Application of cache and distributed lock
1. Cache application
Cache usage scenario:
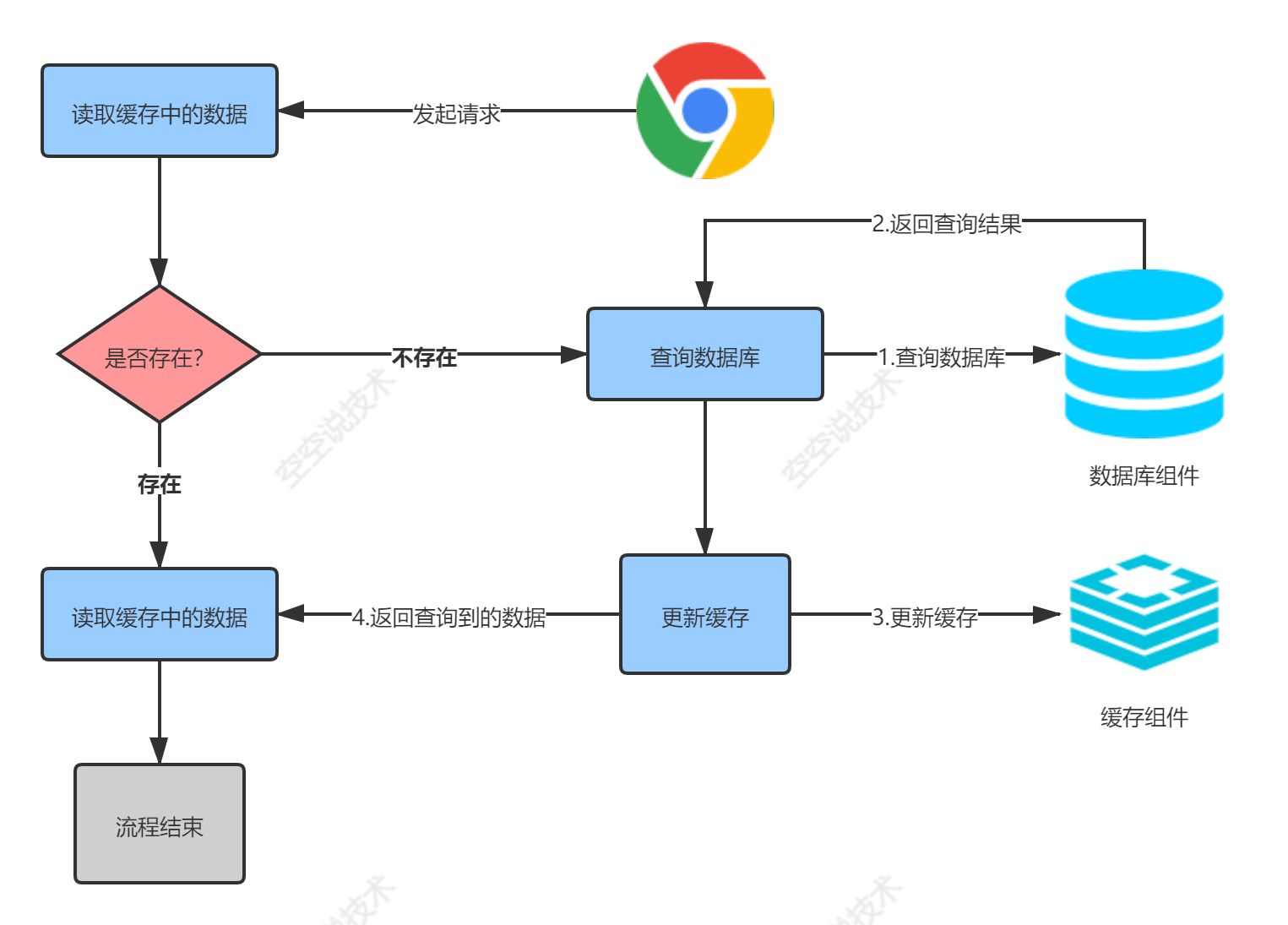
In order to improve the system performance, we usually put some data into the cache to speed up access, while the database only undertakes the data dropping work
So what data is suitable for caching?
- The requirements for immediacy and data consistency are not high
- Large number of visits and low update efficiency
For example, e-commerce applications, commodity classification and commodity list are suitable to be put into the cache and added with an update time (determined by the data update frequency). It is generally acceptable for buyers to see new commodities after 5 minutes when a commodity is released in the background
1. Local application
/**
* Custom cache
*/
private Map<String, Object> cache = new HashMap<>();
/**
* Get real data
*
* @return
*/
public NeedLockDataVO getDataVO() {
NeedLockDataVO cacheDataVO = (NeedLockDataVO) cache.get("cacheDataVO");
// If so, return
if (cacheDataVO != null) {
return cacheDataVO;
}
// If not, get the data in db
NeedLockDataVO needLockDataVO = doGetNeedLockDataVO();
// put into cache
return (NeedLockDataVO) cache.put("cacheDataVO", needLockDataVO);
}
private NeedLockDataVO doGetNeedLockDataVO() {
// TODO tedious business logic code
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
}
return new NeedLockDataVO();
}
Our cache component here makes use of the native Map.
In the same project and in the same JVM, that is, a copy is saved locally, which can be called local cache.

In a single service application, we use the local cache mode. If the cache components and applications are always deployed on the same machine, there will be no problems and the efficiency is very high.
But let's consider the following scenario:
If in a distributed system, a service project is often deployed on more than a dozen servers, and each server comes with its own local cache, what will happen?
In the distributed scenario, the built-in cache of a single application only works on the server where it is located. Suppose we have a commodity service deployed on multiple servers at the same time, and the client initiates a request to query a commodity list. We find the first server through load balancing and find that it is not in the local cache of server 1, so we query it from the database and put it into the local cache of server 1. The second client request is also to query the product list and find the second server through load balancing. At this time, the local cache of the second server will not have the cache information of the first server. This will lead to the following questions:
Question:
- The server takes care of itself. Every request comes in, it has to be checked and put into its own cache
- If you modify the data, you generally need to modify the data in the cache. Suppose that we only modify the cached data of server 1 through load balancing, then the data obtained from requests for load balancing to other servers will be different from the data of server 1, resulting in a serious problem: data consistency
So, how can we use cache to solve the problem of data consistency in our distributed system?
2. Application in distributed scenario
We introduce a middleware redis to hand over the cache control to a third party for processing. All data read and written to the cache are handed over to redis, and the local cache is no longer used
/**
* StringRedisTemplate
*/
@Resource
StringRedisTemplate cache;
/**
* Get real data
*
* @return
*/
public NeedLockDataVO getDataVO() {
// Remove from redis
String jsonObjectStr = cache.opsForValue().get("cacheDataVO");
NeedLockDataVO cacheDataVO = JSONObject.parseObject(jsonObjectStr, new TypeReference<NeedLockDataVO>(){});
// If so, return
if (cacheDataVO != null) {
return cacheDataVO;
}
// If not, get the data in db
NeedLockDataVO needLockDataVO = doGetNeedLockDataVO();
// Save to redis
cache.opsForValue().set("cacheDataVO", JSON.toJSONString(needLockDataVO));
return needLockDataVO;
}
private NeedLockDataVO doGetNeedLockDataVO() {
// TODO tedious business logic code
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
}
return new NeedLockDataVO();
}
Next, we use jmeter for pressure measurement and find that redis will frequently report errors in the later stage: outofdirectoryerror
Causes:
Redis auto configuration
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
}
After springboot 2.0, lettue is used as the client for redis by default. It uses netty for network communication. The bug of lettuce leads to out of heap memory overflow. If netty does not specify out of heap memory, it will use the value of - Xms of the virtual machine by default. You can use - Dio.netty.maxDirectMemory to set it. After a long time, the problem of out of heap memory overflow will certainly occur, and the symptoms will not cure the root cause.
How can we solve this difficult problem?
Jedis replaces the Lettuce used by SpringBoot by default
Exclude the Lettuce package first:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
Out of heap memory overflow outofdirectoryerror, perfect solution!
We solved the problem of cache consistency by adding A third-party cache, but we imagine A scenario. If there are two servers, A requests to update db first, and B updates db later, but the server requested by A has A network problem, resulting in A delay, and the server requested by B operates the cache first before the server requested by A, then we follow the common sense, The last updated data should be queried from the cache, which leads to another problem: the final consistency of the cache

So, how can we solve the problem of "cache final consistency"? Let's first introduce the solution from the security problems existing in the cache!
3. Cache related issues
3.1 cache penetration
Queried data that must not exist - cache penetration
Cache penetration: refers to the data that does not exist in the cache and the database, and the user constantly initiates requests, such as querying the data with id = "- 1" or the data with an extremely large ID that does not exist. At this time, the user is likely to be an attacker, and the attack will lead to excessive pressure on the database
Solution:
- Verification is added in the interface layer (user authentication and id are used as basic verification, and requests with id - 1 are filtered)
- The data that cannot be found in the cache is also written into the cache and saved in the form of key null (the cache time is set to be shorter, and too long will make it unusable under normal conditions). This can prevent violent attacks with the same id
- **Bloom filter: See the boss's article for details
3.2 cache avalanche
Mass expiration of different data in cache - cache penetration
Cache avalanche: it means that a large number of data in the cache are expired and the amount of queries is huge, resulting in great pressure on the database and even downtime. Unlike cache breakdown, avalanche means that different data queried are expired
Solution:
- Random time: add a random time to the original expiration time to prevent mass expiration of data at the same time
- Never expire cache: set the cache data to never expire when circumstances permit
- Redis high availability: prevent the avalanche caused by redis downtime
- Current limiting degradation: read and write caching of the database by locking and queuing. For example, for a key, only one thread is allowed to query the database and other threads wait
- Data preheating: before formal deployment, access the data once and add it to the cache. Set different expiration times to make the time point of cache invalidation as uniform as possible
3.3 buffer breakdown
Hot key failure - cache breakdown
Cache breakdown: when a hot key fails at a certain point in time, a large number of threads query the key, causing a large number of threads to query the database, causing great pressure on the database and even downtime
Solution:
- Mutex lock: among multiple concurrent requests, only the first requesting thread can get the lock and perform database query. After the first thread writes the data to the cache, other threads directly go to the cache
- Distributed lock: in the distributed scenario, the local mutex cannot guarantee that only one thread can query the database, and the distributed lock can also be used to avoid the breakdown problem
- Hot data does not expire: directly set the cache to not expire, and then the scheduled task loads the data asynchronously to update the cache
How do we choose a solution for cache breakdown?
In essence, when the concurrency scenario is very high, we avoid the problem of cache breakdown by reducing the concurrency of threads accessing the database.
Mutex VS distributed lock:
Most of the time, we deploy multiple identical services through clusters. Although the local mutual exclusion lock cannot strictly control a single thread to query the database, our purpose is to reduce the concurrency, as long as we ensure that the requests to the database can be greatly reduced. Therefore, another idea is the JVM lock. Of course, if we want to ensure the final consistency of the cache, We still need to use distributed locks as the final solution!
JVM lock ensures that only one request from a single server can reach the database. Generally speaking, it is enough to ensure that the pressure on the database is greatly reduced, and the performance is better than that of distributed lock.
It is worth noting that whether "distributed lock" or "JVM lock" is used, the lock should be added according to the key dimension.
Locking with a fixed key value will cause different keys to block each other, resulting in serious performance loss.
2. Breakdown solution - lock application
Based on the above results, although our redis cache improves performance, there are still some problems in some special scenarios (CACHE breakdown and final data consistency).
We know that distributed locks can access database resources through a single thread to solve the above two problems. Next, let's discuss the applications related to "locks".
1. Local lock (including under JUC package)
Before we introduce the solution, let's take a look at an example:
/**
* Get real data
*
* @return
*/
public NeedLockDataVO getDataVO() {
String jsonObjectStr = cache.opsForValue().get("cacheDataVO");
NeedLockDataVO cacheDataVO = JSONObject.parseObject(jsonObjectStr, new TypeReference<NeedLockDataVO>(){});
// If so, return
if (cacheDataVO != null) {
return cacheDataVO;
}
// If not, get the data in db
NeedLockDataVO needLockDataVO = doGetNeedLockDataVO();
// Save to redis
cache.opsForValue().set("cacheDataVO", JSON.toJSONString(needLockDataVO));
return needLockDataVO;
}
private NeedLockDataVO doGetNeedLockDataVO() {
// Data local locking
synchronized (this){
// TODO tedious business logic code
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
}
return new NeedLockDataVO();
}
}
Suppose that our instance is managed by Spring, and this obtains the same instance
I wonder if we have found the following problems:
- The read and save of the cache are not in the lock. Even for a single server, there will be downtime risk in case of concurrency.
- Locking is performed locally. Under multiple servers, there are still multiple threads accessing the database, and the consistency of cache data is still unresolved
For the problem of "1", we only need to check the cache once after entering the lock.
The code snippet is changed as follows:
private NeedLockDataVO doGetNeedLockDataVO() {
synchronized (this){
// Query the cache again to prevent the risk of downtime
String jsonObjectStr = cache.opsForValue().get("cacheDataVO");
NeedLockDataVO cacheDataVO = JSONObject.parseObject(jsonObjectStr, new TypeReference<NeedLockDataVO>(){});
// If so, return
if (cacheDataVO != null) {
return cacheDataVO;
}
// TODO tedious business logic code
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
}
return new NeedLockDataVO();
}
}
For the "2" problem, how do we make a distributed lock to solve the current hidden problem?
2. Distributed lock
What is?
When multiple processes are not in the same system, distributed locks are used to control the access of multiple processes to resources.
Distributed solutions
For the implementation of distributed locks, the following schemes are commonly used:
- Implementation of distributed lock based on Database
- Distributed locking based on redis (memcached, tail)
- Implementation of distributed lock based on Zookeeper
Let's focus on the implementation of cache based distributed lock evolution:
Phase I
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1: Account for distributed locks. Go to redis zhankeng
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
if (lock){
//Locking succeeded... Execute business
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//Delete lock
return dataFromDB;
}else {
//Locking failed.... retry
//Sleep for 100 milliseconds and try again
return getCatalogJsonFromDbWithRedisLock();//Spin mode
}
}
Question:
- If an exception occurs in the execution of the business after obtaining the lock, the lock will not be released, resulting in deadlock
Cause: the locking and unlocking processes do not affect each other and will not be rolled back as a whole. There is no handling of locks after exceptions
Solution:
- Specify the expiration time for the lock, and the lock will be unlocked automatically upon expiration
Phase II
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1: Account for distributed locks. Go to redis zhankeng
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
if (lock){
//Locking succeeded... Execute business
//2: Set expiration time
stringRedisTemplate.expire("lock",30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//Delete lock
return dataFromDB;
}else {
//Locking failed.... retry
//Sleep for 100 milliseconds and try again
return getCatalogJsonFromDbWithRedisLock();//Spin mode
}
Question:
- Similarly, if the expiration time is not set for execution due to abnormal reasons, resulting in deadlock
Reason: locking and setting expiration time side operations are not atomic
Solution:
We can use SET key value [EX seconds] to ensure the atomicity of locking and expiration time settings
Phase III
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1: Account for distributed locks. Go to redis zhankeng
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111",30, TimeUnit.SECONDS);
if (lock){
//Locking succeeded... Execute business
//2: Set expiration time
// stringRedisTemplate.expire("lock",30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//Delete lock
return dataFromDB;
}else {
//Locking failed.... retry
//Sleep for 100 milliseconds and try again
return getCatalogJsonFromDbWithRedisLock();//Spin mode
}
}
Question:
- When the service times out, it is found that the lock has expired and can be deleted automatically. What should I do if there is no lock?
- The business takes a long time. After the lock expires automatically, we delete someone else's lock. What should we do? What if other threads come in again?
Reason: Based on the comprehensive reasons of performance and network, we can't guarantee that the timeout time is always less than the expiration time. If the service timeout time is too long, it will lead to confusion in locking and even fail to achieve the purpose of locking.
Solution:
We must ensure that when deleting locks, we cannot delete other people's locks
Phase IV
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1: Account for distributed locks. Go to redis zhankeng
String uuid= UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "uuid",30, TimeUnit.SECONDS);
if (lock){
//Locking succeeded... Execute business
//2: Set expiration time
// stringRedisTemplate.expire("lock",30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
//The obtained value comparison and the successful deletion must be an atomic operation
String lockValue = stringRedisTemplate.opsForValue().get("lock");
if (uuid.equals(lockValue)){
stringRedisTemplate.delete("lock");//Delete lock
}
return dataFromDB;
}else {
//Locking failed.... retry
//Sleep for 100 milliseconds and try again
return getCatalogJsonFromDbWithRedisLock();//Spin mode
}
}
Question:
- After we did uuid.equals(lockValue), we timed out due to network reasons. Before deleting the lock, other threads changed the lock. Although we thought it was our own value, we deleted someone else's lock, and many threads would come in and seize the lock.
- The business takes a long time. After the lock expires automatically, we delete someone else's lock. What should we do? What if other threads come in again?
Reason: deleting locks does not guarantee atomicity
Solution:
Ensure atomicity when deleting locks
Phase V
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1: Account for distributed locks. Go to redis zhankeng
String uuid= UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "uuid",30, TimeUnit.SECONDS);
if (lock){
//Locking succeeded... Execute business
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
String script="if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +
"then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
//Atomic deletion lock
Integer lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Integer>(script, Integer.class), Arrays.asList("lock"), uuid);
return dataFromDB;
}else {
//Locking failed.... retry
//Sleep for 100 milliseconds and try again
return getCatalogJsonFromDbWithRedisLock();//Spin mode
}
}
Question:
- The problem of lock expiration is still not solved
Reason: the service times out. The lock expires before it is deleted. What should I do?
Solution:
Extended lock time
Phase 6
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1: Account for distributed locks. Go to redis zhankeng
String uuid= UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "uuid",30, TimeUnit.SECONDS);
if (lock){
//Locking succeeded... Execute business
Map<String, List<Catelog2Vo>> dataFromDB;
try {
dataFromDB = getDataFromDB();
}finally {
String script="if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +
"then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
//Atomic deletion lock
Integer lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Integer>(script, Integer.class), Arrays.asList("lock"), uuid);
}
return dataFromDB;
}else {
//Locking failed.... retry
//Sleep for 100 milliseconds and try again
return getCatalogJsonFromDbWithRedisLock();//Spin mode
}
}
Distributed lock summary:
- Set the expiration time long enough
- Locking and expiration times must be atomic operations
- Deleting a lock must also be atomic
3. Redisson -- JUC in distributed
After we understand the evolution process of distributed locks, we can solve general scenario problems, but when we encounter some complex scenarios, we need more advanced distributed locks. What should we do? Redis provides us with a one-stop solution - Redisson (Distributed locks with Redis)
What is Redisson: Redisson is a Java in memory data grid implemented on the basis of Redis
Redisson (Chinese English) document link
For all usage, we can refer to the Redisson document
4. Redisson start
Configuration - refer to Chinese documents
/**
* @author lishanbiao
* @Date 2021/11/22
*/
@Configuration
public class MyRedissonConfig {
@Bean(destroyMethod="shutdown")
RedissonClient redisson() throws IOException {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
}
}
test
@Autowired
private Redisson redisson;
/**
* hello world
*/
@RequestMapping("/delete")
// @RequiresPermissions("coupon:coupon:delete")
public String helloWorld(@RequestBody Long[] ids) {
// Acquire lock
RLock lock = redisson.getLock("my-lock");
// Lock blocking wait
lock.lock();
try {
System.out.println("Lock successfully, execute business" + Thread.currentThread().getId());
Thread.sleep(3000);
} catch (Exception e) {
} finally {
// Unlock
System.out.println("Release lock" + Thread.currentThread().getId());
lock.unlock();
}
return "hello";
}
Thinking: will there be a deadlock problem on the terminal before the program is deleted?
The test will find that it will not (do it yourself).
reason:
Looking through the document, you will find that during the extremely long execution of the business, Redisson provides a watchdog to monitor the lock. Its function is to continuously extend the validity of the lock before the Redisson instance is closed. By default, the watchdog's check lock timeout is 30 seconds, which can also be modified Config.lockWatchdogTimeout Otherwise specified.
It should be noted that if the time is specified for the lock, the watchdog function will be turned off. After the business is too long, the program to delete the lock will report an error
Read write lock
I only write some features (please refer to the Redisson document for details):
As long as there is a write lock, you must wait
- Read + read: equivalent to unlocked
- Read + Write: wait for the read lock when writing, and execute after reading
- Write + read: read wait
- Write + Write: write wait
Dual write mode - update the cache while writing to the database

Failure mode - delete the cache while writing to the database and wait for the next read

We can see from the above two figures:
No matter which model we use, there will be data inconsistency, but what can we do?
- If the user's latitude data (it is impossible for the user to add orders and delete orders at a time), the concurrency probability is very small. This problem does not need to be considered. In addition to the expiration time, you only need to actively query the database at intervals
- If it is basic data such as catalog and product introduction, it will not have a great impact on the business and allow inconsistent cache. If you want to consider, you can use cananl subscription
- Cache data + expiration time: most requirements can be guaranteed
- Through locking and concurrent reading and writing, it is suitable for the characteristics of less writing and more reading
Summary:
- The data we put into the cache should not be data with high real-time and consistency requirements
- It should not be over designed to increase the complexity of the system
- In case of data with high real-time requirements, we should check the database, even if it is slower
I only do summary, all the above come from all the big guys