introduce
The full name of APScheduler is Advanced Python Scheduler. It is a lightweight Python timing task scheduling framework. APScheduler supports three scheduling tasks: fixed time interval, fixed time point (date), and cronab command under Linux. At the same time, it also supports asynchronous execution and background execution of scheduling tasks.
APScheduler is based on a Python timing task framework of Quartz, which realizes all functions of Quartz and is very convenient to use.
install
pip install apscheduler
Official address
https://apscheduler.readthedocs.io/en/latest/userguide.html#starting-the-scheduler
Basic concepts
1. Four components of apscheduler
-
Trigger triggers: used to set the conditions for triggering tasks
-
job stores: used to store tasks in memory or database
-
executors: used to execute tasks. You can set the execution mode to single thread or thread pool
-
Scheduler schedulers: take the above three components as parameters and run by creating a scheduler instance
1.1 trigger triggers
Triggers contain scheduling logic. Each task has its own trigger to determine when the job should run. In addition to the initial configuration, the trigger is completely stateless.
1.2 job stores
By default, tasks are stored in memory. It can also be configured to be stored in different types of databases. If the task is stored in the database, the access of the task has a process of serialization and deserialization. At the same time, the function of modifying and searching the task is also realized by the task memory.
Note that one task memory should not be shared with multiple schedulers, otherwise it will lead to state confusion
1.3 actuators
The task will be put into the thread pool or process pool by the executor to execute. After execution, the executor will notify the scheduler.
1.4 scheduler
A scheduler consists of the above three components. Generally speaking, a program only needs one scheduler. Developers also do not need to directly operate the task memory, executor and trigger, because the scheduler provides a unified interface, and components can be operated through the scheduler, such as adding, deleting, modifying and querying tasks.
Scheduler workflow:
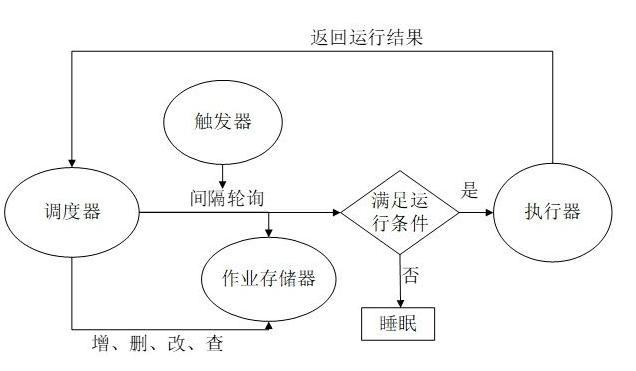
2. Detailed explanation of scheduler components
Select the corresponding components according to the development requirements. The following are different scheduler components:
- Blocking scheduler: it is suitable for programs that only run the scheduler.
- BackgroundScheduler background scheduler: applicable to non blocking situations. The scheduler will run independently in the background.
- Asynchioscheduler asynchio scheduler is applicable to applications using asynchio.
- GeventScheduler Gevent scheduler, which is applicable to applications passing through Gevent.
- Tornado scheduler, which is suitable for building tornado applications.
- Twistedscheduler twistedscheduler, suitable for building Twisted applications.
- QtScheduler Qt scheduler, suitable for building Qt applications.
2.1 selection of task memory
It depends on whether the task needs persistence. If the task you are running is stateless, select the default task store MemoryJobStore to cope with it. However, if you need to save the state of the task when the program is closed or restarted, you should choose a persistent task store. If so, the author recommends using SQLAlchemyJobStore with PostgreSQL as the background database. This scheme can provide powerful data integration and protection functions.
2.2 selection of actuator
It also depends on your actual needs. The default ThreadPoolExecutor thread pool executor scheme can meet most requirements. If your program is computationally intensive, you'd better use the ProcessPoolExecutor process pool executor scheme to make full use of multiple accounting forces. You can also use ProcessPoolExecutor as the second executor and mix two different executors.
To configure a task, you need to set a task trigger. Trigger can set the cycle, times and time of task running.
3. APScheduler has three built-in triggers
- Date: the specific date that triggers the task to run
- Interval: the interval that triggers the task to run
- cron cycle: the cycle that triggers the task to run
- Calendar interval: used when you want to run tasks at calendar based intervals at specific times of the day
A task can also set multiple triggers. For example, it can be triggered when all trigger conditions are met at the same time, or it can be triggered when one item is met.
3.0 trigger code example
date is the most basic scheduling, and the job task will be executed only once. It represents a specific point in time trigger. Its parameters are as follows:
- run_date(datetime or str): the date or time when the task runs
- timezone(datetime.tzinfo or str): Specifies the time zone
from datetime import date
from apscheduler.schedulers.blocking import BlockingScheduler
scheduler = BlockingScheduler()
def my_job(text):
print(text)
# Note: run_ The date parameter can be of type date, datetime, or text.
# Implemented on April 15, 2019
scheduler.add_job(my_job, 'date', run_date=date(2019, 4, 15), args=['Test task'])
# datetime type (for exact time)
# scheduler.add_job(my_job, 'date', run_date=datetime(2019, 4, 15, 17, 30, 5), args = ['test task'])
# character string
#scheduler.add_job(my_job, 'date', run_date='2009-11-06 16:30:05', args = [' test task '])
scheduler.start()
3.2 interval cycle trigger task
Triggered at fixed time intervals. interval scheduling. The parameters are as follows:
- weeks(int): weeks apart
- days(int): days apart
- hours(int): hours apart
- minutes(int): minutes apart
- seconds(int): how many seconds is the interval
- start_date(datetime or str): start date
- end_ Stror (date): end date
- timezone(datetime.tzinfo or str): time zone
from datetime import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def job_func():
print("Current time:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")
scheduler = BlockingScheduler()
# Triggered every 2 hours
scheduler.add_job(job_func, 'interval', hours=2)
# Execute the job every two minutes from 17:00:00 on April 15, 2019 to 24:00:00 on December 31, 2019_ Func method
scheduler .add_job(job_func, 'interval', minutes=2, start_date='2019-04-15 17:00:00' , end_date='2019-12-31 24:00:00')
# jitter vibration parameter, which adds a random floating number of seconds to each trigger. It is generally applicable to multiple servers to avoid service congestion caused by simultaneous operation.
scheduler.add_job(job_func, 'interval', hours=1, jitter=120)
scheduler.start()
3.3 cron trigger
Triggered periodically at a specific time, compatible with the Linux crontab format. It is the most powerful trigger.
- year(int or str), 4 digits
- month(int or str) (range 1-12)
- day(int or str) (range 1-31)
- week(int or str) weeks (range 1-53)
- day_of_week(int or str) the day or days of the week (range 0-6 or mon,tue,wed,thu,fri,stat,sun)
- hour(int or str) (0-23)
- minute(int or str) (0-59)
- second(int or str) second (0-59)
- start_date(datetime or str) earliest start date (inclusive)
- end_date(datetime or str) latest end date (inclusive)
- timezone(datetime.tzinfo or str) specifies the time zone
Expression type
| expression | Parameter type | describe |
|---|---|---|
| * | All | Wildcards. For example, minutes = * is triggered every minute |
| */a | All | Wildcards divisible by a. |
| a-b | All | Range a-b trigger |
| a-b/c | All | Triggered when the range is a-b and can be divided by c |
| xth y | day | The day of the week triggers. x is the day of the week and y is the day of the week |
| last x | day | Last week, last month |
| last | day | Triggered on the last day of the month |
| x,y,z | All | Combining expressions, you can combine the expression above the determined value or |
Note: month and day_ of_ The week parameter accepts the English abbreviations jan – dec and mon – sun respectively
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job_func(text):
print("Current time:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler = BackgroundScheduler()
# Execute jobs at 00:00, 01:00, 02:00 and 03:00 on Mondays and Tuesdays from January to March and July to September every year_ Func task
scheduler.add_job(job_func, 'cron', month='1-3,7-9',day='0, tue', hour='0-3')
scheduler.start()
Using scheduled_ Add job decorator:
@scheduler.scheduled_job('cron', id='my_job_id', day='last sun')
def some_decorated_task():
print("I am printed at 00:00:00 on the last Sunday of every month!")
Note: daylight saving time problem
Some timezone time zones may have problems with daylight saving time. This may cause the task not to be executed or the task to be executed twice when the command time is switched. To avoid this problem, you can use UTC time or predict and plan the implementation problems in advance.
pri# In the European / Helsinki time zone, it will not be triggered on the last Monday of March; It will be triggered twice on the last Monday of October scheduler.add_job(job_function, 'cron', hour=3, minute=30)
4. Configure scheduler
The APScheduler provides many different ways to configure the scheduler. You can use the configuration dictionary or pass options as keyword parameters. You can also instantiate the scheduler first, then add tasks and configure the scheduler. This gives you maximum flexibility in any environment
A complete list of scheduler level configuration options can be found in the API reference of the BaseScheduler class. Scheduler subclasses can also have other options recorded in their respective API references. The configuration options of each task storage and execution program can also be found on its API reference page.
Suppose you want to run the BackgroundScheduler in your application using the default job store and default executor:
from apscheduler.schedulers.background import BackgroundScheduler scheduler = BackgroundScheduler()
This will provide you with a BackgroundScheduler whose MemoryJobStore is named "default", ThreadPoolExecutor is named "default", and the default maximum number of threads is 10.
If you have such a demand now, two task memories are matched with two actuators respectively; At the same time, modify the default parameters of the task; Finally, change the time zone. You can refer to the following examples. They are completely equivalent.
- MongoDBJobStore named "mongo"
- SQLAlchemyJobStore with name "default"
- ThreadPoolExecutor named "ThreadPoolExecutor", with a maximum of 20 threads
- ProcessPoolExecutor with the name "processpool", with a maximum of 5 processes
- UTC time is the time zone of the scheduler
- The default is to turn off merge mode for new tasks ()
- Set the default maximum number of instances for new tasks to 3
Method 1:
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
jobstores = {
'mongo': MongoDBJobStore(),
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
Method 2:
from apscheduler.schedulers.background import BackgroundScheduler
# The "apscheduler." prefix is hard coded
scheduler = BackgroundScheduler({
'apscheduler.jobstores.mongo': {
'type': 'mongodb'
},
'apscheduler.jobstores.default': {
'type': 'sqlalchemy',
'url': 'sqlite:///jobs.sqlite'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false',
'apscheduler.job_defaults.max_instances': '3',
'apscheduler.timezone': 'UTC',
})
Method 3:
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutor
jobstores = {
'mongo': {'type': 'mongodb'},
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': {'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
# .. You can add tasks here
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
Start scheduler
To start the scheduler, simply call start(). In addition to the blocking scheduler, the non blocking scheduler will return immediately and can continue to run the subsequent code, such as adding tasks.
For BlockingScheduler, the program will block at the start() position, so the code to run must be written before start().
Note: after the scheduler is started, the configuration cannot be modified.
5. Add task
There are two ways to add tasks:
- By calling add_job()
- Scheduled via decorator_ job()
5.1 advantages and disadvantages:
- The first method is the most commonly used; The second method is the most convenient, but the disadvantage is that the task cannot be modified at run time.
- First add_ The job () method returns an apscheduler job. Job instance, so that tasks can be modified or deleted at run time.
You can configure tasks at any time. However, if the scheduler is not started and a task is added at this time, the task is in a temporary state. The next run time is calculated only when the scheduler starts.
It should also be noted that if your executor or task store will serialize tasks, these tasks must comply with:
- Callback functions must be globally available
- Callback function parameters must also be serializable
Important reminder!
If the task is read from the database when the program is initialized, you must define an explicit ID for each task and use replace_existing=True, otherwise you will get a new copy of the task every time you restart the program, which means that the state of the task will not be saved.
In the built-in task store, only MemoryJobStore will not serialize tasks; Among the built-in executors, only ProcessPoolExecutor serializes tasks.
Suggestion: if you want to run the task immediately, you can omit the trigger parameter when adding the task
6. Remove task
If you want to remove a task from the scheduler, you need to remove it from the corresponding task store. There are two ways:
- Call remove_job(), parameters: task ID, task memory name
- Through add_ The remove() method is called on the task instance created by job ()
The second method is more convenient, but only if the instance is saved in a variable when the task instance is created. For scheduled_ Only the first method can be selected for the task created by job().
When the task scheduling ends (for example, the trigger of a task no longer generates the next running time), the task will be removed automatically.
job = scheduler.add_job(myfunc, 'interval', minutes=2)
job.remove()
# Similarly, through the specific ID of the task:
scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
scheduler.remove_job('my_job_id')
7. Suspension and resumption of tasks
Through the task instance or scheduler, tasks can be suspended and resumed. If a task is suspended, the next run time of the task will be removed. Before resuming the task, the run count will not be counted.
There are two ways to pause a task:
- apscheduler.job.Job.pause()
- apscheduler.schedulers.base.BaseScheduler.pause_job()
Recovery task
- apscheduler.job.Job.resume()
- apscheduler.schedulers.base.BaseScheduler.resume_job()
8. Get task list
Through get_jobs() can get a list of modifiable tasks. get_ The second parameter of jobs () can specify the name of the task store, and the task list of the corresponding task store will be obtained.
print_jobs() can quickly print the formatted task list, including trigger, next run time and other information.
Modify task
Via apscheduler job. Job. Modify() or modify_job(), you can modify any attribute of the task except id.
For example:
job.modify(max_instances=6, name='Alternate name')
If you want to reschedule tasks (that is, change triggers), you can use apscheduler job. Job. Reschedule() or reschedule_job(). These methods recreate the trigger and recalculate the next run time.
For example:
scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')
9. Turn off the scheduler
scheduler.shutdown()
By default, the scheduler will process the tasks being executed first, and then close the task storage and executor. However, if you close it directly, you can add parameters:
scheduler.shutdown(wait=False)
The above method will force the scheduler to shut down regardless of whether there are tasks executing or not.
10. Suspend and resume the task process
# Pause the task in progress scheduler.pause() # Recovery task: scheduler.resume() # You can also set all tasks to be suspended by default when the scheduler starts. scheduler.start(paused=True)