Lucene (Chinese interpretation web search engine; full text search; search technology; vertical search engine;)
About Lucene
Lucene is a sub project of 4 jakarta project group of Apache Software Foundation, which is an open-source full-text search engine toolkit, but it is not a complete full-text search engine, but a full-text search engine architecture, providing a complete query engine and index engine, part of the text analysis engine (English and German, two western languages). The purpose of Lucene is to provide a simple and easy-to-use toolkit for software developers to facilitate the realization of full-text retrieval function in the target system, or to build a complete full-text retrieval engine based on this. Lucene is an open source library for full-text search and search, supported and provided by the Apache Software Foundation. Lucene provides a simple but powerful application interface that can do full-text indexing and searching. Lucene is a mature free open source tool in java development environment. In itself, Lucene is the most popular free Java information retrieval library at present and in recent years. People often mention the information retrieval library. Although it is related to the search engine, it should not be confused with the search engine.
Lucene features and advantages
Lucene, as a full-text search engine, has the following outstanding advantages:
(1) The index file format is independent of the application platform. Lucene defines a set of 8-bit byte based index file format, which enables compatible systems or applications of different platforms to share the established index file.
(2) Based on the inverted index of the traditional full-text retrieval engine, a block index is implemented, which can build a small file index for new files and improve the index speed. Then through the combination with the original index to achieve the purpose of optimization.
(3) The excellent object-oriented system architecture reduces the learning difficulty of Lucene extension and facilitates the expansion of new functions.
(4) A text analysis interface is designed which is independent of language and file format. The indexer creates the index file by accepting Token stream. The user expands the new language and file format, and only needs to implement the text analysis interface.
(5) A set of powerful query engine has been implemented by default. Users can make the system obtain powerful query ability without writing their own code. In Lucene's query implementation, Boolean operation, fuzzy search (11)) and group query are implemented by default.
Facing the existing commercial full-text search engine, Lucene also has considerable advantages.
First of all, its development source code distribution mode (in accordance with Apache Software License[12]), on this basis, programmers can not only make full use of the powerful functions provided by Lucene, but also learn in-depth and detailed the production technology of full-text search engine and the practice of object-oriented programming, and then write a better and more suitable full-text search engine based on the actual situation of the application. At this point, commercial software is far less flexible than Lucene.
Secondly, Lucene inherits the excellent advantages of open source architecture and designs a reasonable and highly extensible object-oriented architecture. Programmers can expand various functions on the basis of Lucene, such as the expansion of Chinese processing ability, from text expansion to HTML, PDF[13] and other text format processing. The functions of writing these extensions are not only uncomplicated, but also composed of Lucene properly and reasonably abstracts the program of the system equipment, and the extended functions can easily achieve the cross platform capability.
Finally, after transferring to the apache Software Foundation, with the help of the network platform of the apache Software Foundation, programmers can easily communicate with developers and other programmers, promote the sharing of resources, and even directly obtain the completed extended functions. Finally, although Lucene is written in Java language, programmers in the open source community are making unremitting efforts to implement it in various traditional languages (such as. net framework[14]). On the basis of complying with the Lucene index file format, Lucene can run on various platforms, and system administrators can choose a reasonable language according to the current platform.
Development and use
Using Solr and elastic search based on Luence
Solr: Solr is an independent enterprise search application server, which provides an API interface similar to web service. Users can submit XML file of certain format to search engine server to generate index through http request; they can also make search request through Http Get operation and get the return result in XML format. ps: https://baike.baidu.com/item/Solr/4101582?fr=aladdin
Elasticsearch: elasticsearch is a Lucene based search server. It provides a distributed multi-user full-text search engine based on RESTful web interface. Elasticsearch is developed in Java language and released as open source under Apache license. It is a popular enterprise search engine. Elasticsearch is used in cloud computing, which can achieve real-time search, stability, reliability, fast, easy to install and use. Official clients are available in Java,. NET (C), PHP, Python, Apache Groovy, Ruby, and many other languages. According to the ranking of DB engines, elastic search is the most popular enterprise search engine, followed by Apache Solr, which is also based on Lucene. ps: https://baike.baidu.com/item/elasticsearch/3411206?fr=aladdin
2. Cognitive retrieval
1, What is full text retrieval
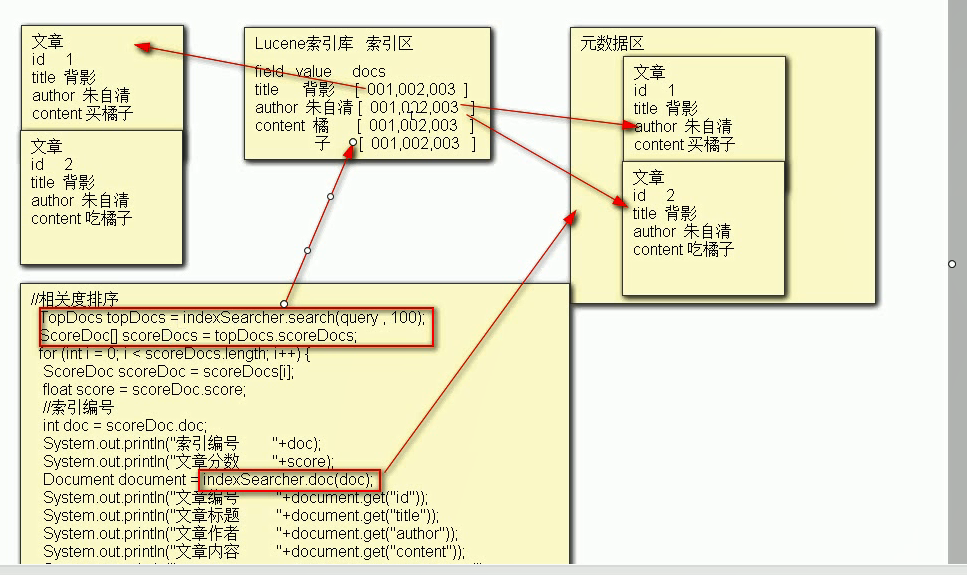
Full text retrieval is a computer program through scanning every word in the article, to establish an index for every word, indicating the number and location of the word in the article. When users query, they search according to the established index, which is similar to the process of searching words through the dictionary's search word table
Full text retrieval uses text as the retrieval object to find the text with the specified vocabulary. Comprehensive, accurate and fast is the key index to measure the Full-Text Retrieval system.
For full-text retrieval, we need to know:
1. Only text is processed.
2. Do not handle semantics.
3. English is not case sensitive when searching.
4. The result list is sorted by relevance.
2, The difference between full-text retrieval and database retrieval
Full text retrieval is different from SQL query of database. (they solve different problems and solutions, so they should not be compared.). The search in the database is to use SQL, such as SELECT * FROM t WHERE content like '% ant%'. There will be the following problems:
1. Matching effect: if you search ant, you will find planning. This will find a lot of irrelevant information.
2. Relevance ranking: the results are not sorted by relevance. I don't know which page I want the results to be on. When we use Baidu search, we usually don't need to turn pages. Why? Because Baidu did correlation ranking: score each result. The more it meets the search criteria, the higher the score. It's called correlation score. The result list will be arranged according to the score from high to low. So the result on page 1 is the result we want most.
3. The speed of full-text search is much faster than that of SQL like search. This is caused by different query methods. For example, to look up a dictionary: like in a database is to turn page by page, line by line, while full-text search is to look up the directory first, get the page number of the result, and then turn directly to this page.
3, Use scenarios of full-text retrieval
We use Lucene to search in the website, that is, search resources in a system. Such as BBS (Forum), blog (blog) in the article search, online store in the product search. Projects using Lucene include Eclipse, Zhilian recruitment, tmall, Jingdong, etc. Generally, we do not search resources on the Internet, because it is not easy to access and manage massive resources (except for companies with professional search direction)
III. Development and use
3.1 jar package
lucene has 7 packages to import: analysis, document, index, queryParser, search, store, util
3.2 develop my first Lucene program
Creating an index is (adding)


package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class CreatLuence {
public static void main(String[] args) throws IOException {
File path = new File("D:\\index");//Used to create folder object construction parameter path
/**
* Get (create) index writer object (indexWriter)
* Directory Index library
*/
Directory directory = FSDirectory.open(path);//Abstract parent class can only be created with child class
Version version = Version.LUCENE_44;//One is the version number of Luence
Analyzer analyzer = new StandardAnalyzer(version);//Participator type here is standard participator StandardAnalyzer
IndexWriterConfig config = new IndexWriterConfig(version,analyzer);//Two parameters one version one
/**
* The first parameter gets where the writer writes the index
* The second configuration initializes the configuration information in Config
* config There are two parameters: one is the version number of Luence, and the other is
* One is that there are many types of word breakers, such as standard word breakers, etc
*/
IndexWriter indexwriter = new IndexWriter(directory,config);
/**
* Write format only supports Document format
*/
Document document = new Document();
/**
* It will be found that the construction method of IndexableField's implementation class has three parameters
* 1.It's data key
* 2.It's value
* 3.Is it put into the specified source data area store (save store)
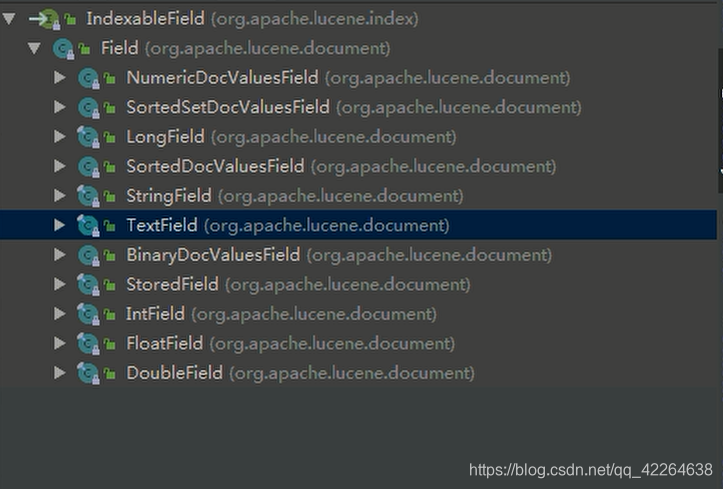
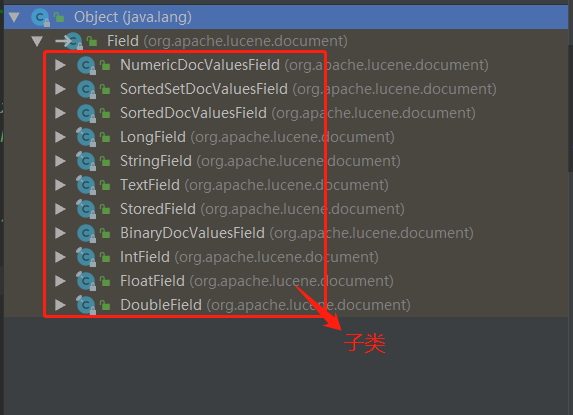
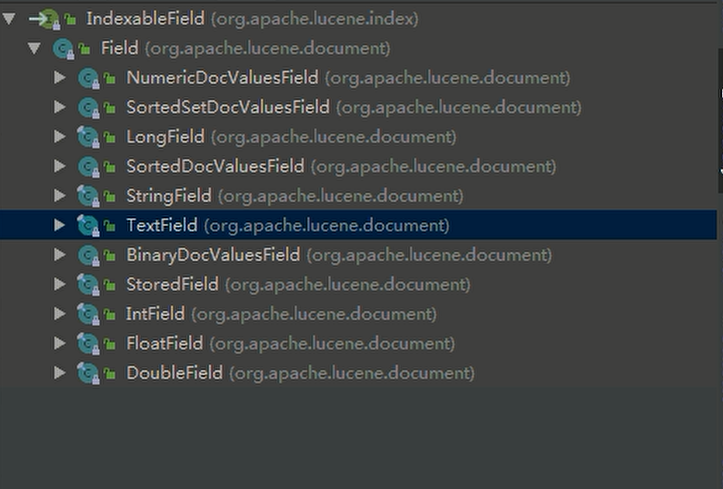
* lucene The Field object in is the specific Field that luene creates the index,
* Field It mainly includes the following three attributes: name (field name),
* value(The value corresponding to the field),
* IndexableFieldType(Configuration information of this field, whether to store, whether to segment, etc.),
* See the following analysis for the attribute details of common Field subclasses
*/
IndexableField field1 = new IntField("id",1,Store.YES);//Interfaces can only be implemented with different types of implementation classes
 field2 = new StringField("title", "no open source", Store.YES ); / / interfaces can only use different implementation classes for different types of implementation classes
IndexableField field3 = new TextField("content","No auction",Store.YES);//Interfaces can only be implemented with different types of implementation classes
document.add(field1);//It must call the methods encapsulated in the class
document.add(field2);//It must call the methods encapsulated in the class
document.add(field3);//It must call the methods encapsulated in the class
/**
* Next, when the Document has a writer, it must use the writer to write the Document to the index to create the index
*/
indexwriter.addDocument(document);//Write specified file to server specified storage index location
/**
* Release resource close indexwriter index writer object
*/
if(indexwriter!=null){
indexwriter.close();
}
/**
* It's time to test
* Test idea run to see if there is automatic index file in the specified path
*/
}
}
Implementation class or subclass of the relevant interface (or abstract class) used
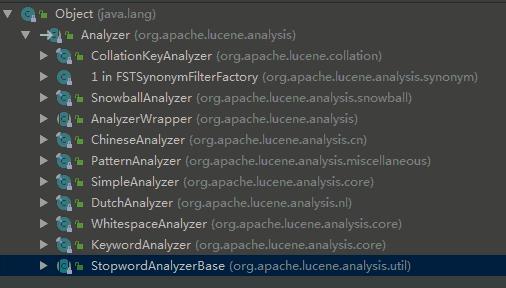
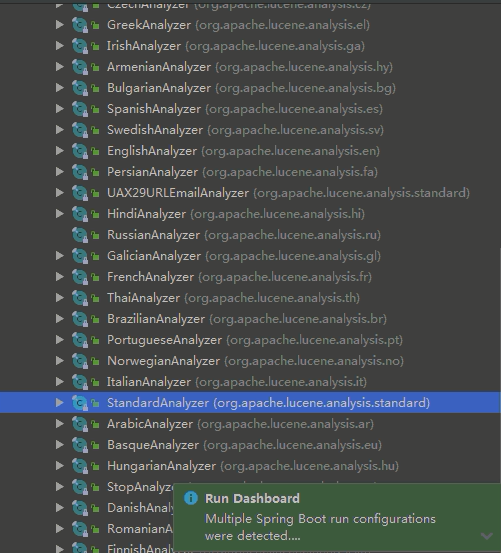
Index searcher

package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class RederLuence {
/** be careful:
* Eight basic data types + String type
* Text The regular word segmentation of the standard word segmentation device of type word segmentation
*/
public static void main(String[] args) throws IOException {
File path = new File("D:\\index");//Index writer write location
Directory directory = FSDirectory.open(path);//An abstract parent class can only create a read location with a child class
/**
* Just finished indexing
* Now, if we use it, we will create the indexwriter of index reference to write the indexer
* Now the reader should read the indexer
*/
IndexReader indexreader = DirectoryReader.open(directory);//Abstract classes are created by abstract class methods
/**
* Create index search object
*/
IndexSearcher indexSearcher = new IndexSearcher(indexreader);
/**
* fld Property column
* text What does the text look up
*/
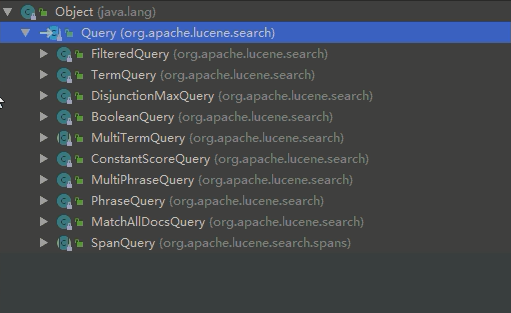
Query query = new TermQuery(new Term("title", "No Kaisen"));//Abstract class (Query query) subclass (TermQuery word Query)
int n=100;//
/**
* topDocs The result of the query is to sort the correlation degree of TopDocs (index area)
*/
TopDocs topDocs = indexSearcher.search(query, n);//Two parameters: the first is based on what search (search criteria) and the second is based on how many
/**
* I want to show you the methods in the topDocs tool class that I just query the results for correlation sorting
*/
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//Check the source code and call this method to return the array
/**
* scoreDoc There is also an object that stores information about the index area of this article, such as index number, index score
* scoreDoc.doc Is the index number of the index area
*/
for (ScoreDoc scoreDoc : scoreDocs) {
int id = scoreDoc.doc;
float score = scoreDoc.score;//Article rating
System.out.println(id);
System.out.println(score);//Article rating
Document doc = indexSearcher.doc(id);//Search in metadata area according to article index number
System.out.println(doc.get("id"));//Metadata area article id
System.out.println(doc.get("title"));//Metadata area article title
System.out.println(doc.get("content"));//Metadata area article content
}
}
}
Information of relevant subclasses or implementation classes or classes used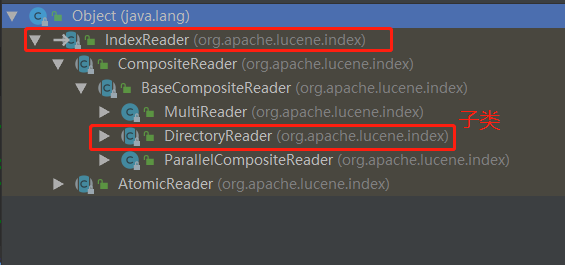
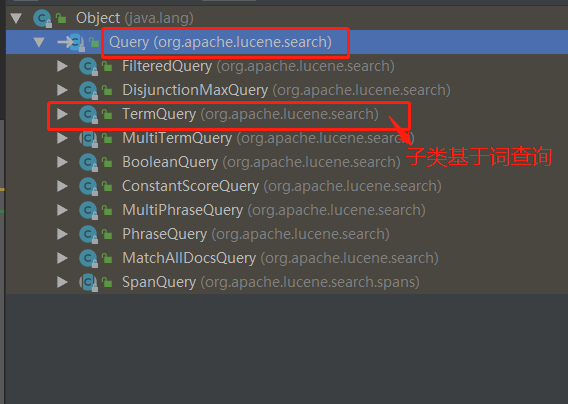
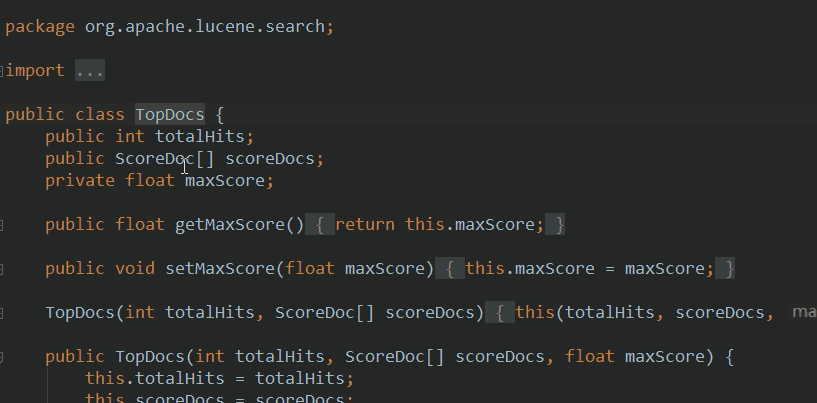
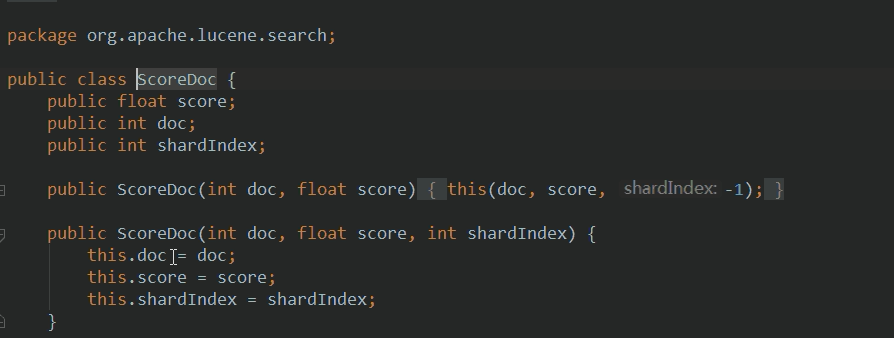
be careful:
*Eight basic data types + String type
*Regular word segmentation of standard word segmentation device of Text type
Delete index
! [insert picture description here]( https://img-blog.csdnimg.cn/20190924210637137.png)
package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class DeleteLuence {
public static void main(String[] args) {
/**
* The first parameter gets where the writer writes the index
* The second configuration initializes the configuration information in Config
* config There are two parameters: one is the version number of Luence, and the other is
* One is that there are many types of word breakers, such as standard word breakers, etc
*/
IndexWriter indexwriter = null;
try {
File path = new File("D:\\index");//Used to create folder object construction parameter path
/**
* Get (create) index writer object (indexWriter)
* Directory Index library
*/
Directory directory = FSDirectory.open(path);//Abstract parent class can only be created with child class
Version version = Version.LUCENE_44;//One is the version number of Luence
Analyzer analyzer = new StandardAnalyzer(version);//Participator type here is standard participator StandardAnalyzer
IndexWriterConfig config = new IndexWriterConfig(version, analyzer);//Two parameters one version one
indexwriter = new IndexWriter(directory, config);
/**
* Term Word
* fld Property column
* text What does the text look up
*/
//If we delete only one word, we will find that it is not what we want to query according to others
indexwriter.deleteDocuments(new Term("title", "No Kaisen"));
indexwriter.deleteDocuments(new Term("id", "1"));
indexwriter.deleteDocuments(new Term("content", "No auction"));
indexwriter.commit();
} catch (Exception e) {
e.printStackTrace();
try {
indexwriter.rollback();
} catch (IOException e1) {
e1.printStackTrace();
throw new RuntimeException(e1);
}
throw new RuntimeException(e);
}finally{
if(indexwriter!=null){
try {
indexwriter.close();
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
}
Modify index
package com.MyFirstLuence.xql.Test;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class UpdateLuence {
//lucene update delete before add
public static void main(String[] args) {
/**
* The first parameter gets where the writer writes the index
* The second configuration initializes the configuration information in Config
* config There are two parameters: one is the version number of Luence, and the other is
* One is that there are many types of word breakers, such as standard word breakers, etc
*/
IndexWriter indexwriter = null;
try {
File path = new File("D:\\index");//Used to create folder object construction parameter path
/**
* Get (create) index writer object (indexWriter)
* Directory Index library
*/
Directory directory = FSDirectory.open(path);//Abstract parent class can only be created with child class
Version version = Version.LUCENE_44;//One is the version number of Luence
Analyzer analyzer = new StandardAnalyzer(version);//Participator type here is standard participator StandardAnalyzer
IndexWriterConfig config = new IndexWriterConfig(version, analyzer);//Two parameters one version one
indexwriter = new IndexWriter(directory, config);
Document document = new Document();
/**
* It will be found that the construction method of IndexableField's implementation class has three parameters
* 1.It's data key
* 2.It's value
* 3.Is it put into the specified source data area store (save store)
* lucene The Field object in is the specific Field that luene creates the index,
* Field It mainly includes the following three attributes: name (field name),
* value(The value corresponding to the field),
* IndexableFieldType(Configuration information of this field, whether to store, whether to segment, etc.),
* See the following analysis for the attribute details of common Field subclasses
*/
IndexableField field1 = new IntField("id",1,Store.YES);//Interfaces can only be implemented with different types of implementation classes
IndexableField field2 = new StringField("title","Kaisen",Store.YES);//Interfaces can only be implemented with different types of implementation classes
IndexableField field3 = new TextField("content","No auction ssssssss",Store.YES);//Interfaces can only be implemented with different types of implementation classes
document.add(field1);//It must call the methods encapsulated in the class
document.add(field2);//It must call the methods encapsulated in the class
document.add(field3);//It must call the methods encapsulated in the class
/**
* Term Word
* fld Property column
* text At this time, this parameter is a new value
* Parameter document which document format
*/
//lucene update delete before add
indexwriter.updateDocument(new Term("id","4"), document);
indexwriter.commit();
} catch (Exception e) {
e.printStackTrace();
try {
indexwriter.rollback();
} catch (IOException e1) {
e1.printStackTrace();
throw new RuntimeException(e1);
}
throw new RuntimeException(e);
}finally{
if(indexwriter!=null){
try {
indexwriter.close();
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
}
be careful:
When Lucene updates, it will delete the qualified data and create a piece of data