python chain home asynchronous IO crawler, using asyncio, aiohttp and aiomysql
Many small partners will learn about crawlers when they start to learn python. When they start to learn python, they will use requests and urlib synchronous libraries for single thread crawlers, which is slow. Later, they will use the scratch framework for crawlers, which is very fast, because the scratch is based on the twisted multi-threaded different step IO framework.
asyncio used in this example is also an asynchronous IO framework. After python3.5, async, the keyword of the orchestration, is added to distinguish the orchestration and the generator, making it more convenient to use the orchestration.
After testing, 30 detail pages can be crawled in one second on average
asyncio.Semaphore can be used to control the concurrency and achieve the effect of speed limit
# -*- coding: utf-8 -*-
"""
:author: KK
:url: http://github.com/PythonerKK
:copyright: © 2019 KK <705555262@qq.com.com>
"""
import asyncio
import re
import aiohttp
from pyquery import PyQuery
import aiomysql
from lxml import etree
pool = ''
#sem = asyncio.Semaphore(4) is used to control the concurrency number, and it is not specified to run at full speed
stop = False
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
MAX_PAGE = 10
TABLE_NAME = 'data' #Data table name
city = 'zh' #Urban shorthand
url = 'https://{}. Lianjia. COM / ershoufang / PG {} / '(URL address splicing)
urls = [] #List of URLs for all pages
links_detail = set() #Collection of detail page links in crawl
crawled_links_detail = set() #Crawling the completed link set for easy de duplication
async def fetch(url, session):
'''
aiohttp Get web source code
'''
# async with sem:
try:
async with session.get(url, headers=headers, verify_ssl=False) as resp:
if resp.status in [200, 201]:
data = await resp.text()
return data
except Exception as e:
print(e)
def extract_links(source):
'''
//Extract links to details page
'''
pq = PyQuery(source)
for link in pq.items("a"):
_url = link.attr("href")
if _url and re.match('https://.*?/\d+.html', _url) and _url.find('{}.lianjia.com'.format(city)):
links_detail.add(_url)
print(links_detail)
def extract_elements(source):
'''
//Extract the details in the details page
'''
try:
dom = etree.HTML(source)
id = dom.xpath('//link[@rel="canonical"]/@href')[0]
title = dom.xpath('//title/text()')[0]
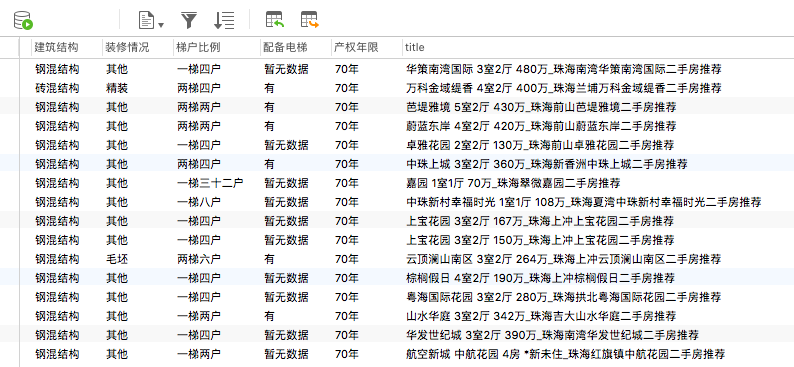
price = dom.xpath('//span[@class="unitPriceValue"]/text()')[0]
information = dict(re.compile('<li><span class="label">(.*?)</span>(.*?)</li>').findall(source))
information.update(title=title, price=price, url=id)
print(information)
asyncio.ensure_future(save_to_database(information, pool=pool))
except Exception as e:
print('Error parsing details page!')
pass
async def save_to_database(information, pool):
'''
//Using asynchronous IO to save data to mysql
//Note: if no data table exists, create the corresponding table
'''
COLstr = '' # Column fields
ROWstr = '' # Row field
ColumnStyle = ' VARCHAR(255)'
for key in information.keys():
COLstr = COLstr + ' ' + key + ColumnStyle + ','
ROWstr = (ROWstr + '"%s"' + ',') % (information[key])
# Asynchronous IO mode inserted into database
async with pool.acquire() as conn:
async with conn.cursor() as cur:
try:
await cur.execute("SELECT * FROM %s" % (TABLE_NAME))
await cur.execute("INSERT INTO %s VALUES (%s)"%(TABLE_NAME, ROWstr[:-1]))
print('Insert data successful')
except aiomysql.Error as e:
await cur.execute("CREATE TABLE %s (%s)" % (TABLE_NAME, COLstr[:-1]))
await cur.execute("INSERT INTO %s VALUES (%s)" % (TABLE_NAME, ROWstr[:-1]))
except aiomysql.Error as e:
print('mysql error %d: %s' % (e.args[0], e.args[1]))
async def handle_elements(link, session):
'''
//Get the contents of detail page and analyze
'''
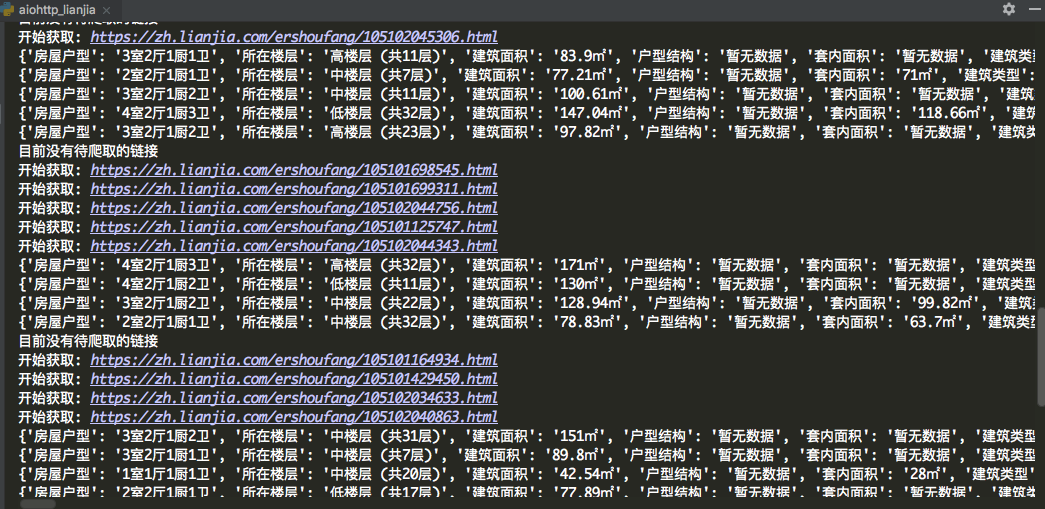
print('Start getting: {}'.format(link))
source = await fetch(link, session)
#Add to crawled collection
crawled_links_detail.add(link)
extract_elements(source)
async def consumer():
'''
//Consume links not crawled
'''
async with aiohttp.ClientSession() as session:
while not stop:
if len(urls) != 0:
_url = urls.pop()
source = await fetch(_url, session)
print(_url)
extract_links(source)
if len(links_detail) == 0:
print('There is no link to climb at present')
await asyncio.sleep(2)
continue
link = links_detail.pop()
if link not in crawled_links_detail:
asyncio.ensure_future(handle_elements(link, session))
async def main(loop):
global pool
pool = await aiomysql.create_pool(host='127.0.0.1', port=3306,
user='root', password='xxxxxx',
db='aiomysql_lianjia', loop=loop, charset='utf8',
autocommit=True)
for i in range(1, MAX_PAGE):
urls.append(url.format(city, str(i)))
print('Total pages crawled:{} Task begins...'.format(str(MAX_PAGE)))
asyncio.ensure_future(consumer())
if __name__ == '__main__':
loop = asyncio.get_event_loop()
asyncio.ensure_future(main(loop))
loop.run_forever()