
Author Pu Ke
This paper introduces how to design the architecture of a large Android project from 0 to 1.
One guide
This article is long and can be combined with the following table to guide you to quickly understand the main context of the full text.
II. Project architecture evolution
This chapter mainly summarizes the evolution process of an Android project architecture from 0 to 1 and then to N (since the development of the project is affected by various factors such as business, team and scheduling, the summary will not strictly match the evolution process of each step, but it is enough to explain the general law of the development stage of the project).
1. Single project stage
For a newly opened project, the number of developers at each end is usually very limited, often only 1-2. At this time, the development cycle is more important than the project architecture design and various development details. The most important goal of this stage is to quickly implement the idea. At this stage, the architecture of the project is often like this

At this time, almost all the code in the project will be written in an independent app module. Under the background of time is king, the most original development mode is often the best and most efficient.
2. Abstract basic library stage
With the project minimized, MVP has been developed. Next, we intend to continue to improve the App. At this time, the probability will encounter the following problems:
- Code version control. In order to speed up the iteration of the project, the team recruits 1-3 new development students. When multiple people develop on a project at the same time, Git code merging will always conflict, which will greatly affect the development efficiency;
- The compilation and construction of the project. With the gradual increase of the amount of project code, the running App is compiled based on the source code, so that the speed of the first full package compilation and construction gradually slows down, and even needs to wait a few minutes or longer to verify the changes of one line of code;
- For the problem of code reuse of multiple applications, the company may be developing multiple apps at the same time. The same code always needs to be reused by copying and pasting. There will also be problems in maintaining the logical consistency of the same function among multiple apps;
Based on one or more of the above reasons, we tend to modularize and package the functions that are rarely changed once the development is completed relative to the whole project.

We extracted the project that originally contained only one application layer down to a basic layer containing many atomic capability libraries such as network library, image loading library and UI library. After doing so, it has greatly improved collaborative development, whole package construction and code reuse.
3. Stage of expanding core competence
After the business began to take shape, App has been put online and has a continuous and stable DAU.
At this time, it is often very critical. With the growth of business, the increase of customer usage, the increase of iteration requirements and other challenges. If the project does not have a set of benign architecture design, the human efficiency of development will decrease inversely with the expansion of team size. Previously, one person can develop five needs per unit time, but now 10 people can't even develop 20 needs in the same time. It is difficult to completely solve this problem simply by adding people. Focus on two things to do at this time
- Development responsibilities are separated. Team members need to be divided into two parts, corresponding to business development and infrastructure respectively. The business development team is responsible for supporting the completion of daily business iterations, with business delivery as the goal; The infrastructure team is responsible for the construction of the underlying core competence, with the goal of improving efficiency, performance and core competence expansion;
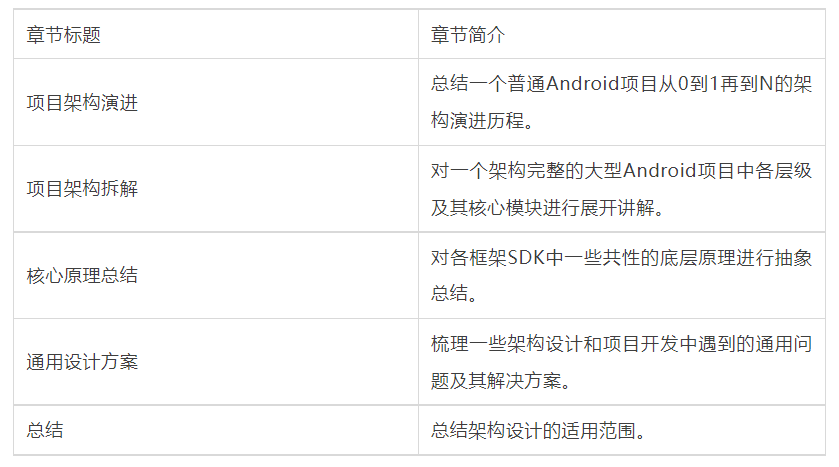
- The project architecture optimization is based on 1. The core architecture layer should be abstracted between the application layer and the foundation layer, and handed over to the infrastructure group together with the foundation layer, as shown in the figure;
This layer will involve the construction of many core competencies, which will not be repeated here. The above modules will be expanded in detail below.
Note: from a global perspective, the basic layer and the core layer can also support the upper business as a whole. Here, it is divided into two layers, mainly considering that the former is a required option and a necessary part of the overall architecture; The latter is optional, but it is also the core indicator to measure the middle office ability of an App.
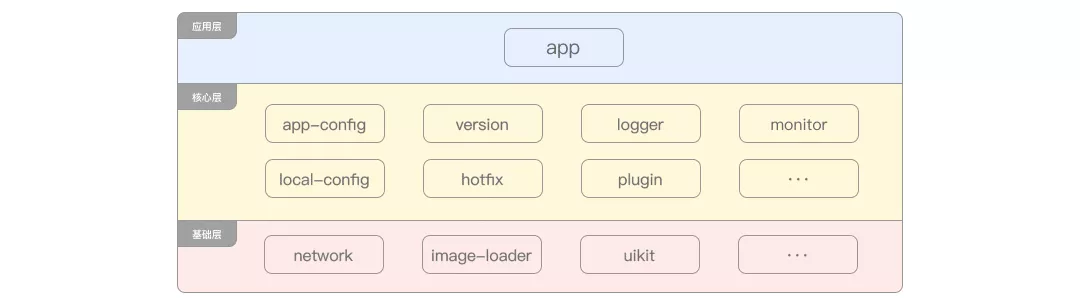
4 modular phase
As the business scale continues to expand, App product managers (hereinafter referred to as PDS) will change from one to multiple. Each PD is responsible for an independent business line. For example, if the App contains multiple modules such as home page, products and my, each PD will correspond to one module here. But the adjustment will bring a very serious problem
The iteration time of the project version is determined. When there is only one PD, each version will raise a batch of requirements. The development will go online if it can be delivered on time. If it cannot be delivered, the iteration will be postponed appropriately, so there will be no problem;
However, now that multiple business lines are parallel, it is difficult to ensure that the requirements iterations of each business line can be delivered normally in an absolute sense. It is like you have organized an activity and agreed on a collection of points, but someone will always encounter some special situations and can't arrive in time. Similarly, this situation that is difficult to be completely consistent will also be encountered in project development. Under the current project architecture, although business lines are split in business, the business module of our project is still a whole, which contains various complex dependency networks. Even if each business line is divided by branch, it is difficult to avoid this problem.
At this time, we need to modularize the project at the architecture level so that multiple business lines do not depend on each other, as shown in the figure
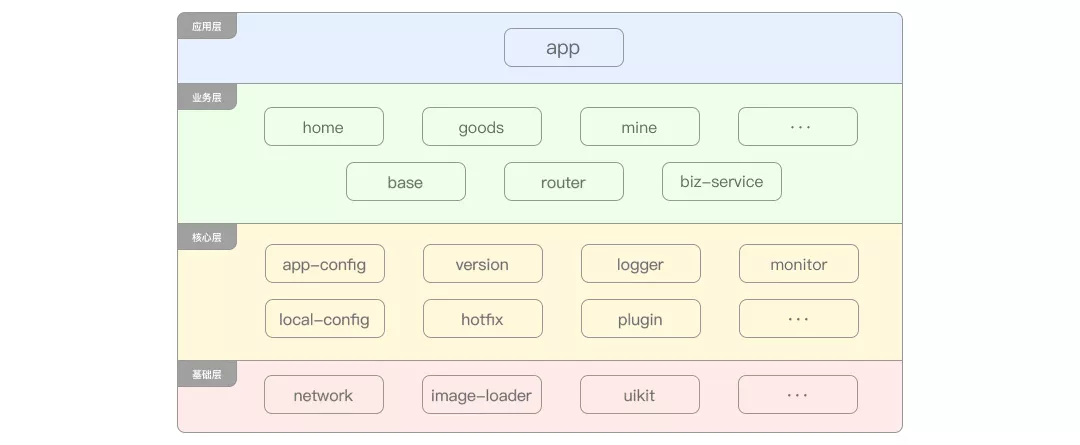
In the business layer, it can be divided more finely according to developers or groups to ensure the decoupling between businesses and the definition of development responsibilities.
5 cross platform development stage
The business scale and user volume continued to expand. In order to cope with the subsequent surge in business demand, the whole end team began to consider the R & D cost.
Why does each business requirement need to be implemented at least once at both ends of Android and iOS? Is there any solution that can meet the requirement that one piece of code can run on multiple platforms? This not only reduces the communication cost, but also improves the R & D efficiency. Of course, the answer is yes. At this time, some end-side businesses begin to enter the stage of cross platform development.
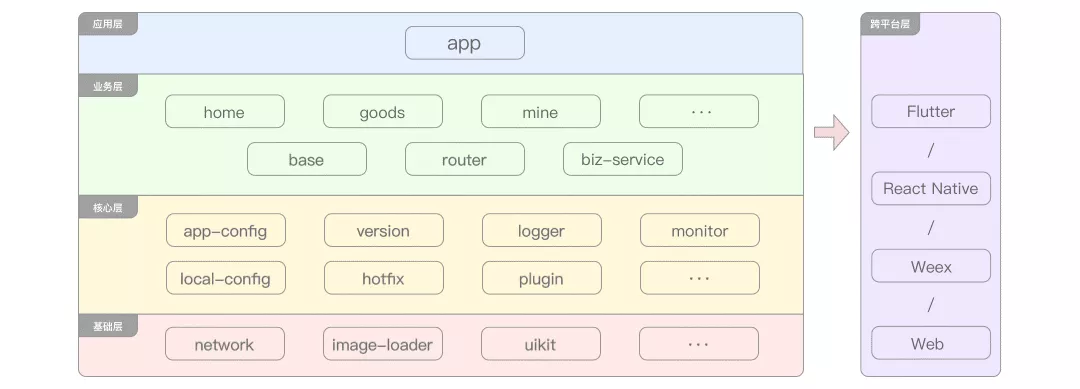
So far, a relatively complete end-to-end system architecture has begun to take shape. There will be more iterations in the follow-up business, but the overall structure of the project will not deviate too much. It is more to make deeper improvements and improvements for some nodes in the current architecture.
The above is a summary of the iterative process of Android project architecture. Next, I will expand the final architecture diagram one by one according to the bottom-up hierarchical order, and analyze and summarize the core modules and possible problems involved in each layer.
III. disassembly of project structure
1 foundation layer
Basic UI module
Extracting the basic UI module has two main purposes:
Unify App global base styles
For example, the main color of App, the text color and size of ordinary text, the internal and external margins of the page, the default prompt copy of network loading failure, the default UI of empty list, etc. especially after the project modularization mentioned below, the unification of these basic UI styles will become very important.
Reuse basic UI components
When the scale of the project and the team is gradually expanded, in order to improve the development efficiency of the upper layer business and adhere to the DRY development principle, it is necessary to uniformly package some high-frequency UI components for the upper layer business to call; From another point of view, the necessary abstract encapsulation can also reduce the size of the final built installation package, so as to avoid the appearance of a semantic resource file in multiple places.
Basic UI components usually include internal development and external reference. Internal development is understandable. They can be developed and encapsulated according to business requirements; External references should emphasize that Github has a large number of reusable and excellent UI component libraries verified by many projects. If it is to quickly meet the demands of business development, these will be a good choice.
Selecting an appropriate UI library will greatly accelerate the whole development process. It may be no problem to implement it manually, but it will take a lot of time and energy. If it is not to study the implementation principle or deep customization, it is recommended to give priority to mature UI libraries.
Network module
Most App applications need networking, and the network module has become an indispensable part of almost all apps.
Frame selection
Several major principles are often referred to in the selection of basic framework:
- The maintenance team and community are relatively large, and there is enough self-help space to solve problems;
- The bottom layer has powerful functions and supports as many upper application scenarios as possible;
- Flexible expansion capability, supporting capacity expansion and AOP processing based on the framework;
- The Api side is friendly and reduces the understanding and use cost of the upper layer;
There is no specific development here. If the basic layer does not have its own additional customization to the network layer, it is recommended to directly use Retrofit2 as the preferred network library. The Api in the upper Java Interface style is very friendly to developers; The lower layer relies on the powerful Okhttp framework, which can almost meet the business demands of most scenarios. Use case reference on the official website

The use case shows the advantages of the retrofit declarative interface. It can be used without manually implementing the interface. The principle behind it is based on the dynamic agent of Java.
Unified interception processing
No matter what network library is selected in the previous step, the ability of the network library to support unified interception needs to be considered. For example, if we want to print the logs of all requests during the whole running process of the App, we need a global Interceptor like Interceptor to support configuration.
As a specific example, in many distributed deployment scenarios on the server, the traditional session method can no longer meet the demands of client state recording. A recognized solution is JWT (JSON WEB TOKEN), which requires the client side to pass the request header information containing the user status to the server after login authentication. At this time, it needs to do a unified interception process similar to the following at the network layer.
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://xxx.xxxxxx.xxx")
.client(new OkHttpClient.Builder()
.addInterceptor(new Interceptor() {
@NonNull
@Override
public Response intercept(@NonNull Chain chain) throws IOException {
// Add unified request header
Request newRequest = chain.request().newBuilder()
.addHeader("Authorization", "Bearer " + token)
.build();
return chain.proceed(newRequest);
}
})
.build()
)
.build();In addition, there is another point that needs to be explained. If there is some business-related information in the application, it is also recommended to consider unified transmission directly through the request header according to the actual business situation. For example, the community Id of the community App and the store Id of the store App have a universal feature. Once the switch is over, many business network requests will need the parameter information. If each interface is manually passed in, it will reduce the development efficiency and lead to some unnecessary human errors.
Picture module
The difference between image library and network library is that the difference of several popular libraries in the industry is not so large. It is recommended to choose according to personal preferences and familiarity. The following is an example of the use I sorted out from the official websites of various picture libraries.
Picasso
Picasso.get().load("http://i.imgur.com/DvpvklR.png").into(imageView);Fresco
Uri uri = Uri.parse("https://raw.githubusercontent.com/facebook/fresco/main/docs/static/logo.png");
SimpleDraweeView draweeView = (SimpleDraweeView) findViewById(R.id.my_image_view);
draweeView.setImageURI(uri);Glide
Glide.with(fragment)
.load(myUrl)
.into(imageView);In addition, the star of each library on Github is attached here for reference.
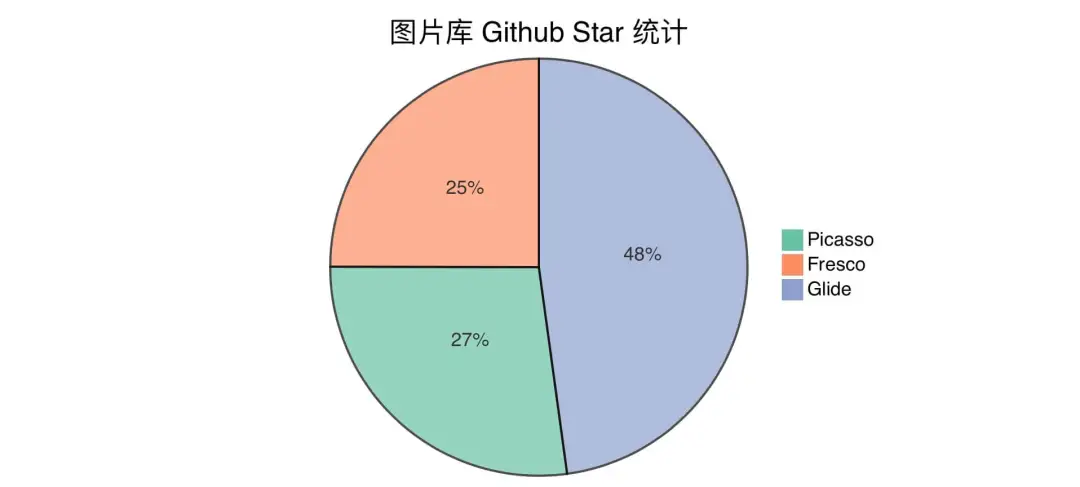
The selection of image library is flexible, but we need to understand its basic principle so that we can have enough coping strategies in case of problems in the image library.
In addition, it should be emphasized that the core of the image library is the design of image cache. For the extension of this part, please refer to the chapter "summary of core principles" below.
Asynchronous module
In Android development, asynchronous will be used a lot, and it also contains many knowledge points. Therefore, this part will be extracted and explained separately here.
1) Asynchronous theorem in Android
To sum up, the main thread handles UI operations and the sub thread handles time-consuming task operations. If you do the opposite, the following problems will arise:
- NetworkOnMainThreadException occurs when the main thread makes a network request;
- When the main thread performs time-consuming tasks, ANR (full name: Application Not Responding, which means that the application does not respond) is likely to occur;
- When a child thread performs UI operations, a CalledFromWrongThreadException exception will appear (only a general discussion will be made here. In fact, a child thread can also update the UI when certain conditions are met. Refer to "can Android child threads really update the UI?", This situation is not discussed in this paper);
2) The child thread calls the main thread
If you are currently in a child thread and want to call the method of the main thread, there are generally the following ways
1. Pass the post method of the main thread Handler
private static final Handler UI_HANDLER = new Handler(Looper.getMainLooper());
@WorkerThread
private void doTask() throws Throwable {
Thread.sleep(3000);
UI_HANDLER.post(new Runnable() {
@Override
public void run() {
refreshUI();
}
});
}2. Pass the sendMessage method of the main thread Handler
private final Handler UI_HANDLER = new Handler(Looper.getMainLooper()) {
@Override
public void handleMessage(@NonNull Message msg) {
if (msg.what == MSG_REFRESH_UI) {
refreshUI();
}
}
};
@WorkerThread
private void doTask() throws Throwable {
Thread.sleep(3000);
UI_HANDLER.sendEmptyMessage(MSG_REFRESH_UI);
}3. Use the runOnUiThread method of the Activity
public class MainActivity extends Activity {
// ...
@WorkerThread
private void doTask() throws Throwable {
Thread.sleep(3000);
runOnUiThread(new Runnable() {
@Override
public void run() {
refreshUI();
}
});
}
}4. Use the post method of View
private View view;
@WorkerThread
private void doTask() throws Throwable {
Thread.sleep(3000);
view.post(new Runnable() {
@Override
public void run() {
refreshUI();
}
});
}3) The main thread calls the child thread
If you want to call the method of the main thread in the current sub thread, there are generally several corresponding methods, as follows
1. Open a new thread
@UiThread
private void startTask() {
new Thread() {
@Override
public void run() {
doTask();
}
}.start();
}2. Through ThreadPoolExecutor
private final Executor executor = Executors.newFixedThreadPool(10);
@UiThread
private void startTask() {
executor.execute(new Runnable() {
@Override
public void run() {
doTask();
}
});
}3. Through AsyncTask
@UiThread
private void startTask() {
new AsyncTask< Void, Void, Void>() {
@Override
protected Void doInBackground(Void... voids) {
doTask();
return null;
}
}.execute();
}Asynchronous programming pain point
Android development uses Java and Kotlin. Of course, it is best if we introduce Kotlin into our project. For asynchronous calls, we only need to call in the following way.
Kotlin scheme
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")Here is an appropriate extension. The asynchronous call method similar to async + await has been supported in many other languages, as follows
Dart scheme
Future< String> fetchUserOrder() =>
Future.delayed(const Duration(seconds: 2), () => 'Large Latte');
Future< String> createOrderMessage() async {
var order = await fetchUserOrder();
return 'Your order is: $order';
}JavaScript scheme
function resolveAfter2Seconds(x) {
return new Promise(resolve => {
setTimeout(() => { resolve(x); }, 2000);
});
}
async function f1() {
var x = await resolveAfter2Seconds(10);
console.log(x); // 10
}
f1();However, if our project is still a pure Java project, we often encounter serial and asynchronous business logic in complex business interaction scenarios. At this time, our code readability will become very poor. An optional solution is to introduce RxJava, as shown below
RxJava solution
source .operator1() .operator2() .operator3() .subscribe(consumer)
2 core layer
Dynamic configuration
Service switch, ABTest
Dynamic configuration of online functions
background
- Android (Native development) is different from the Web, which can be released online at any time. Almost all Android releases need to be reviewed by the application platform;
- In business, AB test or some configuration switches are often required to meet the diversity of business;
Based on the above points, it determines our demand for dynamic configuration of code logic in the Android development process.
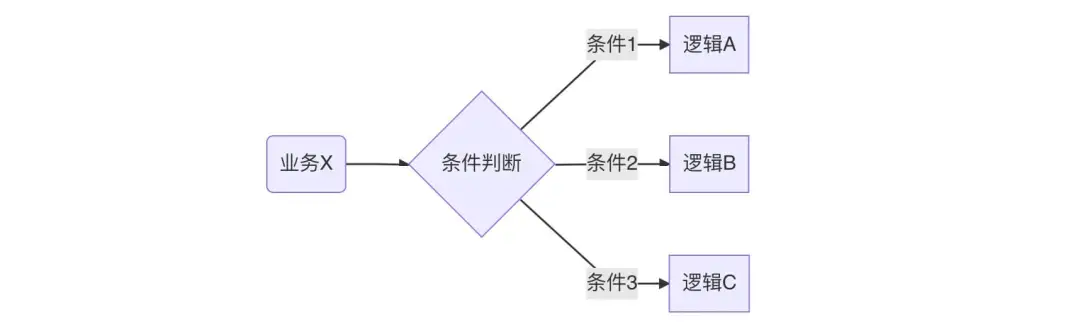
Based on this most basic model unit, the business can evolve very rich playing methods, such as configuring the dwell time of the startup page, configuring whether to display a large picture in the product, configuring how many pieces of data are loaded on each page, configuring whether to allow users to enter a page, and so on.
analysis
There are usually two schemes for the client to obtain configuration information, namely push and pull.
Push refers to establishing a long connection between the client and the server. Once the configuration of the server changes, the changed data will be pushed to the client for update;
Pull means that the client reads the latest configuration through active request every time;
Based on these two modes, the push-pull combination mode will evolve. Its essence is that both modes are used. There are no new changes in the technical level, so I won't repeat it here. The following is a comparison between push and pull methods
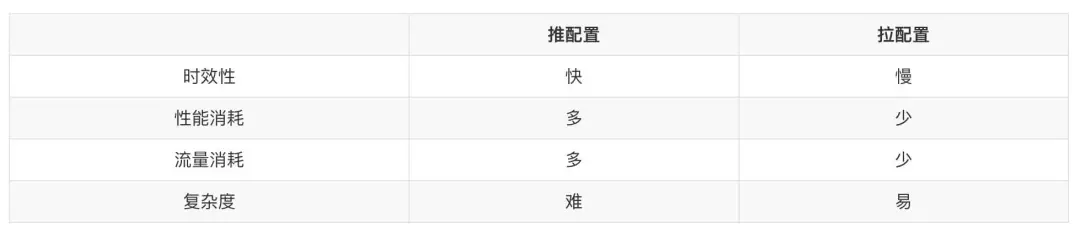
On the whole, if the business does not have very high requirements for timeliness, I personally prefer to pull. The main reason for changing the configuration is low-frequency events. Making a long C-S connection for this low-frequency event will feel like killing a chicken with a bull's knife.
realization
The implementation thinking of push configuration is relatively clear. If there is a configuration, send the client update, but the reconnection logic after the long connection is disconnected needs to be done well.
For the implementation of pull configuration, here are some things we need to think about. Here is a summary of the following points:
- Multi module partition configuration is carried out according to the namespace to avoid a large and comprehensive global configuration;
- Each namespace will have a flag during initialization and each change to identify the current version;
- Each service request of the client uniformly pulls the flags or their combined md5 and other identifiers at the request header, so as to check the timeliness of the flags when the server intercepts them uniformly;
- The timeliness test results of the server are distributed through the unified response header and isolated from the business interface, which is not perceived by the upper business party;
- When the client receives the inconsistent timeliness results, it will pull them according to the specific namespace instead of pulling them in full each time;
Global interception
background
The closest connection between App and users is interaction, which is the bridge between our App products and users.
What action the user wants to perform after clicking a button, what content to display after entering a page, what request to perform after an operation, and what prompt to perform after a request are the most intuitive things the user can see. Global interception is to make technical solutions that can be customized through the previous dynamic configuration for the most high-frequency interaction logic that these users can contact.
Interactive structure
Specific interaction responses (such as popping up a Toast or Dialog and jumping to a page) need to be controlled through code logic, but what this part needs to do is to realize these interactions after the App is released. Therefore, we need to structure some basic common interactions, and then make general embedded logic in the App in advance.
We can make the following conventions to define the concept of Action. Each Action corresponds to a specific interaction behavior that can be identified in the App, such as
1. Pop up Toast
{
"type": "toast",
"content": "Hello, welcome to XXX",
"gravity": "< Fill in here toast Location to show, The options are(center|top|bottom), The default value is center>"
}2. Pop up Dialog
It is worth noting that Toast logic is nested in the Action of Dialog, and the flexible combination of multiple actions can provide us with rich interaction capabilities.
{
"type": "dialog",
"title": "Tips",
"message": "Are you sure to exit the current page?",
"confirmText": "determine",
"cancelText": "cancel",
"confirmAction": {
"type": "toast",
"content": "You clicked OK"
}
}3. Close the current page
{
"type": "finish"
}4. Jump to a page
{
"type": "route",
"url": "https://www.xxx.com/goods/detail?id=xxx"
}5. Executing a network request is the same as 2. Here is also a nested combination of multiple actions.
{
"type": "request",
"url": "https://www.xxx.com/goods/detail",
"method": "post",
"params": {
"id": "xxx"
},
"response": {
"successAction": {
"type": "toast",
"content": "The current commodity price is ${response.data.priceDesc}element"
},
"errorAction": {
"type": "dialog",
"title": "Tips",
"message": "Query failed, About to exit the current page",
"confirmText": "determine",
"confirmAction": {
"type": "finish"
}
}
}
}Unified interception
The interactive structured data protocol specifies the specific events corresponding to each Action. The client parses and encapsulates the structured data, and then can transform the data protocol into product interaction with the user. The next thing to consider is how to make an interactive information effective. Refer to the following logic
1. Provide the ability to obtain the Action issued by the server according to the page and event ID. the DynamicConfig used here is the dynamic configuration mentioned above.
@Nullable
private static Action getClickActionIfExists(String page, String event) {
// Determine the action ID based on the current page and event
String actionId = String.format("hook/click/%s/%s", page, event);
// Resolve whether there are actions to be distributed in dynamic configuration
String value = DynamicConfig.getValue(actionId, null);
if (TextUtils.isEmpty(value)) {
return null;
}
try {
// Resolve the distributed Action into structured data
return JSON.parseObject(value, Action.class);
} catch (JSONException ignored) {
// Do not process in case of format error (for reference)
}
return null;
}2. Provide processing logic for packaging click events (performAction is the parsing logic for specific actions, and its function is relatively simple, so it is not expanded here)
/**
* Packaging click event processing logic
*
* @param page Current page ID
* @param event Current event ID
* @param clickListener Click event processing logic
*/
public static View.OnClickListener handleClick(String page, String event,
View.OnClickListener clickListener) {
// Here, an OnClickListener object is returned to reduce the understanding cost and code change difficulty of the upper business party
return new View.OnClickListener() {
@Override
public void onClick(View v) {
// Retrieve the distribution configuration of the current event
Action action = getClickActionIfExists(page, event);
if (action != null) {
// If there is configuration, follow the configuration logic
performAction(action);
} else if (clickListener != null) {
// If there is no configuration, follow the default processing logic
clickListener.onClick(v);
}
}
};
}With the above foundation, we can quickly realize the function of supporting remote dynamic change of App interaction behavior. Let's compare the code differences of the upper business party before and after this capability.
// before
addGoodsButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Router.open("https://www.xxx.com/goods/add");
}
});
// after
addGoodsButton.setOnClickListener(ActionManager.handleClick(
"goods-manager", "add-goods", new View.OnClickListener() {
@Override
public void onClick(View v) {
Router.open("https://www.xxx.com/goods/add");
}
}));It can be seen that the service side transparently transmits some identification parameters for the current context, and there are no other changes.
So far, we have completed the remote hook capability for the click event of the add goodsbutton button. If there are some reasons that make the add product page unavailable, we only need to add the following configuration in the remote dynamic configuration.
{
"hook/click/goods-manager/add-goods": {
"type": "dialog",
"title": "Tips",
"message": "because XX Reason: the add product page is temporarily unavailable",
"confirmText": "determine",
"confirmAction": {
"type": "finish"
}
}
}At this time, the user clicks the add product button again, and the above prompt message will appear.
The idea of remote interception of click events is introduced above. Corresponding to click events, there are common interactions such as page Jump and network request execution. Their principles are the same and will not be enumerated one by one.
Local configuration
In the App development and testing phase, you usually need to add some localized configurations to realize one-time compilation and construction, allowing compatibility with multiple logics. For example, in the process of joint debugging with the server interface, the App needs to make several common environment switches (daily, advance and online).
Theoretically, this demand can also be realized based on the dynamic configuration mentioned above, but the dynamic configuration is mainly for online users. If you choose to use this capability in the production and research stage, it will undoubtedly increase the complexity of online configuration and rely on the results of network requests.
Therefore, we need to abstract a set of solutions that support localized configuration, which should meet the following capabilities as much as possible
- Default value support is provided for local configuration. When no configuration is made, the configuration returns the default value. For example, the default environment is online. If the configuration is not changed, the daily and advance environments will not be read.
- Simplify the configured read-write interface and let the upper business party perceive the implementation details as little as possible. For example, we do not need to make the upper layer aware that the persistence information of the local configuration is written to SharedPreferences or SQLite, but only need to provide a written API.
- The API mode of entering the local configuration page is exposed to the upper layer to meet the space selectively entered by the upper layer. For example, through the API exposed by us, the upper layer can choose whether to click an operation button on the page, the volume key of the mobile phone, or shake to enter the configuration page during the actual use of the App.
- The control of whether the App has local configuration capability shall be placed at the compilation and construction level as far as possible to ensure that online users will not enter the configuration page. For example, if online users can enter the pre launch environment, it is likely that a security accident is brewing.
version management
In mobile clients, Android applications are different from iOS, which can only be published in the App store apk files support direct installation, which makes it possible for App silent upgrade. Based on this feature, we can realize the user's demand to directly detect and upgrade the new version without passing the application market, shorten the user's App upgrade path, and then improve the coverage when the new version is released.
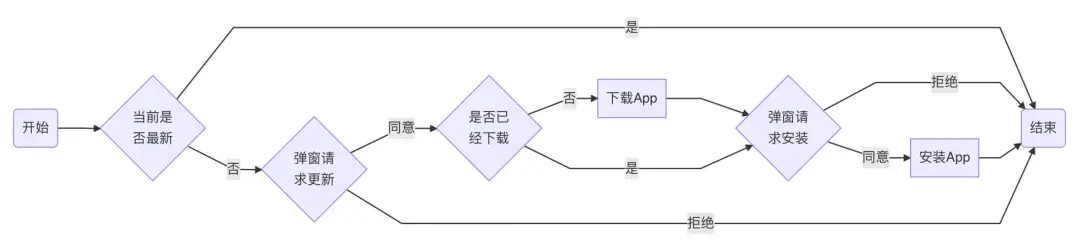
We need to consider the ability to abstract version detection and upgrade in the application. Here, the server needs to provide an interface to detect and obtain the new version of App. Based on a certain policy, for example, each time the client just enters the App or manually clicks the new version detection, the client calls the version detection interface of the server to judge whether the current App is the latest version. If the current version is a new version, provide the apk file download link of the latest version on the App side, and the client downloads the version in the background. The flow chart of the core steps is summarized below
Log monitoring
Environment isolation, local persistence, log reporting
The log monitoring of the client is mainly used to check the user's Crash and other abnormal problems in the process of using the App. For the log part, several points worth noting are summarized
- The environment is isolated, and log output is prohibited in the release package;
- For local persistence, key and important logs (such as Crash caused by a location error) should be saved locally;
- Log reporting: upload the temporary user's local log and analyze the specific operation link if the user's authorization allows;
Two open source logging frameworks are recommended:
logger
timber

Buried point statistics
What the server can query is the number and frequency of client interface calls, but it cannot perceive the user's specific operation path. In order to get a clearer understanding of users and analyze the advantages, disadvantages and bottlenecks of products, we can collect and report the core operation paths of users on the App.
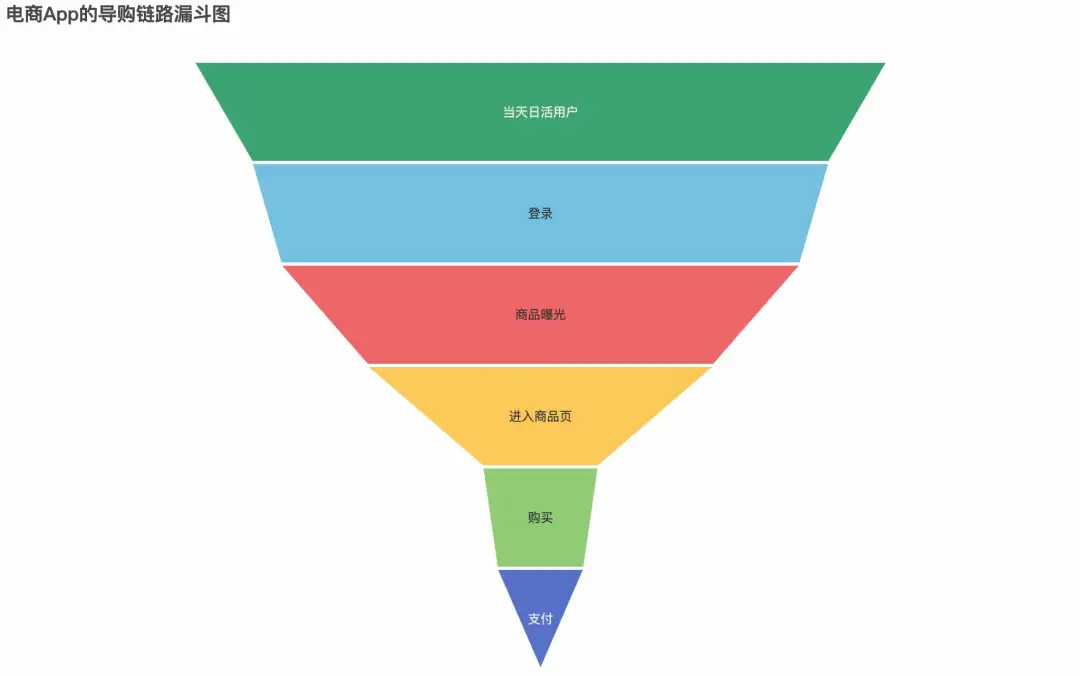
For example, the following is a user transaction funnel diagram of e-commerce App. The data of each layer of the funnel can be obtained through the buried point statistics of the client, and then the visual report can be made through data production.
By analyzing the following funnel, we can clearly see that the key node of transaction loss is between "entering the commodity page" and "buying". Therefore, next, we need to think about why users entering the commodity page are less willing to buy? Is it because of the product itself or the product interaction on the product page? Is it because the purchase button is difficult to click? Or is the product introduction not displayed because the picture on the product page is too large? What is the length of stay of these lost pages? Thinking about these problems will further urge us to add more abtests and more fine-grained buried point statistical analysis in the commodity page. To sum up, buried point statistics provide a very important guiding significance for user behavior analysis and product optimization.
On the technical side, the following key points are summarized for this part
- The embedded point of the client is generally divided into point P (page level), point E (event level) and point C (user-defined point);
- Buried points are divided into two steps: collection and reporting. When the user level is large, pay attention to the optimization processing such as merging and compressing the reported buried points;
- The buried point logic is the auxiliary logic, and the product business is the main logic. When the client resources are tight, it is necessary to balance the resource allocation;
hot fix
Hotfix is a technical solution to dynamically update the original code logic of the released App without application upgrade. It is mainly the same as the following scenarios
- When the application has major defects and seriously affects the use of users, for example, on some models with strong system customization (such as Xiaomi Series), the application Crash appears once entering the commodity details page;
- When the application has obvious blocking problems and affects the normal interaction of users, for example, in some extreme scenarios, users cannot close the page dialog box;
- Product form problems such as asset loss, customer complaint and public opinion storm occur in the application, such as misdisplaying the price unit "Yuan" as "points";
The research on technical solutions related to hot repair can be extended to a large space. The positioning of this paper is the overall architecture of Android project, so it will not be carried out in detail.
3 application layer
Abstraction and encapsulation
For abstraction and encapsulation, it mainly depends on our ability to perceive and think about some pain points and redundant Coding in our daily Coding process.
For example, the following is the standard implementation logic of a list page often written during Android development
public class GoodsListActivity extends Activity {
private final List< GoodsModel> dataList = new ArrayList<>();
private Adapter adapter;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_goods_list);
RecyclerView recyclerView = findViewById(R.id.goods_recycler_view);
recyclerView.setLayoutManager(new LinearLayoutManager(this));
adapter = new Adapter();
recyclerView.setAdapter(adapter);
// Load data
dataList.addAll(...);
adapter.notifyDataSetChanged();
}
private class Adapter extends RecyclerView.Adapter< ViewHolder> {
@NonNull
@Override
public ViewHolder onCreateViewHolder(@NonNull ViewGroup parent, int position) {
LayoutInflater inflater = LayoutInflater.from(parent.getContext());
View view = inflater.inflate(R.layout.item_goods, parent, false);
return new ViewHolder(view);
}
@Override
public void onBindViewHolder(@NonNull ViewHolder holder, int position) {
GoodsModel model = dataList.get(position);
holder.title.setText(model.title);
holder.price.setText(String.format("%.2f", model.price / 100f));
}
@Override
public int getItemCount() {
return dataList.size();
}
}
private static class ViewHolder extends RecyclerView.ViewHolder {
private final TextView title;
private final TextView price;
public ViewHolder(View itemView) {
super(itemView);
title = itemView.findViewById(R.id.item_title);
price = itemView.findViewById(R.id.item_price);
}
}
}This code seems to have no logic problems and can meet the functional demands of a list page.
For the RecyclerView framework layer, in order to provide flexibility and expansion ability of the framework, the API is designed to be atomic enough to support developers' diverse development demands. For example, RecyclerView needs to support multiple itemtypes, so it needs to do the logic of grouping and caching vitemView according to itemType internally.
However, in the actual business development process, many particularities will be put aside. Most of the lists to be displayed on our page are single itemType. After writing many lists of such single itemType, we began to think about some problems:
- Why should I write a ViewHolder for every list?
- Why should an Adapter be written for each list?
- Why should the creation and data binding of itemView in the Adapter be separated into two methods, onCreateViewHolder and onBindViewHolder?
- Why does the Adapter call the corresponding notifyXXX method every time it sets data?
- Why does it take dozens of lines of code to implement a simple list on Android? How many of these are necessary and how many can be abstractly encapsulated?
Thinking about the above problems finally led me to encapsulate the auxiliary class of RecyclerViewHelper. Compared with the standard implementation, users can save cumbersome Adapter and ViewGolder declarations and some high-frequency and necessary code logic. They only need to focus on the core function implementation, as shown below
public class GoodsListActivity extends Activity {
private RecyclerViewHelper< GoodsModel> recyclerViewHelper;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_goods_list);
RecyclerView recyclerView = findViewById(R.id.goods_recycler_view);
recyclerViewHelper = RecyclerViewHelper.of(recyclerView, R.layout.item_goods,
(holder, model, position, itemCount) -> {
TextView title = holder.getView(R.id.item_title);
TextView price = holder.getView(R.id.item_price);
title.setText(model.title);
price.setText(String.format("%.2f", model.price / 100f));
});
// Load data
recyclerViewHelper.addData(...);
}
}The above is just an introduction. In the actual development process, we will encounter many similar situations, as well as some common encapsulation. For example, encapsulating globally unified BaseActivity and BaseFragment includes but is not limited to the following capabilities
- Page embedding points: collect and report the interaction of user pages when users enter and leave the page based on the above-mentioned embedding point statistics;
- Public UI, status bar and action bar at the top of the page, implementation of common drop-down refresh capability of the page, and loading progress bar during page time-consuming operation;
- Permission processing: permission application required to enter the current page, callback logic after user authorization and exception processing logic after rejection;
- Unified interception, combined with the unified interception mentioned above, add the customization ability to support dynamic configuration interaction after entering the page;
modularization
background
The modularization mentioned here refers to the modular splitting of project projects based on App business functions, mainly to solve the difficult problem of collaborative development of large and complex business projects.
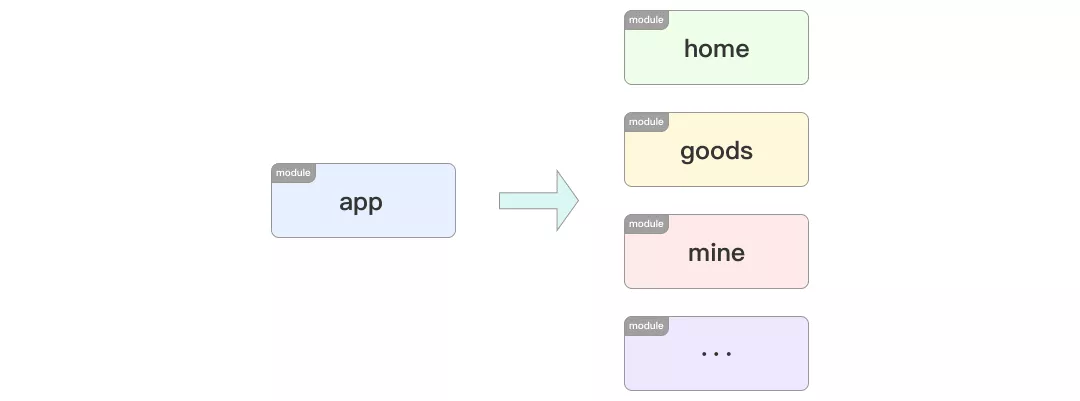
In the transformation of the project structure, as shown in the figure above, the original app module carrying all businesses is divided into home, goods, mine and other business modules.
General capability sinking
Common business capabilities such as BaseActivity and BaseFragment mentioned in the previous chapter "abstraction and encapsulation" also need to be transformed synchronously after the project is modularized. They need to sink into a separate base module in the business layer so that they can be referenced by other business modules.
Implicit routing transformation
After modularization, there is no interdependence between modules. At this time, when jumping across modules, you cannot directly reference the classes of other modules.
For example, when a product recommendation is displayed on the home page, click to jump to the product details page. Before modularization, the writing method is

However, after modularization, the GoodsActivity class cannot be referenced in the home page module, so the page Jump cannot continue the previous method. The implicit routing transformation needs to be carried out on the page, as shown below
1. Register the Activity ID in androidmanifest Add the action ID where the Activity is registered in the XML

2. Replace the jump logic, and the code will implicitly jump according to the Activity ID registered in the previous step

Based on these two steps of transformation, we can achieve the purpose of normal jump to the business page after modularization.
Further, we abstract and encapsulate the logic of implicit jump to extract a static method that specifically provides implicit routing capability. Refer to the following code
public class Router {
/**
* Jump to the target page according to the url
*
* @param context Current page context
* @param url Destination page url
*/
public static void open(Context context, String url) {
// Resolve to Uri object
Uri uri = Uri.parse(url);
// Get url without parameters
String urlWithoutParam = String.format(
"%s://%s%s", uri.getScheme(), uri.getHost(), uri.getPath());
Intent intent = new Intent(urlWithoutParam);
// Parse the parameters in the url and pass them to the next page through Intent
for (String paramKey : uri.getQueryParameterNames()) {
String paramValue = uri.getQueryParameter(paramKey);
intent.putExtra(paramKey, paramValue);
}
// Perform jump operation
context.startActivity(intent);
}
}At this time, when the external page jumps, you only need to call it through the following sentence
Router.open(this, "https://www.xxx.com/goods/detail?goodsId=" + model.goodsId);
This package is OK
- Abstract unified method to reduce external coding cost;
- Unified gateway routing logic, which is convenient for dynamic change of online App routing logic in combination with the previous chapters of "dynamic configuration" and "unified interception";
- Standardize the format of page Jump parameters on the Android side, and uniformly use the String type to remove the ambiguity of type judgment when parsing parameters on the target page;
- Standardized support is provided for the data required to jump to the page. After the iOS side cooperates with the synchronous transformation, the page Jump logic will support full distribution by the business server;
Module communication
Another problem that needs to be solved after modularization is module communication. Modules without direct dependency cannot get any other API to call directly. This problem is often analyzed and handled according to the following categories
1. Notification communication only needs to inform the other party of the event and does not pay attention to the response results of the other party. For this kind of communication, the following methods are generally adopted
- Send events through Intent + BroadcastReceiver (or local broadcastmanager) with the help of the provided by the framework layer;
- Send events with the framework EventBus;
- Sending events based on the observer mode from the implementation message forwarder;
2. Call communication is used to inform the other party of events and pay attention to the event response results of the other party. For this kind of communication, the following methods are generally adopted
- The biz service module is defined, the business interface interface file is imported to the module, and then the business module with the corresponding semantics of each interface implements the interface, and then completes the registration of the implementation class based on some mechanism (manual registration or dynamic scanning);
Abstract the communication protocol of request = > response, and the protocol layer is responsible for completing it
- First, route the Request passed through the caller to the protocol implementation layer of the callee;
- Then, the returned result of the implementation layer is transformed into a generalized Response object;
- Finally, return the Response to the caller;
Compared with biz service, the middle layer of this scheme does not contain any business semantics, and only defines the key parameters required for generalization calls.
4 cross platform layer
The cross platform layer is mainly to improve the developer efficiency. A set of code can run on multiple platforms.
Generally, there are two opportunities for cross platform access. One is that in the initial preliminary project research stage, the direct technology selection is a pure cross platform technology scheme; The other is the stage where the cross platform capability needs to be integrated in the existing Native project. At this time, the App belongs to the mixed development mode, that is, the combination of Native + cross platform.
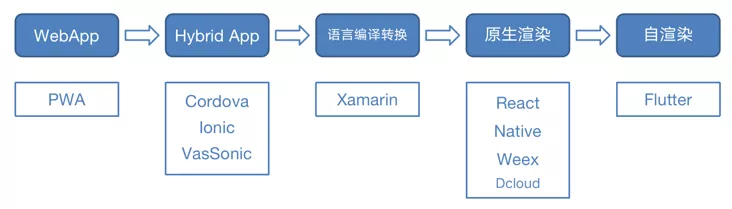
More cross platform selection and details are not within the scope of this paper. For details, please refer to analysis and selection of mobile cross platform development framework. This paper describes in detail the development of the whole cross platform technology, the principles, advantages and disadvantages of each framework. Refer to cross platform technology evolution diagram
For the comparison of current mainstream schemes, please refer to the table below
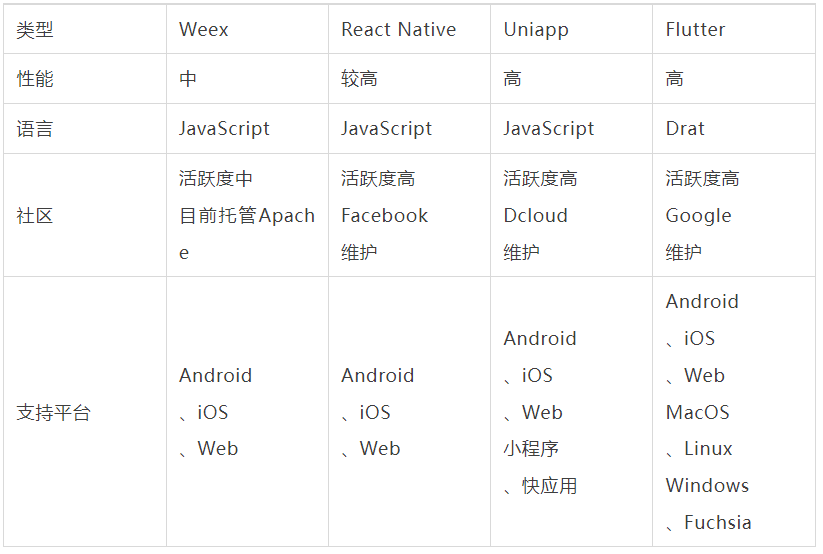
The main modules of each layer in the project architecture are disassembled and analyzed one by one. Next, some very core principles used in architecture design and actual development will be summarized and combed.
IV. summary of core principles
In Android development, we will come into contact with countless frameworks, and these frameworks are still constantly updated and iterated, so it is difficult for us to know every framework like the back of our hand.
However, this does not affect our study and Research on the core technologies in Android. If you have tried to deeply analyze the underlying principles of these frameworks, you will find that many of them are interlinked. Once we master these core principles, we will find that the vast majority of frameworks just use these principles, combined with the core problems to be solved by the framework, and then packaged as general technical solutions.
Below, I will sort out and summarize some core principles that are frequently used in SDK framework and actual development.
1 dual cache
Dual cache refers to the technical scheme of adding double-layer cache in memory and disk to improve the acquisition speed when obtaining some resources through the network. At first, this scheme is mainly used in the picture library mentioned in the "picture module" above. The picture library uses double cache to greatly improve the loading speed of pictures. A standard dual cache scheme is shown below
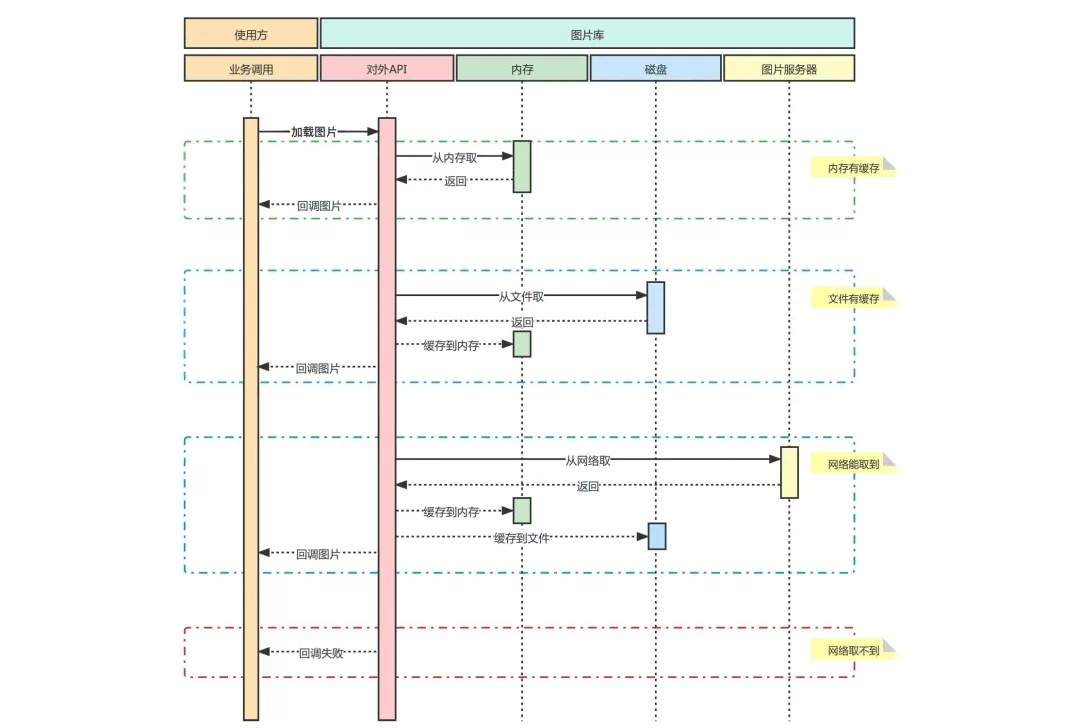
The core idea of the dual cache scheme is to trade space for time as much as possible for network resources with low timeliness or less changes. We know the general data acquisition efficiency: memory > disk > network. Therefore, the essence of this scheme is to copy the resources from the channels with low acquisition efficiency to the ones with high efficiency.
Based on this scheme, we can also expand another scenario in the actual development. For some interface data with low timeliness or less changes in business, in order to improve their loading efficiency, we can also package them in combination with this idea, so as to reduce the rendering time of the first frame of a page dependent on network request from a general few hundred ms to less than tens of ms, and the optimization effect is quite obvious.
2 thread pool
Thread pools are frequently used in Android development, such as
- In the development framework, the network library and picture library need thread pool to obtain network resources;
- In project development, thread pool is required for IO operations such as reading and writing SQLite and local disk files;
- In the API that provides task scheduling, such as AsyncTask, its bottom layer also depends on thread pool;
Thread pools are used in so many scenarios. If we want to grasp the overall view of the project more clearly, it is particularly important to be familiar with some core competencies and internal principles of thread pools.
As far as the API exposed directly is concerned, there are two core methods: thread pool construction method and sub task execution method.
// Construct thread pool
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize,
keepAliveTime, keepAliveTimeUnit, workQueue, threadFactory, rejectedExecutionHandler);
// Submit subtasks
executor.execute(new Runnable() {
@Override
public void run() {
// Do subtask operations here
}
});Among them, submitting a subtask is to pass in an object instance of Runnable type, which will not be repeated. It should be emphasized that it is also the core of the thread pool, and several parameters in the construction method.
// Number of core threads
int corePoolSize = 5;
// Maximum number of threads
int maximumPoolSize = 10;
// Idle thread lifetime
int keepAliveTime = 1;
// Keeping alive time unit
TimeUnit keepAliveTimeUnit = TimeUnit.MINUTES;
// Blocking queue
BlockingDeque< Runnable> workQueue = new LinkedBlockingDeque<>(50);
// Thread factory
ThreadFactory threadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r);
}
};
// Handling strategy of task overflow
RejectedExecutionHandler rejectedExecutionHandler = new ThreadPoolExecutor.AbortPolicy();There are many articles and tutorials about thread pool on the Internet. Each specific parameter is not repeated here; But I'm going to explain separately the torsion mechanism after subtask submission, which is very important to understand the internal principle of thread pool.

The above figure shows the processing mechanism of tasks in the thread pool when subtasks are constantly submitted to the thread pool and the task has no time to execute. This figure is particularly important for understanding the internal principle of the thread pool and configuring thread pool parameters.
3 reflection and annotation
Reflection and annotation are both officially provided technical capabilities in the Java language. The former is used to dynamically read and write object instance (or static) properties and execute object (static) methods during program operation; The latter is used to add annotation information to specified fields such as classes, methods, method input parameters, class member variables and local variables.
Through reflection and annotation technology, combined with code abstraction and encapsulation thinking, we can flexibly realize the demands of many generalized calls, such as
- In the previous "hot fix" chapter, the internal implementation of the solution based on ClassLoader is almost all dex changed through reflection;
- In the previous "network module" chapter, retrofit only needs to declare an interface and add annotations. Its bottom layer also uses reflection annotations and dynamic proxy technology to be introduced below;
- Dependency injection frameworks dagger and Android annotations use Java's APT precompiling technology and compile time annotations to generate injection code;
- If you understand the development of Java server, the mainstream development framework SpringBoot makes a lot of use of injection and annotation technology;
What are the applicable scenarios for reflection and annotation in development? Here are some points
Dependency injection scenario
Common way
public class DataManager {
private UserHelper userHelper = new UserHelper();
private GoodsHelper goodsHelper = new GoodsHelper();
private OrderHelper orderHelper = new OrderHelper();
}Injection mode
public class DataManager {
@Inject
private UserHelper userHelper;
@Inject
private GoodsHelper goodsHelper;
@Inject
private OrderHelper orderHelper;
public DataManager() {
// Inject object instances (internally implemented by reflection + annotation)
InjectManager.inject(this);
}
}The advantage of injection method is to shield the instantiation process of dependent objects for the user, so as to facilitate the unified management of dependent objects.
Calling private or hidden API scenarios
There is a class that contains private methods.
public class Manager {
private void doSomething(String name) {
// ...
}
}After we get the object instance of the Manager, we want to call the private method doSomething. According to the general calling method, there is no solution if we do not change the method to public. But you can do it with reflection
try {
Class< ?> managerType = manager.getClass();
Method doSomethingMethod = managerType.getMethod("doSomething", String.class);
doSomethingMethod.setAccessible(true);
doSomethingMethod.invoke(manager, "< name parameter>");
} catch (Exception e) {
e.printStackTrace();
}There will be many such scenarios in development. It can be said that mastering reflection and annotation technology is not only the performance of Java high-level language features, but also allows us to improve our cognition and perspective when abstracting and encapsulating some general capabilities.
4 dynamic agent
Dynamic agent is a technical scheme that can provide agent capability for a specified interface during program operation.
When using dynamic proxy, it is usually accompanied by the application of reflection and annotation, but compared with reflection and annotation, the role of dynamic proxy is relatively obscure and difficult to understand. Let's look at the role of dynamic agents in a specific scenario.
background
In the process of project development, it is necessary to call the server interface, so the client encapsulates a general method of network request.
public class HttpUtil {
/**
* Execute network request
*
* @param relativePath url Relative path
* @param params Request parameters
* @param callback Callback function
* @param < T> Response result type
*/
public static < T> void request(String relativePath, Map< String, Object> params, Callback< T> callback) {
// Implementation strategy
}
}Since there are multiple pages in the business that need to query the product list data, it is necessary to encapsulate an interface of GoodsApi.
public interface GoodsApi {
/**
* Pagination query commodity list
*
* @param pageNum Page index
* @param pageSize Amount of data per page
* @param callback Callback function
*/
void getPage(int pageNum, int pageSize, Callback< Page< Goods>> callback);
}Add the GoodsApiImpl implementation class for this interface.
public class GoodsApiImpl implements GoodsApi {
@Override
public void getPage(int pageNum, int pageSize, Callback< Page< Goods>> callback) {
Map< String, Object> params = new HashMap<>();
params.put("pageNum", pageNum);
params.put("pageSize", pageSize);
HttpUtil.request("goods/page", params, callback);
}
}Based on the current encapsulation, the service can be called directly.

problem
The business needs to add the following interface to query product details.

We need to add implementation logic to the implementation class.

Next, we need to add the create and update interfaces, and we will continue to implement them.

Not only that, we need to add OrderApi, ContentApi, UserApi, and so on, and each class needs these lists. We will find that every time the business needs to add a new interface, we have to write a call to the HttpUtil#request method, and this calling code is very mechanized.
analysis
We mentioned the mechanization of interface implementation code. Next, we try to abstract this mechanized code into a pseudo code call template, and then analyze it.

Looking at the core essence of each method through the phenomenon of internal code implementation, we can abstract it into the above "template" logic.
Is there a technology that allows us to write only the relevant parameters of the request protocol necessary for the network request without repeating the trivial coding in the following steps every time?
- Manually write a Map;
- Insert parameter key value pairs into the Map;
- Call HttpUtil#request to execute the network request;
At this point, the dynamic agent can solve this problem.
encapsulation
Define path and parameter annotations respectively.
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface Path {
/**
* @return Interface path
*/
String value();
}@Target({ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
public @interface Param {
/**
* @return Parameter name
*/
String value();
}Based on these two annotations, the dynamic agent implementation can be encapsulated (the following code ignores parameter verification and boundary processing logic in order to demonstrate the core link).
@SuppressWarnings("unchecked")
public static < T> T getApi(Class< T> apiType) {
return (T) Proxy.newProxyInstance(apiType.getClassLoader(), new Class[]{apiType}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// Resolve interface path
String path = method.getAnnotation(Path.class).value();
// Resolve interface parameters
Map< String, Object> params = new HashMap<>();
Parameter[] parameters = method.getParameters();
// Note: one more bit is offset here to skip the last callback parameter
for (int i = 0; i < method.getParameterCount() - 1; i++) {
Parameter parameter = parameters[i];
Param param = parameter.getAnnotation(Param.class);
params.put(param.value(), args[i]);
}
// Take the last parameter as the callback function
Callback< ?> callback = (Callback< ?>) args[args.length - 1];
// Execute network request
HttpUtil.request(path, params, callback);
return null;
}
});
}effect
At this time, you need to add the necessary information required by the network request at the interface declaration through annotation.
public interface GoodsApi {
@Path("goods/page")
void getPage(@Param("pageNum") int pageNum, @Param("pageNum") int pageSize, Callback< Page< Goods>> callback);
@Path("goods/detail")
void getDetail(@Param("id") long id, Callback< Goods> callback);
@Path("goods/create")
void create(@Param("goods") Goods goods, Callback< Goods> callback);
@Path("goods/update")
void update(@Param("goods") Goods goods, Callback< Void> callback);
}Obtain the interface instance through ApiProxy externally.
// before GoodsApi goodsApi = new GoodsApiImpl(); // Now? GoodsApi goodsApi = ApiProxy.getApi(GoodsApi.class);
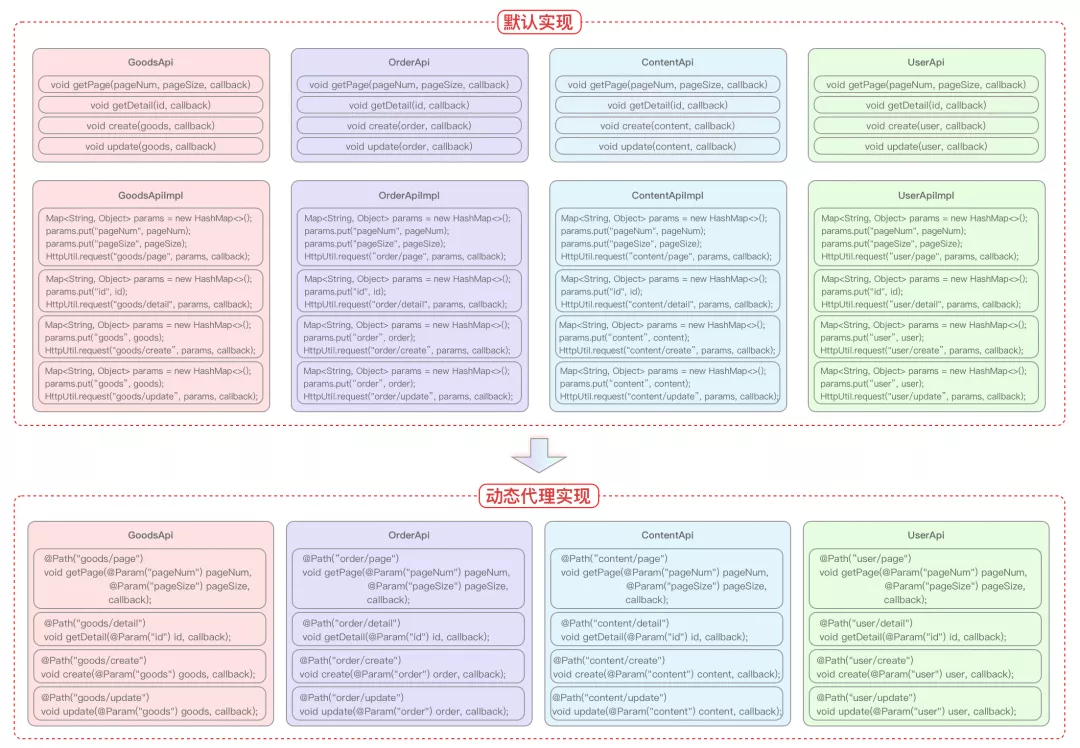
Compared with before, the calling mode of the upper layer has only minimal adjustment; However, the internal implementation has been greatly improved. All interface implementation logic is directly omitted. Refer to the following code comparison diagram.
We talked about the core framework principles involved in the architecture design process, and then we will talk about the general design scheme in the architecture design.
V. general design scheme
The architecture design scenarios are usually different, but the underlying design schemes of some problems are interlinked. This chapter will summarize these interlinked design schemes.
Communication design
In A word, the essence of communication is to solve the problem of how to call between A and B. next, it is analyzed one by one according to the abstract AB model dependency.
Direct dependency
Relational paradigm: a = > b
This is the most common association relationship. Class A directly depends on B, which can be completed only through the most basic method call and callback setting.

scene
The relationship between page Activity (A) and Button (B).
Reference code

Indirect dependency
Relational paradigm: a = > C = > b
The communication mode is the same as that of direct dependence, but an intermediate layer needs to be added for transparent transmission.

scene
The page Activity (A) contains the goodcard view (C), and the product card contains the follow Button (B).
Reference codes C and B communication
public class GoodsCardView extends FrameLayout {
private final Button button;
private OnFollowListener followListener;
public GoodsCardView(Context context, AttributeSet attrs) {
super(context, attrs);
// Slightly
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (followListener != null) {
// C callback B
followListener.onFollowClick();
}
}
});
}
public void setFollowText(String followText) {
// C calls B
button.setText(followText);
}
public void setOnFollowClickListener(OnFollowListener followListener) {
this.followListener = followListener;
}
}Communication between A and C
public class MainActivity extends Activity {
private GoodsCardView goodsCard;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// Slightly
// A calls C
goodsCard.setFollowText("Click the product to follow");
goodsCard.setOnFollowClickListener(new OnFollowListener() {
@Override
public void onFollowClick() {
// C callback A
}
});
}
}synthetic relation
Relational paradigm: a < = C = > b
The communication mode is similar to indirect dependency, but the calling order of one party needs to be inverted.

scene
The page Activity (C) contains the list RecyclerView (A) and the top icon ImageView (B). When you click top, the list needs to scroll to the top.
Reference code
public class MainActivity extends Activity {
private RecyclerView recyclerView;
private ImageView topIcon;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// Slightly
topIcon.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
// B callback C
onTopIconClick();
}
});
recyclerView.addOnScrollListener(new RecyclerView.OnScrollListener() {
@Override
public void onScrollStateChanged(RecyclerView recyclerView, int newState) {
// A callback C
if (newState == RecyclerView.SCROLL_STATE_IDLE) {
LinearLayoutManager layoutManager = (LinearLayoutManager) recyclerView.getLayoutManager();
onFirstItemVisibleChanged(layoutManager.findFirstVisibleItemPosition() == 0);
}
}
});
}
private void onFirstItemVisibleChanged(boolean visible) {
// C calls B
topIcon.setVisibility(visible ? View.GONE : View.VISIBLE);
}
private void onTopIconClick() {
// C calls A
recyclerView.scrollToPosition(0);
// C calls B
topIcon.setVisibility(View.GONE);
}
}Deep dependency / combination relationship
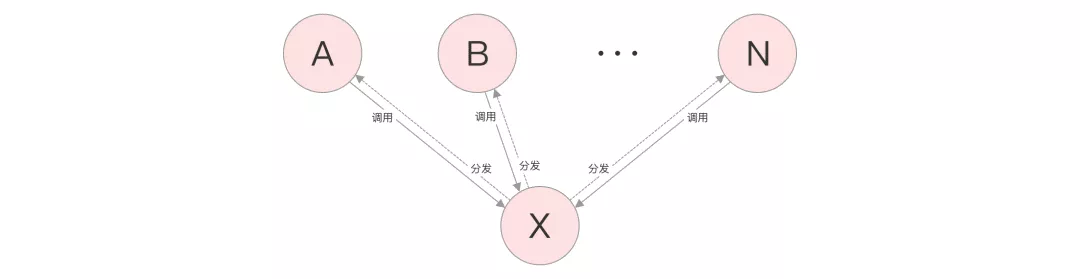
Relational paradigm: a = > C = > ·· = > b, a < = C = > ·· = > b
When the dependencies are separated by multiple layers, the code will become very redundant by directly using the communication method of ordinary call and setting callback. Most of the middle layers do information transparent logic. At this time, another method is adopted to distribute events through the event manager.
scene
After page componentization, component A needs to notify component B of an event.
Reference code
Event manager
public class EventManager extends Observable< EventManager.OnEventListener> {
public interface OnEventListener {
void onEvent(String action, Object... args);
}
public void dispatch(String action, Object... args) {
synchronized (mObservers) {
for (OnEventListener observer : mObservers) {
observer.onEvent(action, args);
}
}
}
}A calls X
public class AComponent {
public static final String ACTION_SOMETHING = "a_do_something";
private final EventManager eventManager;
public AComponent(EventManager eventManager) {
this.eventManager = eventManager;
}
public void sendMessage() {
// A calls X
eventManager.dispatch(ACTION_SOMETHING);
}
}X distribution B
public class BComponent {
private final EventManager eventManager;
public BComponent(EventManager eventManager) {
this.eventManager = eventManager;
eventManager.registerObserver(new EventManager.OnEventListener() {
@Override
public void onEvent(String action, Object... args) {
if (AComponent.ACTION_SOMETHING.equals(action)) {
// X distribution B
}
}
});
}
}It doesn't matter
Relational paradigm: A, B
This refers to the irrelevance of the narrow concept, because in the broad concept, if there is no correlation between the two, they can never communicate.
The communication of this relationship also relies on the event manager. The only difference is that the way to obtain the EventManager object instance is different. It is no longer obtained directly from the current context, but from the globally unique instance object, such as from a single instance.
Design of extensible callback function
background
When we package an SDK, we need to add external callback functions, as shown below.
Callback function
public interface Callback {
void onCall1();
}SDK core class
public class SDKManager {
private Callback callback;
public void setCallback(Callback callback) {
this.callback = callback;
}
private void doSomething1() {
// Slightly
if (callback != null) {
callback.onCall1();
}
}
}External customer call
SDKManager sdkManager = new SDKManager();
sdkManager.setCallback(new Callback() {
@Override
public void onCall1() {
}
});problem
The above is a very common callback setting method. If it is only for business development, there is no problem with this writing method, but if it is made into an SDK for external customers, this method will have defects.
In this way, if the SDK has been provided to external customers, some callbacks need to be added to the outside.
public interface Callback {
void onCall1();
void onCall2();
}If you add callbacks in this way, you cannot upgrade without awareness during external upgrade. The following code will report an error and need to add additional implementation.
sdkManager.setCallback(new Callback() {
@Override
public void onCall1() {
}
});To avoid external perception, another solution is to create an interface.
public interface Callback2 {
void onCall2();
}Then add support for this method in the SDK.
public class SDKManager {
// Slightly
private Callback2 callback2;
public void setCallback2(Callback2 callback2) {
this.callback2 = callback2;
}
private void doSomething2() {
// Slightly
if (callback2 != null) {
callback2.onCall2();
}
}
}Correspondingly, the settings of callback functions need to be added during external calls.
sdkManager.setCallback2(new Callback2() {
@Override
public void onCall2() {
}
});This solution can indeed solve the problem that external SDK s cannot be upgraded silently, but it will bring other problems. With each interface upgrade, there will be more and more external code to set callback functions.
External optimization
For this problem, we can set an empty callback function base class.
public interface Callback {
}SDK callback functions inherit it.
public interface Callback1 extends Callback {
void onCall1();
}
public interface Callback2 extends Callback {
void onCall2();
}The SDK receives the base class callback function when setting the callback. The callback is judged according to the type.
public class SDKManager {
private Callback callback;
public void setCallback(Callback callback) {
this.callback = callback;
}
private void doSomething1() {
// Slightly
if ((callback instanceof Callback1)) {
((Callback1) callback).onCall1();
}
}
private void doSomething2() {
// Slightly
if ((callback instanceof Callback2)) {
((Callback2) callback).onCall2();
}
}
}Then provide an empty implementation class of the callback function to the outside.
public class SimpleCallback implements Callback1, Callback2 {
@Override
public void onCall1() {
}
@Override
public void onCall2() {
}
}At this time, the external can choose to set the callback function through a variety of methods, such as single interface, composite interface and empty implementation class.
// Single interface setting callback
sdkManager.setCallback(new Callback1() {
@Override
public void onCall1() {
// ..
}
});
// Combination interface setting callback
interface CombineCallback extends Callback1, Callback2 {
}
sdkManager.setCallback(new CombineCallback() {
@Override
public void onCall1() {
// ..
}
@Override
public void onCall2() {
// ...
}
});
// Set callback by empty implementation class
sdkManager.setCallback(new SimpleCallback() {
@Override
public void onCall1() {
// ..
}
@Override
public void onCall2() {
//..
}
});Now, if the SDK expands the callback, you only need to add a new callback interface.
public interface Callback3 extends Callback {
void onCall3();
}Add new callback logic internally.
private void doSomething3() {
// Slightly
if ((callback instanceof Callback3)) {
((Callback3) callback).onCall3();
}
}At this time, upgrading the SDK will have no impact on the previous call logic of external customers, and can achieve forward compatibility.
Internal optimization
After the previous optimization, the external does not perceive SDK changes; However, some internal codes are redundant, as follows.
private void doSomething1() {
// Slightly
if ((callback instanceof Callback1)) {
((Callback1) callback).onCall1();
}
}It's really troublesome for the SDK to add this judgment every time it makes an external callback. Next, we will encapsulate this judgment logic separately.
public class CallbackProxy implements Callback1, Callback2, Callback3 {
private Callback callback;
public void setCallback(Callback callback) {
this.callback = callback;
}
@Override
public void onCall1() {
if (callback instanceof Callback1) {
((Callback1) callback).onCall1();
}
}
@Override
public void onCall2() {
if (callback instanceof Callback2) {
((Callback2) callback).onCall2();
}
}
@Override
public void onCall3() {
if (callback instanceof Callback3) {
((Callback3) callback).onCall3();
}
}
}Next, the SDK can directly call the corresponding methods without various redundant judgment logic.
public class SDKManager {
private final CallbackProxy callbackProxy = new CallbackProxy();
public void setCallback(Callback callback) {
callbackProxy.setCallback(callback);
}
private void doSomething1() {
// Slightly
callbackProxy.onCall1();
}
private void doSomething2() {
// Slightly
callbackProxy.onCall2();
}
private void doSomething3() {
// Slightly
callbackProxy.onCall3();
}
}Vi. summary
To do a good job in the architecture design of the project, we need to consider many aspects such as technology selection, business status, team members and future planning. With the development of business, we also need to continuously reconstruct the project and code at different stages of the project.
Business areas vary greatly, which may be e-commerce projects, social projects or financial projects; The development technology has also been iterating rapidly, perhaps using pure Native development mode, perhaps using fluent and RN development mode, or using hybrid development mode; However, in any case, the underlying principles and design ideas of these projects in architecture design are inseparable from their roots, and these things are the core competencies we really want to learn and master.
Related links:
Can Android sub threads really not update UI https://juejin.cn/post/6844904131136618510
Analysis and selection of mobile cross platform development framework: https://segmentfault.com/a/1190000039122907