Here's the table of contents:
Analyze bitcoin blockchain using graph data
The whole process is to obtain data from one format (blockchain data) and convert it to another format( Graphic database ). The only thing that makes this conversion more difficult than typical data conversion is the understanding of data format; Before starting, it will be helpful to understand the structure of bitcoin data [which will be described in detail in the first part]. In addition, you can refer to some open source tools to import blockchain data, bitcoin-to-graph. What is the relationship between Blockchain and Bitcoin? Refer to the link article!
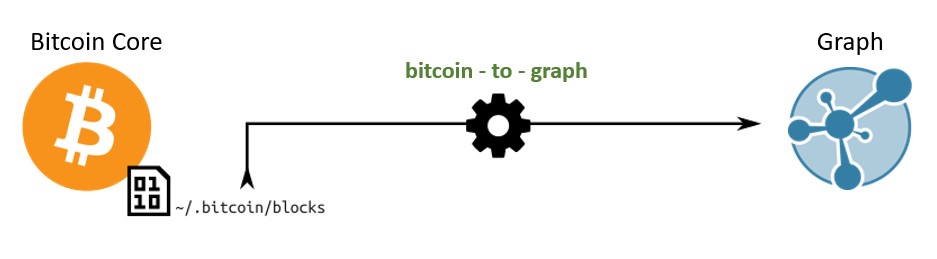
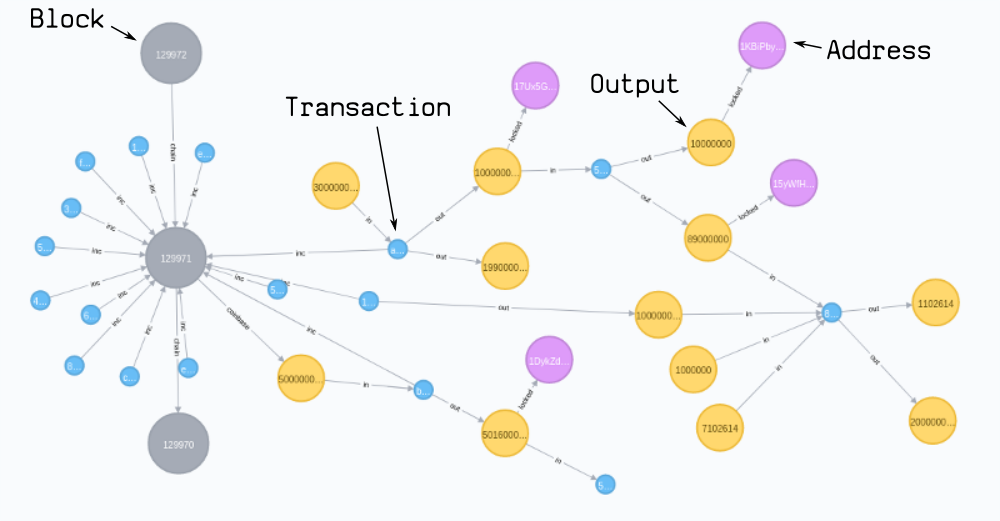
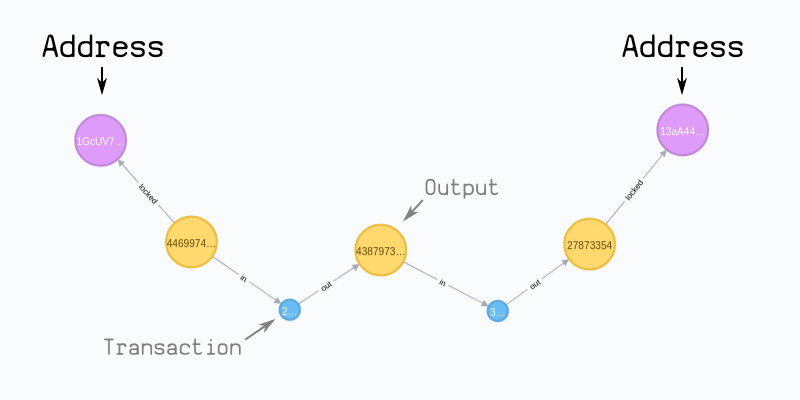
Once the blockchain is imported into the graph database, the analysis that cannot be performed by the SQL database can be performed on the graph database. For example, you can track the path of bitcoin to see whether two different addresses are connected:
1, How does bitcoin work and what is the blockchain
Bitcoin is a computer program. After running the program, it can connect to other computers running the same program and share a file. However, the coolest thing about bitcoin is that anyone can add data to this shared file, and any data that has been written to the file will not be tampered with. Therefore, bitcoin creates a secure file shared on a distributed network.
1.1 what can bitcoin be used for?
In bitcoin, every data added to the file is a transaction. Therefore, this decentralized file is used as the "ledger" of digital currency (i.e. cryptocurrency). This "ledger" is called blockchain.
1.2. Where can I find blockchain?
If you run Bitcoin core program , the blockchain will be stored in a folder on your computer:
- Linux: ~/.bitcoin/blocks
- Mac: ~/Library/Application Support/Bitcoin/blocks
- Windows: C:\Users\YourUserName\Appdata\Roaming\Bitcoin\blocks
When you open this directory, you should notice that it is not a large file, but multiple files named blkxxxx Dat file. This is blockchain data, but it is scattered in multiple smaller files.
2, What does blockchain data look like
blk.dat The file contains serialized data for block blocks and transactions.
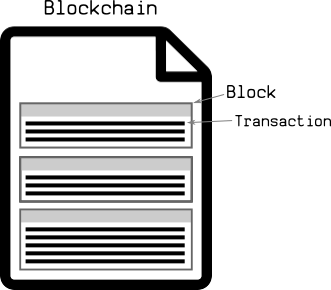

2.1 Blocks
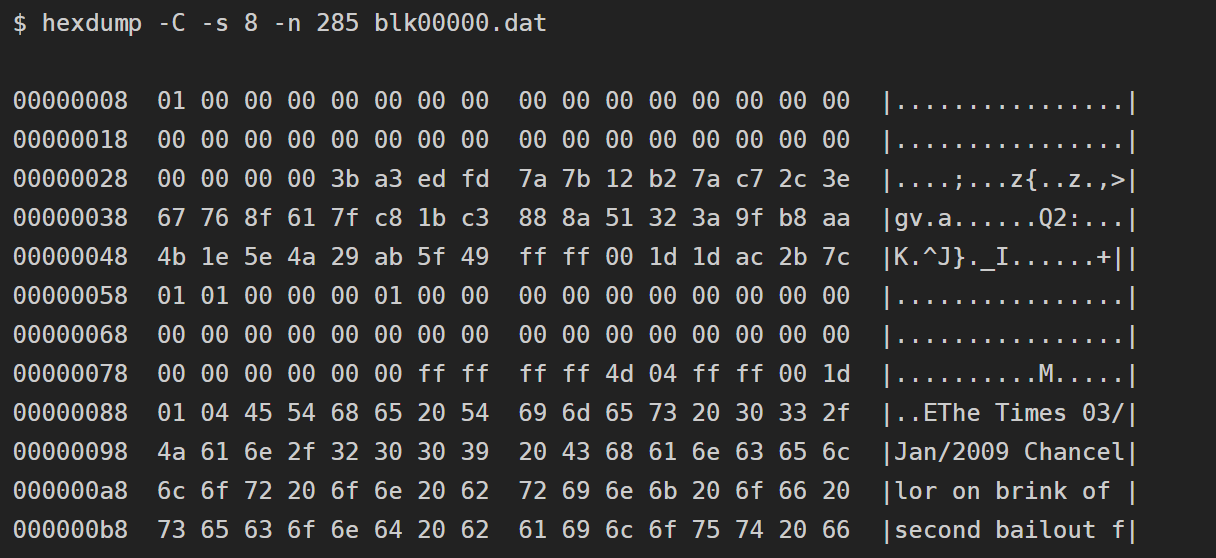
Block quilt magic bytes Separate, followed by the size of the upcoming block. Each block is represented by a Bulk Start [block is the basic container unit of a transaction list]:
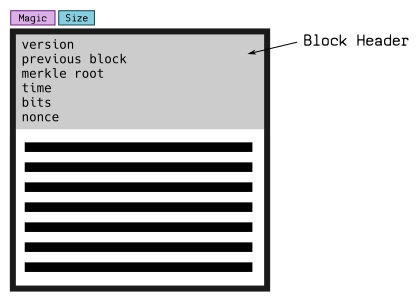
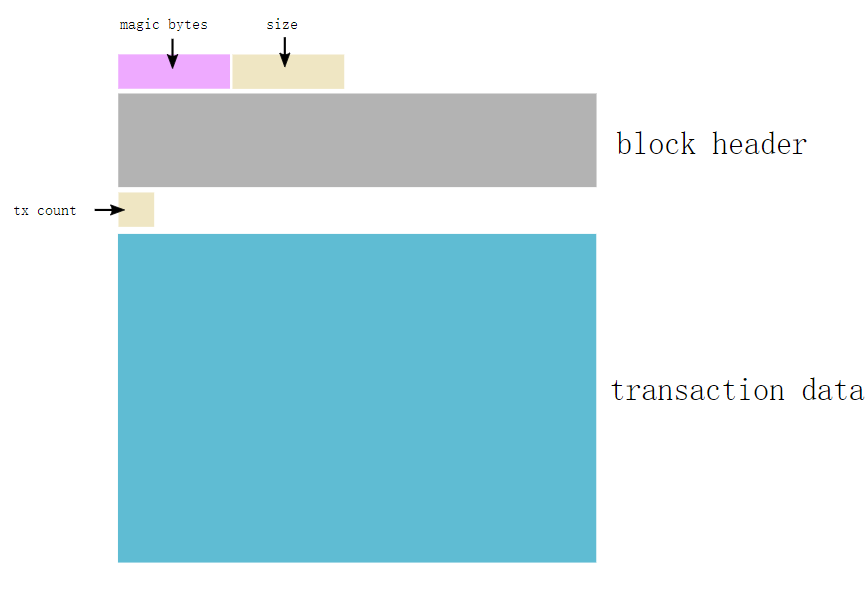
- Example of block header:
000000206c77f112319ae21489b66774e8acd379044d4a23ea7498000000000000000000821fe1890186779b2cc232d5dbecfb9119fd46f8a9cfd1141649ff1cd907374487d8ae59e93c011832ec0399
2.2. Transactions
After the block header, a byte tells you the number of upcoming transactions in the block. After that, you will get the serialized transaction data in turn. transaction Just another piece of code, but they are more interesting in structure. Bitcoin transaction is a pile of data describing the movement of bitcoin. It receives the input and creates a new output.
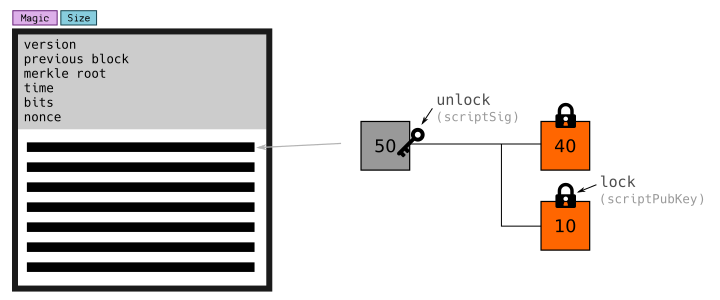

Each transaction has the same pattern:
- Select output (the process of getting input): unlock these inputs so that they can be consumed.
- Create outputs: Lock these outputs to a new address.
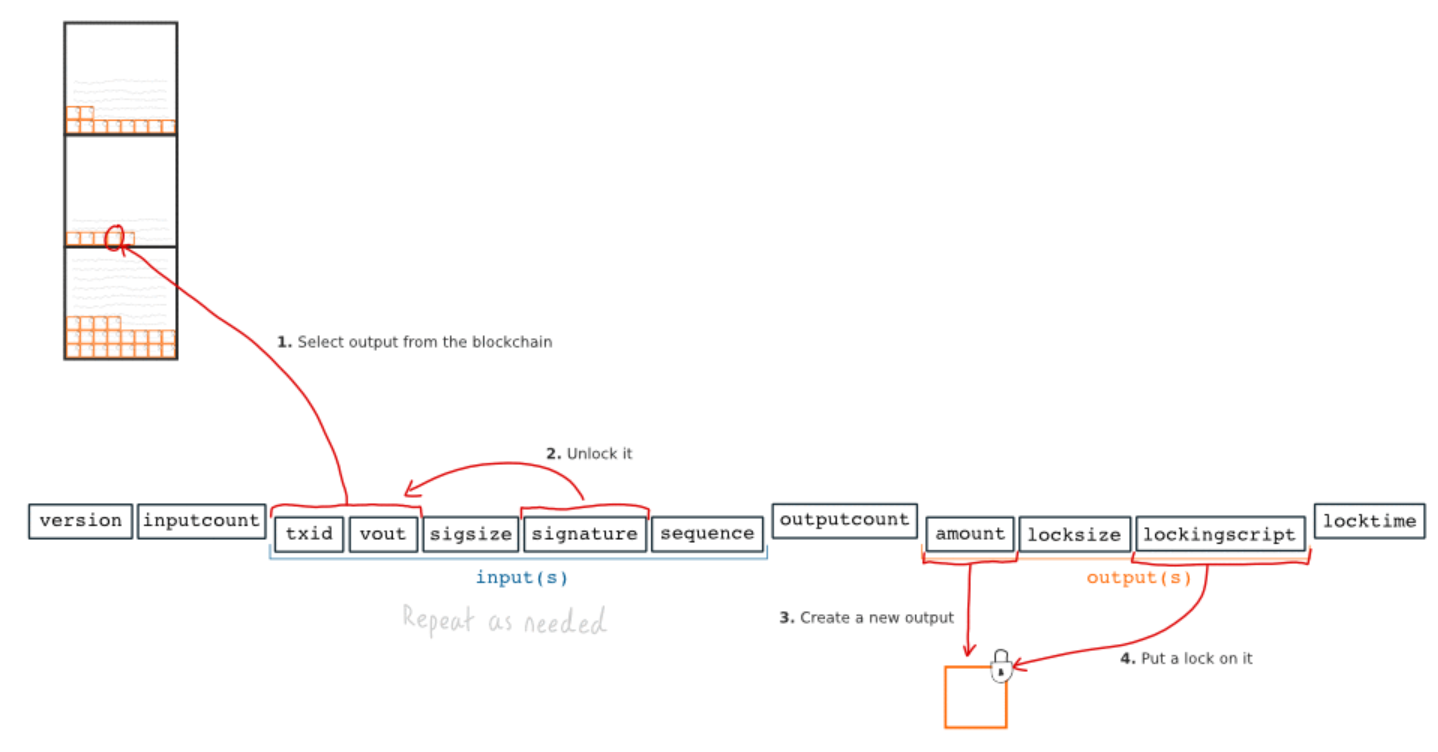
After a series of transactions, you will get such a transaction structure. This is a simplified diagram of blockchain. As you can see, it looks like a figure [similar to the figure in the introduction]:

3, How to import blockchain data into graph database
Through the first and second parts, we have basically figured out what the blockchain data represents (it looks like a graph), and we can continue to use it Import to graph database Yes.
- Read BLK Dat file.
- Decode each block and transaction.
- Convert decoded block / transaction to a Cypher Query.
The following is a visual guide on how to represent blocks, transactions and addresses in the database:
3.1 Blocks
- Create a block node and connect it to the previous block; Set each field in the block header as an attribute of the node.
- Create a coinbase node for each block node, which represents the "new" bitcoin provided by the block.
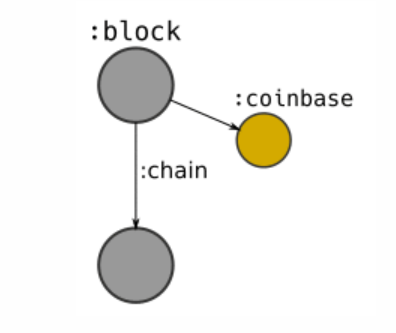
3.2. Transactions
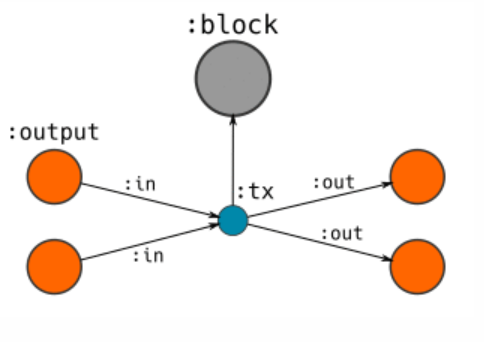
- Create a: tx node and connect it to the: block node we just created; Set: the attribute of tx node is (version, locktime).
- Merge existing: output nodes and associate them [: in] to: tx nodes; Set unlocking code as the attribute of the relationship.
- Create a new: output node generated by this transaction; Set the respective values and locking codes on these nodes.
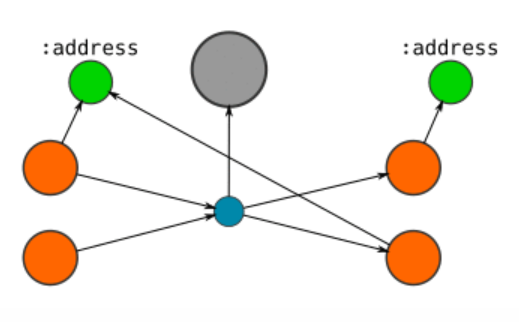
3.3 Addresses
- Create a ': Address' node and connect the: output node to it; At the same time, set the address property on this node. (if different outputs are connected to the same address, they will be connected to the same address node.)
4, Cypher query
Here are some sample Cypher queries that you can use as benchmark queries for inserting blocks and transaction data into the graph database. (Note: it is necessary to decode the block header and transaction data to obtain the parameters of Cypher query.)
4.1 Block data processing
- Reference Cypher
MERGE (block:block {hash:$blockhash})
CREATE UNIQUE (block)-[:coinbase]->(:output:coinbase)
SET
block.size=$size,
block.prevblock=$prevblock,
block.merkleroot=$merkleroot,
block.time=$timestamp,
block.bits=$bits,
block.nonce=$nonce,
block.txcount=$txcount,
block.version=$version,
MERGE (prevblock:block {hash:$prevblock})
MERGE (block)-[:chain]->(prevblock)
- Refer to [example]
{
"blockhash": "00000000000003e690288380c9b27443b86e5a5ff0f8ed2473efbfdacb3014f3",
"version": 536870912,
"prevblock": "000000000000050bc5c1283dceaff83c44d3853c44e004198c59ce153947cbf4",
"merkleroot": "64027d8945666017abaf9c1b7dc61c46df63926584bed7efd6ed11a6889b0bac",
"timestamp": 1500514748,
"bits": "1a0707c7",
"nonce": 2919911776,
"size": 748959,
"txcount": 1926,
}
4.2 Transaction data processing
- Reference Cypher
This query uses FOREACH statement As a condition, it is created only when the $addresses parameter actually contains an address: the address node. Usually, the FOREACH statement is used in scenarios where graph data needs to be created dynamically.
MATCH (block :block {hash:$hash})
MERGE (tx:tx {txid:$txid})
MERGE (tx)-[:inc {i:$i}]->(block)
SET tx += {tx}
WITH tx
FOREACH (input in $inputs |
MERGE (in :output {index: input.index})
MERGE (in)-[:in {vin: input.vin, scriptSig: input.scriptSig, sequence: input.sequence, witness: input.witness}]->(tx)
)
FOREACH (output in $outputs |
MERGE (out :output {index: output.index})
MERGE (tx)-[:out {vout: output.vout}]->(out)
SET
out.value= output.value,
out.scriptPubKey= output.scriptPubKey,
out.addresses= output.addresses
FOREACH(ignoreMe IN CASE WHEN output.addresses <> '' THEN [1] ELSE [] END |
MERGE (address :address {address: output.addresses})
MERGE (out)-[:locked]->(address)
)
)
- Refer to [example]
{
"txid":"2e2c43d9ef2a07f22e77ed30265cc8c3d669b93b7cab7fe462e84c9f40c7fc5c",
"hash":"00000000000003e690288380c9b27443b86e5a5ff0f8ed2473efbfdacb3014f3",
"i":1,
"tx":{
"version":1,
"locktime":0,
"size":237,
"weight":840,
"segwit":"0001"
},
"inputs":[
{
"vin":0,
"index":"0000000000000000000000000000000000000000000000000000000000000000:4294967295",
"scriptSig":"03779c110004bc097059043fa863360c59306259db5b0100000000000a636b706f6f6c212f6d696e65642062792077656564636f646572206d6f6c69206b656b636f696e2f",
"sequence":4294967295,
"witness":"01200000000000000000000000000000000000000000000000000000000000000000"
}
],
"outputs":[
{
"vout":0,
"index":"2e2c43d9ef2a07f22e77ed30265cc8c3d669b93b7cab7fe462e84c9f40c7fc5c:0",
"value":166396426,
"scriptPubKey":"76a91427f60a3b92e8a92149b18210457cc6bdc14057be88ac",
"addresses":"14eJ6e2GC4MnQjgutGbJeyGQF195P8GHXY"
},
{
"vout":1,
"index":"2e2c43d9ef2a07f22e77ed30265cc8c3d669b93b7cab7fe462e84c9f40c7fc5c:1",
"value":0,
"scriptPubKey":"6a24aa21a9ed98c67ed590e849bccba142a0f1bf5832bc5c094e197827b02211291e135a0c0e",
"addresses":""
}
]
}
5, Use blockchain data for query analysis
If you have inserted blocks and transaction data using the Cypher query above, you can do some query analysis from the graph database.
5.1. Query block Bolck
// Relationship between query block and transaction data MATCH (block :block)<-[:inc]-(tx :tx) WHERE block.hash='$blockhash' RETURN block, tx
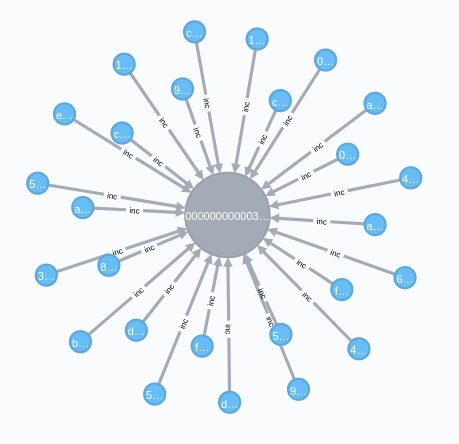
5.2. Query Transaction
// Query the input / output relationship of transaction MATCH (inputs)-[:in]->(tx:tx)-[:out]->(outputs) WHERE tx.txid='$txid' OPTIONAL MATCH (inputs)-[:locked]->(inputsaddresses) OPTIONAL MATCH (outputs)-[:locked]->(outputsaddresses) OPTIONAL MATCH (tx)-[:inc]->(block) RETURN inputs, tx, outputs, block, inputsaddresses, outputsaddresses
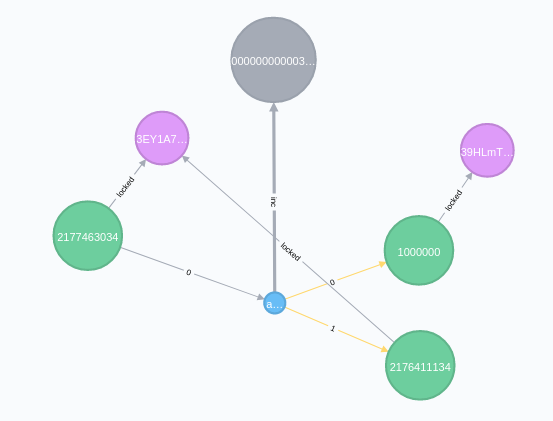
5.3. Query Address
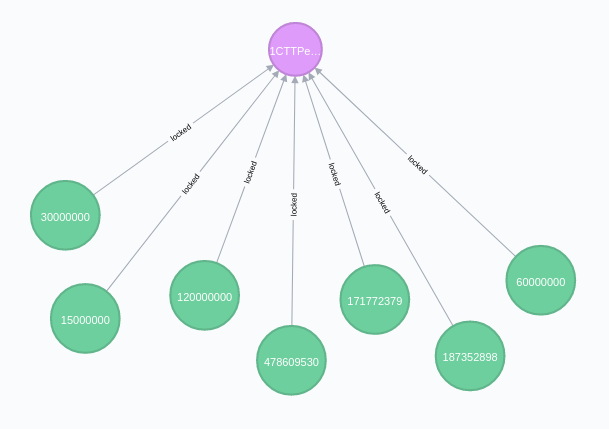
// Relationship between query address and output
MATCH (address :address {address:'1PNXRAA3dYTzVRLwWG1j3ip9JKtmzvBjdY'})<-[:locked]-(output :output)
WHERE address.address='$address'
RETURN address, output
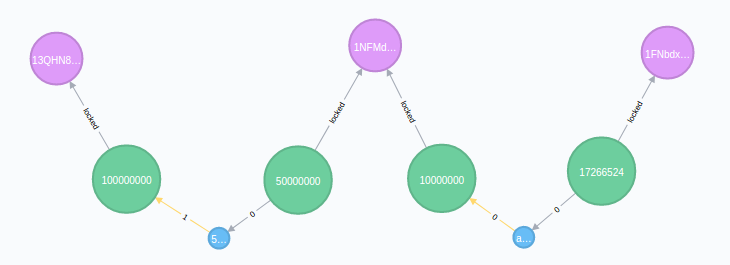
5.4 search path
Finding the path between transaction and address may be the most interesting thing you can do with the graphic database of bitcoin blockchain, so here are some examples of Cypher query:
- Query path between output nodes:
// Query the shortest path between two outputs
MATCH (start :output {index:'$txid:vout'}), (end :output {index:'$txid:out'})
MATCH path=shortestPath( (start)-[:in|:out*]-(end) )
RETURN path

- Path query between addresses:
// Query the shortest path between two addresses
MATCH (start :address {address:'$address1'}), (end :address {address:'$address2'})
MATCH path=shortestPath( (start)-[:in|:out|:locked*]-(end) )
RETURN path
6, Summary
This article is about how to start from BLK Dat file (blockchain) is a simple guide to get block and transaction data and import them into the graph database.
I think it's worth it if you want to analyze the blockchain. Graph database is the most natural expression of bitcoin blockchain data, and using SQL database to analyze bitcoin transaction data is very difficult or even impossible.
In order to make this guide as concise as possible, the following contents are not covered:
- Read blockchain. Read BLK DAT files are easy to. However, the annoying thing about these files is that blocks are not written to these files in order, which makes it a bit tricky to set the height of blocks or calculate the cost of transactions (but you can encode around it).
- Decoding blocks and transactions. If you want to use the Cypher query above, you will need to decode the block header and the original transaction data to obtain the required parameters. You can write your own decoder or try using an existing bitcoin library.
- There are other special formats that need special consideration. But if you understand how data is organized, converting it into different formats is just developing specific programs.