ASR (speech recognition) journey from scratch
1, Introduction to speech recognition
Speech recognition technology, also known as Automatic Speech Recognition (ASR), aims to convert the vocabulary content in human speech into computer-readable input, such as keys, binary codes or character sequences. Unlike speaker recognition and speaker confirmation, the latter attempts to recognize or confirm the speaker who utters the voice rather than the lexical content contained therein.
It is divided into two parts
- Automatically convert human text content into corresponding voice
- Automatically convert human voice content into corresponding text
2, Actual code demonstration of converting text content into speech
There are three methods: using pyttsx3 package and win32com The client's own Dispatch package and SpeedLib package.
1. Using pyttsx3 to convert text into speech
a. Install pyttsx3 package
pip install pyttsx3 -i https://pypi.tuna.tsinghua.edu.cn/simple/
Note: it's best to use Anaconda3 to create a new environment. After installing the package, run it on pycharm.
b. Convert string to speech
# 01demo uses pyttsx to convert text into speech
import pyttsx3 as pyttsx #Change the name to pyttsx. It's useless. It's easy to remember when you ask
speaker=pyttsx.init() #Initialize a pyttsx object
speaker.say('Hello World,Hello world') #Run the say function
speaker.runAndWait() #Run and wait for say end. It will not run without this
If the running result cannot be cut, it will not be cut.
c. Convert text content to speech
# 01demo uses pyttsx to convert text into speech
import pyttsx3 as pyttsx #Change the name to pyttsx. It's useless. It's easy to remember when you ask
speaker=pyttsx.init() #Initialize a pyttsx object
with open('in.txt','r',encoding='utf-8') as f: #Open in TXT text
for line in f:
speaker.say(line)
speaker.runAndWait() #Run and wait for say end
2. Use win32com The client's own Dispatch package realizes the function of converting text into voice
Note: one advantage of using this method is that it can run directly without downloading additional packages
a. Convert string to speech
# 02demo uses Dispatch to convert text into speech
from win32com.client import Dispatch #Load Dispatch package
speaker=Dispatch('SAPI.SpVoice') # Generate a Dispatch object
speaker.Speak('Hello World,Hello world') #Bala said a word
del speaker #Delete Dispatch object
Note 1: the effect of converting text into speech in pyttsx3 is a little better than the SAPI of the built-in Dispatch.
Note 2: the code for converting text into speech is basically the same
3. Use SpeedLib to realize the function of converting text into voice file
#demo3 uses SpeechLib to input from text and convert it to speech
#1, Create speaker and stream objects
from comtypes.client import CreateObject
speaker=CreateObject("SAPI.SpVoice")
stream=CreateObject('SAPI.SpFileStream')
#2, Get input / output file address
from comtypes.gen import SpeechLib
infile='in.txt' #input file
outfile='out_audio.wav' #Output voice
# 3, Connect the speaker voice output stream to the outfile
stream.Open(outfile,SpeechLib.SSFMCreateForWrite)#Bind the stream to the file where the output outfile address is located
speaker.AudioOutputStream=stream #Connect the pipeline stream to the speaker's voice output
# So the speaker can output out_ audio. It's in the wav file
#4, Get infile file content
f=open(infile,'r',encoding='utf-8')
theText=f.read() #All the contents of the infile file are saved in theText
f.close()
#5, Use SAPI method to output text content, which will be output to outfile
speaker.speak(theText) #speaker starts to output. Before line 11, it is the default output to the standard output stream, that is to say
#Now after modifying the pipe flow, it becomes output to out_audio.wav
#6, Release resources
stream.close()
del speaker
3, Convert human voice content into corresponding text
PocketSphinx is an open source API for voice to text conversion It is a lightweight speech recognition engine. It can also work well on mobile phones and mobile devices
1. Using PocketSphinx to convert English speech into text
a. Installing the PocketSpinx package
pip install PocketSphinx -i https://pypi.tuna.tsinghua.edu.cn/simple/
Of course, the following errors are often encountered during installation:
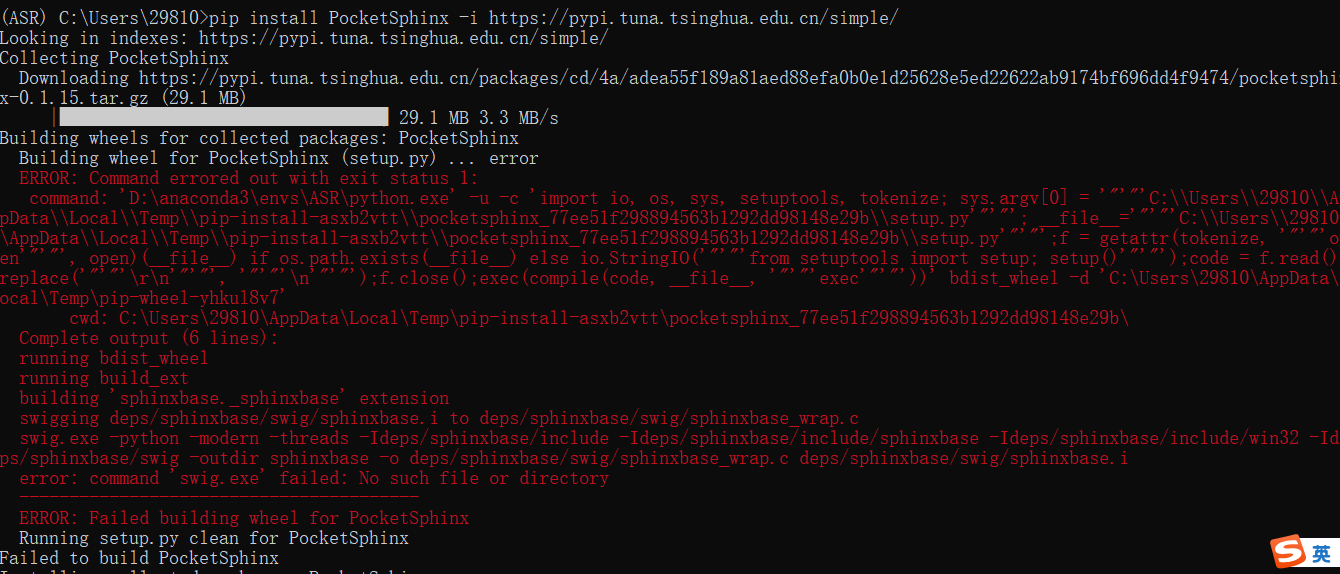
If an error is reported, the following two methods can be used:
-
Reference scheme a: from the following website https://www.lfd.uci.edu/~gohlke/pythonlibs/#pocketsphinx, download the offline package. My python is 3.8, 64 bit, so I'll download the pocketsphinx ‑ 0.1.15 ‑ cp38 ‑ cp38 ‑ win_amd64.whl. After downloading, use the command pip install pocketsphinx ‑ 0.1.15 ‑ cp38 ‑ cp38 ‑ win_amd64.whl complete installation
-
Refer to scheme b: the latest swig compressed package 4.0.2 downloaded from the official website. The official website address is: http://www.swig.org/download.html.
Unzip the downloaded files to the root directory of drive C.
Then, add a new path to the file in the environment variable. Finally, execute PIP install pocketsphinx - I again https://pypi.tuna.tsinghua.edu.cn/simple/
b. Install the SpeechRecognition package
pip install SpeechRecognition -i https://pypi.tuna.tsinghua.edu.cn/simple/
c. Program for converting English speech into text
#1, Initialize a speed_recognition object
import speech_recognition as sr
r=sr.Recognizer()
#2, Open the voice file and save it in audio after encoding
audio_file='out_audio1.wav'
with sr.AudioFile(audio_file) as source:
audio=r.record(source)
#Three. Convert speech to text
print('Text content:',r.recognize_sphinx(audio))
Note: due to recognize_sphinx's default language model is English, so if there is Chinese, it is easy to produce garbled code that is not garbled.
2. Using pocket Sphinx to convert Chinese voice into text
a. Download Mandarin package
https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/
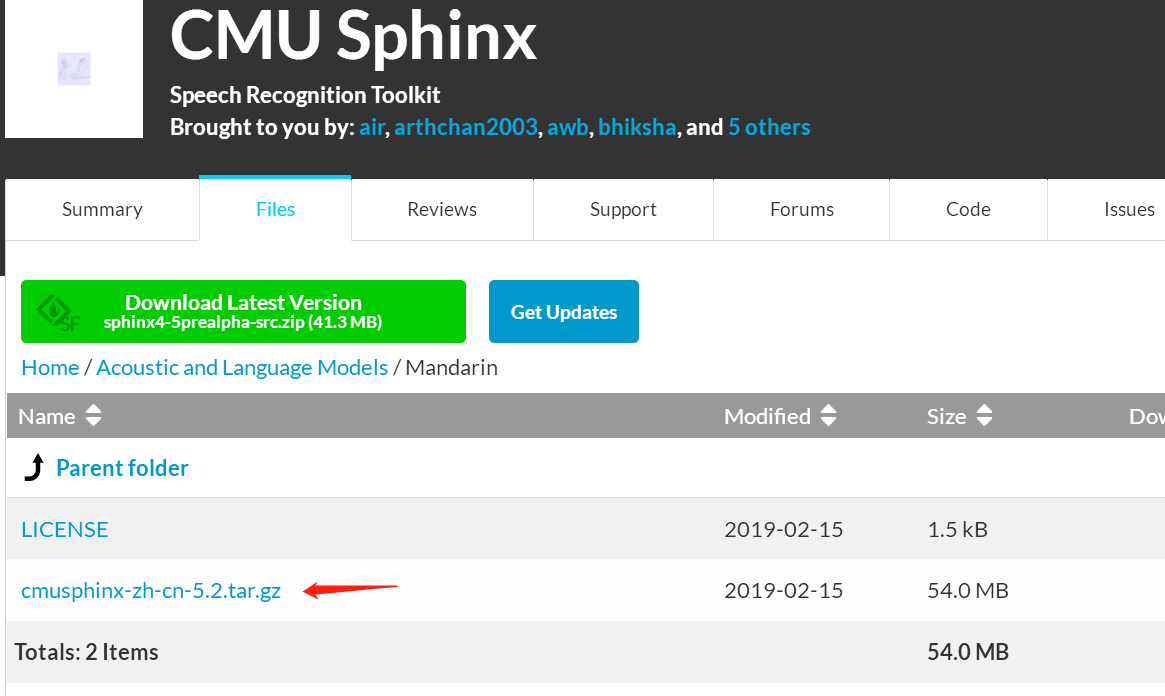
b. Put the package in the right place

This is where I put it
c. Modify the cmusphinx-zh-cn-5.2 package name to Ze CN, and modify the file name in the folder
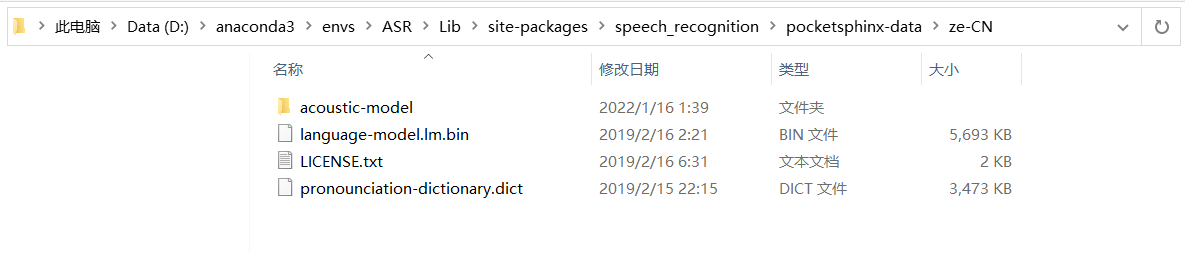
Refer to the name reference. If you are worried about typos, you can copy the corresponding name of the corresponding file in the en-US folder next door
d. Using pocket Sphinx to convert Chinese voice into text
# 04 use PocketSphinx to convert voice into text py
#1, Initialize a speed_recognition object
import speech_recognition as sr
r=sr.Recognizer()
#2, Open the voice file and save it in audio after encoding
audio_file='out_audio1.wav'
with sr.AudioFile(audio_file) as source:
audio=r.record(source)
#3, Convert speech to text
print('Text content:',r.recognize_sphinx(audio,language='ze-CN'))
Note 1: the only difference from the previous program is to modify recognize_ The default language parameter in Sphinx function is the Mandarin package just downloaded
Note 2: English cannot be converted to text
Note 3: Here I use pocket Sphinx as an example. Of course, you can use the latest Vosk library to realize the same functions. That may be better. I'll update this blog when I have time
4, Conclusion
This blog is just to supplement the current lack of a complete set of entry code for csdn. There are still many ways to go in the direction of speech recognition, many principles to learn, come on.