After the system runs for a long time, the available memory becomes less and less, and even some services fail. This is a typical memory leak problem. Such problems are usually difficult to predict and locate through static code sorting. Heap Profiling helps us solve such problems.
As a part of the distributed system, TiKV has initially possessed the ability of Heap Profiling. This paper will introduce some common implementation principles and application methods of Heap Profiler, so as to help readers understand the relevant implementations in TiKV more easily, or better apply such analysis methods to their own projects.
What is Heap Profiling
Memory leakage at runtime is quite difficult to troubleshoot in many scenarios, because such problems are usually difficult to predict and locate through static code combing.
Heap Profiling helps us solve such problems.
Heap Profiling usually refers to collecting or sampling the heap allocation of an application to report the memory usage of the application to us, so as to analyze the cause of memory occupation or locate the source of memory leakage.
How does Heap Profiling work
For comparison, let's first briefly understand how CPU Profiling works.
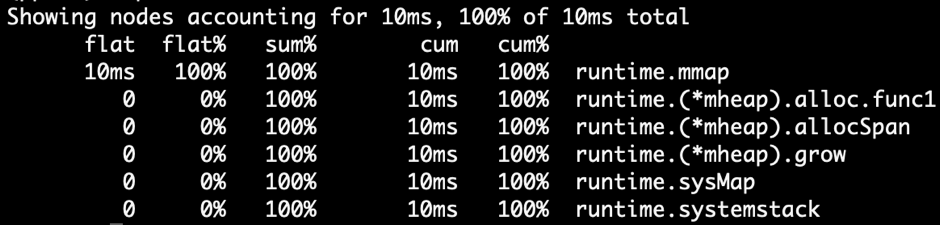
When we are ready for CPU Profiling, we usually need to select a time window. In this window, the CPU Profiler will register a regularly executed hook with the target program (there are many means, such as SIGPROF signal). In this hook, we will get the stack trace of the business thread every time.
We control the execution frequency of hook at a specific value, such as 100hz, so that we can collect a call stack sample of business code every 10ms. When the time window is over, we aggregate all the collected samples, and finally get the number of times each function is collected. Compared with the total number of samples, we get the relative proportion of each function.
With the help of this model, we can find the functions with high proportion, and then locate the CPU hotspot.
In terms of data structure, Heap Profiling is very similar to CPU Profiling. They are both stack trace + statistics models. If you have used pprof provided by Go, you will find that their presentation formats are almost the same:
Go CPU Profile
Go Heap Profile
Different from CPU Profiling, the data collection of Heap Profiling is not simply carried out through the timer, but needs to invade into the memory allocation path in order to get the amount of memory allocation. Therefore, the common practice of Heap Profiler is to directly integrate itself into the memory allocator. When the application allocates memory, it gets the current stack trace, and finally aggregates all samples together, so that we can know the memory allocation amount of each function directly or indirectly.
The stack trace + statistics data model of the Heap Profile is consistent with the CPU Proflie.
Next, we will introduce the use and implementation principle of several heap profilers.
Note: the usage scenarios of tools such as GNU gprof and Valgrind do not match our target scenario, so this article will not expand. Refer to gprof, Valgrind and gperftools - an evaluation of some tools for application level CPU profiling on Linux - Gernot.Klingler.
Heap Profiling in Go
Most readers should be more familiar with Go, so we take Go as the starting point and basis for research.
Note: if we talked about a concept in the previous section, the subsequent sections will not repeat it, even if they are not the same project. In addition, for the purpose of completeness, each project is equipped with a usage section to explain its usage. Students who are already familiar with this can skip it directly.
Usage
Go runtime has built-in convenient profiler, and heap is one of them. We can open a debug port in the following ways:
import _ "net/http/pprof"
go func() {
log.Print(http.ListenAndServe("0.0.0.0:9999", nil))
}()
Then use the command line to get the current command during the program running Heap Profiling Snapshot: $ go tool pprof http://127.0.0.1:9999/debug/pprof/heap
Or you can get it directly once at a specific location in the application code Heap Profiling Snapshot: import "runtime/pprof"
pprof.WriteHeapProfile(writer)
Here we use a complete demo Let's string it heap pprof Usage of: package main
import (
"log"
"net/http"
_ "net/http/pprof"
"time"
)
func main() {
go func() {
log.Fatal(http.ListenAndServe(":9999", nil))
}()
var data [][]byte
for {
data = func1(data)
time.Sleep(1 * time.Second)
}
}
func func1(data [][]byte) [][]byte {
data = func2(data)
return append(data, make([]byte, 1024*1024)) // alloc 1mb
}
func func2(data [][]byte) [][]byte {
return append(data, make([]byte, 1024*1024)) // alloc 1mb
}
The code continues to func1 and func2 Allocate memory separately, with a total of 2 per second mb Heap memory.
After running the program for a period of time, execute the following command: profile Snapshot and open a web Services to browse: $ go tool pprof -http=":9998" localhost:9999/debug/pprof/heap
Go Heap Graph From the figure, we can intuitively see which functions have the largest memory allocation (the box is larger) and the function call relationship (through wiring). For example, it is obvious in the figure above that func1 and func2 The majority of the distribution, and func2 cover func1 Call.
Note that due to Heap Profiling It is also sampled (512 per allocation by default) k Sample once), so the memory size shown here is smaller than the actual allocated memory size. with CPU Profiling Similarly, this value is only used to calculate the relative proportion and then locate the memory allocation hotspot.
Note: in fact, Go runtime There is logic to estimate the original size of the sampled results, but this conclusion is not necessarily accurate.
In addition, func1 Box 48.88% of 90.24% express Flat% of Cum%.
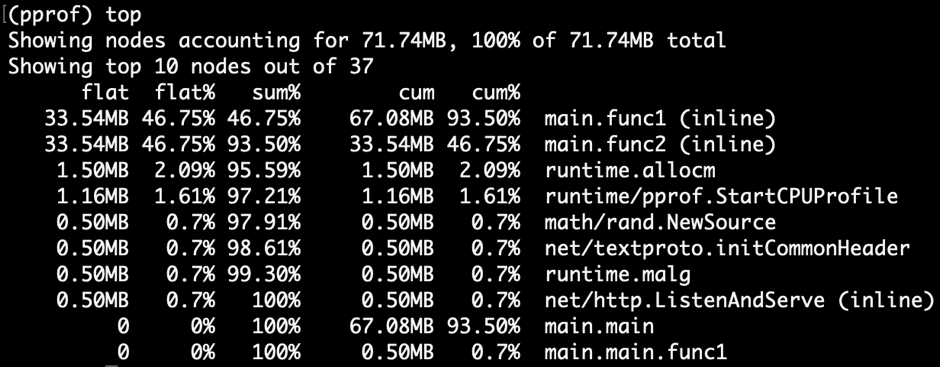
What is? Flat% and Cum%?Let's change the browsing mode, in the upper left corner View Bar drop-down Click Top:
Go Heap TopName List the corresponding function names Flat The list shows how much memory is allocated by the function itself Flat% Column representation Flat Proportion of relative total allocation size Cum The list shows how much memory is allocated for this function and all its sub functions Cum% Column representation Cum Proportion of relative total allocation size
Sum% The list is shown from top to bottom Flat% The above two methods can help us locate specific functions, Go Provides finer grained allocation source statistics at the number of lines of code level, in the upper left corner View Bar drop-down Click Source: Go Heap Source stay CPU Profiling In, we often use the flame diagram to find the wide top to locate the hot spot function quickly and intuitively. Of course, due to the homogeneity of the data model, Heap Profiling The data can also be displayed through the flame diagram in the upper left corner View Bar drop-down Click Flame Graph: Go Heap Flamegraph Through the above methods, we can easily see that the main memory allocation is func1 and func2. However, in the real scene, it will never be so simple for us to locate the root cause of the problem. Because we get a snapshot at a certain moment, it is not enough for the memory leakage problem. What we need is an incremental data to judge which memory is growing continuously. So you can get it again after a certain interval Heap Profile,Make a comparison of the two results diff.
Implementation details In this section, we focus on Go Heap Profiling Implementation principle of.
Review“ Heap Profiling How does it work? " One section, Heap Profiler The usual approach is to integrate itself directly into the memory allocator to get the current memory when the application allocates memory stack trace,and Go That's what I did.
Go The memory allocation entry for is src/runtime/malloc.go Medium mallocgc() Function, one of the key codes is as follows: func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// ...
if rate := MemProfileRate; rate > 0 {
// Note cache c only valid while m acquired; see #47302
if rate != 1 && size < c.nextSample {
c.nextSample -= size
} else {
profilealloc(mp, x, size)
}
}
// ...
}
func profilealloc(mp *m, x unsafe.Pointer, size uintptr) {
c := getMCache()
if c == nil {
throw("profilealloc called without a P or outside bootstrapping")
}
c.nextSample = nextSample()
mProf_Malloc(x, size)
}
This means that every pass mallocgc() Allocation 512 k Heap memory, call profilealloc() Record once stack trace.
Why do I need to define a sampling granularity? every time mallocgc() Record the current stack trace Isn't it more accurate?
It seems more attractive to get the memory allocation of all functions completely and accurately, but the performance overhead is huge. malloc() As a user state library function, it will be called very frequently by applications. It is important to optimize the memory allocation performance allocator Responsibility of the. If every time malloc() All calls are accompanied by a stack backtrace, and the overhead is almost unacceptable, especially on the server side for a long time profiling The scene. Choosing "sampling" is not a better result, but just a compromise.
Of course, we can also modify it ourselves MemProfileRate Variable, setting it to 1 causes each mallocgc() Must proceed stack trace Record, if set to 0, it will be completely closed Heap Profiling,Users can weigh performance and accuracy according to actual scenarios.
Note that when we will MemProfileRate When set to a normal sampling granularity, this value is not completely accurate, but is displayed every time MemProfileRate Take a random value from the exponential distribution of the average value.// nextSample returns the next sampling point for heap profiling. The goal is
// to sample allocations on average every MemProfileRate bytes, but with a
// completely random distribution over the allocation timeline; this
// corresponds to a Poisson process with parameter MemProfileRate. In Poisson
// processes, the distance between two samples follows the exponential
// distribution (exp(MemProfileRate)), so the best return value is a random
// number taken from an exponential distribution whose mean is MemProfileRate.
func nextSample() uintptr
In many cases, the memory allocation is regular. If the sampling is carried out according to a fixed granularity, there may be a large error in the final result, and each sampling may catch up with a specific type of memory allocation. This is why randomization is chosen here.
Not just Heap Profiling,be based on sampling Various types of profiler There will always be some errors (for example: SafePoint Bias),Based on sampling of profiling As a result, you need to remind yourself not to ignore the possibility of errors.
be located src/runtime/mprof.go of mProf_Malloc() The function is responsible for specific sampling:// Called by malloc to record a profiled block.
func mProf_Malloc(p unsafe.Pointer, size uintptr) {
var stk [maxStack]uintptr
nstk := callers(4, stk[:])
lock(&proflock)
b := stkbucket(memProfile, size, stk[:nstk], true)
c := mProf.cycle
mp := b.mp()
mpc := &mp.future[(c+2)%uint32(len(mp.future))]
mpc.allocs++
mpc.alloc_bytes += size
unlock(&proflock)
// Setprofilebucket locks a bunch of other mutexes, so we call it outside of proflock.
// This reduces potential contention and chances of deadlocks.
// Since the object must be alive during call to mProf_Malloc,
// it's fine to do this non-atomically.
systemstack(func() {
setprofilebucket(p, b)
})
}
func callers(skip int, pcbuf []uintptr) int {
sp := getcallersp()
pc := getcallerpc()
gp := getg()
var n int
systemstack(func() {
n = gentraceback(pc, sp, 0, gp, skip, &pcbuf[0], len(pcbuf), nil, nil, 0)
})
return n
}
By calling callers() And further gentraceback() To obtain the current call stack. stk In array (i.e PC Array of addresses), which is called call stack backtracking, and is applied in many scenarios (such as programs) panic Stack expansion).
Note: Terminology PC finger Program Counter,Specific to x86-64 For platform RIP Register; FP finger Frame Pointer,Specific to x86-64 Shi Wei RBP Register; SP finger Stack Pointer,Specific to x86-64 Shi Wei RSP Register.
An original implementation of call stack backtracking is in the function call convention( Calling Convention)When a function call occurs on the RBP Register( on x86-64)The stack base address must be saved instead of being used as a general-purpose register call The command will first RIP ((return address) into the stack, we just need to ensure that the first data in the next stack is current RBP,Then the stack base addresses of all functions are RBP As the header, it forms a linked list of addresses. We just need to RBP The address can be obtained by shifting down one unit RIP Array of. Go FramePointer Backtrace(Picture from go-profiler-notes)Note: it is mentioned in the figure Go The conclusion that all parameters of are passed through the stack is now outdated, Go From 1.17 Register parameter passing is supported in version.
because x86-64 take RBP General purpose registers, such as GCC The compiler is no longer used by default RBP Save the stack base address unless you turn it on with a specific option Go The compiler retains this feature, so Go Passed in RBP Stack backtracking is feasible.
but Go This simple scheme is not adopted because it will cause some problems in some special scenarios, such as if a function is deleted inline Dropped, then pass RBP The call stack obtained by backtracking is missing. In addition, this scheme needs to insert additional instructions between regular function calls and occupy an additional general register, which has a certain performance overhead, even if we do not need stack backtracking.
each Go All binaries contain a file named gopclntab of section,This is Go Program Counter Line Table It maintains PC reach SP And its return address. So we don't need to rely on it FP,It can be completed directly by looking up the table PC Concatenation of linked lists gopclntab Maintained in PC And whether the function in which it is located has been optimized inline, so we will not lose the inline function frame during stack backtracking. In addition gopclntab The symbol table is also maintained and saved PC Corresponding code information (function name, number of lines, etc.), so we can finally see human readable panic Result or profiling As a result, not a lot of address information. gopclntab And specific to Go of gopclntab Different, DWARF Is a standardized debugging format, Go The compiler also generates binary Added DWARF (v4) Information, so some non Go The external tools of ecology can rely on it Go Program debugging. It is worth mentioning that, DWARF The information contained is gopclntab A superset of.
go back to Heap Profiling Here, when we use stack backtracking Technology (in the previous code) gentraceback() Function) get PC After the array is, we don't need to hurry to symbolize it directly. The overhead of symbolization is considerable. We can aggregate it through the pointer address stack first. The so-called aggregation is in hashmap The same samples are accumulated in. The same samples refer to the samples with exactly the same contents of the two arrays.
adopt stkbucket() Function to stk by key Get the corresponding bucket,Then the statistics related fields are accumulated.
In addition, we note that memRecord There are multiple groups memRecordCycle Statistics: type memRecord struct {
active memRecordCycle
future [3]memRecordCycle
}
When accumulating, it is through mProf.cycle Global variables are used as subscript modules to access a specific set of variables memRecordCycle. mProf.cycle Every round GC Will increase, so three rounds are recorded GC Distribution between. Only when one round GC After that, the last round will be GC To this round GC The memory allocation and release between are incorporated into the final displayed statistics. This design is to avoid GC Get it before execution Heap Profile,Show us a lot of useless temporary memory.
And, in one round GC We may also see unstable heap memory state at different times of the cycle.
Final call setprofilebucket() take bucket Record the information related to the assigned address mspan On, for follow-up GC Time call mProf_Free() To record the corresponding release.
That's it. Go runtime Always maintain this bucket Assemble when we need to Heap Profiling When (e.g. calling) pprof.WriteHeapProfile() Will visit this bucket Sets, converting to pprof Output the required format.
This too Heap Profiling And CPU Profiling One difference: CPU Profiling Only in progress profiling There is a certain sampling overhead for the application within the time window of Heap Profiling The sampling of occurs all the time and is executed once profiling Merely dump Take a snapshot of the data so far.
Next we will enter C/C++/Rust The world, fortunately, because most Heap Profiler The implementation principle of is similar. Many of the knowledge described above is in the corresponding later. The most typical, Go Heap Profiling It's actually from Google tcmalloc They have a similar implementation.
Heap Profiling with gperftoolsgperftools(Google Performance Tools)It's a kit, including Heap Profiler,Heap Checker,CPU Profiler And other tools Go Then I introduce it because it is related to Go It has a deep origin.
Mentioned earlier Go runtime Transplanted Google tcmalloc Two community versions have been differentiated internally: one is tcmalloc,Pure malloc Implementation, without other additional functions; the other is gperftools,Yes Heap Profiling Capable malloc Implementation, and other supporting toolsets.
among pprof It is also one of the most well-known tools. pprof Early was a perl Script, which later evolved into Go Powerful tools for writing pprof,Now it has been integrated into Go Trunk, which we usually use go tool pprof The internal command is used directly pprof Bag.
Note: gperftools The main author is Sanjay Ghemawat,And Jeff Dean Pair programming.
UsageGoogle It has been used internally gperftools of Heap Profiler analysis C++ Heap memory allocation of the program, which can:
Figuring out what is in the program heap at any given timeLocating memory leaksFinding places that do a lot of allocation
As Go pprof Our ancestors look like Go Provided Heap Profiling The ability is the same.
Go It's directly in runtime The memory allocation function in is hard coded into the acquisition code, which is similar to this, gperftools Is what it provides libtcmalloc of malloc The acquisition code is embedded in the implementation. The user needs to execute in the project compilation link phase -ltcmalloc Link the library to replace libc default malloc realization.
Of course, we can also rely on Linux Dynamic link mechanism to replace at run time: $ env LD_PRELOAD="/usr/lib/libtcmalloc.so" <binary>
When used LD_PRELOAD Specified libtcmalloc.so After that, the default link in our program malloc() It's covered, Linux The dynamic linker ensures priority execution LD_PRELOAD The specified version.
Running link libtcmalloc Before the executable, if we put the environment variable HEAPPROFILE Set to a file name, then when the program executes, Heap Profile The data is written to the file.
By default, whenever our program is assigned 1 g Memory when, or whenever, the program's memory usage high watermark increases by 100 mb It will be carried out once Heap Profile of dump. These parameters can be modified by environment variables.
use gperftools Self contained pprof Scripts can be analyzed dump Come out profile Files, usage and Go Basically the same. $ pprof --gv gfs_master /tmp/profile.0100.heap
gperftools gv$ pprof --text gfs_master /tmp/profile.0100.heap
255.6 24.7% 24.7% 255.6 24.7% GFS_MasterChunk::AddServer
184.6 17.8% 42.5% 298.8 28.8% GFS_MasterChunkTable::Create
176.2 17.0% 59.5% 729.9 70.5% GFS_MasterChunkTable::UpdateState
169.8 16.4% 75.9% 169.8 16.4% PendingClone::PendingClone
76.3 7.4% 83.3% 76.3 7.4% __default_alloc_template::_S_chunk_alloc
49.5 4.8% 88.0% 49.5 4.8% hashtable::resize
...
Similarly, from left to right Flat(mb),Flat%,Sum%,Cum(mb),Cum%,Name.
Implementation details allied, tcmalloc stay malloc() and operator new Some sampling logic is added in when sampling is triggered according to conditions hook When, the following functions are executed:// Record an allocation in the profile.
static void RecordAlloc(const void* ptr, size_t bytes, int skip_count) {
// Take the stack trace outside the critical section.
void* stack[HeapProfileTable::kMaxStackDepth];
int depth = HeapProfileTable::GetCallerStackTrace(skip_count + 1, stack);
SpinLockHolder l(&heap_lock);
if (is_on) {
heap_profile->RecordAlloc(ptr, bytes, depth, stack);
MaybeDumpProfileLocked();
}
}
void HeapProfileTable::RecordAlloc(
const void* ptr, size_t bytes, int stack_depth,
const void* const call_stack[]) {
Bucket* b = GetBucket(stack_depth, call_stack);
b->allocs++;
b->alloc_size += bytes;
total_.allocs++;
total_.alloc_size += bytes;
AllocValue v;
v.set_bucket(b); // also did set_live(false); set_ignore(false)
v.bytes = bytes;
address_map_->Insert(ptr, v);
}
The execution process is as follows: call GetCallerStackTrace() Gets the call stack. Call stack as hashmap of key call GetBucket() Get the corresponding Bucket. accumulation Bucket Statistics in.
Because there is no GC Compared with the sampling process Go Much simpler. In terms of variable naming, Go runtime Medium profiling The code is indeed transplanted from here.
sampler.h Described in detail in gperftools The sampling rules, in general, are also consistent with Go Consistent, i.e. 512 k average sample step.
stay free() or operator delete You also need to add some logic to record memory release, which is better than having GC of Go It's also much simpler:// Record a deallocation in the profile.
static void RecordFree(const void* ptr) {
SpinLockHolder l(&heap_lock);
if (is_on) {
heap_profile->RecordFree(ptr);
MaybeDumpProfileLocked();
}
}
void HeapProfileTable::RecordFree(const void* ptr) {
AllocValue v;
if (address_map_->FindAndRemove(ptr, &v)) {
Bucket* b = v.bucket();
b->frees++;
b->free_size += v.bytes;
total_.frees++;
total_.free_size += v.bytes;
}
}
Find the appropriate Bucket,accumulation free Relevant fields.
modern C/C++/Rust The process by which a program obtains the call stack is usually dependent libunwind From the library, libunwind The principle and method of stack backtracking Go Similarly, there is no choice Frame Pointer Backtracking patterns are all dependent on a specific in the program section Recorded unwind table. The difference is, Go What we rely on is the one created in our own ecology called gopclntab Specific section,and C/C++/Rust The program depends on .debug_frame section or .eh_frame section.
among .debug_frame by DWARF Standard definitions, Go The compiler will also write this information, but it will not use it and will only be used by third-party tools. GCC Only open -g Parameter will be sent to .debug_frame Write debug information.
and .eh_frame More modern, in Linux Standard Base Defined in. The principle is to let the compiler insert some pseudo instructions in the corresponding position of the assembly code( CFI Directives,Call Frame Information),To assist the assembler in generating the final include unwind table of .eh_frame section.
Take the following code as an example:// demo.c
int add(int a, int b) {
return a + b;
}
We use cc -S demo.c To generate assembly code( gcc/clang Note that it is not used here -g Parameters. .section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _add ## -- Begin function add
.p2align 4, 0x90
_add: ## @add
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
addl -8(%rbp), %eax
popq %rbp
retq
.cfi_endproc
## -- End function
.subsections_via_symbols
You can see a lot from the generated assembly code .cfi_ Pseudo instructions prefixed with, they are CFI Directives.
Heap Profiling with jemalloc Next, let's focus on jemalloc,that is because TiKV Default use jemalloc As a memory allocator, can I jemalloc Go on smoothly Heap Profiling This is a key point worthy of our attention.
Usagejemalloc I brought it myself Heap Profiling Capability, but it is not enabled by default. It needs to be specified at compile time --enable-prof Parameters../autogen.sh
./configure --prefix=/usr/local/jemalloc-5.1.0 --enable-prof
make
make install
And tcmalloc Similarly, we can choose to pass -ljemalloc take jemalloc Link to the program, or through LD_PRELOAD use jemalloc cover libc of malloc() realization.
We take Rust Program as an example to show how to pass jemalloc conduct Heap Profiling. fn main() {
let mut data = vec![];
loop {
func1(&mut data);
std::thread::sleep(std::time::Duration::from_secs(1));
}
}
fn func1(data: &mut Vec<Box<[u8; 1024*1024]>>) {
data.push(Box::new([0u8; 1024*1024])); // alloc 1mb
func2(data);
}
fn func2(data: &mut Vec<Box<[u8; 1024*1024]>>) {
data.push(Box::new([0u8; 1024*1024])); // alloc 1mb
}
And Go Provided in section demo Similarly, we are also Rust 2 allocated per second in mb Heap memory, func1 and func2 Each distribution 1 mb,from func1 call func2.
Direct use rustc Compile the file without any parameters, and then execute the following command to start the program: $ export MALLOC_CONF="prof:true,lg_prof_interval:25"
$ export LD_PRELOAD=/usr/lib/libjemalloc.so
$ ./demo
MALLOC_CONF Used to specify jemalloc Relevant parameters of, where prof:true Indicates on profiler,log_prof_interval:25 Indicates 2 per allocation^25 Byte (32) mb)Heap memory convenience dump A copy profile File.
Note: more MALLOC_CONF Options can refer to the documentation.
After waiting for some time, you can see some profile File generation. jemalloc Provides a and tcmalloc of pprof A similar tool is called jeprof,In fact, it is made by pprof perl script fork We can use it jeprof To review profile File. $ jeprof ./demo jeprof.7262.0.i0.heap
Can also generate and Go/gperftools same graph: $ jeprof --gv ./demo jeprof.7262.0.i0.heap
jeprof svg
Implementation details And tcmalloc similar, jemalloc stay malloc() Sampling logic is added in: JEMALLOC_ALWAYS_INLINE int
imalloc_body(static_opts_t *sopts, dynamic_opts_t *dopts, tsd_t *tsd) {
// ...
// If profiling is on, get our profiling context.
if (config_prof && opt_prof) {
bool prof_active = prof_active_get_unlocked();
bool sample_event = te_prof_sample_event_lookahead(tsd, usize);
prof_tctx_t *tctx = prof_alloc_prep(tsd, prof_active,
sample_event);
emap_alloc_ctx_t alloc_ctx;
if (likely((uintptr_t)tctx == (uintptr_t)1U)) {
alloc_ctx.slab = (usize <= SC_SMALL_MAXCLASS);
allocation = imalloc_no_sample(
sopts, dopts, tsd, usize, usize, ind);
} else if ((uintptr_t)tctx > (uintptr_t)1U) {
allocation = imalloc_sample(
sopts, dopts, tsd, usize, ind);
alloc_ctx.slab = false;
} else {
allocation = NULL;
}
if (unlikely(allocation == NULL)) {
prof_alloc_rollback(tsd, tctx);
goto label_oom;
}
prof_malloc(tsd, allocation, size, usize, &alloc_ctx, tctx);
} else {
assert(!opt_prof);
allocation = imalloc_no_sample(sopts, dopts, tsd, size, usize,
ind);
if (unlikely(allocation == NULL)) {
goto label_oom;
}
}
// ...
}
stay prof_malloc() Call in prof_malloc_sample_object() yes hashmap Accumulate the corresponding call stack records in: void
prof_malloc_sample_object(tsd_t *tsd, const void *ptr, size_t size,
size_t usize, prof_tctx_t *tctx) {
// ...
malloc_mutex_lock(tsd_tsdn(tsd), tctx->tdata->lock);
size_t shifted_unbiased_cnt = prof_shifted_unbiased_cnt[szind];
size_t unbiased_bytes = prof_unbiased_sz[szind];
tctx->cnts.curobjs++;
tctx->cnts.curobjs_shifted_unbiased += shifted_unbiased_cnt;
tctx->cnts.curbytes += usize;
tctx->cnts.curbytes_unbiased += unbiased_bytes;
// ...
}
jemalloc stay free() The logic injected in is also related to tcmalloc Similar, at the same time jemalloc Also dependent libunwind Stack backtracking will not be repeated here.
Heap Profiling with bytehoundBytehound It's a Linux Platform Memory Profiler,use Rust The feature is that the front-end functions provided are relatively rich. We focus on how it is implemented and whether it can be implemented in TiKV So just briefly introduce the basic usage.
Usage We can Releases Page download bytehound Binary dynamic library, only Linux Platform support.
Then, like tcmalloc or jemalloc Same, through LD_PRELOAD Mount its own implementation. Here we assume that Heap Profiling with jemalloc Same section with memory leak Rust Procedure: $ LD_PRELOAD=./libbytehound.so ./demo
Next, a file will be generated in the working directory of the program memory-profiling_*.dat File, this is bytehound of Heap Profiling Products. Note, and others Heap Profiler The difference is that this file is constantly updated, rather than generating a new file every specific time.
Next, execute the following command to open a web The port is used to analyze the above files in real time: $ ./bytehound server memory-profiling_*.dat
Bytehound GUI The most intuitive way is to click the button in the upper right corner Flamegraph View flame diagram: Bytehound Flamegraph It can be easily seen from the picture demo::func1 And demo::func2 Memory hotspots.
Bytehound Provides rich GUI Function, which is one of its highlights. You can refer to the documents to explore by yourself.
Implementation detailsBytehound It also replaces the user's default malloc Implementation, but bytehound It does not implement the memory allocator itself, but is based on jemalloc Packed.// entrance
#[cfg_attr(not(test), no_mangle)]
pub unsafe extern "C" fn malloc( size: size_t ) -> *mut c_void {
allocate( size, AllocationKind::Malloc )
}
#[inline(always)]
unsafe fn allocate( requested_size: usize, kind: AllocationKind ) -> *mut c_void {
// ...
// call jemalloc Allocate memory
let pointer = match kind {
AllocationKind::Malloc => {
if opt::get().zero_memory {
calloc_real( effective_size as size_t, 1 )
} else {
malloc_real( effective_size as size_t )
}
},
// ...
};
// ...
// Stack backtracking
let backtrace = unwind::grab( &mut thread );
// ...
// Record sample
on_allocation( id, allocation, backtrace, thread );
pointer
}
// xxx_real link to jemalloc realization
#[cfg(feature = "jemalloc")]
extern "C" {
#[link_name = "_rjem_mp_malloc"]
fn malloc_real( size: size_t ) -> *mut c_void;
// ...
}
Looks like every time malloc Stack backtracking and recording will be fixed during, and there is no sampling logic on_allocation hook In, the allocation record is sent to channel,By unified processor Thread for asynchronous processing. pub fn on_allocation(
id: InternalAllocationId,
allocation: InternalAllocation,
backtrace: Backtrace,
thread: StrongThreadHandle
) {
// ...
crate::event::send_event_throttled( move || {
InternalEvent::Alloc {
id,
timestamp,
allocation,
backtrace,
}
});
}
#[inline(always)]
pub(crate) fn send_event_throttled< F: FnOnce() -> InternalEvent >( callback: F ) {
EVENT_CHANNEL.chunked_send_with( 64, callback );
}
and EVENT_CHANNEL The implementation of is simple Mutex<Vec<T>>: pub struct Channel< T > {
queue: Mutex< Vec< T > >,
condvar: Condvar
}
Performance overhead In this section, let's explore the various aspects mentioned above Heap Profiler The specific measurement methods vary from scenario to scenario.
All tests are run separately in the following physical machine environment:
Go stay Go Our measurement method is to use TiDB + unistore Deploy a single node for runtime.MemProfileRate Adjust the parameters with sysbench Make measurements.
Relevant software version and pressure measurement parameter data: obtained result data:
Compared with "no record", whether TPS/QPS,still P95 Delay line, 512 k The performance loss of sampling records is basically 1% The performance cost of "full recording" meets the expectation of "high", but it is unexpectedly high: TPS/QPS Shrunk 20 times, P95 The delay increased 30 times.
because Heap Profiling It is a general function. We cannot accurately give the general performance loss in all scenarios. Only the measurement conclusion under a specific project is valuable. TiDB It is a relatively computing intensive application, and the memory allocation frequency may not be as high as that of some memory intensive applications. Therefore, this conclusion (and all subsequent conclusions) can only be used as a reference. Readers can measure the overhead under their own application scenarios.
tcmalloc/jemalloc We are based on TiKV To measure tcmalloc/jemalloc,The method is to deploy one on the machine PD Process and one TiKV Process, using go-ycsb The key parameters are as follows: threadcount=200
recordcount=100000
operationcount=1000000
fieldcount=20
At startup TiKV Used separately before LD_PRELOAD Inject different malloc hook. among tcmalloc Use the default configuration, which is similar to Go 512 of k Sampling; jemalloc The default sampling policy is used, and every 1 is assigned G Heap memory dump A copy profile File.
Finally, the following data are obtained: tcmalloc And jemalloc Their performance is almost the same, OPS This is 4% lower than the default memory allocator% about, P99 The delay line rose by 10% about.
We've learned before tcmalloc Implementation and implementation of Go heap pprof The implementation of is basically the same, but the measured data here are not consistent. It is speculated that the reason is TiKV And TiDB There are differences in memory allocation characteristics, which also confirms the previous statement: "we cannot accurately give the general performance loss in all scenarios, and only the measurement conclusions under specific projects are valuable".
bytehound We didn't bytehound And tcmalloc/jemalloc The reason for putting them together is TiKV Practical use bytehound You will encounter deadlock problems during the startup phase.
Because we speculate bytehound The performance overhead will be very high, which can not be applied in theory TiKV Production environment, so we just need to confirm this conclusion.
Note: it is speculated that the high performance overhead is due to bytehound The sampling logic is not found in the code, and the collected data passes each time channel Sent to the background thread for processing, and channel It's just simple to use Mutex + Vec Encapsulated the next.
We choose a simple one mini-redis Project to measure bytehound Performance overhead, because the goal is only to confirm whether it can be met TiKV The requirements of production environment rather than accurate measurement data, so we only make simple statistics and compare them TPS OK, specific driver The code snippet is as follows: var count int32
for n := 0; n < 128; n++ {
go func() {
for {
key := uuid.New()
err := client.Set(key, key, 0).Err()
if err != nil {
panic(err)
}
err = client.Get(key).Err()
if err != nil {
panic(err)
}
atomic.AddInt32(&count, 1)
}
}()
}
Open 128 goroutine yes server Read and write, one-time reading/Writing is considered a complete operation,Only the number of times is counted, and there is no measurement delay and other indicators. Finally, the total number of times is divided by the execution time to get the start bytehound Differences before and after TPS,The data are as follows: from the results TPS Lost 50% above.
What can BPF bring although BPF Performance overhead is low, but based on BPF To a large extent, we can only get indicators at the system level, usually in the sense of Heap Profiling Statistics need to be made on the memory allocation link, but the memory allocation tends to be hierarchical.
For example, if we advance in our own program malloc A large heap of memory is used as the memory pool, and the allocation algorithm is designed. Next, the heap memory required by all business logic is allocated from the memory pool Heap Profiler It won't work. Because it only tells you that you applied for a large amount of memory at the startup stage, and the number of memory requests at other times is 0. In this scenario, we need to intrude into our designed memory allocation code and do it at the entrance Heap Profiler What to do.
BPF The problem is similar. We can hang a hook on it brk/sbrk When the user state really needs to apply to the kernel for heap memory expansion, the current stack trace Record. However, the memory allocator is a complex black box, which is triggered most often brk/sbrk The user stack of is not necessarily the user stack that causes the memory leak. This needs to be verified by some experiments. If the results are really valuable, it will BPF As a low-cost solution, long-term operation is also possible (additional consideration is required) BPF Permission issues).
as for uprobe,Just non intrusive code implantation, for Heap Profiling It's still going to be allocator We follow the same logic, which leads to the same overhead, and we are not sensitive to the intrusion of the code.
https://github.com/parca-dev/parca Continuous Profiling based on BPF is implemented, but the only module that really uses BPF is CPU Profiler. A Python tool has been provided in BCC tools for CPU Profiling( https://github.com/iovisor/bcc/blob/master/tools/profile.py ), the core principle is the same. For the time being, there is not much reference for Heap Profiling.