the robot performs subsequent operations on test cases by parsing test case files. Before robot 3.2.2, the file content was directly parsed into a format similar to a table with a list. Since version 3.2.2, the lexical parsing part has been rewritten by using the token and abstract syntax tree in the compilation principle.
token can be understood as a field. In the test case file to be processed by the robot, each "word" in each line can be regarded as a field, such as the following line:
[Tags] ID=1 ANIMAL=cat COLOR=red SIZE=big
In the source robot/parsing/lexer/tokenizer.py file
_space_splitter = re.compile(r'(\s{2,}|\t)', re.UNICODE)
self._space_splitter.split(line)
These two lines are mainly used to separate each field
Therefore, the nine token s given by lexical analysis are
['[Tags]', ' ', 'ID=1',' ','ANIMAL=cat',' ','COLOR=red',' ','SIZE=big']
of course, the process of forming a token is not described in detail here, but for details, please refer to the document: Robot Framework Documentation
the method of obtaining token is recorded on page 18 of the document. If you want to know the detailed process, you can write the following test code for debugging according to the prompts in the document:
from robot.api.parsing import get_tokens path = 'example.robot' for token in get_tokens(path): print(repr(token))
If example.robot is the following:
*** Test Cases ***
Example
Keyword argument
Second example
Keyword xxx
*** Keywords ***
Keyword
[Arguments] ${arg}
Log ${arg}
The generated token after parsing is:
Token(TESTCASE_HEADER, '*** Test Cases ***', 1, 0) Token(EOL, '\n', 1, 18) Token(EOS, '', 1, 19) Token(TESTCASE_NAME, 'Example', 2, 0) Token(EOL, '\n', 2, 7) Token(EOS, '', 2, 8) Token(SEPARATOR, ' ', 3, 0) Token(KEYWORD, 'Keyword', 3, 4) Token(SEPARATOR, ' ', 3, 11) Token(ARGUMENT, 'argument', 3, 15) Token(EOL, '\n', 3, 23) Token(EOS, '', 3, 24) Token(EOL, '\n', 4, 0) Token(EOS, '', 4, 1)
after creating the token, we will use the abstract syntax tree to build the model object. The purpose of building the model is to express the test suite, test case, settings, variables, resource, keywords and other information in the file in a structure similar to tree, so as to facilitate other operations on the use case.
the model contains block and statement. Statement just stores the corresponding token value. Block can be simply understood as the key in the json string as an identifier. Each block and statement can also be used as the value of the block. Example:
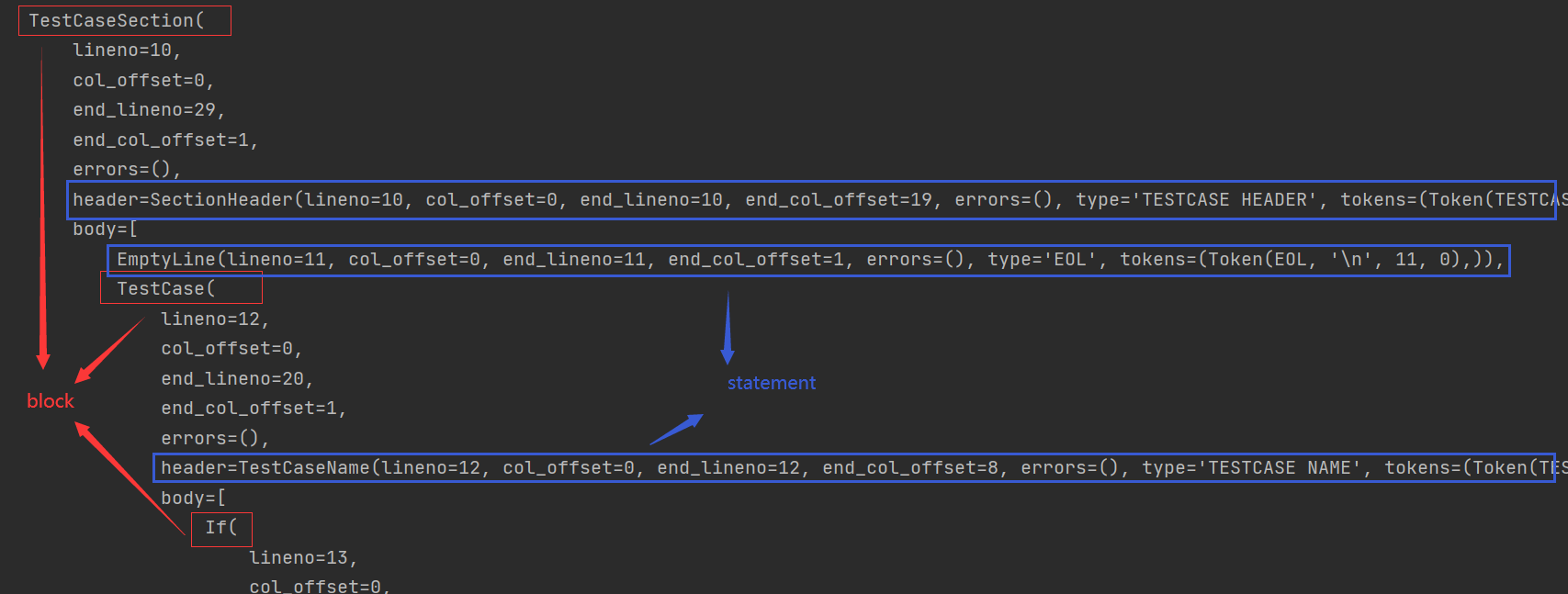
the block in the figure has TestCaseSection, TestCase and If, and the statement has SectionHeader, EmptyLine and TestCaseName. The block identifies the corresponding part in the test file, such as * * * TestCases * * * in the test file.
each block contains two attributes: header and body. The header stores the identification name, such as * * * TestCases * * *, example case, etc. The statement stores the specific token. Of course, there are other attributes, such as lineno. Other attributes indicate the corresponding position of this block or statement in the file or whether there are other errors (mainly non-existent section s or unrecognized data).
robot/parsing/parser/fileparser.py file
def parse(self, statement):
parser_class = {
Token.SETTING_HEADER: SettingSectionParser,
Token.VARIABLE_HEADER: VariableSectionParser,
Token.TESTCASE_HEADER: TestCaseSectionParser,
Token.KEYWORD_HEADER: KeywordSectionParser,
Token.COMMENT_HEADER: CommentSectionParser,
Token.ORTHOGONAL_HEADER: OrthogonalSectionParser,
Token.COMMENT: ImplicitCommentSectionParser,
Token.ERROR: ImplicitCommentSectionParser,
Token.EOL: ImplicitCommentSectionParser
}[statement.type]
parser = parser_class(statement)
self.model.sections.append(parser.model)
return parser
define and create blocks corresponding to * * * XXX * * * in the file, and then create each block to generate the corresponding block or statement in the block, such as TestCaseSectionParser, where the header stores the name of testcase and the body stores the content in * * * testcases * * *, and there may be multiple testcases, and each testcase is a block, And so on, until the specific token value appears, store the token in the statement.
due to my time, I will not describe the creation process in detail here, but for details, please refer to the document: Robot Framework Documentation
There is a section of test code on page 19 of the document. After running debugging and analysis, you can understand the detailed process:
import astpretty
from robot.api.parsing import get_model
model = get_model('example.robot')
astpretty.pprint(model)
I am a novice Xiaobai. Please include more in the blog if you can't explain it. You can also leave a message below for timely correction. Thank you.
I am MySoul and look forward to making progress with you.
Finally, the generated model example is attached:
File(
source='F:\\robot4\\demos\\if.robot',
lineno=1,
col_offset=0,
end_lineno=33,
end_col_offset=4,
errors=(),
sections=[
OrthogonalSection(
lineno=1,
col_offset=0,
end_lineno=5,
end_col_offset=1,
errors=(),
header=SectionHeader(lineno=1, col_offset=0, end_lineno=1, end_col_offset=27, errors=(), type='ORTHOGONAL_HEADER', tokens=(Token(ORTHOGONAL_HEADER, '*** Orthogonal Factors ***', 1, 0), Token(EOL, '\n', 1, 26))),
body=[
OrthogonalFactor(lineno=2, col_offset=0, end_lineno=2, end_col_offset=28, errors=(), type='NAME', tokens=(Token(NAME, 'ANIMAL', 2, 0), Token(SEPARATOR, ' ', 2, 6), Token(ARGUMENT, '["cat", "dog"]', 2, 13), Token(EOL, '\n', 2, 27))),
OrthogonalFactor(lineno=3, col_offset=0, end_lineno=3, end_col_offset=38, errors=(), type='NAME', tokens=(Token(NAME, 'COLOR', 3, 0), Token(SEPARATOR, ' ', 3, 5), Token(ARGUMENT, '["red", "green", "blue"]', 3, 13), Token(EOL, '\n', 3, 37))),
OrthogonalFactor(lineno=4, col_offset=0, end_lineno=4, end_col_offset=29, errors=(), type='NAME', tokens=(Token(NAME, 'SIZE', 4, 0), Token(SEPARATOR, ' ', 4, 4), Token(ARGUMENT, '["big", "small"]', 4, 12), Token(EOL, '\n', 4, 28))),
EmptyLine(lineno=5, col_offset=0, end_lineno=5, end_col_offset=1, errors=(), type='EOL', tokens=(Token(EOL, '\n', 5, 0),)),
],
),
VariableSection(
lineno=6,
col_offset=0,
end_lineno=9,
end_col_offset=1,
errors=(),
header=SectionHeader(lineno=6, col_offset=0, end_lineno=6, end_col_offset=18, errors=(), type='VARIABLE HEADER', tokens=(Token(VARIABLE_HEADER, '*** Variables ***', 6, 0), Token(EOL, '\n', 6, 17))),
body=[
Variable(lineno=7, col_offset=0, end_lineno=7, end_col_offset=16, errors=(), type='VARIABLE', tokens=(Token(VARIABLE, '${AGE}', 7, 0), Token(SEPARATOR, ' ', 7, 6), Token(ARGUMENT, '5', 7, 14), Token(EOL, '\n', 7, 15))),
Variable(lineno=8, col_offset=0, end_lineno=8, end_col_offset=18, errors=(), type='VARIABLE', tokens=(Token(VARIABLE, '${NAME}', 8, 0), Token(SEPARATOR, ' ', 8, 7), Token(ARGUMENT, 'dog', 8, 14), Token(EOL, '\n', 8, 17))),
EmptyLine(lineno=9, col_offset=0, end_lineno=9, end_col_offset=1, errors=(), type='EOL', tokens=(Token(EOL, '\n', 9, 0),)),
],
),
TestCaseSection(
lineno=10,
col_offset=0,
end_lineno=29,
end_col_offset=1,
errors=(),
header=SectionHeader(lineno=10, col_offset=0, end_lineno=10, end_col_offset=19, errors=(), type='TESTCASE HEADER', tokens=(Token(TESTCASE_HEADER, '*** Test Cases ***', 10, 0), Token(EOL, '\n', 10, 18))),
body=[
EmptyLine(lineno=11, col_offset=0, end_lineno=11, end_col_offset=1, errors=(), type='EOL', tokens=(Token(EOL, '\n', 11, 0),)),
TestCase(
lineno=12,
col_offset=0,
end_lineno=20,
end_col_offset=1,
errors=(),
header=TestCaseName(lineno=12, col_offset=0, end_lineno=12, end_col_offset=8, errors=(), type='TESTCASE NAME', tokens=(Token(TESTCASE_NAME, 'if case', 12, 0), Token(EOL, '\n', 12, 7))),
body=[
If(
lineno=13,
col_offset=0,
end_lineno=19,
end_col_offset=8,
errors=(),
header=IfHeader(lineno=13, col_offset=0, end_lineno=13, end_col_offset=32, errors=(), type='IF', tokens=(Token(SEPARATOR, ' ', 13, 0), Token(IF, 'IF', 13, 4), Token(SEPARATOR, ' ', 13, 6), Token(ARGUMENT, '"$${ANIMAL}" == "dog"', 13, 10), Token(EOL, '\n', 13, 31))),
body=[KeywordCall(lineno=14, col_offset=0, end_lineno=14, end_col_offset=43, errors=(), type='KEYWORD', tokens=(Token(SEPARATOR, ' ', 14, 0), Token(KEYWORD, 'Log', 14, 8), Token(SEPARATOR, ' ', 14, 11), Token(ARGUMENT, '$${SIZE}$${COLOR}$${ANIMAL}', 14, 15), Token(EOL, '\n', 14, 42)))],
orelse=If(
lineno=15,
col_offset=0,
end_lineno=18,
end_col_offset=23,
errors=(),
header=ElseIfHeader(lineno=15, col_offset=0, end_lineno=15, end_col_offset=36, errors=(), type='ELSE IF', tokens=(Token(SEPARATOR, ' ', 15, 0), Token(ELSE_IF, 'ELSE IF', 15, 4), Token(SEPARATOR, ' ', 15, 11), Token(ARGUMENT, '"$${ANIMAL}" == "cat"', 15, 14), Token(EOL, '\n', 15, 35))),
body=[KeywordCall(lineno=16, col_offset=0, end_lineno=16, end_col_offset=19, errors=(), type='KEYWORD', tokens=(Token(SEPARATOR, ' ', 16, 0), Token(KEYWORD, 'Log', 16, 8), Token(SEPARATOR, ' ', 16, 11), Token(ARGUMENT, 'mew', 16, 15), Token(EOL, '\n', 16, 18)))],
orelse=If(
lineno=17,
col_offset=0,
end_lineno=18,
end_col_offset=23,
errors=(),
header=ElseHeader(lineno=17, col_offset=0, end_lineno=17, end_col_offset=9, errors=(), type='ELSE', tokens=(Token(SEPARATOR, ' ', 17, 0), Token(ELSE, 'ELSE', 17, 4), Token(EOL, '\n', 17, 8))),
body=[KeywordCall(lineno=18, col_offset=0, end_lineno=18, end_col_offset=23, errors=(), type='KEYWORD', tokens=(Token(SEPARATOR, ' ', 18, 0), Token(KEYWORD, 'Log', 18, 8), Token(SEPARATOR, ' ', 18, 11), Token(ARGUMENT, 'unknown', 18, 15), Token(EOL, '\n', 18, 22)))],
orelse=None,
end=None,
),
end=None,
),
end=End(lineno=19, col_offset=0, end_lineno=19, end_col_offset=8, errors=(), type='END', tokens=(Token(SEPARATOR, ' ', 19, 0), Token(END, 'END', 19, 4), Token(EOL, '\n', 19, 7))),
),
EmptyLine(lineno=20, col_offset=0, end_lineno=20, end_col_offset=1, errors=(), type='EOL', tokens=(Token(EOL, '\n', 20, 0),)),
],
),
TestCase(
lineno=21,
col_offset=0,
end_lineno=29,
end_col_offset=1,
errors=(),
header=TestCaseName(lineno=21, col_offset=0, end_lineno=21, end_col_offset=9, errors=(), type='TESTCASE NAME', tokens=(Token(TESTCASE_NAME, 'if case2', 21, 0), Token(EOL, '\n', 21, 8))),
body=[
If(
lineno=22,
col_offset=0,
end_lineno=28,
end_col_offset=8,
errors=(),
header=IfHeader(lineno=22, col_offset=0, end_lineno=22, end_col_offset=32, errors=(), type='IF', tokens=(Token(SEPARATOR, ' ', 22, 0), Token(IF, 'IF', 22, 4), Token(SEPARATOR, ' ', 22, 6), Token(ARGUMENT, '"$${ANIMAL}" == "dog"', 22, 10), Token(EOL, '\n', 22, 31))),
body=[KeywordCall(lineno=23, col_offset=0, end_lineno=23, end_col_offset=20, errors=(), type='KEYWORD', tokens=(Token(SEPARATOR, ' ', 23, 0), Token(KEYWORD, 'Log', 23, 8), Token(SEPARATOR, ' ', 23, 11), Token(ARGUMENT, 'wang', 23, 15), Token(EOL, '\n', 23, 19)))],
orelse=If(
lineno=24,
col_offset=0,
end_lineno=27,
end_col_offset=23,
errors=(),
header=ElseIfHeader(lineno=24, col_offset=0, end_lineno=24, end_col_offset=36, errors=(), type='ELSE IF', tokens=(Token(SEPARATOR, ' ', 24, 0), Token(ELSE_IF, 'ELSE IF', 24, 4), Token(SEPARATOR, ' ', 24, 11), Token(ARGUMENT, '"$${ANIMAL}" == "cat"', 24, 14), Token(EOL, '\n', 24, 35))),
body=[KeywordCall(lineno=25, col_offset=0, end_lineno=25, end_col_offset=19, errors=(), type='KEYWORD', tokens=(Token(SEPARATOR, ' ', 25, 0), Token(KEYWORD, 'Log', 25, 8), Token(SEPARATOR, ' ', 25, 11), Token(ARGUMENT, 'mew', 25, 15), Token(EOL, '\n', 25, 18)))],
orelse=If(
lineno=26,
col_offset=0,
end_lineno=27,
end_col_offset=23,
errors=(),
header=ElseHeader(lineno=26, col_offset=0, end_lineno=26, end_col_offset=9, errors=(), type='ELSE', tokens=(Token(SEPARATOR, ' ', 26, 0), Token(ELSE, 'ELSE', 26, 4), Token(EOL, '\n', 26, 8))),
body=[KeywordCall(lineno=27, col_offset=0, end_lineno=27, end_col_offset=23, errors=(), type='KEYWORD', tokens=(Token(SEPARATOR, ' ', 27, 0), Token(KEYWORD, 'Log', 27, 8), Token(SEPARATOR, ' ', 27, 11), Token(ARGUMENT, 'unknown', 27, 15), Token(EOL, '\n', 27, 22)))],
orelse=None,
end=None,
),
end=None,
),
end=End(lineno=28, col_offset=0, end_lineno=28, end_col_offset=8, errors=(), type='END', tokens=(Token(SEPARATOR, ' ', 28, 0), Token(END, 'END', 28, 4), Token(EOL, '\n', 28, 7))),
),
EmptyLine(lineno=29, col_offset=0, end_lineno=29, end_col_offset=1, errors=(), type='EOL', tokens=(Token(EOL, '\n', 29, 0),)),
],
),
],
),
KeywordSection(
lineno=30,
col_offset=0,
end_lineno=33,
end_col_offset=4,
errors=(),
header=SectionHeader(lineno=30, col_offset=0, end_lineno=30, end_col_offset=17, errors=(), type='KEYWORD HEADER', tokens=(Token(KEYWORD_HEADER, '*** Keywords ***', 30, 0), Token(EOL, '\n', 30, 16))),
body=[
Keyword(
lineno=31,
col_offset=0,
end_lineno=33,
end_col_offset=4,
errors=(),
header=KeywordName(lineno=31, col_offset=0, end_lineno=31, end_col_offset=5, errors=(), type='KEYWORD NAME', tokens=(Token(KEYWORD_NAME, 'Test', 31, 0), Token(EOL, '\n', 31, 4))),
body=[
KeywordCall(lineno=32, col_offset=0, end_lineno=32, end_col_offset=21, errors=(), type='KEYWORD', tokens=(Token(SEPARATOR, ' ', 32, 0), Token(KEYWORD, 'Log', 32, 4), Token(SEPARATOR, ' ', 32, 7), Token(ARGUMENT, 'Test begin', 32, 10), Token(EOL, '\n', 32, 20))),
EmptyLine(lineno=33, col_offset=0, end_lineno=33, end_col_offset=4, errors=(), type='EOL', tokens=(Token(EOL, ' ', 33, 0),)),
],
),
],
),
],
)