UNIX Basics
reaction to a book or an article:
This chapter is an introduction to Unix. The author summarizes the basic knowledge of Unix in concise language and feels that it is written clearly.
UNIX architecture
Strictly speaking, the operating system can be defined as a kind of software, which controls the computer hardware resources and provides the program running environment. We usually call this kind of software kernel.
The structure of the kernel is called system call.
Broadly speaking, the operating system includes the kernel and some other software (system utility, application program, shell and common function library, etc.).
Sign in
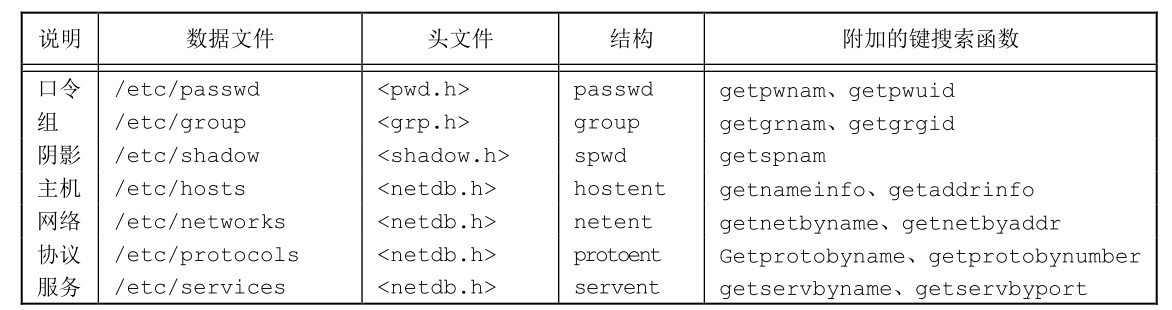
The system stores login entries in the / etc/passwd file, which consists of seven fields separated by colons:
- Login name
- encrypted password
- Digital user ID
- Digital group ID
- comment field
- Starting directory
- shell program
At present, all systems have moved the encrypted password to another file.
Files and directories
UNIX file system is a hierarchical structure of directories and files. The starting point of everything is a directory called root. The name of this directory is a character "/".
A directory is a file that contains directory entries.
The names in the directory are called file names.
When you create a new directory, two file names are automatically created: (called dots) and... (called dots). Point to the current directory and point to the parent directory. In the top-level root directory, dots are the same as dots.
A sequence of one or more file names separated by a slash (which can also start with a slash) constitutes a pathname. The path name starting with a slash is an absolute pathname, otherwise it is called a relative pathname. Relative pathnames point to files relative to the current directory.
Each process has a working directory, sometimes called the current working directory. All relative pathnames are interpreted from the working directory. A process can change its working directory with the chdir function.
When logging in, the working directory is set as the home directory, which is obtained from the login entry of the corresponding user in the password file.
Input and output
File descriptor is usually a small non negative integer, which is used by the kernel to identify the file being accessed by a specific process. When the kernel opens an existing file or creates a new file, it returns a file descriptor.
Whenever a new program is run, all shell s open three file descriptors for it, namely standard input, standard output, and standard error.
The functions open, read, write, lseek, and close provide unbuffered I/O. These functions all use file descriptors.
Standard I/O functions provide a buffered interface for I/O functions that are not buffered.
Procedures and processes
The execution instance of a program is called a process.
The UNIX system ensures that each process has a unique numeric identifier called process ID. The process ID is always a non negative integer.
There are three main functions for process control: fork, exec and waitpid. (there are seven variants of exec functions, which are often collectively referred to as exec functions.)
All threads in a process share the same address space, file descriptor, stack and process related properties. Because they can access the same storage area, each thread needs to take synchronization measures to avoid inconsistency when accessing shared data.
Like processes, threads are also identified with IDs. However, the thread ID only works within the process to which it belongs. Thread IDS in one process have no meaning in another process.
Error handling
When a UNIX system function fails, it usually returns a negative value, and the integer variable errno is usually set to a value with specific information.
Some functions use another convention for errors instead of returning negative values. For example, most functions that return a pointer to an object will return a null pointer when an error occurs.
POSIX and ISO C define errno as a symbol that expands into a modifiable integer lvalue. It can be an integer containing the error number or a function that returns a pointer to the error number. Previously used definitions were:
extern int errno;
However, in the environment of supporting threads, multiple threads share the process address space, and each thread has its own local errno to avoid one thread interfering with another thread. For example, Linux supports multi-threaded access to errno, which is defined as:
extern int *__errno_location(void); #define errno (*__errno_location())
For errno, two rules should be noted:
- If there is no error, its value will not be cleared by the routine. Therefore, the value of a function is checked only if its return value indicates an error.
- No function will set the errno value to 0, and in < errno h> All constants defined in are not 0.
Two functions are defined in the C standard to print error messages:
#include <string.h> char* strerror(int errnum); // Map errornum (usually the errno value) to an error message string and return a pointer to the string #include <stdio.h> void perror(const char *msg); // Based on the current value of errno, an error message is generated on the standard error, and then returned // First, output the character pointed to by msg, then a colon and a space, then output the error message corresponding to the errno value, and finally output a newline character // Usually, we pass argv[0] as a parameter, that is, the file name
Can be set at < errno h> The various errors defined in are divided into two categories: fatal and non fatal.
- Recovery action cannot be performed for fatal errors. The most you can do is print an error message on the user screen or write an error message to the log file, and then exit.
- Non fatal errors can sometimes be handled properly. Most non fatal errors are temporary (e.g. resource shortages).
User ID
The user ID in the password file login is a numeric value that identifies different users to the system.
The user with user ID 0 is root or superuser. In the password file, there is usually a login entry with the login name of root. We call this kind of user privilege super user privilege.
The password file login also includes the user's group ID, which is a numeric value. The group ID is also assigned by the system administrator when specifying the user login name. In general, multiple logins in the password file have the same group ID. Groups are used to assemble several users into projects or departments. This mechanism allows resources (such as files) to be shared among members of the same group.
A group file maps a group name to a numeric group ID. The group file is usually / etc/group.
In addition to the UNIX version ID, most users are allowed to belong to a group in addition to the UNIX version ID. This feature starts with 4.2 BSD, which allows a user to belong to up to 16 other groups. When logging in, read the file / etc/group and look for the first 16 record entries that list the user as its members to get the user's supplementary group ID.
signal
A signal is used to inform a process that something has happened.
The process has the following three ways to process signals:
-
Ignore the signal. This treatment is not recommended.
-
It is handled in the system default way. For divisor 0, the default method is to terminate the process.
-
Provides a function that is called when a signal occurs, which is called capturing the signal. By providing self compiled functions, we can know when the signal is generated and process it in the desired way.
Time value
System basic data type_ T is used to save UTC time value (calendar time).
System basic data type clock_t is used to save the CPU time value (process time).
UNIX system maintains three process time values for a process:
-
Clock time;
-
User CPU time;
-
System CPU time.
User CPU time is the amount of time taken to execute user instructions.
System CPU time is the time spent executing kernel programs for the process.
The sum of user CPU time and system CPU time is often called CPU time.
To obtain the clock time, user time and system time of the process, execute the command time(1).
System calls and library functions
All operating systems provide entry points for multiple services, from which the program requests services from the kernel. Various versions of UNIX implementations provide well-defined, limited number of entry points directly into the kernel, which are called system calls.
Applications can call either system calls or library functions. Many library functions call system calls.
System calls usually provide a minimum interface, while library functions usually provide more complex functions.
Unix standard and Implementation
The first part of this chapter introduces the standard and implementation of Unix operating system, and the later part mainly discusses some macros.
Personally, I think this chapter is not so important for junior programmers like me, so I only record something I think is worth remembering.
Some abbreviations
ANSI: American National Standards Institute, American National Standards Institute.
ISO: International Organization for Standardization.
IEC: International Electronic Commission, International Electronic Technology Association.
IEEE: Institute of Electrical and Electronic Engineers.
POSIX: Portable Operating System Interface.
SUS: Single UNIX Specification.
XSI: X / open system interface.
limit
There are two kinds of restrictions: compile time restrictions and run-time restrictions.
The compile time limit can be defined in the header file, while the run-time limit requires the process to call a function to obtain the limit value.
UNIX provides the following three limitations:
- Compile time restrictions (header files).
- Runtime restrictions independent of files or directories (sysconf function).
- Runtime restrictions related to files or directories (pathconf and fpathconf functions).
#include <unistd.h> long sysconf(int name); long pathconf(const char* pathname, int name); // Use pathname as parameter long fpathconf(int fd, int name); // Use file descriptor as parameter // The above three functions successfully return corresponding values, and - 1 is returned in case of error // If the name parameter is not an appropriate constant, all three functions return - 1 and set errno to EINVAL // Some name s will return a variable value (return value > = 0) or prompt that the value is uncertain. The uncertain value is reflected by returning - 1 without changing the value of errno
option
For each option, there are three possible platform support States.
-
If the symbolic constant is not defined or the defined value is − 1, the platform does not support the corresponding options at compile time.
-
If the defined value of symbolic constant is greater than 0, the platform supports corresponding options.
-
If the defined value of the symbolic constant is 0, you must call sysconf, pathconf, or fpathconf to determine whether the corresponding option is supported. In this case, the name parameter prefix of these functions_ POSIX must be replaced with_ SC or_ PC
For_ Xopen is a constant prefixed with xopen, which must be placed before the name parameter_ SC or_ PC. For example, if constant_ POSIX_ RAW_ If threads is undefined, you can set the name parameter to SC_RAW_THREADS and call sysconf to determine whether the platform supports POSIX thread option. Ruruo constant_ XOPEN_ If UNIX is undefined, you can set the name parameter to_ SC_XOPEN_UNIX, and call sysconf to judge whether the platform supports XSI extension.
File I/O
For the kernel, all open files are referenced through file descriptors. The file descriptor is a nonnegative integer. When an existing file is opened or a new file is created, the kernel returns a file descriptor to the process.
open and openat
Call open and openat to open or create a file.
#include <fcntl.h> int open(const char* path, int oflag, ... /* mode_t mode */); int openat(int fd, const char* path, int oflag, ... /* mode_t mode */); // The path parameter is the name of the file to be opened or created. The oflag parameter can be used to describe multiple options of this parameter // The file descriptor is returned successfully, and - 1 is returned in case of error
oflag parameters are:
- O_RDONLY,O_WRONLY,O_RDWR,O_ Exec (open only), O_ Search (search only, open, apply to directory), these five constants must and can only be specified.
- O_APPEND,O_ TRUNC, O_ Creat (create if not present), O_ Sync (make each write wait for physical I/O to complete, including the I/O required for file attribute update caused by this write operation), O_ Dsync (make each write wait for the physical I/O operation to complete, but if the write operation does not affect the reading of the data just written, there is no need to wait for the file attribute to be updated).
- For more information, please refer to the third edition of APUE P50-P51.
The file descriptor returned by the open and openat functions must be the smallest unused descriptor value.
The fd parameter separates the open function from the openat function. There are three possibilities:
- The path parameter specifies the absolute path name. In this case, the fd parameter is ignored, and the openat function is equivalent to the open function.
- The path parameter specifies the relative pathname, and the fd parameter indicates the starting address of the relative pathname in the file system. The fd parameter is obtained by opening the directory where the relative pathname is located.
- The path parameter specifies the relative pathname, and the fd parameter has a special value of AT_FDCWD. In this case, the pathname is obtained in the current working directory, and the openat function is similar to the open function in operation.
The function of openat:
- Enables a thread to open files in a directory using a relative pathname instead of the current working directory. All threads in the same process share the same current working directory, so it is difficult for multiple different threads in the same process to work in different directories at the same time.
- To avoid time of check to time of use (TOCTTOU) errors.
The basic idea of TOCTTOU error is that if there are two file based function calls, and the second call depends on the result of the first call, the program is fragile.
creat
You can use the create function to create a new file.
#include <fcntl.h> int creat(const char* path, mode_t mode); // Successfully return * write only the file descriptor of open *, and return - 1 in case of error // Equivalent to the following open function call open(path, O_WRONLY | O_CREAT | O_TRUNC, mode);
close
You can use the close function to close an open file.
#include <unistd.h> int close(int fd); // 0 is returned for success and - 1 for error
Closing a file also releases all record locks that the process has placed on the file.
When a process terminates, the kernel automatically closes all its open files. Many programs take advantage of this feature without explicitly closing and opening files with close.
lseek
You can use the lseek function to set the file offset.
#include <unistd.h> off_t lseek(int fd, off_t offset, int whence); // If successful, a new file offset is returned. If an error occurs, a - 1 is returned
The explanation of the parameter offset is related to the value of the parameter when:
- If where is SEEK_SET, set the offset of the file to offset bytes from the beginning of the file.
- If where is SEEK_CUR, set the offset of the file to its current value plus offset, which can be positive or negative.
- If where is SEEK_END, set the offset of the file as the file length plus offset, which can be positive or negative.
View current offset:
off_t currpos; currpos = lseek(fd, 0, SEEK_CUR);
read
Call the read function to read data from the open file.
#include <unistd.h> ssize_t read(int fd, void* buf, size_t nbytes); // Returns the number of bytes read. If the end of the file has been read, it returns 0. If there is an error, it returns - 1
write
Call the write function to write data to the open file.
#include <unistd.h> ssize_t write(int fd, const void* buf, size_t nbytes); // Returns the number of bytes written, or - 1 if there is an error
File sharing
UNIX system supports sharing open files between different processes.
The kernel uses three data structures to represent open files:
-
Each process has a record item in the process table. The record item contains an open file descriptor table, which can be regarded as a vector, and each descriptor occupies one item. Associated with each file descriptor are:
- File descriptor flag;
- Pointer to a file table entry.
-
The kernel maintains a file table for all open files. Each file table entry contains:
- File status flags (read, write, add, sync, non blocking, etc.);
- Current file offset;
- Pointer to the file v node table entry.
-
Each open file (or device) has a v-node structure. The V node contains the file type and pointers to functions that perform various operations on this file. For most files, the V node also contains the i-node (index node) of the file. The I node contains the owner of the file, the length of the file, and the pointer to the location of the actual data block of the file on the disk.
Linux does not use the v node, but uses the general I node structure. Although the two implementations are different, conceptually, the v node is the same as the I node. Both point to the unique i-node structure of the file system.
Some descriptions of the previous operations:
- After each write, the current file offset in the file table entry increases the number of bytes written. If this causes the current file offset to exceed the current file length, set the current file length in the i node table entry to the current file offset.
- If you use o_ When the append flag opens a file, the corresponding flag is also set to the file status flag of the file table item. Each time a write operation is performed on such a file with an additional write flag, the current file offset in the file table entry will first be set to the file length in the i-node table entry. This causes each write of data to be appended to the current end of the file.
- If a file is located at the end of the current file with lseek, the current file offset in the file table item is set to the current file length in the i node table item.
- lseek function only modifies the current file offset in the file table entry without any I/O operation.
Atomic operation
Generally speaking, atomic operation refers to an operation composed of multiple steps. If the operation is performed atomically, either all steps are performed or none is performed. It is impossible to perform only a subset of all steps.
pread and pwrite can atomically locate and execute I / O (can be used in multi-threaded environment):
#include <unistd.h> ssize_t pread(int fd, void* buf, size_t nbytes, off_t offset); // Returns the number of bytes read. If it has reached the end of the file, it returns 0, and if there is an error, it returns - 1 ssize_t pwrite(int fd, const void* buf, size_t nbytes, off_t offset); // The number of bytes read is returned successfully, and - 1 is returned in case of error
DUP and dup2
You can copy an existing file descriptor through the DUP and dup2 functions.
#include <unistd.h> int dup(int fd); int dup2(int fd, int fd2); // A new file descriptor is returned if successful, and - 1 if an error occurs // Where dup is equivalent to fcntl(fd, F_DUPFD, 0); // dup2 is equivalent to: close(fd2); fcntl(fd, F_DUPFD, fd2); // But dup2 is atomic, and the above function is not
The new file descriptor returned by dup must be the smallest number of currently available file descriptors.
For dup2, you can specify the value of the new descriptor with the fd2 parameter:
- If fd2 is already on, turn it off first.
- If FD equals fd2, dup2 returns fd2 without closing it.
- Otherwise, FD of fd2_ The cloexec file descriptor flag is cleared so that fd2 is open when the process calls exec.
sync, fsync, and fdatasync
sync, fsync and fdatasync can be used to ensure the consistency between the actual file system on the disk and the contents in the buffer.
#include <unistd.h> int fsync(int fd); int fdatasync(int fd); // The above two functions return 0 if successful and - 1 if failed void sync(void);
sync simply queues all modified block buffers for writing and then returns. It does not wait for the actual write to disk operation to end.
Typically, a system daemon called update calls the sync function periodically (typically every 30 seconds). This ensures that the block buffer of the kernel is flush ed regularly. The command sync(1) also calls the sync function.
The fsync function works only on a file specified by the file descriptor fd and returns only after the write to disk operation is completed.
fsync can be used for applications such as databases, which need to ensure that modified blocks are written to disk immediately.
The fdatasync function is similar to fsync, but it only affects the data part of the file. In addition to the data, fsync also updates the properties of the file synchronously.
fcntl
The fcntl function can change the properties of an open file.
#include <fcntl.h> int fcntl(int fd, int cmd, ... /* int arg */); // The successful return value depends on cmd, and the error returns - 1
The fcntl function has the following five functions:
- Copy an existing descriptor (cmd=F_DUPFD or f_dupfd_cloxec).
- Gets / sets the file descriptor flag (cmd=F_GETFD or F_SETFD).
- Gets / sets the file status flag (cmd=F_GETFL or F_SETFL).
- Get / set asynchronous I/O ownership (cmd=F_GETOWN or F_SETOWN).
- Get / set record lock (cmd=F_GETLK, F_SETLK or F_SETLKW).
It is necessary to combine the shielded word o when viewing the status flag_ Accmode, please refer to the following code for use mode:
#include "apue.h"
#include <fcntl.h>
// the function of 3-12
// Add flags flag to file descriptor fd
void set_fl(int fd, int flags) {
int val;
if ((val = fcntl(fd, F_GETFL, 0)) < 0) {
err_sys("fcntl F_GETFL error");
}
val |= flags;
if (fcntl(fd, F_SETFL, val) < 0) {
err_sys("fcntl F_SETFL error");
}
}
int main(int argc, char* argv[]) {
int val;
if (argc != 2) {
err_quit("usage: %s <descriptor>", argv[0]);
}
if ((val = fcntl(atoi(argv[1]), F_GETFL, 0)) < 0) {
err_sys("fcntl error for fd %d", atoi(argv[1]));
}
switch (val & O_ACCMODE) {
case O_RDONLY:
printf("read only");
break;
case O_WRONLY:
printf("write only");
case O_RDWR:
printf("read write");
break;
default:
err_dump("unknown access mode");
}
if (val & O_APPEND) {
printf(", append");
}
if (val & O_NONBLOCK) {
printf(", nonblockint");
}
if (val & O_SYNC) {
printf("synchronous writes");
}
#if !defined(_POSIX_C_SOURCE) && defined(O_FSYNC) && (O_FSYNC != O_SYNC)
if (val & O_FSYNC) {
printf(", synchronous writes");
}
#endif
putchar('\n');
exit(0);
}
Set o when the program is running_ The sync flag will increase the system time and clock time.
ioctl
ioctl is the glove box operated by I/O, and terminal I/O is the place where ioctl is used most.
#include <unistd.h> #include <sys/ioctl.h> int ioctl(int fd, int request, ...); // If there is an error, - 1 is returned, and other values are returned successfully
/dev/fd
Newer systems provide a directory named / dev/fd, and its directory entries are files named 0, 1, 2, and so on. Opening the file / dev/fd/n is equivalent to copying descriptor n (assuming descriptor n is open).
Files and directories
stat,fstat,fstatat,lstat
#include <sys/stat.h> int stat(const char* restric pathname, struct stat* restrict buf); int fstat(inf fd, struct stat* buf); int lstat(const char* restrict pathname, strcut stat* restrict buf); int fstatat(int fd, const char* restrict pathname, struct stat* restrict buf, int flag); // If successful, it returns 0; otherwise, it returns - 1
The lstat function is similar to stat, but when the named file is a symbolic link, lstat returns information about the symbolic link instead of the file referenced by the symbolic link.
The fstatat function returns file statistics for a pathname relative to the currently open directory (pointed to by the fd parameter).
-
The flag parameter controls whether a symbolic link is followed. When at_ SYMLINK_ When the nofollow flag is set, fstatat does not follow the symbolic link, but returns the information of the symbolic link itself. Otherwise, by default, the information of the actual file pointed to by the symbolic link is returned.
-
If the value of the fd parameter is AT_FDCWD, and the pathname parameter is a relative pathname, fstatat will calculate the pathname parameter relative to the current directory.
-
If pathname is an absolute path, the fd parameter is ignored.
In the latter two cases, fstatat plays the same role as stat or lstat according to the value of flag.
Note: there are at functions in the follow-up, and the rules are similar to this.
Basic form of struct stat structure:
struct stat {
mode_t st_mode; /* file type & mode (permissions) */
ino_t st_ino; /* i-node number (serial number) */
dev_t st_dev; /* device number (file system) */
dev_t st_rdev; /* device number for special files */
nlink_t st_nlink; /* number of links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
off_t st_size; /* size in bytes, for regular files */
struct timespec st_atime; /* time of last access */
struct timespec st_mtime; /* time of last modification */
struct timespec st_ctime; /* time of last file status change */
blksize_t st_blksize; /* best I/O block size */
blkcnt_t st_blocks; /* number of disk blocks allocated */
};
file type
- regular file. The most commonly used file type, which contains some form of data. As for whether this data is text or binary data, there is no difference for the UNIX kernel. The interpretation of the contents of the ordinary file is performed by the application processing the file.
- Directory file. This file contains the names of other files and pointers to information related to these files. Any process with read permission to a directory file can read the contents of the directory, but only the kernel can write the directory file directly.
- block special file. This type of file provides buffered access to devices (such as disks), with each access taking a fixed length as a unit.
- character special file. This type of file provides unbuffered access to the device, and the length of each access is variable. All devices in the system are either character special files or block special files.
- FIFO. This type of file is used for inter process communication and is sometimes called named pipe.
- socket. This type of file is used for network communication between processes. Sockets can also be used for non network communication between processes on a host.
- symbolic link. This type of file points to another file.
A program to determine the file type:
#include "apue.h"
int main(int argc, char *argv[]) {
struct stat buf;
char *ptr;
for (int i = 1; i < argc; i++) {
printf("%s: ", argv[i]);
if (lstat(argv[i], &buf) < 0) {
err_ret("lstat error");
continue;
}
if (S_ISREG(buf.st_mode))
ptr = "regular";
else if (S_ISDIR(buf.st_mode))
ptr = "directory";
else if (S_ISCHR(buf.st_mode))
ptr = "character special";
else if (S_ISBLK(buf.st_mode))
ptr = "block special";
else if (S_ISFIFO(buf.st_mode))
ptr = "fifo";
else if (S_ISLNK(buf.st_mode))
ptr = "symbolic link";
else if (S_ISSOCK(buf.st_mode))
ptr = "socket";
else
ptr = "** unknown mode **";
printf("%s\n", ptr);
}
exit(0);
}
Set user ID and set group ID
When a program file is executed, the effective user ID of the process is usually the actual user ID, and the effective group ID is usually the actual group ID.
A special flag can be set in the file mode word (st_mode), which means "when this file is executed, set the valid user ID of the process to the user ID (st_uid) of the file owner".
Another bit can also be set in the file mode word, which sets the valid group ID of the process executing the file to the group owner ID (st_gid) of the file.
These two bits in the file mode word are called set user ID bit and set group ID bit.
These two digits are included in the st of the file_ In the mode value, the constants s can be used respectively_ Isuid and S_ISGID for testing.
File access rights
-
S_IRUSR: user read, S_IWUSR: user write, S_IXUSR: user execution.
-
S_IRGRP,S_IWGRP,S_ Ixgrp (Group)
-
S_IROTH,S_IWOTH,S_ Ixoth (others)
Rules for using permissions:
- When we open any type of file with a name, we should have execution permission for each directory contained in the name, including the current working directory it may imply. (the execution permission bit of a directory is often referred to as the search bit)
- The read permission of a file determines whether we can open an existing file for reading. This is the same as o of the open function_ Rdonly and O_RDWR flag related.
- The write permission of a file determines whether we can open an existing file for writing. This is the same as o of the open function_ Wronly and O_RDWR flag related.
- To specify o for a file in the open function_ TRUNC flag, you must have write permission to the file.
- In order to create a new file in a directory, you must have write and execute permissions on the directory.
- In order to delete an existing file, you must have write and execute permissions on the directory containing the file. The file itself does not need to have read and write permissions.
- If you use any of the seven exec functions to execute a file, you must have execution permission on the file. The file must also be a normal file.
Every time a process opens, creates or deletes a file, the kernel tests the file access rights:
- If the valid user ID of the process is 0 (superuser), access is allowed.
- If the effective user ID of the process is equal to the owner ID of the file (that is, the process owns the file), access is allowed if the appropriate access permission bit of the owner is set; Otherwise access is denied.
- If one of the valid group ID of the process or the affiliated group ID of the process is equal to the group ID of the file, access is allowed if the appropriate access permission bit of the group is set; Otherwise access is denied.
- If the appropriate access permission bit of other users is set, access is allowed; Otherwise access is denied.
Ownership of new files and directories
The user ID of the new file is set to a valid user ID of the process. About group IDs, POSIX 1 allows the implementation to select one of the following as the group ID of the new file:
-
The group ID of the new file can be a valid group ID for the process.
-
The group ID of the new file can be the group ID of its directory.
access and faccessat
You can use the access function to test the access rights according to the actual user ID and the actual group ID.
#include <unistd.h> int access(const char* pathname, int mode); int faccessat(int fd, const char* pathname, int mode, int flag); // 0 is returned for success and - 1 for error
mode can be: R_OK,W_OK,X_OK, test the read, write and execute permissions respectively.
The access function and the access function are the same in the following two cases:
- pathname is the absolute path;
- The value of fd parameter is AT_FDCWD and pathname parameter is relative path.
Otherwise, factessat calculates the pathname relative to the open directory (pointed to by the fd parameter).
The flag parameter can be used to change the behavior of factessat if the flag is set to at_ In eAccess, the access check uses the valid user ID and valid group ID of the calling process, rather than the actual user ID and actual group ID.
umask
The umask function sets the file mode for the process, creates a mask word, and returns the previous value.
#include <sys/stat.h> mode_t umask(mode_t cmask);
The umask value is expressed as an octal number, and one bit represents a permission to be shielded.
chmod, fchmod, fchmodat
We can use the chmod function to change the permissions of existing files.
#include <sys/stat.h> int chmod(const char* pathname, mode_t); int fchmod(int fd, mode_t mode); int fchmodat(int fd, const char* pathname, mode_t mode, int flag);
For the difference between fchmodat and chmod functions, refer to the difference between fstatat and stat.
Use example:
#include "apue.h"
int main(int argc, char **argv) {
struct stat statbuf;
if (stat("foo", &statbuf) < 0) {
err_sys("stat error for foo");
}
// Open set group ID and close group execute
if (chmod("foo", (statbuf.st_mode & ~S_IXGRP) | S_ISGID) < 0) {
err_sys("chmod error for foo");
}
if (chmod("bar", S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH) < 0) {
err_sys("chmod error for bar");
}
return 0;
}
The chmod function automatically clears two permission bits under the following conditions:
-
Solaris and other systems give special meaning to the adhesive bit for ordinary files. On these systems, if we try to set the adhesive bit of ordinary files (S_ISVTX) and do not have super user permission, the adhesive bit in mode will be turned off automatically.
-
If the group ID of the new file is not equal to one of the valid group ID of the process or the affiliated group ID of the process, and the process does not have super user permission, the set group ID bit will be automatically closed.
Adhesive position
The adhesive bit (S_ISVTX) was originally used to save the text to improve efficiency. Today's system expands the use scope of the adhesive bit. If the adhesive bit is set for a directory, only the user with write permission to the directory and one of the following conditions can delete or rename the files under the directory:
- Own this document;
- Own this directory;
- Is a super user.
chown,fchown,fchownat,lchown
You can use the chown function to modify the user ID and group ID of the file.
#include <unistd.h> int chown(const char* pathname, uid_t owner, gid_t group); int fchown(int fd, uid_t owner, gid_t group); int fchownat(int fd, const char* pathname, uid_t owner, gid_t group); int lchown(const char* pathname, uid_t owner, gid_t group); // 0 is returned for success and - 1 is returned for failure
Refer to stat series functions for the differences between functions.
file length
stat structure member st_size indicates the length of the file in bytes. This field is only meaningful for ordinary files, catalog files, and symbolic links.
- For ordinary files, the file length can be 0. When reading this file, you will get the end of file indication.
- For directories, the file length is usually an integral multiple of a number, such as 16 or 512.
- For symbolic links, the file length is the actual number of bytes in the file name.
Today, most modern UNIX systems provide the field st_blksize and st_blocks. Among them, the first is the appropriate block length for file I/O, and the second is the actual number of 512 byte blocks allocated.
File truncation
You can use the truncate function to truncate the file to the specified length.
#include <unistd.h> int truncate(const char* pathname, off_t length); int ftruncate(int fd, off_t length); // 0 is returned for success and - 1 is returned for failure
file system
We can divide a disk into one or more partitions. Each partition can contain a file system. The i node is a fixed length record item that contains most of the information about the file.
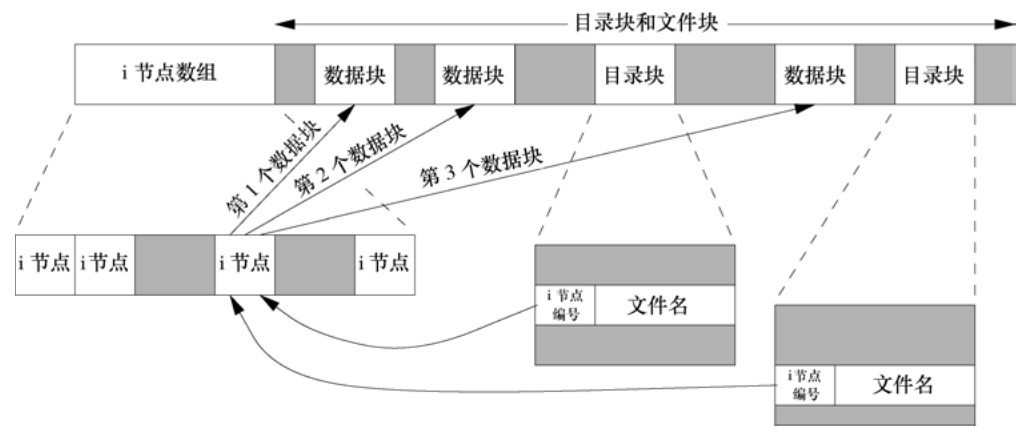
- There is a link count in each i node, and its value is the number of directory items pointing to the i node. The file can be deleted only when the link count is reduced to 0. The link count is included in the nlink of the stat structure_ T members. This type of link is called hard link.
- Another type of link is called symbolic link. The actual content of the symbolic link file (in the data block) contains the name of the file to which the symbolic link points.
- The i node contains all the information related to the file: file type, file access permission bit, file length, pointer to file data block, etc. Most of the information in the stat structure is taken from the i node. Only two important data items are stored in the directory entry: file name and i node number.
- Because the i-node number in a directory entry points to the corresponding i-node in the same file system, a directory entry cannot point to the i-node of another file system.
- When renaming a file without changing the file system, the actual content of the file does not move. Just construct a new directory entry pointing to the existing i node and delete the old directory entry. The link count will not change.
link,linkat,unlink,unlinkat,remove
#include <unistd.h> int link(const char* existingpath, const char* newpath); int linkat(int efd, const char* existingpath, int nfd, const char* newpath, int flag); // 0 is returned for success and - 1 is returned for failure // Refer to stat and fstatat for the difference between the two // These two functions create a new directory entry newpath, which refers to the existing file existingpath. If newpath already exists, an error is returned. Only the last component in the newpath is created, and the rest of the path should already exist. int unlink(const char* pathname); int unlinkat(int fd, const char* pathname, int flag); // 0 is returned for success and - 1 for error // These two functions unlink the file #include <stdio.h> int remove(const char* pathname); // 0 is returned for success and - 1 for error // remove works the same as unlink for files and rmdir for directories
Rename and rename at
You can use the rename function to rename files and directories.
#include <stdio.h> int rename(const char* oldname, const char* newname); int renameat(int oldfd, const char* oldname, int newfd, const char* newname);
Renaming:
- If oldname refers to a file rather than a directory, rename the file or symbolic link. In this case, newname cannot reference a directory if it already exists. If newname already exists and is not a directory, delete the directory entry first, and then rename oldname to newname. The calling process must have write permission on the directory containing oldname and the directory containing newname, because these two directories will be changed.
- If oldname refers to a directory, rename it. If newname already exists, it must refer to a directory and the directory should be empty. If newname exists (and is an empty directory), delete it first, and then rename oldname to newname. In addition, when renaming a directory, newname cannot contain oldname as its path prefix. For example, you cannot rename / usr/foo to / usr/foo/testdir because the old name (/ usr/foo) is the path prefix of the new name and cannot be deleted.
- If oldname or newname refers to a symbolic link, it is the symbolic link itself, not the file it refers to.
- Not right And... Rename. More precisely And... Cannot appear in the last part of oldname and newname.
- As a special case, if oldname and newname refer to the same file, the function returns successfully without making any changes.
Symbolic link
Symbolic link is an indirect pointer to a file. It is different from hard link, which directly points to the i node of the file. The reason for introducing symbolic links is to avoid some limitations of hard links:
-
Hard links usually require the link and file to be in the same file system.
-
Only super users can create hard links to directories (if supported by the underlying file system).
There are no file system restrictions on symbolic links and what objects they point to. Any user can create symbolic links to directories. Symbolic links are generally used to move a file or the entire directory structure to another location in the system.
When you run the ls command with the - F option, an @ symbol appears after the symbolic link
Create and read symbolic links
You can use the symlink function to create a symbolic link.
#include <unistd.h> int symlink(const char* actualpath, const char* sympath); int symlinkat(const char* actualpath, const char* sympath); // 0 is returned for success and - 1 for error // The function creates a new directory entry sympath that points to the actualpath.
readlink provides the function of reading the content of the symbolic link itself (it will not follow the link like open).
#include <unistd.h> ssize_t readlink(const char* restrict pathname, char* restrict buf, size_t bufsize); ssize_t readlinkat(int fd, const char* restrict pathname, char* restrict buf. size_t bufsize); // The number of bytes read is returned successfully, and - 1 is returned in case of error
File time
Each file maintains three time fields:
- st_atime: last access time of file data
- st_mtime: last change time of file data
- st_ CTime: last change time of I node state
The ls -u option sorts by access time and the - c option sorts by status change time.
futimens, utimensat, utimes
You can use the following functions to modify the access and modification time of a file.
#include <sys/stat.h> int futimens(int fd, const struct timespect times[2]); int utimensat(int fd, const char* pathm const struct timespec times[2], int flag); // 0 is returned for success and - 1 for error
How to specify timestamp:
- If the times parameter is a null pointer, both the access time and the modification time are set to the current time.
- If the times parameter points to an array of two timespec structures, the TV of any array element_ The value of the nsec field is UTIME_NOW, the corresponding timestamp is set to the current time and the corresponding TV is ignored_ SEC field.
- If the times parameter points to an array of two timespec structures, the TV of any array element_ The value of the nsec field is UTIME_OMIT, the corresponding timestamp remains unchanged, and the corresponding TV is ignored_ SEC field.
- If the times parameter points to an array of two timespec structures, and TV_ The value of the nsec field is neither UTIME_NOW is not UTIME_OMIT, in this case, the corresponding timestamp is set to the corresponding tv_sec and TV_ The value of the nsec field.
Permissions required to execute these functions:
- If times is a null pointer, or any TV_ The nsec field is set to UTIME_NOW, the valid user ID of the process must be equal to the owner ID of the file; The process must have write permission to the file, or the process is a superuser process.
- If times is a non null pointer and any TV_ The value of the nsec field is neither UTIME_NOW is not UTIME_OMIT, the valid user ID of the process must be equal to the owner ID of the file, or the process must be a superuser process.
- If times is a non null pointer and two TVs_ The values of the nsec field are UTIME_OMIT, no permission check is performed.
#include <sys/time.h>
int utimes(const char* pathname, const struct timeval times[2]);
// 0 is returned for success and - 1 for error
// The structure of timeval is as follows:
struct timeval {
time_t tv_sec; // seconds
long tv_usec; // microseconds
};
mkdir, mkdirat, rmdir
Use the mkdir function to create a directory, and use the rmdir function to delete an empty directory.
#include <sys/stat.h> int mkdir(const char* pathname, mode_t mode); int mkdirat(int fd, const char* pathname, mode_t mode); int rmdir(const char* pathname); // 0 is returned for success and - 1 for error
Read directory
#include <dirent.h> DIR* opendir(const char* pathname); DIR* fdopendir(int fd); // Why not fopendir? Strange. // Pointer returned successfully, NULL returned in case of error struct dirent* readdir(DIR* dp); // Pointer returned successfully, NULL returned in case of error void rewinddir(DIR* dp); // Reset the reading position of the directory to the beginning position int closedir(DIR* dp); // 0 is returned for success and - 1 for error long telldir(DIR* dp); // Returns the current location in the directory associated with dp void seekdir(DIR* dp, long loc);
chdir, fchdir, getcwd
The process can call chdir to change the current working directory.
#include <unistd.h> int chdir(const char* pathname); int fchdir(int fd); // 0 is returned for success and - 1 is returned for failure
Because the current working directory is an attribute of the process, it only affects the process calling chdir itself, not other processes.
Each program runs in a separate process, and the current working directory of the shell will not change with the program calling chdir. It can be seen that in order to change the working directory of the shell process, the shell should directly call the chdir function. Therefore, the cd command is built in the shell.
You can use getcwd to get the current directory.
#include <unistd.h> char* getcwd(char* buf, size_t size); // buf is returned successfully and NULL is returned in case of error
Equipment special documents
st_dev and st_rdev:
-
The storage device of each file system is represented by its primary and secondary device numbers. The data type used for the device number is the basic system data type dev_t. The master device number identifies the device driver, sometimes encoded as a peripheral board communicating with it; The secondary equipment number identifies a specific sub equipment.
-
We can usually use two macros: major and minor to access the primary and secondary device numbers.
-
The st associated with each file name in the system_ The dev value is the device number of the file system, which contains the file name and its corresponding i node.
-
Only character special files and block special files have st_rdev value. This value contains the device number of the actual device.
Stream and FILE objects
For standard I/O libraries, their operations revolve around stream s.
Standard I/O file streams can be used for single byte or multi byte ("wide") character sets.
stream's orientation determines whether the characters read and written are single byte or multi byte.
- When a stream is initially created, it has no orientation.
- If you use a multibyte I/O function on an undirected stream, set the orientation of the stream to wide oriented.
- If you use a single byte I/O function on an undirected stream, set the orientation of the stream to byte oriented.
Only two functions can change the orientation of the flow. The freopen function clears the orientation of a stream; The fwide function can be used to set the orientation of the stream.
#include <stdio.h> #include <wchar.h> int fwide(FILE* fp, int mode); // Returns a positive value if the flow is wide oriented // Returns a negative value if stream is byte oriented // If the flow is directional, then 0 is returned
The fwide function performs different tasks depending on the value of the mode parameter.
- If the value of the mode parameter is negative, fwide will attempt to make the specified stream byte oriented.
- If the mode parameter value is positive, fwide will attempt to make the specified stream wide oriented.
- If the mode parameter value is 0, fwide will not attempt to set the orientation of the stream, but return a value identifying the orientation of the stream.
fwide does not change the orientation of the directed flow.
When a stream is opened, the standard I/O function fopen returns a pointer to the FILE object. This object is usually a structure, which contains all the information required by the standard I/O library to manage the stream, including the FILE descriptor for the actual I/O, the pointer to the buffer used for the stream, the length of the buffer, the number of characters currently in the buffer, and the error flag.
Standard input, standard output, standard error
Three streams are predefined for a process, which can be automatically used by the process. The three standard I/O streams are referenced by the predefined file pointers stdin, stdout and stderr (defined in the header file < stdio. H >).
buffer
Standard I/O provides the following three types of buffering.
- Full buffer. The actual I/O operation is not performed until the standard I/O buffer is filled. Files that reside on disk are usually fully buffered by standard I/O libraries.
- Row buffer. The standard I/O library performs I/O operations when line breaks are encountered in input and output. When a stream involves a terminal (such as standard input and standard output), line buffering is usually used.
- No buffering. The standard I/O library does not buffer characters.
There are two limitations to row buffering:
- As long as the buffer is filled, I/O is performed even if a newline character has not been written.
- Whenever the standard I/O library requires input data from an unbuffered stream or a row buffered stream (which requests data from the kernel), all row buffered output streams will be flushed.
The standard error stream stderr is usually unbuffered, which enables error messages to be displayed as soon as possible, regardless of whether they contain a newline character or not.
You can use the following two functions to change the buffer type:
#include <stdio.h> void setbuf(FILE* restrict fp, char* restric buf); int setvbuf(FILE* restrict fp, char* restric buf, int mode, size_t size); // 0 is returned for success and non-0 is returned for error
You can use the setbuf function to turn the buffering mechanism on or off:
- For buffered I/O, the parameter buf must point to a buffer with a length of BUFSIZ (this constant is defined in < stdio. H >. Usually after that, the stream is fully buffered.
- To turn off buffering, set buf to NULL.
Using setvbuf, we can specify the required buffer type by specifying the mode parameter:
- _ IOFBF full buffer
- _ IOLBF line buffer
- _ IONBF without buffer
If you specify an unbuffered stream, the buf and size parameters are ignored.
If full buffer or line buffer is specified, buf and size can optionally specify a buffer and its length.
If the stream is buffered and buf is NULL, the standard I/O library will automatically allocate a buffer of the appropriate length for the stream. The appropriate length refers to the value specified by the constant BUFSIZ.
Forced flushing one flow:
#include <stdio.h> int fflush(FILE* fp); // 0 is returned for success and EOF is returned for failure
This function causes all unwritten data of the stream to be transferred to the kernel.
Open stream
You can open a standard I/O stream using the following functions:
#include <stdio.h> FILE* fopen(const char* restric pathname, const char* restrict type); FILE* freopen(const char* restrict pathname, const char* restrict type, FILE* restrict fp); FILE* fdopen(int fd, const char* type); // The file pointer is returned successfully, and NULL is returned in case of error
-
The fopen function opens a specified file with the path name pathname.
-
The freopen function opens a specified file on a specified stream. If the stream is already open, close the stream first. If the stream is already directed, use freeopen to clear the direction.
This function is generally used to open a specified file as a predefined stream: standard input, standard output, or standard error.
-
The fdopen function takes an existing file descriptor and combines a standard I/O stream with the descriptor.
This function is commonly used for descriptors returned by the create pipeline and network communication channel functions.
The type parameter specifies the reading and writing methods of the I/O stream:

When a file is opened in read and write type (the + sign in the type), it has the following restrictions:
- If there is no fflush, fseek, fsetpos or rewind in the middle, the input cannot be followed directly after the output.
- If there is no fseek, fsetpos or rewind in the middle, or an input operation does not reach the end of the file, the output cannot be directly followed after the input operation.
You can call fclose to close an open stream:
#include <stdio.h> int fclose(FILE* fp); // 0 is returned for success and EOF is returned for error
Flush the output data in the buffer before the file is closed. Any input data in the buffer is discarded. If the standard I/O library has automatically allocated a buffer for the stream, release the buffer.
When a process terminates normally (directly calling the exit function or returning from the main function), all standard I/O streams with unwritten buffered data are flushed and all open standard I/O streams are closed.
Read and write streams
You can use the getc function to read one character at a time:
#include <stdio.h> int getc(FILE* fp); int fgetc(FILE* fp); int getchar(void); // The next character is returned successfully. If the end of the file has been reached or there is an error, EOF is returned
The function getchar is equivalent to getc(stdin).
The difference between getc and fgetc is that getc can be implemented as a macro, while fgetc cannot be implemented as a macro.
You can use the following two functions to determine whether there is an error and to reach the end of the file:
#include <stdio.h> int ferror(FILE* fp); int feof(FILE* fp); // If the condition is true, it returns non-0, otherwise it returns 0
In most implementations, two flags are maintained in the FILE object for each stream:
- Error flag;
- End of file flag.
You can clear these two flags using the clearerr function:
#include <stdio.h> void clearerr(FILE* fp);
You can use ungetc() to push characters into the reflow:
#include <stdio.h> int ungetc(int c, FILE* fp); // c is returned for success and EOF is returned for error
The characters pressed back into the stream can be read out from the stream later, but the order of reading characters is opposite to that of pressing back.
A successful ungetc call will clear the end of file flag of the stream, so one character can still be returned when the end of the file has been reached. The next reading will return this character, and the second reading will return EOF.
When pressing characters back with ungetc, they are not written to the underlying file or device, but just written back to the stream buffer of the standard I/O library.
You can use the putc function to output one character at a time:
#include <stdio.h> int putc(int c, FILE* fp); int fputc(int c, FILE* fp); int putchar(int c); // c is returned for success and EOF is returned for error
putchar © Equivalent to putc(c, stdout), putc can be implemented as a macro, while fputc cannot be implemented as a macro.
One line of I/O at a time
You can use the fgets function to provide the ability to enter one line at a time:
#include <stdio.h> char* fgets(char* restrict buf, int n, FILE* restrict fp); char* gets(char* buf); // Not recommended, which may cause buffer overflow // buf is returned successfully. If the end of the file has been reached or there is an error, NULL is returned
Delete line breaks, get, and keep line breaks.
You can use the fputs function to output one line at a time:
#include <stdio.h> int fputs(const char* restrict str, FILE* restrict fp); int puts(const char* str); // Non negative value is returned successfully, and EOF is returned in case of error
- fputs writes a string terminated with null bytes to the specified stream, and the terminator null at the end is not written out.
- puts writes a string terminated with null bytes to the standard output, and the terminator is not written out. puts then writes a new line character to the standard output.
Binary I/O
You can use fread and fwrite to perform binary I/O operations:
#include <stdio.h> size_t fread(void* restrict ptr, size_t size, size_t n, FILE* restrict fp); size_t fwrite(const void* restrict ptr, size_t size, size_t n, FILE* restrict fp); // Returns the number of objects read or written
Location flow
There are three ways to locate standard I/O flows:
- ftell and fseek functions. The location of the file is stored in a long integer.
- ftello and fseeko functions. Use off for file offset_ T data type replaces long integer.
- fgetpos and fsetpos functions. Using abstract data type fpos_t record the location of the file. This data type can be defined as a large enough number to record the file location as needed.
Applications that need to be ported to non UNIX systems should use fgetpos and fsetpos.
#include <stdio.h> long ftell(FILE* fp); // The current file location is returned successfully, but - 1L is returned in case of error int fseek(FILE* fp, long offset, int whence); // 0 is returned for success and - 1 for error void rewind(FILE* fp);
To locate a text file, where must be SEEK_SET, and offset can only have two values: 0 (back to the starting position of the file) or the value returned by the ftell of the file.
The rewind function sets a stream to the start of the file.
#include <stdio.h> off_t ftello(FILE* fp); // The current file location is returned successfully, and the error is returned (off_t)-1 off_t fseeko(FILE* fp, off_t offset, int whence); // 0 is returned for success and - 1 for error
Except that the type of offset is off_ Except t instead of long, the ftello function is the same as ftell, and the fseeko function is the same as fseek.
#include <stdio.h> int fgetpos(FILE* restrict fp, fpos_t* restrict pos); int fsetpos(FILE* fp, const fpos_t* pos); // 0 is returned for success and non-0 is returned for error
fgetpos stores the current value of the file location indicator in the object pointed to by pos. When you call fsetpos in the future, you can use this value to relocate the flow to that location.
Format I/O
You can use the printf function to format the output:
#include <stdio.h> int printf(const char* restrict format, ...); int fprintf(FILE* restrict fp, const char* restrict format, ...); int dprintf(int fd, const char* restrict format, ...); // The above three functions successfully return the number of output characters, and an error returns a negative value int sprintf(char* restrict buf, const char* restrict format, ...); // The number of characters stored in the array is returned successfully, and a negative value is returned in case of error int snprintf(char* restrict buf, size_t n, const char* restrict format, ...); // If the buffer is large enough, the number of characters to be stored in the array is returned. If there is an error, a negative value is returned
-
printf writes formatted data to standard output.
-
fprintf writes to the specified stream.
-
dprintf writes to the specified file descriptor.
-
sprintf sends the formatted characters into the array buf.
sprintf automatically adds a null byte at the end of the array, but the character is not included in the return value.
The format specifier will not be described in detail. For details, please refer to P128-P129 of the third edition of APUE.
Variants of printf family:
#include <stdarg.h> #include <stdio.h> int vprintf(const char* restrict format, va_list arg); int vfprintf(FILE* restrict fp, const char* restrict format, va_list arg); int vdprintf(int fd, const char* restrict format, va_list arg); // The above three functions successfully return the number of output characters, and an error returns a negative value int vsprintf(char* restrict buf, const char* restrict format, va_list arg); // The number of characters stored in the array is returned successfully, and a negative value is returned in case of error int vsnprintf(char* restrict buf, size_t n, const char* restrict format, va_list arg); // If the buffer is large enough, the number of characters to be stored in the array is returned. If there is an error, a negative value is returned
You can use the scanf function to format the input:
#include <stdio.h> int scanf(const char* restrict format, ...); int fscanf(FILE* restrict fp, const char* restrict format, ...); int sscanf(const char* restrict buf, const char* restrict format, ...); // Returns the number of input items assigned. If the input is wrong or has reached the end of the file before any conversion, EOF is returned
The format specifier will not be described in detail. For details, please refer to P130 of the third edition of APUE.
Variants of the scanf family:
#include <stdarg.h> #include <stdio.h> int vscanf(const char* restrict format, va_list arg); int vfscanf(FILE* restrict fp, const char* restrict format, va_list arg); int vsscanf(const char* restrict buf, const char* restrict format, va_list arg); // Returns the number of input items assigned. If the input is wrong or has reached the end of the file before any conversion, EOF is returned
Implementation details
We can use the fileno function on a stream to obtain its descriptor:
#include <stdio.h> int fileno(FILE* fp); // Returns the file descriptor associated with the stream
Temporary documents
You can use the following two functions to help create temporary files:
#include <stdio.h> char* tmpnam(char* ptr); // Returns a pointer to a unique pathname FILE* tmpfile(void); // The file pointer is returned successfully, and NULL is returned in case of error
The tmpnam function produces a valid pathname string that is different from the existing file name. Each time it is called, a different pathname is generated, and the maximum number of calls is TMP_ Max (defined in < stdio. H >).
-
If ptr is NULL, the generated pathname is stored in a static area, and the pointer to the static area is returned as a function value.
-
If ptr is not NULL, it should be pointing to a length of at least L_ An array of tmpnam characters (the constant L_tmpnam is defined in the header file < stdio. H >).
Disadvantages of using tmpnam and tmpfile (Note: the place where tmpfile is written in the book is tempnam, which is estimated to be wrong. There are many small errors in this book, and the translation and review are not too serious) functions: there is a time window between returning a unique path name and creating a file with that name. In this time window, another process can create a file with the same name.
We can use the following two functions to solve this problem:
#include <stdlib.h> char* mkdtemp(char* template); // The pointer to the directory name is returned successfully, and NULL is returned in case of error int mkstemp(char* template); // The file descriptor is returned successfully, and - 1 is returned in case of error
- The mkdtemp function creates a directory with a unique name;
- The mkstamp function creates a file with a unique name.
The name is selected through the template string. This string is the pathname with the last 6 bits set to XXXXXX. The function replaces these placeholders with different characters to build a unique pathname. If successful, these two functions will modify the template string to reflect the name of the temporary file.
Use example:
#include "apue.h"
#include <errno.h>
void make_temp(char* template);
int main() {
char good_template[] = "/tmp/dirXXXXXX";
char *bad_template = "/tmp/dirXXXXXX";
printf("trying to create first temp file...\n");
make_temp(good_template);
printf("trying to create second temp file...\n");
make_temp(bad_template);
exit(0);
}
void make_temp(char* template) {
int fd;
struct stat sbuf;
if ((fd = mkstemp(template)) < 0) {
err_sys("can't create temporary file");
}
printf("temp name = %s\n", template);
close(fd);
if (stat(template, &sbuf) < 0) {
if (errno == ENOENT) {
printf("file doesn't exist\n");
} else {
err_sys("stat failed");
}
} else {
printf("file exists\n");
unlink(template);
}
}
Output result:
trying to create first temp file... temp name = /tmp/dirKOBzQc file exists trying to create second temp file... Segmentation fault (core dumped)
Memory stream
We can use fmemopen function to create memory stream:
#include <stdio.h> FILE* fmemopen(void *restrict buf, size_t size, const char* restrict type); // The stream pointer is returned successfully, and NULL is returned in case of failure
The type parameter controls how streams are used:
- Whenever the memory stream is opened in append write mode, the current file position is set to the first null byte in the buffer. If there is no null byte in the buffer, the current position is set to the last byte at the end of the buffer. When the stream is not opened in append write mode, the current position is set as the start position of the buffer.
- If the buf parameter is a null pointer, it makes no sense to open the stream for reading or writing. In this case, the buffer is allocated through fmemopen. There is no way to find the address of the buffer. Opening the stream in write only means that the written data cannot be read. Similarly, opening the stream in read means that only the data in the buffer that we cannot write can be read.
- Whenever you need to increase the amount of data in the stream buffer and call fclose, fflush, fseek, fseeko and fsetpos, a null byte will be written in the current position.
Use example:
#include "apue.h"
#define BSZ 48
int main() {
FILE* fp;
char buf[BSZ];
memset(buf, 'a', BSZ-2);
buf[BSZ-2] = '\0';
buf[BSZ-1] = 'X';
if ((fp = fmemopen(buf, BSZ, "w+")) == NULL) {
err_sys("fmemopen failed");
}
printf("initial buffer contents: %s\n", buf);
fprintf(fp, "hello, world");
printf("before flush: %s\n", buf);
fflush(fp);
printf("after flush: %s\n", buf);
printf("len of string in buf = %ld\n", (long)strlen(buf));
memset(buf, 'b', BSZ-2);
buf[BSZ-2] = '\0';
buf[BSZ-1] = 'X';
fprintf(fp, "hello, world!");
fseek(fp, 0, SEEK_SET);
printf("after fseek: %s\n", buf);
printf("len of string in buf = %ld\n", (long)strlen(buf));
memset(buf, 'c', BSZ-2);
buf[BSZ-2] = '\0';
buf[BSZ-1] = 'X';
fprintf(fp, "hello, world");
fclose(fp);
printf("after fclose: %s\n", buf);
printf("len of string in buf = %ld\n", (long)strlen(buf));
return 0;
}
Output result:
initial buffer contents: before flush: after flush: hello, world len of string in buf = 12 after fseek: bbbbbbbbbbbbhello, world! len of string in buf = 25 after fclose: hello, worldcccccccccccccccccccccccccccccccccc len of string in buf = 46
You can also use open_memstream and open_wmemstream function to create a memory stream:
#include <stdio.h> FILE* open_memstream(char** bufp, size_t *sizep); #include <wchar.h> FILE* openwmemstream(wchar_t** bufp, size_t *sizep); // The above two functions return the stream pointer on success and NULL on error
open_ The stream created by the memstream function is byte oriented and open_ The stream created by the wmemstream function is wide byte oriented.
These two functions differ from fmemopen in that:
- The created stream can only be written and opened;
- You cannot specify your own buffer, but you can access the buffer address and size through bufp and sizep parameters respectively;
- After closing the stream, the buffer needs to be released by itself;
- Adding bytes to the stream increases the buffer size.
Some principles must be followed in the use of buffer address and size:
- The buffer address and length are valid only after calling fclose or fflush;
- These values are valid only until the next stream write or call fclose.
System data files and information
Password file
The password file is / etc/passwd, which is an ASCII file.
To prevent a specific user from logging into the system:
- You can set the login shell to / dev/null
- You can also set the login shell to / dev/false. It simply terminates in an unsuccessful (non-zero) state, which the shell judges as false.
- You can also set the login shell to / bin/true. All it does is terminate in a successful (0) state.
- Some systems provide the nologin command, which prints a customizable error message and then terminates in a non-zero state.
One purpose of using nobody user name is to enable anyone to log in to the system,
Some systems provide vipw to edit password files (administrator privileges are required).
The password file entry can be obtained through the following two functions:
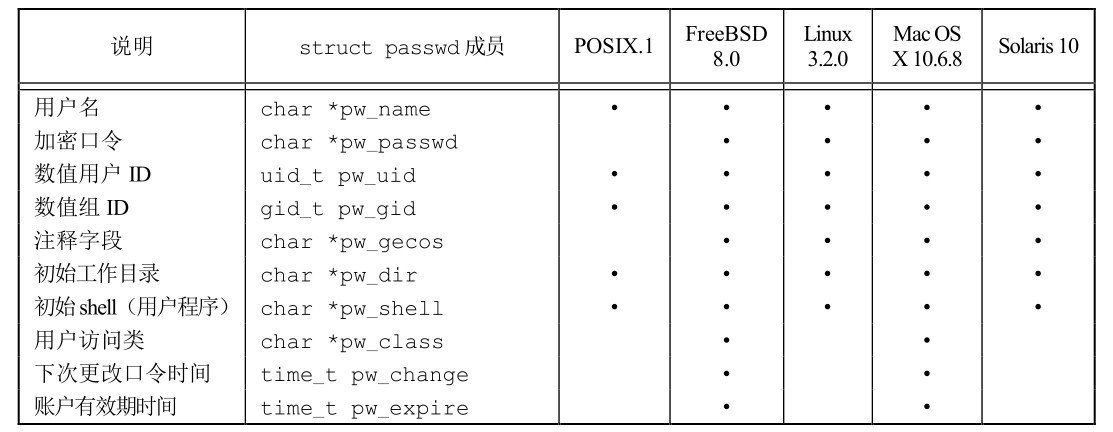
#include <pwd.h> struct passwd* getpwuid(uid_t uid); struct passwd* getpwnam(const char* name); // Pointer returned successfully, NULL returned in case of error
The structure of struct passwd is shown in the following figure:
You can use the following functions to view the entire password file:
#include <pwd.h> struct passwd* getpwent(void); // The pointer is returned successfully. If there is an error or the end of the file is reached, NULL is returned void setpwent(void); void endpwent(void);
- The getpwent function returns the next record entry in the password file.
- setpwent points the read-write address of getpwent to the beginning of the password file.
- endpwent closes these files.
An implementation of getpwnam function:
struct passwd* getpwnam(const char* name) {
struct passwd *ptr;
setpwent();
while ((ptr = getpwent()) != NULL) {
if (strcmp(name, ptr->pw_name) == 0) {
break;
}
}
endpwent();
return ptr;
}
shadow password
The encrypted password is a copy of the user password processed by the one-way encryption algorithm. This algorithm is unidirectional and cannot guess the original password from the encrypted password.
You can access the shadow password file using the following functions:
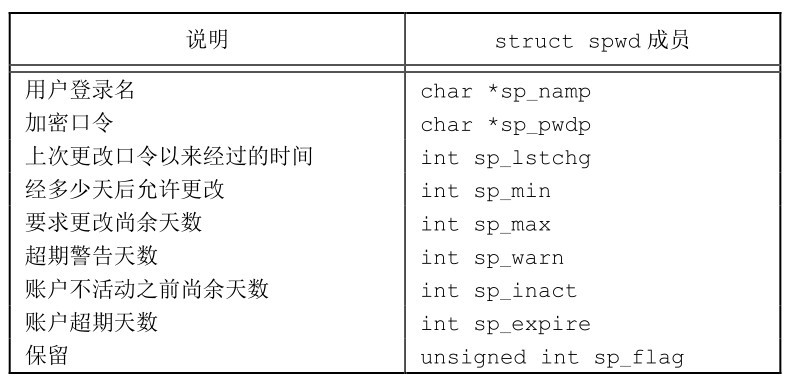
#include <shadow.h> struct spwd* getspwnam(const char* name); struct spwd* getspent(void); // Pointer returned successfully, NULL returned in case of error void setspent(void); void endspent(void);
The structure of struct spwd is shown in the following figure:
Group file
You can use the following two functions to view the group name or numeric group ID:
#include <grp.h> struct group* getgrgid(gid_t gid); struct group* getgrnam(const char* name); // The pointer is returned successfully. If there is an error or the end of the file is reached, NULL is returned
The structure of struct group is shown in the following figure:
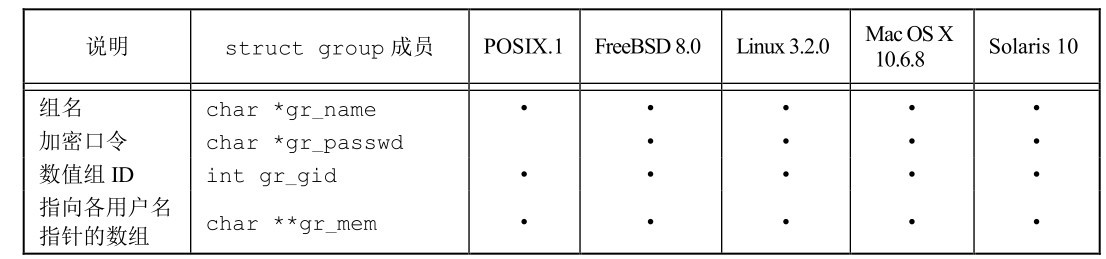
You can use the following functions to search the entire group of files:
#include <grp.h> struct group* getgrent(void); // The pointer is returned successfully. If there is an error or the end of the file is reached, NULL is returned void setgrent(void); void endgrent(void);
Affiliate group ID
You can obtain and set the affiliate group ID through the following functions:
#include <unistd.h> int getgroups(int gidsetsize, git_t grouplist[]); // The number of subsidiary group ID s is returned successfully, and - 1 is returned in case of error #include <grp.h> // in linux int setgroups(int ngroups, const git_t grouplist[]); int initgroups(const char* username, gid_t basegid); // 0 is returned for success and - 1 for error
-
getgroups fills the ID of each affiliated group of the user to which the process belongs into the array grouplist. The maximum number of affiliated group IDs filled into the array is gidsetsize. The number of affiliate group IDs actually filled in the array is returned by the function. If gidsetsize is 0, the function only returns the number of affiliate group IDs, and the array grouplist is not modified.
-
setgroups can be called by the superuser to set the affiliate group ID table for the calling process. grouplist is an array of group IDs, while ngroups describes the number of elements in the array. The value of ngroups cannot be greater than NGROUPS_MAX.
-
Initgroups reads the entire group file (using the numbers getgrent, setgrent, and endgrent), and then determines the membership of its group for username. It then calls setgroups to initialize the affiliate group ID table for the user. In addition to finding all groups where username is located in the group file, initgroups also includes basegid in the affiliated group ID table. Basegid is the group ID of username in the password file.
Other data files
Login account record
Structure used for recording:
struct utmp {
char ut_line[8]; // tty line: "ttyh0", "ttyp0", ...
char ut_name[8]; // login name
long ut_time; // seconds since Epoch
};
When logging in, the login program fills in this type of structure and writes it into utmp file and wtmp file.
When logging off, the init process erases the corresponding records in the utmp file (each byte is filled with null bytes) and adds a new record to the wtmp file.
In the log out record of wtmp file, UT_ The name field is cleared to 0.
When the system restarts, and before and after changing the system time and date, special records are added to the wtmp file.
The who(1) program reads the utmp file and prints its contents in a readable format.
The last(1) command, which reads the wtmp file and prints the selected record.
System identification
You can use the uname function to view information related to the operating system:
#include <sys/utsname.h> int uname(struct utsname* name); // Non negative value is returned successfully, and - 1 is returned in case of error
Structure of struct utsname:
struct utsname {
char sysname[]; // name of the OS
char nodename[]; // name of this node
char release[]; // current release of OS
char version[]; // current version of this release
char machine[]; // name of hardware type
};
You can use uname(1) to print the information in utsname.
You can use the gethostname function to view the hostname:
#include <unistd.h> int gethostname(char* name, int namelen); // 0 is returned for success and - 1 for error
You can get and set the hostname through the hostname(1) command.
Time and date routine
The time function returns the current time and date.
#include <time.h> time_t time(time_t *calptr); // The time value is returned successfully, and - 1 is returned in case of error
You can also use clock_gettime function to get the time of the specified clock:
#include <sys/time.h> int clock_gettime(clockid_t clock_id, struct timespec *tsp); // 0 is returned for success and - 1 for error
Where clock_ Standard value of ID:

The clock ID is set to clock_ When realtime, clock_ In the case of high precision, the function of gettime is similar to the function of gettime_ Gettime may get a more precise time value than the time function.
You can use clock_getres function to adjust the clock accuracy:
#include <sys/time.h> int clock_getres(clockid_t clock_id, struct timespec *tsp); // 0 is returned for success and - 1 for error
clock_ The getres function initializes the timespec structure pointed to by the parameter tsp to and clock_ The clock precision corresponding to the ID parameter. For example, if the accuracy is 1 millisecond, TV_ The SEC field is 0, TV_ The nsec field is 1 000 000.
We can use clock_ Set time to set the time for a specific clock:
#include <sys/time.h> int clock_settime(clockid_t clock_id, const struct timespec *tsp); // 0 is returned for success and - 1 for error
SUSv4 specifies that the gettimeofday function is now deprecated. However, some programs still use this function because gettimeofday provides higher precision (up to microseconds) than the time function.
#include <sys/time.h> int gettimeofday(struct timeval* restrict tp, void* restrict tzp); // The only legal value for tzp is NULL // Always return 0
You can use localtime and gmtime to convert calendar time into decomposed time:
#include <time.h> struct tm *gmtime(const time_t *calptr); struct tm *localtime(const time_t *calptr); // The pointer to the decomposed tm structure is returned successfully, and NULL is returned in case of error
The structure of struct tm is:
struct tm { /* a broken-down time */
int tm_sec; /* seconds after the minute: [0 - 60] */
int tm_min; /* minutes after the hour: [0 - 59] */
int tm_hour; /* hours after midnight: [0 - 23] */
int tm_mday; /* day of the month: [1 - 31] */
int tm_mon; /* months since January: [0 - 11] */
int tm_year; /* years since 1900 */
int tm_wday; /* days since Sunday: [0 - 6] */
int tm_yday; /* days since January 1: [0 - 365] */
int tm_isdst; /* daylight saving time flag: <0, 0, >0 */
};
You can use the mktime function to convert the year, month and day of the local time into time_t value.
#include <time.h> time_t mktime(struct tm *tmptr); // Return value: if successful, return the calendar time; If there is an error, return - 1
You can use the strftime function to format the output time:
#include <time.h> size_t strftime(char *restrict buf, size_t maxsize, const char *restrict format, const struct tm *restrict tmptr); size_t strftime_l(char *restrict buf, size_t maxsize, const char *restrict format, const struct tm *restrict tmptr, locale_t locale); // If the buf space is large enough, the number of characters stored in the array is returned; otherwise, 0 is returned
strftime_l allows the caller to specify the region as a parameter, in addition to strftime and strftime_ The l function is the same.
The tmptr parameter is the time value to be formatted, which is described by a pointer to the decomposition time value tm structure. The format result is stored in a buf array with maxsize characters in length. If the buf length is enough to store the format result and a null terminator, the function returns the number of characters stored in the buf (excluding the null terminator); Otherwise, the function returns 0.
The format parameter controls the format of the time value.

A usage example:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
time_t t;
struct tm* tmp;
char buf1[16];
char buf2[64];
time(&t);
tmp = localtime(&t);
if (strftime(buf1, 16, "time and date: %r, %a %b %d, %Y", tmp) == 0) {
printf("buffer length 16 is too small\n");
} else {
printf("%s\n", buf1);
}
if (strftime(buf2, 64, "time and date: %r, %a %b %d, %Y", tmp) == 0) {
printf("buffer length 64 is too small\n");
} else {
printf("%s\n", buf2);
}
exit(0);
}
Output result:
buffer length 16 is too small time and date: 02:28:54 PM, Wed Apr 28, 2021
strptime function is the reverse version of strftime, which converts string time into decomposition time.
#include <time.h> char *strptime(const char *restrict buf, const char *restrict format, struct tm *restrict tmptr); // Return value: pointer to the next character of the last parsed character; Otherwise, NULL is returned
Format specifier:

process environment
C programs always start with the main function. The prototype of the main function is:
int main(int argc, char *argv[]);
Where argc is the number of command line parameters, and argv is an array of pointers to parameters.
When the kernel executes C program through exec function, a special startup routine is called before calling main. The executable file specifies this startup routine as the starting address of the program (this is set by the connection editor, which is called by the C compiler). The startup routine obtains the command line parameters and environment variable values from the kernel to prepare for calling the main function.
Process termination
There are eight ways to terminate a process.
Five of them are normal termination:
- Return from main;
- Call exit;
- Call_ Exit or_ Exit;
- The last thread returns from its startup routine;
- Pthread is called from the last thread_ exit.
Three types are abnormal termination:
- Call abort;
- Receive a signal;
- The last thread responds to the cancel request.
You can use the exit function to exit the program:
#include <stdlib.h> void exit(int status); void _Exit(int status); #include <unistd.h> void _exit(int status);
Among them_ exit and_ exit immediately enters the kernel. exit performs some cleaning processing first, and then returns to the kernel.
The status parameter passed in is called the termination status (you can check it through the echo $? Command in the shell. If you remember correctly, the maximum value of the status seems to be 255).
The main function returns an integer value, which is equivalent to calling exit with this value.
You can register the termination handler through the atexit function:
#include <stdlib.h> int atexit(void (*func)(void)); // 0 is returned for success and 1 is returned for failure
A process can register up to 32 termination handlers, which will be automatically called by exit. Exit calls these functions in the reverse order of their registration. If the same function is registered multiple times, it will also be called multiple times.
According to ISO C and POSIX 1. exit first calls each termination handler, and then closes (through fclose) all open streams. POSIX.1 extends the ISO C standard, which states that if a program calls any function in the exec function family, all installed termination handlers will be cleared.
Use example of atexit function:
#include "apue.h"
static void my_exit1(void);
static void my_exit2(void);
int main() {
if (atexit(my_exit2) != 0) {
err_sys("can't register my_exit2");
}
if (atexit(my_exit1) != 0) {
err_sys("can't unregister my_exit1");
}
if (atexit(my_exit1) != 0) {
err_sys("can't unregister my_exit1");
}
printf("main is done\n");
return 0;
}
static void my_exit1(void) {
printf("first exit handler\n");
}
static void my_exit2(void) {
printf("second exit handler\n");
}
Output result:
main is done first exit handler first exit handler second exit handler
Command line parameters
ISO C and POSIX 1 requires argv[argc] to be a null pointer.
Environment table
Each program receives an environment table. The environment table is an array of character pointers, where each pointer contains the address of a null terminated C string. The global variable environ contains the address of the pointer array:
extern char **environ;
We call environment pointer, and the pointer array is the environment table, where the string pointed to by each pointer is the environment string.
Storage layout of C program
C program has always been composed of the following parts:
-
Body paragraph. This is the part of the machine instructions executed by the CPU. Usually, the body segment is shareable or read-only.
-
Initialize the data segment. This segment is usually called data segment, which contains variables that need to be explicitly assigned initial values in the program.
-
Data segment not initialized. This segment is usually called bss segment. Before the program starts to execute, the kernel initializes the data in this segment as 0 or null pointer.
-
Stack. Automatic variables and the information to be saved during each function call are stored in this section. Each time a function is called, its return address and the caller's environment information (such as the value of some machine registers) are stored on the stack.
Each time a recursive function calls itself, it uses a new stack frame, so the variable set in one function call instance will not affect the variables in another function call instance.
-
Pile. Dynamic storage allocation is usually done in the heap. Due to historical conventions, the heap is located between uninitialized data segments and the stack.
Typical storage layout:
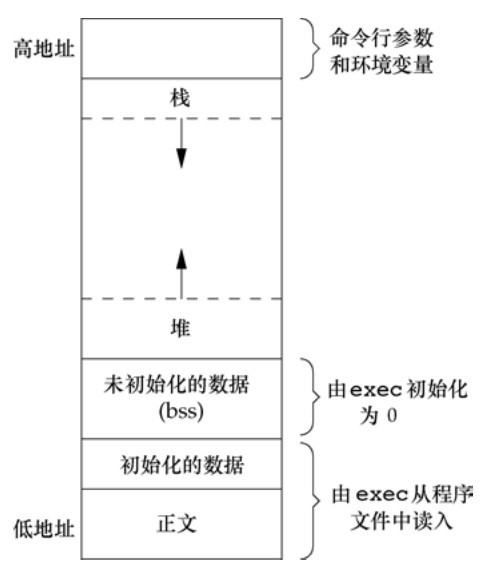
You can view the size of each segment through the size(1) command.
Shared library
The shared library eliminates the need to include common library functions in the executable file, and only saves a copy of this library routine in a store that can be referenced by all processes.
When a program executes or calls a library function for the first time, the dynamic link method is used to link the program with the shared library function.
This reduces the length of each executable, but adds some runtime overhead. This time overhead occurs when the program is executed for the first time, or when each shared library function is called for the first time.
Another advantage of a shared library is that it can replace the old version with a new version of the library function without reconnecting and editing the program using the library (assuming that the number and type of parameters have not changed).
Storage space allocation
You can use malloc, calloc, realloc functions to dynamically allocate memory:
#include <stdlib.h> void* malloc(size_t size); void* calloc(size_t nobj, size_t size); void* realloc(void* ptr, size_t newsize); // The non NULL pointer is returned successfully, and NULL is returned in case of error
The pointers returned by these three allocation functions must be properly aligned so that they can be used for any data object.
If ptr is NULL, realloc has the same function as malloc.
You can use the free function to free dynamically allocated memory:
#include <stdlib.h> void free(void* ptr);
environment variable
The format of the environment string is:
name=value
You can use the getenv function to get the value of the environment variable:
#include <stdlib.h> char* getenv(const char* name); // If found, the pointer of value associated with name will be returned. If not found, NULL will be returned
You can use putenv, setenv, unseenv to set environment variables:
#include <stdlib.h> int putenv(char* str); // 0 is returned for success and non-0 is returned for error int setenv(const char* name, const char* value, int rewrite); int unsetenv(const char* name); // 0 is returned for success and - 1 for error
- putenv puts the string in the form of name=value into the environment table. If name already exists, the original definition will be overwritten.
- setenv sets name to value. If rewrite is not 0, it will be overwritten when it already exists; Otherwise, the existing definition will not be deleted and no error will be reported.
- Unseenv deletes the definition of name. Even if there is no such definition, it is not an error.
Difference between putenv and setenv:
- setenv must allocate storage space to create a name=value string based on its parameters.
- putenv is free to put the parameter string passed to it directly into the environment.
Therefore, passing the string stored in the stack to putenv as a parameter will cause an error because the storage area occupied by its stack frame may be reused when returning from the current function.
setjmp and longjmp
#include <setjmp.h> int setjmp(jmp_buf env); // Direct call returns 0, return from longjmp, return non-0 void longjmp(jmp_buf env, int val);
A usage example:
#include "apue.h"
#include <setjmp.h>
static void f1(int, int, int, int);
static void f2(void);
static jmp_buf jmpbuffer;
static int globalval;
int main() {
int autoval;
register int regival;
volatile int volval;
static int staval;
globalval = 1, autoval = 2, regival = 3, volval = 4, staval = 5;
if (setjmp(jmpbuffer) != 0) {
printf("after longjmp:\n");
printf("globalval = %d, autoval = %d, regival = %d, volval = %d, staval = %d\n", globalval, autoval, regival, volval, staval);
exit(0);
}
globalval = 95, autoval = 96, regival = 97, volval = 98, staval = 99;
f1(autoval, regival, volval, staval);
return 0;
}
static void f1(int i, int j, int k, int l) {
printf("in f1():\n");
printf("globalval = %d, autoval = %d, regival = %d, volval = %d, staval = %d\n", globalval, i, j, k, l);
f2();
}
static void f2(void) {
longjmp(jmpbuffer, 1);
}
Output result:
in f1(): globalval = 95, autoval = 96, regival = 97, volval = 98, staval = 99 after longjmp: globalval = 95, autoval = 96, regival = 3, volval = 98, staval = 99
Whether the value of the variable is rolled back after calling longjmp is uncertain.
If you have an automatic variable and don't want to roll back its value, you can define it as having volatile attribute.
Values declared as global or static variables remain unchanged when longjmp is executed.
getrlimit and setrlimit
Each process has a set of resource constraints, some of which can be queried and changed using the getrlimit and setrlimit functions.
#include <sys/resource.h> int getrlimit(int resource, struct rlimit* rlptr); int setrlimit(int resource, struct rlimit* rlptr); // 0 is returned for success and non-0 is returned for error
The structure of struct rlimit is as follows:
struct rlimit {
rlim_t rlim_cur; /* soft limit: current limit */
rlim_t rlim_max; /* hard limit: maximum value for rlim_cur */
};
When changing resource limits, the following three rules must be followed:
- Any process can change a soft limit value to be less than or equal to its hard limit value.
- Any process can lower its hard limit, but it must be greater than or equal to its soft limit. This reduction is irreversible for ordinary users.
- Only the superuser process can raise the hard limit value.
Constant RLIM_INFINITY specifies an unlimited limit.
For the value of the resource parameter, please refer to P176-177 of the third edition of APUE.
Process control
Process ID
Each process has a unique process ID represented by a non negative integer.
Although it is unique, the process ID is reusable. When a process terminates, its process ID becomes a candidate for reuse.
There are some special processes in the system, and the specific details vary with the implementation:
-
The process with ID 0 is usually a scheduling process, which is often called a swap process. This process is a part of the kernel. It does not execute any programs on disk, so it is also called system process.
-
The process with process ID 1 is usually an init process, which is called by the kernel at the end of the bootstrap process. This process is responsible for starting a UNIX system after booting the kernel. The init process will never terminate. It is an ordinary user process (unlike the exchange process, it is not a system process in the kernel), but it runs with super user privileges.
-
In some UNIX virtual memory implementations, the process with process ID 2 is the page daemon, which is responsible for supporting the paging operation of the virtual memory system.
Some process identifiers can be obtained through the following functions:
#include <unistd.h> pid_t getpid(void); // Returns the process ID of the calling process pid_t getppid(void); // Returns the parent process ID of the calling process uid_t getuid(void); // Returns the actual user ID of the calling process uid_t geteuid(void); // Returns the valid user ID of the calling process git_t getgid(void); // Returns the actual group ID of the calling process gid_t getegid(void); // Returns the valid group ID of the calling process // None of these functions returned an error
fork
An existing process can call the fork function to create a new thread:
#include <unistd.h> pid_t fork(void); // The child process returns 0, the parent process returns the child process ID, and the error returns - 1
A child process is a copy of the parent process, which obtains copies of the parent process's data space, heap and stack.
Parent and child processes share body segments.
Since fork is often followed by exec, many current implementations do not execute a full copy of the parent process data segment, stack, and heap. As an alternative, copy on write (COW) technology is used. These areas are shared by parent and child processes, and the kernel changes their access permissions to read-only. If any one of the parent and child processes tries to modify these areas, the kernel only makes a copy of the memory of the modified area, usually a "page" in the virtual storage system.
Simple demonstration of fork function:
#include "apue.h"
int globvar = 6;
char buf[] = "a write to stdout\n";
int main() {
int var;
pid_t pid;
var = 88;
if (write(STDOUT_FILENO, buf, sizeof(buf) - 1) != sizeof(buf) - 1) {
err_sys("write error!");
}
printf("before fork\n"); // don't flush stdout
if ((pid = fork()) < 0) {
err_sys("fork error!");
} else if (pid == 0) { // child process
globvar++;
var++;
} else { // parent process
sleep(2);
}
printf("pid = %ld, glob = %d, var = %d\n", (long)getpid(), globvar, var);
return 0;
}
Direct output result:
a write to stdout before fork pid = 25767, glob = 7, var = 89 pid = 25766, glob = 6, var = 88
Output after redirecting to a file:
a write to stdout before fork pid = 25790, glob = 7, var = 89 before fork pid = 25789, glob = 6, var = 88
Redirection will change the standard output from "line buffering" to "full buffering", resulting in different results.
One feature of fork is that all open file descriptors of the parent process are copied to the child process. The parent and child processes share a file table entry for each of the same open descriptors, as if the dup function had been executed.
Therefore, when redirecting the standard output of the parent process, the standard output of the child process is also redirected.
In addition to opening the file, many other properties of the parent process are also inherited by the child process, including:
- Actual user ID, actual group ID, valid user ID, valid group ID, affiliated group ID, process group ID and session ID;
- Control terminal;
- Set the user ID flag and set the group ID flag;
- Current working directory and root directory;
- Create screen word in file mode;
- Signal shielding and arrangement;
- Close on exec flag for any open file descriptor;
- Environment, connected shared storage segments, storage images, resource constraints.
Differences between parent and child processes:
- The return value of fork is different;
- If the process ID is different, the parent process ID is different;
- TMS of child process_ utime,tms_stime,tms_cutime and TMS_ The value of ustime is set to 0;
- The child process does not inherit the file lock set by the parent process;
- The unprocessed alarm clock of the child process is cleared;
- The unprocessed signal set of the child process is set to an empty set.
vfork
The vfork function is used to create a new process whose purpose is to exec a new program.
Like fork, vfork creates a child process, but it does not completely copy the address space of the parent process into the child process.
Before the child process calls exec or exit, it runs in the space of the parent process.
vfork ensures that the child process runs first. The parent process may be scheduled to run only after it calls exec or exit. When the child process calls either of these two functions, the parent process will resume running.
exit
The process has 5 normal termination modes and 3 abnormal termination modes.
5 normal termination modes:
-
Execute the return statement within the main function, which is equivalent to calling exit.
-
Call the exit function. Its operations include calling each termination handler (the termination handler is registered when calling atexit function), and then closing all standard I/O streams.
-
Call_ Exit or_ Exit function.
-
The last thread of a process executes a return statement in its startup routine. However, the return value of the thread is not used as the return value of the process. When the last thread returns from its startup routine, the process returns with a termination status of 0.
-
Pthread is called by the last thread of the process_ Exit function. The process termination status is always 0, and is transmitted to pthread_ The parameter of exit is irrelevant.
Three abnormal termination methods:
- Call abort. It generates SIGABRT signal.
- When the process receives some signals. Signals can be generated by the process itself (such as calling the abort function), other processes, or the kernel.
- The last thread responded to the "cancellation" request.
For all processes whose parent process has terminated, their parent process is changed to init process. This process is called the init process.
A process that has been terminated but has not been dealt with by its parent process (obtaining information about terminating the child process and releasing the resources it still occupies) is called zombie. The ps(1) command prints the status of the dead process as Z.
wait and waitpid
When a process terminates normally or abnormally, the kernel sends a SIGCHLD signal to its parent process. Because the termination of a child process is an asynchronous event (which can occur at any time when the parent process is running), this signal is also an asynchronous notification sent by the kernel to the parent process.
Possible effects of calling wait and waitpid:
-
Blocking occurs if all of its child processes are still running.
-
If a child process has been terminated and is waiting for the parent process to obtain its termination status, the termination status of the child process will be returned immediately.
-
If it does not have any child processes, an error is returned immediately.
#include <sys/wait.h> pid_t wait(int *statloc); pid_t waitpid(pid_t pid, int *statloc, int options); // The process ID is returned successfully, and 0 or - 1 is returned in case of error
Statloc is an integer pointer. If statloc is not a null pointer, the termination state of the terminating process is stored in the unit it points to. If you do not care about the termination state, you can specify this parameter as a null pointer.
You can test statloc through the following macros (where status=*statloc):
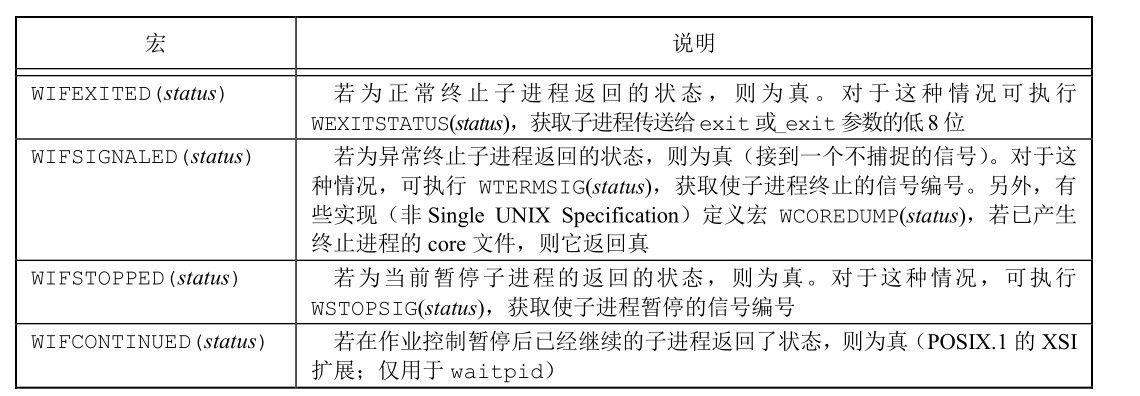
Functions of pid parameters in waitpid function:
-
pid = = − 1: wait for any child process. In this case, waitpid is equivalent to wait.
-
pid > 0: wait for a child process whose process ID is equal to pid.
-
pid == 0: wait for any child process whose group ID is equal to the calling process group ID.
-
pid < − 1: wait for any child process whose group ID is equal to the absolute value of pid.
options parameter of waitpid:

For wait, the only error is that the calling process has no child process. However, for waitpid, if the specified process or process group does not exist, or the process specified by the parameter pid is not a child process of the calling process, an error may occur.
An interesting example is that by fork ing twice, the parent process does not need to wait for the child process to terminate, and the child process does not need to be in a dead state until the parent process terminates.
#include "apue.h"
#include <sys/wait.h>
int main() {
pid_t pid;
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid == 0) {
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) {
exit(0);
}
sleep(2);
// when cur process's parent called exit(0),
// cur process will be adopted by the init process
printf("second child, parent pid = %ld\n", (long)getppid());
exit(0);
}
if (waitpid(pid, NULL, 0) != pid) {
err_sys("waitpid error");
}
exit(0);
}
waitid
Single UNIX Specification includes another function waitid to obtain the process termination status. This function is similar to waitpid, but provides more flexibility.
#include <sys/wait.h> int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options); // 0 is returned for success and - 1 for error
The idtype s and options supported by this function are as follows:
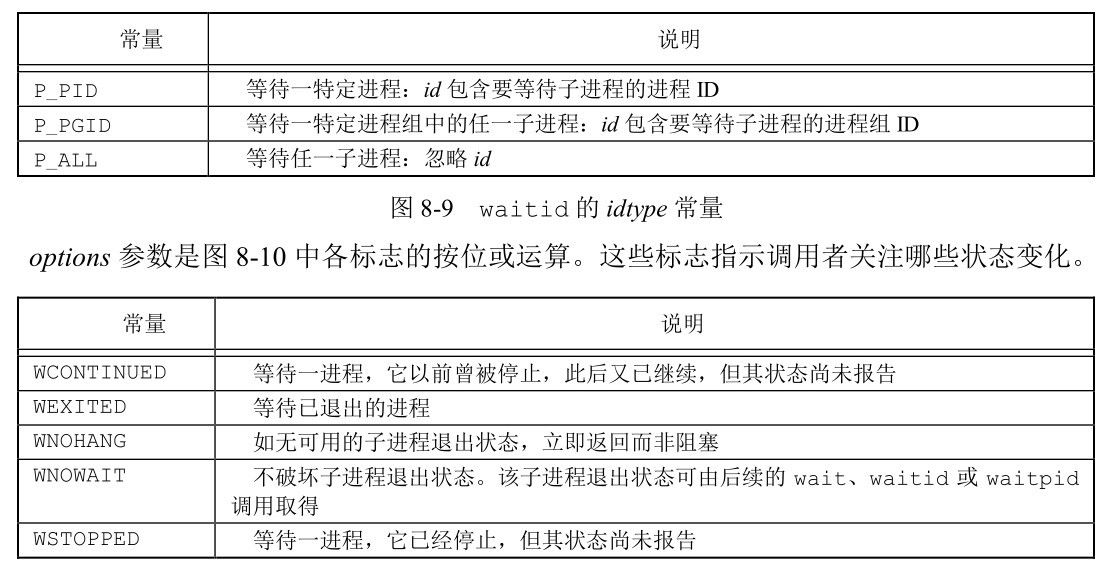
The infop parameter is a pointer to the siginfo structure. This structure contains the detailed information about the signal causing the state change of the child process.
wait3 and wait4
wait3 and wait4 are descended from the BSD branch. They provide more functions than POSIX 1. There should be one more function wait, waitpid and waitid.
#include <sys/types.h> #include <sys/wait.h> #include <sys/time.h> #include <sys/resource.h> pid_t wait3(int *statloc, int options, struct rusage* rusage); pid_t wait4(pid_t pid, int *statloc, int options, struct rusage* rusage); // The process ID is returned successfully, and - 1 is returned in case of error
exec
When a process calls the exec function, the program executed by the process is completely replaced by a new program, and the new program is executed from its main function.
Calling exec does not create a new process. Exec just replaces the body segment, data segment, heap segment and stack segment of the current process with a new program on the disk.
#include <unistd.h> int execl(const char* pathname, const char* arg0, ... /* (char*)0 */); int execv(const char* pathname, char* const argv[]); int execle(const char* pathname, const char* arg0, ... /* (char*)0 char* const envp[] */); int execve(const char* pathname, char* const argv[], char* const envp[]); int execlp(const char* pathname, const char* arg0, ... /* (char*)0 */); int execvp(const char* pathname, char* const argv[]); int fexecve(int fd, char* const argv[], char* const envp[]); // Success is not returned, and error is returned - 1
Functions with p:
-
If the filename contains /, it will be regarded as a pathname;
-
Otherwise, press the PATH environment variable to search for executable files in the directories specified by it.
If execlp or execvp finds an executable file using one of the path prefixes, but the file is not a machine executable generated by the connection editor, it is considered to be a shell script, so try calling / bin/sh and taking the filename as the input of the shell.
l stands for list and v for vector.
Functions ending in e can pass a pointer to an array of environment string pointers. The other four functions use the environ variable in the calling process to copy the existing environment for the new program.
Before and after exec, the actual user ID and actual group ID remain unchanged, while whether the effective ID changes depends on whether the user ID bit and setting group ID bit of the executed program file are set. If the user ID bit of the new program is set, the valid user ID becomes the ID of the program file owner; Otherwise, the valid user ID remains unchanged. The group ID is treated the same way.
Change user ID and change group ID
User ID and group ID can be set through setuid and setgid:
#include <unistd.h> int setuid(uid_t uid); int setgid(gid_t gid); // 0 is returned for success and - 1 for error
Refer to the following figure for the change rules (including the exec function):

The values of actual user ID and valid user ID can be exchanged through setreuid and setregid:
#include <unistd.h> int setreuid(uid_t ruid, uid_t euid); int setregid(gid_t rgid, gid_t egid); // 0 is returned for success and - 1 is returned for failure
Valid ID s can be set through seteuid and setegid:
#include <unistd.h> int seteuid(uid_t uid); int setegid(gid_t gid); // 0 is returned for success and - 1 for error
Interpreter Files
interpreter file is a text file, and its starting line is:
#! pathname [ optional-argument ]
Personal understanding: if the starting line is specified, the parameters of the starting line will be inserted before the original argv array.
system
You can use the system function to execute a command line command in the program:
#include <stdlib.h> int system(const char* cmdstring);
If cmdstring is a null pointer, system returns a non-zero value only if the command handler is available.
system calls fork, exec and waitpid in its implementation, so there are 3 return values.
-
If fork fails or waitpid returns an error other than EINTR, the system returns − 1 and sets errno.
-
If exec fails (indicating that the shell cannot be executed), the return value is the same as if the shell executed exit(127).
-
If all three functions (fork, exec and waitpid) succeed, the return value of system is the termination state of the shell.
A program that sets a user ID or sets a group ID should never call the system function.
Process accounting
The super user executes an accton command with a pathname parameter to enable accounting. The accounting records are written to the specified file. In FreeBSD and Mac OS X, the file is usually / var / Account / account; In Linux, the file is / var/account/pacct; In Solaris, the file is / var/adm/pacct. Execute the accton command without any parameters to stop accounting processing.
Typical accounting records contain a small amount of binary data, generally including command name, total CPU time used, user ID and group ID, startup time, etc.
Each data required for accounting records (each CPU time, the number of characters transmitted, etc.) is saved in the process table by the kernel and initialized when a new process is created (such as in the sub process after fork). Write an accounting record when the process terminates.
Precautions for accounting records:
- We cannot obtain accounting records for processes that never end. Processes like init run throughout the system life cycle and do not produce accounting records. The same applies to kernel daemons, which usually do not terminate.
- The order recorded in the accounting file corresponds to the order in which processes terminate, not the order in which they start.
- Accounting records correspond to processes rather than procedures.
User ID
You can use the getlogin function to get the user login name:
#include <unistd.h> char* getlogin(void); // The pointer to the login string is returned successfully, and NULL is returned in case of error
If the process calling this function is not connected to the terminal used when the user logs in, the function will fail. These processes are commonly referred to as daemon s.
Given the login name, you can use getpwnam to find the corresponding records of users in the password file, so as to determine their login shell, etc.
Process scheduling
NZERO is the system default friendly value.
A process can obtain or change its nice value through the nice function. Using this function, a process can only affect its own nice value, not the nice value of any other process.
#include <unistd.h> int nice(int incr); // The new friendly value is returned successfully, and - 1 is returned in case of error
The ncr parameter is added to the nice value of the calling process. If incr is too large, the system directly reduces it to the maximum legal value. If incr is too small, the system will silently raise it to the minimum legal value.
You can use the getpriority function to get friendly values:
#include <sys/resource.h> int getpriority(int which, id_t who); // The friendly value between - NZERO~NZEROR-1 is returned successfully, and - 1 is returned in case of error
The which parameter controls how the who parameter is interpreted:
- PRIO_PROCESS: process;
- PRIO_PGRP: process group;
- PRIO_USER: user ID.
If the who parameter is 0, it indicates the calling process, process group or user.
When which is set to prio_ When user and who are 0, the actual user ID of the calling process is used.
If the which parameter acts on multiple processes, the highest priority (the smallest nice value) of all processes is returned.
You can use the setpriority function to set priorities for processes, process groups, and all processes belonging to a specific user ID:
#include <sys/resource.h> int setpriority(int which, id_t who, int value); // 0 is returned for success and - 1 for error
Process time
Any process can obtain the process time through the times function:
#include <sys/times.h> clock_t times(struct tms* buf); // The elapsed wall clock time is returned successfully, and - 1 is returned in case of error
The structure of struct tms is:
struct tms {
clock_t tms_utime; // user CPU time
clock_t tms_stime; // system CPU time
clock_t tms_cutime; // user CPU time, terminated children
clock_t tms_cstime; // system CPU time, terminated children
};
The two fields for child processes in this structure contain the values of each child process that this process has been waiting for with the wait function family.
Process relationship
Terminal login
Traditional user authentication in Unix system
When the system bootstrap, the kernel creates the init process. The init process puts the system into multi-user mode. The init process reads the file / etc/ttys. For each terminal device that allows login, init calls fork once, and the child process it generates is the exec getty program.
getty calls the open function on the terminal device to open the terminal by reading and writing.
When the user types in the user name, getty's work is finished. It then calls the login program in a manner similar to the following:
execle("/bin/login", "login", "-p", username, (char *)0, envp);
Multi authentication in modern UNIX system
FreeBSD, Linux, Mac OS X and Solaris all support a more flexible scheme called PAM (Pluggable Authentication Modules). PAM allows managers to configure which authentication methods to use to access services written using the PAM library.
If the user logs in correctly, login will complete the following work:
-
Change the current working directory to the user's starting directory (chdir).
-
Call chown to change the ownership of the terminal so that the logged in user becomes its owner.
-
Change the access right to the terminal device to "user read and write".
-
Call setgid and initgroups to set the group ID of the process.
-
Initialize the environment with all the information obtained from login: starting directory (HOME), shell (shell), USER name (USER and LOGNAME) and a system default PATH (PATH).
-
The login process changes to the user ID (setuid) of the login user and calls the login shell of the user, which is similar to:
execl("/bin/sh", "-sh", (char *)0);The negative sign of the first character of argv[0] is a flag, indicating that the shell is called as a login shell.
Then log in to the shell and read the startup file (such as. bashrc). After executing the startup file, the user finally gets the shell prompt and can type commands.
Network login
In the case of network login, login is only an available service, which is the same as other network services (such as FTP or SMTP).
In order to enable the same software to handle both terminal login and network login, the system uses a software driver called pseudo terminal, which simulates the running behavior of serial terminal and maps the terminal operation to network operation, and vice versa.
BSD network login:
As part of the system startup, init calls a shell to execute the shell script / etc/rc. This shell script starts a daemon inetd. Once the shell script terminates, the parent process of inetd becomes init. Inetd waits for a TCP/IP connection request to arrive at the host, and when a connection request arrives, it executes a fork, and then the generated subprocess exec the appropriate program.
inetd, sometimes referred to as the Internet super server, waits for most network connections.
The login of other systems is roughly the same.
Process group
In addition to a process ID, each process also belongs to a process group.
A process group is a collection of one or more processes. Usually, they are combined in the same job, and each process in the same process group receives various signals from the same terminal. Each process group has a unique process group ID.
You can use the getpgrp function to obtain the process group ID of the calling process:
#include <unistd.h> pid_t getpgrp(void); // Returns the process group ID of the calling process
-
Each process group has a process leader. The process group ID of the leader process is equal to its process ID.
-
The process group leader can create a process group, create processes in the group, and then terminate.
-
As long as there is a process in a process group, the process group exists, which has nothing to do with whether the leader process is terminated or not.
-
The time interval from the creation of a process group to the departure of the last process is called the life of the process group.
-
The last process in a process group can be terminated or transferred to another process group.
A process can call setpgid to join an existing process group or create a new process group:
#include <unistd.h> int setpgid(pid_t pid, pid_t pgid); // 0 is returned for success and - 1 for error
The setpgid function sets the process group ID of the pid process to pgid.
- If these two parameters are equal, the process specified by pid becomes the process group leader.
- If pid is 0, the caller's process ID is used.
- If pgid is 0, the process ID specified by pid is used as the process group ID.
A process can only set the process group ID for itself or its child processes. After its child process calls exec, it will not change the process group ID of the child process.
conversation
A session is a collection of one or more process groups.
Usually, several processes are grouped by the pipeline of the shell.
The process can call the setsid function to create a new session:
#include <unistd.h> pid_t setsid(void); // The process group ID is returned successfully, and - 1 is returned in case of error
If the process calling this function is not the leader of a process group, this function creates a new session:
-
The process becomes the session leader of the new session (session leader, which is the process that creates the session).
-
The process becomes the leader of a new process group. The new process group ID is the process ID of the calling process.
-
The process has no control terminal. If the process has a control terminal before calling setsid, this connection is also cut off.
If the calling process is already the leader of a process group, this function returns an error.
You can call the getsid function to get the process group ID of the first process of the session:
#include <unistd.h> pid_t getsid(pid_t pid); // The process group ID of the first process of the session is returned successfully, and - 1 is returned in case of error
If pid is 0, getsid returns the process group ID of the first process in the session of the calling process.
For security reasons, some implementations have the following limitations: if the pid does not belong to the session where the caller is located, the calling process cannot get the process group ID of the first process of the session.
Control terminal
Additional features of sessions and process groups:
-
A session can have a control terminal. It is usually a terminal device (terminal login) or a pseudo terminal device (network login).
-
The first process of establishing a connection with the control terminal is called the control process.
-
Several process groups in a session can be divided into a foreground process group and one or more background process groups.
-
If a session has a control terminal, it has a foreground process group, and other process groups are background process groups.
-
Whenever you type the interrupt key of the terminal (usually Delete or Ctrl+C), the interrupt signal will be sent to all processes in the foreground process group.
-
Whenever you type the exit key of the terminal (usually Ctrl + \), the exit signal will be sent to all processes in the foreground process group.
-
If the terminal interface detects that the modem (or network) has been disconnected, it sends a hang up signal to the control process.
tcgetpgrp, tcsetpgrp, tcgetsid
You can control the foreground process group through tcgetpgrp and tcsetpgrp:
#include <unistd.h> pid_t tcgetpgrp(int fd); // The foreground process group ID is returned successfully, and - 1 is returned in case of error int tcsetpgrp(int fd, pid_t pgrpid); // 0 is returned for success and - 1 for error
If a process has a control terminal, the process can call tcsetpgrp to set the foreground process group ID to pgrpid.
- The pgrpid value should be the ID of a process group in the same session.
- fd must refer to the control terminal of the session.
You can obtain the process group ID of the first process of the session through the tcgetsid function:
#include <termios.h> pid_t tcgetsid(int fd); // The first process group ID of the session is returned successfully, and - 1 is returned in case of error
Job control
Job control requires the following three forms of support.
-
A shell that supports job control.
-
The terminal driver in the kernel must support job control.
-
The kernel must provide support for some job control signals.
There are three special characters that enable the terminal driver to generate signals and send them to the foreground process group:
-
Interrupt character (usually Delete or Ctrl+C) generates SIGINT;
-
The exit character (Ctrl + \) generates SIGQUIT;
-
The hanging character (generally Ctrl+Z) generates SIGTSTP.
Only the foreground job receives terminal input. If the background job tries to read the terminal, this is not an error, but the terminal driver will detect this and send a specific signal SIGTTIN to the background job. This signal usually stops the background job, and the shell notifies the relevant user of this situation, and then the user can use the shell command to turn the job into a foreground job, so it can read the terminal.
We can control whether the background job is allowed to be output to the control terminal through the stty(1) command. When it is prohibited, it will send SIGTTOU signal to the job to block it (similar to SIGTTIN).
shell executor
The test results of this part on my computer are different from those in the book. I don't understand it very well and don't take notes for the time being.
Orphaned Process Groups
POSIX.1. Define an orphaned process group as: the parent process of each member in the group is either a member of the group or not a member of the session to which the group belongs.
The condition that a process group is not an orphan process group is that there is a process in the group and its parent process is in another group belonging to the same session.
If the process group is not an orphan process group, the parent process in another group belonging to the same session has the opportunity to restart the process stopped in the group.
An example:
#include "apue.h"
#include <errno.h>
static void sig_hup(int signo) {
printf("SIGHUP received, pid = %ld\n", (long) getpid());
}
static void pr_ids(char *name) {
printf("%s: pid = %ld, ppid = %ld, pgrp = %ld, tpgrp = %ld\n", name, (long) getpid(), (long) getppid(),
(long) getpgrp(), (long) tcgetpgrp(STDIN_FILENO));
fflush(stdout);
}
int main() {
char c;
pid_t pid;
pr_ids("parent");
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) {
sleep(5);
} else {
pr_ids("child");
signal(SIGHUP, sig_hup);
kill(getpid(), SIGTSTP);
pr_ids("child");
if (read(STDIN_FILENO, &c, 1) != 1) {
printf("read error %d on controlling TTY\n", errno);
}
exit(0);
}
}
When I use clion to run, the result is similar to that in the book, but the result of manually compiling through gcc and running in wsl is different from that in the book. At present, I don't know what's going on.
FreeBSD implementation
Each session is assigned a session structure:
-
s_count is the number of process groups in the session. When this counter decreases to 0, this structure can be released.
-
s_ The leader is a pointer to the proc structure of the first process of the session.
-
s_ttyvp is a pointer to the vnode structure of the control terminal.
-
s_ttyp is a pointer to the tty structure of the control terminal.
-
s_sid is the session ID.
When calling setsid, allocate a new session structure in the kernel:
- s_count is set to 1.
- s_ The leader is set as the pointer to the proc structure of the calling process.
- s_sid is set to the process ID.
- Because the new session has no control terminal, s_ttyvp and s_ttyp is set to null pointer.
Each terminal device and each pseudo terminal device allocate tty structure in the kernel:
-
t_session refers to the session structure that takes this terminal as the control terminal. When the terminal loses the carrier signal, it uses this pointer to send the suspension signal to the session first process.
-
t_pgrp points to the pgrp structure of the foreground process group. The terminal driver uses this field to send a signal to the foreground process group. Three signals generated by inputting special characters (interrupt, exit and hang) are sent to the foreground process group.
-
t_termios is a structure that contains all these special characters and information related to the terminal (such as baud rate, echo on or off, etc.).
-
t_winsize is a winsize structure that contains the current size of the terminal window. When the size of the terminal window changes, the signal SIGWINCH is sent to the foreground process group.
In order to find the foreground process group of a specific session, the kernel starts with the session structure, and then uses s_ttyp obtains the tty structure of the control terminal, and then t_pgrp gets the pgrp structure of the foreground process group.
The pgrp structure contains information about a specific process group:
-
pg_id is the process group ID.
-
pg_session refers to the session structure of the session to which this process group belongs.
-
pg_members is a pointer to the proc structure table of this process group, which represents the members of the process group. P in proc structure_ The pglist structure is a two-way linked list that points to the next process and the previous process in the group. Until the last process in the process group is encountered, P in its proc structure_ Pglist structure is null pointer.
The proc structure contains all the information of a process:
-
p_pid contains the process ID.
-
p_pptr is a pointer to the proc structure of the parent process.
-
p_pgrp pointer to the pgrp structure of the process group to which this process belongs.
-
p_pglist is a structure that contains two pointers to the previous and next processes in the process group.
signal
Signal concept
The signal is a software interrupt. Each signal has a name that begins with "SIG".
In the header file < signal h> In, signal names are defined as positive integer constants (signal numbers). There is no signal with number 0.
Some ways to generate signals:
-
Pressing some terminal keys will cause the terminal to generate signals.
-
Hardware exception generates signals: divisor is 0, invalid memory reference, etc. These conditions are usually detected by the hardware and notified to the kernel. The kernel then generates the appropriate signal for the process running when the condition occurs.
-
A process can send any signal to another process or process group by calling the kill(2) function. Permission requirements: the owners of the receiving signal process and the sending signal process must be the same, or the owner of the sending signal process must be a super user.
-
Use the kill(1) command at the terminal to send signals to other processes. This command is the interface to the kill function
-
A signal is also generated when it is detected that a software condition has occurred and should be notified to the relevant process. For example, SIGURG (out of band data uploaded from the network connection), SIGPIPE (a process writes to the pipeline after the reading process of the pipeline has been terminated) and SIGALRM (the timer set by the process has timed out).
Signal processing method:
-
Ignore the signal.
-
Capture the signal.
-
Perform the system default action. The default action of the system for most signals is to terminate the process.
SIGKILL and SIGSTOP signals cannot be ignored and captured.
The reason why these two signals cannot be ignored is that they provide the kernel and super users with a reliable way to terminate or stop processes. In addition, if some signals generated by hardware exceptions are ignored (such as illegal memory reference or division by 0), the running behavior of the process is undefined.
For detailed introduction of signals, please refer to the third edition of APUE P252-P256.
signal
#include <signal.h> void (*signal(int signo, void (*func)(int)))(int); // The previous signal handler is returned successfully, and SIG is returned in case of error_ ERR // Function prototypes can be simplified with typedef typedef void (*Sigfunc)(int); Sigfunc* signal(int, Sigfunc*);
-
The signo parameter is the signal name.
-
The value of func is a constant SIG_IGN, constant sig_ Address of DFL or signal processing function.
- If sig is specified_ IGN, it indicates to the kernel that this signal is ignored.
- If sig is specified_ DFL indicates that the action after receiving this signal is the default action of the system.
- When the function address is specified, the function is called when the signal occurs. We call this processing as capturing the signal, and call this function as signal handler or signal capturing function.
A simple example:
#include "apue.h"
static void sig_usr(int);
int main() {
if (signal(SIGUSR1, sig_usr) == SIG_ERR) {
err_sys("can't catch SIGUSR1");
}
if (signal(SIGUSR2, sig_usr) == SIG_ERR) {
err_sys("can't catch SIGUSR2");
}
for (;;) {
pause();
}
}
static void sig_usr(int signo) {
if (signo == SIGUSR1) {
printf("received SIGUSR1\n");
} else if (signo == SIGUSR2) {
printf("received SIGUSR2\n");
} else {
err_dump("received signal %d\n", signo);
}
}
Interrupted system call
A feature of early UNIX systems is that if a process catches a signal during blocking while executing a low-speed system call, the system call is interrupted and will not continue. The system call returned an error with errno set to EINTR.
System calls fall into two categories: low-speed system calls and other system calls. Low speed system call is a kind of system call that may block the process forever.
In order to help applications avoid having to deal with interrupted system calls, 4.2BSD introduces automatic restart of some interrupted system calls.
System calls for automatic restart include ioctl, read, readv, write, writev, wait and waitpid.
The first five functions will only be interrupted by the signal when operating the low-speed equipment. The wait and waitpid are always interrupted when they catch the signal.
Reentrant function
SUS describes the functions that ensure call safety in the signal processing program. These functions are reentrant and are called asynchronous signal safe.
Non reentrant possibilities:
- They are known to use static data structures;
- They call malloc or free;
- They are standard I/O functions.
SIGCLD semantics
In linux, SIGCLD is the same as SIGCLD.
Early treatment of SIGCLD:
-
If the process explicitly sets the configuration of the signal to SIG_ IGN, the child process of the calling process will not produce a dead process. This is different from its default action (SIG_DFL) "ignore" (see Figure 10-1). When a child process terminates, its state is discarded. If the calling process then calls a wait function, it will block until all the child processes are terminated, then the wait will return to 1 and set its errno to ECHILD. (the default configuration of this signal is ignored, but this will not make the above semantics work. Its configuration must be explicitly specified as SIG_IGN.)
-
If the configuration of SIGCLD is set to capture, the kernel immediately checks whether any child processes are ready to wait, and if so, calls the SIGCLD handler.
Terms and semantics of reliable signals
- When the event causing the signal occurs, generate a signal for a process (or send a signal to a process).
- When a signal is generated, the kernel usually sets a flag in some form in the process table.
- When this action is taken on a signal, we say a signal is delivered to the process.
- In the time interval between signal generation and delivery, the signal is said to be pending.
kill and raise
The kill function sends a signal to a process or process group, and the raise function allows the process to send a signal to itself.
#include <signal.h> int kill(pid_t pid, int signo); int raise(int signo); // 0 is returned for success and - 1 for error
Calling raise(signo) is equivalent to calling kill (getpid()), Signo
The pid parameters of kill have four different conditions:
-
pid > 0: send the signal to the process with process ID pid.
-
pid == 0: send the signal to all processes that belong to the same process group as the sending process and the sending process has sending permission.
-
pid < 0: send the signal to all processes whose process group ID is equal to the absolute value of pid and whose sending process has sending permission.
-
pid = = − 1: send signals to all processes that have permission to send signals to them.
The term "all processes" here does not include the system process set defined by the implementation. For most UNIX systems, the system process set includes kernel processes and init (pid 1).
POSIX.1 defines the signal number 0 as an empty signal. If the signo parameter is 0, kill still performs normal error checking, but does not send a signal. This is often used to determine whether a particular process still exists. If a null signal is sent to a non-existent process, kill returns − 1 and errno is set to ESRCH.
alarm and pause
The alarm function is used to set a timer. At some time in the future, the timer will timeout and generate SIGALRM signal. If the signal is ignored or not captured, the default action is to terminate the process calling the alarm function.
#include <unistd.h> unsigned int alarm(unsigned int seconds); // Returns 0 or the remaining alarm time
The value of the parameter seconds is the number of clock seconds required to generate the signal SIGALRM. When this time arrives, the signal is generated by the kernel. Due to the delay of process scheduling, it takes a time interval for the process to be controlled so that it can process the signal.
Call alarm(0) to cancel the last alarm time and take the remaining time as the return value.
The pause function suspends the calling process until a signal is caught.
#include <unistd.h> int pause(void); // Return - 1 and set errno to EINTR
Signal set
POSIX.1 define the data type sigset_t to contain a signal set, and five functions for processing signal sets are defined.
#include <signal.h> int sigemptyset(sigset_t* set); int sigfillset(sigset_t* set); int sigaddset(sigset_t* set, int signo); int sigdelset(sigset_t* set, int signo); // 0 is returned for success and - 1 for error int sigismember(const sigset_t* set, int signo); // The signal returns 1 in the signal set, otherwise it returns 0
-
sigemptyset initializes the signal set pointed by set and clears all signals in it.
-
sigfillset initializes the signal set pointed by set to include all signals.
-
sigaddset adds a signal to an existing signal set
-
sigdelset deletes a signal from the signal set.
sigprocmask
The signal mask word of a process specifies the set of signals that are currently blocked and cannot be delivered to the process. Calling the function sigprocmask can detect or change, or detect and change the signal mask word of the process at the same time.
#include <signal.h> int sigprocmask(int how, const sigset_t* restrict set, sigset_t* restrict oset); // 0 is returned for success and - 1 for error
-
If oset is a non null pointer, the current signal mask word of the process is returned through oset.
-
If set is a non null pointer, the parameter how indicates how to modify the current signal mask word.

-
If set is a null pointer, the signal mask word of the process is not changed, and the value of how is meaningless.
After calling sigprocmask, if there are any pending signals that are no longer blocked, at least one of them will be delivered to the process before sigprocmask returns.
A simple example:
#include "apue.h"
#include <errno.h>
void pr_mask(const char* str) { // print the signals
sigset_t sigset;
int errno_save;
errno_save = errno;
if (sigprocmask(0, NULL, &sigset) < 0) {
err_ret("sigprocmask errno");
} else {
printf("%s", str);
if (sigismember(&sigset, SIGINT)) {
printf(" SIGINT");
}
if (sigismember(&sigset, SIGQUIT)) {
printf(" SIGQUIT");
}
if (sigismember(&sigset, SIGUSR1)) {
printf(" SIGUSR1");
}
if (sigismember(&sigset, SIGALRM)) {
printf(" SIGALRM");
}
printf("\n");
}
errno = errno_save;
}
sigpending
The sigpending function returns a set of signals. For the calling process, each signal is blocked and cannot be delivered, so it must be currently pending.
#include <signal.h> int sigpending(sigset_t* set); // 0 is returned for success and - 1 for error
A sample program:
#include "apue.h"
static void sig_quit(int);
int main() {
sigset_t newmask, oldmask, pendmask;
if (signal(SIGQUIT, sig_quit) == SIG_ERR) {
err_sys("can't catch SIGQUIT");
}
sigemptyset(&newmask);
sigaddset(&newmask, SIGQUIT);
if (sigprocmask(SIG_BLOCK, &newmask, &oldmask) < 0) {
err_sys("SIG_BLOCK error");
}
sleep(5);
if (sigpending(&pendmask) < 0) {
err_sys("sigpending error");
}
if (sigismember(&pendmask, SIGQUIT)) {
printf("\nSIGQUIT pending\n");
}
if (sigprocmask(SIG_SETMASK, &oldmask, NULL) < 0) {
err_sys("SIG_SETMASK error");
}
printf("SIGQUIT unblocked\n");
sleep(5);
exit(0);
}
static void sig_quit(int signo) {
printf("caught SIGQUIT\n");
if (signal(SIGQUIT, SIG_DFL) == SIG_ERR) {
err_sys("can't reset SIGQUIT");
}
}
sigaction
The sigaction function is used to check or modify the processing action associated with the specified signal.
#include <signal.h> int sigaction(int signo, const struct sigaction* restrict act, struct sigaction* oact); // 0 is returned for success and - 1 for error
- signo is the signal number to detect or modify its specific action.
- If the act pointer is not null, modify its action.
- If the oact pointer is not empty, the previous action of the signal is returned through the oact pointer.
The structure of struct sigaction is as follows:
struct sigaction {
void (*sa_handler)(int); // Signal handler address or SIG_IGN or SIG_DEL
sigset_t sa_mask; // Additional blocking signal
int sa_flags; // signal options
void (*sa_sigaction)(int, siginfo_t*, void*); // Alternative signal handler
};
If SA_ The handler field contains the address of a signal capture function (not a constant SIG_IGN or SIG_DFL), then SA_ The mask field describes a signal set that will be added to the signal mask word of the process before calling the signal capture function. Restore the signal mask word of the process to its original value only when it returns from the signal capture function.
sa_ The flags field specifies the options for processing the signal.
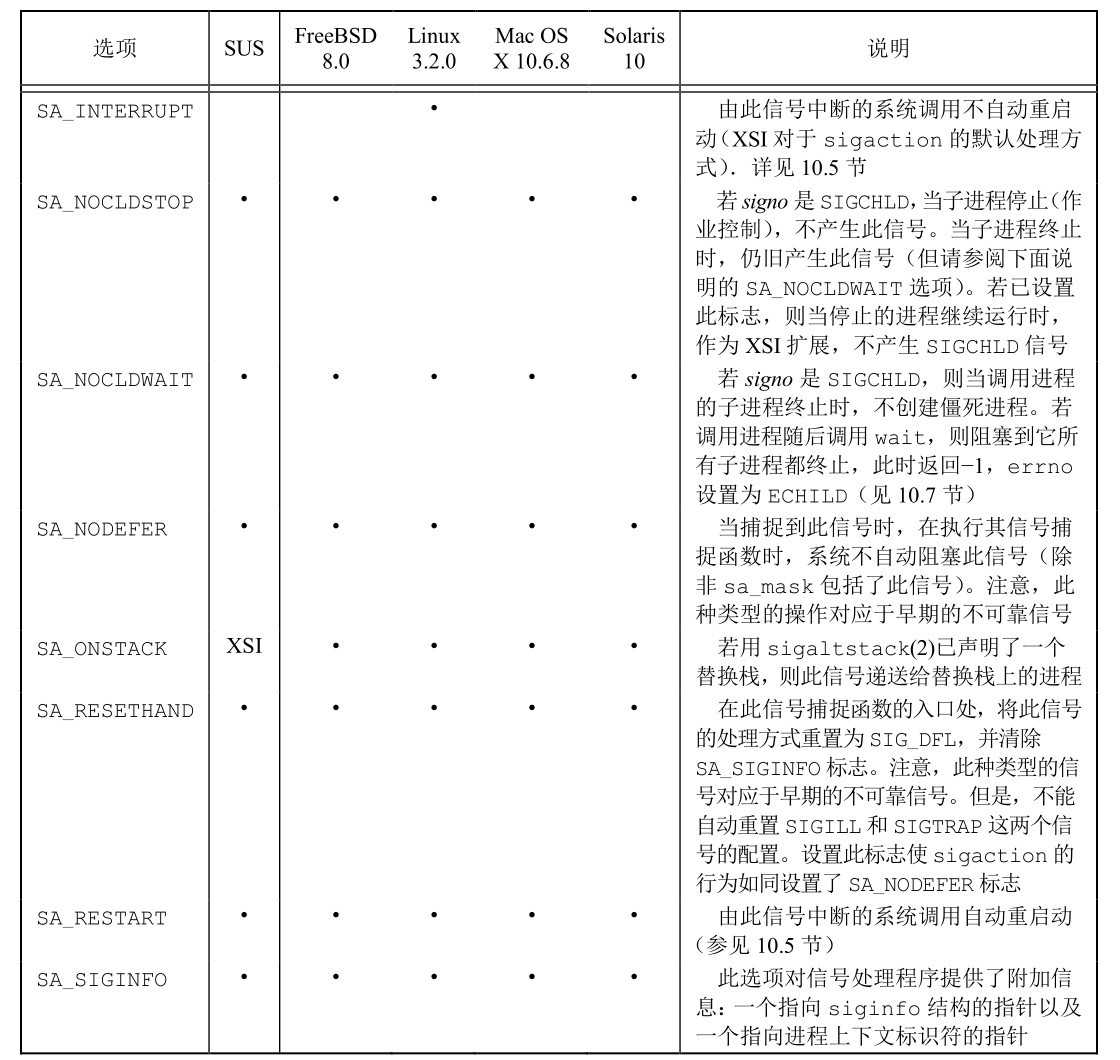
sa_ The sigaction field is an alternative signal handler that uses SA in the sigaction structure_ This signal handler is used when siginfo flag is used. For sa_sigaction field and SA_ The implementation of handler field may use the same storage area, so the application can only use one of these two fields at a time.
The siginfo structure contains information about the cause of the signal. The general style of the structure is shown below.
struct siginfo {
int si_signo; /* signal number */
int si_errno; /* if nonzero, errno value from <errno.h> */
int si_code; /* additional info (depends on signal) */
pid_t si_pid; /* sending process ID */
uid_t si_uid; /* sending process real user ID */
void* si_addr; /* address that caused the fault */
int si_status; /* exit value or signal number */
union sigval si_value; /* application-specific value */
/* possibly other fields also */
};
sigsetjmp and siglongjmp
You can use sigsetjmp and siglongjmp to make nonlocal transfers in signal handlers:
#include <setjmp.h> int sigsetjmp(segjmp_buf env, int savemask); // The direct call returns 0, and the non-0 is returned from the signongjmp call void siglongjmp(sigjmp_buf env, int val);
-
When calling sigsetjmp, if savemask is not 0, sigsetjmp saves the current signal mask word of the process in env.
-
When calling siglongjmp, if the env has been saved in the sigsetjmp call with non-0savemask, siglongjmp will recover the saved signal mask word from it.
sigsuspend
Using sigsuspend, you can restore the signal mask word in an atomic operation, and then put the process to sleep
#include <signal.h> int sigsuspend(const sigset_t* sigmask); // Return - 1 and set errno to EINTR
The signal mask word of the process is set to the value pointed to by sigmask. The process is suspended until a signal is caught or a signal occurs that will terminate the process. If a signal is captured and returned from the signal handler, sigsuspend returns and the signal mask word of the process is set to the value before calling sigsuspend.
A sample program:
#include "apue.h"
volatile sig_atomic_t quitflag;
static void sig_int(int signo) {
if (signo == SIGINT) {
printf("\ninterrupt\n");
} else if (signo == SIGQUIT) {
quitflag = 1;
}
}
int main() {
sigset_t newmask, oldmask, zeromask;
if (signal(SIGINT, sig_int) == SIG_ERR) {
err_sys("signal(SIGINT) error");
}
if (signal(SIGQUIT, sig_int) == SIG_ERR) {
err_sys("signal(SIGQUIT) error");
}
sigemptyset(&zeromask);
sigemptyset(&newmask);
sigaddset(&newmask, SIGQUIT);
if (sigprocmask(SIG_BLOCK, &newmask, &oldmask) < 0) {
err_sys("SIG_BLOCK error");
}
while (quitflag == 0) {
sigsuspend(&zeromask);
}
quitflag = 0;
printf("hello, world!");
if (sigprocmask(SIG_BLOCK, &oldmask, NULL) < 0) {
err_sys("SIG_SETMASK error");
}
exit(0);
}
abort
You can use the abort function to terminate the program abnormally:
#include <stdlib.h> void abort(void);
This function sends a SIGABRT signal to the calling process (the process should not ignore this signal).
ISO C stipulates that calling abort will deliver a notification of unsuccessful termination to the host environment by calling the raise(SIGABRT) function. ISO C requires that if this signal is captured and the corresponding signal handler returns, abort will not return to its caller.
system
A simple example program:
#include "apue.h"
static void sig_int(int signo) {
printf("caught SIGINT\n");
}
static void sig_chld(int signo) {
printf("caught SIGCHLD\n");
}
int main() {
if (signal(SIGINT, sig_int) == SIG_ERR) {
err_sys("signal(SIGINT) error");
}
if (signal(SIGCHLD, sig_chld) == SIG_ERR) {
err_sys("signal(SIGCHLD) error");
}
if (system("/bin/ed") < 0) {
err_sys("system() error");
}
exit(0);
}
In this way, specific signals can be captured during the use of ed editor (SIGINT and sigchld in this case).
The system function is an implementation of signal processing:
#include <sys/wait.h>
#include <errno.h>
#include <signal.h>
#include <unistd.h>
int system(const char* cmdstring) {
pid_t pid;
int status;
struct sigaction ignore, saveintr, savequit;
sigset_t chldmask, savemask;
if (cmdstring == NULL) {
return 1;
}
ignore.sa_handler = SIG_IGN; // ignore SIGINT and SIGQUIT
sigemptyset(&ignore.sa_mask);
ignore.sa_flags = 0;
if (sigaction(SIGINT, &ignore, &saveintr) < 0) {
return -1;
}
if (sigaction(SIGQUIT, &ignore, &savequit) < 0) {
return -1;
}
sigemptyset(&chldmask);
sigaddset(&chldmask, SIGCHLD); // now block SIGCHLD
if ((pid = fork()) < 0) {
return -1;
} else if (pid == 0) {
sigaction(SIGINT, &saveintr, NULL);
sigaction(SIGQUIT, &savequit, NULL);
sigprocmask(SIG_SETMASK, &savemask, NULL);
execl("/bin/sh", "sh", "-c", cmdstring, (char*)0);
_exit(127);
} else {
while (waitpid(pid, &status, 0) < 0) {
if (errno != EINTR) {
status = -1;
break;
}
}
}
if (sigaction(SIGINT, &saveintr, NULL) < 0) {
return -1;
}
if (sigaction(SIGQUIT, &savequit, NULL) < 0) {
return -1;
}
if (sigprocmask(SIG_SETMASK, &savemask, NULL) < 0) {
return -1;
}
return status;
}
sleep, nanosleep, clock_nanosleep
#include <unistd.h> unsigned int sleep(unsigned int seconds); // Returns 0 or the number of seconds that haven't finished hibernating #include <time.h> int nanosleep(const struct timespec* reqtp, struct timespec* remtp); // If it sleeps for a specified time, it returns 0, and if there is an error, it returns - 1 int clock_nanoslepp(clockid_t clock_id, int flags, const struct timespec* reqtp, struct timespec* remtp); // If it sleeps for a specified time, it returns 0 and an error code is returned
The sleep function suspends the calling process until one of the following two conditions is met:
-
The wall clock time specified by seconds has passed.
-
The calling process captures a signal and returns from the signal handler.
The nanosleep function is similar to the sleep function, but provides nanosecond accuracy.
The reqtp parameter specifies the length of time to sleep in seconds and nanoseconds. If a signal interrupts the sleep interval and the process does not terminate, the timespec structure pointed to by the remtp parameter will be set to the length of time that the sleep has not been completed. If you are not interested in the time of not sleeping, you can set this parameter to NULL.
sigqueue
The following operations must be done when using queued signals:
-
Specify SA when installing a signal handler using the sigaction function_ Siginfo logo.
-
SA in sigaction structure_ A signal handler is provided in the sigaction member.
-
Use the sigqueue function to send a signal.
#include <signal.h> int sigqueue(pid_t pid, int signo, const union sigval value); // Return value: 0 if successful; If there is an error, return − 1
The sigqueue function can only send signals to a single process. You can use the value parameter to pass integer and pointer values to the signal handler. In addition, the sigqueue function is similar to the kill function.
Operation control signal
6 operation control signals:
-
SIGCHLD child process stopped or terminated.
-
SIGCONT if the process has stopped, let it continue to run.
-
SIGSTOP signal (cannot be captured or ignored).
-
SIGTSTP interactive stop signal.
-
SIGTTIN background process group member read control terminal.
-
SIGTTOU background process group member write control terminal.
When any one of the four stop signals (SIGTSTP, SIGSTOP, SIGTTIN or SIGTTOU) is generated for a process, any pending SIGCONT signal for the process is discarded.
Similarly, when a SIGCONT signal is generated for a process, any pending stop signal for the same process is discarded.
If the process is stopped, the default action of SIGCONT is to continue the process; Otherwise, ignore this signal.
When a SIGCONT signal is generated for a stopped process, the process continues, even if the signal is blocked or ignored.
Signal name and number
Use the psignal function to portably print the string corresponding to the signal number.
#include <signal.h> void psignal(int signo, const char *msg);
The string msg (usually the program name) is output to the standard error file, followed by a colon and a space, followed by a description of the signal, and finally a newline character. If msg is NULL, only the signal description part is output to the standard error file.
If there is siginfo structure in sigaction signal handler, you can use psiginfo function to print signal information:
#include <signal.h> void psiginfo(const siginfo_t *info, const char *msg);
You can use the strsignal function to obtain the character description part of the signal:
#include <string.h> char *strsignal(int signo); // Return value: pointer to the string describing the signal
Solaris provides a pair of functions. One function maps a signal number to a signal name, and the other vice versa.
#include <signal.h> int sig2str(int signo, char *str); int str2sig(const char *str, int *signop); // 0 is returned for success and − 1 is returned for error
thread
Thread concept
Each thread contains the necessary information to represent the execution environment, including the thread ID identifying the thread in the process, a set of register values, stack, scheduling priority and policy, signal mask word, errno variable and thread private data.
All information of a process is shared by all threads of the process, including the code of the executable program, the global memory and heap memory of the program, the stack and the file descriptor.
Thread ID
Just as each process has a process ID, each thread also has a thread ID. The process ID is unique in the whole system, but the thread ID is different. The thread ID is meaningful only in the process context it belongs to.
With pthread_t type to represent thread ID. for portability, pthread is required_ The equal function to compare two thread IDS:
#include <pthread.h> int pthread_equal(pthread_t tid1, pthread_t tid2); // Equal returns a non-zero value, and unequal returns 0
Pthread can be called_ Self function to obtain its own thread ID:
#include <pthread.h> pthread_t pthread_self(void); // Returns the thread ID of the calling thread
Thread creation
You can use pthread_create to create a new thread:
#include <pthread.h> int pthread_create(pthread_t* restrict tidp, const pthread_attr_t* restrict attr, void* (*start_rtn)(void*), void* restrict arg); // 0 is returned for success and error number is returned for error
When it returns successfully, the memory area pointed to by tidp stores the ID of the new thread.
The attr parameter is used to customize various thread attributes. You can pass NULL to set it as the default attribute.
The newly created thread starts from start_ The address of the RTN function starts running, and the function has only one typeless pointer parameter arg. If you need to start_ If the RTN function passes more than one parameter, you need to put these parameters into a structure, and then pass the address of this structure as Arg parameter.
Thread termination
If any thread in the process calls exit_ Exit or_ Exit, then the whole process will terminate.
Similarly, if the default action is to terminate the process, the signal sent to the thread will terminate the whole process.
A thread can exit in three ways, and its control flow can be stopped without terminating the whole process:
-
Simply return from the startup routine. The return value is the exit code of the thread.
-
Canceled by another thread in the same process.
-
Call pthread_exit.
#include <pthread.h> void pthread_exit(void* rval_ptr);
rval_ The value of PTR will be used as the return value of the thread (note that it is not the data pointed to by rval_ptr, but rval_ptr itself).
You can use pthread_join to get the return value of the thread:
#include <pthread.h> int pthread_join(pthread_t thread, void** rval_ptr); // 0 is returned for success and error number is returned for error
The calling thread will block until the specified thread calls pthread_exit, return from the startup routine, or cancel.
- If a thread simply returns from its startup routine, rval_ptr points to the return value.
- If the thread is canceled, rval_ The memory unit specified by PTR is set to PTHREAD_CANCELED.
pthread_join automatically puts threads in a detached state. If the thread is already in a detached state, pthread_ The join call will fail and return EINVAL.
If you are not interested in the return value of the thread, you can put rval_ptr is set to NULL.
A simple example:
#include "apue.h"
#include <pthread.h>
void* thr_fn1(void* arg) {
printf("thread 1 returning\n");
return ((void*)1);
}
void* thr_fn2(void* arg) {
printf("thread 2 returning\n");
pthread_exit((void*)2);
}
int main() {
int err;
pthread_t tid1, tid2;
void* tret;
err = pthread_create(&tid1, NULL, thr_fn1, NULL);
if (err != 0) {
err_exit(err, "can't create thread 1");
}
err = pthread_create(&tid2, NULL, thr_fn2, NULL);
if (err != 0) {
err_exit(err, "can't create thread 2");
}
err = pthread_join(tid1, &tret);
if (err != 0) {
err_exit(err, "can't join with thread 1");
}
printf("thread 1 exit code %ld\n", (long)tret);
err = pthread_join(tid2, &tret);
if (err != 0) {
err_exit(err, "can't join with thread 2");
}
printf("thread 2 exit code %ld\n", (long)tret);
exit(0);
}
Threads can call pthread_cancel function to request the cancellation of other threads in the same process.
#include <pthread.h> int pthread_cancel(pthread_t tid); // 0 is returned for success and error number is returned for error
By default, pthread_ The cancel function causes the thread identified by tid to behave as if calling thread_exit(PTHREAD_CANCELED). Threads can choose to ignore cancel or control how it is cancelled.
Threads can use pthread_cleanup_push and pthread_cleanup_pop to register the thread cleaning handler (similar to atexit function, multiple can be established, and the calling order is opposite to the registration order):
#include <pthread.h> void pthread_cleanup_push(void (*rtn)(void*), void* arg); void pthread_cleanup_pop(int execute);
These thread cleanup handlers are triggered only when:
-
Call pthread_exit;
-
When responding to cancellation request;
-
Pthread is called with a non-zero execute parameter_ cleanup_ Pop.
If the execute parameter is set to 0, the cleanup function will not be called.
pthread_cleanup_pop(0) is used for and pthread_cleanup_push matching.
In linux, these two functions are implemented with macros. If it is not matched, the compilation cannot pass.
A usage example:
#include "apue.h"
#include <pthread.h>
void cleanup(void *arg) {
printf("cleanup: %s\n", (char *) arg);
}
void *thr_fn1(void *arg) {
printf("thread 1 start\n");
pthread_cleanup_push(cleanup, "thread 1 first handler") ;
pthread_cleanup_push(cleanup, "thread 1 second handler") ;
printf("thread 1 push complete\n");
if (arg)
return ((void *) 1);
pthread_cleanup_pop(0);
pthread_cleanup_pop(0);
return ((void *) 1);
}
void *thr_fn2(void *arg) {
printf("thread 2 start\n");
pthread_cleanup_push(cleanup, "thread 2 first handler") ;
pthread_cleanup_push(cleanup, "thread 2 second handler") ;
printf("thread 2 push complete\n");
if (arg)
pthread_exit((void *) 2);
pthread_cleanup_pop(0);
pthread_cleanup_pop(0);
pthread_exit((void *) 2);
}
int main() {
int err;
pthread_t tid1, tid2;
void *tret;
err = pthread_create(&tid1, NULL, thr_fn1, (void*)1);
if (err != 0) {
err_exit(err, "can't create thread 1");
}
err = pthread_create(&tid2, NULL, thr_fn2, (void*)1);
if (err != 0) {
err_exit(err, "can't create thread 2");
}
err = pthread_join(tid1, &tret);
if (err != 0) {
err_exit(err, "can't join with thread 1");
}
printf("thread 1 exit code %ld\n", (long)tret);
err = pthread_join(tid2, &tret);
if (err != 0) {
err_exit(err, "can't join with thread 2");
}
printf("thread 2 exit code %ld\n", (long)tret);
exit(0);
}
Output results (the results of each run may be different):
thread 1 start thread 1 push complete thread 2 start thread 2 push complete thread 1 exit code 1 cleanup: thread 2 second handler cleanup: thread 2 first handler thread 2 exit code 2
Thread synchronization
mutex
Pthread for mutually exclusive variables_ mutex_ T type representation.
Before using a mutex variable, you need to initialize it and set it to a constant PTHREAD_MUTEX_INITIALIZER or call pthread_mutex_init function to initialize.
If the mutex is allocated dynamically, pthread needs to be called before releasing memory_ mutex_ destroy.
Call pthread_mutex_lock to lock the mutex. If the mutex is locked, the calling thread will block until the mutex is unlocked. Call pthread_mutex_unlock unlocks the mutex.
If the thread does not want to be blocked, you can use pthread_mutex_trylock tried to lock the mutex.
- If pthread is called_ mutex_ When the mutex is unlocked during trylock, pthread_mutex_trylock will lock the mutex and return 0 without blocking,
- Otherwise pthread_mutex_trylock will fail, cannot lock the mutex, and returns EBUSY.
#include <pthread.h> int pthread_mutex_init(pthread_mutex_t* restrict mutex, const pthread_mutexattr_t* restrict attr); // Initialize with default configuration when attr is NULL int pthread_mutex_destroy(pthread_mutex_t* mutex); int pthread_mutex_lock(pthread_mutex_t* mutex); int pthread_mutex_unlock(pthread_mutex_t* mutex); int pthread_mutex_trylock(pthread_mutex_t* mutex); // 0 is returned for success and error number is returned for error
When a thread attempts to acquire a locked mutex, pthread_mutex_timedlock mutex primitive allows binding thread blocking time. pthread_mutex_timedlock function and pthread_mutex_lock is basically equivalent, but when the timeout value is reached, pthread_mutex_timedlock does not lock the mutex, but returns the error code ETIMEDOUT.
#include <pthread.h> #include <time.h> int pthread_mutex_timedlock(pthread_mutex_t* restrict mutex, const struct timespec* restrict tsptr); // 0 is returned for success and error number is returned for error
A usage example:
#include "apue.h"
#include <pthread.h>
int main() {
int err;
struct timespec tout;
struct tm* tmp;
char buf[64];
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&lock);
printf("mutex is locked\n");
clock_gettime(CLOCK_REALTIME, &tout);
tmp = localtime(&tout.tv_sec);
strftime(buf, sizeof(buf), "%r", tmp);
printf("current time is %s\n", buf);
tout.tv_sec += 10;
/* this could lead to deadlock */
err = pthread_mutex_timedlock(&lock, &tout);
clock_gettime(CLOCK_REALTIME, &tout);
tmp = localtime(&tout.tv_sec);
strftime(buf, sizeof(buf), "%r", tmp);
printf("current time is %s\n", buf);
if (err == 0) {
printf("mutex locked again\n");
} else {
printf("can't lock mutex again: %s\n", strerror(err));
}
exit(0);
}
Read write lock
There are three states of read-write lock: lock state in read mode, lock state in write mode and no lock state. Only one thread can occupy the read-write lock of write mode at a time, but multiple threads can occupy the read-write lock of read mode at the same time.
When the read-write lock is in the write lock state, all threads trying to lock the lock will be blocked before the lock is unlocked. When the read-write lock is in the read lock state, all threads trying to lock it in read mode can get access, but any thread that wants to lock it in write mode will block until all threads release their read locks. When the read-write lock is locked in read mode, and a thread attempts to obtain the lock in write mode, the read-write lock will usually block the subsequent read-write lock request.
In short, this is a write first read-write lock.
Read / write locks are also called shared exclusive locks. When the read-write lock is locked in the read mode, it can be said to be locked in the shared mode. When it is locked in write mode, it can be said to be locked in mutually exclusive mode.
Compared with mutexes, read-write locks must be initialized before use (use PTHREAD_RWLOCK_INITIALIZER or call pthread_rwlock_init function), and must be destroyed before releasing their underlying memory (call pthread_rwlock_destroy function).
To lock the read-write lock in read mode, you need to call pthread_rwlock_rdlock. To lock the read-write lock in write mode, you need to call pthread_rwlock_wrlock. Pthread can be called no matter how the read-write lock is locked_ rwlock_ Unlock to unlock.
SUS also defines the conditional Version (trylock version) of the read-write lock primitive.
#include <pthread.h> int pthread_rwlock_init(pthread_rwlock_t* restrict rwlock, const pthread_rwlockattr_t* restrict attr); int pthread_rwlock_destroy(pthread_rwlock_t* rwlock); int pthread_rwlock_rdlock(pthread_rwlock_t* rwlock); int pthread_rwlock_wrlock(pthread_rwlock_t* rwlock); int pthread_rwlock_unlock(pthread_rwlock_t* rwlock); int pthread_rwlock_tryrdlock(pthread_rwlock_t* rwlock); int pthread_rwlock_trywrlock(pthread_rwlock_t* rwlock); // 0 is returned for success and error number is returned for error
A usage example:
#include <stdlib.h>
#include <pthread.h>
struct job {
struct job* j_next;
struct job* j_prev;
pthread_t j_id;
// more stuff here
};
struct queue {
struct job* q_head;
struct job* q_tail;
pthread_rwlock_t q_lock;
};
int queue_init(struct queue* qp) {
int err;
qp->q_head = NULL;
qp->q_tail = NULL;
err = pthread_rwlock_init(&qp->q_lock, NULL);
if (err != 0) {
return err;
}
return 0;
}
void job_insert(struct queue* qp, struct job* jp) {
pthread_rwlock_wrlock(&qp->q_lock);
jp->j_next = qp->q_head;
jp->j_prev = NULL;
if (qp->q_head != NULL) {
qp->q_head->j_prev = jp;
} else {
qp->q_tail = jp;
}
qp->q_head = jp;
pthread_rwlock_unlock(&qp->q_lock);
}
void job_append(struct queue* qp, struct job* jp) {
pthread_rwlock_wrlock(&qp->q_lock);
jp->j_next = NULL;
jp->j_prev = qp->q_tail;
if (qp->q_tail != NULL) {
qp->q_tail->j_next = jp;
} else {
qp->q_head = jp;
}
qp->q_tail = jp;
pthread_rwlock_unlock(&qp->q_lock);
}
void job_remove(struct queue* qp, struct job* jp) {
pthread_rwlock_wrlock(&qp->q_lock);
if (jp == qp->q_head) {
qp->q_head = jp->j_next;
if (qp->q_tail == jp) {
qp->q_tail = NULL;
} else {
jp->j_next->j_prev = jp->j_prev;
}
} else if (jp == qp->q_tail) {
qp->q_tail = jp->j_prev;
jp->j_prev->j_next = jp->j_next;
} else {
jp->j_prev->j_next = jp->j_next;
jp->j_next->j_prev = jp->j_prev;
}
pthread_rwlock_unlock(&qp->q_lock);
}
struct job* job_find(struct queue* qp, pthread_t id) {
struct job* jp;
if (pthread_rwlock_rdlock(&qp->q_lock) != 0) {
return NULL;
}
for (jp = qp->q_head; jp != NULL; jp = jp->j_next) {
if (pthread_equal(jp->j_id, id)) {
break;
}
}
pthread_rwlock_unlock(&qp->q_lock);
return jp;
}
SUS also provides a locking function with timeout for read-write locks:
#include <pthread.h> #include <time.h> int pthread_rwlock_timedrdlock(pthread_rwlock_t* restrict rwlock, const struct timespec* restrict tsptr); int pthread_rwlock_timedwlock(pthread_rwlock_t* restrict rwlock, const struct timespec* restrict tsptr); // 0 is returned for success and error number is returned for error
Conditional variable
The initialization and destruction of condition variables are similar to the previous mutexes and read-write locks:
#include <pthread.h> int pthread_cond_init(pthread_cond_t* restrict cond, const pthread_condattr_t* restrict attr); int pthread_cond_destroy(pthread_cond_t* cond); // 0 is returned for success and error number is returned for error
Using pthread_cond_wait to wait for the condition variable to be true:
#include <pthread.h> int pthread_cond_wait(pthread_cond_t* restrict cond, pthread_mutex_t* restrict mutex); int pthread_cond_timedwait(pthread_cond_t* restrict cond, pthread_mutex_t* restrict mutex, const struct timespec* restrict tsptr); // 0 is returned for success and - 1 for error
Pass to pthread_ cond_ The mutex of wait protects the condition. The caller passes the locked mutex to the function, and then the function automatically puts the calling thread on the thread list of waiting conditions to unlock the mutex. This closes the time channel between the condition check and the thread going to sleep waiting for the condition to change, so that the thread will not miss any change in the condition. pthread_ cond_ When wait returns, the mutex is locked again.
There are two functions that can be used to notify a thread that a condition has been met.
#include <pthread.h> int pthread_cond_signal(pthread_cond_t *cond); int pthread_cond_broadcast(pthread_cond_t *cond); // 0 is returned for success and error number is returned for error
pthread_ cond_ The signal function can wake up at least one thread waiting for the condition, and pthread_ cond_ The broadcast function can wake up all threads waiting for the condition.
POSIX specification to simplify pthread_ cond_ The implementation of signal allows it to wake up more than one thread during implementation.
Use example:
#include <pthread.h>
struct msg {
struct msg* m_next;
// more stuff here
};
struct msg* workq;
pthread_cond_t qready = PTHREAD_COND_INITIALIZER;
pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER;
void process_msg() {
struct msg* mp;
for( ; ; ) {
pthread_mutex_lock(&qlock);
while (workq == NULL) {
pthread_cond_wait(&qready, &qlock);
}
mp = workq;
workq = mp->m_next;
pthread_mutex_unlock(&qlock);
/* now process the message up */
}
}
void enqueue_msg(struct msg* mp) {
pthread_mutex_lock(&qlock);
mp->m_next = workq;
workq = mp;
pthread_mutex_unlock(&qlock);
pthread_cond_signal(&qready);
}
Spin lock
#include <pthread.h> int pthread_spin_init(pthread_spinlock_t* lock, int pshared); int pthread_spin_destroy(pthread_spinlock_t* lock); int pthread_spin_lock(pthread_spinlock_t* lock); int pthread_spin_unlock(pthread_spinlock_t* lock); int pthread_spin_trylock(pthread_spinlock_t* lock); // 0 is returned for success and error number is returned for error
The pshared parameter indicates the process sharing attribute:
- If PTHREAD_PROCESS_SHARED, the spin lock can be obtained by threads that can access the underlying memory of the lock, even if those threads belong to different processes.
- If PTHREAD_PROCESS_PRIVATE, the spin lock can only be accessed by the thread inside the process initializing the lock.
Pthread if the spin lock is currently unlocked_ spin_ The lock function can lock it without spinning. If the thread has locked it, the result is undefined. Call pthread_spin_lock returns an EDEADLK error (or other error), or the call may spin permanently. The specific behavior depends on the actual implementation. An attempt to unlock a spin lock without a lock is also undefined.
a barrier
Barrier is a synchronization mechanism for users to coordinate multiple threads to work in parallel. The barrier allows each thread to wait until all cooperating threads reach a certain point, and then continue execution from that point.
#include <pthread.h> int pthread_barrier_init(pthread_barrier_t *restrict barrier, const pthread_barrierattr_t *restrict attr, unsigned int count); int pthread_barrier_destroy(pthread_barrier_t *barrier); // If 0 is returned successfully, the error number will be returned
The count parameter specifies the number of threads that must reach the barrier before allowing all threads to continue running.
The attr parameter specifies the properties of the barrier object (NULL initializes the barrier with the default properties).
You can use pthread_barrier_wait function to indicate that the thread has completed its work and is ready to wait for all other threads to catch up.
#include <pthread.h> int pthread_barrier_wait(pthread_barrier_t *barrier); // Successfully returned 0 or PTHREAD_BARRIER_SERIAL_THREAD, error number returned
Call pthread_ barrier_ The thread of wait will enter sleep state when the barrier count (set when calling pthread_barrier_init) does not meet the conditions. If this thread is the last to call pthread_ barrier_ The wait thread meets the barrier count, and all threads are awakened.
For an arbitrary thread, pthread_ barrier_ The wait function returned PTHREAD_BARRIER_SERIAL_THREAD. The return value seen by the remaining threads is 0. This allows one thread to act as the main thread, and it can work on the work results completed by all other threads.
Once the barrier count is reached and the thread is in a non blocking state, the barrier can be reused. But unless pthread is called_ barrier_ After the destroy function, pthread is called again_ barrier_ The init function initializes the count with another number, otherwise the barrier count will not change.
Use example:
#include "apue.h"
#include <pthread.h>
#include <limits.h>
#include <sys/time.h>
#define NTHR 8 // num of threads
#define NUMNUM 8000000L // num of numbers to sort
#define TNUM (NUMNUM/NTHR) // num per thread
long nums[NUMNUM];
long snums[NUMNUM];
pthread_barrier_t b;
#ifdef SOLARIS
#define heapsort qsort
#else
extern int heapsort(void*, size_t, size_t, int (*)(const void*, const void*));
#endif
int complong(const void* arg1, const void* arg2) {
long l1 = *(long*)arg1;
long l2 = *(long*)arg2;
if (l1 == l2) {
return 0;
} else if (l1 < l2) {
return -1;
} else {
return 1;
}
}
void* thr_fn(void* arg) {
long idx = (long)arg;
heapsort(&nums[idx], TNUM, sizeof(long), complong);
pthread_barrier_wait(&b);
return ((void*)0);
}
void merge() {
long idx[NTHR];
long i, minidx, sidx, num;
for (i = 0; i < NTHR; i++) {
idx[i] = i * TNUM;
}
for (sidx = 0; sidx < NUMNUM; sidx++) {
num = LONG_MAX;
for (i = 0; i < NTHR; i++) {
if ((idx[i] < (i + 1) * TNUM) && (nums[idx[i]] < num)) {
num = nums[idx[i]];
minidx = i;
}
}
snums[sidx] = nums[idx[minidx]];
idx[minidx]++;
}
}
int main() {
unsigned long i;
struct timeval start, end;
long long startusec, endusec;
double elapsed;
int err;
pthread_t tid;
srandom(1);
for (i = 0; i < NUMNUM; i++) {
nums[i] = random();
}
gettimeofday(&start, NULL);
pthread_barrier_init(&b, NULL, NTHR + 1);
for (i = 0; i < NTHR; i++) {
err = pthread_create(&tid, NULL, thr_fn, (void*)(i * TNUM));
if (err != 0) {
err_exit(err, "can't create thread");
}
}
pthread_barrier_wait(&b);
merge();
gettimeofday(&end, NULL);
startusec = start.tv_sec * 1000000 + start.tv_usec;
endusec = end.tv_sec * 1000000 + end.tv_usec;
elapsed = (double)(endusec - startusec) / 1000000.0;
printf("sort took %.4f seconds\n", elapsed);
for (i = 0; i < NUMNUM; i++) {
printf("%ld\n", snums[i]);
}
exit(0);
}
This code cannot run on linux. The heapsort function cannot be found. (you may need to download the header file of bsd)
Thread control
Thread properties
You can use pthread_attr_t type to control pthread_ The create function creates the properties of a new thread:
pthread_ attr_ Initialization and de initialization of type T:
#include <pthread.h> int pthread_attr_init(pthread_attr_t* attr); int pthread_attr_destroy(pthread_attr_t* attr); // 0 is returned for success and error number is returned for error
You can also get and set pthread through the following functions_ attr_ detachstate thread attribute in T structure:
#include <pthread.h> int pthread_attr_getdetachstate(const pthread_attr_t* restrict attr, int* detachstate); int pthread_attr_setdetachstate(pthread_attr_t* attr, int* detachstate); // 0 is returned for success and error number is returned for error
detachstate has two legal values: pthread_ CREATE_ Detached and pthread_ CREATE_ Joinable (normal startup program).
An example:
#include "apue.h"
#include <pthread.h>
int makethread(void* (*fn)(void*), void* arg) {
int err;
pthread_t tid;
pthread_attr_t attr;
err = pthread_attr_init(&attr);
if (err != 0) {
return err;
}
err = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
if (err == 0) {
err = pthread_create(&tid, &attr, fn, arg);
}
pthread_attr_destroy(&attr);
return err;
}
Thread stack properties can be managed through the following functions:
#include <pthread.h> int pthread_attr_getstack(const pthread_attr_t* restrict attr, void** restrict stackaddr, size_t* restrict stacksize); int pthread_attr_setstack(pthread_attr_t* attr, void* stackaddr, size_t stacksize); // 0 is returned for success and error number is returned for error
If the virtual address space of the thread stack is exhausted, you can use malloc or mmap to allocate space for the alternative stack and pthread_attr_setstack function to change the stack position of the new thread.
You can read or set the thread property stacksize through the following functions:
#include <pthread.h> int pthread_attr_getstacksize(const pthread_attr_t* restrict attr, size_t* restrict stacksize); int pthread_attr_setstacksize(pthread_attr_t* attr, size_t stacksize); // 0 is returned for success and error number is returned for error
The thread attribute guardsize controls the size of the extended memory after the end of the thread stack to avoid stack overflow. The default value of this property is defined by the specific implementation, but the common value is the system page size. The guardsize thread property can be set to 0, and this characteristic behavior of the property is not allowed: in this case, the alert buffer will not be provided. Similarly, if the thread attribute stackaddr is modified, the system will think that we will manage the stack ourselves, thus invalidating the stack alert buffer mechanism, which is equivalent to setting the guardsize thread attribute to 0.
#include <pthread.h> iint pthread_attr_getguardsize(const pthread_attr_t* restrict attr, size_t* restrict guardsize); int pthread_attr_setguardsize(pthread_attr_t* attr, size_t guardsize); // 0 is returned for success and error number is returned for error
If the guardsize thread property is modified, the operating system may take it as an integral multiple of the page size. If the stack pointer of the thread overflows into the warning area, the application may receive an error message through the signal.
Synchronization properties
Mutex attribute
Using pthread_mutexaddr_t type to control the mutex attribute:
#include <pthread.h> int pthread_mutexattr_init(pthread_mutexattr_t* attr); int pthread_mutexattr_destroy(pthread_mutexattr_t* attr); // 0 is returned for success and error number is returned for error
Process shared properties of mutex:
#include <pthread.h> int pthread_mutexattr_getpshared(const pthread_mutexattr_t* restrict attr, int* restrict pshared); int pthread_mutexattr_setpshared(pthread_mutexattr_t* attr, int pshared); // 0 is returned for success and error number is returned for error
By default, the process shared mutex property is set to PTHREAD_PROCESS_PRIVATE, multiple threads in the current process can access the same synchronization object.
If the process shared mutex property is set to PTHREAD_PROCESS_SHARED, the mutex allocated from the memory data blocks shared by multiple processes can be used for the synchronization of these processes.
Robust attributes of mutex:
#include <pthread.h> int pthread_mutexattr_getrobust(const pthread_mutexattr_t* restrict attr, int* restrict robust); int pthread_mutexattr_setrobust(pthread_mutexattr_t* attr, int robust); // 0 is returned for success and error number is returned for error
There are two possible cases for robust attribute values:
- The default is PTHREAD_MUTEX_STALLED, which means that no special action is required when the process holding the mutex terminates.
- Another value is PTHREAD_MUTEX_ROBUST. This value will cause the thread to call pthread_mutex_lock obtains the lock, which is held by another process, but it does not unlock the lock when it terminates. At this time, the thread will block and pthread_mutex_lock returns EOWNERDEAD instead of 0. Applications can learn from this special return value that, if possible, they need to recover regardless of the mutex state they protect.
If the application state cannot be restored, the mutex will be permanently unavailable after the thread unlocks it. To avoid this problem, threads can call pthread_ mutex_ The consistent function indicates that the state related to the mutex is consistent before the mutex is unlocked.
#include <pthread.h> int pthread_mutex_consistent(pthread_mutex_t *mutex); // 0 is returned for success and error number is returned for error
If the thread does not call pthread first_ mutex_ Consistent unlocks the mutex, and other blocking threads trying to get the mutex will get the error code ENOTRECOVERABLE. If this happens, the mutex will no longer be available. The thread calls pthread_ in advance. mutex_ Consistent, which can make the mutex work normally, so that it can be used continuously.
Type attribute of mutex:
#include <pthread.h> int pthread_mutexattr_gettype(const pthread_mutexattr_t* restrict attr,int* restrict type); int pthread_mutexattr_settype(pthread_mutexattr_t* attr, int type); // 0 is returned for success and error number is returned for error
Possible values of type parameter:
-
PTHREAD_MUTEX_NORMAL: Standard mutex type, without any special error checking or deadlock detection.
-
PTHREAD_ MUTEX_ Error check: provides error checking.
-
PTHREAD_MUTEX_RECURSIVE this mutex type allows the same thread to lock the mutex multiple times before unlocking it. Recursive mutex maintains the count of locks. When the number of times of unlocking and locking are different, the lock will not be released. Therefore, if a recursive mutex is locked twice and then unlocked once, the mutex will still be locked. The lock cannot be released until it is unlocked again.
-
PTHREAD_MUTEX_DEFAULT: provides default properties and behaviors. The operating system can freely map this type to one of other mutex types when implementing it. For example, Linux 3.2.0 maps this type to a normal mutex type, while FreeBSD 8.0 maps it to an error checking mutex type.
Read / write lock properties
With pthread_rwlockattr_t type controls the properties of read-write locks.
Property initialization and de initialization:
#include <pthread.h> int pthread_rwlockattr_init(pthread_rwlockattr_t* attr); int pthread_rwlockattr_destroy(pthread_rwlockattr_t* attr); // 0 is returned for success and error number is returned for error
The only properties supported by read-write locks are process sharing properties:
#include <pthread.h> int pthread_rwlockattr_getpshared(const pthread_rwlockattr_t* restrict attr, int* restrict pshared); int pthread_rwlockattr_setpshared(pthread_rwlockattr_t* attr, int pshared); // 0 is returned for success and error number is returned for error
Conditional variable properties
Through pthread_condattr_t type controls the properties of condition variables:
Property initialization and de initialization:
#include <pthread.h> int pthread_condattr_init(pthread_condattr_t* attr); int pthread_condattr_destroy(pthread_condattr_t* attr); // 0 is returned for success and error number is returned for error
SUS defines two attributes of conditional variables: process sharing and clock attribute:
#include <pthread.h> int pthread_condattr_getpshared(const pthread_condattr_t* restrict attr, int* restrict pshared); int pthread_condattr_setpshared(pthread_condattr_t* attr, int pshared); int pthread_condattr_getclock(const pthread_condattr_t* restrict attr, clockid_t* restrict clock_id); int pthread_condattr_setclock(pthread_condattr_t* attr, clockid_t* restrict clock_id); // 0 is returned for success and error number is returned for error
Clock attribute control calculation pthread_ cond_ Which clock is used when the timeout parameter (tsptr) of the timedwait function is.
Barrier properties
Through pthread_barrierattr_t type controls the properties of condition variables:
Property initialization and de initialization:
#include <pthread.h> int pthread_barrierattr_init(pthread_barrierattr_t* attr); int pthread_barrierattr_destroy(pthread_barrierattr_t* attr); // 0 is returned for success and error number is returned for error
Currently, the only barrier attribute defined is the process sharing attribute:
#include <pthread.h> int pthread_barrierattr_getpshared(const pthread_barrierattr_t* restrict attr, int* restrict pshared); int pthread_barrierattr_setpshared(pthread_barrierattr_t* attr, int pshared); // 0 is returned for success and error number is returned for error
Reentry
If a function is reentrant for multiple threads, it is said that the function is thread safe. However, this does not mean that the function is also reentrant for the signal processor. If the function is safe for the reentry of asynchronous signal handler, it can be said that the function is asynchronous signal safe.
POSIX.1 provides a thread safe way to manage FILE objects. You can use flowfile and ftrylockfile to obtain the lock associated with a given FILE object. The lock is recursive: when you own the lock, you can still acquire the lock again without causing a deadlock.
All standard I/O routines that operate on FILE objects must behave as if they internally called flowfile and funlockfile.
#include <stdio.h> int ftrylockfile(FILE* fp); // 0 is returned successfully. If the lock cannot be obtained, a non-0 value is returned void flockfile(FILE* fp); void funlockfile(FILE* fp);
In order to avoid the performance degradation of reading and writing a single character caused by lock, there is an unlocked version of character based standard I/O routine:
#include <stdio.h> int getchar_unlocked(void); int getc_unlocked(FILE* fp); // The next character is returned successfully, and EOF is returned when the end of file or error is encountered int putchar_unlocked(int c); int putc_unlocked(int c, FILE* fp); // c is returned for success and EOF is returned for error
Implementation of getenv function in reentrant (thread safe) version:
#include <string.h>
#include <errno.h>
#include <pthread.h>
#include <stdlib.h>
extern char** environ;
pthread_mutex_t env_mutex;
static pthread_once_t init_done = PTHREAD_ONCE_INIT;
static void thread_init() {
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
pthread_mutex_init(&env_mutex, &attr);
pthread_mutexattr_destroy(&attr);
}
int getenv_r(const char* name, char* buf, int buflen) {
int i, len, olen;
pthread_once(&init_done, thread_init);
len = strlen(name);
pthread_mutex_lock(&env_mutex);
for (i = 0; environ[i] != NULL; i++) {
if ((strncmp(name, environ[i], len) == 0) && (environ[i][len] == '=')) {
olen = strlen(&environ[i][len+1]);
if (olen >= buflen) {
pthread_mutex_unlock(&env_mutex);
return ENOSPC;
}
strcpy(buf, &environ[i][len+1]);
pthread_mutex_unlock(&env_mutex);
return 0;
}
}
pthread_mutex_unlock(&env_mutex);
return ENOENT;
}
Thread specific data
Thread specific data, also known as thread private data, is a mechanism for storing and querying thread specific data. Each thread can access its own copy of data without worrying about synchronous access with other threads.
Before allocating thread specific data, you need to create a key associated with that data. This key will be used to obtain access to thread specific data. Using pthread_key_create creates a key.
#include <pthread.h> int pthread_key_create(pthread_key_t* keyp, void (*destructor)(void*)); // 0 is returned for success and error number is returned for error
In addition to creating keys, pthread_key_create can associate an optional destructor for the key. When the thread exits, if the data address has been set to a non null value, the destructor will be called, and its only parameter is the data address.
When a thread calls pthread_exit or thread execution returns. When it exits normally, the destructor will be called. Similarly, when the thread is canceled, the destructor will not be called until the last cleanup handler returns. If the thread calls exit_ exit,_ The destructor will not be called when exit or abort, or other abnormal exits occur.
You can use pthread_key_delete cancels the association between the key and the thread specific data value:
#include <pthread.h> int pthread_key_delete(pthread_key_t key); // 0 is returned for success and error number is returned for error
By using pthread_once to ensure only one initialization:
#include <pthread.h> pthread_once_t initflag = PTHREAD_ONCE_INIT; int pthread_once(pthread_once_t* initflag, void (*initfn)(void)); // 0 is returned for success and error number is returned for error
initflag must be a non local variable (such as global variable or static variable) and must be initialized to PTHREAD_ONCE_INIT.
After the key is created, you can use pthread_ The setspecific function associates a key with a specific data type:
#include <pthread.h> void* pthread_getspecific(pthread_key_t key); // Returns a thread specific data value. If no value is associated with the key, NULL is returned int pthread_setspecific(pthread_key_t key, const void* value); // 0 is returned for success and error number is returned for error
Compatible version of thread safe getenv:
#include <limits.h>
#include <string.h>
#include <pthread.h>
#include <stdlib.h>
#define MAXSTRINGSZ 4096
static pthread_key_t key;
static pthread_once_t init_done = PTHREAD_ONCE_INIT;
pthread_mutex_t env_mutex = PTHREAD_MUTEX_INITIALIZER;
extern char** environ;
static void thread_init() {
pthread_key_create(&key, free);
}
char* getenv(const char* name) {
int i, len;
char* envbuf;
pthread_once(&init_done, thread_init);
pthread_mutex_lock(&env_mutex);
envbuf = (char*) pthread_getspecific(key);
if (envbuf == NULL) {
envbuf = malloc(MAXSTRINGSZ);
if (envbuf == NULL) {
pthread_mutex_unlock(&env_mutex);
return NULL;
}
pthread_setspecific(key, envbuf);
}
len = strlen(name);
for (i = 0; environ[i] != NULL; i++) {
if ((strncmp(name, environ[i], len) == 0) && (environ[i][len] == '=')) {
strncpy(envbuf, &environ[i][len+1], MAXSTRINGSZ - 1);
pthread_mutex_unlock(&env_mutex);
return envbuf;
}
}
pthread_mutex_unlock(&env_mutex);
return NULL;
}
Cancel option
There are two thread attributes that are not included in the pthread_ attr_ In the T structure, they are cancellable States and cancellable types. These two properties affect the thread's response to pthread_ The behavior rendered when the cancel function is called.
The cancellable status attribute can be PTHREAD_CANCEL_ENABLE, or PTHREAD_CANCEL_DISABLE. Threads can call pthread_setcancelstate modifies its cancelable state.
#include <pthread.h> int pthread_setcancelstate(int state, int* oldstate); // Return value: 0 if successful; Otherwise, the error number is returned
By default, the thread continues to run after the cancellation request is issued until the thread reaches a cancellation point. The cancellation point is a place where the thread checks whether it has been cancelled. If it has been cancelled, it will act according to the request.
Refer to P362-363 of the third edition of APUE for some functions that may cause the request point to appear.
The default cancellable state when a thread starts is PTHREAD_CANCEL_ENABLE. When the status is set to pthread_cancel_ When disable, pthread_ The call to cancel does not kill the thread. On the contrary, the cancellation request is still in the suspended state for this thread. When the cancellation state changes to pthread again_ CANCEL_ When enable, the thread will process all pending cancellation requests at the next cancellation point.
You can use pthread_ Add your own cancellation point with the testanchor function:
#include <pthread.h> void pthread_testcancle(void);
Call pthread_ When testing cancel, if a cancellation request is pending and the cancellation is not invalidated, the thread will be cancelled. However, if the cancellation is set to invalid, pthread_ The testancel call has no effect.
The default cancellation type is pthreadcancel_deferred. Call pthread_ After canceling, there will be no real cancellation before the thread reaches the cancellation point.
You can also set the cancellation type to asynchronous cancellation (PTHREAD_CANCEL_ASYNCHRONOUS). When using asynchronous cancellation, a thread can be undone at any time, rather than having to encounter a cancellation point to be cancelled.
You can call pthread_setcanceltype to modify the cancellation type.
#include <pthread.h> int pthread_setcanceltype(int type, int* oldtype); // 0 is returned for success and error number is returned for error
Threads and signals
Each thread has its own signal mask word, but the signal processing is shared by all threads in the process.
The behavior of sigprocmask is not defined in multithreaded processes, and threads must use pthread_sigmask to set the signal mask word:
#include <signal.h> int pthread_sigmask(int how, const sigset_t* restrict set, sigset_t* restrict oset); // 0 is returned for success and error number is returned for error
Threads can wait for one or more signals by calling sigwait (personal feeling is very similar to sigsuspend):
#include <signal.h> int sigwait(const sigset_t *restrict set, int *restrict signop); // 0 is returned for success and error number is returned for error
To send the signal to the process, you can call kill. To send a signal to a thread, you can call pthread_kill.
#include <signal.h> int pthread_kill(pthread_t thread, int signo); // 0 is returned for success and error number is returned for error
A sample program:
#include "apue.h"
#include <pthread.h>
int quitflag;
sigset_t mask;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t waitloc = PTHREAD_COND_INITIALIZER;
void* thr_fn(void* arg) {
int err, signo;
for ( ; ; ) {
err = sigwait(&mask, &signo);
if (err != 0) {
err_exit(err, "sigwait failed");
}
switch (signo) {
case SIGINT:
printf("\ninterrupt\n");
break;
case SIGQUIT:
pthread_mutex_lock(&lock);
quitflag = 1;
pthread_mutex_unlock(&lock);
pthread_cond_signal(&waitloc);
return 0;
default:
printf("unexpected signal %d\n", signo);
exit(1);
}
}
}
int main() {
int err;
sigset_t oldmask;
pthread_t tid;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigaddset(&mask, SIGQUIT);
if ((err = pthread_sigmask(SIG_BLOCK, &mask, &oldmask)) != 0) {
err_exit(err, "SIG_BLOCK failed");
}
err = pthread_create(&tid, NULL, thr_fn, 0);
if (err != 0) {
err_exit(err, "pthread_create failed");
}
pthread_mutex_lock(&lock);
while (quitflag == 0) {
pthread_cond_wait(&waitloc, &lock);
}
pthread_mutex_unlock(&lock);
quitflag = 0;
if (sigprocmask(SIG_SETMASK, &oldmask, NULL) < 0) {
err_sys("SIG_SETMASK error");
}
exit(0);
}
Thread and fork
When a thread calls fork, it creates a copy of the entire process address space for the child process.
By inheriting the copy of the entire address space, the child process also inherits the state of each mutex, read-write lock and condition variable from the parent process. If the parent process contains more than one thread, the child process needs to clear the lock state if it does not immediately call exec after the fork returns.
Pthread can be called_ The atfork function installs up to three functions that help clear locks.
#include <pthread.h> int pthread_atfork(void (*prepare)(void), void (*parent)(void), void (*child)(void)); // 0 is returned for success and error number is returned for error
The prepare handler is called by the parent process before creating the child process in fork. The task of this handler is to obtain all locks defined by the parent process.
The parent handler is invoked in the context of the parent process before fork creates the child process and returns. The task of this handler is to unlock all locks obtained by the prepare handler.
The child handler is called in the context of the child process before fork returns. The child handler must also release all locks acquired by the prepare handler.
The parent and child handlers are called in the order in which they were registered, while the prepare handler is called in the reverse order in which they were registered. This allows multiple modules to register their own fork handlers and maintains the lock hierarchy.
Threads and I/O
Refer to the pread and pwrite functions in the atomic operation section of the notes in Chapter 3.
Daemon
daemon is a long-lived process. They often start when the system boots and loads and terminate only when the system is shut down. They have no control terminal and run in the background. UNIX systems have many daemons that perform daily business activities.
Characteristics of Daemons
The system process depends on the implementation of the operating system. Processes with parent process ID 0 are usually kernel processes, which are started as part of the system boot loading process. (init is an exception. It is a user level command started by the kernel at boot load.) Kernel processes are special and usually exist in the whole life cycle of the system. They run with super user privileges, no control terminal, no command line.
Most daemons run with root privileges. All daemons have no control terminals, and their terminal names are set to question marks. The kernel daemon starts as an uncontrolled terminal. The lack of control terminal of the user layer daemon may be the result of the daemon calling setsid. Most user layer daemons are the leader of the process group and the first process of the session, and are the only process in these process groups and sessions (rsyslogd is an exception). Finally, it should be noted that the parent process of the user layer daemon is the init process.
Programming rules
There are some basic rules to follow when writing daemons:
- First, call umask to set the file mode creation mask word to a known value (usually 0).
- Call fork, and then make the parent process exit.
- Call setsid to create a new session. Make the calling process: (a) become the first process of the new session, (b) become the leader of a new process group, and (c) have no control terminal.
- Change the current working directory to the root directory. Alternatively, some daemons may change the current working directory to a specified location and do all their work there. For example, the line printer spooler daemon might change its working directory to their spool directory.
- Close file descriptors that are no longer needed.
- Some daemons open / dev/null to have file descriptors 0, 1, and 2, so that any library routine that attempts to read standard input, write standard output, or standard error will have no effect.
Example:
#include "apue.h"
#include <syslog.h>
#include <fcntl.h>
#include <sys/resource.h>
void daemonize(const char* cmd) {
int i, fd0, fd1, fd2;
pid_t pid;
struct rlimit r1;
struct sigaction sa;
umask(0);
if (getrlimit(RLIMIT_NOFILE, &r1) < 0) {
err_quit("%s: can't get file limit", cmd);
}
if ((pid = fork()) < 0) {
err_quit("%s: can't fork", cmd);
} else if (pid != 0) {
exit(0);
}
setsid();
sa.sa_handler = SIG_IGN;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
if (sigaction(SIGHUP, &sa, NULL) < 0) {
err_quit("%s: can't ignore SIGHUP", cmd);
}
if ((pid = fork()) < 0) {
err_quit("%s: can't fork", cmd);
} else if (pid != 0) {
exit(0);
}
if (chdir("/") < 0) {
err_quit("%s: can't chdir to /", cmd);
}
if (r1.rlim_max == RLIM_INFINITY) {
r1.rlim_max = 1024;
}
for (i = 0; i < r1.rlim_max; i++) {
close(i);
}
fd0 = open("/dev/null", O_RDWR);
fd1 = dup(0);
fd2 = dup(0);
openlog(cmd, LOG_CONS, LOG_DAEMON);
if (fd0 != 0 || fd1 != 1 || fd2 != 2) {
syslog(LOG_ERR, "unexpected file descriptors %d %d %d", fd0, fd1, fd2);
exit(1);
}
}
I don't quite understand what the result of this function is. The result of the test program written is a little different from that imagined.
Error record
There are three ways to generate log messages:
- Kernel routines can call the log function. Any user process can read these messages by opening and reading the / dev/klog device.
- Most user processes (daemons) call the syslog(3) function to generate log messages. This causes the message to be sent to the UNIX domain datagram socket / dev/log.
- Whether a user process is on this host or on other hosts connected to this host through TCP/IP network, it can send log messages to UDP port 514. Note that the syslog function never generates these UDP datagrams. They require the process that generates this log message to perform explicit network programming.
Typically, the syslogd daemon reads log messages in all three formats. This daemon reads a configuration file at startup, and its file name is usually / etc / syslog Conf, which determines where different kinds of messages should be sent.
#include <syslog.h> void openlog(const char* ident, int option, int facility); void syslog(int priority, const char* format, ...); void closelog(void); int setlogmask(int maskpri); // Returns the previous logging priority mask word
Calling openlog is optional. If openlog is not called, openlog will be called automatically when syslog is called for the first time.
Calling closelog is also optional because it simply closes the descriptor that was used to communicate with the syslogd daemon.
Calling openlog enables us to specify an ident, which will be added to each log message in the future. Ident is generally the name of the program (e.g. cron, inetd).
The option parameter specifies the bit mask of various options:

facility parameter:

The priority parameter is a combination of facility and level.
Possible values of level (priority from high to low):
If you do not call openlog or call it with facility 0, you can describe facility as a part of the priority parameter when calling syslog.
The setlogmask function is used to set the record priority mask word of the process. It returns the mask word before calling it.
When the recording priority mask word is set, each message will not be recorded unless it has been set in the recording priority mask word.
Note that trying to set the record priority mask word to 0 does not work.
Many platforms also provide a variant of syslog:
#include <syslog.h> #include <stdarg.h> void vsyslog(int priority const char* format, va_list arg);
Single-Instance Daemons
For normal operation, some daemons are implemented to run only one copy of the daemon at any time.
The file and record locking mechanism provides the basis for a method that ensures that only one copy of a daemon is running. If each daemon creates a file with a fixed name and adds a write lock to the whole file, only one such write lock is allowed to be created. After that, all attempts to create a write lock fail, indicating to subsequent daemons that a copy is already running.
File and record locks provide a convenient mutual exclusion mechanism. If the daemon gets a write lock on the whole file, the lock will be automatically deleted when the daemon terminates.
Sample program:
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <syslog.h>
#include <string.h>
#include <errno.h>
#include <stdio.h>
#include <sys/stat.h>
#define LOCKFILE "/var/run/daemon.pid"
#define LOCKMODE (S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH)
extern int lockfile(int);
int already_running() {
int fd;
char buf[16];
fd = open(LOCKFILE, O_RDWR|O_CREAT, LOCKMODE);
if (fd < 0) {
syslog(LOG_ERR, "can't open %s: %s", LOCKFILE, strerror(errno));
}
if (lockfile(fd) < 0) {
if (errno == EACCES || errno == EAGAIN) {
close(fd);
return 1;
}
syslog(LOG_ERR, "can't lock %s: %s", LOCKFILE, strerror(errno));
exit(1);
}
ftruncate(fd, 0);
sprintf(buf, "%ld", (long)getpid());
write(fd, buf, strlen(buf) + 1);
return 0;
}
I don't know where the lockfile function is, but I can't find it 😭.
Daemon conventions
On UNIX systems, daemons follow the following general conventions:
- If the daemon uses a lock file, it is usually stored in the / var/run directory. The name of the lock file is usually name PID, where name is the name of the daemon or service.
- If the daemon supports configuration options, the configuration files are usually stored in the / etc directory. The name of the configuration file is usually name conf.
- Daemons can be started from the command line, but usually they are started by one of the system initialization scripts (/ etc/rc * or / etc/init.d / *). If the daemon terminates, it should be restarted automatically (we can include the respawn record entry for the daemon in / etc/inittab, so init will restart the daemon).
- If a daemon has a configuration file, the file will be read when the daemon starts, but it will not be viewed after that. If an administrator changes the configuration file, the daemon may need to be stopped and then started for the configuration file changes to take effect. To avoid this trouble, some daemons will catch the SIGHUP signal and reread the configuration file when they receive it.
Client server process model
Daemons are often used as server processes.
Generally speaking, the server process waits for the client process to contact it and put forward some type of service request.
Advanced I/O
Non blocking I/O
Non blocking I/O allows us to issue I/O operations such as open, read and write, but it will not block forever. If this operation cannot be completed, the call immediately returns an error, indicating that the operation will be blocked if it continues.
There are two ways to specify non blocking I/O for a given descriptor:
-
If you call open to get the descriptor, you can specify O_NONBLOCK flag.
-
For a descriptor that has been opened, you can call the fcntl function to open O_NONBLOCK file status flag.
A simple example:
#include "apue.h"
#include <errno.h>
#include <fcntl.h>
char buf[500000];
int main() {
int ntowrite, nwrite;
char* ptr;
ntowrite = read(STDIN_FILENO, buf, sizeof(buf));
fprintf(stderr, "read %d bytes\n", ntowrite);
set_fl(STDOUT_FILENO, O_NONBLOCK);
ptr = buf;
while (ntowrite > 0) {
errno = 0;
nwrite = write(STDOUT_FILENO, ptr, ntowrite);
fprintf(stderr, "nwrite = %d, errno = %d\n", nwrite, errno);
if (nwrite > 0) {
ptr += nwrite;
ntowrite -= nwrite;
}
}
clr_fl(STDOUT_FILENO, O_NONBLOCK);
exit(0);
}
Record lock
The function of record locking is to prevent other processes from modifying the same file area when a process is reading or modifying a part of the file.
fcntl record lock
#include <fcntl.h> int fcntl(int fd, int cmd, .../* struct flock* flockptr */); // The successful return value depends on cmd, and the error returns - 1
For record locks, cmd is F_GETLK,F_SETLK or F_SETLKW, the third parameter uses flockptr.
flockptr is a pointer to the flock structure.
struct flock {
short l_type; /* Lock type: F_RDLCK, F_WRLCK, or F_UNLCK */
short l_whence; /* SEEK_SET, SEEK_CUR, or SEEK_END */
off_t l_start; /* Relative L_ Offset of where */
off_t l_len; /* Length of locked area, 0 represents the length up to EOF */
pid_t l_pid; /* cmd For F_GETLK: when returning, the lock held by the process represented by pid can block the current process */
};
The basic rule of shared read lock (l_type is L_RDLCK) and exclusive write lock (L_WRLCK) is that any number of processes can have a shared read lock on a given byte, but only one process can have an exclusive write lock on a given byte.
cmd has three values:
-
F_GETLK: judge whether the lock described by flockptr will be blocked by another lock. If there is a lock that prevents the creation of the lock described by flockptr, the information of the existing lock will overwrite the information pointed to by flockptr. If this does not exist, in addition to l_type set to f_ In addition to unlck, other information in the structure pointed to by flockptr remains unchanged.
-
F_SETLK: set the lock described by flockptr. If we try to obtain a read lock (l_type is F_RDLCK) or write lock (l_type is F_WRLCK), and the compatibility rules prevent the system from giving us this lock, fcntl will immediately return an error, and at this time, errno is set to EACCES or EAGAIN. This command is also used to clear the lock specified by flockptr (l_type is F_UNLCK).
-
F_SETLKW: this command is f_ Blocking version of setlk (W for Wait). If the requested read lock or write lock cannot be granted because another process has currently locked a part of the requested area, the calling process will be put into sleep. If the lock requested to be created is already available, or sleep is interrupted by a signal, the process is awakened.
When setting or releasing a lock on a file, the system combines or splits adjacent areas as required.
Implicit inheritance and release of locks
Three rules for automatic inheritance and release of record locks:
- Locks are associated with both processes and files. When a process terminates, all the locks it establishes are released; Whenever a descriptor is closed, any lock on the file referenced by the process through this descriptor will be released.
- The child process generated by fork does not inherit the lock set by the parent process.
- After exec is executed, the new program can inherit the lock of the original program. However, if the close on execution flag is set for a file descriptor, all locks of the corresponding file will be released when the file descriptor is closed as part of exec.
Recommended and mandatory locks
A suggestive lock cannot prevent any other process that has write permission to the file from writing to the file.
The mandatory lock will let the kernel check each open, read and write to verify whether the calling process violates a lock on the file being accessed.
Mandatory locks are sometimes called enforcement mode locking.
Opening the set group ID bit and closing the group execution bit for a specific file opens the mandatory locking mechanism for the file.
Impact of mandatory lock on read and write of other processes:

I/O multiplexing
select and pselect
The select function allows us to perform I/O multiplexing. The parameters passed to select tell the kernel:
- Descriptors we care about;
- The conditions we care about for each descriptor (whether we want to read from a given descriptor, write a given descriptor, and care about the exception conditions of a given descriptor);
- How long are you willing to wait (you can wait forever, for a fixed time, or not at all).
When returning from select, the kernel tells us:
- The total number of descriptors prepared;
- For each of the three conditions read, write, or exception, which descriptor is ready.
#include <sys/select.h> int select(int maxfdp1, fd_set* restrict readfds, fd_set* restrict writefds, fd_set* restrict exceptfds, struct timeval* restrict tvptr); // Returns the number of ready descriptors, 0 for timeout and − 1 for error
The tvptr parameter specifies the length of time you are willing to wait:
-
tvptr == NULL: wait forever. If a signal is captured, this indefinite wait is interrupted. Returns when one of the specified descriptors is ready or captures a signal. If a signal is captured, select returns - 1 and errno is set to EINTR.
-
tvptr->tv_ sec == 0 && tvptr->tv_ USEC = = 0: do not wait. Test all specified descriptors and return immediately. It can be used to query the status of multiple descriptors.
-
tvptr->tv_ sec != 0 || tvptr->tv_ usec != 0: returns immediately when one of the specified descriptors is ready or when the specified time value has exceeded. If a descriptor is not ready when the timeout expires, 0 is returned. This waiting can also be interrupted by the captured signal.
readfds, writefds, and exceptfds are pointers to descriptor sets.
Each descriptor set is stored in one fd_set data type. It can hold one bit for each possible descriptor.
fd_ Related operations of set data type:
#include <sys/select.h> int FD_ISSET(int fd, fd_set* fdset); // If fd returns a non-zero value in the descriptor set, otherwise it returns 0 void FD_CLR(int fd, fd_set* fdset); void FD_SET(int fd, fd_set* fdset); void FD_ZERO(fd_set* fdset);
These interfaces can be implemented as macros or functions.
-
Call FD_ZERO will a FD_ All bits of the set variable are set to 0.
-
To turn on a bit in the descriptor set, you can call FD_SET.
-
Call FD_CLR can clear one bit.
-
FD can be called_ Isset tests whether a pointer in the descriptor set is turned on.
The maxfdp1 parameter is the number value of the largest file descriptor in the three descriptor sets plus 1. This parameter is used to improve the efficiency of traversing the file descriptor.
Return value of select:
-
Return value - 1: error. For example, a signal is captured when none of the specified descriptors are ready. In this case, neither descriptor set is modified.
-
Return value 0: timeout without descriptor ready. At this point, all descriptor sets will be set to 0.
-
Positive return value: indicates the number of descriptors that have been prepared. This value is the sum of the number of prepared descriptors in the three descriptor sets.
If the end of a file is encountered on a descriptor, select will consider the descriptor readable. Then call read, which returns 0, which is the way the UNIX system indicates the end of the file.
POSIX.1 defines a variant of select called pselect:
#include <sys/select.h> int pselect(int maxfdp1, fd_set* restrict readfds, fd_set* restrict writefds, fd_set* restrict exceptfds, const struct timespec* restrict tsptr, const sigset_t* restrict sigmask); // Returns the number of ready descriptors, 0 for timeout and − 1 for error
-
The timeout value of select is specified with the timeval structure, while pselect uses the timespec structure (more precisely).
-
The timeout value of pselect is declared const, which ensures that calling pselect will not change this value.
-
sigmask specifies the signal mask word. When pselect is called, the signal mask word is installed in the way of atomic operation. On return, restore the previous signal mask word. (NULL is the same as select)
poll
#include <poll.h> int poll(struct pollfd fdarray[], nfds_t nfds, int timeout); // Returns the number of ready descriptors, 0 for timeout and - 1 for error
Each element in the fdarray array specifies a descriptor number and the conditions we are interested in the descriptor. The nfds parameter specifies the length of the array.
The struct pollfd structure is as follows:
struct pollfd {
int fd; /* file descriptor to check, or < 0 to ignore */
short events; /* events of interest on fd */
short revents; /* events that occurred on fd */
};
Value of events member:
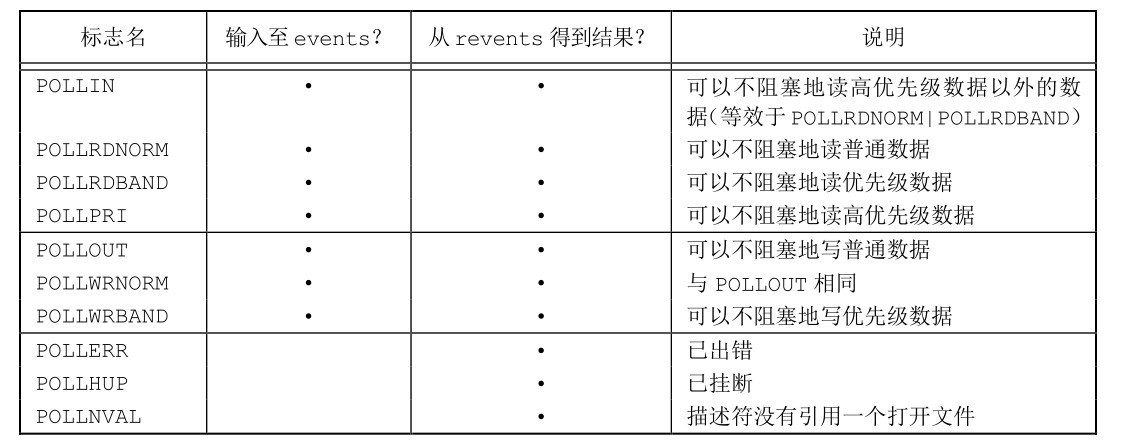
Possible values of timeout:
-
timeout == -1: wait forever. Returns when one of the specified descriptors is ready or a signal is captured. If a signal is captured, poll returns - 1 and errno is set to EINTR.
-
timeout == 0: do not wait. Test all descriptors and return immediately.
-
Timeout > 0: wait for timeout milliseconds. Returns immediately when one of the specified descriptors is ready, or when the timeout expires. If a descriptor is not ready when the timeout expires, the return value is 0.
Asynchronous I/O
POSIX asynchronous I/O interface provides a consistent method for asynchronous I/O of different types of files.
Asynchronous I/O is based on the aiocb(AIO control block) structure, which includes at least the following fields:
struct aiocb {
int aio_fildes; /* file descriptor */
off_t aio_offset; /* file offset for I/O */
volatile void* aio_buf; /* buffer for I/O */
size_t aio_nbytes; /* number of bytes to transfer */
int aio_reqprio; /* priority */
struct sigevent aio_sigevent; /* signal information */
int aio_lio_opcode; /* operation for list I/O */
};
aio_ The sigevent field controls how to notify the application after the I/O event is completed.
This field is described by sigevent structure:
struct sigevent {
int sigev_notify; /* notify type */
int sigev_signo; /* signal number */
union sigval sigev_value; /* notify argument */
void (*sigev_notify_function)(union sigval);/* notify function */
pthread_attr_t* sigev_notify_attributes; /* notify attrs */
};
sigev_ The notify field controls the type of notification:
-
SIGEV_NONE: after the asynchronous I/O request is completed, the process is not notified.
-
SIGEV_SIGNAL: generated by sigev after the asynchronous I/O request is completed_ The signal specified in the Signo field.
-
SIGEV_THREAD: when the asynchronous I/O request is completed, sigev_ notify_ The function specified in the function field is called. sigev_ The value field is passed in as its only parameter. Unless sigev_ notify_ The attributes field is set to the address of the pthread attribute structure, which specifies another thread attribute, otherwise the function will be executed in a separate thread in the separated state.
Call aio_read function to perform asynchronous read operation and call aio_write function to perform asynchronous write operations.
#include <aio.h> int aio_read(struct aiocb* aiocb); int aio_write(struct aiocb* aiocb); // 0 is returned for success and − 1 is returned for error
AIO can be called_ The fsync function forces all pending asynchronous operations to write to persistent storage without waiting.
#include <aio.h> int aio_fsync(int op, struct aiocb* aiocb); // 0 is returned for success and − 1 is returned for error
AIO in AIO control block_ The fields field specifies the file whose asynchronous writes are synchronized.
- If op parameter is set to O_DSYNC, then the operation will be executed as if fdatasync was called.
- If op parameter is set to O_SYNC, then the operation will be executed as if fsync was called.
AIO can be called_ The error function obtains the completion status of asynchronous read, write or synchronous operations:
#include <aio.h> int aio_error(const struct aiocb* aiocb);
There are four return values:
-
0: the asynchronous operation completed successfully. AIO needs to be called_ The return function gets the return value of the operation.
-
− 1: for AIO_ The call to error failed.
-
EINPROGRESS: asynchronous read, write, or synchronous operations are still waiting.
-
Other return values are the error codes returned when the related asynchronous operation fails.
If the asynchronous operation is successful, AIO can be called_ Return function to get the return value of the asynchronous operation.
#include <aio.h> ssize_t aio_return(const struct aiocb* aiocb);
Return value:
- If aio_return if the function itself fails, it will return − 1 and set errno.
- In other cases, it will return the result of asynchronous operation, that is, it will return the result that read, write or fsync may return when it is successfully called.
AIO needs to be called after the asynchronous operation is successful_ Return function. The result before the operation is completed is undefined.
AIO can only be called once per asynchronous operation_ return. After calling, the operating system can release the record containing the return value of I/O operation.
AIO can be called if the asynchronous operation is not completed after all transactions are completed_ Suspend function to block the process until the operation is completed.
#include <aio.h> int aio_suspend(const struct aiocb* const list[], int nent, const struct timespec* timeout); // 0 is returned for success and − 1 is returned for error
Return value:
- If interrupted by a signal, return - 1 and set errno to EINTR.
- If the blocking time exceeds the time limit specified by the optional timeout parameter in the function without any I/O operation completed, aio_suspend will return - 1 and set errno to EAGAIN.
- If any I/O operations are completed, aio_suspend will return 0.
If we call AIO_ During suspend operation, all asynchronous I/O operations have been completed, then aio_suspend will return directly without blocking.
When the timeout parameter is a null pointer, it means that no time limit is set.
The list parameter is a pointer to the AIO control block array, and the net parameter indicates the number of entries in the array. Null pointers in the array are skipped, and other entries must point to the AIO control block that has been used to initialize asynchronous I/O operations.
You can use AIO_ The cancel function attempts to cancel pending asynchronous I/O operations that you no longer want to complete.
#include <aio.h> int aio_cancel(int fd, struct aiocb* aiocb);
Return value:
-
AIO_ALLDONE: all operations completed before attempting to cancel them.
-
AIO_ Cancelled: all required operations have been cancelled.
-
AIO_ Not canceled: at least one of the requested operations has not been canceled.
-
-1: For AIO_ The call to cancel fails, and the error code will be stored in errno.
The fd parameter specifies the file descriptor of the incomplete asynchronous I/O operation. If the aiocb parameter is NULL, the system will attempt to cancel all outstanding asynchronous I/O operations on the file.
There is no guarantee that the system can cancel any operation in progress.
If the asynchronous I/O operation is successfully cancelled, AIO is called on the corresponding AIO control block_ The error function will return the error ECANCELED.
If the operation cannot be cancelled, the corresponding AIO control block will not_ It is modified due to the call of cancel.
lio_ The listio function can be called either synchronously or asynchronously. This function submits a series of I/O requests described by a list of AIO control blocks.
#include <aio.h> int lio_listio(int mode, struct aiocb* restrict const list[restrict], int nent, struct sigevent* restrict sigev); // 0 is returned for success and − 1 is returned for error
Possible values of the mode parameter:
-
LIO_WAIT: the function returns after all I/O operations specified by the list are completed. In this case, the sigev parameter is ignored.
-
LIO_NOWAIT: the function will return immediately after the I/O request is queued. The process will be notified asynchronously after all I/O operations are completed, as specified by the sigev parameter. If you don't want to be notified, you can set sigev to NULL.
Each AIO control block itself may also enable asynchronous notification when its own operation is completed. The asynchronous notification specified by the sigev parameter is added in addition to this, and will only be sent after all I/O operations are completed.
The list parameter points to the list of AIO control blocks, which specifies the I/O operations to run. The element parameter specifies the number of elements in the array. NULL entries in the list will be ignored.
AIO in struct aiocb structure_ lio_ The opcode field specifies whether the operation is a read operation (LIO_READ), a write operation (LIO_WRITE), or an empty operation (LIO_NOP) that will be ignored. The read operation will be transmitted to AIO according to the corresponding AIO control block_ Read function. The write operation will be transferred to AIO according to the corresponding AIO control block_ Write function.
An example program of asynchronous I/O:
#include "apue.h"
#include <ctype.h>
#include <fcntl.h>
#include <aio.h>
#include <errno.h>
#define BSZ 4096
#define NBUF 8
enum rwop {
UNUSED = 0,
READ_PENDING = 1,
WRITE_PENDING = 2
};
struct buf {
enum rwop op;
int last;
struct aiocb aiocb;
unsigned char data[BSZ];
};
struct buf bufs[NBUF];
unsigned char translate(unsigned char c) {
if (isalpha(c)) {
if (c >= 'n') {
c -= 13;
} else if (c >= 'a') {
c += 13;
} else if (c >= 'N') {
c -= 13;
} else {
c += 13;
}
}
return (c);
}
int main(int argc, char* argv[]) {
int ifd, ofd, i, j, n, err, numop;
struct stat sbuf;
const struct aiocd* aiolist[NBUF];
off_t off = 0;
if (argc != 3) {
err_quit("usage: rot13 infile outfile");
}
if ((ifd = open(argv[1], O_RDONLY)) < 0) {
err_sys("can't open %s", argv[1]);
}
if ((ofd = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE)) < 0) {
err_sys("can't create %s", argv[2]);
}
if (fstat(ifd, &sbuf) < 0) {
err_sys("fstat error");
}
for (i = 0; i < NBUF; i++) {
bufs[i].op = UNUSED;
bufs[i].aiocb.aio_buf = bufs[i].data;
bufs[i].aiocb.aio_sigevent.sigev_notify = SIGEV_NONE;
aiolist[i] = NULL;
}
numop = 0;
for ( ; ; ) {
for (i = 0; i < NBUF; i++) {
switch (bufs[i].op) {
case UNUSED:
if (off < sbuf.st_size) {
bufs[i].op = READ_PENDING;
bufs[i].aiocb.aio_fildes = ifd;
bufs[i].aiocb.aio_offset = off;
off += BSZ;
if (off >= sbuf.st_size) {
bufs[i].last = 1;
}
bufs[i].aiocb.aio_nbytes = BSZ;
if (aio_read(&bufs[i].aiocb) < 0) {
err_sys("aio_read failed");
}
aiolist[i] = &bufs[i].aiocb;
numop++;
}
break;
case READ_PENDING:
if ((err = aio_error(&bufs[i].aiocb)) == EINPROGRESS) {
continue;
}
if (err != 0) {
if (err == -1) {
err_sys("aio_error failed");
} else {
err_exit(err, "read failed");
}
}
if ((n = aio_return(&bufs[i].aiocb)) < 0) {
err_sys("aio_return failed");
}
if (n != BSZ && !bufs[i].last) {
err_quit("short read (%d/%d)", n, BSZ);
}
for (j = 0; j < n; j++) {
bufs[i].data[j] = translate(bufs[i].data[j]);
}
bufs[i].op = WRITE_PENDING;
bufs[i].aiocb.aio_fildes = ofd;
bufs[i].aiocb.aio_nbytes = n;
if (aio_write(&bufs[i].aiocb) < 0) {
err_sys("aio_write failed");
}
break;
case WRITE_PENDING:
if ((err = aio_error(&bufs[i].aiocb)) == EINPROGRESS) {
continue;
}
if (err != 0) {
if (err == -1) {
err_sys("aio_error failed");
} else {
err_exit(err, "write failed");
}
}
if ((n = aio_return(&bufs[i].aiocb)) < 0) {
err_sys("aio_return failed");
}
if (n != bufs[i].aiocb.aio_nbytes) {
err_quit("short write (%d/%d)", n, BSZ);
}
aiolist[i] = NULL;
bufs[i].op = UNUSED;
numop--;
break;
}
}
if (numop == 0) {
if (off >= sbuf.st_size) {
break;
}
} else {
if (aio_suspend(aiolist, NBUF, NULL) < 0) {
err_sys("aio_suspend failed");
}
}
}
bufs[0].aiocb.aio_fildes = ofd;
if (aio_fsync(O_SYNC, &bufs[0].aiocb) < 0) {
err_sys("aio_fsync failed");
}
exit(0);
}
readv and writev
The readv and writev functions are used to read and write multiple discontinuous buffers in one function call.
These two functions are also called scatter read and gather write.
#include <sys/aio.h> ssize_t readv(int fd, const struct iovec* iov, int iovcnt); ssize_t writev(int fd, const struct iovec* iov, int iovcnt); // The number of bytes read or written is returned successfully, and − 1 is returned in case of error
The struct iovec structure is as follows:
struct iovec {
void* iov_base; /* starting address of buffer */
size_t iov_len; /* size of buffer */
};
The iovcnt parameter specifies the number of elements in the iov array.
writev returns the total number of bytes output, which should usually be equal to the sum of all buffer lengths.
readn and writen
Pipeline, FIFO and some equipment (especially terminal and network) have the following two properties:
-
A read operation may return less data than required, even if it has not reached the end of the file. This is not an error and you should continue reading the device.
-
The return value of a write operation may be less than the number of bytes specified for output. This may be caused by some factor, such as the kernel output buffer becoming full. This is not an error. You should continue to write the remaining data.
Usually, this write midway return occurs only when a non blocking descriptor or a signal is captured.
We can implement two functions to read and write the specified N-byte data:
#include "apue.h"
ssize_t readn(int fd, void* ptr, size_t n) {
size_t nleft;
ssize_t nread;
nleft = n;
while (nleft > 0) {
if ((nread = read(fd, ptr, nleft)) < 0) {
if (nleft == n) {
return -1;
} else {
break;
}
}
nleft -= nread;
ptr += nread;
}
return n - nleft;
}
ssize_t writen(int fd, const void* ptr, size_t n) {
size_t nleft;
ssize_t nwritten;
nleft = n;
while (nleft > 0) {
if ((nwritten = write(fd, ptr, nleft)) < 0) {
if (nleft == n) {
return -1;
} else {
break;
}
}
nleft -= nwritten;
ptr += nwritten;
}
return n - nleft;
}
Storage mapping I/O
Memory mapped I/O can map a disk file to a buffer in the storage space. Therefore, when taking data from the buffer, it is equivalent to reading the corresponding bytes in the file. When the data is stored in the buffer, the corresponding bytes are automatically written to the file. In this way, I/O can be performed without using read and write.
We can use the mmap function to tell the kernel to map a given file to a storage area:
#include <sys/mman.h> void* mmap(void* addr, size_t len, int prot, int flag, int fd, off_t off); // The starting address of the mapping area is returned successfully, and map is returned in case of error_ FAILED
The addr parameter specifies the starting address of the mapping store. Usually set to 0, which means that the system selects the starting address of the mapping area.
The fd parameter is a descriptor that specifies the file to be mapped. The file must be opened before it can be mapped to an address space. len parameter is the number of bytes mapped, and off is the starting offset of the bytes to be mapped in the file.
The prot parameter specifies the protection requirements of the mapped storage area:
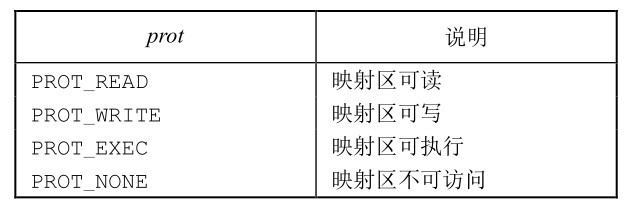
The prot parameter can be specified as PROT_NONE, can also be specified as PROT_READ,PROT_WRITE and prot_ Bitwise or of any combination of exec.
Possible values of flag parameter:
-
MAP_FIXED: the return value must be equal to addr. If this flag is not specified and addr is not 0, the kernel only regards addr as a suggestion of where to set the mapping area, but there is no guarantee that the required address will be used.
-
MAP_SHARED: this flag describes the configuration of the process's storage operation on the mapping area. This flag specifies that the storage operation modifies the mapping file, that is, the storage operation is equivalent to writing the file.
-
MAP_PRIVATE: this flag indicates that the storage operation of the mapping area results in the creation of a private copy of the mapping file. All subsequent references to the mapping area refer to the copy.
One use of this flag is to debug a program. It maps the body part of the program file to the storage area, but allows the user to modify the instructions in it. Any modification only affects the copy of the program document, not the original document.
Map must be specified_ Shared and map_ One and only one of private can be specified.
The value of off and the value of addr (if MAP_FIXED is specified) are usually required to be multiple of the length of the virtual storage page of the system.
The SIGSEGV signal is usually used to indicate that a process is trying to access a storage area that is not available to it. If the mapped storage area is specified as read-only by mmap, this signal will also be generated when the process attempts to store data in the mapped storage area.
If a part of the mapping area no longer exists at the time of access, a SIGBUS signal is generated.
The child process can inherit the storage mapping area through fork (because the child process copies the address space of the parent process, and the storage mapping area is a part of the address space), but for the same reason, the new program cannot inherit the storage mapping area through exec.
You can call the mprotect function to change the permissions of an existing mapping:
#include <sys/mman.h> int mprotect(void* addr, size_t len, int prot); // 0 is returned for success and - 1 for error
The legal value of prot is the same as that of the prot parameter in mmap
If the page in the shared map has been modified, you can call msync to flush the page into the mapped file. The msync function is similar to fsync, but works on the storage mapping area.
#include <sys/mman.h> int msync(void* addr, size_t len, int flags); // 0 is returned for success and - 1 for error
If the mapping is private, the mapped file is not modified.
The flags parameter controls how to flush the storage area:
- MS can be specified_ Async flag to simply debug the page to be written.
- If you want to wait for the write operation to complete before returning, you can specify MS_SYNC flag.
- MS_ Invalid is an optional flag that allows us to tell the operating system to discard pages that are not synchronized with the underlying storage.
Be sure to specify MS_ASYNC and MS_ One of sync.
When the process terminates, it will automatically unmap the storage mapping area, or directly call the munmap function to unmap the storage mapping area.
#include <sys/mman.h> int munmap(void* addr, size_t len); // 0 is returned for success and - 1 for error
Calling munmap does not cause the contents of the mapping area to be written to the disk file. For map_ The disk files in shared area will be updated automatically according to the kernel virtual storage algorithm at a certain time after we write the data to the storage mapping area. After the storage area is unmapped, the map_ Modifications to the private store are discarded.
The file descriptor used when closing the mapped store does not unmap the store.
A simple example (copying files using storage mapped I/O):
#include "apue.h"
#include <fcntl.h>
#include <sys/mman.h>
#define COPYINCR (1024*1024*1024) // 1 GB
int main(int argc, char *argv[]) {
int fdin, fdout;
void *src, *dst;
size_t copysz;
struct stat sbuf;
off_t fsz = 0;
if (argc != 3) {
err_quit("usage: %s <fromfile> <tofile>", argv[0]);
}
if ((fdin = open(argv[1], O_RDONLY)) < 0) {
err_sys("can't open %s for reading", argv[1]);
}
if ((fdout = open(argv[2], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) < 0) {
err_sys("can't open %s for writing", argv[2]);
}
if (fstat(fdin, &sbuf) < 0) {
err_sys("fstat error");
}
if (ftruncate(fdout, sbuf.st_size) < 0) {
err_sys("ftruncate error");
}
while (fsz < sbuf.st_size) {
if ((sbuf.st_size - fsz) > COPYINCR) {
copysz = COPYINCR;
} else {
copysz = sbuf.st_size - fsz;
}
if ((src = mmap(0, copysz, PROT_READ, MAP_SHARED, fdin, fsz)) == MAP_FAILED) {
err_sys("mmap error for input");
}
if ((dst = mmap(0, copysz, PROT_READ | PROT_WRITE, MAP_SHARED, fdout, fsz)) == MAP_FAILED) {
err_sys("mmap error for output");
}
memcpy(dst, src, copysz);
munmap(src, copysz);
munmap(dst, copysz);
fsz += copysz;
}
exit(0);
}
Interprocess communication
InterProcess Communication, IPC for short.
The Conduit
You can create a pipe through the pipe function:
#include <unistd.h> int pipe(int fd[2]); // 0 is returned for success and - 1 for error
After successful return, fd[0] is opened for reading and fd[1] is opened for writing. The output of fd[1] is the input of fd[0].
The fstat function returns a file descriptor of FIFO type for each end of the pipeline. You can use S_ISFIFO macro to test the pipeline.
Usually, the process will call pipe first and then fork, so as to create an IPC channel between the parent process and the child process.
- For parent to child channels. The parent process closes the read end of the pipeline (fd[0]), and the child process closes the write end (fd[1]).
- For the pipeline from the child process to the parent process, the parent process closes the write side (fd[1]) and the child process closes the read side (fd[0]).
When reading a pipeline whose write end has been closed, after all data has been read, read returns 0, indicating the end of the file.
When writing to a pipeline whose read end has been closed, the signal SIGPIPE is generated. If the signal is ignored or captured and returned from its handler, write returns − 1 and errno is set to EPIPE.
A simple example:
#include "apue.h"
int main() {
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if (pipe(fd) < 0) {
err_sys("pipe error");
}
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) {
close(fd[0]);
write(fd[1], "hello world!\n", 12);
} else {
close(fd[1]);
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
exit(0);
}
TELL_ Implementation of the use pipeline of wait series functions:
#include "apue.h"
static int pfd1[2], pfd2[2];
void TELL_WAIT(void) {
if (pipe(pfd1) < 0 || pipe(pfd2) < 0) {
err_sys("pipe error");
}
}
void TELL_PARENT(pid_t pid) {
if (write(pfd2[1], "c", 1) != 1) {
err_sys("write error");
}
}
void WAIT_PARENT(void) {
char c;
if (read(pfd1[0], &c, 1) != 1) {
err_sys("read error");
}
if (c != 'p') {
err_quit("WAIT_PARENT: incorrect data");
}
}
void TELL_CHILD(pid_t pid) {
if (write(pfd1[1], "p", 1) != 1) {
err_sys("write error");
}
}
void WAIT_CHILD(void) {
char c;
if (read(pfd2[0], &c, 1) != 1) {
err_sys("read error");
}
if (c != 'c') {
err_quit("WAIT_CHILD: incorrect data");
}
}
popen and pclose
#include <stdio.h> FILE* popen(const char* cmdstring, const char* type); // The file pointer is returned successfully, and NULL is returned in case of error int pclose(FILE* fp); // The termination status of cmdstring is returned successfully, and - 1 is returned in case of error
The function popen first executes fork, then calls exec to execute cmdstring, and returns a standard I/O file pointer.
-
If type is "r", the file pointer is connected to the standard output of cmdstring.
-
If the type is "w", the file pointer is connected to the standard input of cmdstring,
The pclose function closes the standard I/O stream, waits for the command to terminate, and then returns to the termination state of the shell. If the shell cannot be executed, the termination status returned by pclose is the same as the shell execution exit(127).
Sample program (implementation of popen and pclose):
#include "apue.h"
#include <errno.h>
#include <fcntl.h>
#include <sys/wait.h>
static pid_t* childpid = NULL; // pointer to array allocated at run-time
static int maxfd;
FILE* popen(const char* cmdstring, const char* type) {
int i;
int pfd[2];
pid_t pid;
FILE* fp;
if ((type[0] != 'r' && type[0] != 'w') || type[1] != 0) {
errno = EINVAL;
return NULL;
}
if (childpid == NULL) {
maxfd = open_max();
if ((childpid = calloc(maxfd, sizeof(pid_t))) == NULL) {
return NULL;
}
}
if (pipe(pfd) < 0) {
return NULL;
}
if (pfd[0] >= maxfd || pfd[1] >= maxfd) {
close(pfd[0]);
close(pfd[1]);
errno = EMFILE;
return NULL;
}
if ((pid = fork()) < 0) {
return NULL;
} else if (pid == 0) {
if (*type == 'r') {
close(pfd[0]);
if (pfd[1] != STDOUT_FILENO) {
dup2(pfd[1], STDOUT_FILENO);
close(pfd[1]);
}
} else {
close(pfd[1]);
if (pfd[0] != STDIN_FILENO) {
dup2(pfd[0], STDIN_FILENO);
close(pfd[0]);
}
}
/* close all descriptors in childpid[] */
/* to comply with POSIX.1 */
for (i = 0; i < maxfd; i++) {
if (childpid[i] > 0) {
close(i);
}
}
execl("/bin/sh", "sh", "-c", cmdstring, (char*)0);
_exit(127);
}
/* parent */
if (*type == 'r') {
close(pfd[1]);
if ((fp = fdopen(pfd[0], type)) == NULL) {
return NULL;
}
} else {
close(pfd[0]);
if ((fp = fdopen(pfd[1], type)) == NULL) {
return NULL;
}
}
childpid[fileno(fp)] = pid; // remember child pid for this fd
return fp;
}
int pclose(FILE* fp) {
int fd, stat;
pid_t pid;
if (childpid == NULL) {
errno = EINVAL;
return -1;
}
fd = fileno(fp);
if (fd > maxfd) {
errno = EINVAL;
return -1;
}
if ((pid = childpid[fd]) == 0) {
errno = EINVAL;
return -1;
}
childpid[fd] = 0;
if (fclose(fp) == EOF) {
return -1;
}
while (waitpid(pid, &stat, 0) < 0) {
if (errno != EINTR) {
return -1;
}
}
return stat;
}
Collaborative process
UNIX system filter reads data from standard input and writes data to standard output. When a filter program not only generates the input of a filter program, but also reads the output of the filter program, it becomes a copprocess.
FIFO
FIFO is also called named pipe.
Unnamed pipes can only be used between two related processes, and the two related processes also have a common ancestor process that created them. However, through FIFO, unrelated processes can also exchange data.
You can use the mkfifo function to create a FIFO:
#include <sys/stat.h> int mkfifo(const char* path, mode_t mode); int mkfifoat(int fd, const char* path, mode_t mode); // 0 is returned for success and - 1 for error
The optional value of the mode parameter is the same as that of the mode parameter in the open function
Functions with at type are still in the original mode:
- If the path parameter specifies an absolute pathname, the fd parameter is ignored, and the behavior of the mkfifoat function is similar to that of mkfifo.
- If the path parameter specifies a relative pathname, the fd parameter is a valid file descriptor for the open directory,.
- If the path parameter specifies a relative pathname and the fd parameter has a special value of AT_FDCWD, the pathname starts with the current directory, and mkfifoat is similar to mkfifo.
After creating a FIFO, use open to open the FIFO.
Impact of non blocking flag (O_NONBLOCK) when opening FIFO:
-
Under normal circumstances (no O_NONBLOCK is specified), the read-only open is blocked until some other process opens the FIFO for writing. Write only open blocks until some other process opens it for reading.
-
If O is specified_ Nonblock, then read-only open returns immediately. If no process opens a FIFO for reading, write only open will return − 1 and set errno to ENXIO.
XSI IPC
There are three kinds of XSI IPC: message queue, semaphore and shared memory.
Identifier and key
The IPC structure (message queue, semaphore or shared memory segment) in each kernel is referenced by a non negative integer identifier.
Each IPC object is associated with a key (key, the corresponding type is key_t), and this key is used as the external name of the object.
The method of converging client processes and server processes on the same IPC structure:
- The server process can specify the IPC key_ Private creates a new IPC structure and stores the returned identifier somewhere (such as a file) for the client process to access. Key IPC_PRIVATE ensures that the server process creates a new IPC structure.
- Define a key recognized by both client and server processes in a common header file. The server process then specifies this key to create a new IPC structure.
- The client process and the server process identify a path name and an item ID (the item ID is a character value between 0 and 255), and then call the function ftok to convert the two values into a key. Then use this key in method (2).
#include <sys/ipc.h> key_t ftok(const char* path, int fd); // Return key for success and (key_t)-1 for error
IPC must never be specified_ Private is used as a key to reference an existing queue. This special key value is always used to create a new queue.
If you want to create a new IPC structure and ensure that you do not reference an existing IPC structure with the same identifier, you must also specify IPC in the flag_ Creat and IPC_EXCL bit. After doing so, if the IPC structure already exists, an error will be caused and EEXIST will be returned.
Permission structure
XSI IPC associates IPC for each IPC structure_ Perm structure. This structure specifies the authority and owner, and it includes at least the following members:
struct ipc_perm {
uid_t uid; /* owner's effective user id */
gid_t gid; /* owner's effective group id */
uid_t cuid; /* creator's effective user id */
gid_t cgid; /* creator's effective group id */
mode_t mode; /* access modes */
/* more fi*/
};
The mode field is S_IRUSR,S_ Combination of 9 values such as iwusr.
Message queue
Message queue is the link table of messages, which is stored in the kernel and identified by the message queue identifier (queue ID).
msgget is used to create a new queue or open an existing queue. msgsnd adds a new message to the end of the queue. msgrcv is used to fetch messages from the queue.
Each queue has an msqid_ds structure is associated with it:
struct msqid_ds {
struct ipc_perm msg_perm; // For permission structure, refer to the previous section
msgqnum_t msg_qnum; // num of messages on queue
msglen_t msg_qbytes; // max num of bytes on queue
pid_t msg_lspid; // pid of last msgsnd()
pid_t msg_lrpid; // pid of last msgrcv()
time_t msg_stime; // last-msgsnd() time
time_t msg_rtime; // last-msgrcv() time
time_t msg_ctime; // last change time
};
The prototype of msgget is as follows:
#include <sys/msg.h> int msgget(key_t key, int flag); // The message queue ID is returned successfully, and - 1 is returned in case of error
When you create a new queue, msqid is_ Initialize the DS structure:
-
Initialize IPC perm structure. The mode member will be set according to the corresponding permission bit in the flag. The value of flag is as follows:
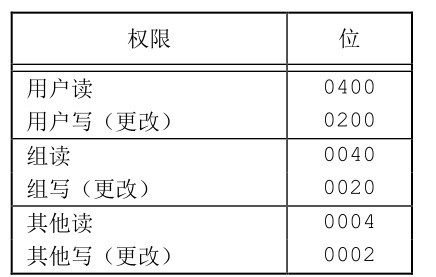
-
msg_qnum,msg_lspid,msg_lrpid,msg_stime and msg_rtime is set to 0.
-
msg_ctime is set to the current time.
-
msg_qbytes is set to the system limit.
The returned queue ID can be used for several other functions.
msgctl is a queue related garbage can function (that is, it can do many things):
#include <sys/msg.h> int msgctl(int msqid, int cmd, struct msqid_ds* buf); // 0 is returned for success and - 1 for error
msqid is the queue ID.
The value of cmd is as follows:
-
IPC_STAT: msqid of this queue_ The DS structure is stored in the structure pointed to by buf.
-
IPC_SET: set the field msg_perm.uid,msg_perm.gid,msg_perm.mode and msg_qbytes is copied from the structure pointed to by buf to the msqid associated with this queue_ DS structure.
-
IPC_RMID: delete the message queue and all data still in the queue from the system. This deletion takes effect immediately. Other processes that are still using this message queue will get an EIDRM error the next time they try to operate on this queue.
The latter two commands have permission requirements: either the valid user ID of the process is equal to msg_perm.cuid or msg_perm.uid, or super user privilege. And only super users can add MSG_ Value of qbytes.
msgsnd is used to put data into the message queue:
#include <sys/msg.h> int msgsnd(int msqid, const void* ptr, size_t nbytes, int flag); // 0 is returned for success and - 1 for error
msqid is the queue ID.
ptr points to a long integer, followed by message data. The long integer number indicates the message type (positive), and the length of the subsequent message data is indicated by nbytes. If the longest message sent is 512 bytes, the following structure can be defined:
struct mymesg {
long mtype;
char mtext[512];
};
ptr is a pointer to the mymesg structure.
The receiver can use the message type (mtype field) to retrieve messages in non first in first out order.
The value of the parameter flag can be specified as IPC_NOWAIT. If the message queue is full (or the total number of messages in the queue is equal to the system limit, or the total number of bytes in the queue is equal to the system limit), msgsnd immediately makes an error and returns EAGAIN.
If IPC is not specified_ Nowait, the process will be blocked until: there is space to accommodate the message to be sent; Or delete this queue from the system (EIDRM error returned); Or capture a signal and return it from the signal handler (return EINTR error).
The processing of deleting message queue is not very perfect. Each message queue does not maintain a reference counter (there is such a counter for open files), so after the queue is deleted, the process still using the queue will return an error the next time it operates on the queue.
msgsnd returns the msqid related to the message queue when success is returned_ The DS structure will be updated, indicating the process ID (msg_lspid) of the call, the time of the call (msg_stime) and the new message in the queue (msg_qnum).
msgrcv is used to get messages from the queue:
#include <sys/msg.h> ssize_t msgrcv(int msqid, const void* ptr, size_t nbytes, long type, int flag); // The length of message data is returned successfully, and - 1 is returned in case of error
The ptr parameter points to a long integer number (where the returned message type is stored), followed by a buffer that stores the actual message data. nbytes specifies the length of the data buffer.
If the length of the returned message is greater than nbytes and MSG is set in the flag_ Noerror bit, the message will be truncated. If this flag is not set and the message is too long, an error returns E2BIG (the message remains in the queue).
The parameter type can specify which message you want:
- type == 0: returns the first message in the queue.
- Type > 0: returns the first message with message type in the queue.
- Type < 0: returns the message whose message type value is less than or equal to the absolute value of type in the queue. If there are several such messages, the message with the smallest type value is taken.
The flag value can be specified as IPC_NOWAIT, so that the operation is not blocked. If no message of the specified type is available, msgrcv returns − 1 and error is set to ENOMSG.
If IPC is not specified_ Nowait, the process will block until a message of the specified type is available, or the queue is deleted from the system (return − 1, error is set to EIDRM), or a signal is captured and returned from the signal handler (this will cause msgrcv to return − 1, error is set to EINTR).
When msgrcv executes successfully, the kernel updates the msgid associated with the message queue_ DS structure to indicate the caller's process ID (msg_lrpid) and call time (msg_rtime), and indicate that the number of messages in the queue has been reduced by 1 (msg_qnum).
Semaphore
XSI semaphores are not a single non negative value, but a collection of one or more semaphores. When creating a semaphore, you need to specify the number of semaphores in the set.
The kernel maintains a semid for each semaphore set_ DS structure:
struct semid_ds {
struct ipc_perm sem_perm; // Permission structure
unsigned short sem_nsems; // num of semaphores in set
time_t sem_otime; // last-semop() time
time_t sem_ctime; // last-change time
};
Each semaphore is represented by an unnamed structure and contains at least the following members:
struct {
unsigned short semval; // semaphore value, always >= 0
pid_t sempid; // pid for last operation
unsigned short semncnt; // num of processes awaiting semval > curval
unsigned short semzcnt; // num of processes awaiting semval == 0
};
A semaphore ID can be obtained through semget function:
#include <sys/sem.h> int semget(key_t key, int nsems, int flag); // The semaphore ID is returned successfully, and - 1 is returned in case of error
When creating a new collection, the kernel initializes semid in this way_ DS structure:
- icp_ The initialization of perm structure is similar to that of message queue.
- sem_otime is set to 0.
- sem_ctime is set to the current time.
- sem_nsems is set as the nsems parameter.
Semaphores also have a garbage can function semctl:
#include <sys/sem.h> int semctl(int semid, int semnum, int cmd, .../* union semun arg */); // The return value is shown below
The structure of union semun is as follows:
union semun {
int val; // for SETVAL
struct semid_ids* buf; // for IPC_STAT and ICP_SET
unsigned short* array; // for GETALL and SETALL
};
Possible values of cmd parameter:
- IPC_STAT: take semid for this set_ DS structure and stored by arg BUF points to the structure.
- IPC_SET: press arg The value in the structure pointed to by buf, and set the SEM in the structure related to this collection_ perm. uid,sem_perm.gid and sem_perm.mode field.
- IPC_RMID: delete the semaphore set from the system. This deletion occurs immediately. Other processes that are still using this semaphore set at the time of deletion will return an error to EIDRM the next time they try to operate on this semaphore set.
- GETVAL: returns the semval value of the member semnum.
- SETVAL: sets the semval value of the member semnum. This value is determined by arg Val specified.
- GETPID: returns the sempid value of the member semnum.
- GETNCNT: returns the semncnt value of the member semnum.
- GETZCNT: returns the semzcnt value of the member semnum.
- GETALL: take all semaphore values in the set. These values are stored in arg In the array pointed to by array.
- Set all: set all semaphore values in the set to arg The value in the array pointed to by array.
ICP_SET and ICP_RMID permission requirements and heartache in message queue
For all GET commands except GETALL, the semctl function returns the corresponding value. For other commands, if successful, the return value is 0. If there is an error, set errno and return − 1.
The function semop automatically performs an array of operations on the semaphore set:
#include <sys/sem.h> int semop(int semid, struct sembuf semoparray[], size_t nops); // Return value: 0 if successful; If there is an error, return − 1
The sembuf structure is as follows:
struct sembuf {
unsigned short sem_num; // Sequence number of semaphore in semaphore set, [0, nsems-1]
short sem_op; // operation(neg, 0, or pos)
short sem_flg; // ICP_NOWAIT, SEM_UNDO
};
-
If sem_op is a positive value. Semaphore value plus sem_op. If the undo flag is specified, it becomes minus sem_op.
-
If sem_op is negative. If semaphore value > = SEM_ The absolute value of OP, then the value of semaphore plus sem_op (adding a negative value is equivalent to decreasing). If the undo flag is specified, it becomes minus sem_op. If semaphore value < sem_op, then:
-
If IPC is specified_ Nowait, the semop error returns EAGAIN.
-
If IPC is not specified_ NOWAIT, the semncnt value of the semaphore is increased by 1, and the calling process is suspended until one of the following events occurs:
- This semaphore value becomes greater than or equal to SEM_ The absolute value of Op. Then, the semncnt value of the semaphore is subtracted by 1, and SEM is subtracted from the semaphore value_ The absolute value of Op. If the undo flag is specified, it becomes plus.
- This semaphore was removed from the system. In this case, the function returns EIDRM in case of error.
- The process captures a signal and returns it from the signal handler. In this case, the semncnt value of this semaphore is reduced by 1, and the function returns EINTR in case of error.
-
-
If sem_op is 0, which means that the calling process wants to wait until the semaphore value becomes 0.
- If the semaphore value is currently 0, this function returns immediately.
- If the semaphore value is not 0, then:
- If IPC is specified_ Nowait, an error occurs and EAGAIN is returned.
- If IPC is not specified_ NOWAIT, the semzcnt of the semaphore plus 1, and then the calling process is suspended until the following event occurs:
- This semaphore value becomes 0. The semzcnt value of this semaphore is minus 1.
- This semaphore was removed from the system. In this case, the function returns EIDRM in case of error.
- The process captures a signal and returns from the signal handler. In this case, the semzcnt value of this semaphore is reduced by 1, and the function returns EINTR in case of error.
The semop function is atomic. It either performs all the operations in the array or does none at all.
Shared storage
The difference between XSI shared storage and memory mapped files is that shared storage has no related files. XSI shared memory segments are anonymous segments of memory.
The kernel maintains a shmid for each shared memory segment_ DS structure:
struct shmid_ids {
struct ipc_perm shm_perm; /* Permission structure */
size_t shm_segsz; /* size of segment in bytes */
pid_t shm_lpid; /* pid of last shmop() */
pid_t shm_cpid; /* pid of creator */
shmatt_t shm_nattch; /* number of current attaches */
time_t shm_atime; /* last-attach time */
time_t shm_dtime; /* last-detach time */
time_t shm_ctime; /* last-change time */
};
You can get a shared storage identifier through the shmget function.
#include <sys/shm.h> int shmget(key_t key, size_t size, int flag); // The shared storage ID is returned successfully, and - 1 is returned in case of error
When creating a new shared storage segment, the kernel initializes shmid in this way_ DS structure:
- icp_ The initialization of perm structure is similar to that of message queue.
- shm_lpid,shm_nattach,shm_atime and shm_dtime is set to 0.
- sem_ctime is set to the current time.
- shm_ Set segsz to the size parameter.
Parameter size is the length of the shared storage segment, in bytes. The implementation usually takes it up as an integral multiple of the system page length. However, if the size value specified by the application is not an integral multiple of the system page length, the rest of the last page is not available.
If you are creating a new segment (usually in a server process), you must specify its size. If you are referencing an existing segment (a client process), specify size as 0. When a new segment is created, the content in the segment is initialized to 0.
Shared storage also has a trash can function shmctl:
#include <sys/shm.h> int shmctl(int shmid, int cmd, struct shmid_ds* buf); // 0 is returned for success and - 1 for error
Possible values for cmd parameter:
-
IPC_STAT: take the shmid of this segment_ DS structure and store it in the structure pointed by buf.
-
IPC_ The value in this storage segment is related to the setting of bushf in this storage segment_ The following three fields in DS structure: shm_perm.uid,shm_perm.gid and shm_perm.mode.
-
IPC_RMID: delete the shared storage segment from the system. Because each shared storage segment maintains a connection count (shm_nattch field in shmid_ds structure), the storage segment will not be actually deleted unless the last process using the segment terminates or separates from the segment. Whether this segment is still in use or not, the segment identifier will be deleted immediately, so shmat can no longer be connected to this segment.
-
SHM_LOCK: lock the shared storage segment in memory. This command can only be executed by the superuser.
-
SHM_UNLOCK: unlocks the shared storage segment. This command can only be executed by the superuser.
IPC_SET and ICP_ The permission requirements of rmid are the same as before.
The last two commands are not part of SUS. Linux and Solaris provide these two commands.
Once a shared storage segment is created, the process can call shmat to connect it to its address space.
#include <sys/shm.h> void* shmat(int shmid, const void* addr, int flag); // The pointer to the shared storage segment is returned successfully, and - 1 is returned in case of error
The address on which the shared memory segment is connected to the calling process is related to the addr parameter and whether SHM is specified in the flag_ Rnd bit related:
- If addr is 0, this segment is connected to the first available address selected by the kernel. This is the recommended way to use.
- If addr is not 0 and SHM is not specified_ Rnd, then this segment is connected to the address specified by addr.
- If addr is not 0 and SHM is specified_ Rnd, then this segment is connected to the address represented by (addr − (addr mod SHMLBA)). SHM_RND command means "rounding". SHMLBA means "low boundary address multiple", which is always a power of 2. This formula takes the address down to the multiple of the last SHMLBA.
If SHM is specified in flag_ Rdonly bit, connect this segment in read-only mode, otherwise connect this segment in read-write mode.
When the operation on the shared storage segment has ended, shmdt is called to separate from the segment. Note that this does not remove its identifier and its associated data structure from the system. The identifier remains until a process (typically a server process) has IPC_ The rmid command is called shmctl until it is specifically deleted.
#include <sys/shm.h> int shmdt(const void* addr); // 0 is returned for success and - 1 for error
If successful, shmdt will make the relevant shmid_ SHM in DS structure_ Nattch counter value minus 1.
POSIX semaphore
POSIX semaphores come in two forms: named and unnamed. The difference lies in the form of creation and destruction, but other work is the same.
-
Unnamed semaphores exist only in memory and require that processes that can use semaphores must have access to memory. This means that they can only be applied to threads in the same process, or threads in different processes that have mapped the same memory content to their address space.
-
Named semaphores can be accessed by name and can be used by threads in any process that knows their name.
We can call sem_open function to create a new named semaphore or use an existing semaphore.
#include <semaphore.h> sem_t* sem_open(const char* name, int oflag, ... /* mode_t mode, unsigned int value */ ); // The pointer pointing to the error returned by SEM_FAILED
When using an existing named semaphore, simply specify the semaphore name and set oflag to 0.
When oflag parameter has o_ When creating a flag set, if the named semaphore does not exist, a new one is created. If it already exists, it will be used, but no additional initialization will occur.
When we specify o_ When using the creat flag, two additional parameters need to be provided. The mode parameter specifies who can access the semaphore. The value of mode is the same as the permission bits for opening files: user read, user write, user execute, group read, group write, group execute, other read, other write and other execute. The permission assigned to the semaphore can be modified by the caller's file creation mask word.
When creating a semaphore, the value parameter is used to specify the initial value of the semaphore. Its value is 0 ~ SEM_VALUE_MAX.
If we want to ensure that the semaphore is created, we can set the oflag parameter to O_CREAT | O_EXCL. If the semaphore already exists, it will cause sem_open failed.
Semaphore naming specification:
- The first character of the name should be a slash (/).
- Names should not contain other slashes to avoid implementing defined behavior.
- The maximum length of a semaphore name is implementation defined. The name should not be longer than_ POSIX_NAME_MAX.
SEM can be called_ Close function to release semaphore related resources:
#include <semaphore.h> int sem_close(sem_t* sem); // 0 is returned for success and - 1 for error
If the process does not call SEM first_ Close and exit, the kernel will automatically close any open semaphores.
You can use sem_unlink function to destroy a named semaphore.
#include <semaphore.h> int sem_unlink(const char *name); // Return value: 0 if successful; If there is an error, return - 1
sem_ The unlink function deletes the name of the semaphore. If there is no open semaphore reference, the semaphore will be destroyed. Otherwise, destruction is delayed until the last open reference is closed.
You can use sem_wait or sem_trywait function to realize the minus 1 operation of semaphore (i.e. P operation).
#include <semaphore.h> int sem_trywait(sem_t* sem); int sem_wait(sem_t* sem); // 0 is returned for success and − 1 is returned for error
Using SEM_ When using the wait function, if the semaphore count is 0, it will be blocked. It does not return until the semaphore is successfully reduced by 1 or interrupted by the signal.
Call SEM_ During trywait, if the semaphore is 0, it will not block, but will return − 1 and set errno to EAGAIN.
You can also use SEM_ The timedwait function to specify the maximum wait time:
#include <semaphore.h> #include <time.h> int sem_timedwait(sem_t* restrict sem, const struct timespec* restrict tsptr); // Return value: 0 if successful; If there is an error, return − 1
If the timeout expires and the semaphore count fails to decrease by 1, sem_timedwait will return - 1 and set errno to ETIMEDOUT.
SEM can be called_ The post function increases the semaphore value by 1 (i.e. V operation):
#include <semaphore.h> int sem_post(sem_t* sem); // 0 is returned for success and − 1 is returned for error
Call SEM_ When post, if SEM is called_ If a process is blocked in wait (or sem_timedwait), the process will wake up and be blocked by SEM_ The semaphore count of post incremented by 1 will be checked by SEM again_ Wait (or sem_timedwait) minus 1.
SEM can be called_ Init function to create an unnamed semaphore.
#include <semaphore.h> int sem_init(sem_t* sem, int pshared, unsigned int value); // 0 is returned for success and − 1 is returned for error
The pshared parameter indicates whether semaphores are used in multiple processes. If yes, it needs to be set to a non-zero value.
The value parameter specifies the initial value of the semaphore.
SEM can be called_ The destroy function destroys unnamed semaphores:
#include <semaphore.h> int sem_destroy(sem_t* sem); // 0 is returned for success and − 1 is returned for error
You can use sem_getvalue function to retrieve semaphore value:
#include <semaphore.h> int sem_getvalue(sem_t *restrict sem, int *restrict valp); // 0 is returned for success and − 1 is returned for error
After the call is successful, the integer value pointed to by valp will contain the semaphore value.
But when we try to use the value we just read out, the value of the semaphore may have changed. Unless additional synchronization mechanisms are used to avoid this competition, SEM_ The getValue function can only be used for debugging.
Realize its own lock structure with semaphore:
// slock.h
#include <semaphore.h>
#include <fcntl.h>
#include <limits.h>
#include <sys/stat.h>
struct slock {
sem_t* semp;
char name[_POSIX_NAME_MAX];
};
struct slock* s_alloc();
void s_free(struct slock*);
int s_lock(struct slock*);
int s_trylock(struct slock*);
int s_unlock(struct slock*);
#include "slock.h"
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
struct slock* s_alloc() {
struct slock* sp;
static int cnt;
if ((sp = malloc(sizeof(struct slock))) == NULL) {
return NULL;
}
do {
snprintf(sp->name, sizeof(sp->name), "/%ld.%d", (long)getpid(), cnt++);
sp->semp = sem_open(sp->name, O_CREAT | O_EXCL, S_IRWXU, 1);
} while ((sp->semp == SEM_FAILED) && (errno == EEXIST));
if (sp->semp == SEM_FAILED) {
free(sp);
return NULL;
}
sem_unlink(sp->name);
return sp;
}
void s_free(struct slock* sp) {
sem_close(sp->semp);
free(sp);
}
int s_lock(struct slock* sp) {
return sem_wait(sp->semp);
}
int s_trylock(struct slock* sp) {
return sem_trywait(sp->semp);
}
int s_unlock(struct slock* sp) {
return sem_post(sp->semp);
}
Network IPC: socket
socket descriptor
Socket descriptor is regarded as a file descriptor in UNIX system. Many functions that handle file descriptors, such as read and write, can be used to handle socket descriptors.
You can use the socket function to create a socket:
#include <sys/socket.h> int socket(int domain, int type, int protocol); // The socket descriptor is returned successfully, and - 1 is returned in case of error
The optional values of domain include:
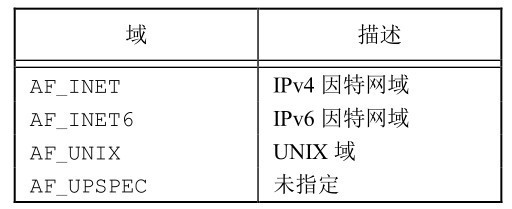
AF stands for address family
The parameter type determines the type of socket and has the following optional values:

Possible values of the parameter protocol are:

The parameter protocol is usually 0, indicating that the default protocol is selected for a given domain and socket type. When multiple protocols are supported for the same domain and socket type, you can use protocol to select a specific protocol.
Datagram (SOCK_DGRAM) provides connectionless service.
Byte stream (SOCK_STREAM) provides byte stream service (connected), and the application cannot distinguish the boundary of the message. From sock_ When a stream socket reads data, it may not return all the bytes written by the sending process. To get all the data sent, you may need to make multiple function calls.
SOCK_ The default protocol of Dgram is UDP and sock_ The default protocol of stream is TCP.
SOCK_SEQPACKET socket and SOCK_STREAM socket is very similar, except that what we get from this socket is a message based service rather than a byte stream service. That is, from sock_ Seq the amount of data received by the packet socket is consistent with that sent by the other party.
SOCK_RAW socket provides a datagram interface for direct access to the following network layer (i.e. IP layer in Internet domain). When using this interface, the application is responsible for constructing its own protocol header because transport protocols such as TCP and UDP are bypassed.
Super user privileges are required when creating a raw socket.
Common I/O functions support socket descriptors:
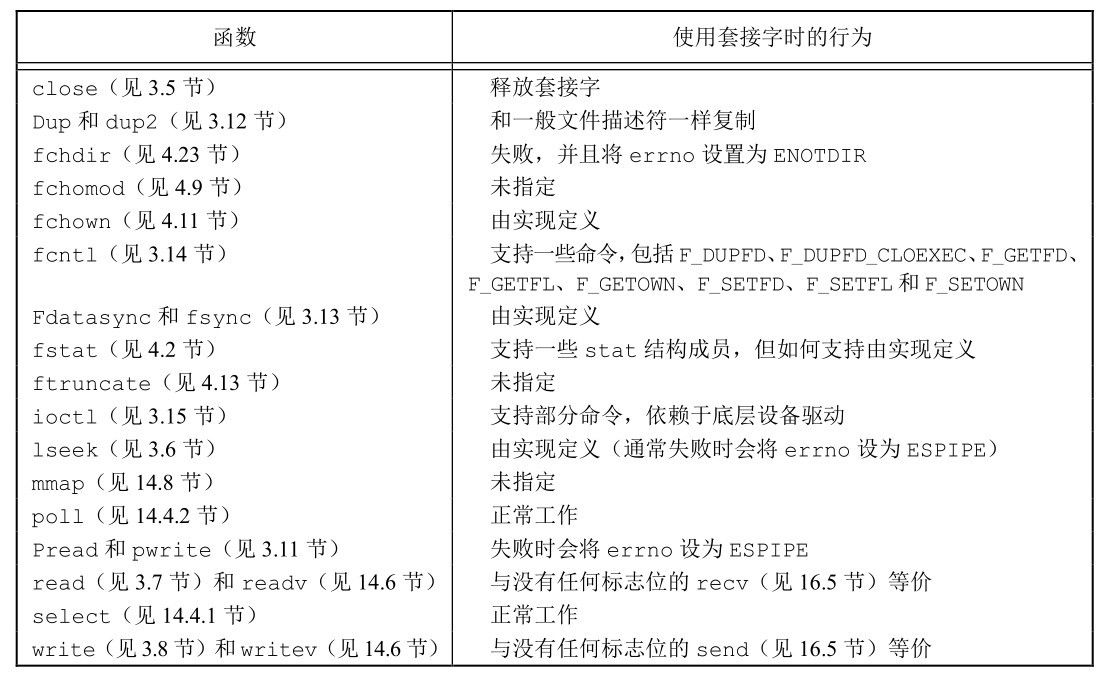
Socket communication is bidirectional. The shutdown function can be used to disable I/O to a socket.
#include <sys/socket.h> int shutdown(int sockfd, int how); // 0 is returned for success and − 1 is returned for error
- If how is SHUT_RD (close the reader), then data cannot be read from the socket.
- If how is SHUT_WR (close the write side), then the socket cannot be used to send data.
- If how is SHUT_RDWR, you can neither read data nor send data.
addressing
Byte order
Big endian byte order: the byte address of the most significant byte is the lowest.
Small end byte order: the byte address of the least significant byte is the lowest.
TCP/IP protocol stack uses big endian byte order.
4 functions used to convert between processor byte order and network byte order:
#include <arpa/inet.h> uint32_t htonl(uint32_t hostint32); // Returns a 32-bit integer in network byte order uint16_t htons(uint16_t hostint16); // Returns a 16 bit integer in network byte order uint32_t ntohl(uint32_t netint32); // Returns a 32-bit integer in host byte order uint16_t ntohs(uint16_t netint16); // Returns a 16 bit integer in host byte order
h stands for host, n for network, l for long, s for short.
Address format
An address identifies the socket endpoint of a specific communication domain.
In order to enable addresses in different formats to be passed into socket functions, the address will be forcibly converted into a general address structure sockaddr:
struct sockaddr {
sa_family_t sa_family; // address family: AF_INET, AF_INET6, ...
char sa_data[]; // variable-length address
};
Socket implementations are free to add additional members and define SAS_ The size of the data member.
The Internet address is defined in < netinet / in h> In the header file. Socket address structure SOCKADDR in IPv4_ In means:
struct in_addr {
in_addr_t s_addr; // IPv4 address
};
struct sockaddr_in {
sa_family_t sin_family; // address family
in_port_t sin_port; // port number
struct in_addr sin_addr;// IPv4 address
};
The structure SOCKADDR is used in IPv6_ In6 means:
struct in6_addr {
uint8_t s6_addr[16]; // IPv6 address
};
struct sockaddr_in6 {
sa_family_t sin6_family; // address family
in_port_t sin6_port; // port number
uint32_t sin_flowinfo; // traffic class and flow info
struct in6_addr sin6_addr; // IPv6 address
uint32_t sin6_scope_id; // set of interfaces for scope
};
These are the definitions of SUS, and more fields can be added freely for specific implementation.
Although sockaddr_in and sockaddr_in6 structures are quite different, but they are all forced into sockaddr structures and input into socket routines.
Conversion between socket binary address format and dotted decimal character representation:
#include <arpa/inet.h> const char *inet_ntop(int domain, const void *restrict addr, char *restrict str, socklen_t size); // The address string pointer is returned successfully, and NULL is returned in case of error int inet_pton(int domain, const char *restrict str, void *restrict addr); // 1 is returned for success, 0 is returned for invalid format, and - 1 is returned for error
- inet_ntop converts the binary address of network byte order into text string format.
- inet_pton converts the text string format into a binary address in network byte order.
The parameter domain supports only two values: AF_INET and AF_INET6.
The parameter size is usually INET_ADDRSTRLEN to store a text string representing IPv4 address; Take INET6_ADDRSTRLEN to store a text string representing IPv6 address.
Address query
You can call the gethostent function to find the host information of a given computer system:
#include <netdb.h> struct hostent *gethostent(void); // Pointer returned successfully, NULL returned in case of error void sethostent(int stayopen); void endhostent(void);
If the host database file is not open, gethostent will open it. The function gethostent returns the next entry in the file.
The sethost function opens the file and wraps it around if it has already been opened. When the stayopen parameter is set to a non-zero value, the file will remain open after calling gethost.
I don't quite understand what winding means.
The endhost function closes the file.
When gethostent returns, you will get a pointer to the hostent structure, which may contain a static data buffer. Each time gethostent is called, the buffer will be overwritten.
The struct host structure contains at least the following members:
struct hostent {
char *h_name; // name of host
char **h_aliases; // pointer to alternate host name array
int h_addrtype; // address type
int h_length; // length in bytes of address
char **h_addr_list; // pointer to array of network addresses
}
The returned addresses are in network byte order. The address type (h_addrtype) is AF_INET series constants.
You can use the following functions to get the network name and network number:
#include <netdb.h> struct netent *getnetbyaddr(uint32_t net, int type); struct netent *getnetbyname(const char *name); struct netent *getnetent(void); // Pointer returned successfully, NULL returned in case of error void setnetent(int stayopen); void endnetent(void);
The structure of netent contains at least the following fields:
struct netent {
char *n_name; // network name
char **n_aliases; // alternate network name array pointer
int n_addrtype; // address type
uint32_t n_net; // network number
};
The network number is returned in network byte order. The address type is one of the address family constants (such as AF_INET).
You can use the following functions to map between the protocol name and the protocol number:
#include <netdb.h> struct protoent *getprotobyname(const char *name); struct protoent *getprotobynumber(int proto); struct protoent *getprotoent(void); // Pointer returned successfully, NULL returned in case of error void setprotoent(int stayopen); void endprotoent(void);
The protoent structure contains at least the following members:
struct protoent {
char *p_name; // protocol name
char **p_aliases; // pointer to alternate protocol name array
int p_proto; // protocol number
};
The service is represented by the port number part of the address. Each service is supported by a unique well-known port number. You can use the function getservbyname to map a service name to a port number, use the function getservbyport to map a port number to a service name, and use the function getserve to scan the service database sequentially.
#include <netdb.h> struct servent *getservbyname(const char *name, const char *proto); struct servent *getserbyport(int port, const char *proto); struct servent *getservent(void); // Pointer returned successfully, NULL returned in case of error void setservent(int stayopen); void endservent(void);
The service structure contains at least the following members:
struct servent{
char *s_name; /* service name */
char **s_aliases; /* pointer to alternate service name array */
int s_port; /* port number */
char *s_proto; /* name of protocol */
};
You can use the getaddrinfo function to map a host name and a service name to an address:
#include <sys/socket.h> #include <netdb.h> int getaddrinfo(const char *restrict host, const char *restrict sevice, const struct addrinfo *restrict hint, struct addrinfo **restrict res); // 0 is returned for success and non-0 error code is returned for error void freeaddrinfo(struct addrinfo *ai);
The getaddrinfo function returns a linked list structure addrinfo.
The addrinfo structure contains at least the following members:
struct addrinfo {
int ai_flags; // customize behavior
int ai_family; // address family
int ai_socktype; // socket type
int ai_protocol; // protocol
socklen_t ai_addrlen; // length in bytes of address
struct sockaddr *ai_addr; // address
char *ai_cannoname; // canonical name of host
struct addrinfo *ai_next; // next in list
};
freeaddrinfo can release one or more of these structures, depending on using AI_ How many structures are linked by the next field.
hint is a template for filtering addresses, including ai_family,ai_flags,ai_protocol and ai_socktype field. The remaining integer field must be set to 0 and the pointer field must be empty.
The optional values are flags:

If getaddrinfo fails, you need to use Gai_ The strError function converts the returned error code into an error message:
#include <netdb.h> const char *gai_strerror(int error); // Returns a pointer to a string describing the error
The getnameinfo function converts an address into a host name and a service name:
#include <sys/socket.h> #include <netdb.h> int getnameinfo(const struct sockaddr *restrict addr, socklen_t alen, char *restrict host, socklen_t hostlen, char *restrict service, socklen_t servlen, int flags); // 0 is returned successfully, and a non-0 value is returned in case of error
The socket address (addr) is translated into a host name and a service name.
If the host is not empty, it points to a buffer with a length of hostlen bytes to store the returned host name.
If the service is not empty, it points to a buffer with a length of servlen bytes to store the returned hostname.
The optional values of flags parameter are as follows:

A sample program:
#include "apue.h"
#if defined(SOLARIS)
#include <netinet/in.h>
#endif
#include <netdb.h>
#include <arpa/inet.h>
#if defined(BSD)
#include <sys/socket.h>
#include <netinet/in.h>
#endif
void print_family(struct addrinfo* aip) {
printf(" family ");
switch (aip->ai_family) {
case AF_INET:
printf("inet");
break;
case AF_INET6:
printf("inet6");
break;
case AF_UNIX:
printf("unix");
break;
case AF_UNSPEC:
printf("unspecified");
break;
default:
printf("unknown");
}
}
void print_type(struct addrinfo* aip) {
printf(" type ");
switch (aip->ai_socktype) {
case SOCK_STREAM:
printf("stream");
break;
case SOCK_DGRAM:
printf("datagram");
break;
case SOCK_SEQPACKET:
printf("seqpacket");
break;
case SOCK_RAW:
printf("raw");
break;
default:
printf("unknown (%d)", aip->ai_socktype);
}
}
void print_protocol(struct addrinfo* aip) {
printf(" protocol ");
switch (aip->ai_protocol) {
case 0:
printf("default");
break;
case IPPROTO_TCP:
printf("TCP");
break;
case IPPROTO_UDP:
printf("UDP");
break;
case IPPROTO_RAW:
printf("raw");
break;
default:
printf("unknow (%d)", aip->ai_protocol);
}
}
void print_flags(struct addrinfo* aip) {
printf("flags");
if (aip->ai_flags == 0) {
printf(" 0");
} else {
if (aip->ai_flags & AI_PASSIVE) {
printf(" passive");
}
if (aip->ai_flags & AI_CANONNAME) {
printf(" canon");
}
if (aip->ai_flags & AI_NUMERICHOST) {
printf(" numhost");
}
if (aip->ai_flags & AI_NUMERICSERV) {
printf(" numserv");
}
if (aip->ai_flags & AI_V4MAPPED) {
printf(" v4mapped");
}
if (aip->ai_flags & AI_ALL) {
printf(" all");
}
}
}
int main(int argc, char* argv[]) {
struct addrinfo *ailist, *aip;
struct addrinfo hint;
struct sockaddr_in *sinp;
const char *addr;
int err;
char abuf[INET_ADDRSTRLEN];
if (argc != 3) {
err_quit("usage: %s <nodename> <service>", argv[0]);
}
hint.ai_flags = AI_CANONNAME;
hint.ai_family = 0;
hint.ai_socktype = 0;
hint.ai_protocol = 0;
hint.ai_addrlen = 0;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(argv[1], argv[2], &hint, &ailist)) != 0) {
err_quit("getaddrinfo error: %s", gai_strerror(err));
}
for (aip = ailist; aip != NULL; aip = aip->ai_next) {
print_flags(aip);
print_family(aip);
print_protocol(aip);
printf("\n\thost %s", aip->ai_canonname ? aip->ai_canonname : "-");
if (aip->ai_family == AF_INET) {
sinp = (struct sockaddr_in*)aip->ai_addr;
addr = inet_ntop(AF_INET, &sinp->sin_addr, abuf, INET_ADDRSTRLEN);
printf(" address %s", addr ? addr : "unknown");
printf(" port %d", ntohs(sinp->sin_port));
}
printf("\n");
}
exit(0);
}
Associate socket with address
Use the bind function to associate the address with the socket:
#include <sys/socket.h> int bind(int sockfd, const struct sockaddr *addr, socklen_t len); // 0 is returned for success and - 1 for error
If the address is not bound to the socket when you call connect or listen, the system will select an address to bind to the socket.
You can call the getsockname function to get the address bound to the socket:
#include <sys/socket.h> int getsockname(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict alenp); // 0 is returned for success and - 1 for error
Before calling getsockname, alenp points to an integer to specify the length of the buffer sockaddr. When returned, the integer will be set to the size of the return address. If the address does not match the length of the buffer provided, the address will be automatically truncated without error. If no address is currently bound to the socket, the result is undefined.
If the socket is already connected to the peer, you can call the getpeername function to find the address of the peer.
#include <sys/socket.h> int getpeername(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict alenp); // 0 is returned for success and - 1 for error
Establish connection
When processing a connection oriented network service (SOCK_STREAM or SOCK_SEQPACKET), a connection needs to be established between the process socket (client) requesting the service and the process socket (server) providing the service.
Use the connect function to establish a connection:
#include <sys/socket.h> int connect(int sockfd, const struct sockaddr *addr, socklen_t len); // 0 is returned for success and - 1 for error
The addr parameter specifies the address of the server with which we want to communicate.
If sockfd is not bound to an address at this time, connect will bind a default address to the caller.
The connect function can also be used for connectionless network services (SOCK_DGRAM). If sock is used_ When the Dgram socket calls connect, the destination address of the transmitted message will be set to the address specified in the connect call, so there is no need to provide the address each time the message is transmitted. And can only receive messages from the specified address.
The server calls the listen function to announce that it is willing to accept the connection request:
#include <sys/socket.h> int listen(int sockfd, int backlog); // 0 is returned for success and - 1 for error
The backlog parameter specifies the number of outstanding connection requests to be queued by the process. When the queue is full, the system will reject redundant connection requests.
After calling listen, the socket can receive the connection request. You can use the accept function to obtain the connection request and establish the connection.
#include <sys/socket.h> int accept(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict len); // The file (socket) descriptor is returned successfully, and − 1 is returned in case of error
The returned file descriptor is the socket descriptor, which is connected to the client calling connect. This new socket descriptor has the same socket type and address family as the original socket (sockfd). The original socket passed to accept is not associated with this connection, but remains available and receives other connection requests.
When returning, accept will set addr as the address of the client and update the integer pointing to len to reflect the size of the address. If you don't care about these two parameters, you can set them to NULL.
If no connection request is waiting, accept will block until a request arrives. If sockfd is in non blocking mode, accept returns − 1 and sets errno to EAGAIN or EWOULDBLOCK.
data transmission
There are three functions for sending data.
#include <sys/socket.h> ssize_t send(int sockfd, const void *buf, size_t nbytes, int flags); // The number of bytes sent is returned successfully, and - 1 is returned in case of error
When using send, the socket must be connected.
The buf and nbytes parameters are the same as those in the write function.
The optional values of flags parameter are as follows:
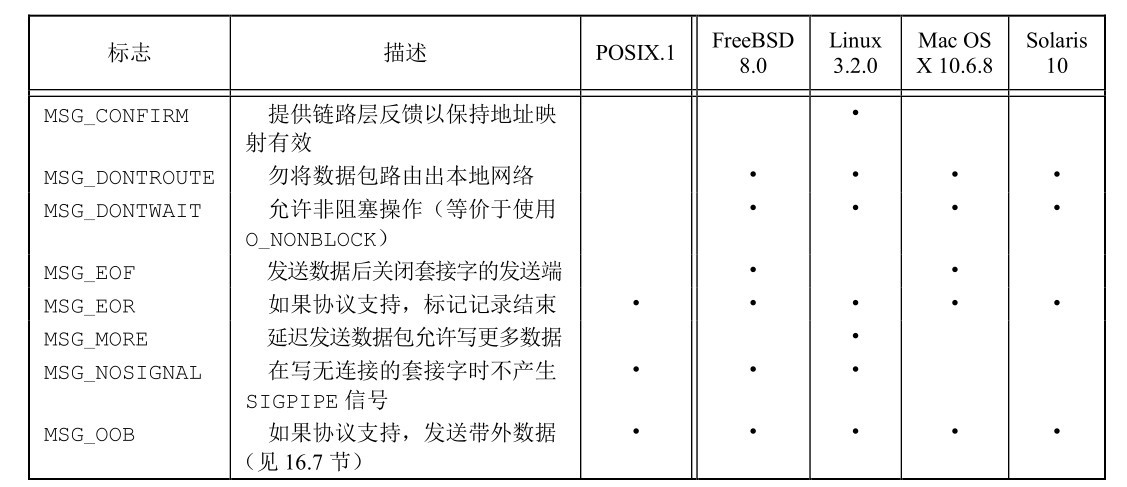
Even if send returns successfully, it does not mean that the process at the other end of the connection must have received data. All we can guarantee is that when send returns successfully, the data has been sent to the network driver without error.
For protocols that support message boundaries, if the length of a single message trying to send exceeds the maximum length supported by the protocol, send will fail and set errno to EMSGSIZE. For byte stream protocol, send will block until the whole data transmission is completed.
sendto can specify a destination address based on send (for connectionless sockets):
#include <sys/socket.h> ssize_t sendto(int sockfd, const void *buf, size_t nbytes, int flags, const struct sockaddr *destaddr, socklen_t destlen); // The number of bytes sent is returned successfully, and - 1 is returned in case of error
For connection oriented sockets, the destination address is ignored.
The sendmsg function is similar to the writev function:
#include <sys/socket.h> ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags); // The number of bytes sent is returned successfully, and - 1 is returned in case of error
The structure of msghdr is as follows:
struct msghdr {
void *msg_name; // optional address
socklen_t msg_namelen; // address size in bytes
struct iovec *msg_iov; // array of I/O buffers
int msg_iovlen; // number of elements in array
void *msg_control; // Auxiliary data
socklen_t msg_controllen; // number of ancillary data
int msg_flags;
};
There are three functions that accept data:
The recv function is similar to the read function:
#include <sys/socket.h> ssize_t recv(int sockfd, void *buf, size_t nbytes, int flags); // The byte length of the returned data. If there is no available data or the peer has ended in order, it will return 0, and if there is an error, it will return - 1
The optional values of flags parameter are:
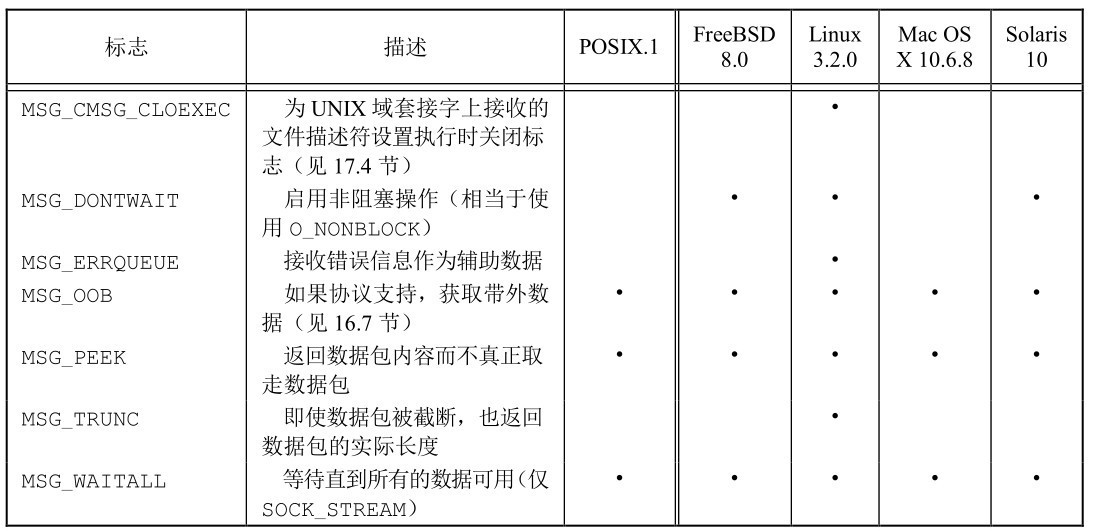
When MSG is specified_ When the peek flag is, you can view the next data to be read, but you don't really take it away. When read or one of the recv functions is called again, the data just viewed will be returned.
For SOCK_STREAM sockets can receive less data than expected. MSG_ The waitall flag prevents this behavior and the recv function does not return until all the requested data is returned. For SOCK_DGRAM and SOCK_SEQPACKET socket, MSG_ The waitall flag does not change any behavior because these message based socket types return the entire message in one read.
If the sender has called shutdown to end the transmission, or the network protocol supports shutdown in the default order and the sender has been shut down, recv returns 0 when all data is received.
You can use the recvfrom function to get the source address of the data sender:
#include <sys/socket.h> ssize_t recv(int sockfd, void *buf, size_t nbytes, int flags, struct sockaddr *restrict addr, socklen_t *restrict addrlen); // The byte length of the returned data. If there is no available data or the peer has ended in order, it will return 0, and if there is an error, it will return - 1
The recvmsg function is similar to the readv function:
#include <sys/socket.h> ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags); // The byte length of the returned data. If there is no available data or the peer has ended in order, it will return 0, and if there is an error, it will return - 1
Socket options
You can use the setsockopt function to set socket options.
#include <sys/socket.h> int setsockopt(int sockfd, int option, const void *val, socklen_t len); // 0 is returned for success and - 1 for error
The parameter level identifies the protocol to which the option applies. If the option is a general socket hierarchy option, set the level to SOL_SOCKET. Otherwise, level is set to the protocol number that controls this option. For the TCP option, level is IPPROTO_TCP, for IP, the level is IPPROTO_IP.
The optional values of the option parameter are as follows:
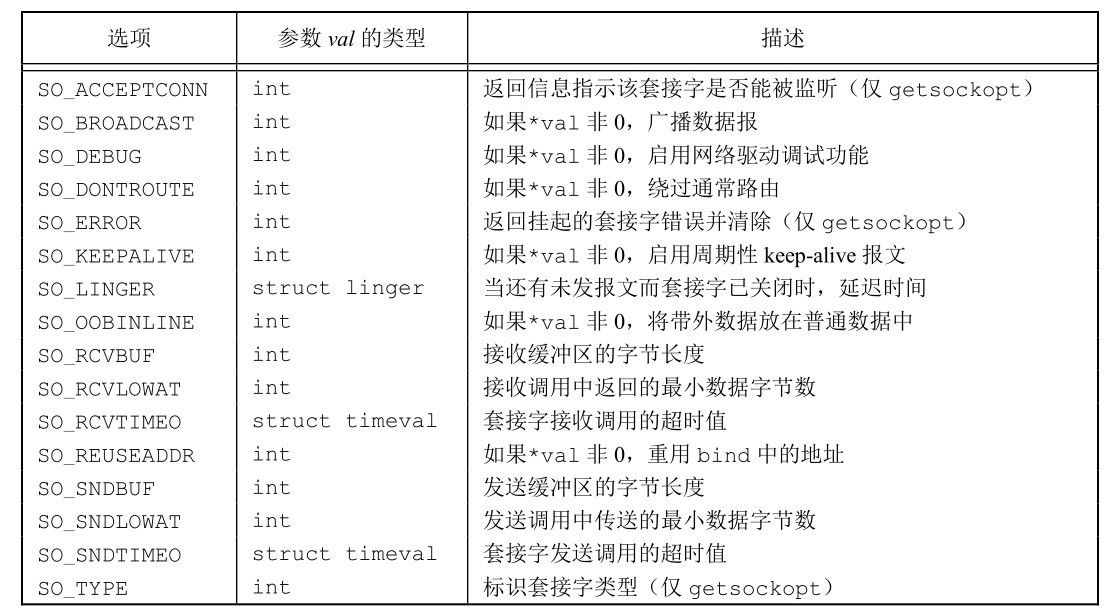
The parameter Val points to a data structure or an integer according to different options. Some options are on/off switches. If the integer is not 0, the option is enabled. If the integer is 0, the option is disabled. The len parameter specifies the size of the object pointed to by val.
You can use the getsockopt function to get the current value of the option:
#include <sys/socket.h> int getsockopt(int sockfd, int level, int option, void *restrict val, socklen_t *restric lenp); // 0 is returned for success and - 1 for error
The parameter lenp is a pointer to an integer. Before calling getsockopt, set this integer to the length of the copy option buffer. If the actual length of the option is greater than this value, the option is truncated. If the actual length is exactly less than this value, this value will be updated to the actual length on return.
Out of band data
Out of band data is an optional function supported by some communication protocols. Compared with ordinary data, it allows higher priority data transmission. Out of band data is transmitted first, even if there is data in the transmission queue.
TCP supports out of band data, but UDP does not.
TCP calls out of band data urgent data. TCP only supports one byte of emergency data, but allows emergency data to be transmitted outside the data stream of ordinary data transmission mechanism.
In order to generate emergency data, you can specify MSG in any of the three send functions_ OOB flag. If with MSG_ When the number of bytes sent by OOB flag exceeds one, the last byte will be regarded as emergency data byte.
If the signal generation is arranged through the socket, the SIGURG signal will be sent when the emergency data is received.
You can schedule a process to receive a signal from a socket by calling the following function:
fcntl(sockfd, F_SETOWN, pid);
TCP supports the concept of emergency mark, that is, the location of emergency data in ordinary data stream. If socket option is used_ Oobinline, emergency data can be received in normal data.
You can use the sockatmark function to determine whether the emergency flag has been reached:
#include <sys/socket.h> int sockatmark(int sockfd); // Return value: if it is at the mark, return 1; If it is not at the mark, return 0; If there is an error, return − 1
When the next byte to be read is at the emergency flag, sockatmark returns 1.
Non blocking and asynchronous I/O
In socket based asynchronous I/O, there are two steps to start asynchronous I/O:
- Establish socket ownership so that signals can be passed to the appropriate process.
- Notifies the socket to signal when I/O operations are not blocked.
There are three ways to complete the first step.
- Use f in fcntl_ Setown command.
- Use the FIOSETOWN command in ioctl.
- Use the SIOCSPGRP command in ioctl.
There are 2 ways to complete the second step.
- Use f in fcntl_ Setfl command and enable file flag O_ASYNC.
- Use the FIOASYNC command in ioctl.
Advanced interprocess communication
This chapter tends to practice, so much of the content in the book is not recorded in the notes. I still have some difficulties in mastering these codes at present 😭.
UNIX domain socket
UNIX domain sockets are used for communication between processes running on the same computer. Although Internet domain sockets can be used for the same purpose, UNIX domain sockets are more efficient.
UNIX domain socket provides two interfaces: stream and datagram. The UNIX domain datagram service is reliable and will neither lose messages nor deliver errors.
You can use the socketpair function to create a pair of unnamed, interconnected UNIX domain sockets:
#include <sys/socket.h> int socketpair(int domain, int type, int protocol, int sockfd[2]); // 0 is returned for success and - 1 for error
A pair of interconnected UNIX domain sockets can act as a full duplex pipeline: both ends are open to read and write.
Naming UNIX domain sockets
The address of the UNIX domain socket is determined by sockaddr_un structure representation.
The format of the structure is related to the specific implementation. Among them, Linux 3 2.0 is expressed as:
struct sockaddr_un {
sa_family_t sun_family; // AF_UNIX
char sun_path[108]; // pathname
};
sockaddr_ Sun with UN structure_ The path member contains a path name. When we bind an address to a UNIX domain socket, the system creates an s with the pathname_ File of type ifsock.
Using this address and the bind function, we can create a named UNIX domain socket.
This file is only used to notify the client process of the socket name. The file cannot be opened or used by the application for communication.
If the file already exists when we try to bind to the same address, the bind request will fail. When the socket is closed, the file is not automatically deleted, so you must ensure that the file is unlinked before the application exits.
Use example:
#include "apue.h"
#include <sys/socket.h>
#include <sys/un.h>
int main() {
int fd, size;
struct sockaddr_un un;
un.sun_family = AF_UNIX;
strcpy(un.sun_path, "foo.socket");
if ((fd = socket(AF_UNIX, SOCK_STREAM, 0)) < 0) {
err_sys("socket failed");
}
size = offsetof(struct sockaddr_un, sun_path) + strlen(un.sun_path);
// offsetof is a macro:
// #define offsetof(TYPE, MEMBER) ((int)&((TYPE *)0)->MEMBER)
if (bind(fd, (struct sockaddr*)&un, size) < 0) {
err_sys("bind failed");
}
printf("UNIX domain socket bound\n");
exit(0);
}
getopt
You can use the getopt function to handle command-line options.
I've seen an article written well before Blog , can be referred to together.
#include <unistd.h> int getopt(int argc, char *const argv[], const char *options); // If all options are processed, return - 1, otherwise return the next option character extern int optind, opterr, optopt; extern char *optarg;
The parameters argc and argv are the same as those passed into the main function.
The options parameter is a string containing the characters of the options supported by the command. If an option character is followed by a colon, it indicates that the option requires parameters; Otherwise, no additional parameters are required for this option.
When an invalid option is encountered, getopt returns a problem flag (which should refer to the character?) instead of this character. If the option is missing parameters, getopt will also return a problem flag, but if the first character of the option string is a colon, getopt will return a colon directly.
The special "–" format will cause getopt to stop processing options and return - 1. This allows the user to pass parameters that start with "-" but are not options.
For example, if there is a file named "- bar", the following command line cannot delete the file:
rm –bar
Because rm will try to interpret - bar as an option. The correct command to delete a file should be:
rm -- -bar
The getopt function supports the following four external variables.
-
Optarg: if an option requires parameters, getopt will set optarg to point to the parameter string of the option when processing the option.
-
Opter: if an error occurs in an option, getopt will print an error message by default. Applications can disable this behavior by setting the opter parameter to 0.
-
optind: used to store the subscript of the next string to be processed in the argv array. It starts with 1. getopt increments each parameter by 1.
-
Optopt: if an error occurs when processing options, getopt will set optopt to point to the option string causing the error.
Some sample programs intercepted:
while ((c = getopt(argc, argv, "d")) != EOF) {
switch (c) {
case "d":
debug = 1;
break;
case '?':
err_quit("unrecognized option -%c", optopt);
}
}
For some more detailed examples, please refer to what I just shared Blog.