
Resource Links:
Tesseract has two important github connections:
https://github.com/rmtheis/tess-two
https://github.com/tesseract-ocr/tessdata
tesseract uses:
1. Add a dependency compile'com.rmtheis:tess-two:8.0.0'(this should be familiar with)
2. Download the corresponding font library from the link to the second tessdata above, create the assets directory, and add the font library, as shown below 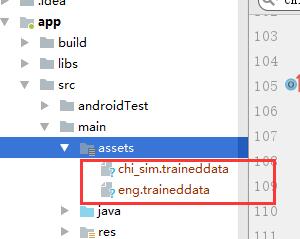
3. Coding
(1) Initialize the TessBase API
Route
private String mDataPath=Environment.getExternalStorageDirectory().getAbsolutePath()+"/tessdata/";The following create directory and copy libraries are both in the onCreate method, but activity will be blank for a short while.
//Create parent directory
File parentfile=new File(mDataPath);
if (!parentfile.exists()){
parentfile.mkdir();
}
copyFiles();//Copy the font library, see below for code
String lang = "chi_sim+eng";//Chinese Simplified + English
mTess = new TessBaseAPI();
mTess.init(mFilePath, lang);//mFilePath doesn't know?(2) Copy font library
private void copyFiles() {
//Cyclic Copy 2 Chinese Library
String[] datafilepaths = new String[]{mDataPath + "/chi_sim.traineddata",mDataPath+"/eng.traineddata"};
for (String datafilepath : datafilepaths) {
copyFile(datafilepath);
}
}
private void copyFile(String datafilepath) {
try {
String filepath = datafilepath;
String[] filesegment = filepath.split(File.separator);
String filename = filesegment[(filesegment.length - 1)];//Get the chi_sim.traineddata and eng.traineddata file names
AssetManager assetManager = getAssets();
InputStream instream = assetManager.open(filename);//Open the chi_sim.traineddata and eng.traineddata files
OutputStream outstream = new FileOutputStream(filepath);
byte[] buffer = new byte[1024];
int read;
while ((read = instream.read(buffer)) != -1) {
outstream.write(buffer, 0, read);
}
outstream.flush();
outstream.close();
instream.close();
File file = new File(filepath);
if (!file.exists()) {
throw new FileNotFoundException();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}(3) Achieving results
This step is time consuming and asynchronous AsyncTask or Rxjava is recommended
Long starttime=System.currentTimeMillis();
String OCRresult = null;
mTess.setImage(bitmap);
OCRresult = mTess.getUTF8Text();
Long endtime=System.currentTimeMillis();
Log.e("Time-consuming",(endtime-starttime)+"");Summary:
1. Recognition time for two languages is many times slower than that for a single language. Recognition speed for a small number of words is OK, but if you need to recognize a large number of words, it will almost collapse...This needs to be improved
2. I haven't added osd.traineddata to the above picture yet, trying to rotate the picture will not work well
3. The quality of recognition also depends on the picture you are working with. There are many factors.