, followed by the length of the payload, followed by
// the concatenation of the RLP encodings of the items. The
// range of the first byte is thus [0xF8, 0xFF].
size, err = s.readUint(b - 0xF7)
if err == nil && size < 56 {
err = ErrCanonSize
}
return List, size, err
}
This function returns the original type (Byte/String/List) and size information of the encoded data by parsing the encoded header information. The s.readUint() function is used to read byte data of corresponding size.
reflect library description
In order to facilitate the encoding and decoding of different go data types, it is necessary to use the reflect library. See for details here