Catalog
Hadoop configuration (non-HA)
Hadoop is a distributed, highly available batch processing framework. Hadoop for CDH comes with other components such as Hbase, Hive, etc. However, Apache package only comes with Distributed File System HDFS, Resource Scheduling Yarn, and Batch Computing Framework Mapred. Other components such as Hbase and Hive need to adapt their own installation configuration.
The version of Hadoop is Apache Hadoop 3.0.3, which willTar.gzCompressed packages are unpacked and placed in the / home/stream home directory. Several files after unpacking are described:
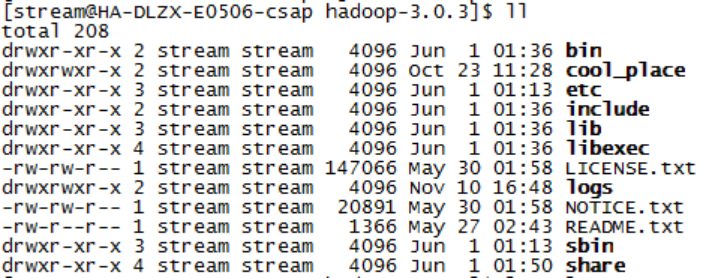
The most basic management scripts and directories to use scripts for bin:Hadoop, which are the basic implementation of management scripts under the sbin directory, can be used directly by users to manage and use Hadoop.
etc:The directory where the Hadoop configuration file is located, including core-site,xml, hdfs-site.xml,Mapredsite.xmlConfiguration files such as;
include: External programming library header files (specific dynamic libraries and static libraries in the lib directory), which are defined in C++, are usually used for C++ programs to access HDFS or write MapReduce programs;
lib: This directory contains Hadoop's external programming dynamic and static libraries, which are used in conjunction with the header files in the include directory.
libexec: The directory in which the shell configuration files used by each service pair are located, which can be used to configure basic information such as log output, startup parameters (such as JVM parameters).
sbin: The directory where the Hadoop management scripts are located, mainly including start/close scripts for various services in HDFS and YARN;
share: The directory where the compiled jar packages for each module of Hadoop are located;
To configure
Common, HDFS, Yarn, and MapReduce in Hadoop have their own configuration files for saving configurable parameters in the corresponding modules. These configuration files are in XML format and consist of two parts: the system default configuration file and the administrator customized configuration file.
System default profiles are core-default.xml, hdfs-default.xml, mapred-default.xml, yarn-default.xml, most of which are specified by default, with the following links:

Custom profiles are core-site.xml, hdfs-site.xml, mapred-Site.xmlAnd yarn-site.xml, its daemon configuration properties on the official website are linked as follows:
.Configuring the Hadoop Daemons
These profiles are used to define properties that the default configuration does not have or override the default values in the default configuration file, which cannot be modified once they are determined (Hadoop needs to be restarted if you want to modify it).
Core-Default.xmlAnd core-Site.xmlConfiguration files belonging to the common base libraries, which are loaded first by Hadoop by default.
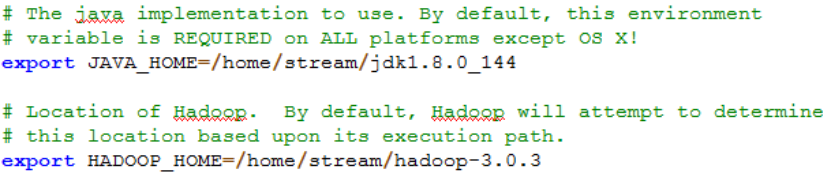
Hadoop-env.sh
Just configure JAVA_HOME and HADOOP_The value of HOME;
Hdfs
Define buffer sizes for default Fs and temporary folders and IO s;
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.19.72.155/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data01/hadoop</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>hdfs-site.xml
Configuration of namenode:
<configuration>
<property>
<name>dfs.namenode.rpc-address</name>
<value>172.19.72.155:8020</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>172.19.72.156:9868</value>
</property>
<property>
<name>dfs.namenode.secondary.hosts</name>
<value>172.19.72.156</value>
</property>
<property>
<name>dfs.secondarynamenode.hosts</name>
<value>172.19.72.156</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data01/hdfs/nn</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>172.19.72.155</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>172.19.72.155:9870</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>Configuration of datanode:
<configuration>
<property>
<name>dfs.namenode.rpc-address</name>
<value>172.19.72.155:8020</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>172.19.72.156:9868</value>
</property>
<property>
<name>dfs.namenode.secondary.hosts</name>
<value>172.19.72.156</value>
</property>
<property>
<name>dfs.secondarynamenode.hosts</name>
<value>172.19.72.156</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data01/hdfs/nn</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>172.19.72.155</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>172.19.72.155:9870</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data01/hdfs/dn</value>
</property>
</configuration>Yarn
Yarn is the component responsible for cluster resource scheduling management. Yarn's goal is to achieve "one cluster multiple framework". Yarn deploys a unified resource scheduling management framework on the same cluster. On top of Yarn, you can deploy other computing frameworks, such as MapRudece, Storm, Spark, etc. Yarn provides unified resource management services (including CPU, memory) for these computing frameworks, andMoreover, it can adjust the resources occupied by each computing framework according to the load requirements, achieve cluster resource sharing and resource elastic contraction, and improve cluster utilization.Different frameworks share the underlying storage to avoid cross-cluster data movement and greatly reduce the cost of enterprise operations and maintenance.
- Computing resource scaling on demand
- High cluster utilization without load application Mashup
- Share underlying storage to avoid data migration across clusters
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>172.19.72.155:8081</value>
</property>
<property>
<name> yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>172.19.72.155:8082</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>172.19.72.155:8083</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>172.19.72.155:8084</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>172.19.72.155:8085</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>172.19.72.155</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.resourcemanager.nodes.include-path</name>
<value>HA-DLZX-E0407-csap,HA-DLZX-E0507-csap,HA-DLZX-E0408-csap,HA-DLZX-E0508-csap</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>90</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data01/yarn/nodemanager</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data01/yarn/logs</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>MapReduce
MapReduce is a distributed parallel computing framework for large-scale datasets (larger than 1T). It highly abstracts complex parallel computing processes running on large-scale clusters into two functions: Map and Ruduce, which greatly facilitates distributed programming and makes it easy for programmers to program without distributed parallel programming.The program runs on a distributed system to complete the calculation of large amounts of data.
MapReduce is designed with the idea that computing is closer to data rather than data is closer to calculation because mobile computing is more economical for large-scale data than mobile data, which requires a lot of network transmission overhead.With this idea, in a cluster, whenever possible, the MapRdeuce framework runs the Map program close to the node where the HDFS data resides, that is, the computing node runs with the storage node, which reduces the cost of data movement between nodes.
mapred-site.xml
<configuration>
<property>
<name> mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx2014M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>172.19.72.155:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>172.19.72.155:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data01/yarn/temp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data01/yarn/done</value>
</property>
</configuration>Worker File
Lists the host name or IP address of all working nodes, one per line.
List all worker hostnames or IP addresses in your etc/hadoop/workers file, one per line. Helper scripts (described below) will use the etc/hadoop/workers file to run commands on many hosts at once. 172.19.72.156 172.19.72.157 172.19.72.158 172.19.72.159
Startup and Validation
Starting hdfs for the first time requires formatting:
$HADOOP_HOME/bin/hdfs namenode -format
Start the daemon instance:
$HADOOP_HOME/bin/hdfs --daemon start namenode $HADOOP_HOME/bin/hdfs --daemon start datanode $HADOOP_HOME/bin/yarn --daemon start resourcemanager $HADOOP_HOME/bin/yarn --daemon start nodemanager $HADOOP_HOME/bin/yarn --daemon start proxyserver $HADOOP_HOME/bin/mapred --daemon start historyserver
After closing the daemon instance, start the component:
$HADOOP_HOME/sbin/start-yarn.sh $HADOOP_HOME/sbin/start-dfs.sh
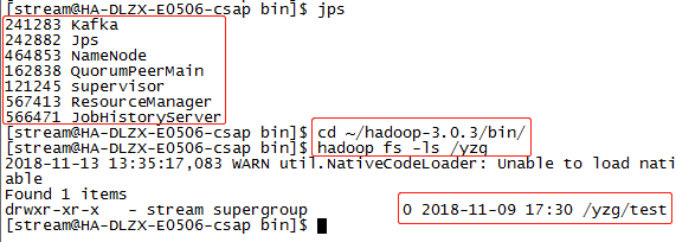
Use jps to see if related component processes exist, manually create folders on hdfs and upload files to verify that hdfs is configured successfully:
problem
1. Path permissions for hdfs, yarn, MR data and log configured in xml, yarn's log directory does not have write permissions, which makes yarn start successfully, but spark start failed (stuck). The solution is to give yarn-Site.xmlConfiguringYarn.nodemanager.log-dirs path assignment;

2. core-Site.xmlIn ConfigurationFs.defaultFsValue and host inconsistencies, according to the official network configurationFs.defaultFSThe value of isHdfs://172.19.72.15: 9000, error alerted:java.io.IOException: Failed on local exception; removeFs.defaultFsMedium port number succeeded;
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.19.72.155/</value>
</property>3. Unresolved: found when running: WARNUtl.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable error, in configuration file hadoop-Env.shMedium increase:
exportHADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"