Application of thread pool
After understanding the basic implementation principle of thread pool in Java, how do developers apply thread pool in some excellent Java frameworks?
Take Tomcat and dubbo as examples to analyze the application of thread pool in actual production.
Thread pool in Tomcat
Tomcat extends the thread pool of JUC based on its own business scenario. Its main extensions include two classes:
- ThreadPoolExecute
- TaskQueue
ThreadPoolExecute
To extend the thread pool, you must first customize a ThreadPoolExecute to inherit java.util.concurrent.ThreadPoolExecutor
public class ThreadPoolExecutor extends java.util.concurrent.ThreadPoolExecutor
Then override the execute method
@Override
public void execute(Runnable command) {
execute(command,0,TimeUnit.MILLISECONDS);
}
public void execute(Runnable command, long timeout, TimeUnit unit) {
//Count plus one
submittedCount.incrementAndGet();
try {
super.execute(command);
} catch (RejectedExecutionException rx) {
if (super.getQueue() instanceof TaskQueue) {
final TaskQueue queue = (TaskQueue)super.getQueue();
try {
//After the task is rejected, try adding to the queue again
if (!queue.force(command, timeout, unit)) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException(sm.getString("threadPoolExecutor.queueFull"));
}
} catch (InterruptedException x) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
} else {
submittedCount.decrementAndGet();
throw rx;
}
}
}
In the tomcat thread pool, a counting variable submittedCount is defined, which represents the total number of tasks submitted to the thread pool, including the number of threads being executed and the number of tasks in the queue.
Its value is updated in real time when the execute method and the self implemented afterExecute method are executed.
In addition, why add some additional functions, such as stopCurrentThreadIfNeeded, and turn off the current thread to prevent memory leakage.
TaskQueue
TaskQueue is a blocking queue implemented by tomcat. It mainly rewrites the offer method.
@Override
public boolean offer(Runnable o) {
if (parent==null) return super.offer(o);
if (parent.getPoolSize() == parent.getMaximumPoolSize()) return super.offer(o);
//If the number of tasks submitted to the thread pool is less than the number of threads, it indicates that there are idle threads. Then put the tasks in the queue and wait for the threads to fetch them
if (parent.getSubmittedCount()<=(parent.getPoolSize())) return super.offer(o);
//If the number of threads in the thread pool is less than the maximum number of threads, adding a task to the queue fails
if (parent.getPoolSize()<parent.getMaximumPoolSize()) return false;
return super.offer(o);
}
In the JUC thread pool, the second step of the execute method is to try to add to the queue when the number of threads is greater than the number of cores. If the addition fails, create a new thread to execute the task.
In tomcat, the queue method is: if the number of threads is less than the maximum number of threads, the call to the offer method will fail, that is, the third step of the execute method will be executed: create a new thread.
summary
Compared with the native thread pool of JUC, tomcat thread pool takes the lead in creating threads to execute tasks. Tasks will be submitted to the queue only when the number of threads reaches the maximum number of threads or there are idle threads.
Why?
Why did tomcat make this change?
Thread pool configuration is usually based on CPU intensive and IO intensive business scenarios.
JUC thread pool, which keeps as few core threads as possible to perform tasks, is obviously more suitable for CPU intensive scenarios.
As a web container, Tomcat needs to process a large number of network requests, so generally, its scenario is IO intensive. In this scenario, the thread execution time is short, and increasing the number of threads can enhance the concurrent processing ability.
Thread pool in dubbo
When it comes to the application of thread pool in dubbo, you must first understand the thread model in dubbo.
dubbo thread model
By default, the underlying network communication of dubbo uses netty. Netty is implemented and extended based on Java Nio by default, so it adopts Selector network communication mode. The implementation in netty is that the service party uses two-level thread pools, EventLoopGroup(boss) and EventLoopGroup(worker). The former handles IO connections and the latter handles IO read-write events.
How should the service provider's Netty IO thread handle the business logic?
If the processing logic is relatively simple and new IO requests will not be initiated, it will be faster to process directly on the current thread; If the processing logic is complex or time-consuming, business threads should be used for processing. Otherwise, IO threads will be blocked and the processing efficiency will be low.
dubbo provides five thread models according to whether the requested message is processed directly on the IO thread or by the business thread pool:
- All (all dispatcher) all messages are dispatched to the business thread pool
- All direct (direct dispatcher) messages are not distributed to the business thread pool, but are processed on the IO thread
- message(MessageOnlyDispatcher) sends only the requested response message to the business thread pool
- execution(ExecutionDispatcher) only request messages are dispatched to the business thread pool
- connection(ConnectionOrderedDispatcher) queues the connection and disconnection events on the IO thread and executes them in sequence. Other events are sent to the business thread
In dubbo's design, SPI mechanism is widely used so that users can freely configure the policies used in various scenarios. The same is true for the thread model policy. The default policy is all.
@SPI(AllDispatcher.NAME)
public interface Dispatcher{}
Thread pool policy
dubbo also provides a variety of implementations for thread pools.
@SPI("fixed")
public interface ThreadPool {}
The default policy of the service provider is a thread pool with a fixed number of threads.
- fixed(FixedThreadPool) is a thread pool with a fixed number of threads. The default number of threads is 200, which is the same as newFixedThreadPool in JUC
- cached(CachedThreadPool) is an adaptive thread pool. One thread is created for each request. The idle thread is destroyed after 1 minute. It is the same as newCachedThreadPool in JUC
- The number of limited(LimitedThreadPool) threads increases until the limit value (200 by default), and idle threads will not be destroyed
- eager(EagerThreadPool) gives priority to using threads to process tasks. Only when the number of direct threads reaches the maximum can they be put into the queue, which is the same as the thread pool in tomcat
ThreadLessExecutor
Dubbo releases milestone version with 30% performance improvement
In Dubbo version 2.7.5, the process pool model at the consumer end is optimized because:
"For Dubbo applications before version 2.7.5, especially some consumer applications, when faced with large traffic scenarios that require a large number of services and a large number of concurrencies (typical such as gateway scenarios), there is often the problem of excessive allocation of consumer end processes.".
This change introduces org.apache.dubbo.common.threadpool.ThreadlessExecutor.
The thread pool policy on the consumer side is cached by default. The thread pool will create a thread for each consumption request. When the concurrency of consumer applications is large or the response time of providers is long, there will be a lot of consumer threads.
Consumer thread
Consumer model before version 2.7.5
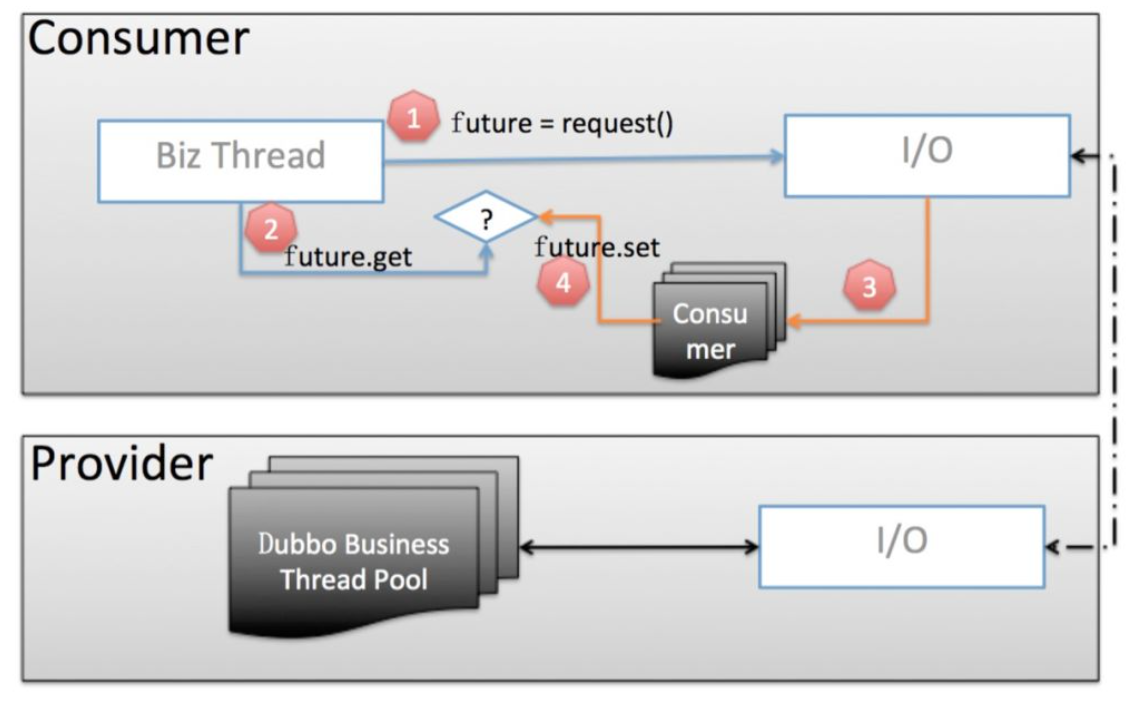
- The consumer business thread initiates a request to get a Future instance
- The business thread then calls future.get() to block and wait for the business result to return
- The service provider returns the result of the business, which is handled by an independent consumer thread pool for anti serialization, and then calls future.set() to write back the result.
- The consumer business thread gets the business result
Consumer thread model after version 2.7.5

- The consumer initiates a request and gets a Future instance
- Before calling future.get(), call the ThreadlessExecutor.waitAndDrain() method, which will make the consumer business thread wait on a blocking queue
- The service provider returns the business result, encapsulates the result into a Runnable Task and adds it to the ThreadlessExecutor queue
- The consumer business thread obtains the Task from the queue and executes it in this thread: deserialize and set it into the future
- Business threads get results from the future
Compared with the old version, the consumer business thread in version 2.7.5 is responsible for monitoring and parsing the results, which eliminates the additional thread pool overhead on the consumer end and solves the problem of a large number of threads on the consumer end.
//org.apache.dubbo.rpc.AsyncRpcResult#get(), where the consumer calls future.get()
@Override
public Result get() throws InterruptedException, ExecutionException {
if (executor != null && executor instanceof ThreadlessExecutor) {
ThreadlessExecutor threadlessExecutor = (ThreadlessExecutor) executor;
//Before calling future.get(), call the wait method to make the business thread wait in the queue
threadlessExecutor.waitAndDrain();
}
return responseFuture.get();
}
Threadless
The biggest difference from ordinary thread pools is that ThreadlessExecutor does not manage any threads.
By calling the execute() method, the tasks submitted to the treadlesexecutor will not be scheduled to specific threads.
@Override
public void execute(Runnable runnable) {
runnable = new RunnableWrapper(runnable);
synchronized (lock) {
if (!waiting) {
sharedExecutor.execute(runnable);
} else {
//After the service provider returns the result, it adds the task to the queue, and then the consumer business thread takes the result from the queue and executes it
queue.add(runnable);
}
}
}
Before calling the future.get() method, the consumer business thread waits in a queue until the service provider returns the result
public void waitAndDrain() throws InterruptedException {
if (finished) {
return;
}
//Blocking waits for the service provider to call excute() and write the result to the queue
Runnable runnable = queue.take();
synchronized (lock) {
waiting = false;
runnable.run();
}
runnable = queue.poll();
while (runnable != null) {
runnable.run();
runnable = queue.poll();
}
finished = true;
}
summary
Before version 2.7.5, the consumer end of dubbo will have too many threads on the consumer end in some cases (the call concurrency is large and the time for the service provider to return the result is long), resulting in oom. Therefore, after version 2.7.5, dubbo adjusted the thread model of the consumer end through local thread reuse (i.e. business thread blocking and waiting) To avoid additional thread consumption.