When deploying Kubernetes, we often find such a scenario: the official strongly recommends closing the Swap space during environment initialization. For example, when performing K8S related operations, the following prompts are given:
Running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false
Or throw the following error message:
[ERROR Swap]: running with swap on is not supported. Please disable swap
Of course, in fact, not only Kubernetes, but also other components, such as Hadoop, ES and other clusters, it is also not recommended to turn on Swap.
So, what is Swap?
Generally speaking, Swap Space is an area opened on the operating system disk. This area can be a partition, a file, or a combination of them. Based on its scene characteristics, that is, when the physical memory of the operating system is insufficient, the Linux system will synchronize the infrequently accessed data in the memory to Swap, so that the system has more physical memory to serve each process; On the contrary, when the operating system needs to access the content stored on the Swap, it loads the data on the Swap into memory, which is what we often call Swap Out and Swap In.
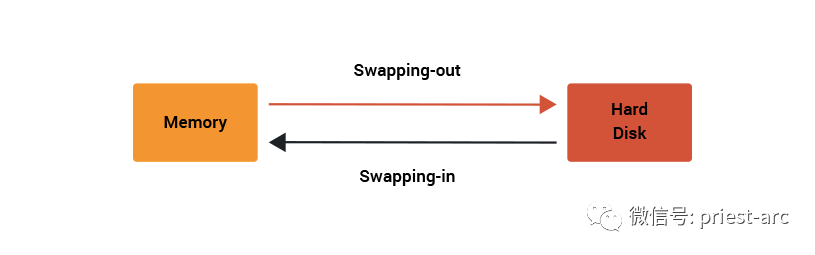
Refer to the following schematic diagram for the related activity status association of Swap In and Swap Out:
The size and usage of the Swap partition can usually be viewed with the free -m command line, as shown below:
[administrator@JavaLangOutOfMemory ~ %] free -m
total used free shared buffers cached
Mem: 32167 2055 20785 0 28 296
-/+ buffers/cache: 530 470
Swap: 0 0 0Based on the above query results, the Swap Size is 0 M, indicating that the current operating system does not use Swap partitions. In addition, we can also use the Swap command to view the current Swap related information: for example, the Swap space is Swap Partition, Swap Size, usage and other details, as shown below:
[administrator@JavaLangOutOfMemory ~ %] swapon -s
Based on the current operating system properties, there are two forms of swap partitions in Linux: Swap Disk and Swap File. Swap Disk is a block device specially used for swap, which is provided to the swap mechanism as a raw device; The latter is a specific file stored on the file system. Its implementation depends on different file systems and will vary. We can refer to the following schematic diagram, as shown below:
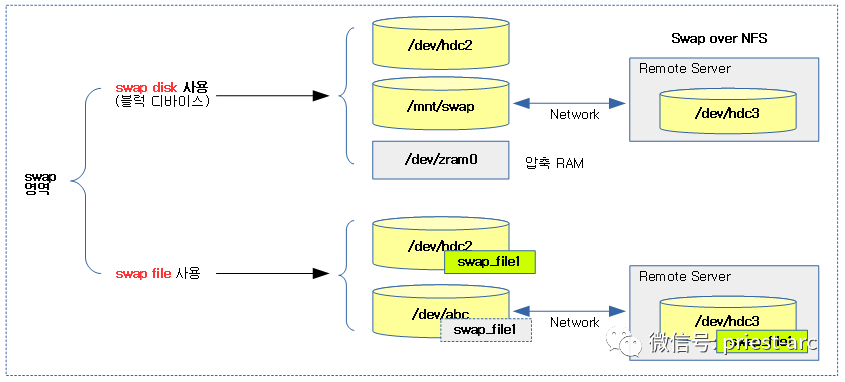
(this figure is derived from: http://jake.dothome.co.kr/wp-content/uploads/2019/10/swap-8a.png )
For the above two different Swap partitions, we can convert a Swap Disk or Swap File to the format of the Swap partition through the mkswap command. The corresponding Swap partition can then be turned on or off through the Swapon and Swapoff commands. You can view the status of Swap partitions in use through cat /proc/swaps or Swap on - S. For the data structure of Swap, in the Linux operating system, Swap is used in the kernel_ info_ The struct structure manages the Swap partition as follows:
/*
* The in-memory structure used to track swap areas.
*/
struct swap_info_struct {
unsigned long flags; /* SWP_USED etc: see above */
signed short prio; /* swap priority of this type */
struct plist_node list; /* entry in swap_active_head */
signed char type; /* strange name for an index */
unsigned int max; /* extent of the swap_map */
unsigned char *swap_map; /* vmalloc'ed array of usage counts */
struct swap_cluster_info *cluster_info; /* cluster info. Only for SSD */
struct swap_cluster_list free_clusters; /* free clusters list */
unsigned int lowest_bit; /* index of first free in swap_map */
unsigned int highest_bit; /* index of last free in swap_map */
unsigned int pages; /* total of usable pages of swap */
unsigned int inuse_pages; /* number of those currently in use */
unsigned int cluster_next; /* likely index for next allocation */
unsigned int cluster_nr; /* countdown to next cluster search */
struct percpu_cluster __percpu *percpu_cluster; /* per cpu's swap location */
struct swap_extent *curr_swap_extent;
struct swap_extent first_swap_extent;
struct block_device *bdev; /* swap device or bdev of swap file */
struct file *swap_file; /* seldom referenced */
unsigned int old_block_size; /* seldom referenced */
#ifdef CONFIG_FRONTSWAP
unsigned long *frontswap_map; /* frontswap in-use, one bit per page */
atomic_t frontswap_pages; /* frontswap pages in-use counter */
#endif
spinlock_t lock; /*
* protect map scan related fields like
* swap_map, lowest_bit, highest_bit,
* inuse_pages, cluster_next,
* cluster_nr, lowest_alloc,
* highest_alloc, free/discard cluster
* list. other fields are only changed
* at swapon/swapoff, so are protected
* by swap_lock. changing flags need
* hold this lock and swap_lock. If
* both locks need hold, hold swap_lock
* first.
*/
spinlock_t cont_lock; /*
* protect swap count continuation page
* list.
*/
struct work_struct discard_work; /* discard worker */
struct swap_cluster_list discard_clusters; /* discard clusters list */
struct plist_node avail_lists[0]; /*
* entries in swap_avail_heads, one
* entry per node.
* Must be last as the number of the
* array is nr_node_ids, which is not
* a fixed value so have to allocate
* dynamically.
* And it has to be an array so that
* plist_for_each_* can work.
*/
};As shown above, a swap_info_struct corresponds to a Swap partition. Within the Swap partition, multiple Swap slots will be divided by Page size, and at the same time through swap_map records the usage of each Slot. 0 means idle, and greater than 0 means the number of processes in which the Slot is mapped.
Here, from the perspective of source code, let's briefly understand the relevant workflow of Swap In and Swap Out, as follows.
Swap In
The entrance of Swap In is do_swap_page, because the physical page is recycled, when the process accesses a virtual address again, it will generate a page missing interrupt and finally enter do_swap_page, a new page will be reassigned in this function, and then the data corresponding to this virtual address will be read back from the Swap partition. Part of the code analysis is as follows:
int do_swap_page(struct vm_fault *vmf)
{
......
entry = pte_to_swp_entry(vmf->orig_pte); //Get swap entry from pte, that is, orig_pte cast type to swp_entry_t type
......
page = lookup_swap_cache(entry, vma, vmf->address); //Find the page corresponding to the entry in the swap cache
swapcache = page;
if (!page) { //If it is not found in the swap cache, enter the if code segment
struct swap_info_struct *si = swp_swap_info(entry); //Get swap partition descriptor
......
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE, vmf); //Allocate a page, read the data from the swap partition, fill it in the page, and then put the page into the swap cache for caching. At this time, the PG of the page_ When the lock is set, you need to wait for the IO read operation to complete before clearing, that is, the page is locked. If others want to lock the page, you need to wait for the page to be unlock ed
swapcache = page;
......
}
locked = lock_page_or_retry(page, vma->vm_mm, vmf->flags); //At this time, if you try to lock the page, 1 will be returned if successful, and 0 will be returned if failed
....
if (!locked) { //Obviously, the return is 0 at this time, that is, the IO read operation of page is still not completed.
ret |= VM_FAULT_RETRY; //Set the return flag to retry
goto out_release; //Return to retry do_swap_page, but trying do again_ swap_ Page, you can get the page directly from the page cache, and there is no need to read data from the swap partition
}
//When the program arrives, it indicates that the IO read operation of the page has been completed
......
pte = mk_pte(page, vmf->vma_page_prot); //The pte is generated according to the physical address of the page and the protection bit of the page
if ((vmf->flags & FAULT_FLAG_WRITE) && reuse_swap_page(page, NULL)) { //If the missing page is interrupted as a write access exception and only one process uses the page, delete the page from the swap cache and clear the corresponding data in the swap partition. Reuse will be analyzed below_ swap_ Page function
pte = maybe_mkwrite(pte_mkdirty(pte), vmf->vma_flags); //Set the writable protection bit and pte in PTE_DIRTY bit
vmf->flags &= ~FAULT_FLAG_WRITE;
ret |= VM_FAULT_WRITE;
exclusive = RMAP_EXCLUSIVE;
}
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte); Update the corresponding virtual address pte
......
do_page_add_anon_rmap(page, vma, vmf->address, exclusive); //Create a new anonymous mapping
mem_cgroup_commit_charge(page, memcg, true, false);
activate_page(page); //Put the page into the active anonymous LRU linked list
......
swap_free(entry); //Update the counter of the page slot, that is, minus one. If the counter is equal to 0, it means that all the people who need the storage block data have been read back to memory, and the page is not in the swap cache, then directly clear the storage block data, that is, recycle the page slot to free up more swap space
if (mem_cgroup_swap_full(page) ||
(vmf->vma_flags & VM_LOCKED) || PageMlocked(page))
try_to_free_swap(page); //If the swap partition is full, an attempt is made to recycle the useless page slots
unlock_page(page); //Unlock PG_lock
......
out:
return ret;
......
}Swap Out
The entrance to Swap Out is in shrink_page_list, this function is for Page_ The memory in the list is processed in turn to reclaim the memory that meets the conditions, that is, the Swap Out action occurs when the system needs to reclaim physical memory. The first time you Shrink, the memory Page will pass add_to_swap is allocated to the corresponding Swap Slot, set as a dirty Page and write back. Finally, the Page is added to the Swap Cache without recycling. During the second Shrink, if the dirty Page has been written back, the Page will be deleted from the Swap Cache and recycled. Part of the code analysis is as follows:
static unsigned long shrink_page_list(struct list_head *page_list,
struct pglist_data *pgdat,
struct scan_control *sc,
enum ttu_flags ttu_flags,
struct reclaim_stat *stat,
bool force_reclaim)
{
LIST_HEAD(ret_pages); //Initialize the returned linked list, that is, put the pages that cannot be recycled in this shrink into the linked list
LIST_HEAD(free_pages); //Initialize the recycled linked list, that is, put the pages that can be recycled in this shrink into the linked list
...
while (!list_empty(page_list)) {
...
page = lru_to_page(page_list);
list_del(&page->lru); // From page_ Take a page from the list, page_list page linked list to be recycled
if (!trylock_page(page)) //First judge whether other processes are using the page. If not, set PG_lock and return 1. This flag is mostly used for io reading, but in most cases, no other process is using this page during the first shrink, so go on
goto keep;
may_enter_fs = (sc->gfp_mask & __GFP_FS) ||
(PageSwapCache(page) && (sc->gfp_mask & __GFP_IO));
if (PageAnon(page) && PageSwapBacked(page)) { //Judge whether it is an anonymous page and not a lazyfree page. Obviously, this condition is met
if (!PageSwapCache(page)) { //Judge whether the anonymous page is a swapcache, that is, through the PG of the page_ The flag of the swapcache is used to determine whether the page is shrunk for the first time, so whether to enter the process in the if
...
if (!add_to_swap(page)) //Create an SWP for this anonymous page_ entry_ t. And store it in the page - > private variable, put the page into the swap cache, and set the PG of the page_ Swapcache and PG_dirty's flag and update swap_ info_ The page slot information of struct, which is the interface function to swap core and swap cache, will be analyzed below
{
...
goto activate_locked; // Return after failure
}
...
/* Adding to swap updated mapping */
mapping = page_mapping(page); // According to SWP in page_ entry_ T get the corresponding swapper_spaces[type][offset], here you can review the swap in the data structure chapter_ Introduction to spaces.
}
} else if (unlikely(PageTransHuge(page))) {
/* Split file THP */
if (split_huge_page_to_list(page, page_list))
goto keep_locked;
}
/*
* The page is mapped into the page tables of one or more
* processes. Try to unmap it here.
*/
if (page_mapped(page)) {
enum ttu_flags flags = ttu_flags | TTU_BATCH_FLUSH;
if (unlikely(PageTransHuge(page)))
flags |= TTU_SPLIT_HUGE_PMD;
if (!try_to_unmap(page, flags, sc->target_vma)) { // Unmap, that is, unmap the virtual address of the upper layer, and modify the pte to make its value equal to page - > private, that is, swp_entry_t variable. When swapin, the pte mandatory type is directly converted to SWP_ entry_ The value of type T, you can get the entry.
nr_unmap_fail++;
goto activate_locked;
}
}
if (PageDirty(page)) { //Due to add_ to_ The swap function finally sets the page as a dirty page, so the if is established and enters the if
...
/*
* Page is dirty. Flush the TLB if a writable entry
* potentially exists to avoid CPU writes after IO
* starts and then write it out here.
*/
try_to_unmap_flush_dirty();
switch (pageout(page, mapping, sc)) { // Initiate io write back request and set the flag of the page to PG_writeback, and then put PG_dirty clear
......
case PAGE_SUCCESS: //If the request is successful, return PAGE_SUCCESS
if (PageWriteback(page)) //If this condition holds, jump to keep
goto keep;
......
}
}
......
keep:
list_add(&page->lru, &ret_pages); //Put the page in ret_ In the pages linked list, all pages in the linked list will be put into the recycling lru linked list when returning, that is, the pages will not be recycled
VM_BUG_ON_PAGE(PageLRU(page) || PageUnevictable(page), page);
}
......
list_splice(&ret_pages, page_list);
......
return nr_reclaimed;
}
Let's take another look add_to_swap Function implementation
int add_to_swap(struct page *page)
{
swp_entry_t entry;
int err;
......
entry = get_swap_page(page); //Assign an SWP to the page_ entry_ t. And update swap_ info_ Slot information of struct
if (!entry.val)
return 0;
......
err = add_to_swap_cache(page, entry,
__GFP_HIGH|__GFP_NOMEMALLOC|__GFP_NOWARN); //Add the page to the swap cache and set PG_ Swap cache, save the entry to the page - > private variable, and pass it along with the page
/* -ENOMEM radix-tree allocation failure */
set_page_dirty(page); // Set the page as dirty
return 1;
......
}
The above only shows part of the code. The related function analysis in the code will be described in subsequent articles. Please pay attention.
Next, let's think about what environment and scenario the operating system will use Swap Space? In fact, in essence, Linux is controlled by a parameter Swappiness. Of course, it also involves complex algorithms.
Swappiness, a Linux kernel parameter, controls the relative weight of swapping out runtime memory. The swappiness parameter value can be set between 0 and 100. Low parameter values will make the system kernel avoid using Swap as much as possible, and higher parameter values will make the kernel use Swap Space more. The default value is 60 (refer to network resources: start using Swap Space when the remaining physical memory is less than 40%). For most operating systems, setting to 100 may affect overall performance, while setting to a lower value (or even 0) may reduce response latency. For details, please refer to the following:
vm.swappiness = 0 only in the case of insufficient memory, when the remaining free memory is lower than VM min_ free_ Use swap space when Kbytes limit.
vm.swappiness = 1 kernel version v3 5 and above, Red Hat kernel version 2.6 32-303 and above, perform the minimum exchange without disabling the exchange.
vm.swappiness = 10 this value is recommended to improve performance when the system has enough memory.
vm.swappiness = 60 default
vm.swappiness = 100 kernel will actively use swap space.
For kernel version v3 5 and above, Red Hat kernel version 2.6 32-303 and above. In most cases, it may be better to set to 1, and 0 is suitable for ideal cases (it is likelybetter to use 1 for cases where 0 used to be optimal). The details are as follows:
[administrator@JavaLangOutOfMemory ~ %] cat /proc/sys/vm/swappiness 30
The adjustment of Swappiness parameters mainly includes the following strategies: Based on temporary adjustment and permanent adjustment, the command line operations for temporary policies are as follows:
[administrator@JavaLangOutOfMemory ~ %] echo 10 > /proc/sys/vm/swappiness
Or the following command line operation:
[administrator@JavaLangOutOfMemory ~ %] sysctl vm.swappiness=10
For permanent adjustment policies, in the configuration file / etc / sysctl Modify VM. Conf The value of the swappiness parameter, and then restart the system. The command line operation is as follows:
[administrator@JavaLangOutOfMemory ~ %] echo 'vm.swappiness=10' >>/etc/sysctl.conf
Abandon the demands of the operating system kernel level. In the actual business scenario, based on the use of Swap Space, it mainly depends on the following levels, as shown below:
1. Goal based orientation
In some specific business scenarios, we prefer memory acceleration. For example, in Mysql memory index, Redis and other scenarios, we avoid using Swap as much as possible.
As mentioned earlier, not only Hadoop, but most Java applications, including ES, strongly recommend turning off Swap. After all, such scenarios are related to the GC of the JVM. When the virtual machine performs GC, it will traverse all the allocated heap memory. If this part of memory is swept out, it will have a great impact on disk IO.
2. Result based optimization
Under the requirements of some specific business scenarios, in the cluster environment we build, we don't want any jitter, increased delay and response delay. Based on the inherent horizontal scalability of the system, we can strictly avoid using Swap.
In fact, in a sense, Swap can be considered as an optimization for the previous small memory, but now almost most hosts have sufficient memory capacity, so it can be turned on in some specific business scenarios.
So why disable Swap for Kubernetes? Of course, this strategy is associated with its underlying principles. Based on its starting point, the purpose of Kubernetes cloud native implementation is to tightly package running instances to as close as 100%. All deployment and running environments should be limited to a controllable space with CPU and memory. So if the scheduler sends a Pod to a node machine, it should not use Swap. After all, if you turn on Swap, it will slow down. Therefore, turning off Swap is mainly for performance reasons. Of course, in addition, from the perspective of resource-saving scenarios, for example, the maximum number of containers can be run as much as possible.