
01 what is data kinship
Data kinship tracking, recording and displaying where the data comes from and what conversion operations are applied in the data flow process. It helps to trace the data source and processing process.
Core functions of data kinship system:
- Automatic discovery and creation of data assets
- Automatic discovery and creation of blood relationship
- Analysis and display of blood relationship and assets from different perspectives
A concept easily confused with data kinship: data origin. Data origin focuses on tracking the original source of data, including data related collection, rules and processes, so as to help data engineers evaluate the quality of data.
02 Apache atlas and its features
Atlas is a set of scalable and scalable data governance services that enable enterprises to effectively and efficiently meet their compliance requirements in the Hadoop ecosystem and allow integration with the entire enterprise data ecosystem.
Atlas provides organizations with open metadata management and governance capabilities to establish their data asset catalog, classify and manage these assets, and provides data scientists, analysts and data governance teams with collaborative capabilities around these data assets.
- Metadata and entity
Predefined metadata types of Hadoop and non Hadoop systems.
Category and entity management based on Rest API
Automatic capture of categories and entities
- Data kinship
Automatic blood capture
Detectable data blood relationship display
Data kinship management based on Rest API
- search
You can search by data asset category, entity and attribute
Complex search based on Rest API
SQL like search language
- Security and sensitive data masking
Fine grained control of metadata access.
It integrates with Apache Ranger for entity classification based authorization and data masking.
- classification
Category auto discovery
Entity category label automation
Transmission based on kinship classification
03 data kinship Perspective
(1) Engineer's perspective
Data engineers usually want to see the blood relationship of data processing details, such as mapping, de duplicate, data masking, merge, join, update, delete, insert and other operations in the process of data processing, so as to facilitate their retrospective analysis and positioning in case of data problems.
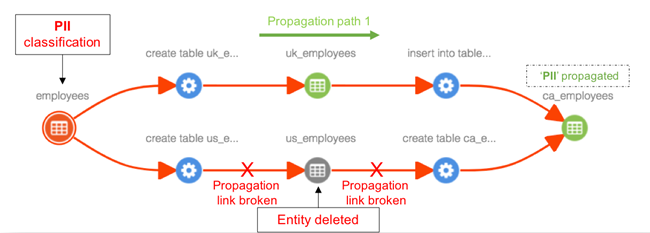
(2) Business user perspective
Business users usually want to see where the data comes from, through those key processing links, and who is responsible for each processing link. They usually don't care about operations with very technical details such as merge and join. For example:

In this typical user perspective, the leftmost data origin, crawlers, ftp and other key nodes are actually difficult to be automatically discovered and managed by Apache Atlas. In Apache Atlas, this metadata usually needs to be captured manually.
According to the characteristics of Apache Atlas version, 1.0 does not support the icon customization function of entity type. Version 2.1 supports the customization function of entity type icons. The seven bridge problem of gothensburg successfully explains that a picture is worth thousands of words. At the same time, it also gives birth to a new discipline: graph theory. Selecting entity icon types that conform to the actual business scenarios can often reduce a lot of unnecessary explanations.
Note: Apache Atlas is not a software that can be compatible with two blood perspectives at the same time. In the actual scenario, the missing key entity categories and entity information are manually captured to form a complete data blood relationship.
04 Apache Atlas Compilation and deployment
Apache Atlas provides two build modes:
- Standard mode
Standard patterns are typically used for deployment in production environments.
mvn clean -DskipTests package -Pdist
*Slide left to see more
- Embedded mode
The embedded build pattern provides out of the box functionality, which is usually used in PoC or small-scale scenarios.
- Prepackaged Hbase and Solr
mvn clean -DskipTests package -Pdist,embedded-hbase-solr
*Slide left to see more
Among them, Hbase provides storage for Atlas library, while Solr is responsible for providing search for atlas.
- Prepackaged Cassandra and Solr
mvn clean package -Pdist,embedded-cassandra-solr
*Slide left to see more
Cassandra provides storage for Atlas library, while Solr is responsible for providing search for atlas.
No matter which construction mode is selected, avoid configuring Alibaba's Maven image warehouse. The construction cannot be completed due to the lack of some dependent packages. During the construction process, at least 20GB of free space is guaranteed, and the construction will be completed in less than 2 hours.
Take embedded HBase Solr as an example to deploy a rapid prototyping environment.
#!/bin/bash
# This script was tested in EMR 6.3 environment.
# The "embedded Apache HBase & Apache Solr" was tested.
# Create apache directory
sudo mkdir /apache
sudo chown hadoop.hadoop /apache
# Download JDK
cd /apache
wget https://corretto.aws/downloads/latest/amazon-corretto-11-x64-linux-jdk.tar.gz
tar xzf amazon-corretto-11-x64-linux-jdk.tar.gz
# Download Atlas-2.1.0
# ---------------start---------------
cd /apache
# Please upload your compiled distribution package into your bucket and grant read permission.
curl -O https://your-s3-bucketname.s3.amazonaws.com/apache-atlas-2.1.0-bin.tar.gz
tar xzf apache-atlas-2.1.0-bin.tar.gz
# Configuration
# atlas-env.sh
# 20 export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64
sed -i "s%.*export JAVA_HOME.*%export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64%" /apache/apache-atlas-2.1.0/conf/atlas-env.sh
sed -i "s%.*export JAVA_HOME.*%export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64%" /apache/apache-atlas-2.1.0/hbase/conf/hbase-env.sh
# atlas-application.properties
# 104 atlas.notification.embedded=false
# 106 atlas.kafka.zookeeper.connect=localhost:2181
# 107 atlas.kafka.bootstrap.servers=localhost:9092
sed -i "s/atlas.graph.index.search.solr.zookeeper-url.*/atlas.graph.index.search.solr.zookeeper-url=localhost:9983" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.notification.embedded=.*/atlas.notification.embedded=false/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.kafka.zookeeper.connect=.*/atlas.kafka.zookeeper.connect=localhost:9983/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.kafka.bootstrap.servers=.*/atlas.kafka.bootstrap.servers=localhost:9092/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.audit.hbase.zookeeper.quorum=.*/atlas.audit.hbase.zookeeper.quorum=localhost/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
# ---------------end---------------
# Solr start
# ---------------start---------------
# Export environment variable
export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64
export SOLR_BIN=/apache/apache-atlas-2.1.0/solr/bin
export SOLR_CONF=/apache/apache-atlas-2.1.0/conf/solr
# Startup solr
$SOLR_BIN/solr start -c
# Initialize the index
$SOLR_BIN/solr create_collection -c vertex_index -d $SOLR_CONF
$SOLR_BIN/solr create_collection -c edge_index -d $SOLR_CONF
$SOLR_BIN/solr create_collection -c fulltext_index -d $SOLR_CONF
# ---------------end---------------
# Config the hive hook
# ---------------start---------------
sudo sed -i "s#</configuration># <property>\n <name>hive.exec.post.hooks</name>\n <value>org.apache.atlas.hive.hook.HiveHook</value>\n </property>\n\n</configuration>#" /etc/hive/conf/hive-site.xml
sudo cp /apache/apache-atlas-2.1.0/conf/atlas-application.properties /etc/hive/conf
sudo sed -i 's%export HIVE_AUX_JARS_PATH.*hcatalog%export HIVE_AUX_JARS_PATH=${HIVE_AUX_JARS_PATH}${HIVE_AUX_JARS_PATH:+:}/usr/lib/hive-hcatalog/share/hcatalog:/apache/apache-atlas-2.1.0/hook/hive%' /etc/hive/conf/hive-env.sh
sudo cp -r /apache/apache-atlas-2.1.0/hook/hive/* /usr/lib/hive/auxlib/
sudo systemctl stop hive-server2
sudo systemctl start hive-server2
# ---------------end---------------
# Start atlas
# ---------------start---------------
# Initialize will be completed in 15 mintues
export MANAGE_LOCAL_HBASE=true
export MANAGE_LOCAL_SOLR=true
python2 /apache/apache-atlas-2.1.0/bin/atlas_start.py
python2 /apache/apache-atlas-2.1.0/bin/atlas_stop.py
python2 /apache/apache-atlas-2.1.0/bin/atlas_start.py
# ---------------end---------------
# Download and startup kafka
# ---------------start---------------
cd /apache
curl -O https://mirrors.bfsu.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz
tar xzf kafka_2.13-2.8.0.tgz
sed -i "s/zookeeper.connect=.*/zookeeper.connect=localhost:9983/" /apache/kafka_2.13-2.8.0/config/server.properties
/apache/kafka_2.13-2.8.0/bin/kafka-server-start.sh -daemon /apache/kafka_2.13-2.8.0/config/server.properties
# ---------------end---------------*Slide left to see more
Although the hook of Hive/Hbase/Sqoop/Storm/Falcon/Kafka is embedded in Apache Atlas, there are few plugin s of other processing engines, such as Spark/Flink, which is widely used at present. If these two computing engines are used to process data, customized development is required to capture relevant data blood.
05 manually capture data
Apache Atlas is a typical type inheritance system. When adding data that cannot be automatically captured through Atlas hook or plugin, you must first understand its type system and the formation principle of blood relationship. Then create the necessary subtypes and their entities according to the business needs.
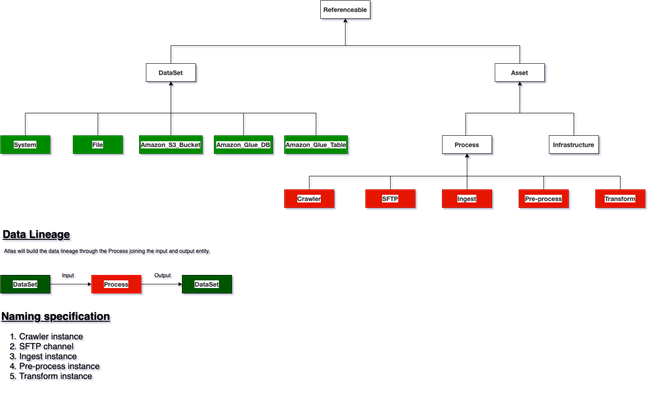
Among them, those marked in green are DataSet static subtypes, and those marked in red are process subtypes. Process entities form blood relationship by connecting DataSet subtype entities as input and output.
06 spark and Apache Atlas
There are two ways to capture Spark data kinship:
- Connector, benefits automated data capture
- REST API with high degree of customization
(1) Spark atlas connector
It is an open source Connector of Hortonworks. The last code update was on July 12, 2019. From the actual code compilation results, it has compatibility problems with Spark 3.1.1. The default configuration of the project (pom.xml):
- Spark 2.4.0
- Scala 2.11.12
- Atlas 2.0.0
If it is 2.4.0 Spark, this connector can be considered.
For some supplements to the document used in this project, if you use the rest api to automatically populate the data, please configure the following parameters:
- rest.address
- client.username
- client.password
These configuration options are derived from Atlas clientconf Scala files.
(2) spline
It is an open source project with high activity to capture Spark data kinship, but it has poor compatibility with Atlas, but it is self-contained, but the project has very good compatibility with Spark.
Author of this article

Yang Shuaijun
Senior Data Architect
Focus on data processing. At present, it mainly provides data management services for automobile enterprises.

