Server side programming often needs to construct high-performance IO models. Common IO models include:
- Blocking IO
Traditional IO model - Synchronous non blocking IO
All sockets created by default are blocked. Non blocking IO requires that the socket be set to NONBLOCK - IO multiplexing
The classic Reactor design pattern is sometimes called asynchronous blocking IO. Selector in Java and epoll in Linux are both such models - Asynchronous IO
The classic Proactor design pattern, also known as asynchronous non blocking IO
1, Synchronous blocking IO
In order to process the connection and requested data of the client, the server writes the following code
listenfd = socket(); // Open a network communication port
bind(listenfd); // binding
listen(listenfd); // monitor
while(1) {
connfd = accept(listenfd); // Blocking connection establishment
int n = read(connfd, buf); // Blocking read data
doSomeThing(buf); // What do you do with the data you read
close(connfd); // Close the connection and cycle until the next connection
}
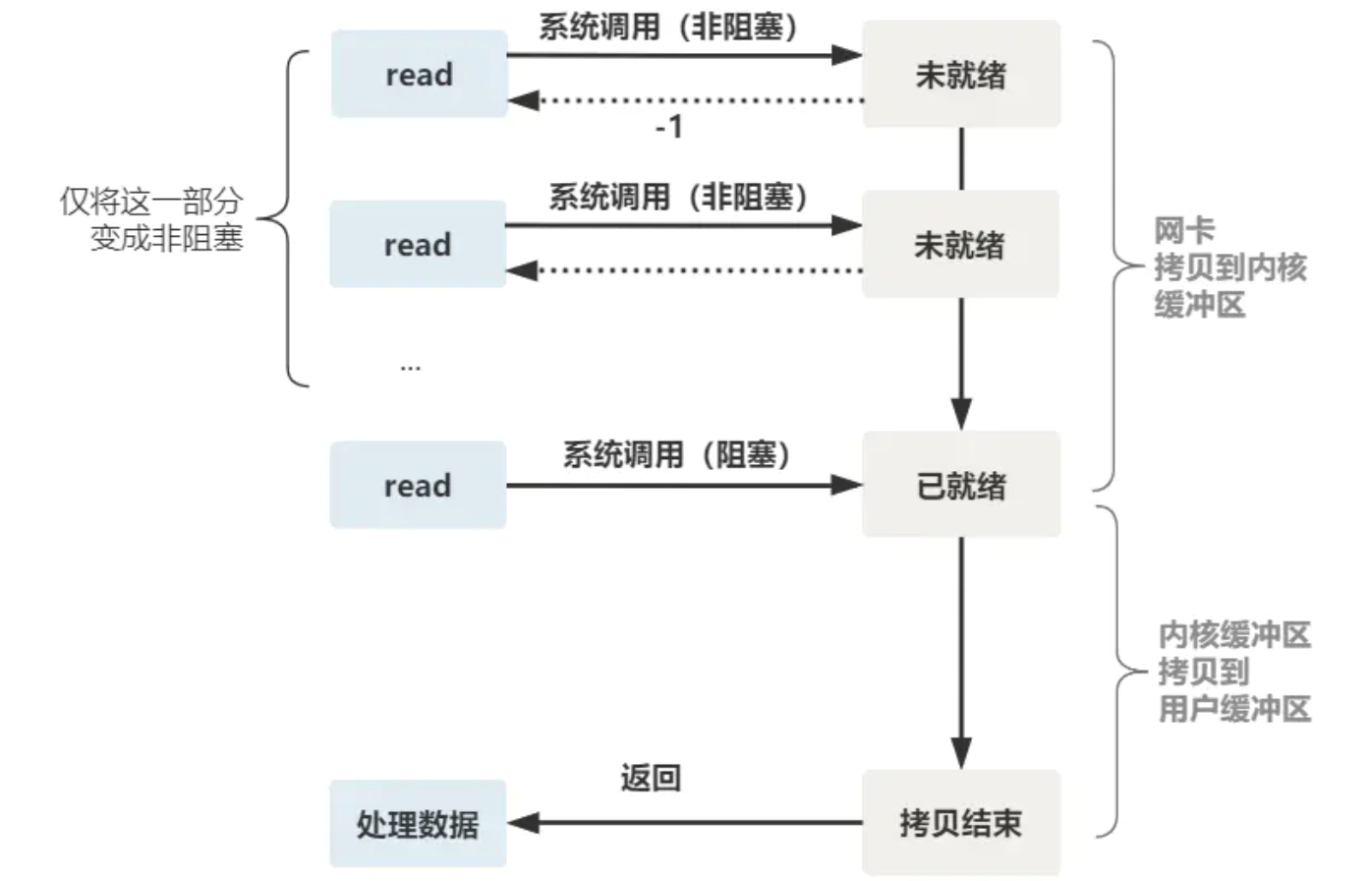
In this code, the thread of the server is blocked in two places, one is the accept function and the other is the read function
If you expand the details of the read function, it is found that it is blocked in two stages
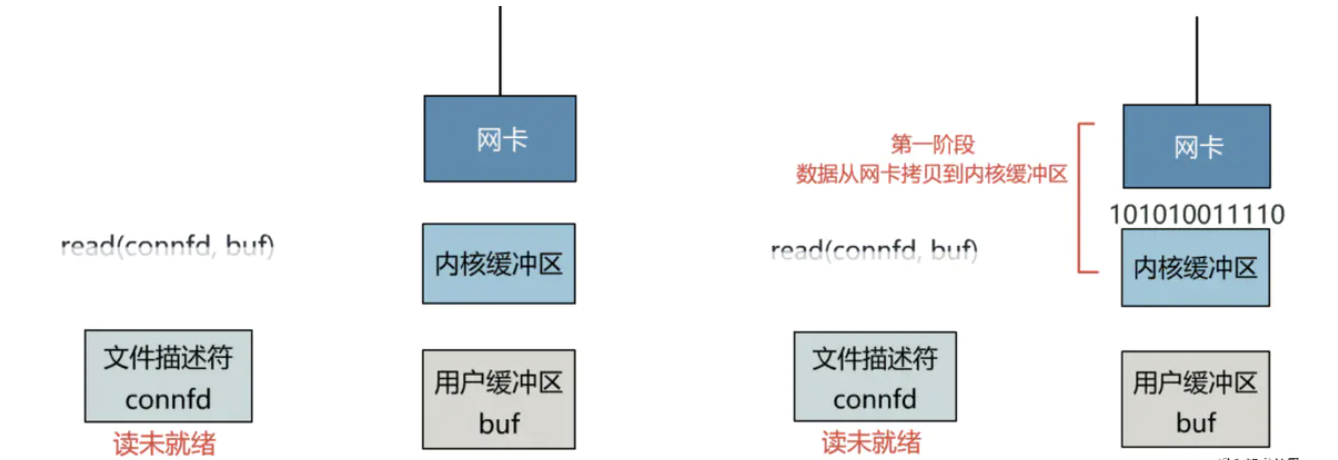
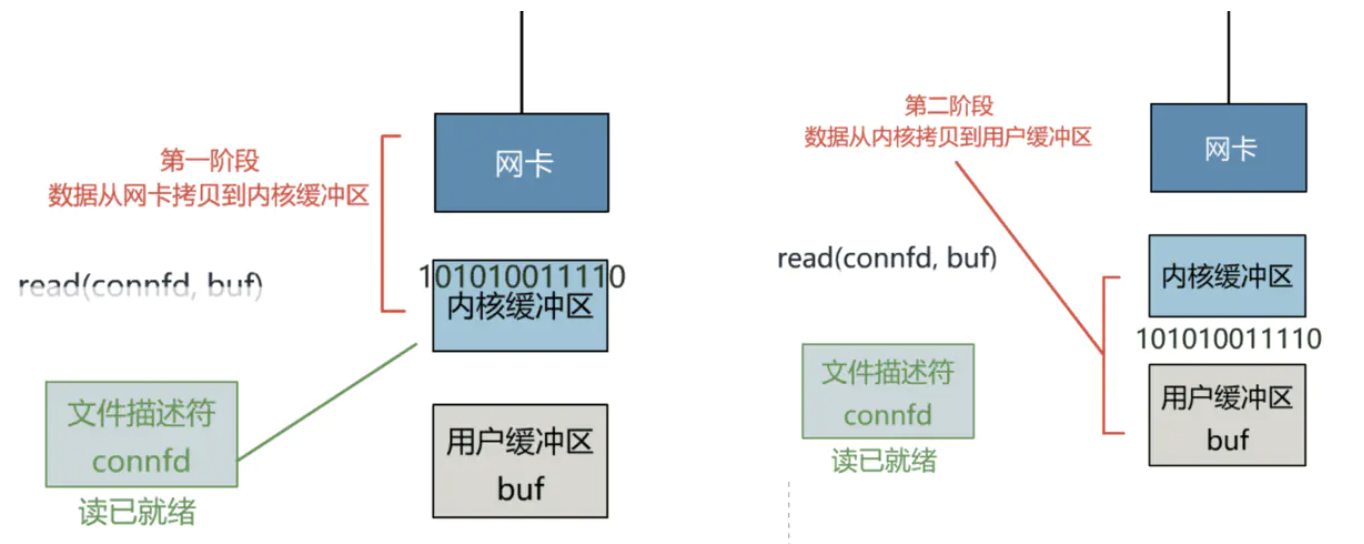
- Copy the data from the kernel card to the buffer of the client
- The kernel buffer sets the associated file descriptor to be readable, and copies the data in the kernel buffer to the user buffer
The overall process is as follows:
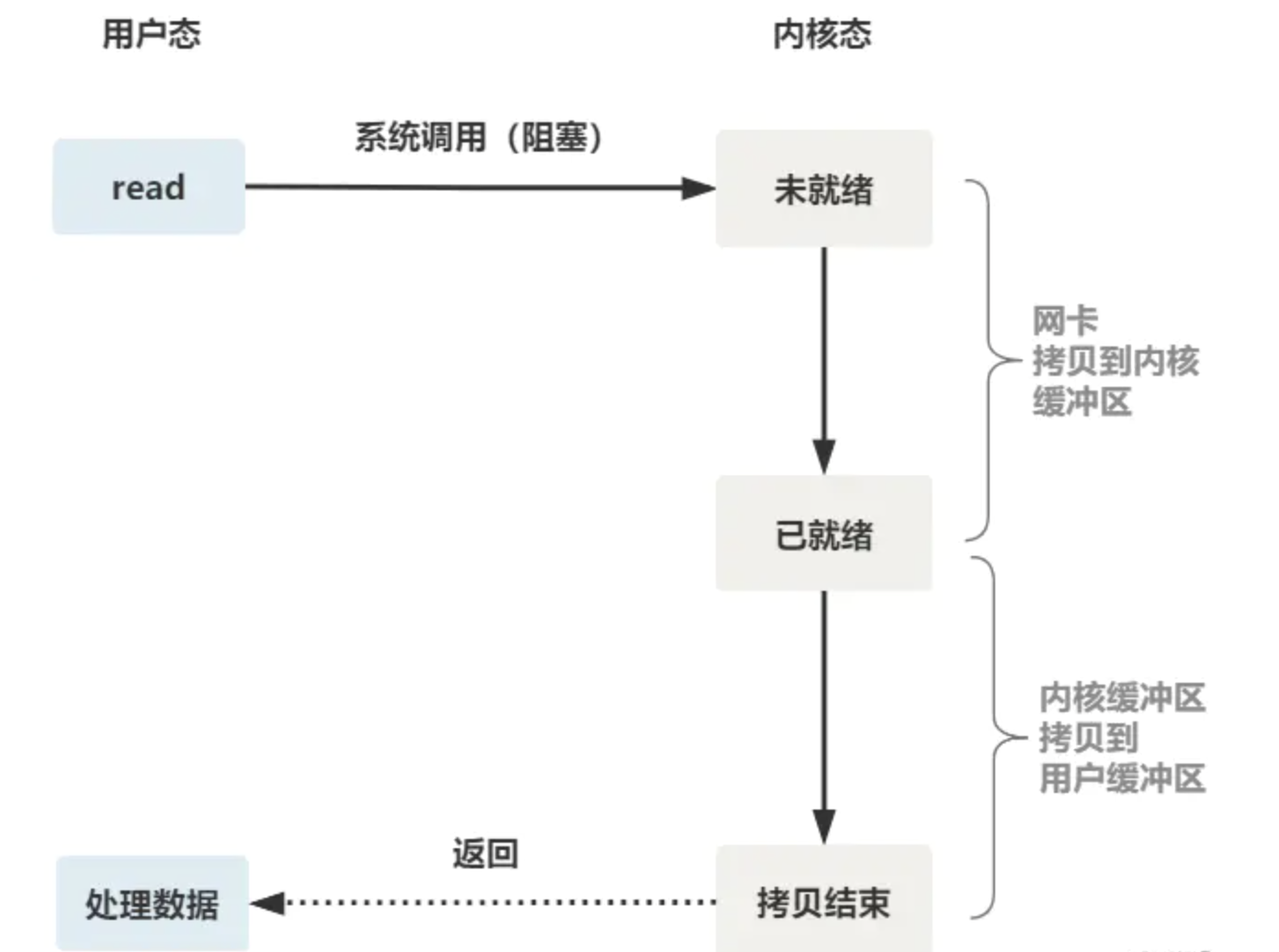
Therefore, if the client of this connection does not send data all the time, the server thread will be blocked all the time, will not return on the read function, and will not be able to accept other client connections
2, Non blocking IO
In order to solve the above problems, the key is to transform the read function
One way is to create a new process or thread every time, call the read function and do business processing
while(1) {
connfd = accept(listenfd); // Blocking connection establishment
pthread_create(doWork); // Create a new thread
}
void doWork() {
int n = read(connfd, buf); // Blocking read data
doSomeThing(buf); // What do you do with the data you read
close(connfd); // Close the connection and cycle until the next connection
}
In this way, when a connection is established for a client, you can immediately wait for a new client connection without blocking the read request of the original client
However, this is not called non blocking IO. It just uses multithreading to make the main thread not stuck in the read function and does not process down. The read function provided by the operating system is still blocked
Therefore, the real non blocking IO cannot be processed only through the user layer, but the operating system should provide a non blocking read function
The effect of this read function is that if no data arrives (reaches the network card and copies it to the kernel buffer), it immediately returns an error value (- 1), rather than waiting in a blocking way
The operating system provides such a function. You only need to set the file descriptor to non blocking before calling read
fcntl(connfd, F_SETFL, O_NONBLOCK); int n = read(connfd, buffer) != SUCCESS);
In this way, the user thread needs to call read circularly until the return value is not - 1, and then start processing the business
Two issues are noted here:
- Non blocking read refers to the non blocking stage before the data arrives, that is, before the data reaches the network card or reaches the network card but has not been copied to the kernel buffer
When the data has reached the kernel buffer, calling the read function is still blocked. You need to wait for the data to be copied from the kernel buffer to the user buffer before returning - Create a thread for each client, and the thread resources on the server side are easily consumed
The overall process is as follows:
3, IO multiplexing
Of course, there is another way. After each client connection is accept ed, put the file descriptor (connfd) into an array, and then get a new thread to continuously traverse the array and call the non blocking read method of each element
fdlist.add(connfd);
while(1) {
for(fd <-- fdlist) {
if(read(fd) != -1) {
doSomeThing();
}
}
}
However, this is the same as using multith read ing to transform blocking IO into non blocking io. This traversal method is just a small trick devised by the user. Each time the traversal returns - 1, it is still a system call that wastes resources
Making system calls in a while loop is just as uneconomical as making rpc requests in a while loop for distributed projects
Therefore, it is still necessary for the operating system to provide a function with such an effect, and pass a batch of file descriptors to the kernel through a system call, which can be traversed by the kernel layer to really solve this problem
- select
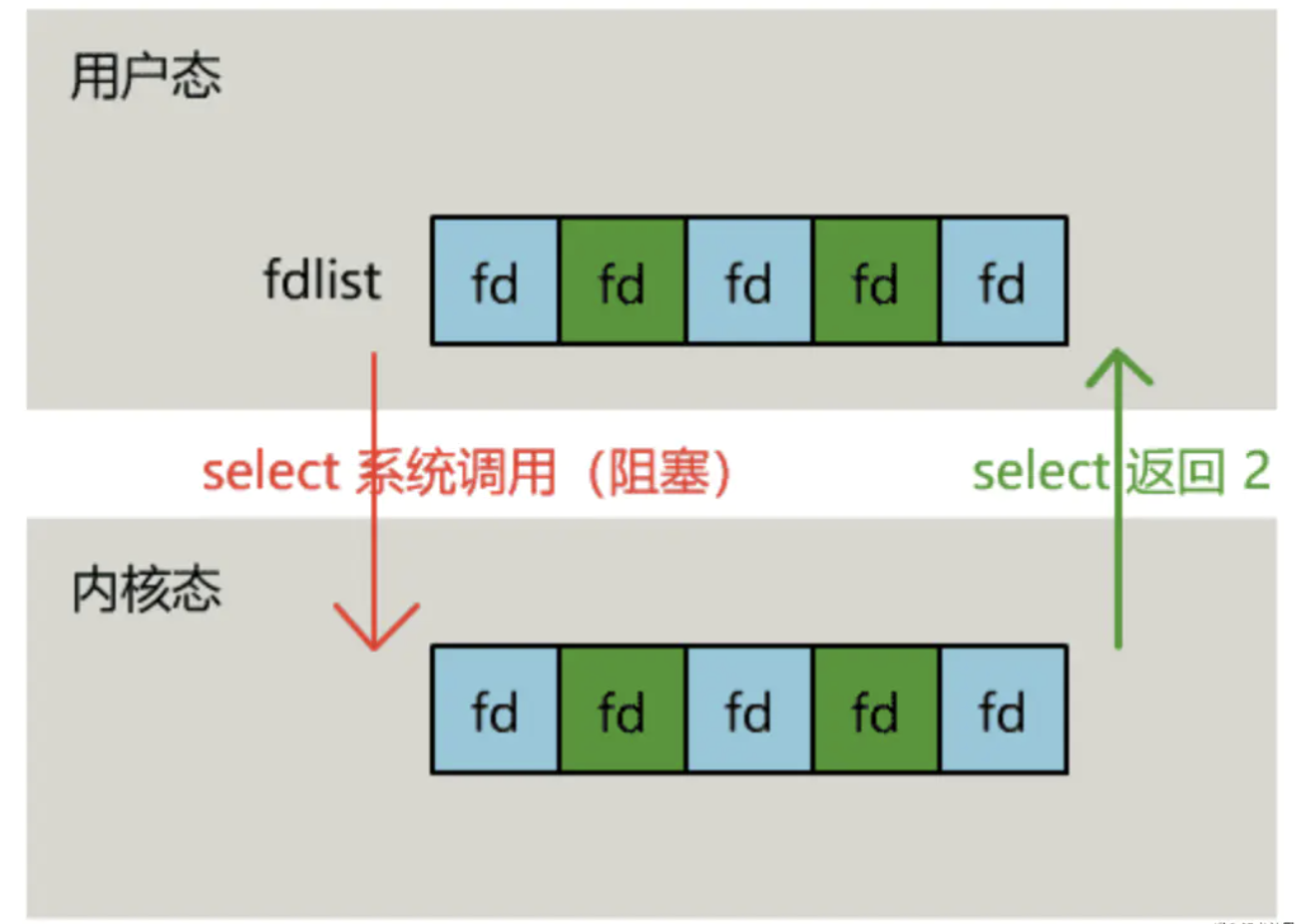
select is a system call function provided by the operating system. Through it, an array of file descriptors can be sent to the operating system, which can be traversed by the operating system to determine which file descriptor can be read and written, and then processed:
The functions called by the select system are defined as follows:
int select(
int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
// nfds: add 1 to the maximum file descriptor in the monitored file descriptor set
// readfds: monitors whether the read data reaches the file descriptor set and passes in and out parameters
// writefds: monitors whether the write data reaches the file descriptor set and passes in and out parameters
// exceptfds: monitor the file descriptor set when an exception occurs, and pass in and out parameters
// timeout: timed blocking monitoring time, 3 cases
// 1.NULL, wait forever
// 2. Set timeval and wait for a fixed time
// 3. Set the time in timeval to 0, and return immediately after checking the description word and polling
First, a thread continuously accepts client connections and puts the socket file descriptor into a list
while(1) {
connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
fdlist.add(connfd);
}
Then, instead of traversing by itself, another thread calls select and gives the batch of file descriptor list s to the operating system for traversal
while(1) {
// Pass a list of file descriptors to the select function
// If there are ready file descriptors, it will be returned, and nready indicates how many are ready
nready = select(list);
...
}
However, when the select function returns, the user still needs to traverse the list just submitted to the operating system
However, the operating system will identify the ready file descriptor, and the user layer will no longer have meaningless system call overhead
while(1) {
nready = select(list);
// The user layer still needs to traverse, but there are a lot of invalid system calls
for(fd <-- fdlist) {
if(fd != -1) {
// Read only ready file descriptor
read(fd, buf);
// There are only nready ready descriptors in total, so there is no need to traverse too much
if(--nready == 0) break;
}
}
}
Several details can be seen:
- The select call needs to pass in the fd array and copy a copy to the kernel. In high concurrency scenarios, the resource consumption of such a copy is amazing (it can be optimized not to copy)
- In the kernel layer, select still checks the ready status of file descriptors through traversal. It is a synchronous process, but there is no overhead of system call switching context (the kernel layer can be optimized for asynchronous event notification)
- select only returns the number of readable file descriptors. The specific readable file must be traversed by the user (it can be optimized to return only the user ready file descriptors without invalid traversal)
The flow chart of the whole select is as follows:
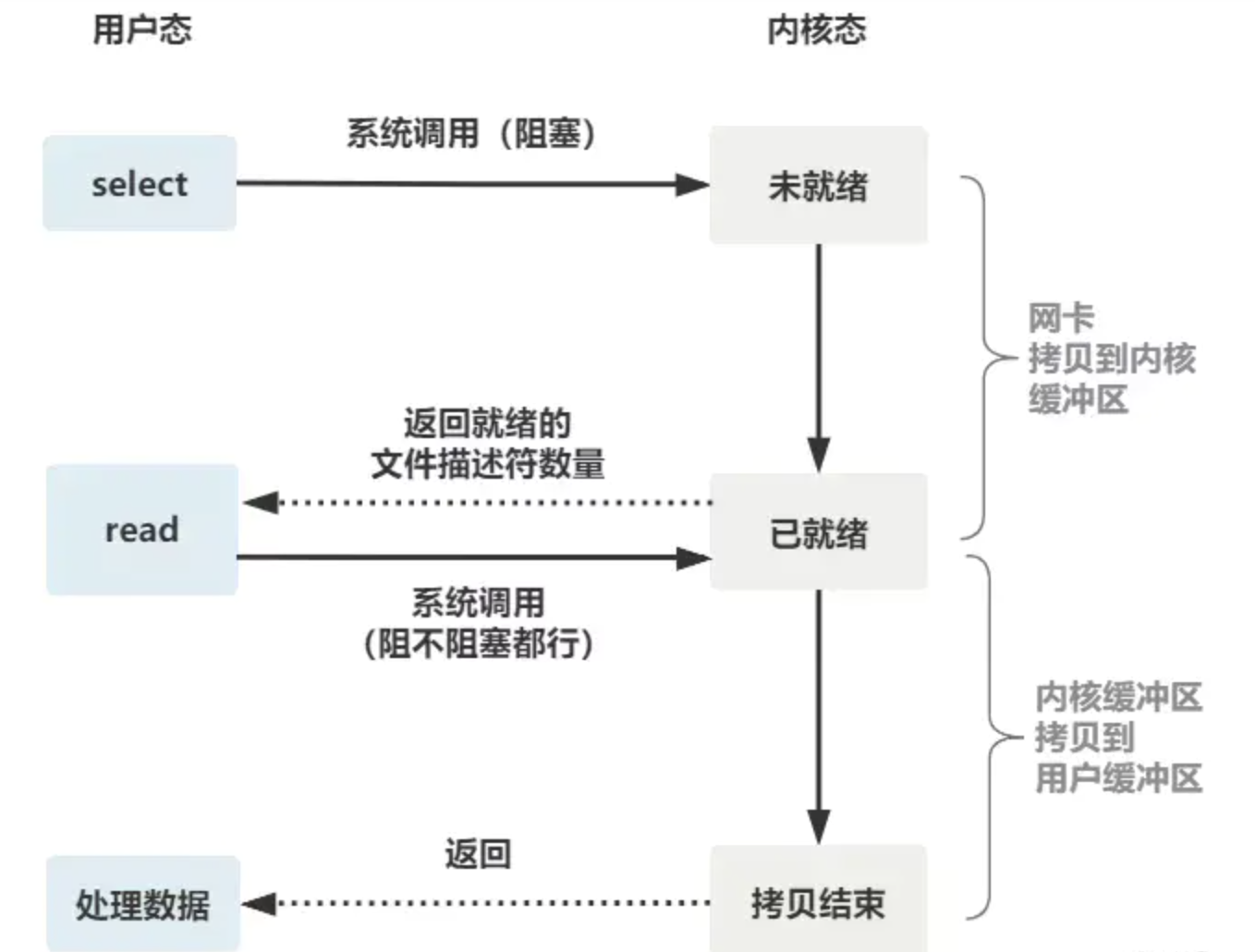
It can be seen that this method not only enables one thread to process multiple client connections (file descriptors), but also reduces the overhead of system calls (multiple file descriptors have only one select system call + n ready file descriptor read system calls)
- poll
poll is also a system call function provided by the operating system
int poll(struct pollfd *fds, nfds_tnfds, int timeout);
struct pollfd {
intfd; /*File descriptor*/
shortevents; /*Monitored events*/
shortrevents; /*Monitor the events returned if the conditions are met*/
};
The main difference between it and select is that it removes the restriction that select can only listen to 1024 file descriptors
- epoll
Remember the three details of select above?
-
The select call needs to pass in the fd array and copy a copy to the kernel. In high concurrency scenarios, the resource consumption of such a copy is amazing (it can be optimized not to copy)
-
In the kernel layer, select still checks the ready status of file descriptors through traversal. It is a synchronous process, but there is no overhead of system call switching context (the kernel layer can be optimized for asynchronous event notification)
-
select only returns the number of readable file descriptors. The specific readable file must be traversed by the user (it can be optimized to return only the user ready file descriptors without invalid traversal)
Therefore, epoll mainly improves on these three points. -
A set of file descriptors is saved in the kernel. You don't need to re-enter it every time. You just need to tell the kernel what to modify
-
The kernel no longer finds the ready file descriptor by polling, but wakes up by asynchronous IO events
-
The kernel will only return the file descriptors with IO events to the user, and the user does not need to traverse the whole set of file descriptors
Specifically, the operating system provides these three functions
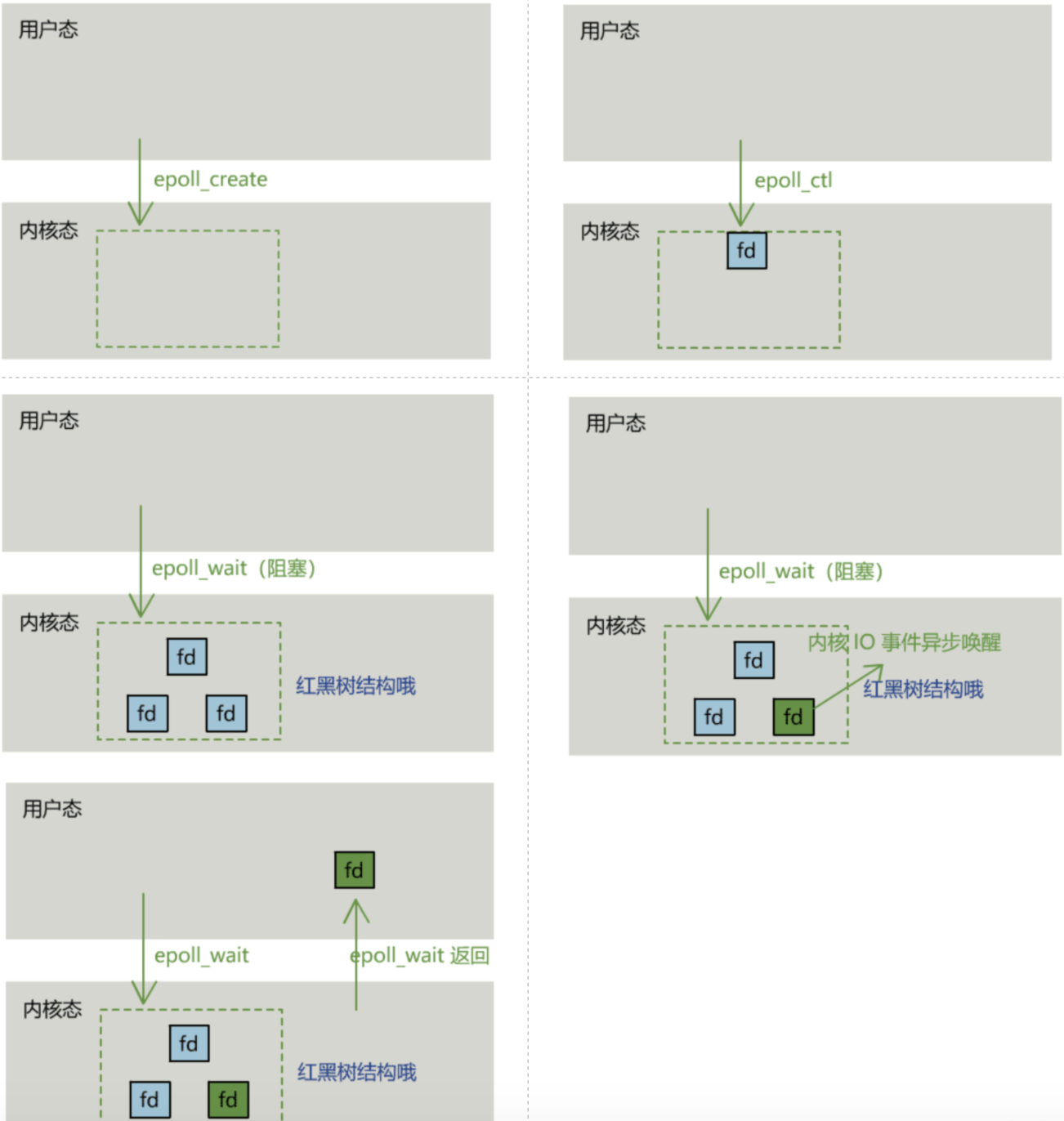
The first step is to create an epoll handle
int epoll_create(int size);
The second step is to add, modify or delete the file descriptor to be monitored to the kernel
int epoll_ctl( int epfd, int op, int fd, struct epoll_event *event);
In the third step, a select() call is similarly initiated
int epoll_wait( int epfd, struct epoll_event *events, int max events, int timeout);
The specific process is as follows: