Antlr deep learning
This document carries out in-depth study of Antlr, mainly coding through VScode and realizing some related functions in combination with Java language, so as to better understand the principle and use of Antlr.
1, Write your own TestRig test syntax
1.Antlr document preparation:
-
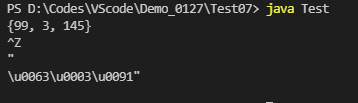
/* File name: arrayinit g4 File path: Demo_0127\Test01 Function Description: identify a sequence and output it according to hexadecimal character code For example: {99, 3145} Output: */ grammar ArrayInit ; init: '{' value ( ',' value)* '}' ; value: init | INT ; INT: [0-9]+ ; WS: [ \t\r\n] ->skip ;
2. Auxiliary Java program:
-
After writing the antlr file, generate java code
antlr4 ArrayInit.g4 javac *.java
-
/* File name: shorttonicodestring java File path: Demo_0127\Test01 Function introduction: convert integer into hexadecimal character code */ import javax.sound.sampled.SourceDataLine; //Where ArrayInitBaseListener is antlr, which is automatically generated when compiling java files public class ShortToUnicodeString extends ArrayInitBaseListener { // Translate {into“ public void enterInit(ArrayInitParser.InitContext ctx) { System.out.println('"'); } // Translate} into“ public void exitInit(ArrayInitParser.InitContext cxt) { System.out.println('"'); } //Outputs an integer as a hexadecimal character code preceded by \ u @Override public void enterValue(ArrayInitParser.ValueContext ctx) { int value = Integer.valueOf(ctx.INT().getText()); System.out.printf("\\u%04x",value); //\u stands for Unicode //04x indicates that the hexadecimal length is 4 bits, and the preceding insufficient is represented by 0 } } -
Knowledge supplement: the syntax analysis tree listener is used here
-
Syntax analysis tree listener: in order to convert the event triggered when traversing the tree into the call of the listener, the ANTLR runtime provides the pasertree Walker class. We can implement the ParseTreeListener interface by ourselves and fill it with our own logic implementation code, so as to build our own language application.
-
ANTLR generates a subclass of pastertreelistener for each syntax file. In this class, each rule in the syntax has a corresponding enter method and exit method. For example, when the traverser accesses the init rule, it will call the enterInit() method, and then pass the corresponding syntax analysis tree node - the instance of InitContext - to it as a parameter. After the traverser accesses all the child nodes of init node, it will call exitInit(). Code as above.
-
3. Main program entry:
-
/* File name: test Java File path: Demo_0127\Test01 Function introduction: the main entry of the program is equivalent to the command grun, that is, TestRig (Antlr built-in test program) */ import org.antlr.v4.runtime.*; import org.antlr.v4.runtime.tree.*; public class Test{ public static void main(String[] args) throws Exception{ //Create a new CharStream to read data from standard input ANTLRInputStream input = new ANTLRInputStream(System.in); //Create a new lexical analyzer to process the input CharStream ArrayInitLexer lexer = new ArrayInitLexer(input); //Create a new lexical symbol buffer to store the lexical symbols that will be generated by the lexical analyzer CommonTokenStream tokens = new CommonTokenStream(lexer); //Create a new parser to process the contents of lexical symbol buffer ArrayInitParser parser = new ArrayInitParser(tokens); //Start parsing for init rule ParseTree tree = parser.init(); //System.out.println(tree.toStringTree(parser)); //Create a general syntax analysis tree traverser that can trigger callback functions ParseTreeWalker walker = new ParseTreeWalker(); //Traverse the parsing tree generated in the parsing process and trigger the callback walker.walk(new ShortToUnicodeString(), tree); System.out.println(); //Print line breaks after translation } }
5. Operation results:
-
Compile and run Java files
javac *.java java Test
2, Matching arithmetic expression language
1.Antlr document preparation:
-
/* File name: expr g4 File path: Demo_0128\test01 Function: match some arithmetic expressions; For example: 193 a = 5 2 * a Note: syntax and morphology are separated here. When using morphology, it is necessary to introduce the lexical file, and import should be used after the grammar file name. */ grammar Expr ; import CommonLexerRules ; // //Starting rule, the starting point of parsing prog: stat+ ; stat: expr NEWLINE | ID '=' expr NEWLINE | NEWLINE ; expr: expr ( '*'|'/') expr | expr ( '+'|'-') expr | INT | ID | '(' expr ')' ; -
/* File name: commonlexerrules g4 File path: Demo_0128\test01 Function: lexical rules Note: the first line here is different from the syntax file. lexer should be added before */ lexer grammar CommonLexerRules ; ID: [a-zA-Z]+ ; //Match identifier NEWLINE: '\r'? '\n' ; //Tell the grammer to start a new line, that is, the statement termination flag INT: [0-9]+ ; //Match number WS: [ \t] ->skip ;
2. Input text preparation
-
Write a text input file named t.expr
-
193 a = 5 b = 6 a + b * 2 (1 + 2) * 3
# Execute the command line to generate and compile java code antlr4 Expr.g4 javac *.java
3. Main program entry:
-
/* File name: testride java File path: Demo_0128\test01 Function Description: match the text and print it in the form of text */ import java.io.FileInputStream; import java.io.InputStream; import javax.swing.InputMap; import org.antlr.v4.runtime.*; import org.antlr.v4.runtime.tree.*; public class TestRide { public static void main(String[] args) throws Exception{ //Create a new input stream for lexical analyzer to process characters String inputFile = null; if( args.length>0) { inputFile = args[0]; } InputStream is = System.in; if(inputFile != null ) { is = new FileInputStream(inputFile); } //Create a new lexical analyzer and parser object, and a lexical symbol flow pipeline between them ANTLRInputStream input = new ANTLRInputStream(is); ExprLexer lexer = new ExprLexer(input); CommonTokenStream tokens = new CommonTokenStream(lexer); ExprParser parser = new ExprParser(tokens); //Start the parser and start parsing the text ParseTree tree = parser.prog(); //Print out the syntax analysis tree returned by the rule method prog() in text form System.out.println(tree.toStringTree(parser)); } }
4. Operation results:
-
# Compile your own test code javac TestRide.java # Run and specify the file t.expr java TestRide t.expr

- Sort it out:

3, Building calculators with accessors
1.Antlr document preparation:
-
/* File name: numerical g4 File path: Demo_0128\test02 Function introduction: simple calculator simulation Note: # Represents the label of alternative branches, which enables each alternative branch to have different accessor methods, This allows you to get a different "event" for each input. The label begins with # and is placed to the right of each alternative branch These tags can be arbitrary identifiers as long as there is no rule name conflict */ grammar Calcular ; import CommonLexerRules ; //Starting rule, the starting point of parsing prog: stat+ ; stat: expr NEWLINE # printExpr | ID '=' expr NEWLINE # assign | NEWLINE # blank ; expr: expr op=( '*'|'/') expr # MulDiv | expr op=( '+'|'-') expr # AddSub | INT # int | ID # id | '(' expr ')' # parens ; -
/* File name: numerical g4 File path: Demo_0128\test02 Lexical Rules */ lexer grammar CommonLexerRules ; MUL: '*' ; //Name the '*' used in grammar, the same as below DIV: '/' ; ADD: '+' ; SUB: '-' ; ID: [a-zA-Z]+ ; //Match identifier NEWLINE: '\r'? '\n' ; //Tell the grammer to start a new line, that is, the statement termination flag INT: [0-9]+ ; //Match number WS: [ \t] ->skip ;
-
# Generate java code and compile antlr4 Calcular.g4 javac *.java
2. Rewrite the access interface:
-
First, make ANTLR automatically generate an accessor interface and generate a method for each labeled alternative branch by the following command.
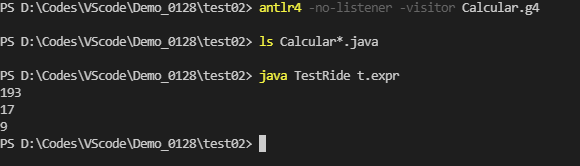
#Generate visitor interface calculation G4 Antlr file written for yourself antlr4 -no-listener -visitor Calcular.g4
For example, visitAssign indicates the branch ID '=' expr NEWLINE # assign in the antlr file
-
The interface uses the generic definition of java. The parameterized type is the type of the return value of the visit method. For simplicity, integer is used here. Therefore, the access class we rewrite should inherit the CalcularBaseVisitor class and override the methods corresponding to the expression and assignment statement rules in the accessor.
/* File name: evalvisitor java File path: Demo_0128\Test02 Function Description: override the method corresponding to the expression and assignment statement rules in the accessor. Enable to complete the corresponding calculation, storage and other functions of the calculator Note: the note before each method is the corresponding antlr copywriting rule */ import java.util.HashMap; import java.util.Map; public class EvalVisitor extends CalcularBaseVisitor<Integer> { /** Establish the "memory" of the calculator to store the corresponding relationship between variable name and variable value */ Map<String, Integer> memory = new HashMap<String, Integer>(); /** expr NEWLINE */ @Override public Integer visitPrintExpr(CalcularParser.PrintExprContext ctx) { Integer value = visit(ctx.expr()); //Calculate the value of expr child node System.out.println(value); //Print results return 0; } /** ID '=' expr NEWLINE */ @Override public Integer visitAssign(CalcularParser.AssignContext ctx) { String id = ctx.ID().getText(); //id is to the left of '=' int value = visit(ctx.expr()); //Calculates the value of the expression on the right memory.put(id, value); //Store this mapping relationship in the memory of the calculator return value; } /** '(' expr ')' */ @Override public Integer visitParens(CalcularParser.ParensContext ctx) { return visit(ctx.expr()); //Returns the value of a subexpression } /** expr op=('*'|'/') expr */ @Override public Integer visitMulDiv(CalcularParser.MulDivContext ctx) { int left = visit(ctx.expr(0)); //Evaluates the left subexpression int right = visit(ctx.expr(1)); //Evaluates the value of the subexpression on the right // Decide whether to multiply or divide if(ctx.op.getType() == CalcularParser.MUL ){ return left * right ; } return left / right; } /** expr op=('+'|'-') expr */ @Override public Integer visitAddSub(CalcularParser.AddSubContext ctx) { int left = visit(ctx.expr(0)); //Evaluates the left subexpression int right = visit(ctx.expr(1)); //Evaluates the value of the subexpression on the right // Judge whether to add or subtract if(ctx.op.getType() == CalcularParser.ADD ){ return left + right ; } return left - right; } /** ID */ @Override public Integer visitId(CalcularParser.IdContext ctx) { String id = ctx.ID().getText(); //Judge whether there is a corresponding id in the calculator memory, return the corresponding value if there is one, and return 0 if there is none if( memory.containsKey(id) ){ return memory.get(id); } return 0; } /** INT */ @Override public Integer visitInt(CalcularParser.IntContext ctx) { return Integer.valueOf(ctx.INT().getText()); } }
3. Main program entry:
-
/* File name: testride java File path: Demo_0128\Test02 Function introduction: TestRig test entry */ import java.io.FileInputStream; import java.io.InputStream; import javax.swing.InputMap; import org.antlr.v4.runtime.*; import org.antlr.v4.runtime.tree.*; public class TestRide { public static void main(String[] args) throws Exception{ //Create a new input stream for lexical analyzer to process characters String inputFile = null; if( args.length>0) { inputFile = args[0]; } InputStream is = System.in; if(inputFile != null ) { is = new FileInputStream(inputFile); } //Create a new lexical analyzer and parser object, and a lexical symbol flow pipeline between them ANTLRInputStream input = new ANTLRInputStream(is); CalcularLexer lexer = new CalcularLexer(input); CommonTokenStream tokens = new CommonTokenStream(lexer); CalcularParser parser = new CalcularParser(tokens); //Start the parser and start parsing the text ParseTree tree = parser.prog(); //Create a new custom accessor EvalVisitor eval = new EvalVisitor(); //Call the visit() method to start traversing the parsing tree returned by the prog() method eval.visit(tree); } }
4. Operation results:
-
# You need to execute the command line again, otherwise you cannot output antlr4 -no-listener -visitor Calcular.g4 # Compile all java files with utf-8 encoding javac -encoding UTF-8 *.java # Connect the file or standard input and print to view the input file (this step is optional) cat t.expr # Run the Java program and enter it in the specified file java TestRide t.expr