Table of Contents
- background knowledge
- Architectural Evolution in the Big Data Age
- RocketMQ Connector&Stream
- Apache Hudi
- Building Lakehouse Practices
The title of this article contains three keywords: Lakehouse, RocketMQ, Hudi. We start with the overall Lakehouse architecture, and then step by step analyze the causes of the architecture, the characteristics of the architecture components, and the practical part of building the Lakehouse architecture.
background knowledge
1. Lakehouse architecture
Lakehouse was originally proposed by Databrick and requires the following Lakehouse architecture features:
(1) Transaction support
Many data pipelines within an enterprise often read and write data concurrently. Support for ACID transactions ensures consistency when multiple parties read and write data concurrently.
(2)Schema enforcement and governance
Lakehouse should have a way to support pattern execution and evolution, a paradigm that supports DW schema s (such as star or snowflake models), an ability to reason about data integrity, and a robust governance and auditing mechanism;
(3) Openness
The storage formats used are open and standardized, such as parquet, and provide API s for a variety of tools and engines, including machine learning and Python/R libraries, so that they can access data directly and effectively;
(4) BI support
Lakehouse can use BI tools directly on the source data. This improves data freshness, reduces latency, and reduces the cost of operating two copies of data in a data pool and a data warehouse.
(5) Separation of storage from computation
In practice, this means that storage and computing use separate clusters, so these systems can scale to support larger user concurrency and data volumes. Some modern number compartments also have this attribute;
(6) Support multiple data types from unstructured to structured data
Lakehouse can be used to store, optimize, analyze, and access many data applications including image, video, audio, text, and semi-structured data.
(7) Support various workloads
Includes data science, machine learning, and SQL and analysis. Multiple tools may be required to support these workloads, but their underlying layers depend on the same data repository;
(8) End-to-end flow
Real-time reports are standard applications in many enterprises. Streaming support eliminates the need to build separate systems dedicated to serving real-time data applications.
From the above description of the Lakehouse architecture, we can see that for a single function, we can build a set of solutions using some open source portfolios. However, there does not seem to be a common solution for support of all functions at present. Next, let's look at what the mainstream data processing architecture is in the big data age.
Architectural Evolution in the Big Data Age
1. Open Source Products in the Big Data Age
There are many types of open source products in the big data era, including RocketMQ and Kafka in the messaging field. flink, spark, storm in computing; HDFS, Hbase, Redis, ElasticSearch, Hudi, DeltaLake, etc. in the storage domain.
Why are there so many open source products? First of all, in the big data age, with the growing volume of data and the varying needs of each business, there are various types of products that architects can choose to support a variety of scenarios. However, many types of products also cause some difficulties for architects, such as difficult selection, high trial and error costs, high learning costs, complex architecture and so on.

2. Current Mainstream Multilayer Architecture
Processing scenarios in the large data field include data analysis, BI, scientific computing, machine learning, indicator monitoring, etc. For different scenarios, business will choose different computing and storage engines according to business characteristics. For example, a combination of binlog + CDC+ RocketMQ + Flink + Hbase + ELK can be used for BI and MTIC visualization.
(1) Advantages of a multi-tier architecture: support for a wide range of business scenarios;
(2) Disadvantages of multi-tier architecture:
- Processing link length, high latency;
- More copies of data, double the cost;
- High learning costs;
The main reason for the disadvantage of multilayer architecture is that the storage and computing links are too long.
- Do we really need so many solutions to support a wide range of business scenarios? Is the Lakehouse architecture a unified solution?
- Can multi-layer reservoirs be merged? Can Hudi products support multiple storage needs?
- Can computing layers in a multi-tier architecture be merged? Can RocketMQ stream fuse the messaging and computing layers?
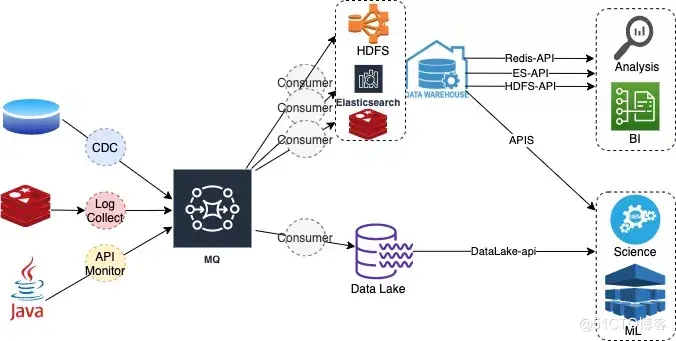
Current mainstream multitier architecture
3. Lakehouse architecture generation
Lakehouse architecture is an upgraded version of a multitier architecture that continues to reduce storage layer complexity to one level. Further compression of the computing layer fuses the messaging and computing layers, and RocketMQ stream acts as the computing role. We have the new architecture shown in the figure below. In the new architecture, the entry and exit of messages are implemented by RocketMQ connector, and the message computing layer is implemented by RocketMQ stream, which completes the intermediate flow of message computing within RocketMQ. The results are calculated through the RocketMQ-Hudi-connector closing house Hudi, which supports multiple indexes and provides a uniform API output to different products.
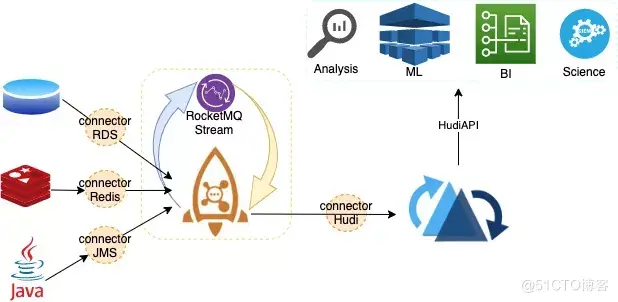
Lakehouse architecture
Below we analyze the characteristics of this architecture.
(1) Advantages of the Lakehouse architecture:
- Shorter links, more suitable for real-time scenes, high freshness of data;
- Controllable cost reduces storage costs;
- Low cost of learning and friendly to programmers;
- Operational complexity is greatly reduced;
(2) Disadvantages of Lakehouse architecture
Requirements for stability and ease of use are high for message products and data Lake products, while message products need to support computing scenarios, and data Lake products need to provide strong indexing capabilities.
(3) Selection
In the Lakehouse architecture we chose the messaging product RocketMQ and the data Lake product Hudi.
At the same time, RocketMQ stream can be used to integrate the computing layer in the RocketMQ cluster, which reduces the computing layer to one level and can satisfy most large and medium data processing scenarios.
Next we will step by step analyze the features of both RocketMQ and Hudi products.
RocketMQ Connector & Stream
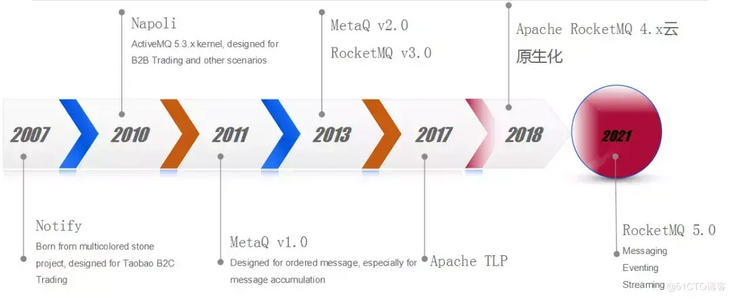
RocketMQ History Diagram
RocketMQ has been hatched in Apache since 2017, completed proto-cloud biochemistry by RocketMQ 4.0 in 2018, and fully integrated messages, events and streams by RocketMQ 5.0 in 2021.
1. Business Messaging Preferences
RocketMQ has become the preferred messaging product in the business world as a "sleeping messaging product", mainly due to the following features of the product:
(1) High reliability of financial class
It has undergone the flood peak test of Alibaba Double 11;
(2) Minimalist architecture
As shown in the figure below, the architecture of RocketMQ consists of two main parts: the source data cluster NameServer Cluster and the computed storage cluster Broker Cluster.
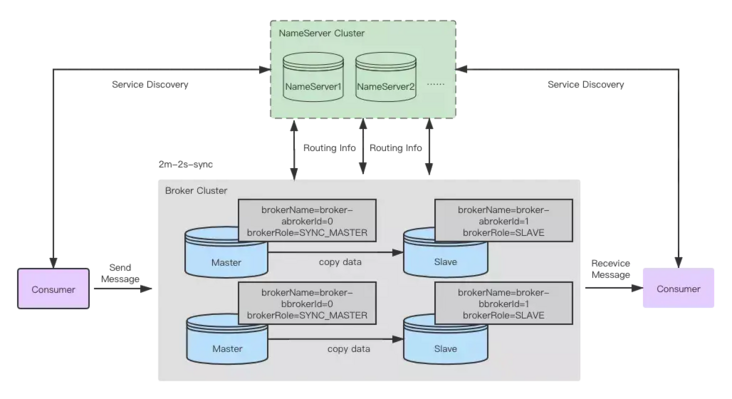
RocketMQ Architecture
NameServer nodes are stateless and can be scaled horizontally very easily. Broker nodes use primary and standby methods to ensure high data reliability, support a primary and standby scenario, and flexible configuration.
How to set it up: A RocketMQ cluster can be built with simple code:
Jar:
nohup sh bin/mqnamesrv & nohup sh bin/mqbroker -n localhost:9876 &
On K8S:
kubectl apply -f example/rocketmq_cluster.yaml
(3) Very low operating and maintenance costs
RocketMQ has a low maintenance cost and provides a good CLI tool MQAdmin. MQAdmin provides rich command support, covering many aspects such as cluster health check, cluster in and out flow control. For example, a mqadmin clusterList command can get all the node states (production and consumption traffic, latency, queue length, disk water level, etc.) of the current cluster. The mqadmin updateBrokerConfig command can set the readable and writable state of broker nodes or topic s in real time, which can dynamically remove temporary unavailable nodes to achieve the effect of flow migration for production and consumption.
(4) Rich message types
The types of messages supported by RocketMQ include normal messages, transaction messages, deferred messages, timed messages, sequential messages, and so on. Easily support large data and business scenarios.
(5) High throughput and low latency
Pressure scene master-standby synchronous replication mode, each Broker node can fill disk utilization and control p99 latency at the millisecond level.
2. Overview of RocketMQ 5.0
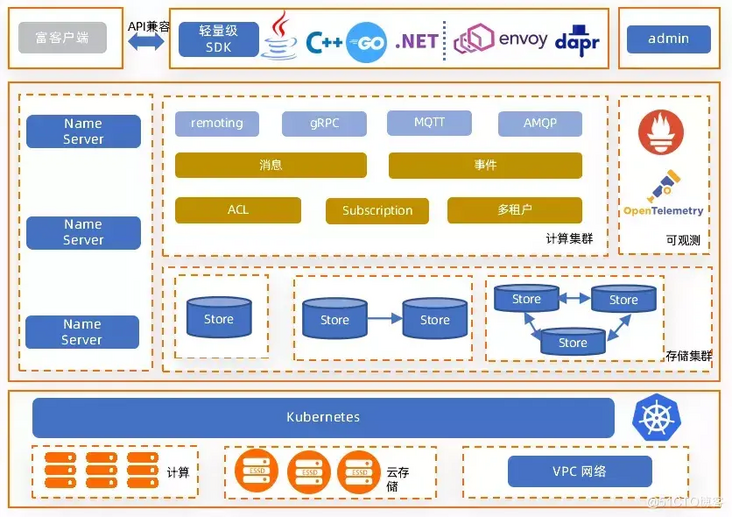
RocketMQ 5.0 is a cloud-based, cloud-growing native messaging, events, and streaming hyperfusion platform with the following features:
(1) Lightweight SDK
- Fully support the cloud native communication standard gRPC protocol;
- Stateless Pop consumption mode, multilingual friendliness and easy integration;
(2) Minimalist architecture
- No external dependency, reduce the burden of operation and maintenance;
- Loose coupling between nodes allows any service node to migrate at any time.
(3) Separation of separable and combinable storage computing
- Broker upgraded to a truly stateless service node with no binding;
- Broker and Store nodes are deployed separately and scaled independently;
- Multi-protocol standard support, no vendor lock-in;
- It can be divided and combined to adapt to a variety of business scenarios and reduce the burden of operation and maintenance;
As shown in the figure below, Computing Clusters (Broker s) mainly include abstract models and corresponding protocol adaptions, as well as consumer and governance capabilities. Store is mainly divided into message storage CommitLog (multitype message storage, multimodal storage) and index storage index (multivariate index). If you can make full use of the storage capacity in the cloud, configuring CommitLog and Index in the file system in the cloud can naturally separate storage from computation.
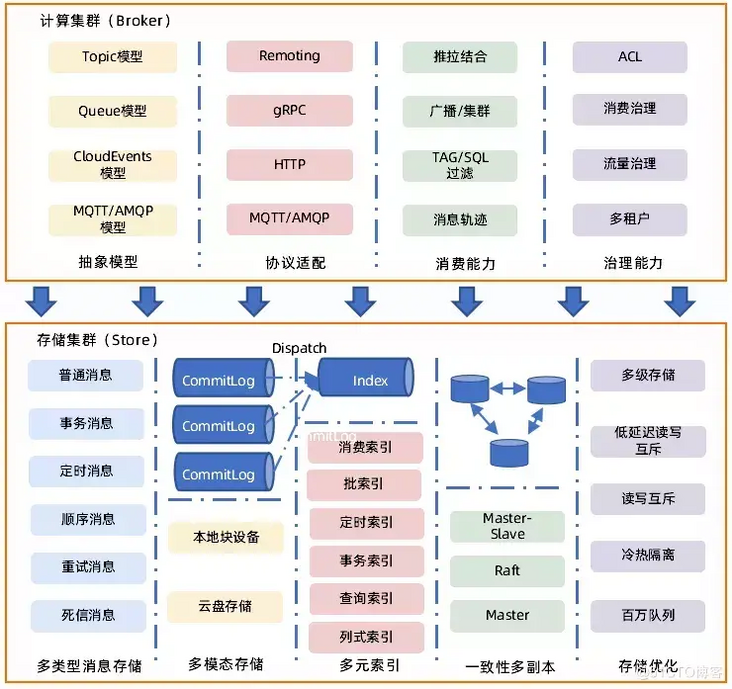
(4) Multimode storage support
- Satisfies high availability demands in different basic scenarios;
- Take full advantage of cloud infrastructure to reduce costs;
(5) Cloud native infrastructure:
- Observable performance cloud biochemistry, OpenTelemetry standardization;
- Kubernetes One-Click Deployment Extension Delivery.
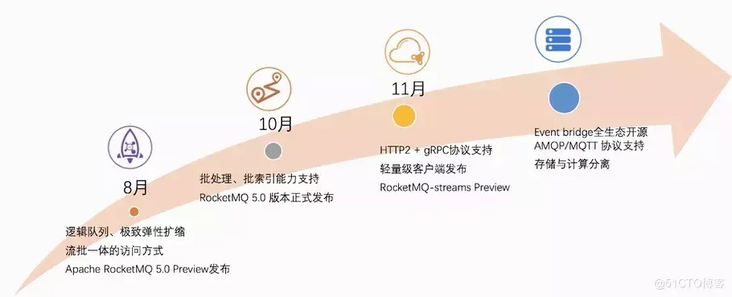
RocketMQ 5.02021 Events and Future Planning
3, RocketMQConnector
a. Traditional data streams
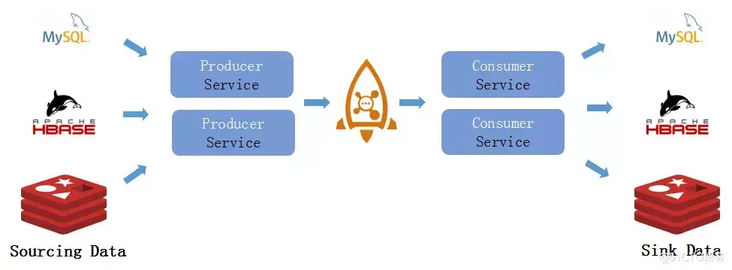
(1) Disadvantages of traditional data streams
- Producer consumer code needs to be implemented by itself, which is costly.
- Data synchronization tasks are not managed uniformly;
- Repeated development, uneven code quality;
(2) Solution: RocketMQ Connector
- Co-build, reuse data synchronization task code;
- Unified management and scheduling to improve resource utilization;
b. RocketMQ Connector data synchronization process
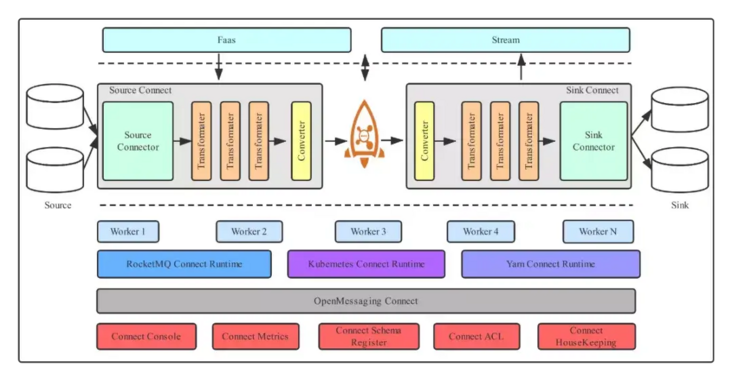
Compared to traditional data streams, RocketMQ connector data streams differ in their unified management of source and sink, open source, and active community.
4. RocketMQ Connector architecture
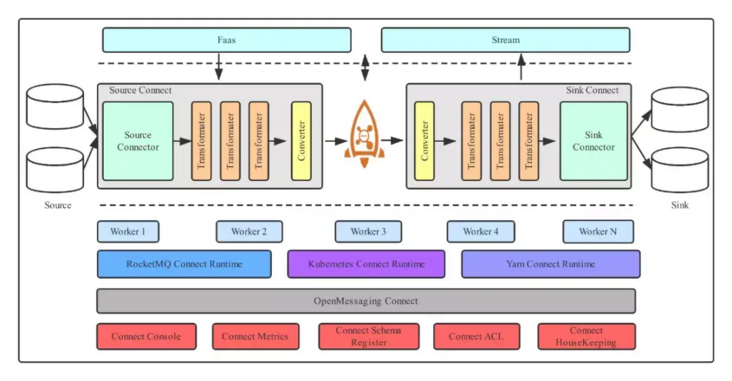
As shown in the figure above, the RocketMQ Connector architecture mainly consists of Runtime and Worker, as well as EcoSource&Sink.
(1) Standard: OpenMessaging
(2) Ecology: supports most products in data fields such as ActiveMQ, Cassandra, ES, JDBC, JMS, MongoDB, Kafka, RabbitMQ, Mysql, Flume, Hbase, Redis, etc.
(3) Components: Manager unified management scheduling, if there are multiple tasks, all tasks can be uniformly load balanced, evenly distributed to different Workers, and Workers can be scaled horizontally.
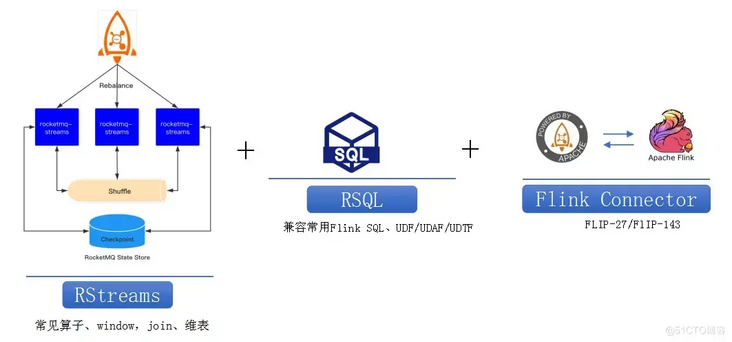
5,RocketMQ Stream
RocketMQ Stream is a product that compresses the computing layer into one layer. It supports common operators such as window, join, dimension table and is compatible with Flink SQL, UDF/UDAF/UDTF.
Apache Hudi
Hudi is a streaming data Lake platform that supports fast updates to large amounts of data. Built-in table format to support transactional reservoirs, a series of table services, data services (out-of-the-box uptake tools), and complete maintenance monitoring tools. Hudi can offload storage to OSS, AWS S3 on Ali Cloud.
Hudi features include:
- Transactional write, MVCC/OCC concurrency control;
- Native support for record level updates and deletions;
- Query-oriented optimization: small file automatic management, for incremental pull optimization design, automatic compression, clustering to optimize file layout;
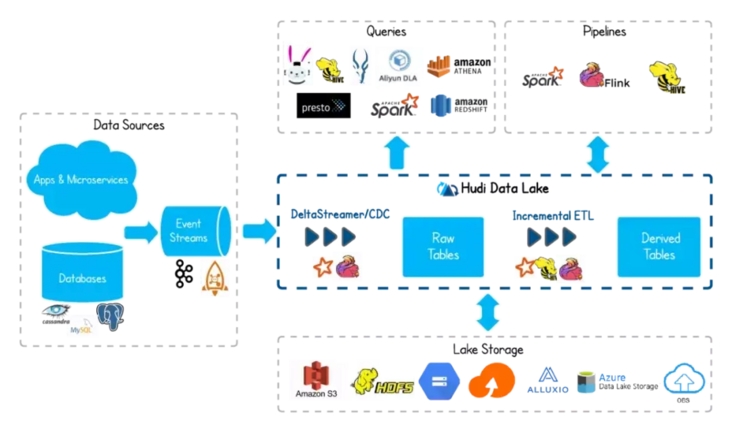
Apache Hudi is a complete data Lake platform. It is characterized by:
- Each module is tightly integrated and self-managed.
- Write using Spark, Flink, Java;
- Use Spark, Flink, Hive, Presto, Trino, Impala,
AWS Athena/Redshift etc. - Out-of-the-box tools/services for data operations.
Apache Hudi is optimized for three main types of scenarios:
1. Streaming stack
(1) Incremental treatment;
(2) Fast and efficient;
(3) Line-oriented;
(4) Unoptimized scanning;
2. Batch Stack
(1) batch processing;
(2) low efficiency;
(3) formats for scanning and storing in columns;
3. Incremental Processing Stack
(1) Incremental treatment;
(2) Fast and efficient;
(3) Scan and column format.
Building Lakehouse Practices
This section only describes the main processes and operational configuration items, and the operational details of the local setup can be referred to in the appendix section.
1. Preparations
RocketMQ version: 4.9.0
rocketmq-connect-hudi version: 0.0.1-SNAPSHOT
Hudi version: 0.8.0
2. Build RocketMQ-Hudi-connector
(1) Download:
git clone https://github.com/apache/roc...
(2) Configuration:
/data/lakehouse/rocketmq-externals/rocketmq-connect/rocketmq-connect-runtime/target/distribution/conf/connect.conf in connector-plugin Route
(3) Compilation:
cd rocketmq-externals/rocketmq-connect-hudi mvn clean install -DskipTest -U
rocketmq-connect-hudi-0.0.1-SNAPSHOT-jar-with-dependencies.jar is the rocketmq-hudi-connector we need to use
3. Running
(1) Start or use an existing RocketMQ cluster and initialize the metadata Topic:
connector-cluster-topic (cluster information) connector-config-topic (configuration information)
connector-offset-topic (sink consumption progress) connector-position-topic (source data processing progress and to keep messages in order, each top can have only one queue)
(2) Start the RocketMQ connector runtime
cd /data/lakehouse/rocketmq-externals/rocketmq-connect/rocketmq-connect-runtime sh ./run_worker.sh ## Worker can start multiple
(3) Configure and launch the RocketMQ-hudi-connector task
Request RocketMQ connector runtime to create a task
curl http://${runtime-ip}:${runtime-port}/connectors/${rocketmq-hudi-sink-connector-name} ?config='{"connector-class":"org.apache.rocketmq.connect.hudi.connector.HudiSinkConnector","topicNames":"topicc","tablePath":"file:///tmp/hudi_connector_test","tableName":"hudi_connector_test_table","insertShuffleParallelism":"2","upsertShuffleParallelism":"2","deleteParallelism":"2","source-record-converter":"org.apache.rocketmq.connect.runtime.converter.RocketMQConverter","source-rocketmq":"127.0.0.1:9876","src-cluster":"DefaultCluster","refresh-interval":"10000","schemaPath":"/data/lakehouse/config/user.avsc"}'
Successful startup prints the following logs:
2021-09-06 16:23:14 INFO pool-2-thread-1 - Open HoodieJavaWriteClient successfully(4) At this point, the data produced to source top is automatically written to the corresponding table of 1 Hudi, which can be queried through Hudi's api.
4. Configuration resolution
(1) The RocketMQ connector needs to configure the RocketMQ cluster information and the connector plug-in location, including: the connection work node id identifies workerid, the connection service command receive port httpPort, the rocketmq cluster namesrvAddr, the connection local configuration storage directory storePathRootDir, and the connector plug-in directory pluginPaths.

RocketMQ connector configuration table
(2) The Hudi task needs to configure the Hudi table path tablePath and table name tableName, as well as the Schema file used by Hudi.
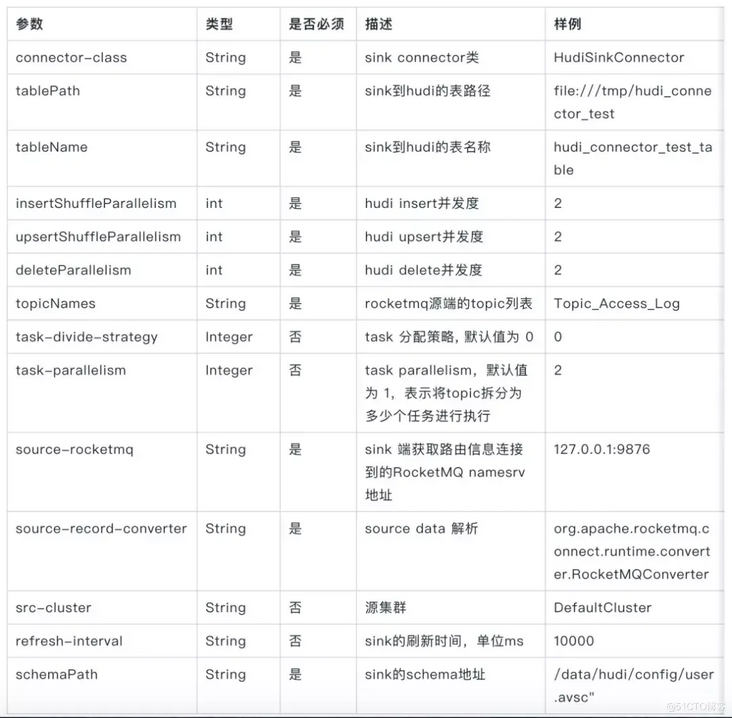
Hudi Task Configuration Table
Click Here View Lakehouse build live video
Appendix: Build Lakehouse demo on your local Mac system
Components involved: rocketmq, rocketmq-connector-runtime, rocketmq-connect-hudi, hudi, hdfs, avro, spark-shell 0, starting HDFS
Download hadoop package
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
cd /Users/osgoo/Documents/hadoop-2.10.1
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- You can use commands hostname View host name Here the host name is hadoop1-->
<value>hdfs://localhost:9000</value>
</property>
<!--Cover core-default.xml Default configuration in-->
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
./bin/hdfs namenode -format
./sbin/start-dfs.sh
jps look down namenode,datanode
lsof -i:9000
./bin/hdfs dfs -mkdir -p /Users/osgoo/Downloads
1,start-up rocketmq Cluster, Create rocketmq-connector Built-in topic
QickStart: https://rocketmq.apache.org/docs/quick-start/
sh mqadmin updatetopic -t connector-cluster-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-config-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-offset-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-position-topic -n localhost:9876 -c DefaultCluster
2,Create a source for data entering the lake topic,testhudi1
sh mqadmin updatetopic -t testhudi1 -n localhost:9876 -c DefaultCluster
3,Compile rocketmq-connect-hudi-0.0.1-SNAPSHOT-jar-with-dependencies.jar
cd rocketmq-connect-hudi
mvn clean install -DskipTest -U
4,start-up rocketmq-connector runtime
To configure connect.conf
--------------
workerId=DEFAULT_WORKER_1
storePathRootDir=/Users/osgoo/Downloads/storeRoot
## Http port for user to access REST API
httpPort=8082
# Rocketmq namesrvAddr
namesrvAddr=localhost:9876
# Source or sink connector jar file dir,The default value is rocketmq-connect-sample
pluginPaths=/Users/osgoo/Downloads/connector-plugins
---------------
Copy rocketmq-hudi-connector.jar reach pluginPaths=/Users/osgoo/Downloads/connector-plugins
sh run_worker.sh
5,Configure Into Lake config
curl http://localhost:8082/connectors/rocketmq-connect-hudi?config='{"connector-class":"org.apache.rocketmq.connect.hudi.connector.HudiSinkConnector","topicNames":"testhudi1","tablePath":"hdfs://localhost:9000/Users/osgoo/Documents/base-path7","tableName":"t7","insertShuffleParallelism":"2","upsertShuffleParallelism":"2","deleteParallelism":"2","source-record-converter":"org.apache.rocketmq.connect.runtime.converter.RocketMQConverter","source-rocketmq":"127.0.0.1:9876","source-cluster":"DefaultCluster","refresh-interval":"10000","schemaPath":"/Users/osgoo/Downloads/user.avsc"}'
6,Send a message to testhudi1
7,## Reading with spark
cd /Users/osgoo/Downloads/spark-3.1.2-bin-hadoop3.2/bin
./spark-shell \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "t7"
val basePath = "hdfs://localhost:9000/Users/osgoo/Documents/base-path7"
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath + "/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select * from hudi_trips_snapshot").show()Welcome to the discussions and exchanges with Rocketmq enthusiasts:

Nail Scavenger Group