First knowledge of distributed lock (II): analysis of ZooKeeper distributed lock principle and practical cases
It's not easy to write. Praise and collect attention so that you can see it next time. Thank you for your support ~
Last time we talked about using Mysql database to realize distributed locking. It is relatively simple to implement.
However, the defects are also relatively obvious. On the one hand, there is no expiration mechanism for SQL lock. If it is not kept highly available, the thread will deadlock if it does not release the lock.
On the other hand, because the performance of SQL itself is not high, the use of SQL locking will greatly drag down the performance of the whole system.
Based on the above points, in this issue, we will expand along Zookeeper to introduce how to use Zookeeper to realize corresponding distributed locks.

Introduction to Zookeeper
Before starting our article, let's introduce what Zookeeper is. Let's first look at Baidu Encyclopedia's definition of Zookeeper.
ZooKeeper is a Distributed Open source Distributed application Coordination services, yes Google Chubby one Open Source The implementation of is Hadoop and Hbase Important components of. It is a software that provides consistency services for distributed applications. Its functions include configuration maintenance, domain name service, distributed synchronization, group service and so on.
The goal of ZooKeeper is to encapsulate complex and error prone key services and provide users with simple and easy-to-use interfaces and systems with efficient performance and stable functions.
ZooKeeper contains a simple set of primitives that provide interfaces between Java and C.
In the code version of ZooKeeper, interfaces of distributed exclusive lock, election and queue are provided. The code is in $zookeeper_home\src\recipes. There are distributed locks and queues Java And C versions, only Java version.

To put it in plain terms, Zookeeper is essentially like a file management system. It manages and listens to multiple nodes (Znode) in a way similar to file path, and judges the current state of the machine on each node (whether it is down, disconnected, etc.), so as to achieve distributed collaborative operation.
The following is a brief description of ZK management function.
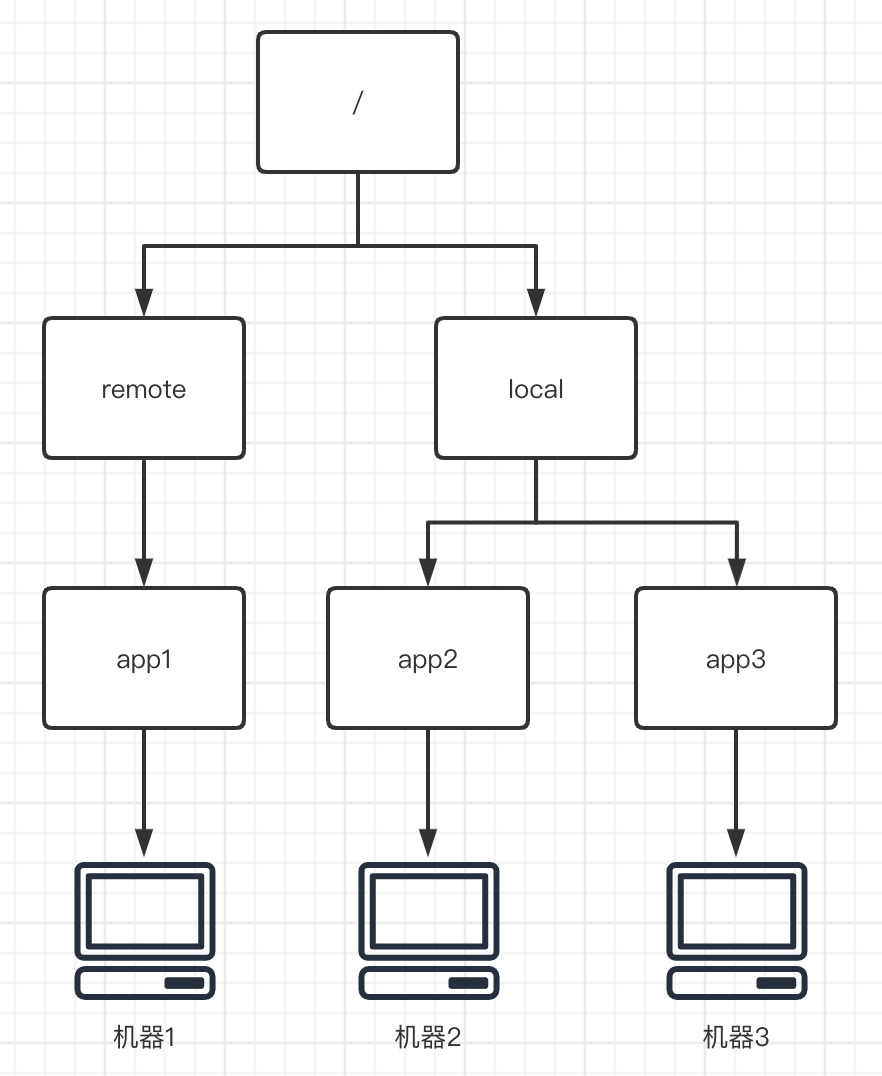
Four kinds of nodes
When it comes to ZK, we have to mention the four basic nodes of ZK, which are:
- PERSISTENT node: this node is PERSISTENT and will not be deleted because the client is disconnected.
- PERSISTENT_SEQUENTIAL: this node will persist in a certain order and will not be deleted because the client is disconnected.
- EPHEMERAL: this node will be deleted after the client disconnects.
- EPHEMERAL_SEQUENTIAL: the node will be deleted after the client is disconnected; Will be arranged in a certain order.
These four nodes constitute the most basic ZK functions.
event listeners
In addition to the four nodes, we have to mention the Watcher (event listener) implemented by ZK itself, which is a very important feature in ZooKeeper.
ZooKeeper allows users to register some watchers on the specified node, and when some specific events are triggered, the ZooKeeper server will notify the interested clients of the events. This mechanism is an important feature of ZooKeeper's implementation of distributed coordination services.
At the same time, this mechanism is also one of the important dependency characteristics of distributed lock implementation.
Principle analysis
Locking principle:
ZK's implementation of distributed locks mainly depends on the above two mechanisms:
1. Temporary sequence node.
2. Event listening.
First, when each program needs to lock, it will need a corresponding locking path (here we assume it is "/ curatorLock"), and a new temporary node node1 will be generated in ZK according to this locking path.
Assume that the newly generated temporary node a is the first temporary node. Node node1, as the first program to apply for lock, naturally has the right to lock, so it is a success.
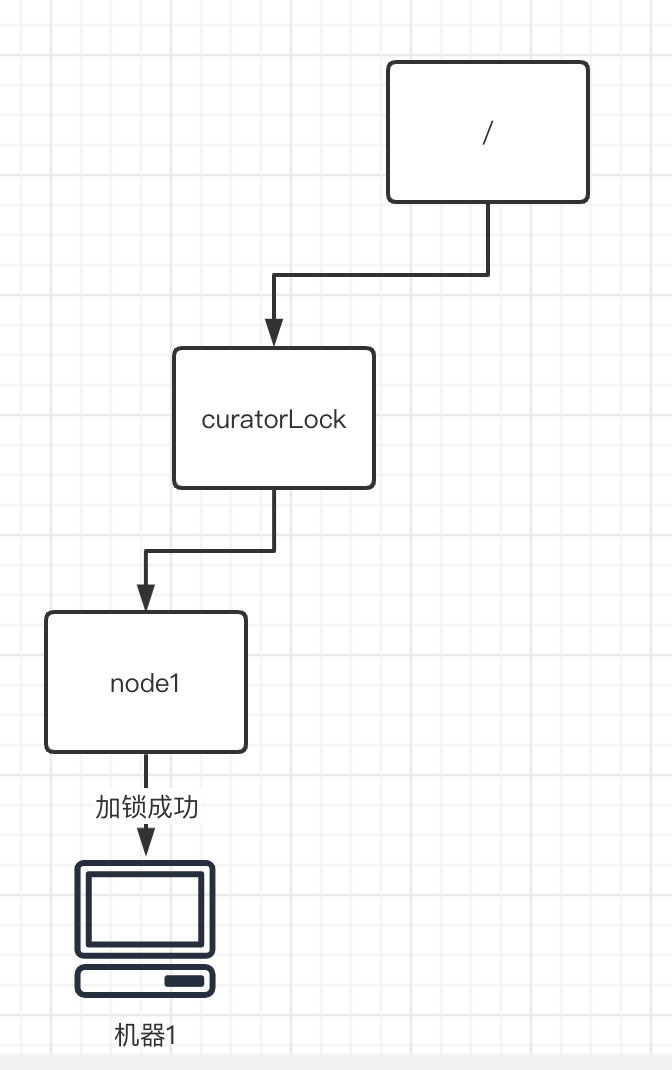
However, if there are other nodes in front of the current node node1, lock it. At this time, it is obvious that we cannot obtain the lock, so we can only use the event listening mechanism to listen to the previous node until the previous node releases the lock.
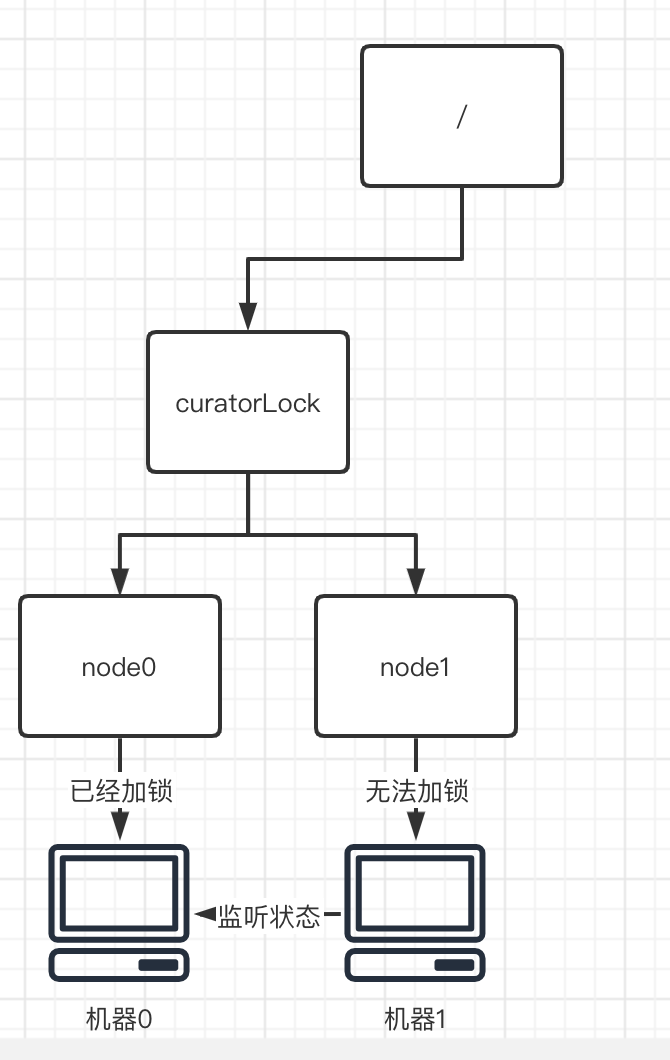
The case of three or more nodes is similar. The whole logic of locking is not complicated.
Unlocking principle:
The main operation of unlocking is opposite to locking. First, you need to delete all the monitors currently monitoring yourself, so as to tell other machines, "I've run out of locks ~". So that other machines can get it again, or reset the listening object and listening status.
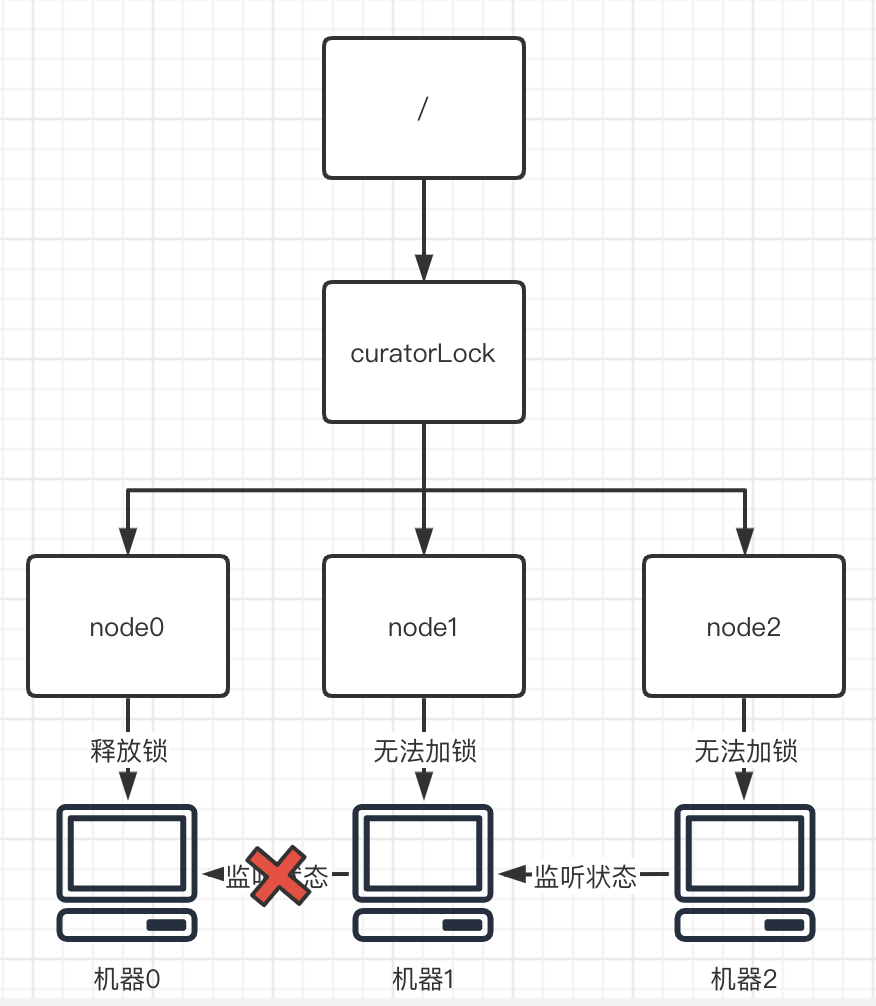
Then, the node that obtains the lock (node0) will delete itself, so that other nodes can become the first node and lock.
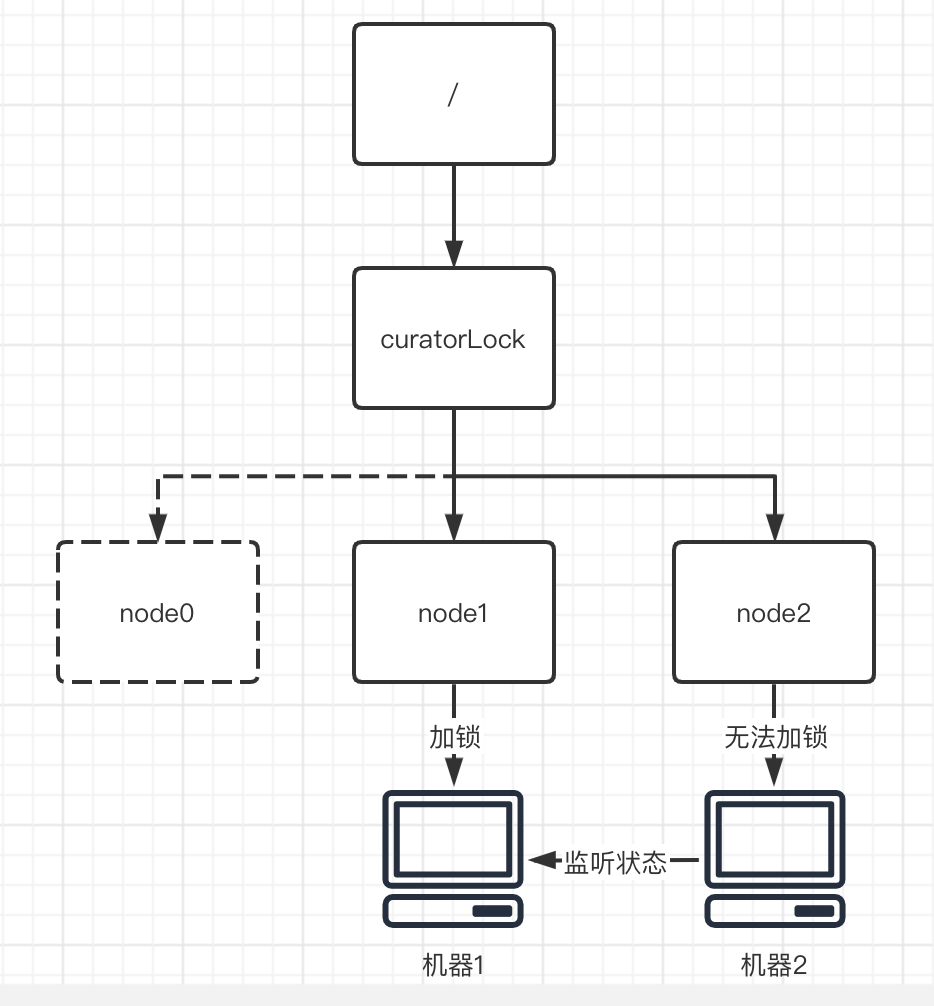
As a result, the whole unlocking process is realized.

Zookeeper distributed lock practice
code implementation
Here, we implement the corresponding logic with the help of the CuratorFramework framework and the InterProcessMutex mutex provided by the framework.
@Component
@Slf4j
public class ZkClientUtil {
//zk connection ip
private final String zkServers = "Yours zk The server Ip";
private CuratorFramework curatorFramework;
// zk self incrementing storage node
private String lockPath = "/curatorLock";
InterProcessMutex lock;
@PostConstruct
public void initZKClient(){
//If the waiting time is less than the maximum spin time, spin
LOGGER.info(">>>>Zk Connecting....");
ExponentialBackoffRetry retryPolicy = new ExponentialBackoffRetry(1000, 3);
curatorFramework = CuratorFrameworkFactory.builder()
.connectString(zkServers) //zk service address
.sessionTimeoutMs(5000) // Session timeout
.connectionTimeoutMs(5000) // Connection timeout
.retryPolicy(retryPolicy)
.build();
curatorFramework.start();
lock = new InterProcessMutex(curatorFramework, lockPath);
LOGGER.info(">>>>Zk Connection successful!");
}
/**
* Obtain the corresponding node lock
*/
@SneakyThrows
public void getLock(){
//Set timeout
boolean acquire = lock.acquire(50, TimeUnit.SECONDS);
if (acquire){
LOGGER.info("ZK Locking succeeded:"+Thread.currentThread().getId());
}else {
LOGGER.info("ZK Locking failed:"+Thread.currentThread().getId());
}
}
/**
* Unlock the corresponding node
*/
@SneakyThrows
public void unlock(){
lock.release();
LOGGER.info("ZK Unlocked successfully"+Thread.currentThread().getId());
}
}
Then we only need to make a small change to our original code of the last issue ~
@SneakyThrows
public synchronized Boolean deductProduct(ProductPO productPO){
CompletableFuture<Exception> subThread = CompletableFuture.supplyAsync(()->{
try{
zkClientUtil.getLock(); // Replace key lock codes
....
}finally {
zkClientUtil.unlock(); // Replace key unlock codes
}
});
Exception exception = subThread.get();
if (exception !=null){
throw exception;
}
return true;
}
Then run the code proudly, and the results are as follows:
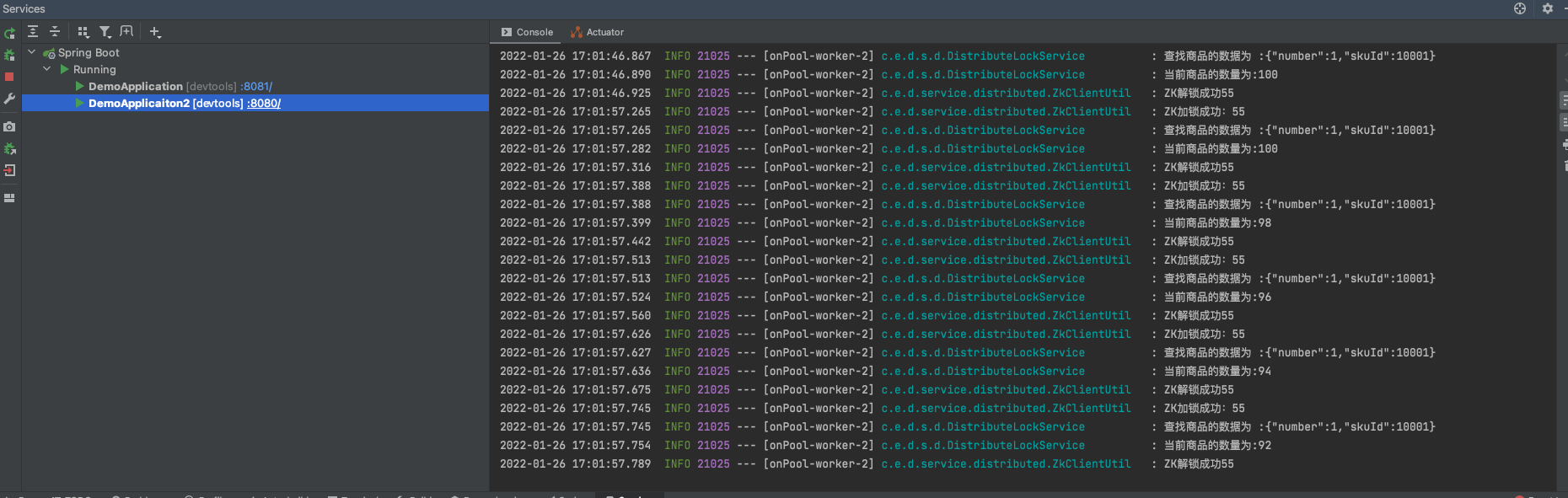
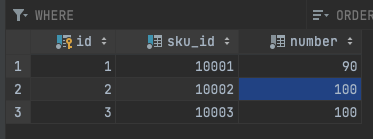
It can be seen that the results are indeed in line with expectations ~

Source code analysis
However, as the most beautiful baby in the universe, how can optics meet me? Everyone must be curious about how to realize the underlying principle of curator framework
First, let's look at the locking part. The key code is mainly the acquire part:
public boolean acquire(long time, TimeUnit unit) throws Exception {
return this.internalLock(time, unit);
}
The acquire part of the code then goes deep into the internalLock method to see the specific logic.
private boolean internalLock(long time, TimeUnit unit) throws Exception {
Thread currentThread = Thread.currentThread();
// Attempt to get lock data for thread from record table
InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread);
if (lockData != null) {
// If the data is not empty, re-entry is realized, the count is + 1, and the locking success is returned
lockData.lockCount.incrementAndGet();
return true;
} else {
// If the data is empty, lock it (key code, in-depth view)
String lockPath = this.internals.attemptLock(time, unit, this.getLockNodeBytes());
if (lockPath != null) {
//Save the lock record in ThreadData for easy storage
InterProcessMutex.LockData newLockData = new InterProcessMutex.LockData(currentThread, lockPath);
this.threadData.put(currentThread, newLockData);
return true;
} else {
return false;
}
}
}
Then catch up with the module code trying to lock. The most critical codes are createTheLock method and internalLockLoop method.
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception{
final long startMillis = System.currentTimeMillis(); // Get the current system time
final Long millisToWait = (unit != null) ? unit.toMillis(time) : null; // Same unit conversion
final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
int retryCount = 0;
String ourPath = null;
boolean hasTheLock = false;
boolean isDone = false;
while ( !isDone ){
isDone = true;
try{
/*Key methods > > > > > create temporary sequential nodes according to the path and obtain the corresponding path of the node*/
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
/*Key method > > > > > > here, judge the corresponding object to be monitored according to the child nodes of the corresponding lock*/
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
}catch ( KeeperException.NoNodeException e ){
if ( client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()) ){
//If the retry policy allows retry, retry.
isDone = false;
}else{
throw e;
}
}
}
if ( hasTheLock ){
//If the lock is held, the path of locking and adding points is returned
return ourPath;
}
return null;
}
The createTheLock method will create a temporary sequence node for subsequent locking.
@Override
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception{
String ourPath;
if ( lockNodeBytes != null ) {
ourPath = client
.create()
.creatingParentContainersIfNeeded()
.withProtection()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(path, lockNodeBytes);
}else{
ourPath = client
.create()
.creatingParentContainersIfNeeded()
.withProtection()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(path);
}
return ourPath;
}
The internalLockLoop method will first obtain the corresponding child node (i.e. the locked node) according to the path of the current lock, and then judge whether the current node can obtain the distributed lock according to a key variable maxleaks (the default is 1, and the probability can be controlled by modifying maxleaks to control whether a lock can be obtained by multiple people at the same time).
If the length of the child node array exceeds maxleaks at this time, my current node cannot obtain the lock, so I need to listen to the node with the length maxleaks of the array to expect to obtain the corresponding lock. At the same time, the component also makes special treatment for timeout to avoid deadlock or constant waiting.
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception{
boolean haveTheLock = false;
boolean doDelete = false;
try{
if ( revocable.get() != null ){
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ){
List<String> children = getSortedChildren();
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ){
haveTheLock = true;
} else{
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
try{
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // If the monitoring timeout occurs, the node will automatically release to avoid deadlock
break;
}
wait(millisToWait);
}
else{
wait();
}
}
catch ( KeeperException.NoNodeException e ){
// it has been deleted (i.e. lock released). Try to acquire again
}
}
}
}
}catch ( Exception e ){
ThreadUtils.checkInterrupted(e);
doDelete = true;
throw e;
}finally{
if ( doDelete ){ //If the timeout or error is reported, the node will be deleted
deleteOurPath(ourPath);
}
}
return haveTheLock;
}
As a result, the logic of locking is relatively clear.
Unlock:
The code of unlocking part is basically similar. The source code is as follows:
public void release() throws Exception{
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData == null ){
throw new IllegalMonitorStateException("You do not own the lock: " + basePath);
}
int newLockCount = lockData.lockCount.decrementAndGet();
if ( newLockCount > 0 ){
return;
}
if ( newLockCount < 0 ){
throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);
}
try{
internals.releaseLock(lockData.lockPath);
}finally{
threadData.remove(currentThread);
}
}
First, the corresponding lock information will be obtained from the record table according to the current thread. If the lock information does not exist, an exception will be thrown.
If the lock information exists, first judge whether it has re entered. If it is a re entered lock, count - 1.
Otherwise, perform the operation of releasing the lock. Here, first delete all the corresponding observers under the node, and then delete the temporary node to complete the release of the lock.
final void releaseLock(String lockPath) throws Exception
{
client.removeWatchers(); // Remove observer
revocable.set(null);
deleteOurPath(lockPath); // Delete the lock of the corresponding path
}
Thus, the whole process of locking and unlocking is completely resolved ~
Advantages and disadvantages analysis
advantage:
- ZK's ready-made framework supports relatively perfect and easy to use, and supports the mechanism of deleting locks over time to avoid possible deadlocks.
- The curator framework is essentially an implementation that queues in the order in which it is created. This scheme is efficient and avoids the "shock group" effect. When the lock is released, only one client will be awakened.
- ZK's natural design is distributed coordination and strong consistency. The model of lock is robust, easy to use and suitable for distributed lock.
- When ZK implements distributed lock, if the node cannot obtain the lock, it only needs to add a listener without polling all the time, and the performance consumption is small.
Disadvantages:
- In order to maintain high consistency, ZK will cause the re-election algorithm to take a long time when the cluster leader hangs up. Therefore, the logic of locking and unlocking may not be available for a long time.
- If more clients frequently apply for locking and releasing locks, it will put great pressure on zk clusters.
reference
Zk (zookeeper) implementation of distributed lock
Are you still using zkclient to develop zookeeper? It's time to use cursor!
Click ZooKeeper to realize the scheme of distributed lock, with examples!