Asynchronous crawler
First understanding asynchronous crawler mode
- Multithreading, multiprocessing (not recommended):
-Advantages: threads and processes can be opened separately for related blocked (time-consuming) operations, and the blocked program will execute asynchronously
-Disadvantages: cannot limit multiple processes or multiple processes - Thread pool, process pool:
-Advantages: reduce the frequency of thread and process creation and destruction, and reduce the system overhead
-Disadvantages: there is an upper limit on the number of threads and processes in the pool
Take a chestnut to see the role of threads intuitively
import time
def get_text(char):
print("Downloading",char)
time.sleep(2)
print("Successfully loaded",char)
return char
#Single threaded operation:
#Run text
text=['a','b','c','d']
#Record start time
start_time=time.time()
for i in text:
get_text(i)
#Record end time
end_time=time.time()
print("Total time required for a single process:",end_time-start_time)
#Multithreading
#Guide library
from multiprocessing.dummy import Pool
#Instantiate 4 thread pool
pool=Pool(4)
start_time=time.time()
text_list=pool.map(get_text#The name of the objective function for multithreading, without ()
,text#List of incoming data
)
#The return value of the function is a list composed of the return value of the function, and the order corresponds to the incoming list
end_time=time.time()
print("Total time required for multiple processes:",end_time-start_time)
print(text_list)
The result is:
Downloading a
Successfully loaded a
Downloading b
Successfully loaded b
Downloading c
Successfully loaded c
Downloading d
Successfully loaded d
Total time required for a single process: 8.001578569412231
Downloading a
Downloading b
Downloading c
Downloading d
Successfully loaded b Successfully loaded d
Successfully loaded c
Successfully loaded a
Total time required for multiple processes: 2.0006678104400635
['a', 'b', 'c', 'd']
We find that the sequential end time of multithreading output is random, which also proves that multithreading does not affect each other
Come on, climb for the latest pear video
Code and part explanation
import os
from lxml import etree
import re
import requests
from multiprocessing.dummy import Pool
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.5211 SLBChan/25"
}
# Pear video url
url = 'https://www.pearvideo.com/'
# cookie cracking
session = requests.Session()
session.get(url=url, headers=header)
# Get the foreground code and parse the target url [1]
response = session.get(url=url, headers=header).text
tree = etree.HTML(response).xpath('/html/body/div[2]/div[9]/div[2]/div[2]/ul/li')
# Stores a list of names and addresses
content_name_loc = []
for each_tree in tree:
# each_tree.xpath('./div/a/@href')[0] address resolution is incomplete. Explain it completely [1]
each_loc = 'https://www.pearvideo.com/' + each_tree.xpath('./div/a/@href')[0]
# Definition of video storage name [1]
each_name = each_tree.xpath('./div/a/div[2]/text()')[0] + ".mp4"
# url_2 is each_loc enters a package inside the interface. We can't get the package directly from the foreground interface, so we need to get a new URL
# This url_2 is the address shared by all video detail interfaces. Different videos can be presented through the 'contId' value in different params
# Explanation [2]
url_2 = 'https://www.pearvideo.com/videoStatus.jsp?'
header_1 = {
# Explanation [2]
'Referer': each_loc
,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.5211 SLBChan/25"
}
# We found that the 'contId' parameter is not random, but we get each in the main interface_ A string of numbers after LOC
# Chestnuts:
# If each_loc=https://www.pearvideo.com/video_1733139
# Then the 'contId' parameter is' 1733373 ', so we pass'' To split
params = {
# See explanation [2] for the location of this parameter
'contId': each_loc.split('_')[-1]
}
each_response = session.get(url=url_2, params=params, headers=header_1).json()
# Look at the explanation below
str_1 = each_response["videoInfo"]["videos"]["srcUrl"]
"""
each_response of json character string
{
"resultCode":"1",
"resultMsg":"success", "reqId":"9424322a-fe48-48a8-86fd-85070498a1e8",
"systemTime": "1624770918308",
"videoInfo":{"playSta":"1","video_image":"https://image1.pearvideo.com/cont/20210624/11429718-143425-1.png",
"videos":{"hdUrl":"","hdflvUrl":"","sdUrl":"","sdflvUrl":"","srcUrl":"https://video.pearvideo.com/mp4/third/20210624/1624770918308-11429718-143415-hd.mp4"}}
}
What we need to extract is"https://video.pearvideo.com/mp4/third/20210624/1624770918308-11429718-143415-hd.mp4"
But we opened the website and found that it showed: 404 Not Found
Why?
Because the real website is in this form'https://video.pearvideo.com/mp4/third/20210624/cont-1733139-11429718-143415-hd.mp4'
So the discovery failed, so we think the video interface is ajax,It can't be resolved. Capturing packets is not what we want
But when the mountains and rivers are heavy, calm down and find that the website we just extracted is so similar to the video website
So I had an idea:
Split the existing extracted URL to form our target URL!!!
each_loc='https://www.pearvideo.com/video_1733139'
str_1="https://video.pearvideo.com/mp4/third/20210624/1624770918308-11429718-143415-hd.mp4"
new_loc='https://video.pearvideo.com/mp4/third/20210624/cont-1733139-11429718-143415-hd.mp4'
new_loc It's our goal. How can we get it?
Just put str_1 Replace 1624770918308 with cont-1733139
and cont I think it's the parameter name. Each video is the same
For 1733139 each_loc A string behind
So there is the following code
So let's start analyzing it step by step:
1. a = 'cont-' + each_loc.split('_')[-1]
each_loc.split('_')The result is
['https://www.pearvideo.com/video''1733139']
each_loc.split('_')[-1]namely'1733139',Add'cont-',That's what we want
2. re_1 = "(.*)/.*?-(.*)"
b = re.findall(re_1, str_1)
These two sentences are extracted using regular expressions str_1 Medium
'https://video.pearvideo.com/mp4/third/20210624 '(greedy matching is used because the last / end)
and
'11429718-143415-hd.mp4'
b The result is[("https://video.pearvideo.com/mp4/third/20210624","11429718-143415-hd.mp4")]
3. new_loc = b[0][0] + "/" + a + "-" + b[0][1]
Splice the results to get the results
Don't forget"/" and"-"
This gives us the video address we are looking for
"""
a = 'cont-' + each_loc.split('_')[-1]
print(str_1)
re_1 = "(.*)/.*?-(.*)"
b = re.findall(re_1, str_1)
new_loc = b[0][0] + "/" + a + "-" + b[0][1]
print(new_loc)
# You may have forgotten about multithreading here, hee hee
# Here, it is more convenient to crawl the content for the last multi thread
# We also use the dictionary format for the data video name each_name and new_ Place LOC in content_ name_ In LOC
content_name_loc.append({"name": each_name, "loc": new_loc})
# Output here to see if the results meet expectations
print(content_name_loc)
# create folder
if not os.path.exists("./Pear video"):
os.mkdir("./Pear video")
# Repackaging thread pool
def get_content(dic):
# Request data
video_data = session.get(url=dic['loc'], headers=header).content
# Open file and write
fp = open("./Pear video/" + dic["name"], mode="wb")
fp.write(video_data)
fp.close()
# Calculation time (related to network speed)
start = time.time()
# Instantiate the Pool and determine the number
pool = Pool(len(content_name_loc))
# Multithreading
pool.map(get_content, content_name_loc)
# Close thread
pool.close()
# Wait for all threads to end
pool.join()
end = time.time()
# Output time
print(end - start)
Look at the results:
(explain in advance that this is not the content that bloggers like. It's a complete coincidence. Believe me, hee hee ~ ~)

explain
Explanation [1]
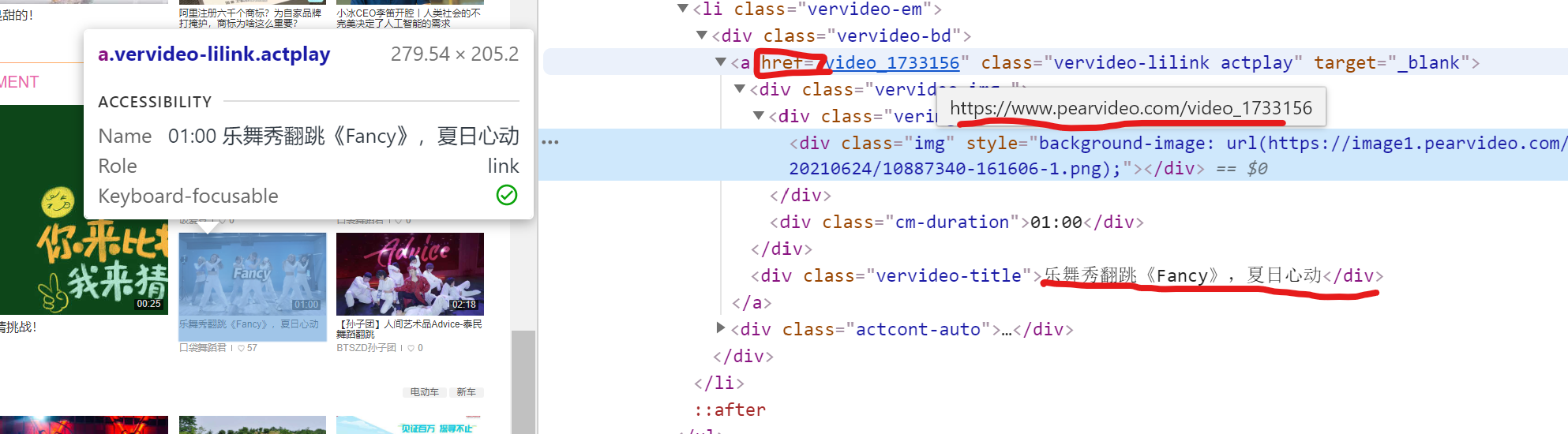
Just a few simple lines???
Yes, that's right!!! Silence is better than sound here
Explanation [2]
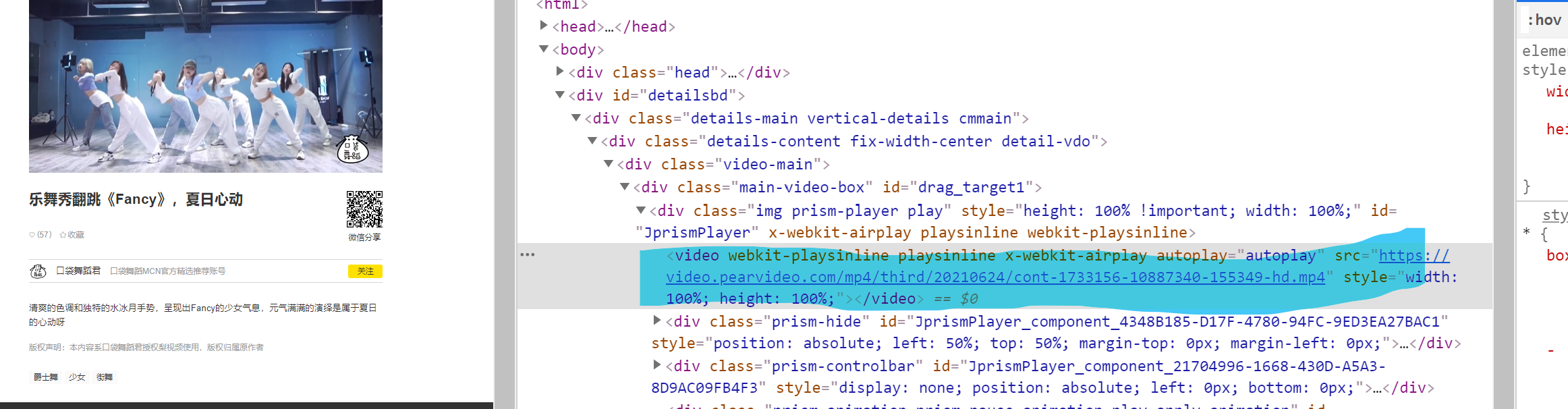
The blue content is the video address we want to get! Eh? What is this? I can't climb directly? Still use your segmentation? But after you crawl, you will find that you can't find this website in the data Why? Let's refresh the interface
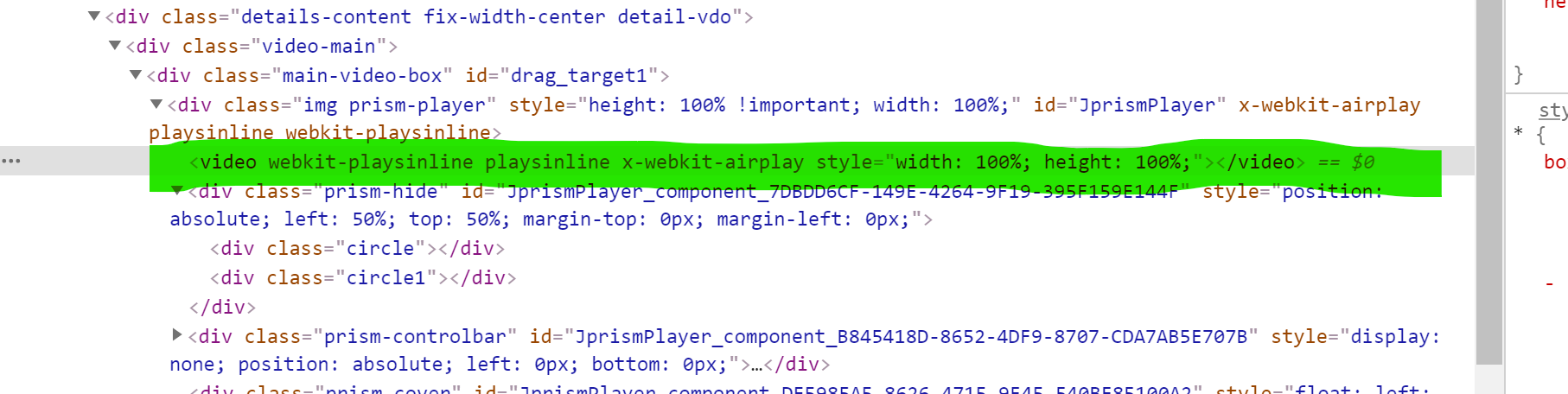
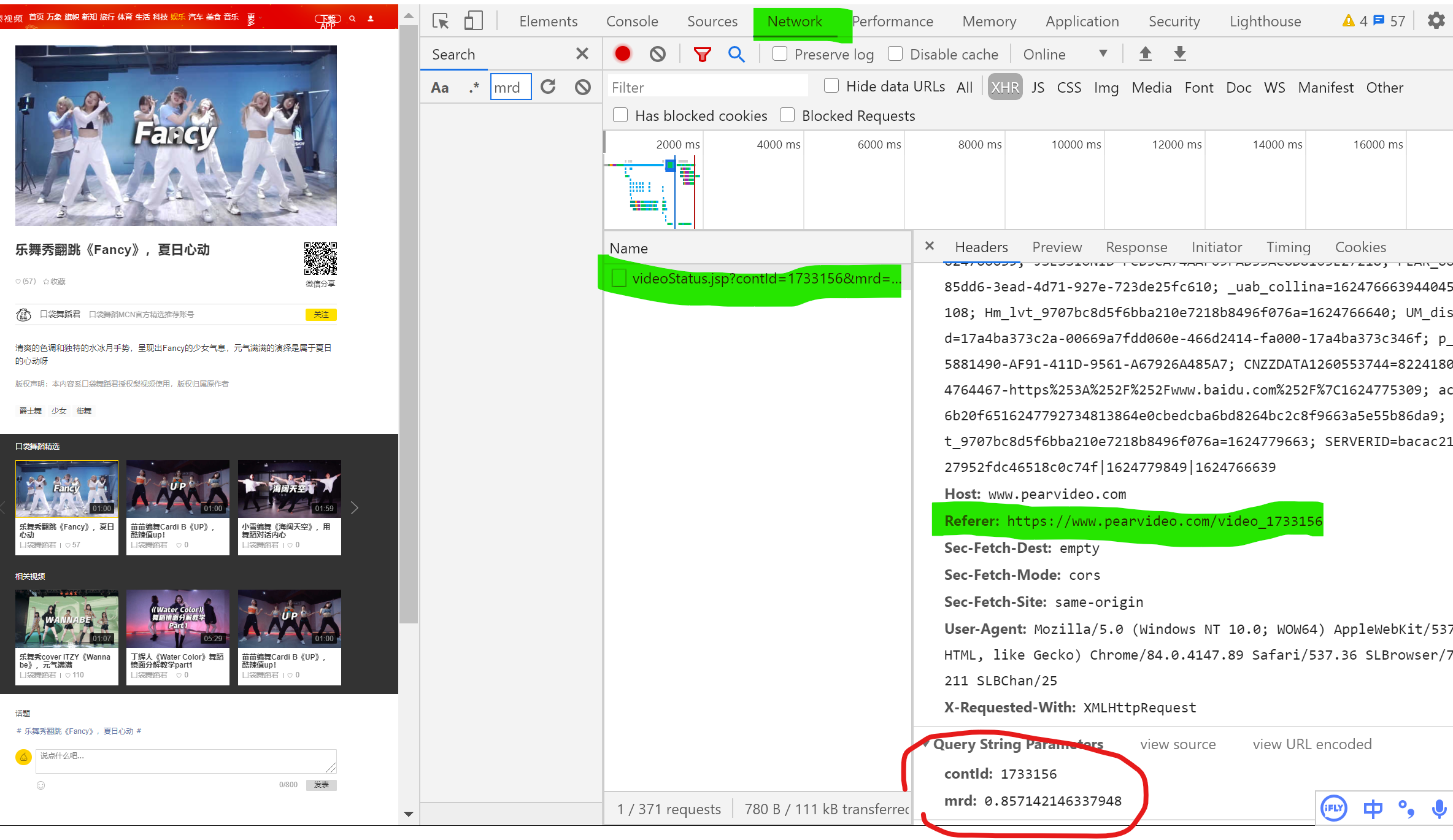
That website will disappear So we suspect ajxa,So we copied it and looked in the bag Results no results, in XHR There is only one package in the. This package is the synthesis we mentioned new_loc My bag have other refer Parameters need to be in headers in The return value code of the package has been mentioned and will not be shown here
Concurrent asynchronous programming
What is a collaborative process:
A coroutine is not a process or thread. Its execution process is more similar to a subroutine, or a function call without a return value.
A program can contain multiple processes, which can be compared with a process containing multiple threads. Therefore, let's compare processes and threads. We know that multiple threads are relatively independent, have their own context, and the switching is controlled by the system; The collaboration process is also relatively independent and has its own context, but its switching is controlled by itself. Switching from the current collaboration process to other collaboration processes is controlled by the current collaboration process.
Significance of collaborative process:
At the same time, multiple time-consuming operations are run at the same time to improve the operation efficiency of our code. In the crawler, you can request multiple data and crawl multiple data / pictures / videos at the same time
Methods to realize Ctrip:
- greeenlt
- yeid
- asyncio
- async, await keyword
We don't need to know 1, 2 and 3 here. We focus on 4, because the fourth is the most efficient and the code is more concise. In addition, python 3 The use of the third co process is not supported after 7
event loop
It can be understood as an endless loop, which always checks the execution of some code
# Each event has its own status: completed, incomplete: pending task list=[Task 1, task 2, task 3....] while True: List of executable tasks=Take out the tasks that can be run from the task list Completed task list=Take out the completed tasks from the task list for Ready task in List of executable tasks: Execute ready task for Task completed in Completed task list: Remove completed tasks from the task list Jump out of the loop until the task list is complete
Shape such as
async def Function name:
Function body
Is a coprocessor function
The call of a coroutine function is a coroutine object, that is, the function name()
However, the object obtained by calling the coprocessor function will not be executed directly(Because the event is not loaded into the task list of the event loop)
Specific functions are required to implement
Cognitive synergy
import asyncio
async def request_1(url):
print('Requesting url yes',url)
print('Request succeeded,',url)
return url
async def request_2(url):
print('Requesting url yes', url)
print('Request succeeded,', url)
return url
# Create an event loop object
loop = asyncio.get_event_loop()
# A task is created based on loop_ 1 task object (note that the task loop.create_task must be created after the event loop is created)
task_1 = loop.create_task(request_1("https://www.taobao.com/"))
# A task is created based on loop_ 2 task object. Now there are two tasks in the loop event cycle
task_2=loop.create_task(request_2("https://www.baidu.com/?"))
print(task_2)#Check the status
# Start the event loop, which can be either a task object or a coroutine object
# The function will automatically add one step to register the collaboration object in the loop event loop
loop.run_until_complete(task_1)
print(task_2)#Result finished
print(task_1)#Result finished
#Description loop run_ until_ Complete (task_1) running task_ 1 starts all task event objects in the event loop
# So, is it possible to run all events by starting only one event cycle in the future? Of course not
# Because in the task_1 in a very short time after completion, the main program has not had time to print(task_2), task_ 2 is also completed immediately, so that we can see the task when print(task_2)_ 2 completed
#When task_ 2 takes a little longer (for example, when await asyncio.sleep(0.01) is added to request_2, it will be found that although it is 0.01 seconds, the result of print(task_2) is pending, that is, it is not completed)
#Explain that the following code may be executed when other tasks are not completed for some reason
#So we need to ensure that all tasks are completed before we can continue to run, so what should we do?
Multiple event initiation
import asyncio
async def request_1(url):
print('Requesting url yes',url)
print('Request succeeded,',url)
return url
async def request_2(url):
print('Requesting url yes', url)
print('Request succeeded,', url)
return url
#******************Method 1****************
# Create an event loop object
loop = asyncio.get_event_loop()
#Don't actually use loop create_ Task can also be run, but it is recommended to add
task_list = [
loop.create_task(request_1("https://www.baidu.com/?"))
,loop.create_task(request_1("https://www.taobao.com/"))
]
#It has been mentioned above in run_ until_ Task object and collaboration object to be passed in complete
#So loop run_ until_ Complete (task_list) is wrong because task_ List is a list
#And add asyncio Wait can implement the incoming task list
#In this way, all tasks in the loop can be realized before proceeding to the next step
done,pending=loop.run_until_complete(asyncio.wait(task_list))
#done is the collection of completed tasks and pending is the collection of unfinished tasks
#******************Method 2****************
task_list = [
request_1("https://www.baidu.com/?")
,request_1("https://www.taobao.com/")
]
#The meaning of this code is to create an event loop and run it
#Equivalent to loop = asyncio get_ event_ Loop () and loop run_ until_ Complete (asyncio. Wait (task_list))
#However, you should pay special attention to the fact that the task must be created after the event loop is created_ List can only be written as a collaboration object, not a task object
done,pending=asyncio.run(asyncio.wait(task_list))
So far, the above co process codes are run in a single thread, that is, when starting the event cycle, the sequence of running is that one task runs and then the next task runs. Not all times in the time cycle run at the same time, so it does not achieve our goal of multithreading. For running multiple threads at the same time, You need to manually suspend some specific statements in the coroutine function. These suspended functions are generally time-consuming functions. When will they run down after the function is suspended? Here we return to our cycle time. The function of cycle time is to detect the state of the suspended function in the task. When it is detected that it has been completed, it will run downward. So how to hang? We use the keyword await
await keyword
import asyncio
# await + wait object (collaboration object, Future, Task object) IO wait
# When running the statement after await, it will automatically switch to other tasks to run multiple tasks at the same time
#When used by crawlers, they are usually get and post requests
async def request_1(url):
print('Requesting url yes', url)
await asyncio.sleep(5)
print('Request succeeded,', url)
return url
async def request_2(url):
print('Requesting url yes', url)
await asyncio.sleep(2)
print('Request succeeded,', url)
return url
task_list = [
request_1("https://www.baidu.com/?")
, request_2("https://www.taobao.com/")
]
start = time.time()
done,pending=asyncio.run(asyncio.wait(task_list))
print(time.time() - start)
result:
Requesting url yes https://www.baidu.com/?
Requesting url yes https://www.taobao.com/
Request succeeded, https://www.taobao.com/
Request succeeded, https://www.baidu.com/?
5.001507520675659
"""
asyncio.run(asyncio.wait(task_list))Running sequence:
Enter first request_1("https://www.baidu.com/? "), running to await asyncio.sleep(5) suspended
Then enter request_2("https://www.taobao.com / "), run to await asyncio.sleep(2) and hang (if there are other tasks to run),
If no task is detected, the cycle ends, and the event cycle continues to detect the status of the tasks in the whole task list in turn,
If the pending function is not completed, proceed to the next task. If it is not completed, continue to detect the status of the tasks in the whole task list in turn,
If it detects that a task has completed the suspended function, it will run immediately below the suspended function of the task until it meets another task await Function or finished running (deleted from the task list),
Then perform the next task status detection
"""
Callback function
Why is there a callback function
async def request_1(url):
print('Requesting url yes', url)
await asyncio.sleep(5)
print('Request succeeded,', url)
return url
When used by reptiles, it is usually incoming url,
return Return to get,post Information
But we can't get it directly return Returned value
Therefore, it should be implemented through the callback function
import asyncio
#Co process function
async def request_1(url):
print('Requesting url yes', url)
await asyncio.sleep(2)
print('Request succeeded,', url)
return url
#Callback function
def call_back(t):
# Data can be parsed here through t.result()
print(t.result())
#Create event loop
loop=asyncio.get_event_loop()
#Add task to time cycle
task_1=loop.create_task(request_1("https://www.baidu.com/?"))
#Bind a coroutine task to a callback function
task_1.add_done_callback(call_back)
#Run loop
loop.run_until_complete(task_1)
Note: the callback function must be finished async def request_1(url)after
The return value is automatically passed in as a parameter through a special wrapper def call_back(t)in
Pass in callback function t.result()You can get it request_1 Returned value
requests in collaboration - aiohttp
because requests Multithreading is not supported, so we have to replace the library to achieve data crawling, that is aiohttp Medium ClientSession() It and requests Same usage, except get,post Parameters in function proxy Changed from dictionary form to string form.
import asyncio
import aiohttp
#The reason why async with as is used is that it automatically closes the instantiated object after running. The modifier keyword async is a fixed usage of the coprocessor function with as
async def request(url_1):
async with aiohttp.ClientSession() as session:
# Don't forget () in ClientSession()
async with await session.get(url_1) as response:
# Note the string type data (text)
# Binary (picture video) type data read()
# json() returns the json object
page_text = await response.text()
return page_text
def call_back_fun(t):
# Resolvable stored data
print("The result is:",t.result())
# Crawl URL target
loc_list = [
"https://www.taobao.com/"
, "https://www.jd.com/"
]
# Create event loop
loop = asyncio.get_event_loop()
# Store task object
task_list = []
for i in loc_list:
# Add task object in loop
task = loop.create_task(request(i))
# Bind callback function for each task object
task.add_done_callback(call_back_fun)
# Save task to list
task_list.append(task)
# Start loop
loop.run_until_complete(asyncio.wait(task_list))
Data crawling based on CO process
import os
import asyncio
import aiohttp
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.5211 SLBChan/25"
}
# Incoming url and picture name
async def request(url_1, name):
async with aiohttp.ClientSession() as session:
async with await session.get(url_1) as response:
page_text = await response.read()
return [page_text, name]
# Give the data and picture name to the callback function
# Callback parameters are in list form
def call_back_fun(t):
data=t.result()[0]
name=t.result()[1]
with open("./Picture crawling/" + name + ".jpg", mode="wb") as fp:
fp.write(data)
print(name," has been over")
# Crawling website target (two picture addresses)
loc_list = [
"https://img1.baidu.com/it/u=684012728,3682755741&fm=26&fmt=auto&gp=0.jpg"
, "https://img2.baidu.com/it/u=3236440276,662654086&fm=26&fmt=auto&gp=0.jpg"
]
name_list = ["Little sister 1", "Little sister 2"]
# Create event loop
loop = asyncio.get_event_loop()
# Store task object
task_list = []
for j, i in enumerate(loc_list):
# Add task object in loop
task = loop.create_task(request(i, name_list[j]))
# Bind callback function for each task object
task.add_done_callback(call_back_fun)
# Save task to list
task_list.append(task)
if not os.path.exists("./Picture crawling"):
os.mkdir("./Picture crawling")
# Start loop
loop.run_until_complete(asyncio.wait(task_list))
[continuous updat ing]
