preface
At this year's Google I/O conference, the Jetpack library added three new components (Alpha version just released), namely, MarcrobenChmark, AppSearch and Google Shortcuts. The MarcrobenChmark component is a library used to measure code performance. Google Shortcuts sounds like a shortcut. In this article, we will focus on leading you to enjoy the use of AppSearch. So what is AppSearch?
What is AppSearch
According to the official description, AppSearch is a search library for managing locally stored structured data, including API s for indexing data and retrieving data through full-text search. You can use this library to build custom in app search functions for users. When I saw the in app search, I first thought of the search page in Android settings. For example, we search and display two words. Here, all function entries containing the word "display" will be displayed, as shown in Figure 1:

Figure 1 setting internal search
Next, let's take a detailed look at how to use AppSearch and the pits I've stepped on.
Import related Library
First, we introduce the relevant libraries of AppSearch components in build.gradle. The code is as follows:
def appsearch_version = "1.0.0-alpha01"
implementation("androidx.appsearch:appsearch:$appsearch_version")
kapt("androidx.appsearch:appsearch-compiler:$appsearch_version")
implementation("androidx.appsearch:appsearch-local-storage:$appsearch_version")In AppSearch, a data unit is represented as a document. Each document in the AppSearch database is uniquely identified by its namespace and ID. Namespaces are used to separate data from different sources, which is equivalent to tables in sql. So let's create a data unit.
Create a data unit
We take the news class as an example and create the following data classes:
@Document
data class News(
@Document.Namespace
val namespace: String,
@Document.Id
val id: String,
@Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES)
val newsTitle: String,
@Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES)
val newsContent: String
)First of all, all data units in AppSearch should be annotated with @ Document. namespace and id are the required fields of data type. newsTitle and newsContent are the news title and news content fields defined by ourselves, which are mentioned here
@Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES)
This annotation, @ Document.StringProperty is to configure the string type variable as the AppSearch property. If it is an integer, it is
@Document.Int64Property
Boolean type is
@Document.BooleanProperty
And so on. The indexingType attribute value can be understood as the matching method, which is set to indexing here_ TYPE_ Prefixes. For example, when the matching condition is Huang, you can match HuangLinqing. For other sexy interests, you can see the source code androidx.appsearch.app.AppSearchSchema class. After creating the data class, like other database operations, next, create a database.
Create database
When the database is created, a ListenableFuture will be returned to us for the operation of the whole database. The code is as follows:
val context: Context = applicationContext
val sessionFuture = LocalStorage.createSearchSession(
LocalStorage.SearchContext.Builder(context, /*databaseName=*/"news")
.build()
)At this point, we can see that an error is reported in this line of code, as shown below:

Generally speaking, we need to rely on a library. To be honest, the AppSearch library can be relied on by itself, which is much more convenient for developers, but after all, AppSearch has just released a beta version, and the requirements should not be too high.
We introduce the guava library into build.gradle. The code is as follows:
implementation("com.google.guava:guava:30.1.1-android")After dependency, the above code can run normally, but not here. We can only set the environment of java1.8, otherwise the error of java.lang.nosuchmethoderror: no static method factory will appear later
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
// For Kotlin projects
kotlinOptions {
jvmTarget = "1.8"
}I raised the original question to Google, see https://issuetracker.google.com/issues/191389033
Set data mode
There are the concepts of Schema and schema types in AppSearch, which means Schema and Schema type. A Schema consists of schema types representing unique data types. Here, it refers to the news class. A Schema type consists of attributes containing name, data type and cardinality. Setting the data mode here actually specifies what types of data we can add to the data air named "news".
val setChemaRequest = SetSchemaRequest
.Builder()
.addDocumentClasses(News::class.java).build()
var setSchemaFuture = Futures.transformAsync(
sessionFuture,
AsyncFunction<AppSearchSession?, SetSchemaResponse?> {
it?.setSchema(setChemaRequest)
},
mainExecutor
)First, we created a schema class with the data type of News, and then set the data schema for the data document through the setSchema method of AppSearchSession. The confusion here may be the future.transformasync method. In fact, it is very simple. Future is an asynchronous thread framework in Java, which can be compared to a collaboration, Therefore, if the design of AppSearch can be independent of future, it may be much simpler to use.
But what makes me different is that I consulted some Java friends. They all said that this thing is rarely used. So here we only focus on the use of AppSearch and future related classes. Those who are interested can learn more.
After setting the data mode, we can write data.
Write data
We first define a data class to insert, as shown below:
val new1 = News(
namespace = "new1",
id = "new_id_2",
newsTitle = "who is a boy",
newsContent = "Everyone, guess who is the handsome boy"
)Build PutDocumentsRequest object and execute
val putRequest = PutDocumentsRequest.Builder().addDocuments(new1).build()
val putFuture = Futures.transformAsync(
sessionFuture,
AsyncFunction<AppSearchSession?, AppSearchBatchResult<String, Void>?> {
it?.put(putRequest)
},
mainExecutor
)We can listen for the execution results through Futures.addCallback. The method is as follows:
Futures.addCallback(
putFuture,
object : FutureCallback<AppSearchBatchResult<String, Void>?> {
override fun onSuccess(result: AppSearchBatchResult<String, Void>?) {
// Gets map of successful results from Id to Void
val successfulResults = result?.successes
// Gets map of failed results from Id to AppSearchResult
val failedResults = result?.failures
Log.d(TAG, "success:" + successfulResults.toString())
Log.d(TAG, "Failed:" + failedResults.toString())
}
override fun onFailure(t: Throwable) {
Log.d(TAG, t.message.toString())
}
},
mainExecutor
)After running, the program prints as follows:
Com.longbon.appsearchdemo D / mainactivity: Success: {new_id_1=null} Com.longbon.appsearchdemo D / mainactivity: failed: {}
Note that the storage is successful. Next, we insert another piece of data. The inserted code is consistent, so there is no repetition. The data is as follows:
val news2 = News(
namespace = "new1",
id = "new_id_1",
newsTitle = "Huang Linqing is handsome a boy",
newsContent = "Huang Linqing is an Android development engineer working in Hefei"
)Query data
To query data, first of all, we need to specify that the query range is namespace, which is equivalent to specifying a data table. After all, there may be the same qualified data in different tables.
val searchSpec = SearchSpec.Builder()
.addFilterNamespaces("new1")
.build()Then execute the query operation. The keyword we query here is "handsome"“
val searchFuture = Futures.transform(
sessionFuture,
Function<AppSearchSession?, SearchResults> {
it?.search("handsome", searchSpec)
},
mainExecutor
)Similarly, we use the addCallback method to detect the query results. The code is as follows:
Futures.addCallback(
searchFuture,
object : FutureCallback<SearchResults> {
override fun onSuccess(result: SearchResults?) {
iterateSearchResults(result)
}
override fun onFailure(t: Throwable) {
Log.d(
TAG, "Query failed:" + t
.message
)
}
},
mainExecutor
)If the query is successful, the SearchResults class will be returned. We need to traverse this instance, take out all data and print it, that is, the iterateSearchResults method. The code is as follows:
private fun iterateSearchResults(searchResults: SearchResults?) {
Futures.transform(searchResults?.nextPage, Function<List<SearchResult>, Any> {
it?.let {
it.forEach { searchResult ->
val genericDocument: GenericDocument = searchResult.genericDocument
val schemaType = genericDocument.schemaType
if (schemaType == "News") {
try {
var note = genericDocument.toDocumentClass(News::class.java)
Log.d(
TAG,
"Query result: news title-" + note.newsTitle
)
Log.d(
TAG,
"Query results: news content-" + note.newsContent
)
} catch (e: AppSearchException) {
Log.e(
TAG,
"Failed to convert GenericDocument to Note",
e
)
}
}
}
}
}, mainExecutor)
}The query result is a collection, so we need to traverse the collection, and the data type needs to be News class before we can continue to the next step. Here, we print the News headlines that meet the conditions. The results are as follows:
D/MainActivity: query result: News Title - who is a boy . appsearchdemo D/MainActivity: query result: news content - Everyone, guess who is the handsome boy . appsearchdemo D/MainActivity: query result: News Title - Huang Linqing is a handsome boy . appsearchdemo D/MainActivity: query result: news content - Huang Linqing is an Android development engineer working
Here we can see that when the keyword we query is handsome, we print both results. The first result is that the news title contains the handsome keyword, and the second result is that the news content contains the keyword. If we use ordinary sql, we probably need to do this
select * from table where newsTitle like %key% or newsContent like %key%
Using AppSearch doesn't need to care about which field is matched. As long as any field contains relevant content, the results will be displayed. It's a bit like Baidu search. We can see that some keywords are in the title, some keywords are in the content, and these contents can be queried quickly.
Why do I praise myself
The keyword we searched here is handsome, and the news title is Huang Linqing is a handsome boy. Huang Linqing is a handsome boy. I don't mean to praise myself here, but I found a bug when learning the use of AppSearch. That is, if the above code is inserted in Chinese, I won't get any results during the search, After discovering this problem last night, I raised it to Google
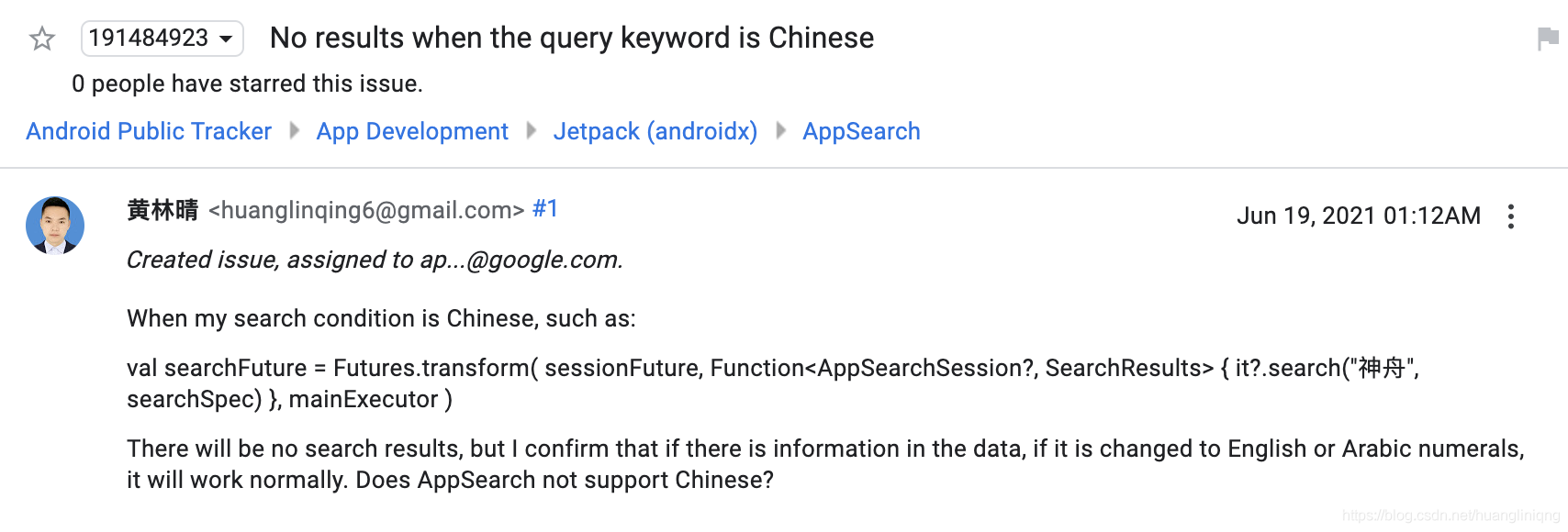
Google also gave a quick reply
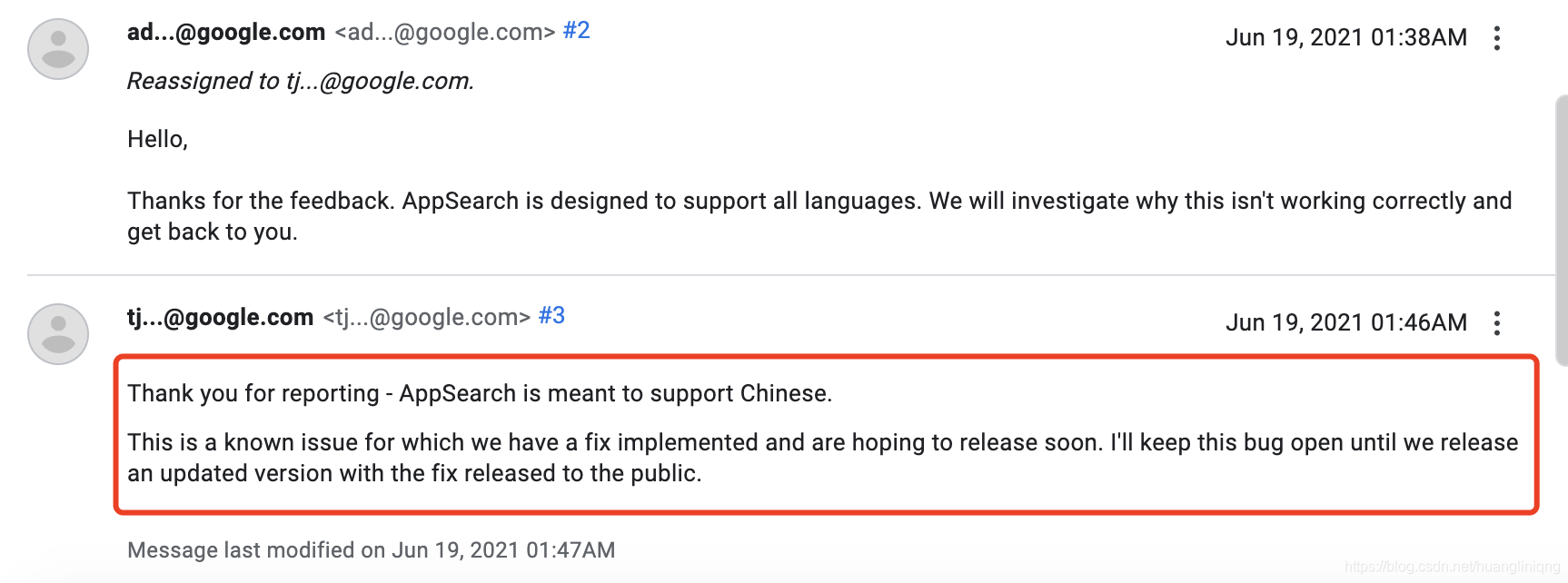
Chinese search is not supported. This is a known problem, and Google will fix it in the new version and release the version as soon as possible, so we can know this problem before the release of the new version to avoid invalid check of our own code.
Delete data
When deleting data, we need to specify the namespace and data id to build a request to delete data. The code is as follows:
val deleteRequest = RemoveByDocumentIdRequest.Builder("new1")
.addIds("new_id_2")
.build()val removeFuture = Futures.transformAsync(
sessionFuture, AsyncFunction {
it?.remove(deleteRequest)
},
mainExecutor
)Here, we can also see that in fact, the use of Appsearch for data operations is to build a request first, and then use Futures to execute it. If you need to detect the results, you can add a callback through Futures.addCallback. After deleting here, we use the keyword "handsome" again "When you query, you will find that only one piece of data is displayed, and the execution results are not displayed here.
Close session
At the beginning of use, we created a Listenablefuture < appsearchsession >, all subsequent data operations are established through this session. After use, we need to close this session. The code is as follows:
val closeFuture = Futures.transform<AppSearchSession, Unit>(
sessionFuture,
Function {
it?.close()
}, mainExecutor
)Summary
AppSearch is the latest component launched by Jetpack. AppSearch is a search library that can easily realize the search function in the application. The I/O usage of AppSearch is very low. Compared with SQLite, AppSearch may be more efficient. However, at present, I still think it has different problems and different angles of solving problems, and is not comparable with other databases, so I choose the appropriate solution Most important.